
An Analog Architecture and Algorithm for Efficient Convolutional Neural Network Image Computation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
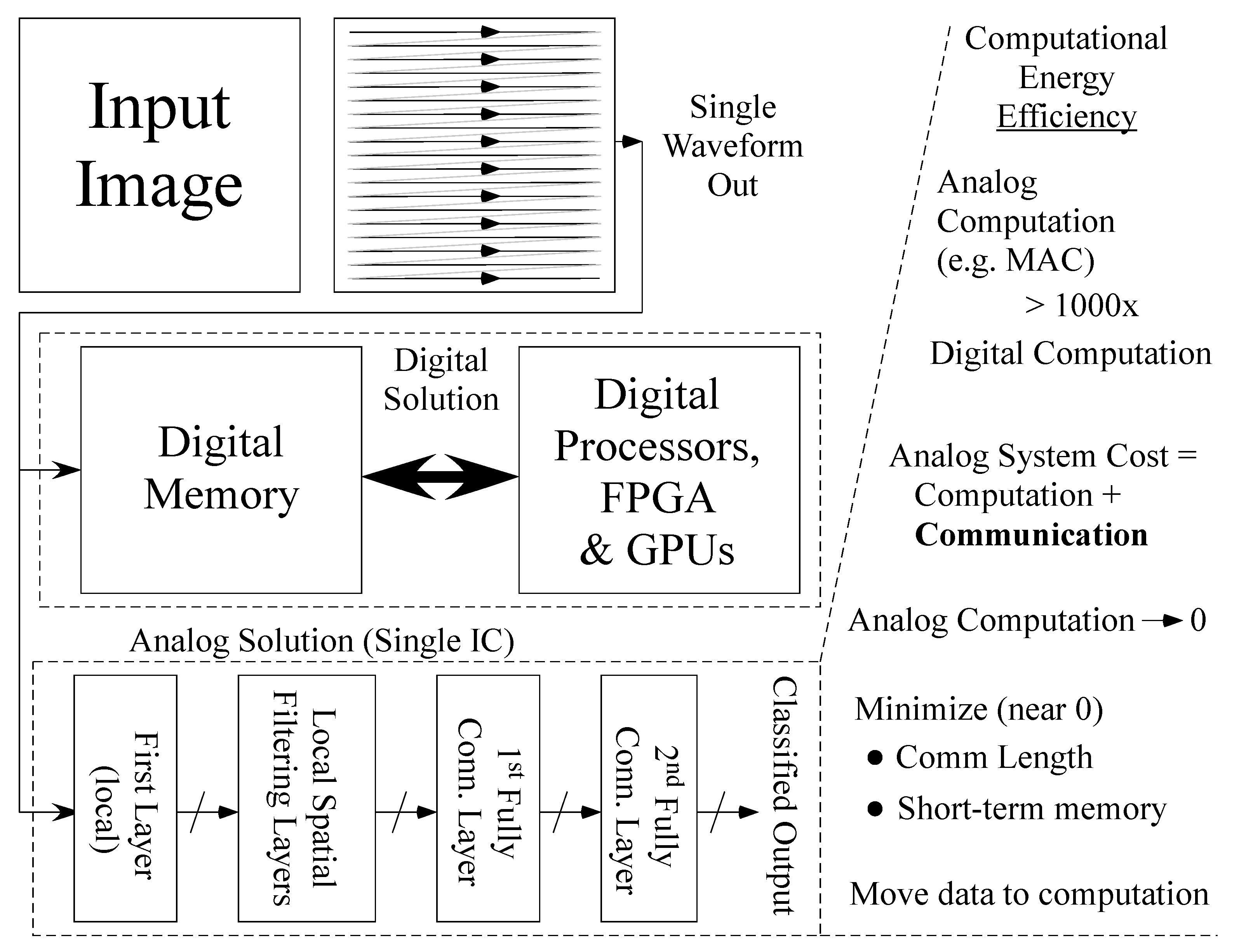
1. Image Classification Requires Analog Architecture Innovations
