Performance and Power Analysis of HPC Workloads on Heterogeneous Multi-Node Clusters †


Abstract
1. Introduction and Related Works
2. Problem Analysis
3. Proposed Methodology
- The High-end HPC cluster comprises 5 computing nodes, where every node embeds Intel Xeon E5-2630v3 CPUs and NVIDIA K80 dual-GPU boards, thus accounting for 16 CUDA devices per node. Each CUDA device is a GK210 GPUs (Kepler architecture), with 2496 cores. The nodes are interconnected with 56Gb/s FDR InfiniBand links and each node hosts Mellanox MT27500 Family [ConnectX-3] HCA. This cluster is named Computing On Kepler Architecture (COKA) and it is managed by INFN & University of Ferrara (Italy), providing a peak performance of ∼100 TFLOPs.
- The Embedded cluster comprises 15 nodes, each of them housing a NVIDIA Tegra X1 (http://www.nvidia.com/object/embedded-systems-dev-kits-modules.html) SoC, embedding a Quad Arm Cortex-A57, with 2 MB of L2 cache and 4 GB LPDDR4 (with a peak bandwidth of 25.6 GB/s). supported by a 16 GB eMMC storage device and accelerated with an embedded NVIDIA GPU (Maxwell architecture), with 256 CUDA cores. Node interconnection is performed using a single Gigabit Ethernet link per node. The cluster is installed at the Barcelona Supercomputing Center (Spain) and we refer to it as Jetson cluster in the rest of the text.
3.1. Lattice Boltzmann
