Towards Neuromorphic Learning Machines Using Emerging Memory Devices with Brain-Like Energy Efficiency


Abstract
1. Introduction
2. Neuromorphic Computing and Emerging Devices
2.1. Digital Neuromorphic Platforms
2.2. Subthreshold Analog Neuromorphic Platforms
2.3. Neuromorphic Platforms Using Floating-Gate and Phase Change Memories
2.4. Nanoscale Emerging Devices
- Non-volatility and high-resolution of the synaptic weights
- High neurosynaptic density, approaching billions of synapses and millions of neurons per chip
- Massively-parallel learning algorithms with localized updates (or in-memory computing)
- Event-driven ultra-low-power neural computation and communication
3. Mixed-Signal Neuromorphic Architecture
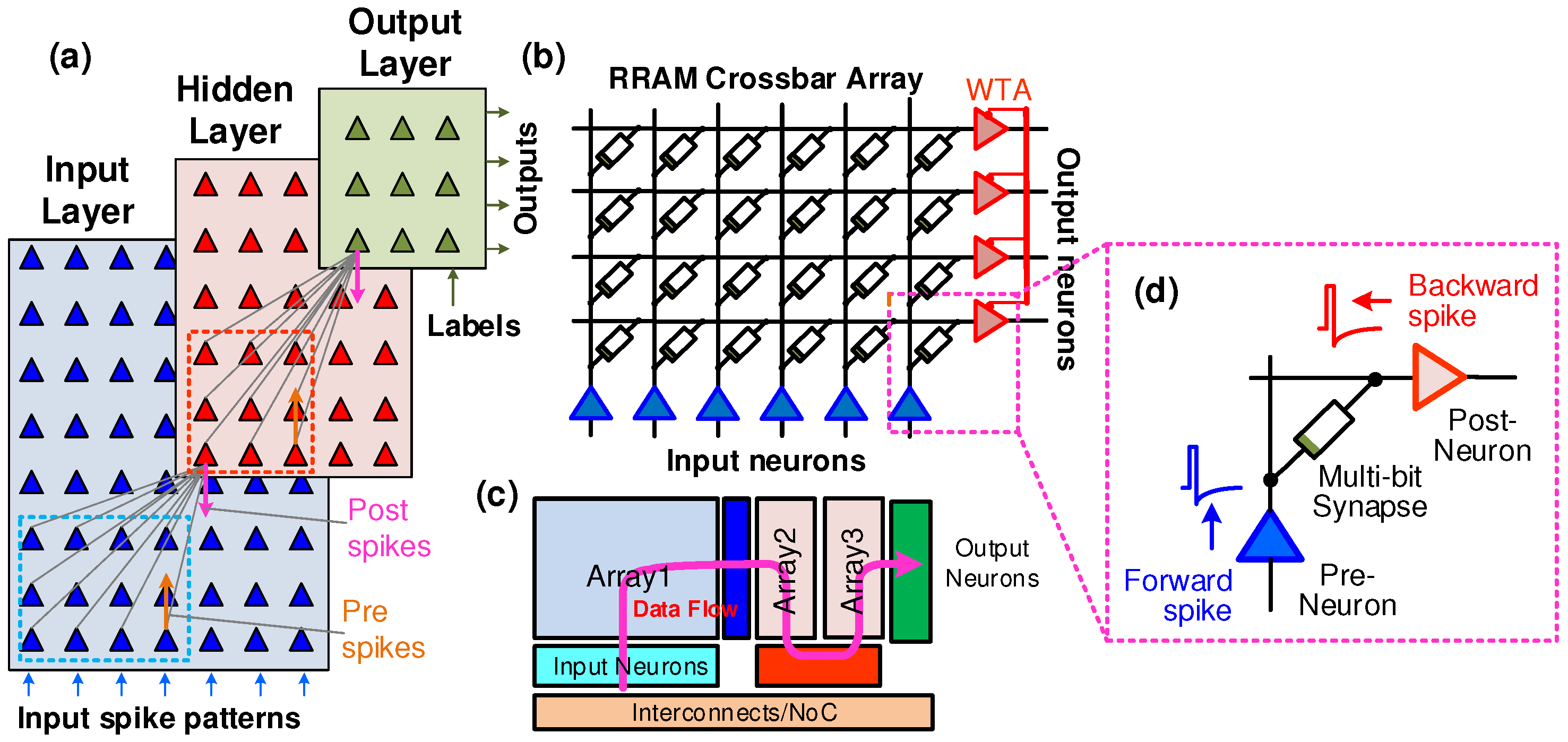
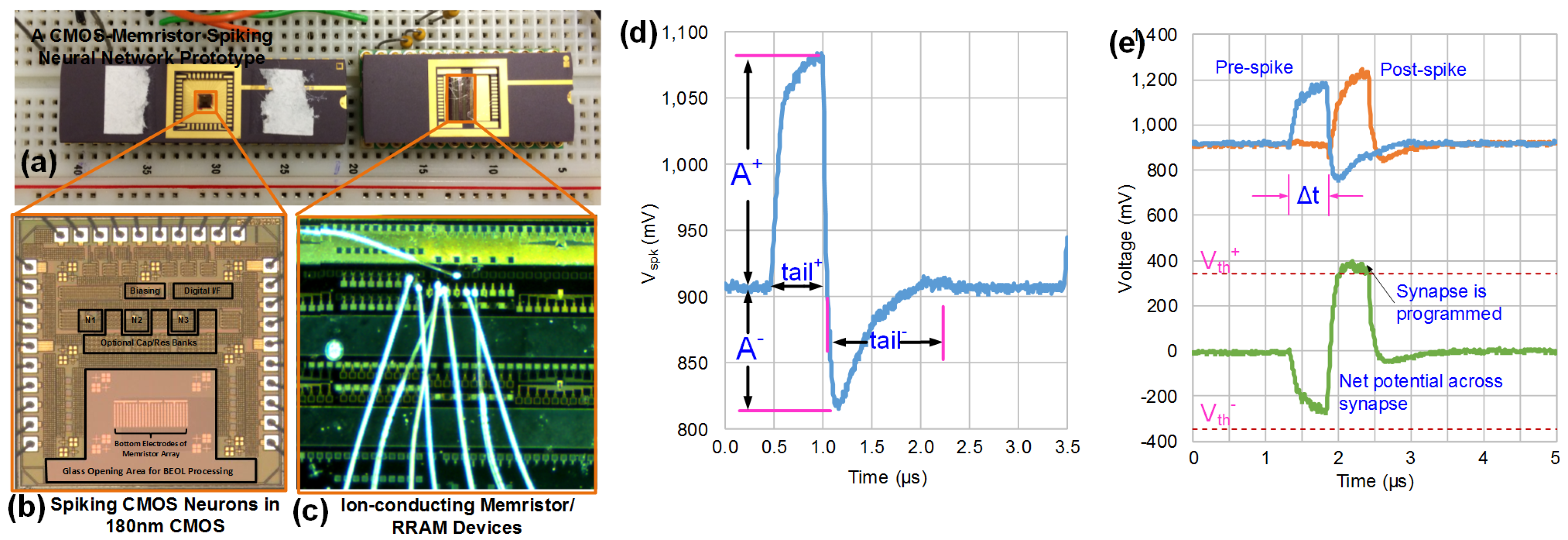
3.1. Crossbar Networks