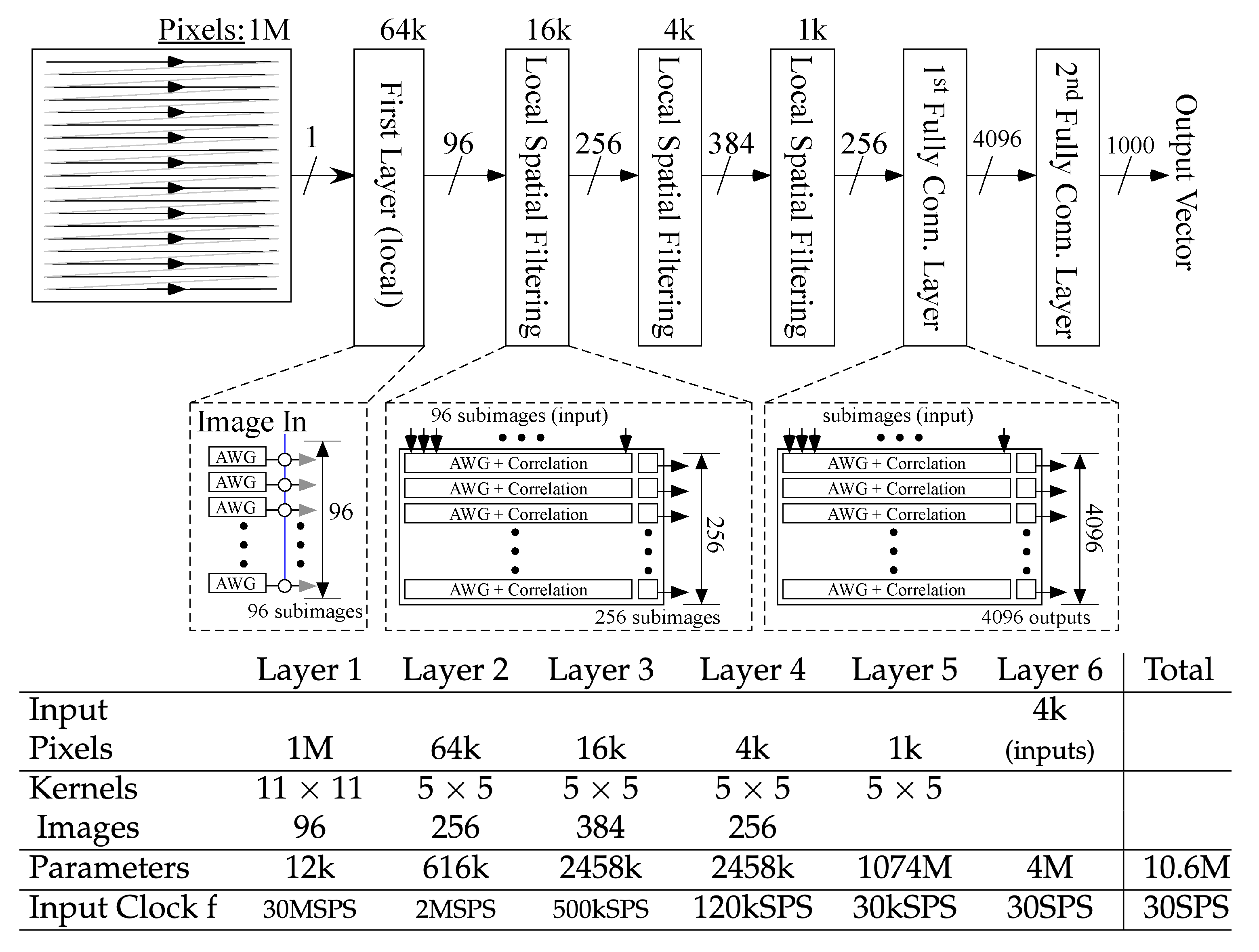
2. Analog Architecture for Convolutional Neural Networks: Minimizing the Cost of Moving Data and Parameters