4. Application Analysis with Extrae and Paraver
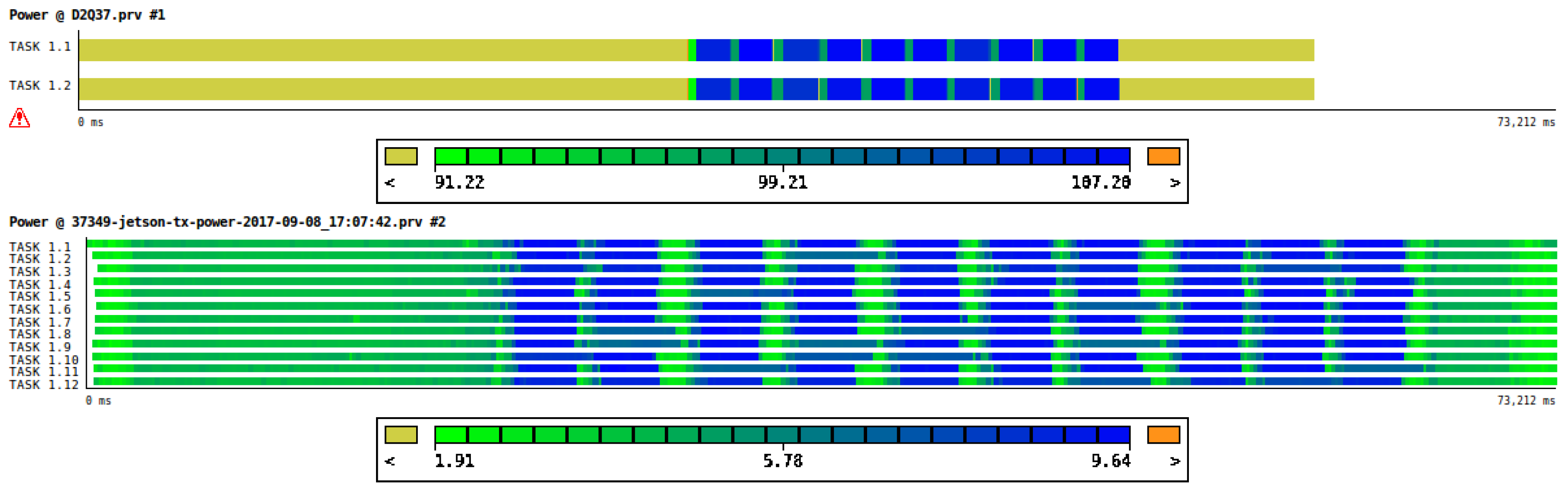
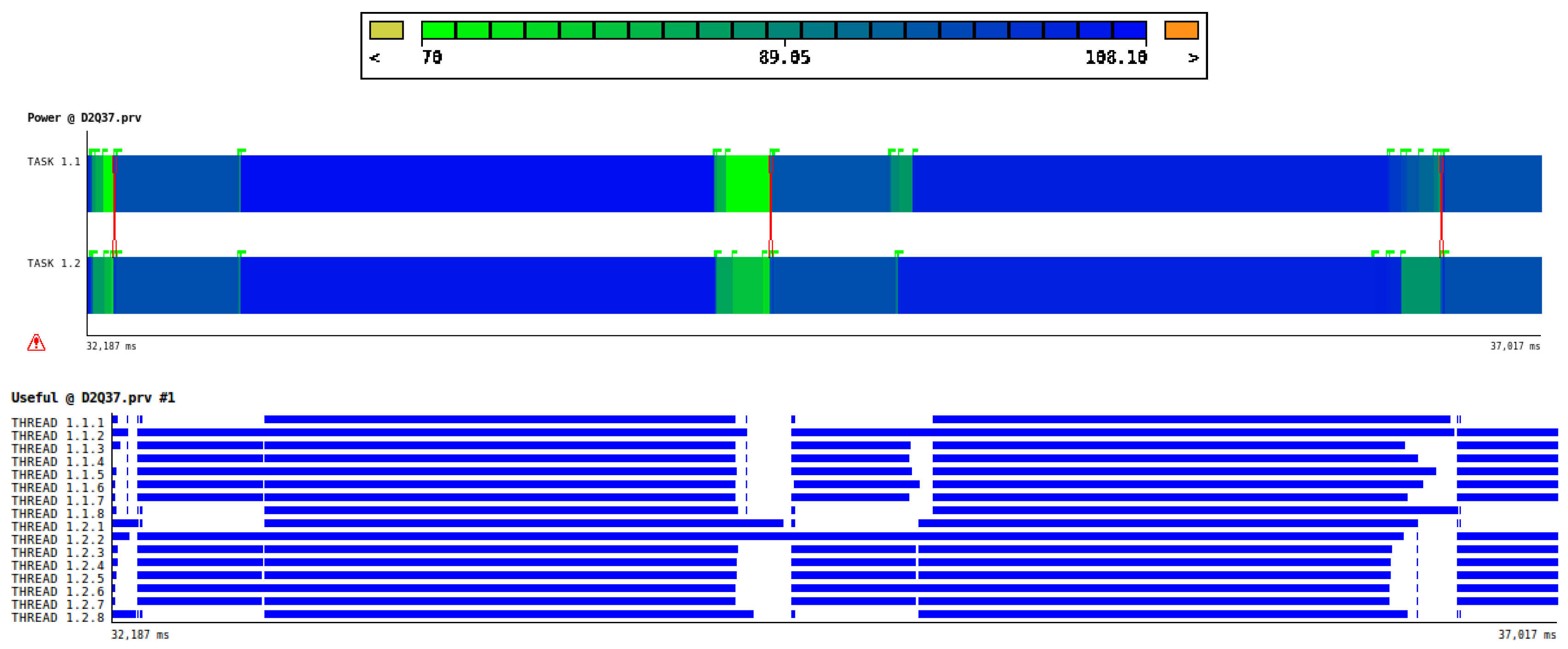
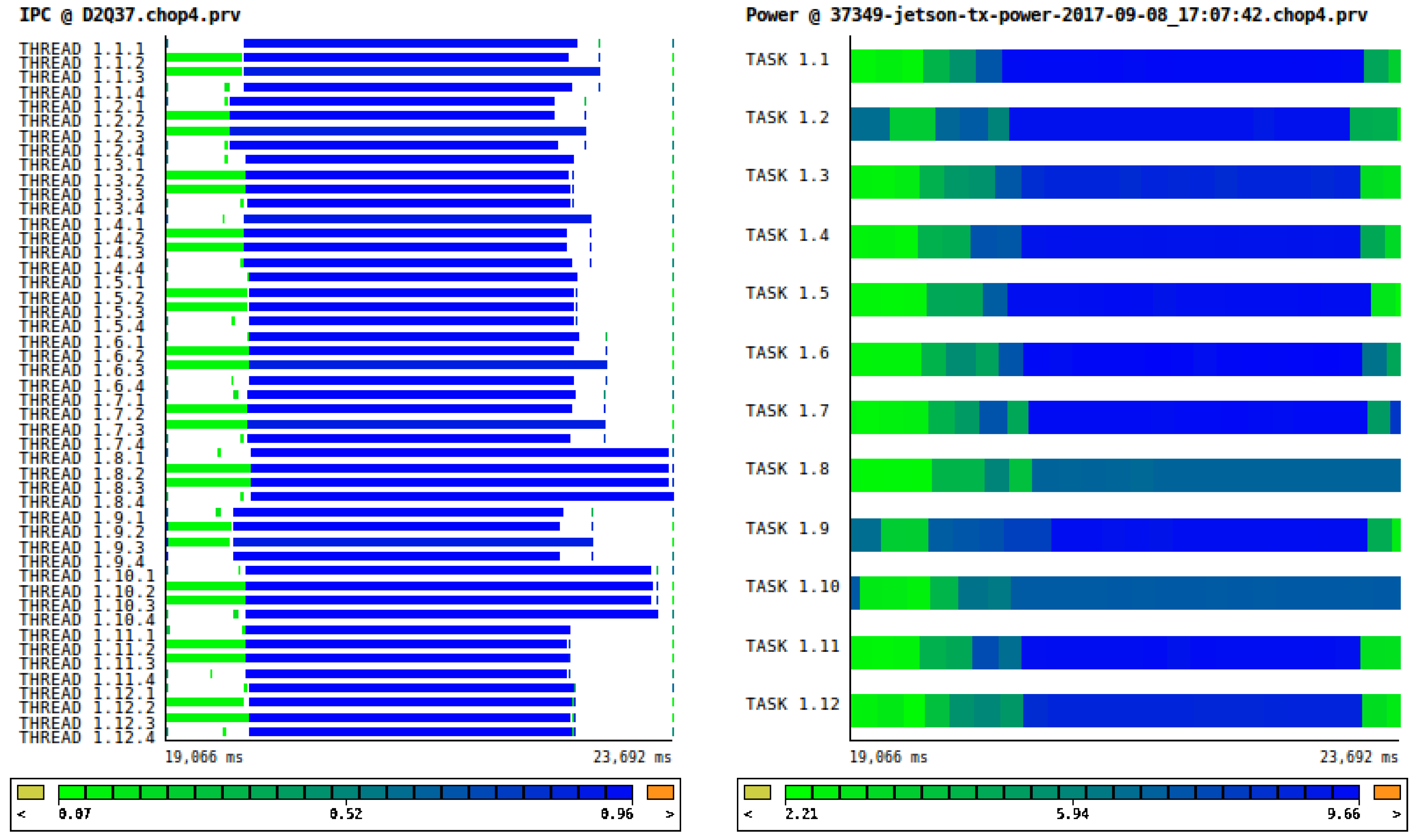
4.1. Metrics Visualization and Analysis with Paraver
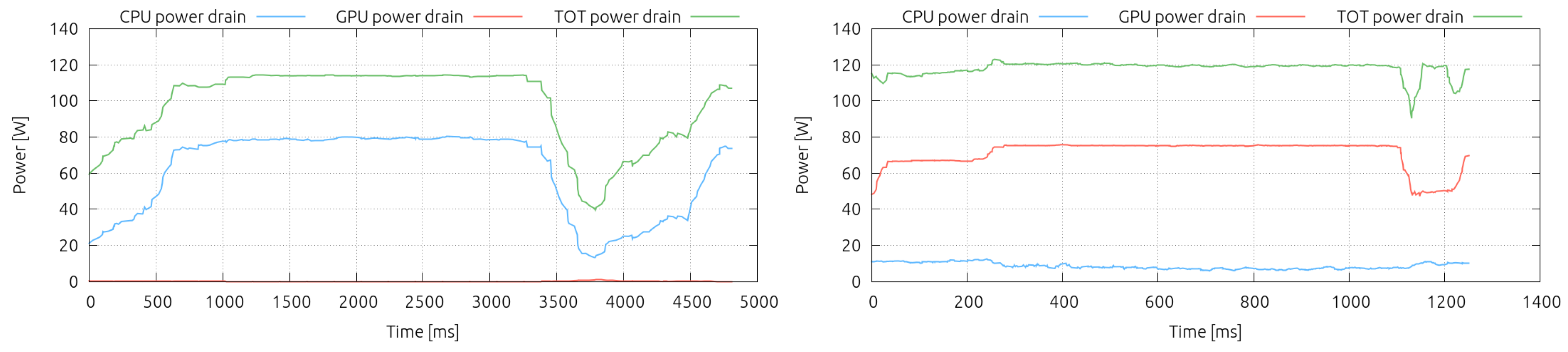
4.2. Performance and Power Comparisons
- the MPI+OpenMP+Intrinsics implementation for CPUs—12 Jetson nodes are equivalent to one COKA node from the Energy to solution point of view, although the former are less power hungry, while the latter is faster. This highlights the fact that a trade-off could be found between “low-powerness” and performance, without impacting the overall energy to be spent, selecting one architecture or the other.
