
A Robust Ultra-Low Voltage CPU Utilizing Timing-Error Prevention †

Abstract
:1. Introduction
2. Ultra-Low Voltage Operation
2.1. Motivation and Challenges
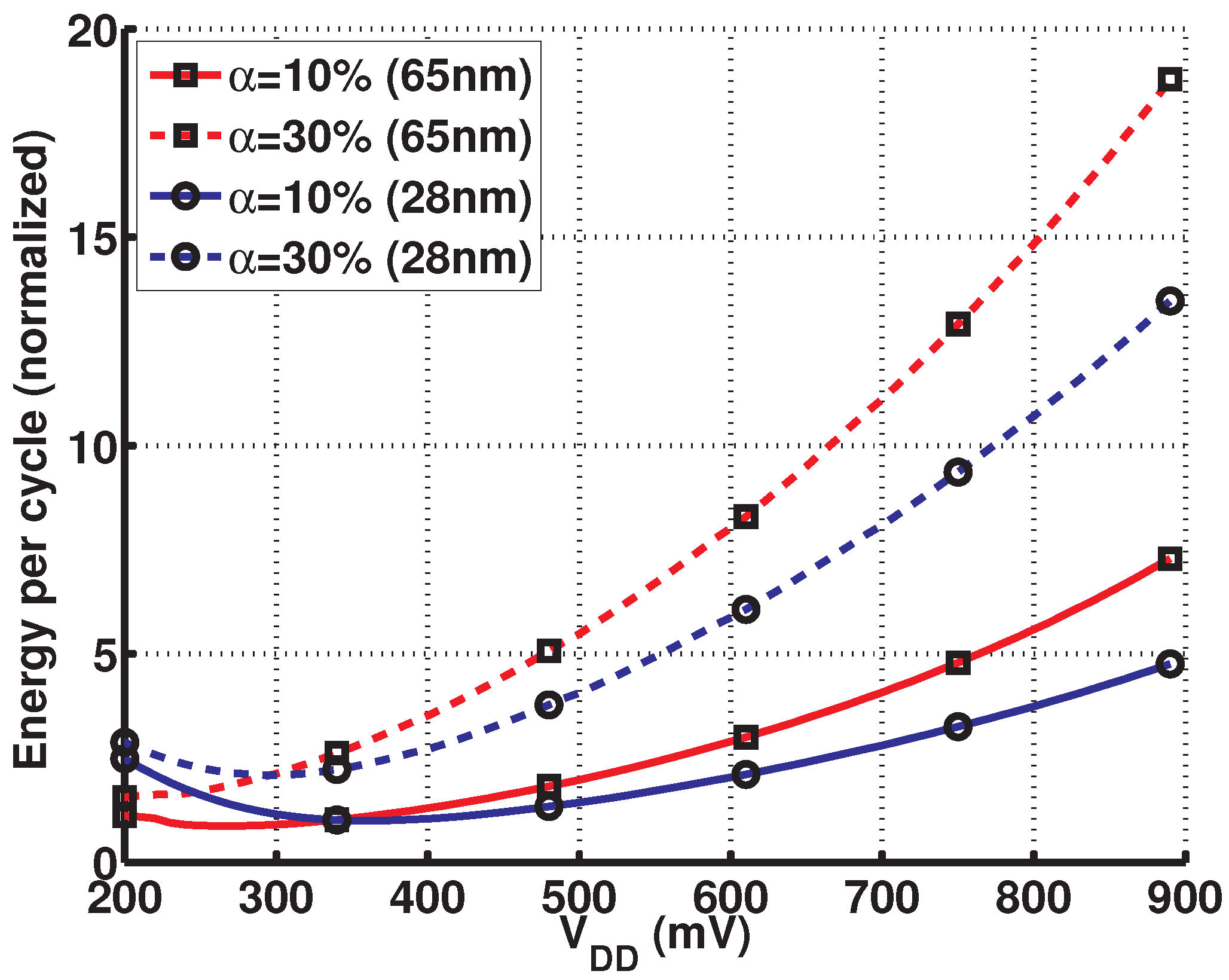

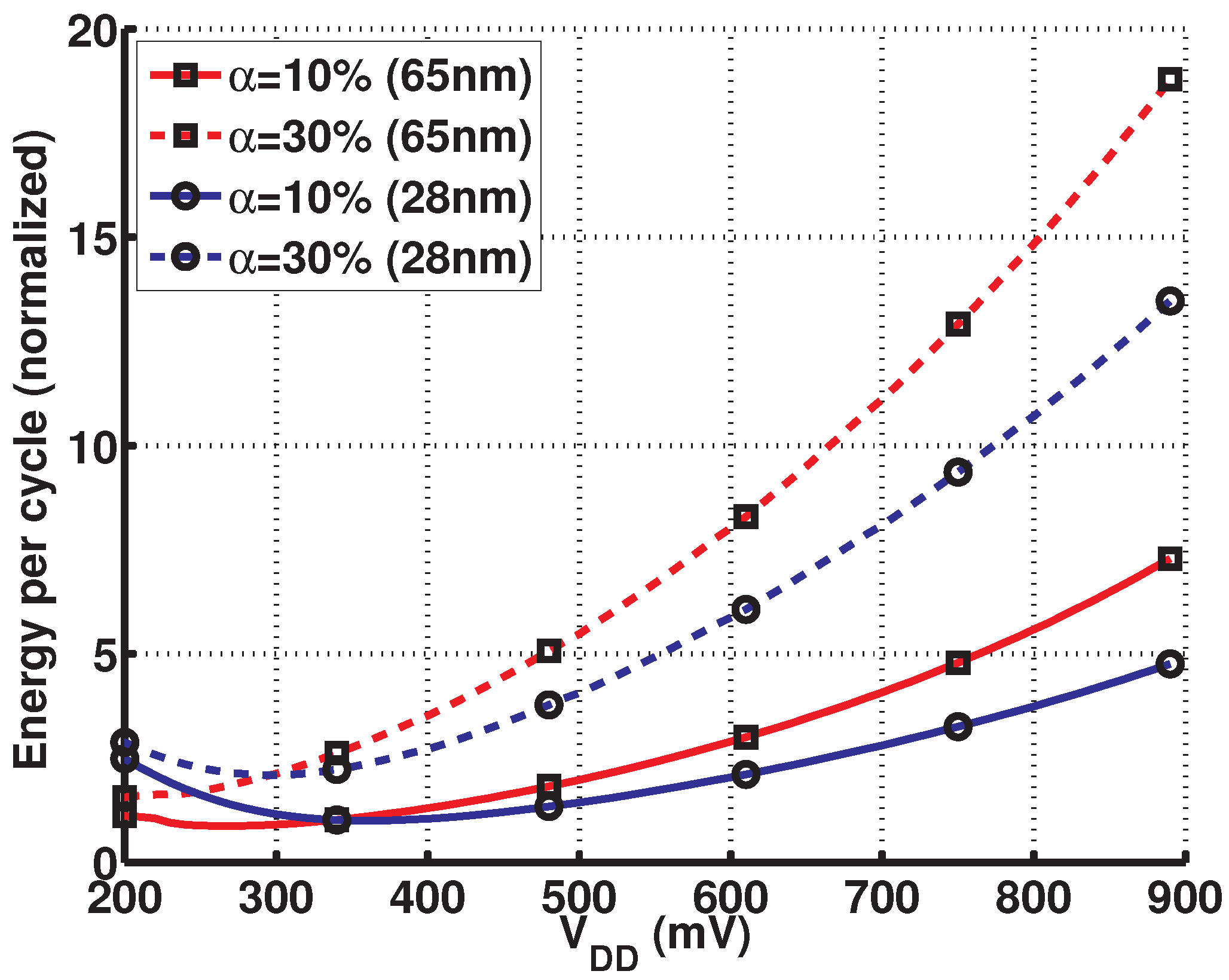{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (ns) | (ns) | (ns) | σ (ns) | |
|---|---|---|---|---|
| 0.3 V | 305 | 237 (–22.2%) | 393 (+28.9%) | 32.8 (10.8%) |
| 0.4 V | 40.1 | 31.9 (–20.4%) | 52.0 (+29.7%) | 3.9 (9.7%) |
| 0.5 V | 6.63 | 5.57 (–16.0%) | 8.20 (+23.7%) | 0.5 (7.3%) |
| 0.6 V | 1.90 | 1.71 (–10.0%) | 2.17 (+14.2%) | 0.09 (4.7%) |
