Path Planning for Highly Automated Driving on Embedded GPUs

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction and Related Work
1.1. Motivation
1.2. Related Work
2. Methods
2.1. Programming an Embedded GPU
2.2. Overview
- Calculate start values in Frenet coordinates for the path planning algorithm in relation to the current vehicle position.
- Plan different paths with different lengthwise and crosswise variations with respect to the reference path.
- Transform from Frenet coordinates to Cartesian coordinates.
- Calculate the costs for each path and select the best path.
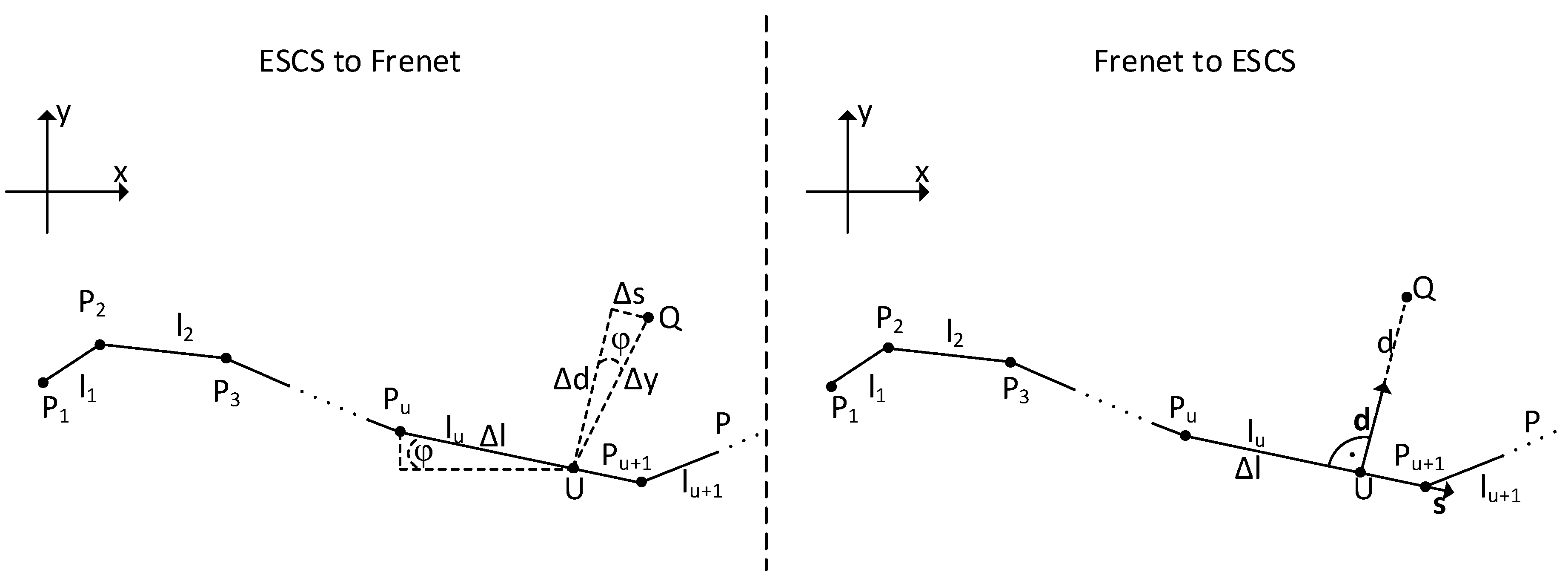
2.3. Frenet Coordinates
- is the tangent unit vector,
- is the normal unit vector,
- is the binormal unit vector,
- The change of the angle between two polygon courses can only be moderate. Otherwise, there will be jump discontinuity in the polygon course. Since our approach is proposed for highway scenarios, that is not a limitation.
- The polygon course has to be monotonically increasing along the x-axis.
- The path P is an open polygon course and is defined as .
2.4. Path Generation
2.5. Rating of Paths
- Distance to the left corridor boundary () and to the right corridor boundary ().
- A crosswise deviation related to the reference path in the endpoint of the path ().