3.2. Analog Synapses Using RRAM/Memristors
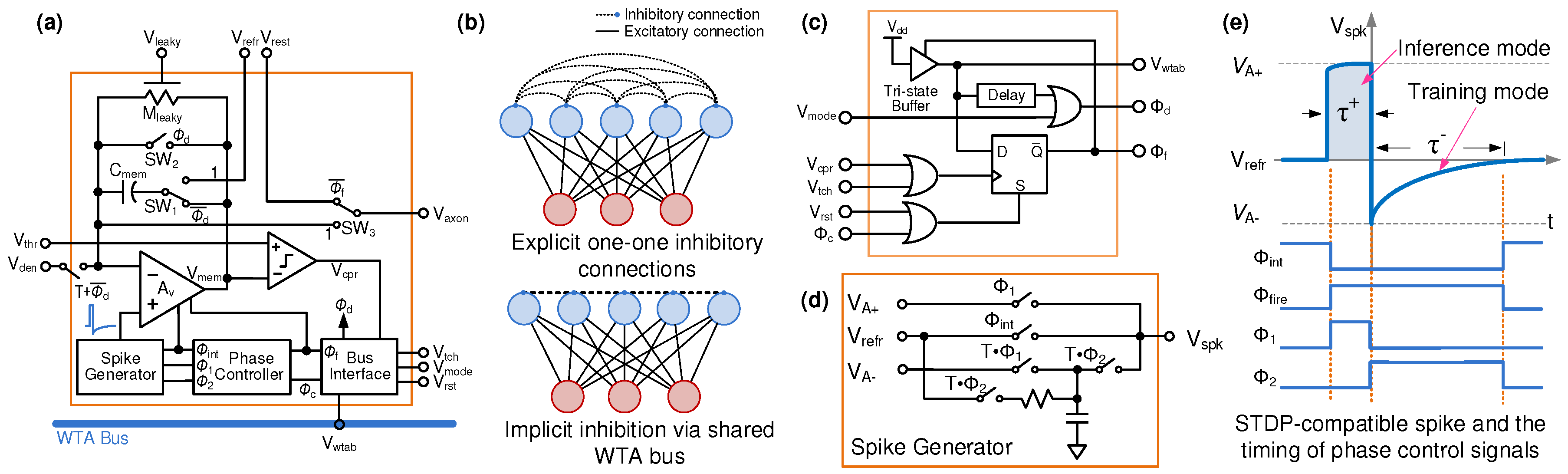
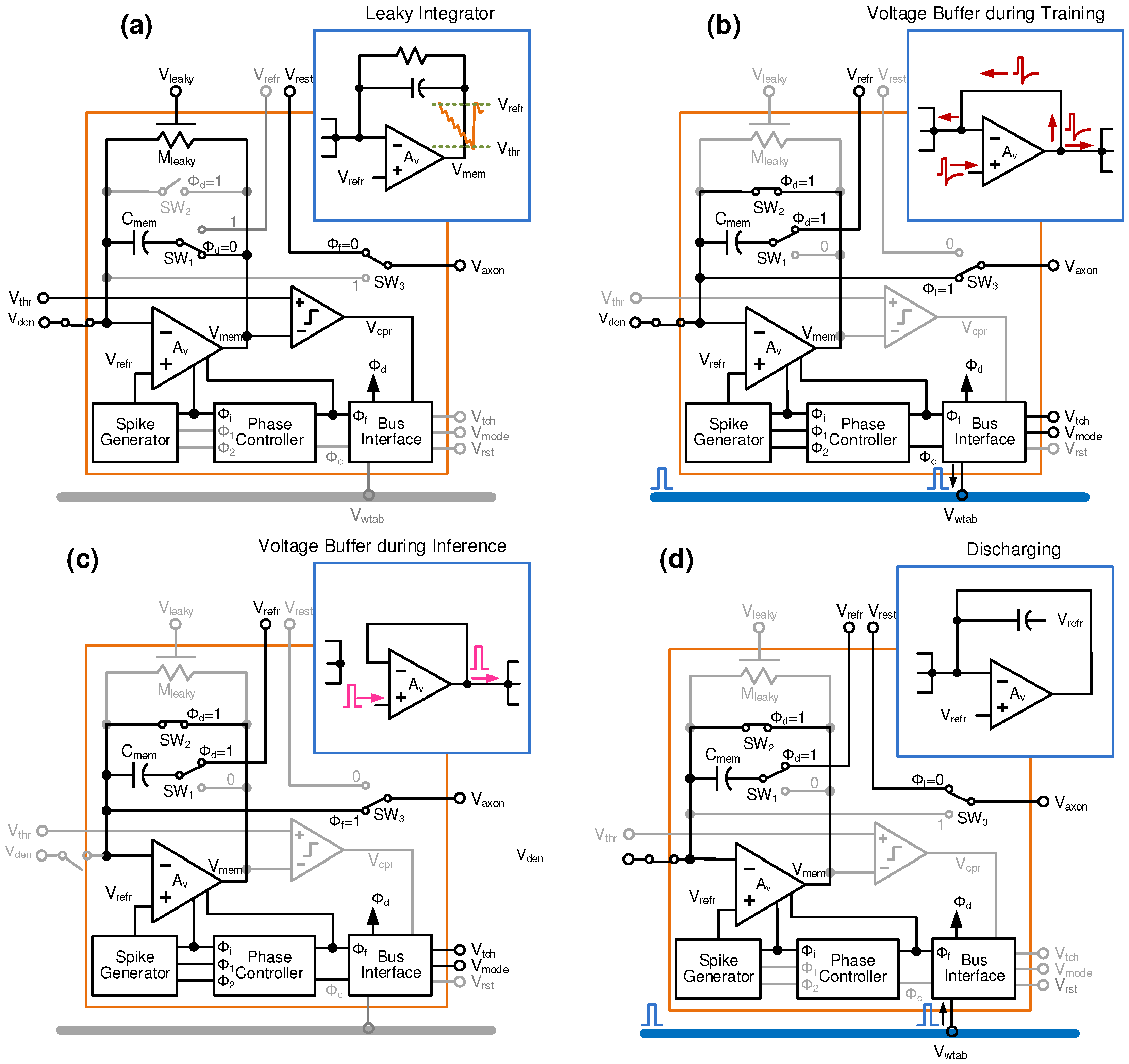
3.3. Event-Driven Neurons with Localized Learning
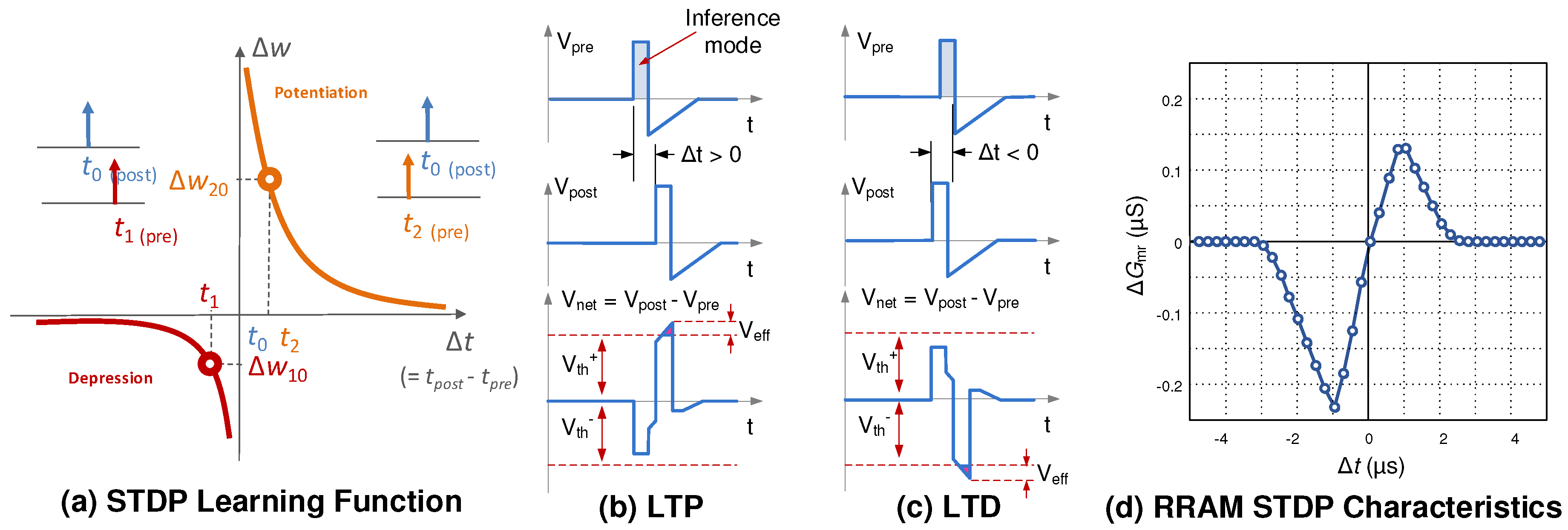
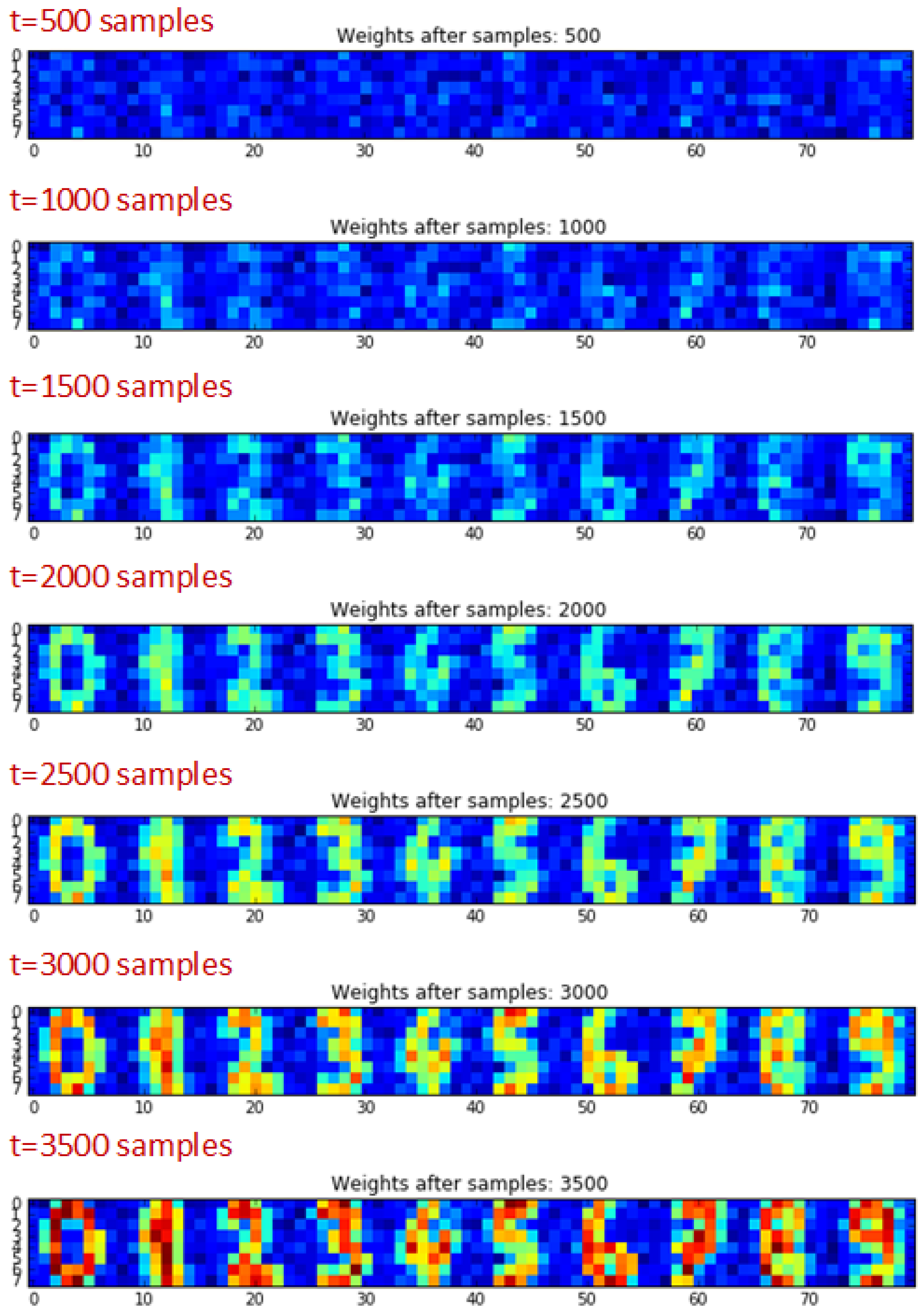
3.4. Spike-Based Neural Learning Algorithms
3.5. Challenges with Emerging Devices as Synapses
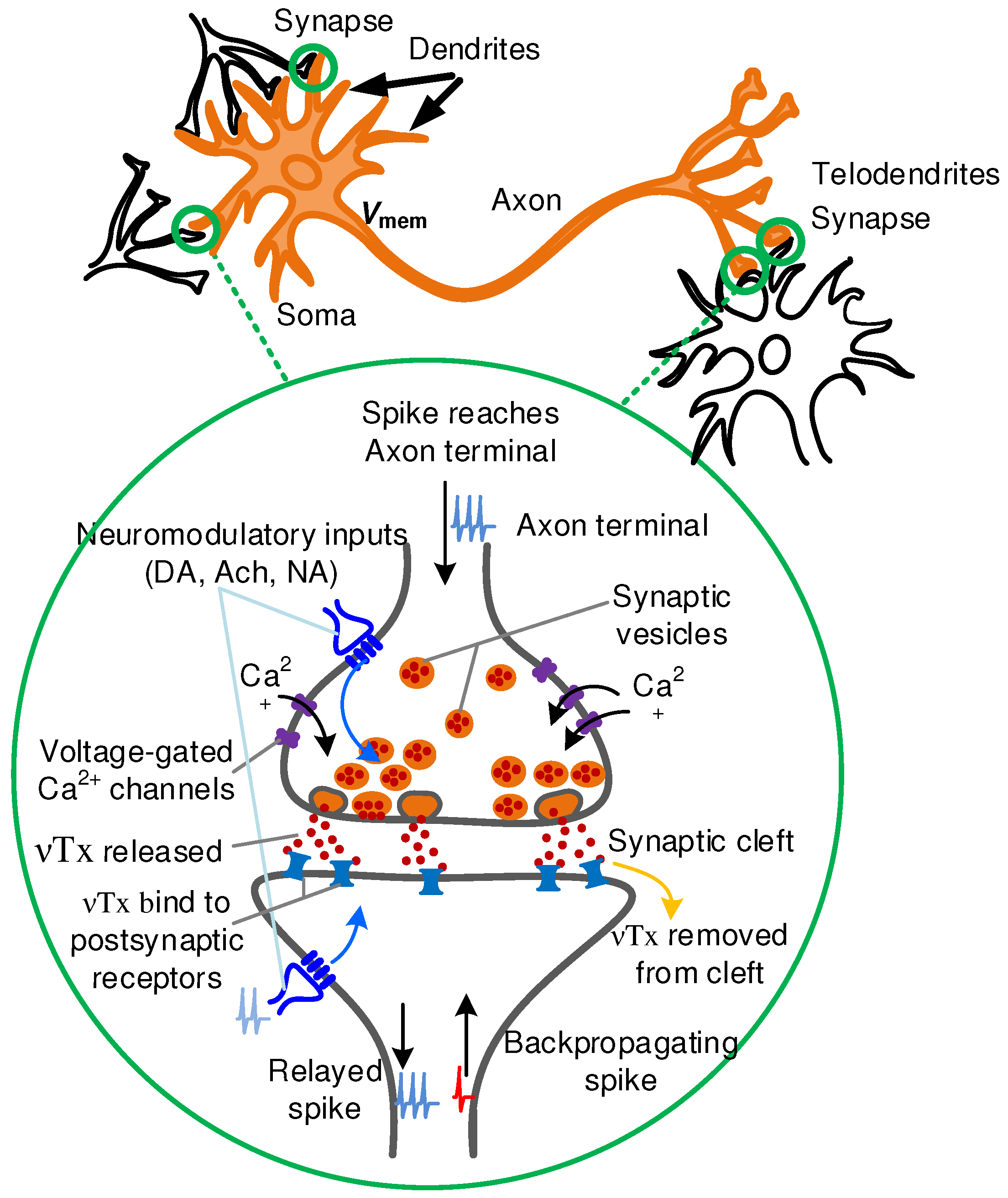
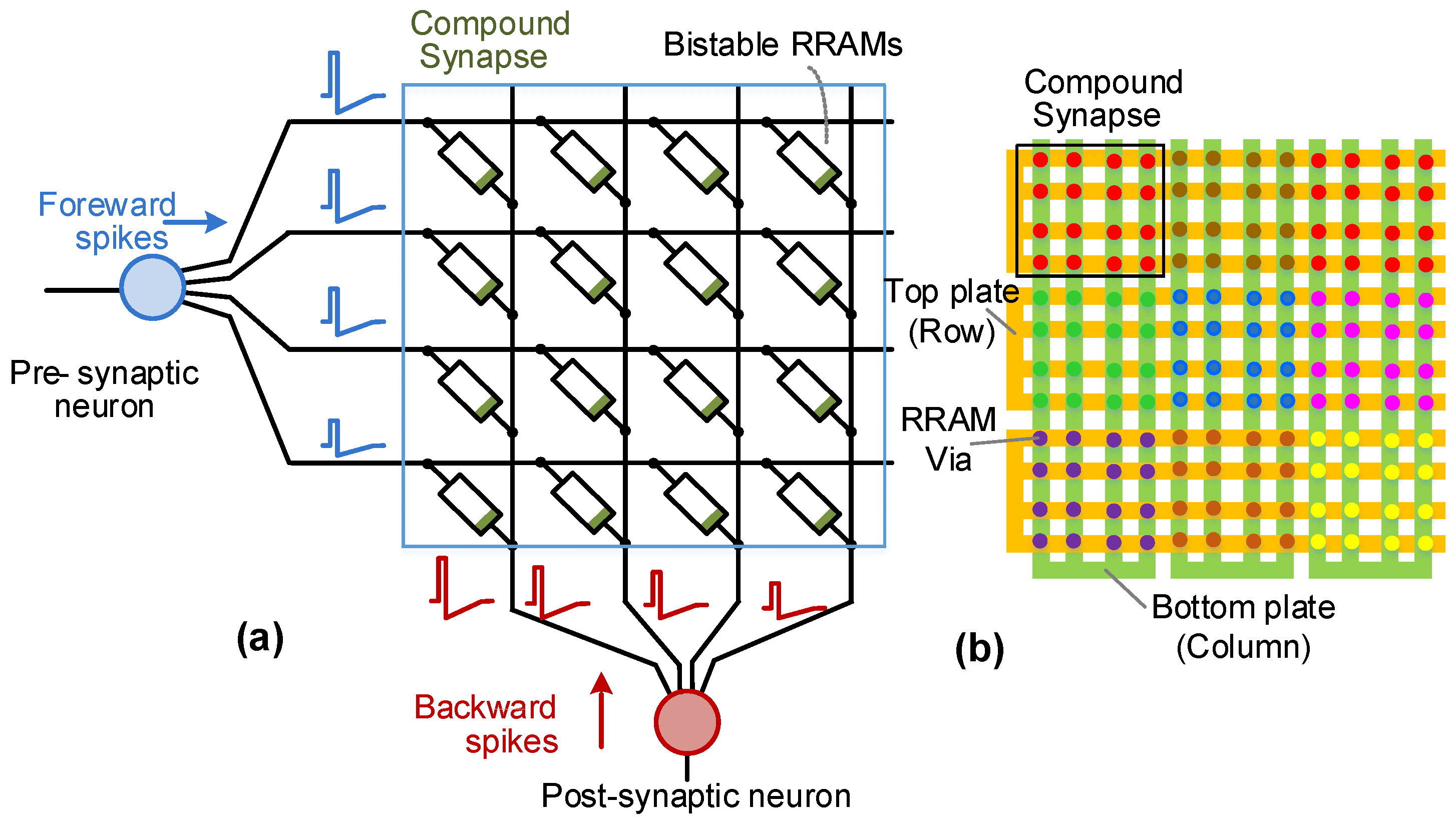
4. Bio-Inspiration for Higher-Resolution Synapses
4.1. Compound Synapse with Axonal and Dendritic Processing
4.2. Modified CMOS Neuron with Dendritic Processing
5. Energy-Efficiency of Neuromorphic SoCs
6. Towards Large-Scale Neuromorphic SoCs
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| ASIC | Application Specific Integrated Circuit |
| CBRAM | Conductive Bridge Random Access Memory |