- the MPI+CUDA implementation on GPUs—one NVIDA K80 board of the COKA cluster is faster than the 12 GPUs of the Jetson cluster, but also more power hungry. Furthermore, concerning the energy-efficiency, in order to reach the same result, the Jetson cluster uses more energy than a single K80 board of the COKA cluster. This difference can be justified by the architecture of the GPU housed in the Jetson SoC. Even if it is similar to the K80 (Kepler), the Maxwell architecture favors single and half precision floating point performance, delivering less performance in the presence of double precision workload, as for the case of our LB application [41]. Moreover, using 12 hundreds-of-cores GPUs, instead of a single K80 board (hosting 2 thousands-of-cores GPUs), requires more and slower communications, which, although overlapped with computations, represents an overhead.
4.3. Limitations
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Feng, W.; Cameron, K. The green500 list: Encouraging sustainable supercomputing. Computer 2007, 40. [Google Scholar] [CrossRef]
- Lucas, R.; Ang, J.; Bergman, K.; Borkar, S.; Carlson, W.; Carrington, L.; Chiu, G.; Colwell, R.; Dally, W.; Dongarra, J.; et al. Top Ten Exascale Research Challenges; DOE ASCAC Subcommittee Report; 2014; pp. 1–86. Available online: https://science.energy.gov/~/media/ascr/ascac/pdf/meetings/20140210/Top10reportFEB14.pdf (accessed on 4 May 2018).
- Benedict, S. Energy-aware performance analysis methodologies for HPC architectures—An exploratory study. J. Netw. Comput. Appl. 2012, 35, 1709–1719. [Google Scholar] [CrossRef]
- Pillet, V.; Labarta, J.; Cortes, T.; Girona, S. Paraver: A tool to visualize and analyze parallel code. In Proceedings of the 187th World Occam and Transputer User Group Technical Meeting, Transputer and Occam Developments, WoTUG-18, Manchester, UK, 9–13 April 1995; Volume 44, pp. 17–31. [Google Scholar]
- Alonso, P.; Badia, R.M.; Labarta, J.; Barreda, M.; Dolz, M.F.; Mayo, R.; Quintana-Ortí, E.S.; Reyes, R. Tools for Power-Energy Modelling and Analysis of Parallel Scientific Applications. In Proceedings of the 2012 41st International Conference on Parallel Processing (ICPP), Pittsburgh, PA, USA, 10–13 September 2012; pp. 420–429. [Google Scholar]
- Servat, H.; Llort, G.; Giménez, J.; Labarta, J. Detailed and simultaneous power and performance analysis. Concurr. Comput. Pract. Exp. 2016, 28, 252–273. [Google Scholar] [CrossRef]
- Dongarra, J.; London, K.; Moore, S.; Mucci, P.; Terpstra, D. Using PAPI for hardware performance monitoring on Linux systems. In Proceedings of the Conference on Linux Clusters: The HPC Revolution, Linux Clusters Institute, Urbana, IL, USA, 26–27 June 2001; Volume 5. [Google Scholar]
- Schöne, R.; Tschüter, R.; Ilsche, T.; Schuchart, J.; Hackenberg, D.; Nagel, W.E. Extending the functionality of score-P through plugins: Interfaces and use cases. In Tools for High Performance Computing 2016; Springer: Berlin, Germany, 2017; pp. 59–82. [Google Scholar]
- Hackenberg, D.; Ilsche, T.; Schuchart, J.; Schöne, R.; Nagel, W.E.; Simon, M.; Georgiou, Y. HDEEM: High definition energy efficiency monitoring. In Proceedings of the 2nd International Workshop on Energy Efficient Supercomputing, New Orleans, LA, USA, 16 November 2014; pp. 1–10. [Google Scholar]