- Maximum lateral acceleration () of the vehicle along the planned path.
3. Experiments
3.1. Evaluation Environment
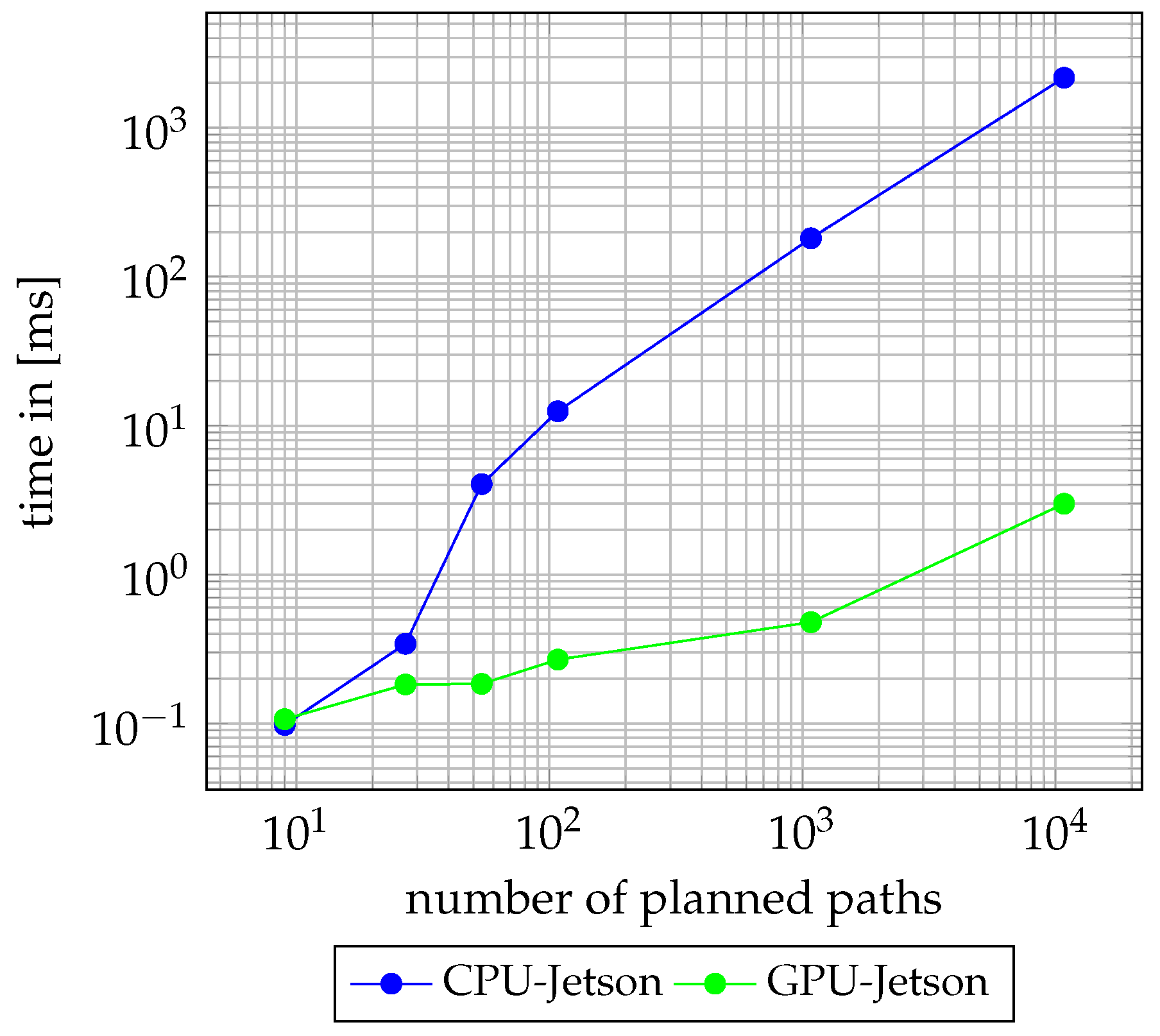
3.2. Evaluation of the Coordinate Transformation from Frenet Coordinates to Cartesian Coordinates
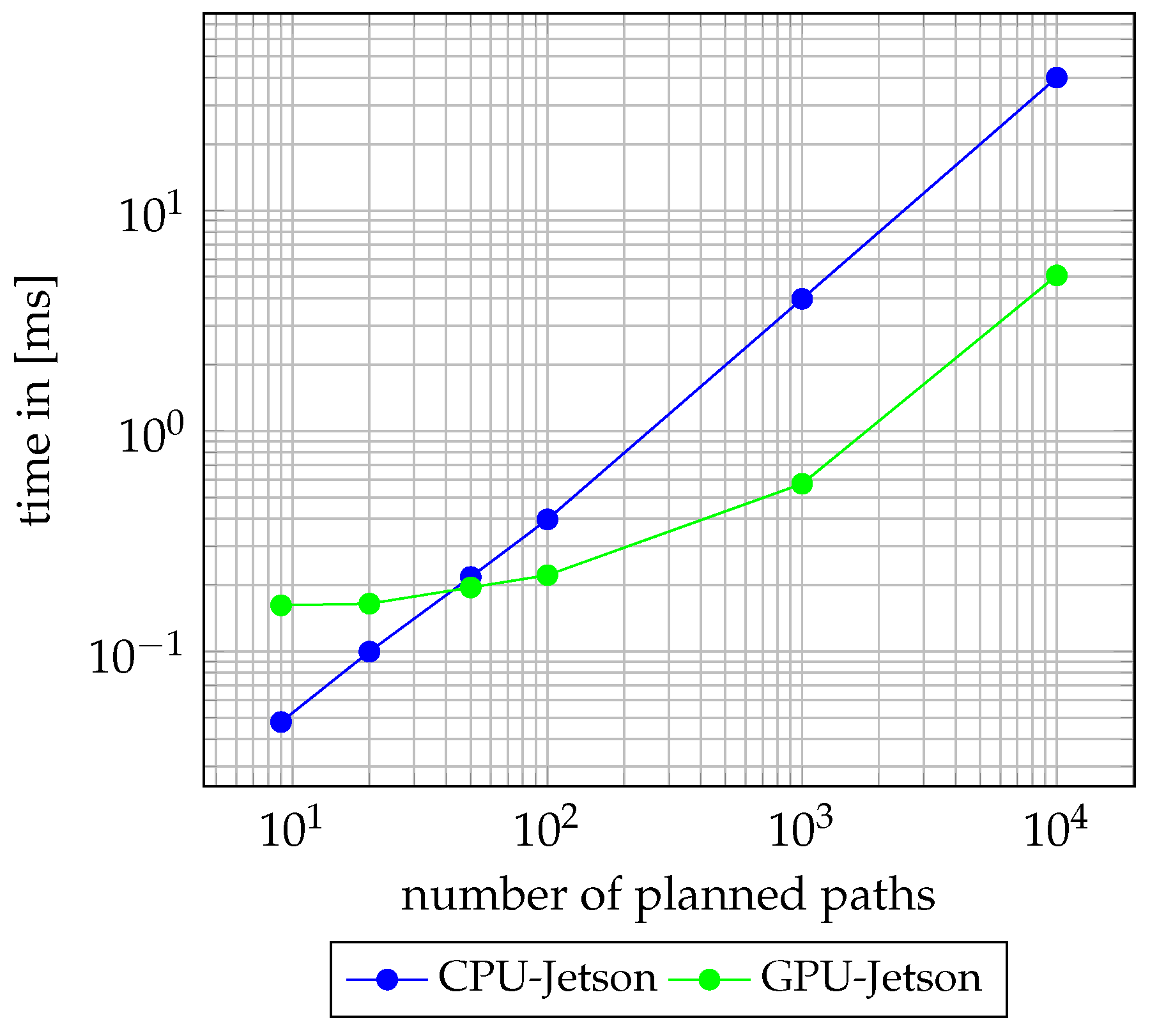