| CMOS | Complementary Metal Oxide Semiconductor |
| CNN | Convolutional Neural Network |
| DAC | Digital-to-Analog Converter |
| eRBP | Event-Driven Random Backpropagation |
| FPGA | Field Programmable Gate Array |
| GPU | Graphics Processing Unit |
| HRS | High-Resistance State |
| IC | Integrated Circuit |
| ICA | Intelligent Cognitive Assistants |
| LRS | Low-Resistance State |
| LTD | Long-Term Depression |
| LTP | Long-Term Potentiation |
| NVM | Non-Volatile Memory |
| PCM | Phase Change Memory |
| PCRAM | Phase Change Random Access Memory |
| RRAM | Resistive Random Access Memory |
| SF | Source Follower |
| RBP | Random Backpropagation |
| SRAM | Static Random Access Memory |
| SNN | Spiking Neural Networks |
| SNR | Signal-to-Noise Ratio |
| STDP | Spike-Timing Dependent Plasticity |
| STTRAM | Spin-Transfer Torque Random Access Memory |
| TSV | Through-Silicon Via |
| NeuSoC | Neuromorphic System-on-a-Chip |
| VLSI | Very Large Scale Integrated Circuits |
| WTA | Winner Take All |
References
- Williams, R.; DeBenedictis, E.P. OSTP Nanotechnology-Inspired Grand Challenge: Sensible Machines. In IEEE Rebooting Computing Whitepaper; 2015; Available online: http://www.webcitation.org/72ppzDEKx (accessed on 30 September 2018).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Kandel, E.R.; Schwartz, J.H.; Jessell, T.M.; Siegelbaum, S.A.; Hudspeth, A.J. Principles of Neural Science; McGraw-Hill: New York, NY, USA, 2000; Volume 4. [Google Scholar]
- Krzanich, B. Intel Pioneers New Technologies to Advance Artificial Intelligence. Available online: http://www.webcitation.org/72pqcyFZF (accessed on 30 September 2018).