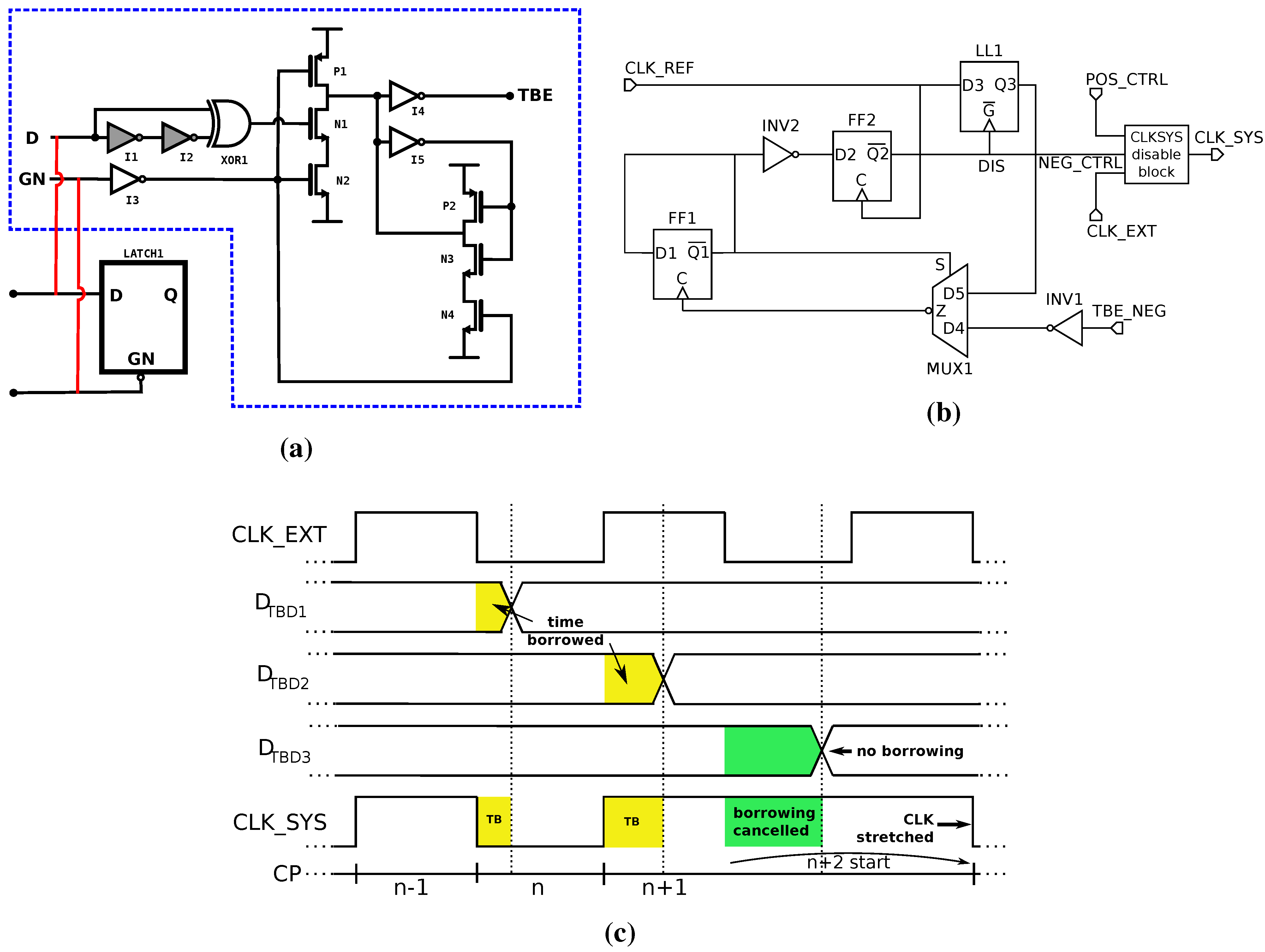
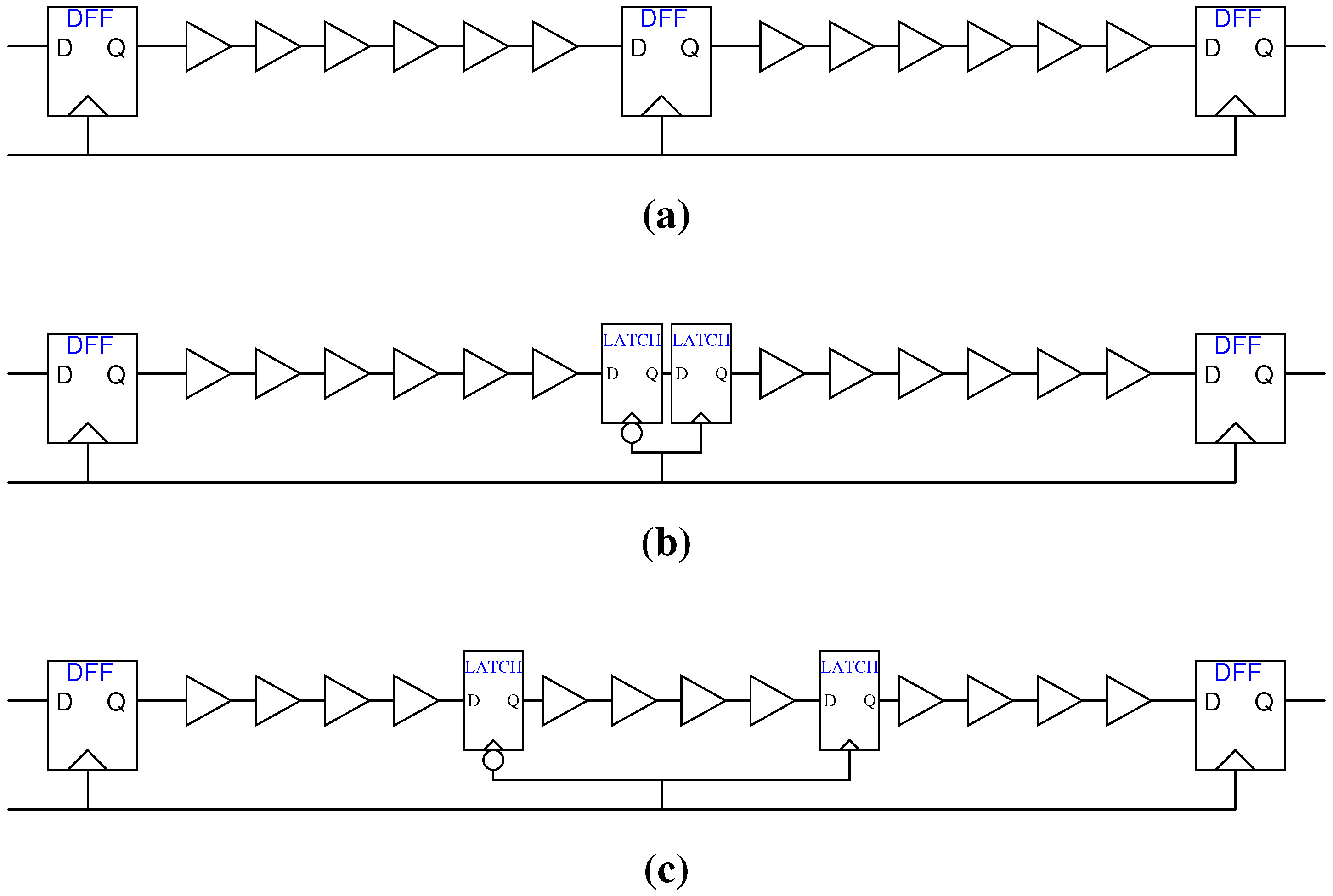
2.2. Adaptive Timing Methods
2.2.1. Timing-Error Detection
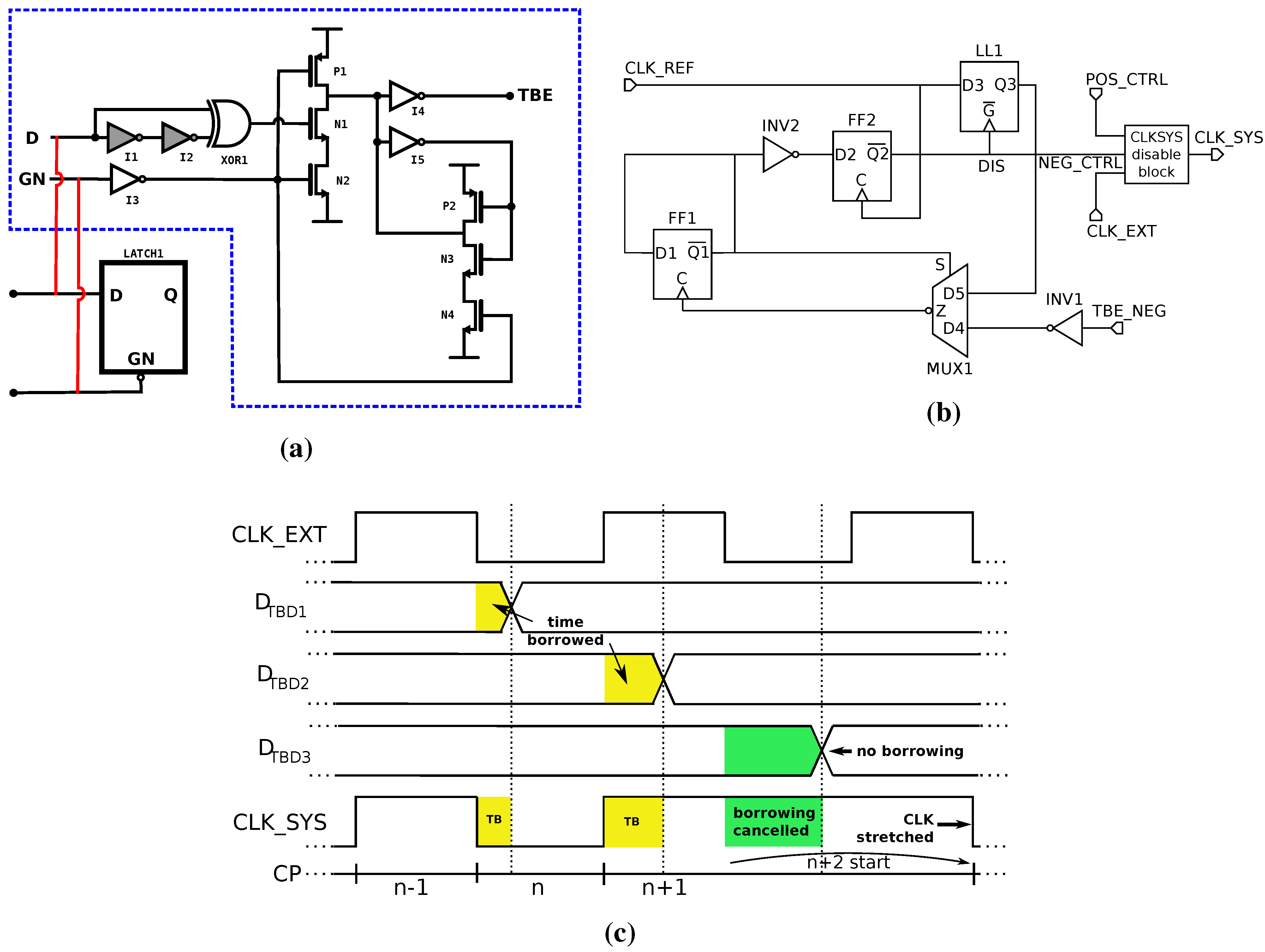
2.2.2. Timing-Error Prevention
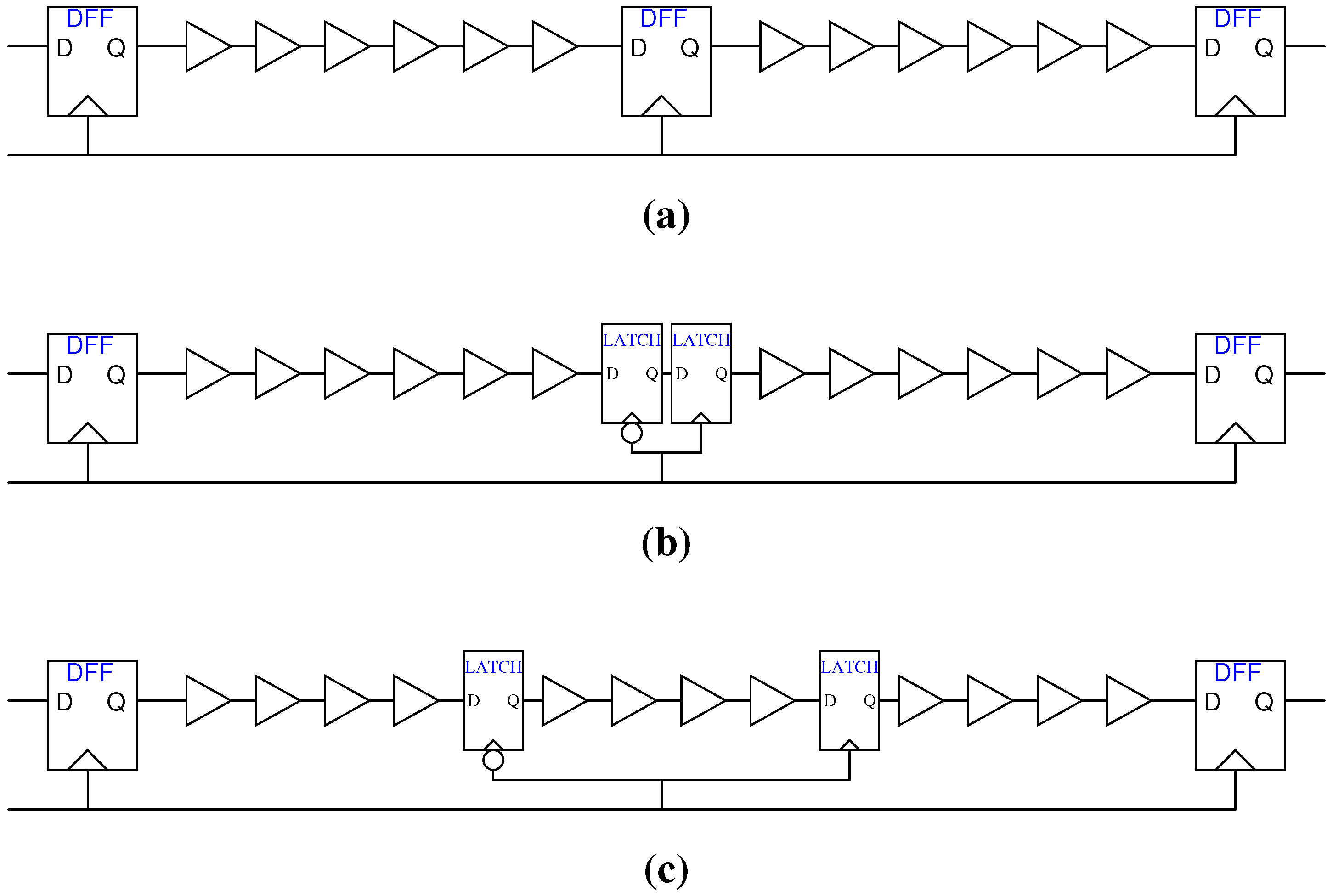
3. Design of a 32-bit RISC CPU with TEP
| Design attribute | CPU1 | CPU2 |
|---|---|---|
| Pipeline implementation | Latch transformation + retime | RTL rewrite |
| Memory type | SRAM | Latch array |
| Supply voltage (mV) | 400 | 400 |
| Frequency target (MHz) | 0.89 | 0.67 |
| Sequential cells | 3623 latches | 2006 latches |