3.3. Evaluation of Lengthwise and Crosswise Path Planning
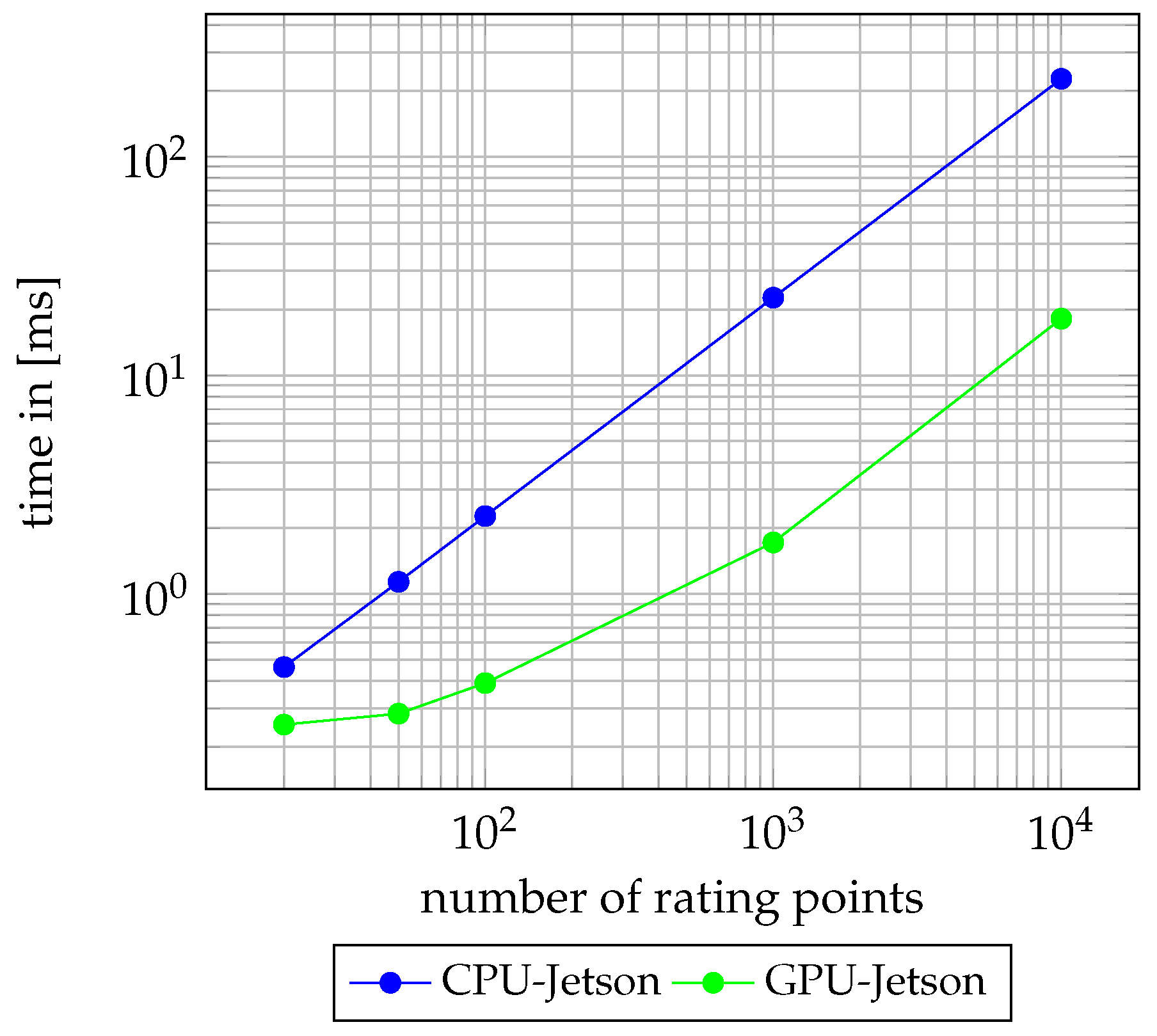
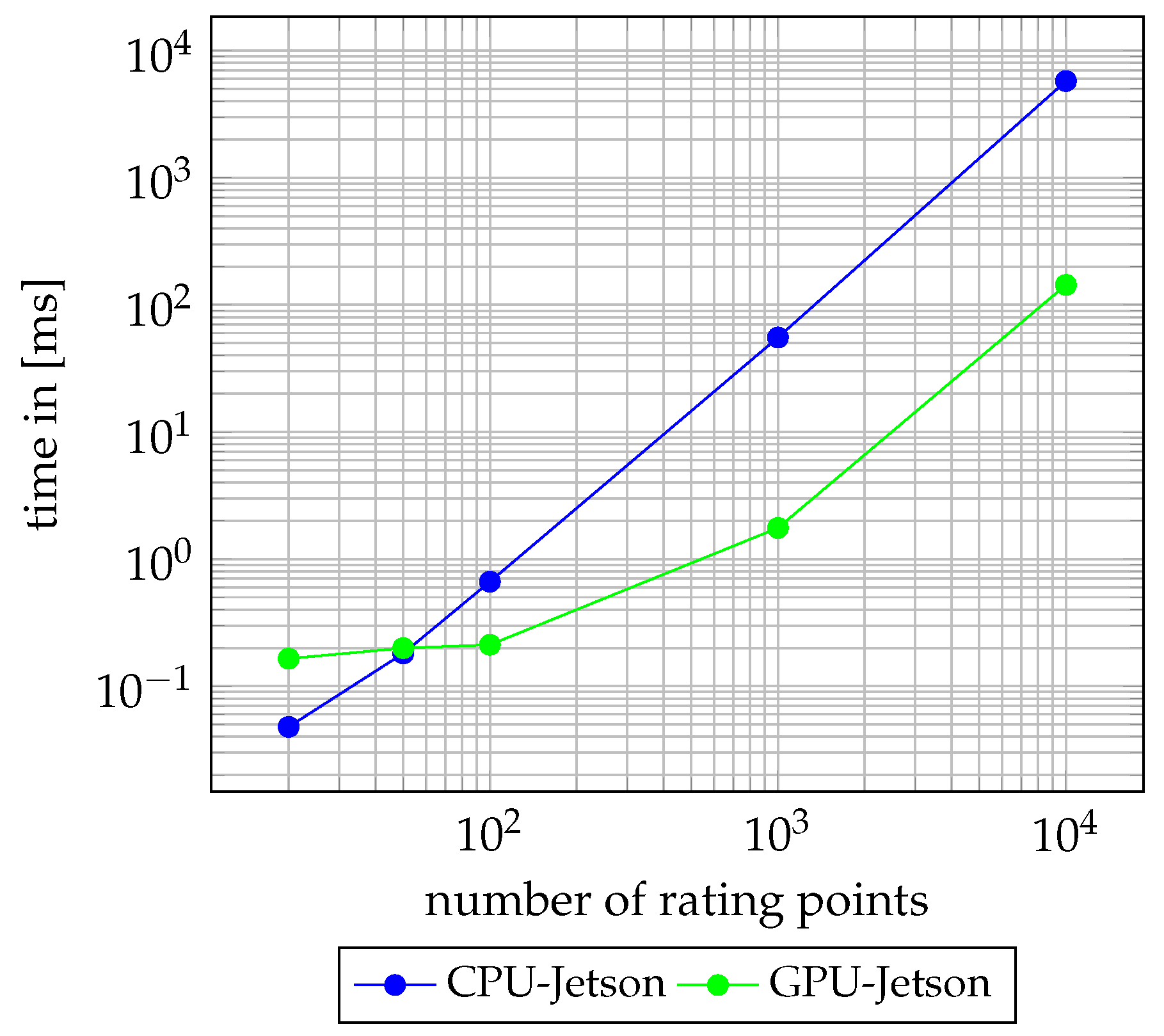
3.4. Evaluation of the Path Rating
4. Conclusion and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver Assistance System |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
| ECU | Electronic Control Unit |
| SIMT | Single Instruction Multiple Thread |
| SLAM | Simultaneous Localization and Mapping |
| FMA | Fused Multiply Add |
| ROI | Region of Interest |
| OVM | Own Vehicle Motion |
| ESCS | Environment Sensor Coordinate System |
| SoC | System-on-Chip |
| GPGPU | General Purpose Computation on Graphics Processing Unit |
| MIMD | Multiple Instruction, Multiple Data |
References
- Taxonomy and Definitions for Terms Related to On-Road Motor Vehicle Automated Driving Systems. Available online: https://www.sae.org/standards/content/j3016_201401/ (accessed on 26 September 2018).