- Ilsche, T.; Schöne, R.; Schuchart, J.; Hackenberg, D.; Simon, M.; Georgiou, Y.; Nagel, W.E. Power measurement techniques for energy-efficient computing: reconciling scalability, resolution, and accuracy. Comput. Sci. Res. Dev. 2017, 1–8. [Google Scholar] [CrossRef]
- Schuchart, J.; Gerndt, M.; Kjeldsberg, P.G.; Lysaght, M.; Horák, D.; Říha, L.; Gocht, A.; Sourouri, M.; Kumaraswamy, M.; Chowdhury, A.; et al. The READEX formalism for automatic tuning for energy efficiency. Computing 2017, 99, 727–745. [Google Scholar] [CrossRef]
- Bekas, C.; Curioni, A. A new energy aware performance metric. Computer Comput. Sci. Res. Dev. 2010, 25, 187–195. [Google Scholar] [CrossRef]
- Scogland, T.R.; Steffen, C.P.; Wilde, T.; Parent, F.; Coghlan, S.; Bates, N.; Feng, W.c.; Strohmaier, E. A power-measurement methodology for large-scale, high-performance computing. In Proceedings of the 5th ACM/SPEC International Conference On Performance Engineering, Dublin, Ireland, 22–26 March 2014; pp. 149–159. [Google Scholar]
- Rajagopal, D.; Tafani, D.; Georgiou, Y.; Glesser, D.; Ott, M. A Novel Approach for Job Scheduling Optimizations under Power Cap for ARM and Intel HPC Systems. In Proceedings of the 24th IEEE International Conference on High Performance Computing, Data, and Analytics (HiPC 2017), Jaipur, India, 18–21 December 2017. [Google Scholar]
- Ahmad, W.A.; Bartolini, A.; Beneventi, F.; Benini, L.; Borghesi, A.; Cicala, M.; Forestieri, P.; Gianfreda, C.; Gregori, D.; Libri, A.; et al. Design of an Energy Aware Petaflops Class High Performance Cluster Based on Power Architecture. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lake Buena Vista, FL, USA, 29 May–2 June 2017; pp. 964–973. [Google Scholar]
- Rajovic, N.; Carpenter, P.; Gelado, I.; Puzovic, N.; Ramirez, A.; Valero, M. Supercomputing with commodity CPUs: Are mobile SoCs ready for HPC? In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Denver, Colorado, 17–21 November 2013; pp. 1–12. [Google Scholar]
- Rajovic, N.; Rico, A.; Mantovani, F.; Ruiz, D.; Vilarrubi, J.O.; Gomez, C.; Backes, L.; Nieto, D.; Servat, H.; Martorell, X.; et al. The Mont-blanc Prototype: An Alternative Approach for HPC Systems. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 13–18 November 2016; IEEE Press: Piscataway, NJ, USA, 2016. [Google Scholar]
- Cesini, D.; Corni, E.; Falabella, A.; Ferraro, A.; Morganti, L.; Calore, E.; Schifano, S.; Michelotto, M.; Alfieri, R.; De Pietri, R.; et al. Power-Efficient Computing: Experiences from the COSA Project. Sci. Program. 2017. [Google Scholar] [CrossRef]
- Cesini, D.; Corni, E.; Falabella, A.; Ferraro, A.; Lama, L.; Morganti, L.; Calore, E.; Schifano, S.; Michelotto, M.; Alfieri, R.; et al. The INFN COSA Project: Low-Power Computing and Storage. Adv. Parallel Comput. 2018, 32, 770–779. [Google Scholar] [CrossRef]
- Nikolskiy, V.P.; Stegailov, V.V.; Vecher, V.S. Efficiency of the Tegra K1 and X1 systems-on-chip for classical molecular dynamics. In Proceedings of the 2016 International Conference on High Performance Computing Simulation (HPCS), Innsbruck, Austria, 18–22 July 2016; pp. 682–689. [Google Scholar]