- Bi, G.Q.; Poo, M.M. Synaptic modification by correlated activity: Hebb’s postulate revisited. Annu. Rev. Neurosci. 2001, 24, 139–166. [Google Scholar] [CrossRef] [PubMed]
- Dan, Y.; Poo, M.M. Spike timing-dependent plasticity of neural circuits. Neuron 2004, 44, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Masquelier, T.; Thorpe, S.J. Unsupervised Learning of Visual Features through Spike Timing Dependent Plasticity. PLoS Comput. Biol. 2007, 3, e31. [Google Scholar] [CrossRef] [PubMed]
- Nessler, B.; Pfeiffer, M.; Buesing, L.; Maass, W. Bayesian computation emerges in generic cortical microcircuits through spike-timing-dependent plasticity. PLoS Comput. Biol. 2013, 9, e1003037. [Google Scholar] [CrossRef] [PubMed]
- Burr, G.W.; Shelby, R.M.; Sebastian, A.; Kim, S.; Kim, S.; Sidler, S.; Virwani, K.; Ishii, M.; Narayanan, P.; Fumarola, A.; et al. Neuromorphic computing using non-volatile memory. Adv. Phys. 2017, 2, 89–124. [Google Scholar] [CrossRef]
- James, C.D.; Aimone, J.B.; Miner, N.E.; Vineyard, C.M.; Rothganger, F.H.; Carlson, K.D.; Mulder, S.A.; Draelos, T.J.; Faust, A.; Marinella, M.J.; et al. A historical survey of algorithms and hardware architectures for neural-inspired and neuromorphic computing applications. Biol. Inspired Cogn. Architect. 2017, 19, 49–64. [Google Scholar] [CrossRef]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A survey of neuromorphic computing and neural networks in hardware. arXiv, 2017; arXiv:1705.06963. [Google Scholar]
- Merolla, P.A.; Arthur, J.V.; Alverez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Sci. Mag. 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Painkras, E.; Plana, L.; Garside, J.; Temple, S.; Davidson, S.; Pepper, J.; Clark, D.; Patterson, C.; Furber, S. Spinnaker: A multi-core system-on-chip for massively-parallel neural net simulation. In Proceedings of the 2012 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 9–12 September 2012; pp. 1–4. [Google Scholar]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Liu, S.C. Event-Based Neuromorphic Systems; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Indiveri, G. Neuromorphic Bisable VLSI Synapses with Spike-Timing-Dependent Plasticity. In Proceedings of the Neural Information Processing Systems 2003, Vancouver, BC, Canada, 8–13 December 2003; pp. 1115–1122. [Google Scholar]
- Fusi, S.; Annunziato, M.; Badoni, D.; Salamon, A.; Amit, D.J. Spike-driven synaptic plasticity: Theory, simulation, VLSI implementation. Neural Comput. 2000, 12, 2227–2258. [Google Scholar] [CrossRef] [PubMed]
- Indiveri, G.; Chicca, E.; Douglas, R. A VLSI reconfigurable network of integrate-and-fire neurons with spike-based learning synapses. In Proceedings of the 2004 European Symposium on Artificial Neural Networks, Bruges Belgium, 28–30 April 2004. [Google Scholar]
- Indiveri, G.; Chicca, E.; Douglas, R. A VLSI array of low-power spiking neurons and bistable synapses with spike-timing dependent plasticity. IEEE Trans. Neural Netw. 2006, 17, 211–221. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Fusi, S.; Indiveri, G. Real-Time Classification of Complex Patterns Using Spike-Based Learning in Neuromorphic VLSI. IEEE Trans. Biomed. Circuits Syst. 2009, 3, 32–42. [Google Scholar] [CrossRef] [PubMed]
- Qiao, N.; Mostafa, H.; Corradi, F.; Osswald, M.; Stefanini, F.; Sumislawska, D.; Indiveri, G. A reconfigurable on-line learning spiking neuromorphic processor comprising 256 neurons and 128 K synapses. Front. Neurosci. 2015, 9, 141. [Google Scholar] [CrossRef] [PubMed]
- Azghadi, M.R.; Iannella, N.; Al-Sarawi, S.F.; Indiveri, G.; Abbott, D. Spike-based synaptic plasticity in silicon: design, implementation, application, and challenges. Proc. IEEE 2014, 102, 717–737. [Google Scholar] [CrossRef]
- Benjamin, B.V.; Gao, P.; McQuinn, E.; Choudhary, S.; Chandrasekaran, A.R.; Bussat, J.M.; Alvarez-Icaza, R.; Arthur, J.V.; Merolla, P.; Boahen, K. Neurogrid: A mixed-analog-digital multichip system for large-scale neural simulations. Proc. IEEE 2014, 102, 699–716. [Google Scholar] [CrossRef]
- Saxena, V.; Wu, X.; Zhu, K. Energy-Efficient CMOS Memristive Synapses for Mixed-Signal Neuromorphic System-on-a-Chip. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Pfeil, T.; Potjans, T.C.; Schrader, S.; Potjans, W.; Schemmel, J.; Diesmann, M.; Meier, K. Is a 4-bit synaptic weight resolution enough?-constraints on enabling spike-timing dependent plasticity in neuromorphic hardware. arXiv, 2012; arXiv:1201.6255. [Google Scholar]
- Neftci, E.; Das, S.; Pedroni, B.; Kreutz-Delgado, K.; Cauwenberghs, G. Event-driven contrastive divergence for spiking neuromorphic systems. Front. Neurosci. 2013, 7, 272. [Google Scholar] [CrossRef] [PubMed]
- Pfeil, T.; Grübl, A.; Jeltsch, S.; Müller, E.; Müller, P.; Petrovici, M.A.; Schmuker, M.; Brüderle, D.; Schemmel, J.; Meier, K. Six networks on a universal neuromorphic computing substrate. Front. Neurosci. 2013, 7, 11. [Google Scholar] [CrossRef] [PubMed]
- Schemmel, J.; Briiderle, D.; Griibl, A.; Hock, M.; Meier, K.; Millner, S. A wafer-scale neuromorphic hardware system for large-scale neural modeling. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; pp. 1947–1950. [Google Scholar]
- Brink, S.; Nease, S.; Hasler, P. Computing with networks of spiking neurons on a biophysically motivated floating-gate based neuromorphic integrated circuit. Neural Netw. 2013, 45, 39–49. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Young, S.; Arel, I.; Holleman, J. A 1 TOPS/W analog deep machine-learning engine with floating-gate storage in 0.13 μm CMOS. IEEE J. Solid-State Circuits 2015, 50, 270–281. [Google Scholar] [CrossRef]
- Kim, S.; Ishii, M.; Lewis, S.; Perri, T.; BrightSky, M.; Kim, W.; Jordan, R.; Burr, G.; Sosa, N.; Ray, A.; et al. NVM neuromorphic core with 64k-cell (256-by-256) phase change memory synaptic array with on-chip neuron circuits for continuous in situ learning. In Proceedings of the 2015 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 7–9 December 2015. [Google Scholar]
- TN-12-30: NOR Flash Cycling Endurance and Data Retention; Technical Report; Micron Technology Inc.: Boise, ID, USA, 2013.