- Latombe, J.C. Robot Motion Planning; Kluwer Academic Publishers: Norwell, MA, USA, 1991. [Google Scholar]
- Choset, H.; Lynch, K.M.; Hutchinson, S.; Kantor, G.A.; Burgard, W.; Kavraki, L.E.; Thrun, S. Principles of Robot Motion: Theory, Algorithms, and Implementations; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- McNaughton, M.; Urmson, C.; Dolan, J.M.; Lee, J. Motion planning for autonomous driving with a conformal spatiotemporal lattice. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 4889–4895. [Google Scholar] [CrossRef]
- Werling, M. Ein neues Konzept für die Trajektoriengenerierung und -stabilisierung in zeitkritischen Verkehrsszenarien. Ph.D. Thesis, Karlsruher Institut für Technology (KIT), Karlsruhe, Baden-Württemberg, Germany, 2011. [Google Scholar]
- Fassbender, D.; Müller, A.; Wuensche, H. Trajectory planning for car-like robots in unknown, unstructured environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014; pp. 3630–3635. [Google Scholar] [CrossRef]
- Ferguson, D.; Howard, T.M.; Likhachev, M. Motion planning in urban environments. J. Field Robot. 2008, 25, 939–960. [Google Scholar] [CrossRef]
- Ziegler, J.; Stiller, C. Spatiotemporal state lattices for fast trajectory planning in dynamic on-road driving scenarios. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 1879–1884. [Google Scholar] [CrossRef]
- Ziegler, J.; Bender, P.; Dang, T.; Stiller, C. Trajectory planning for Bertha—A local, continuous method. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 450–457. [Google Scholar] [CrossRef]
- Choi, J.W.; Curry, R.; Hugh Elkaim, G. Continuous Curvature Path Generation Based on Bezier Curves for Autonomous Vehicles. Int. J. Appl. Math. 2010, 40, 91–101. [Google Scholar]
- Ziegler, J.; Bender, P.; Schreiber, M.; Lategahn, H.; Strauss, T.; Stiller, C.; Dang, T.; Franke, U.; Appenrodt, N.; Keller, C.G.; et al. Making Bertha Drive—An Autonomous Journey on a Historic Route. IEEE Intell. Transp. Syst. Mag. 2014, 6, 8–20. [Google Scholar] [CrossRef]
- Gotte, C.; Keller, M.; Hass, C.; Glander, K.H.; Seewald, A.; Bertram, T. A model predictive combined planning and control approach for guidance of automated vehicles. In Proceedings of the 2015 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Yokohama, Japan, 5–7 November 2015; pp. 69–74. [Google Scholar] [CrossRef]
- Anderson, S.J.; Karumanchi, S.B.; Iagnemma, K. Constraint-based planning and control for safe, semi-autonomous operation of vehicles. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 383–388. [Google Scholar] [CrossRef]
- Dafflon, B.; Gechter, F.; Gruer, P.; Koukam, A. Vehicle platoon and obstacle avoidance: A reactive agent approach. IET Intell. Transp. Syst. 2013, 7, 257–264. [Google Scholar] [CrossRef]
- Von Hundelshausen, F.; Himmelsbach, M.; Hecker, F.; Mueller, A.; Wuensche, H.J. Driving with Tentacles: Integral Structures for Sensing and Motion. J. Field Robot. 2008, 25, 640–673. [Google Scholar] [CrossRef]
- Heil, T.; Lange, A.; Cramer, S. Adaptive and efficient lane change path planning for automated vehicles. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 December 2016; pp. 479–484. [Google Scholar] [CrossRef]
- Burns, E.; Lemons, S.; Ruml, W.; Zhou, R. Best-first Heuristic Search for Multicore Machines. J. Artif. Intell. Res. 2010, 39, 689–743. [Google Scholar] [CrossRef]