| Time-borrow detectors | 272 | 256 |
| TBD area overhead (%) | 7.5 | 10.9 |
| Die area (excl. memory) () | 0.030 | 0.022 |
3.1. CPU1
3.2. CPU2

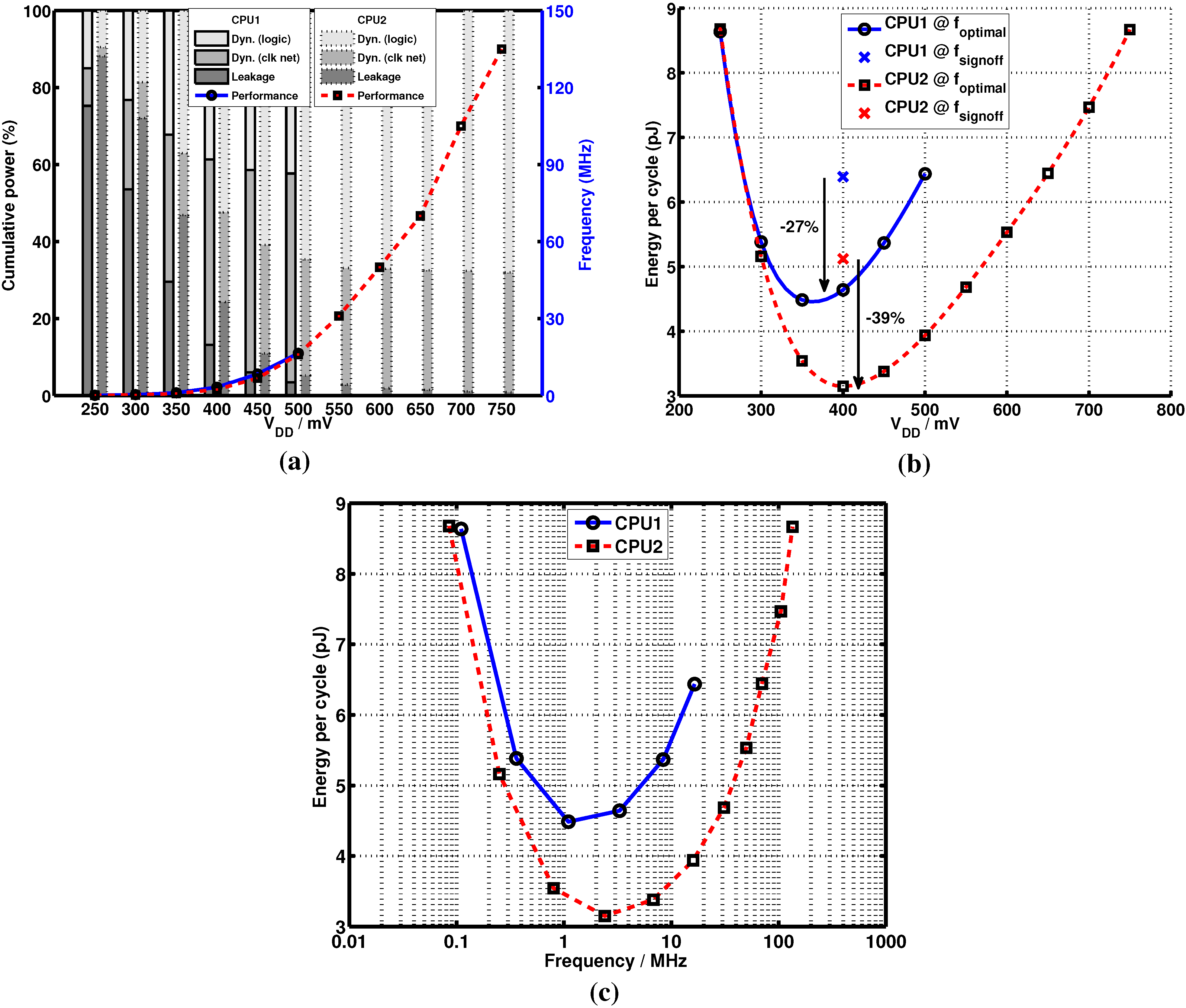
4. Measurement Results and Discussion

| Design metric | MIT, JSSC [13] | Sleepwalker [14] | This Work (CPU2) |
|---|---|---|---|
| Technology | 65 nm CMOS | 65 nm CMOS LP/GP | 28 nm CMOS LP |
| CPU | 16-bit MSP430 compatible | 16-bit MSP430 compatible | 32-bit LatticeMico32 |
| CPU area () | 0.14 | approx. 0.12 | 0.022 |
| Ext. supply (V) | 1.2 | 1.0–1.2 | 1.0 V–1.5 V |
| Int Vdd (V) | 0.3–0.6 | 0.32–0.48 | 0.25–0.5 |