- Demler, M. Mythic Multiplies in a Flash: Analog In-Memory Computing Eliminates DRAM Read/Write Cycles; Technical Report; Microprocessor Report: Redwood City, CA, USA, 2018. [Google Scholar]
- Burr, G.W.; Shelby, R.M.; Sidler, S.; Di Nolfo, C.; Jang, J.; Boybat, I.; Shenoy, R.S.; Narayanan, P.; Virwani, K.; Giacometti, E.U.; et al. Experimental demonstration and tolerancing of a large-scale neural network (165,000 synapses) using phase-change memory as the synaptic weight element. IEEE Trans. Electron Devices 2015, 62, 3498–3507. [Google Scholar] [CrossRef]
- Burr, G.W.; Brightsky, M.J.; Sebastian, A.; Cheng, H.Y.; Wu, J.Y.; Kim, S.; Sosa, N.E.; Papandreou, N.; Lung, H.L.; Pozidis, H.; et al. Recent progress in phase-change memory technology. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 146–162. [Google Scholar] [CrossRef]
- Zhou, Y.; Ramanathan, S. Mott memory and neuromorphic devices. Proc. IEEE 2015, 103, 1289–1310. [Google Scholar] [CrossRef]
- Waser, R.; Ielmini, D.; Akinaga, H.; Shima, H.; Wong, H.S.P.; Yang, J.J.; Yu, S. Introduction to nanoionic elements for information technology. In Resistive Switching: From Fundamentals of Nanoionic Redox Processes to Memristive Device Applications; Wiley: Hoboken, NJ, USA, 2016; pp. 1–30. [Google Scholar]
- Jo, S.H.; Chang, T.; Ebong, I.; Bhadviya, B.B.; Mazumder, P.; Lu, W. Nanoscale memristor device as synapse in neuromorphic systems. Nano Lett. 2010, 10, 1297–1301. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhong, Y.; Xu, L.; Zhang, J.; Xu, X.; Sun, H.; Miao, X. Ultrafast Synaptic Events in a Chalcogenide Memristor. Sci. Rep. 2013, 3, 1619. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.J.; Strukov, D.B.; Stewart, D.R. Memristive devices for computing. Nat. Nanotechnol. 2013, 8, 13–24. [Google Scholar] [CrossRef] [PubMed]
- Chang, T.; Yang, Y.; Lu, W. Building neuromorphic circuits with memristive devices. IEEE Circuits Syst. Mag. 2013, 13, 56–73. [Google Scholar] [CrossRef]
- Yu, S.; Kuzum, D.; Wong, H.S.P. Design considerations of synaptic device for neuromorphic computing. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 1062–1065. [Google Scholar]
- Indiveri, G.; Legenstein, R.; Deligeorgis, G.; Prodromakis, T. Integration of Nanoscale Memristor Synapses in Neuromorphic Computing Architectures. Nanotechnology 2013, 24, 384010. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Saxena, V.; Zhu, K. Homogeneous Spiking Neuromorphic System for Real-World Pattern Recognition. IEEE J. Emerg. Sel. Top. Circuits Syst. 2015, 5, 254–266. [Google Scholar] [CrossRef]
- Shi, J.; Ha, S.D.; Zhou, Y.; Schoofs, F.; Ramanathan, S. A correlated nickelate synaptic transistor. Nat. Commun. 2013, 4, 2676. [Google Scholar] [CrossRef] [PubMed]
- Fuller, E.J.; Gabaly, F.E.; Léonard, F.; Agarwal, S.; Plimpton, S.J.; Jacobs-Gedrim, R.B.; James, C.D.; Marinella, M.J.; Talin, A.A. Li-ion synaptic transistor for low power analog computing. Adv. Mater. 2016, 29, 1604310. [Google Scholar] [CrossRef] [PubMed]
- Saxena, V. Memory Controlled Circuit System and Apparatus. US Patent Application No. 14/538,600, 1 October 2015. [Google Scholar]
- Saxena, V. A Compact CMOS Memristor Emulator Circuit and its Applications. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Windsor, ON, Canada, 5–8 August 2018; pp. 1–5. [Google Scholar]
- Govoreanu, B.; Kar, G.; Chen, Y.; Paraschiv, V.; Kubicek, S.; Fantini, A.; Radu, I.; Goux, L.; Clima, S.; Degraeve, R.; et al. 10× 10 nm 2 Hf/HfO x crossbar resistive RAM with excellent performance, reliability and low-energy operation. In Proceedings of the 2011 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 5–7 December 2011; pp. 31–36. [Google Scholar]
- Chen, Y.Y.; Degraeve, R.; Clima, S.; Govoreanu, B.; Goux, L.; Fantini, A.; Kar, G.S.; Pourtois, G.; Groeseneken, G.; Wouters, D.J.; et al. Understanding of the endurance failure in scaled HfO 2-based 1T1R RRAM through vacancy mobility degradation. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 10–13 December 2012; pp. 20–23. [Google Scholar]
- Kozicki, M.N.; Mitkova, M.; Valov, I. Electrochemical Metallization Memories. In Resistive Switching; Wiley-Blackwell: Hoboken, NJ, USA, 2016; pp. 483–514. [Google Scholar]
- Fong, X.; Kim, Y.; Venkatesan, R.; Choday, S.H.; Raghunathan, A.; Roy, K. Spin-transfer torque memories: Devices, circuits, and systems. Proc. IEEE 2016, 104, 1449–1488. [Google Scholar] [CrossRef]
- Micron. 3D XPointTM Technology: Breakthrough Nonvolatile Memory Technology. Available online: http://www.webcitation.org/72pvm4wn3 (accessed on 30 September 2018).