- Ukidave, Y.; Kaeli, D.; Gupta, U.; Keville, K. Performance of the NVIDIA Jetson TK1 in HPC. In Proceedings of the 2015 IEEE International Conference on Cluster Computing (CLUSTER), Chicago, IL, USA, 8–11 September 2015; pp. 533–534. [Google Scholar]
- Geveler, M.; Ribbrock, D.; Donner, D.; Ruelmann, H.; Höppke, C.; Schneider, D.; Tomaschewski, D.; Turek, S. The ICARUS White Paper: A Scalable, Energy-Efficient, Solar-Powered HPC Center Based on Low Power GPUs. In Euro-Par 2016: Parallel Processing Workshops, Proceedings of the Euro-Par 2016 International Workshops, Grenoble, France, 24–26 August 2016; Desprez, F., Dutot, P.F., Kaklamanis, C., Marchal, L., Molitorisz, K., Ricci, L., Scarano, V., Vega-Rodríguez, M.A., Varbanescu, A.L., Hunold, S., et al., Eds.; Springer International Publishing: Berlin, Germany, 2017; pp. 737–749. [Google Scholar]
- Durand, Y.; Carpenter, P.M.; Adami, S.; Bilas, A.; Dutoit, D.; Farcy, A.; Gaydadjiev, G.; Goodacre, J.; Katevenis, M.; Marazakis, M.; et al. Euroserver: Energy efficient node for european micro-servers. In Proceedings of the 2014 17th Euromicro Conference on Digital System Design (DSD), Verona, Italy, 27–29 August 2014; pp. 206–213. [Google Scholar]
- Mantovani, F.; Calore, E. Multi-Node Advanced Performance and Power Analysis with Paraver. In Parallel Computing is Everywhere; Advances in Parallel Computing; IOS Press Ebooks: Amsterdam, The Netherlands, 2018; Volume 32. [Google Scholar]
- Etinski, M.; Corbalán, J.; Labarta, J.; Valero, M. Understanding the future of energy-performance trade-off via DVFS in HPC environments. J. Parallel Distrib.Comput. 2012, 72, 579–590. [Google Scholar] [CrossRef]
- Weaver, V.; Johnson, M.; Kasichayanula, K.; Ralph, J.; Luszczek, P.; Terpstra, D.; Moore, S. Measuring Energy and Power with PAPI. In Proceedings of the 2012 41st International Conference on Parallel Processing Workshops (ICPPW), Pittsburgh, PA, USA, 10—13 September 2012; pp. 262–268. [Google Scholar]
- Succi, S. The Lattice-Boltzmann Equation; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Sbragaglia, M.; Benzi, R.; Biferale, L.; Chen, H.; Shan, X.; Succi, S. Lattice Boltzmann method with self-consistent thermo-hydrodynamic equilibria. J. Fluid Mech. 2009, 628, 299–309. [Google Scholar] [CrossRef]
- Scagliarini, A.; Biferale, L.; Sbragaglia, M.; Sugiyama, K.; Toschi, F. Lattice Boltzmann methods for thermal flows: Continuum limit and applications to compressible Rayleigh-Taylor systems. Phys. Fluids 2010, 22, 055101. [Google Scholar] [CrossRef]
- Biferale, L.; Mantovani, F.; Sbragaglia, M.; Scagliarini, A.; Toschi, F.; Tripiccione, R. Second-order closure in stratified turbulence: Simulations and modeling of bulk and entrainment regions. Phys. Rev. E 2011, 84, 016305. [Google Scholar] [CrossRef] [PubMed]
- Biferale, L.; Mantovani, F.; Sbragaglia, M.; Scagliarini, A.; Toschi, F.; Tripiccione, R. Reactive Rayleigh-Taylor systems: Front propagation and non-stationarity. EPL 2011, 94, 54004. [Google Scholar] [CrossRef]