| Frequency (MHz) | 0.43 (25 C) | 25 | 2.4 (0.4 V/25 C) |
| CPU energy (pJ/cyc) | 6–10 | 2.6 | 3.15 |
| DMIPS/MHz | 0.45 | 0.45 | 1.14 |
| DMIPS/mJ (estim.) | 60 | 173 | 362 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bol, D.; Ambroise, R.; Flandre, D.; Legat, J.D. Interests and Limitations of Technology Scaling for Subthreshold Logic. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2009, 17, 1508–1519. [Google Scholar] [CrossRef]
- Calhoun, B.; Chandrakasan, A. Ultra-Dynamic Voltage scaling (UDVS) using sub-threshold operation and local Voltage dithering. IEEE J. Solid-State Circuits 2006, 41, 238–245. [Google Scholar] [CrossRef]
- Wang, A.; Calhoun, B.H.; Chandrakasan, A.P. Sub-Threshold Design for Ultra Low-Power Systems (Series on Integrated Circuits and Systems); Springer-Verlag New York, Inc.: Secaucus, NJ, USA, 2006. [Google Scholar]
- Das, S.; Tokunaga, C.; Pant, S.; Ma, W.H.; Kalaiselvan, S.; Lai, K.; Bull, D.; Blaauw, D. RazorII: In Situ Error Detection and Correction for PVT and SER Tolerance. IEEE J. Solid-State Circuits 2009, 44, 32–48. [Google Scholar] [CrossRef]