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The Missing Memristor Found. Nature 2008, 453, 80. [Google Scholar] [CrossRef] [PubMed]
- Saxena, V.; Wu, X.; Srivastava, I.; Zhu, K. Towards spiking neuromorphic system-on-a-chip with bio-plausible synapses using emerging devices. In Proceedings of the 4th ACM International Conference on Nanoscale Computing and Communication, Washington, DC, USA, 27–29 September 2017; p. 18. [Google Scholar]
- Kuzum, D.; Jeyasingh, R.G.; Lee, B.; Wong, H.S.P. Nanoelectronic programmable synapses based on phase change materials for brain-inspired computing. Nano Lett. 2011, 12, 2179–2186. [Google Scholar] [CrossRef] [PubMed]
- Seo, K.; Kim, I.; Jung, S.; Jo, M.; Park, S.; Park, J.; Shin, J.; Biju, K.P.; Kong, J.; Lee, K.; et al. Analog memory and spike-timing-dependent plasticity characteristics of a nanoscale titanium oxide bilayer resistive switching device. Nanotechnology 2011, 22, 254023. [Google Scholar] [CrossRef] [PubMed]
- Koch, C. Computation and the single neuron. Nature 1997, 385, 207. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Saxena, V.; Zhu, K.; Balagopal, S. A CMOS Spiking Neuron for Brain-Inspired Neural Networks With Resistive Synapses and In Situ Learning. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 1088–1092. [Google Scholar] [CrossRef]
- Wu, X.; Saxena, V.; Zhu, K. A CMOS Spiking Neuron For Dense Memristor-synapse Connectivity For Brain-inspired Computing. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–6. [Google Scholar]
- Serrano-Gotarredona, T.; Prodromakis, T.; Linares-Barranco, B. A proposal for hybrid memristor-CMOS spiking neuromorphic learning systems. IEEE Circuits Syst. Mag. 2013, 13, 74–88. [Google Scholar] [CrossRef]
- Serrano-Gotarredona, T.; Masquelier, T.; Prodromakis, T.; Indiveri, G.; Linares-Barranco, B. STDP and STDP variations with memristors for spiking neuromorphic learning systems. Front. Neurosci. 2013, 7, 2. [Google Scholar] [CrossRef] [PubMed]
- Indiveri, G.; Linares-Barranco, B.; Hamilton, T.J.; Van Schaik, A.; Etienne-Cummings, R.; Delbruck, T.; Liu, S.C.; Dudek, P.; Häfliger, P.; Renaud, S.; et al. Neuromorphic silicon neuron circuits. Front. Neurosci. 2011, 5, 73. [Google Scholar] [CrossRef] [PubMed]
- Joubert, A.; Belhadj, B.; Héliot, R. A robust and compact 65 nm LIF analog neuron for computational purposes. In Proceedings of the 2011 IEEE 9th International New Circuits and Systems Conference (NEWCAS), Bordeaux, France, 26–29 June 2011; pp. 9–12. [Google Scholar]
- Wang, R.; Hamilton, T.J.; Tapson, J.; van Schaik, A. A generalised conductance-based silicon neuron for large-scale spiking neural networks. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 1564–1567. [Google Scholar]
- Cruz-Albrecht, J.M.; Yung, M.W.; Srinivasa, N. Energy-efficient neuron, synapse and STDP integrated circuits. IEEE Trans. Biomed. Circuits Syst. 2012, 6, 246–256. [Google Scholar] [CrossRef] [PubMed]
- Sahoo, B.D. Ring oscillator based sub-1V leaky integrate-and-fire neuron circuit. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Ebong, I.E.; Mazumder, P. CMOS and Memristor-Based Neural Network Design for Position Detection. Proc. IEEE 2012, 100, 2050–2060. [Google Scholar] [CrossRef]
- Serrano-Gotarredona, T.; Linares-Barranco, B. Design of adaptive nano/CMOS neural architectures. In Proceedings of the 2012 19th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Seville, Spain, 9–12 December 2012; pp. 949–952. [Google Scholar]
- Latif, M.R. Nano-Ionic Redox Resistive RAM–Device Performance Enhancement through Materials Engineering, Characterization and Electrical Testing. Ph.D. Thesis, Boise State University, Boise, ID, USA, 2014. [Google Scholar]
- Latif, M.; Csarnovics, I.; Kökényesi, S.; Csik, A.; Mitkova, M. Photolithography-free Ge–Se based memristive arrays; materials characterization and device testing 1. Can. J. Phys. 2013, 92, 623–628. [Google Scholar] [CrossRef]
- Latif, M.R.; Mitkova, M.; Tompa, G.; Coleman, E. PECVD of GexSe1−x films for nano-ionic redox conductive bridge memristive switch memory. In Proceedings of the 2013 IEEE Workshop on Microelectronics and Electron Devices (WMED), Boise, ID, USA, 12 April 2013; pp. 1–4. [Google Scholar]
- Masquelier, T.; Guyonneau, R.; Thorpe, S.J. Spike Timing Dependent Plasticity Finds the Start of Repeating Patterns in Continuous Spike Trains. PLoS ONE 2008, 3, e1377. [Google Scholar] [CrossRef] [PubMed]
- Diehl, P.U.; Cook, M. Unsupervised Learning of Digit Recognition Using Spike-timing-dependent Plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the International Joint Conference onNeural Networks (IJCNN), Budapest, Hungary, 14–19 July 2015; pp. 1–8. [Google Scholar]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR), Edinburgh, UK, 6 August 2003; p. 958. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1058–1066. [Google Scholar]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training deep spiking neural networks using backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef] [PubMed]
- Neftci, E.O.; Augustine, C.; Paul, S.; Detorakis, G. Event-driven random back-propagation: Enabling neuromorphic deep learning machines. Front. Neurosci. 2017, 11, 324. [Google Scholar] [CrossRef] [PubMed]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Thorpe, S.J.; Masquelier, T. STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 2018, 99, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Tavanaei, A.; Maida, A.S. Bio-Inspired Spiking Convolutional Neural Network using Layer-wise Sparse Coding and STDP Learning. arXiv, 2016; arXiv:1611.03000. [Google Scholar]
- Saxena, V. Tutorial—Neuromorphic Computing: Algorithms, Devices and Circuits. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Windsor, ON, Canada, 5–8 August 2018. [Google Scholar]
- Nielsen, M. Neural Networks and Deep Learning, 1st ed.; 2017; Available online: http://neuralnetworksanddeeplearning.com (accessed on 30 September 2018).