- Biferale, L.; Mantovani, F.; Pivanti, M.; Pozzati, F.; Sbragaglia, M.; Scagliarini, A.; Schifano, S.F.; Toschi, F.; Tripiccione, R. A Multi-GPU Implementation of a D2Q37 Lattice Boltzmann Code. In Parallel Processing and Applied Mathematics, Proceedings of the 9th International Conference on PPAM 2011, Lecture Notes in Computer Science, Torun, Poland, 11–14 September 2012; Springer: Berlin/Heidelberg, Germany; pp. 640–650.
- Calore, E.; Schifano, S.F.; Tripiccione, R. On Portability, Performance and Scalability of an MPI OpenCL Lattice Boltzmann Code. In Euro-Par 2014: Parallel Processing Workshops; LNCS; Springer: Berlin, Germany, 2014; pp. 438–449. [Google Scholar]
- Calore, E.; Gabbana, A.; Kraus, J.; Schifano, S.F.; Tripiccione, R. Performance and portability of accelerated lattice Boltzmann applications with OpenACC. Concurr. Comput. Pract. Exp. 2016, 28, 3485–3502. [Google Scholar] [CrossRef]
- Calore, E.; Gabbana, A.; Kraus, J.; Pellegrini, E.; Schifano, S.F.; Tripiccione, R. Massively parallel lattice-Boltzmann codes on large GPU clusters. Parallel Comput. 2016, 58, 1–24. [Google Scholar] [CrossRef]
- Mantovani, F.; Pivanti, M.; Schifano, S.F.; Tripiccione, R. Performance issues on many-core processors: A D2Q37 Lattice Boltzmann scheme as a test-case. Comput. Fluids 2013, 88, 743–752. [Google Scholar] [CrossRef]
- Calore, E.; Schifano, S.F.; Tripiccione, R. Energy-Performance Tradeoffs for HPC Applications on Low Power Processors. In Euro-Par 2015: Parallel Processing Workshops, Proceedings of the Euro-Par 2015 International Workshops, Vienna, Austria, 24–25 August 2015; Springer: Berlin, Germany, 2015; pp. 737–748. [Google Scholar]
- Biferale, L.; Mantovani, F.; Pivanti, M.; Pozzati, F.; Sbragaglia, M.; Scagliarini, A.; Schifano, S.F.; Toschi, F.; Tripiccione, R. An optimized D2Q37 Lattice Boltzmann code on GP-GPUs. Comput. Fluids 2013, 80, 55–62. [Google Scholar] [CrossRef][Green Version]
- Calore, E.; Marchi, D.; Schifano, S.F.; Tripiccione, R. Optimizing communications in multi-GPU Lattice Boltzmann simulations. In Proceedings of the 2015 International Conference on High Performance Computing Simulation (HPCS), Amsterdam, The Netherlands, 20–24 July 2015; pp. 55–62. [Google Scholar]
- Calore, E.; Gabbana, A.; Schifano, S.F.; Tripiccione, R. Evaluation of DVFS techniques on modern HPC processors and accelerators for energy-aware applications. Concurr. Comput. Pract. Exp. 2017. [Google Scholar] [CrossRef]
- Smith, R.; Ho, J. Tegra X1’s GPU: Maxwell for Mobile. Available online: https://www.anandtech.com/show/8811/nvidia-tegra-x1-preview/2 (accessed on 28 April 2018).
- Hackenberg, D.; Ilsche, T.; Schone, R.; Molka, D.; Schmidt, M.; Nagel, W. Power measurement techniques on standard compute nodes: A quantitative comparison. In Proceedings of the 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Austin, TX, USA, 21–23 April 2013; pp. 194–204. [Google Scholar]
- Hackenberg, D.; Schone, R.; Ilsche, T.; Molka, D.; Schuchart, J.; Geyer, R. An Energy Efficiency Feature Survey of the Intel Haswell Processor. In Proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium Workshop (IPDPSW), Hyderabad, India, 25–29 May 2015; pp. 896–904. [Google Scholar]