- Bowman, K.; Tschanz, J.; Lu, S.; Aseron, P.; Khellah, M.; Raychowdhury, A.; Geuskens, B.; Tokunaga, C.; Wilkerson, C.; Karnik, T.; et al. A 45 nm Resilient Microprocessor Core for Dynamic Variation Tolerance. IEEE J. Solid-State Circuits 2011, 46, 194–208. [Google Scholar] [CrossRef]
- Mäkipää, J.; Turnquist, M.J.; Laulainen, E.; Koskinen, L. Timing-Error Detection Design Considerations in Subthreshold: An 8-bit Microprocessor in 65 nm CMOS. J. Low Power Electron. Appl. 2012, 2, 180–196. [Google Scholar] [CrossRef]
- Chae, K.; Mukhopadhyay, S. A Dynamic Timing Error Prevention Technique in Pipelines with Time Borrowing and Clock Stretching. IEEE Trans. Circuits Syst. I 2014, 61, 74–83. [Google Scholar] [CrossRef]
- Fojtik, M.; Fick, D.; Kim, Y.; Pinckney, N.; Harris, D.; Blaauw, D.; Sylvester, D. Bubble Razor: Eliminating Timing Margins in an ARM Cortex-M3 Processor in 45 nm CMOS Using Architecturally Independent Error Detection and Correction. IEEE J. Solid-State Circuits 2013, 48, 66–81. [Google Scholar] [CrossRef]
- LatticeMico32: Open, Free 32-Bit Soft Processor. Available online: http://www.latticesemi.com/en/Products/DesignSoftwareAndIP/IntellectualProperty/IPCore/IPCores02/LatticeMico32.aspx (accessed on 20 Febuary 2015).