- Lillicrap, T.P.; Cownden, D.; Tweed, D.B.; Akerman, C.J. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 2016, 7, 13276. [Google Scholar] [CrossRef] [PubMed]
- Maass, W. Searching for principles of brain computation. Curr. Opin. Behav. Sci. 2016, 11, 81–92. [Google Scholar] [CrossRef]
- He, W.; Sun, H.; Zhou, Y.; Lu, K.; Xue, K.; Miao, X. Customized binary and multi-level HfO2-x-based memristors tuned by oxidation conditions. Sci. Rep. 2017, 7, 10070. [Google Scholar] [CrossRef] [PubMed]
- Beckmann, K.; Holt, J.; Manem, H.; Van Nostrand, J.; Cady, N.C. Nanoscale Hafnium Oxide RRAM Devices Exhibit Pulse Dependent Behavior and Multi-level Resistance Capability. MRS Adv. 2016, 1, 3355–3360. [Google Scholar] [CrossRef]
- Sjostrom, J.; Gerstner, W. Spike-timing dependent plasticity. Scholarpedia 2010, 5, 1362. [Google Scholar] [CrossRef]
- Pedrosa, V.; Clopath, C. The Role of Neuromodulators in Cortical Plasticity. A Computational Perspective. Front. Synapt. Neurosci. 2016, 8, 38. [Google Scholar] [CrossRef] [PubMed]
- Poirazi, P.; Mel, B.W. Impact of active dendrites and structural plasticity on the memory capacity of neural tissue. Neuron 2001, 29, 779–796. [Google Scholar] [CrossRef]
- O’Connor, D.H.; Wittenberg, G.M.; Wang, S.S.H. Graded bidirectional synaptic plasticity is composed of switch-like unitary events. Proc. Natl. Acad. Sci. USA 2005, 102, 9679–9684. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, J.I.; Horiike, Y.; Matsuzaki, M.; Miyazaki, T.; Ellis-Davies, G.C.; Kasai, H. Protein synthesis and neurotrophin-dependent structural plasticity of single dendritic spines. Science 2008, 319, 1683–1687. [Google Scholar] [CrossRef] [PubMed]
- Rueckauer, B.; Lungu, I.A.; Hu, Y.; Pfeiffer, M.; Liu, S.C. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef] [PubMed]
- Bill, J.; Legenstein, R. A compound memristive synapse model for statistical learning through STDP in spiking neural networks. Front. Neurosci. 2014, 8, 412. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Saxena, V. Enabling Bio-Plausible Multi-level STDP using CMOS Neurons with Dendrites and Bistable RRAMs. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Wu, X.; Saxena, V. Dendritic-Inspired Processing Enables Bio-Plausible STDP in Compound Binary Synapses. arXiv, 2018; arXiv:1801.02797v1. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the 2012 Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Harris, M. New Pascal GPUs Accelerate Inference in the Data Center. 2016. Available online: http://www.webcitation.org/72pzi62Tb (accessed on 30 September 2018).
- Saxena, V.; Baker, R.J. Indirect Compensation Techniques For Three-stage Cmos Op-amps. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Cancun, Mexico, 2–5 August 2009; pp. 9–12. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 13, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Goodrich, B.; Arel, I. Unsupervised neuron selection for mitigating catastrophic forgetting in neural networks. In Proceedings of the 2014 IEEE 57th International Midwest Symposium on Circuits and Systems (MWSCAS), College Station, TX, USA, 3–6 August 2014; pp. 997–1000. [Google Scholar]
- Boahen, K. Neurogrid: Emulating A Million Neurons In The Cortex. In Proceedings of the International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006. [Google Scholar]
- Rasul, R.A.; Teimouri, P.; Chen, M.S.W. A time multiplexed network architecture for large-scale neuromorphic computing. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1216–1219. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
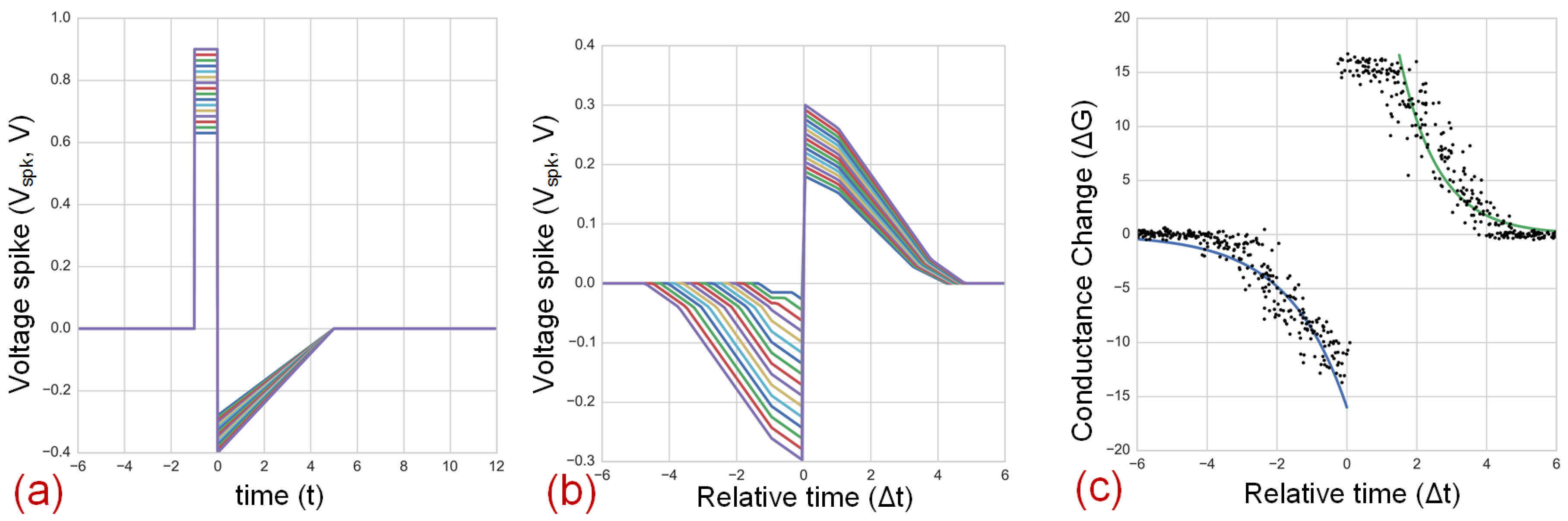{kind=link}
{kind=link}
| Low | Medium | High | ||
|---|---|---|---|---|
| Spike Width | 100 ns | |||
| Spike Amplitude | 300 mV | |||
| LRS Resistance | 100 k | 1 M | 10 M | |
| Single Spike Energy | 1.4 pJ | 140 fJ | 14 fJ | |
| Neuron Energy | 1.56 pJ | 260 fJ | 43.3 fJ | |
| Neuron Sparsity | 0.6 | |||
| Fraction of RRAMs in LRS | 0.5 | |||
| Single Event Energy | 422.6 J | 42.33 J | 4.24 J | |
| Images/sec/watt | 2.4 k | 23.6 k | 235 k | |
| Acceleration over GPU | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saxena, V.; Wu, X.; Srivastava, I.; Zhu, K. Towards Neuromorphic Learning Machines Using Emerging Memory Devices with Brain-Like Energy Efficiency. J. Low Power Electron. Appl. 2018, 8, 34. https://doi.org/10.3390/jlpea8040034
Saxena V, Wu X, Srivastava I, Zhu K. Towards Neuromorphic Learning Machines Using Emerging Memory Devices with Brain-Like Energy Efficiency. Journal of Low Power Electronics and Applications. 2018; 8(4):34. https://doi.org/10.3390/jlpea8040034
Chicago/Turabian StyleSaxena, Vishal, Xinyu Wu, Ira Srivastava, and Kehan Zhu. 2018. "Towards Neuromorphic Learning Machines Using Emerging Memory Devices with Brain-Like Energy Efficiency" Journal of Low Power Electronics and Applications 8, no. 4: 34. https://doi.org/10.3390/jlpea8040034
APA StyleSaxena, V., Wu, X., Srivastava, I., & Zhu, K. (2018). Towards Neuromorphic Learning Machines Using Emerging Memory Devices with Brain-Like Energy Efficiency. Journal of Low Power Electronics and Applications, 8(4), 34. https://doi.org/10.3390/jlpea8040034