- Beneventi, F.; Bartolini, A.; Cavazzoni, C.; Benini, L. Continuous Learning of HPC Infrastructure Models Using Big Data Analytics and In-memory Processing Tools. In Proceedings of the Conference on Design, Automation & Test in Europe, Lausanne, Switzerland, 27–31 March 2017; pp. 1038–1043. [Google Scholar]
- Tran, K.A.; Carlson, T.E.; Koukos, K.; Själander, M.; Spiliopoulos, V.; Kaxiras, S.; Jimborean, A. Clairvoyance: Look-ahead compile-time scheduling. In Proceedings of the 2017 International Symposium on Code Generation and Optimization, Austin, TX, USA, 4–8 February 2017; pp. 171–184. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
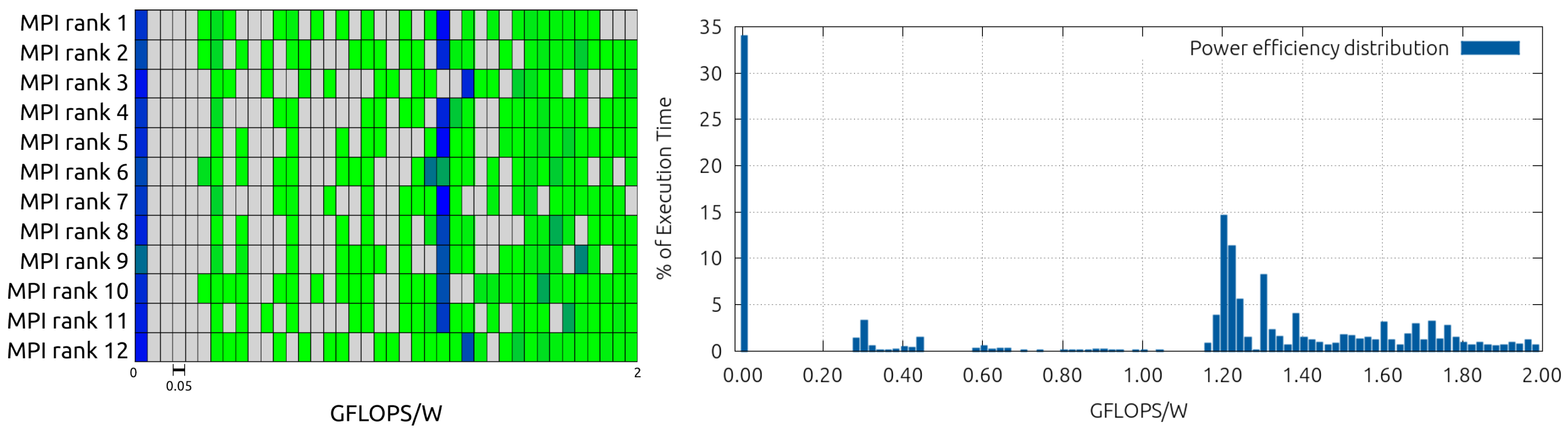
| [0.00;0.20) | [0.20;0.40) | [0.40;0.60) | [0.60;0.80) | [0.80;1.00) | [1.00;1.20) | [1.20;1.40) | [1.40;1.60) | [1.60;1.80) | [1.80;2.00] | |
|---|---|---|---|---|---|---|---|---|---|---|
| MPI rank 1 | 33.85% | 5.48% | 0.00% | 2.23% | 0.76% | 1.12 % | 42.14% | 7.45 % | 6.35 % | 0.62% |
| MPI rank 2 | 30.13% | 6.43% | 0.93% | 0.86% | 0.26% | 0.00 % | 39.81% | 2.26 % | 15.76% | 3.54% |
| MPI rank 3 | 39.05% | 0.94% | 0.00% | 1.05% | 0.14% | 0.04 % | 36.28% | 12.84% | 4.56 % | 5.10% |
| MPI rank 4 | 33.58% | 5.54% | 0.00% | 0.49% | 0.09% | 0.00 % | 46.46% | 3.22 % | 7.52 % | 3.10% |
| MPI rank 5 | 35.37% | 0.72% | 0.20% | 0.17% | 0.13% | 0.00 % | 40.82% | 5.06 % | 13.83% | 3.70% |
| MPI rank 6 | 30.22% | 6.20% | 1.83% | 0.27% | 0.13% | 23.28% | 16.58% | 5.70 % | 11.61% | 4.17% |
| MPI rank 7 | 33.18% | 7.18% | 0.00% | 1.04% | 0.25% | 0.00 % | 42.87% | 8.44 % | 3.58 % | 3.46% |
| MPI rank 8 | 36.48% | 0.73% | 0.22% | 0.08% | 0.14% | 3.63 % | 34.18% | 2.57 % | 18.92% | 3.04% |
| MPI rank 9 | 24.24% | 5.23% | 2.93% | 0.66% | 0.62% | 0.00 % | 30.08% | 4.71 % | 27.47% | 4.05% |
| MPI rank 10 | 35.14% | 0.65% | 0.34% | 0.16% | 0.20% | 0.08 % | 33.29% | 6.67 % | 18.07% | 5.41% |
| MPI rank 11 | 37.26% | 0.43% | 0.14% | 0.13% | 0.16% | 3.02 % | 33.42% | 4.38 % | 17.29% | 3.77% |
| MPI rank 12 | 39.36% | 0.89% | 0.11% | 0.11% | 0.13% | 0.02 % | 32.73% | 9.75 % | 10.88% | 6.02% |
| [ns/site] | [W] | [J/site] | EDP [/site] | |||
|---|---|---|---|---|---|---|
| CPUs | Jetson Nodes | 93.38 | 89.92 | 8.29 | ||
| COKA Node | 42.32 | 206.78 | 8.74 | |||
| GPUs | Jetson Nodes | 50.47 | 66.46 | 3.35 | ||
| COKA K80 | 7.15 | 290.18 | 2.09 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mantovani, F.; Calore, E. Performance and Power Analysis of HPC Workloads on Heterogeneous Multi-Node Clusters. J. Low Power Electron. Appl. 2018, 8, 13. https://doi.org/10.3390/jlpea8020013
Mantovani F, Calore E. Performance and Power Analysis of HPC Workloads on Heterogeneous Multi-Node Clusters. Journal of Low Power Electronics and Applications. 2018; 8(2):13. https://doi.org/10.3390/jlpea8020013
Chicago/Turabian StyleMantovani, Filippo, and Enrico Calore. 2018. "Performance and Power Analysis of HPC Workloads on Heterogeneous Multi-Node Clusters" Journal of Low Power Electronics and Applications 8, no. 2: 13. https://doi.org/10.3390/jlpea8020013
APA StyleMantovani, F., & Calore, E. (2018). Performance and Power Analysis of HPC Workloads on Heterogeneous Multi-Node Clusters. Journal of Low Power Electronics and Applications, 8(2), 13. https://doi.org/10.3390/jlpea8020013