- Bleiweiss, A. GPU Accelerated Pathfinding. In Proceedings of the 23rd ACM SIGGRAPH/EUROGRAPHICS Symposium on Graphics Hardware (GH), Sarajevo, Bosnia, 20–21 June 2008; pp. 65–74. [Google Scholar]
- Kider, J., Jr.; Henderson, M.; Likhachev, M.; Safonova, A. High-dimensional planning on the GPU. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–7 May 2010; pp. 2515–2522. [Google Scholar] [CrossRef]
- Cekmez, U.; Ozsiginan, M.; Sahingoz, O.K. A UAV path planning with parallel ACO algorithm on CUDA platform. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Orlando, FL, USA, 27–30 May 2014; pp. 347–354. [Google Scholar] [CrossRef]
- Palossi, D.; Marongiu, A.; Benini, L. On the Accuracy of Near-Optimal GPU-Based Path Planning for UAVs. In Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems (SCOPES), Sankt Goar, Germany, 12–13 June 2017; pp. 85–88. [Google Scholar] [CrossRef]
- Programming Guide—CUDA Toolkit Documentation. 2016. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/ (accessed on 25 September 2018).
- Grauer-Gray, S.; Killian, W.; Searles, R.; Cavazos, J. Accelerating Financial Applications on the GPU. In Proceedings of the 6th Workshop on General Purpose Processor Using Graphics Processing Units, Houston, TX, USA, 16 March 2013; pp. 127–136. [Google Scholar] [CrossRef]
- Bakkum, P.; Skadron, K. Accelerating SQL Database Operations on a GPU with CUDA. In Proceedings of the 3rd Workshop on General-Purpose Computation on Graphics Processing Units, Pittsburgh, PA, USA, 14 March 2010; pp. 94–103. [Google Scholar] [CrossRef]
- Werling, M.; Ziegler, J.; Kammel, S.; Thrun, S. Optimal trajectory generation for dynamic street scenarios in a Frenet Frame. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 987–993. [Google Scholar] [CrossRef]
- Serret, J.A. Sur quelques formules relatives à la théorie des courbes à double courbure. J. de Mathématiques Pures et Appliquées 1851, 16, 193–207. [Google Scholar]
- Gantmacher, F.; Brenner, J. Applications of the Theory of Matrices; Dover Publications: Mineola, NY, USA, 2005. [Google Scholar]
- NVIDIA Jetson TK1 Developer Kit. 2016. Available online: http://www.nvidia.com/object/jetson-tk1-embedded-dev-kit.html (accessed on 25 September 2018).
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. On a Formal Model of Safe and Scalable Self-driving Cars. Comput. Res. Repos. 2018, arXiv:1708.06374v5. [Google Scholar]










© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fickenscher, J.; Schmidt, S.; Hannig, F.; Bouzouraa, M.E.; Teich, J. Path Planning for Highly Automated Driving on Embedded GPUs. J. Low Power Electron. Appl. 2018, 8, 35. https://doi.org/10.3390/jlpea8040035
Fickenscher J, Schmidt S, Hannig F, Bouzouraa ME, Teich J. Path Planning for Highly Automated Driving on Embedded GPUs. Journal of Low Power Electronics and Applications. 2018; 8(4):35. https://doi.org/10.3390/jlpea8040035
Chicago/Turabian StyleFickenscher, Jörg, Sandra Schmidt, Frank Hannig, Mohamed Essayed Bouzouraa, and Jürgen Teich. 2018. "Path Planning for Highly Automated Driving on Embedded GPUs" Journal of Low Power Electronics and Applications 8, no. 4: 35. https://doi.org/10.3390/jlpea8040035
APA StyleFickenscher, J., Schmidt, S., Hannig, F., Bouzouraa, M. E., & Teich, J. (2018). Path Planning for Highly Automated Driving on Embedded GPUs. Journal of Low Power Electronics and Applications, 8(4), 35. https://doi.org/10.3390/jlpea8040035