- Hiienkari, M.; Teittinen, J.; Koskinen, L.; Turnquist, M.; Kaltiokallio, M. A 3.15 pJ/cyc 32-bit RISC CPU with Timing-Error Prevention and Adaptive Clocking in 28 nm CMOS. In Proceedings of the 2014 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 15–17 September 2014; pp. 1–4.
- Hiienkari, M.; Teittinen, J.; Koskinen, L.; Turnquist, M.; Kaltiokallio, M.; Makipaa, J.; Rantala, A.; Sopanen, M. Ultra-Wide Voltage Range 32-bit RISC CPU with Timing-Error Prevention in 28 nm CMOS. In Proceedings of the 2014 IEEE SOI-3D-Subthreshold Microelectronics Technology Unified Conference (S3S), Millbrae, CA, USA, 6–9 October 2014; pp. 1–2.
- Yoshikawa, K.; Hagihara, Y.; Kanamaru, K.; Nakamura, Y.; Inui, S.; Yoshimura, T. Timing Optimization by Replacing Flip-Flops to Latches. In Proceedings of the 2004 Asia and South Pacific Design Automation Conference, ASP-DAC ’04, Singapore, 27–30 January 2004; IEEE Press: Piscataway, NJ, USA, 2004; pp. 186–191. [Google Scholar]
- Kwong, J.; Ramadass, Y.; Verma, N.; Chandrakasan, A. A 65 nm Sub-Vt Microcontroller with Integrated SRAM and Switched Capacitor DC-DC Converter. IEEE J. Solid-State Circuits 2009, 44, 115–126. [Google Scholar] [CrossRef]
- Bol, D.; de Vos, J.; Hocquet, C.; Botman, F.; Durvaux, F.; Boyd, S.; Flandre, D.; Legat, J. SleepWalker: A 25-MHz 0.4-V Sub-mm2 7-μW/MHz Microcontroller in 65-nm LP/GP CMOS for Low-Carbon Wireless Sensor Nodes. IEEE J. Solid State Circuits 2013, 48, 20–32. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hiienkari, M.; Teittinen, J.; Koskinen, L.; Turnquist, M.; Mäkipää, J.; Rantala, A.; Sopanen, M.; Kaltiokallio, M. A Robust Ultra-Low Voltage CPU Utilizing Timing-Error Prevention. J. Low Power Electron. Appl. 2015, 5, 57-68. https://doi.org/10.3390/jlpea5020057
Hiienkari M, Teittinen J, Koskinen L, Turnquist M, Mäkipää J, Rantala A, Sopanen M, Kaltiokallio M. A Robust Ultra-Low Voltage CPU Utilizing Timing-Error Prevention. Journal of Low Power Electronics and Applications. 2015; 5(2):57-68. https://doi.org/10.3390/jlpea5020057
Chicago/Turabian StyleHiienkari, Markus, Jukka Teittinen, Lauri Koskinen, Matthew Turnquist, Jani Mäkipää, Arto Rantala, Matti Sopanen, and Mikko Kaltiokallio. 2015. "A Robust Ultra-Low Voltage CPU Utilizing Timing-Error Prevention" Journal of Low Power Electronics and Applications 5, no. 2: 57-68. https://doi.org/10.3390/jlpea5020057
APA StyleHiienkari, M., Teittinen, J., Koskinen, L., Turnquist, M., Mäkipää, J., Rantala, A., Sopanen, M., & Kaltiokallio, M. (2015). A Robust Ultra-Low Voltage CPU Utilizing Timing-Error Prevention. Journal of Low Power Electronics and Applications, 5(2), 57-68. https://doi.org/10.3390/jlpea5020057