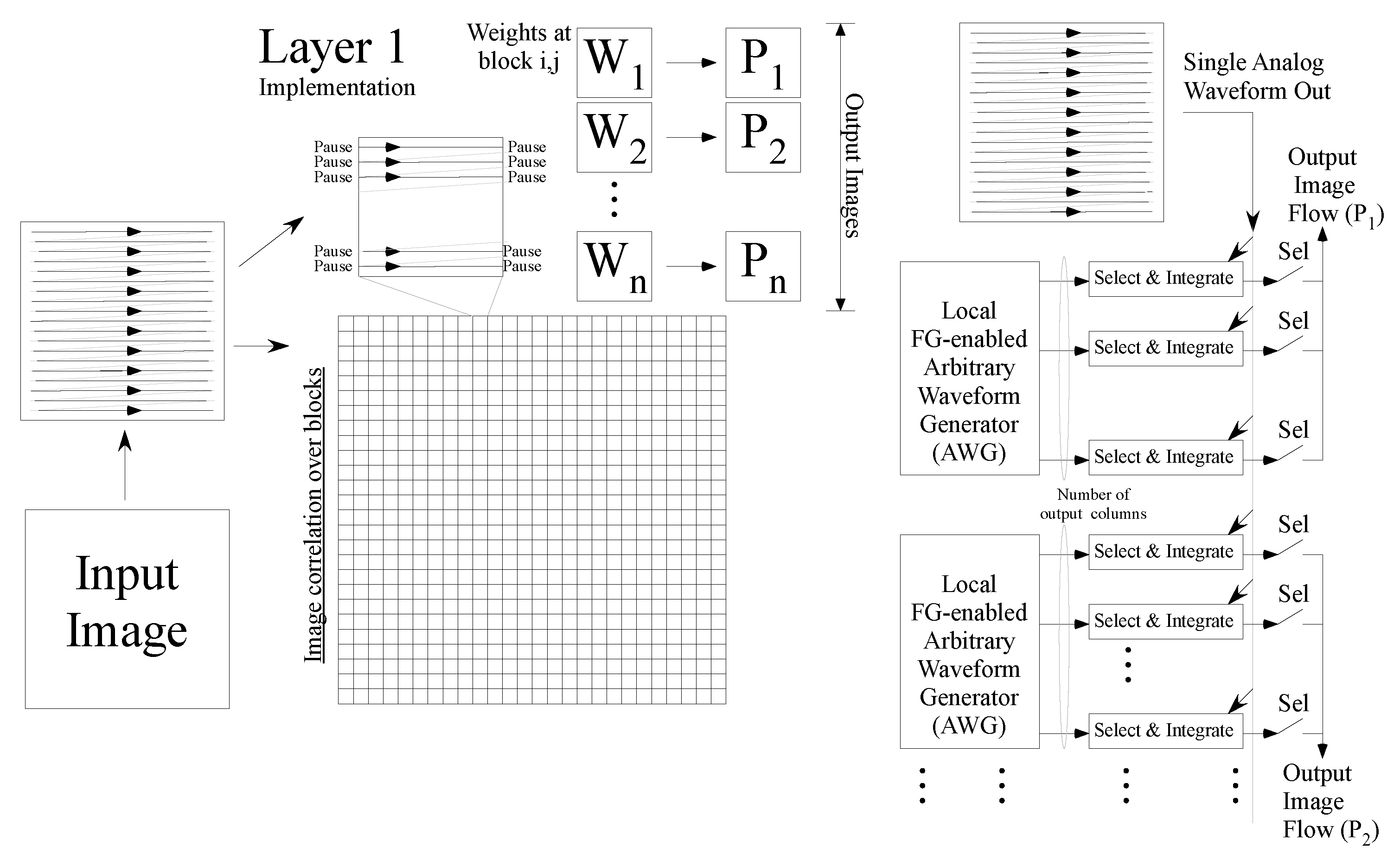
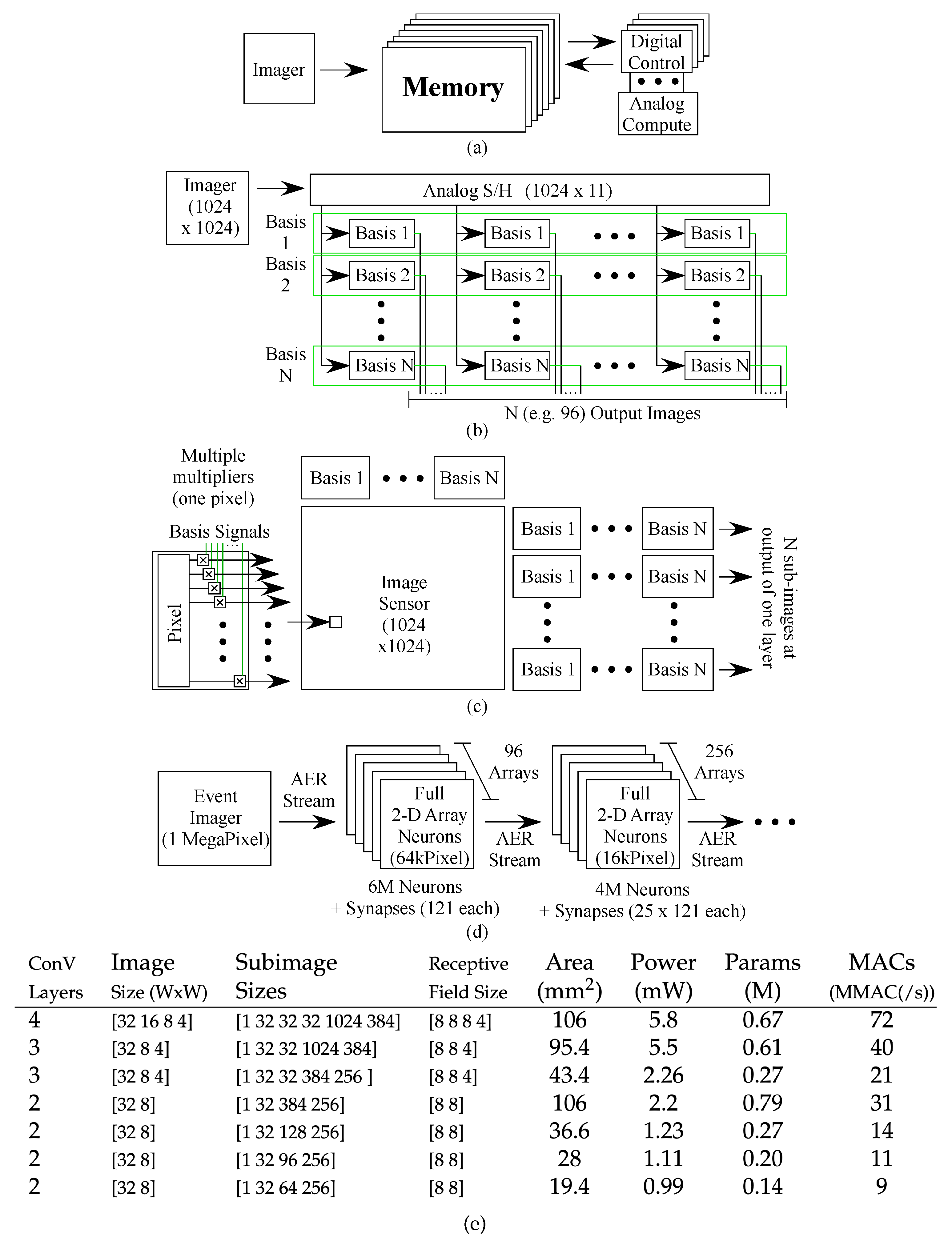
3. First ConvNN Convolutional Layer
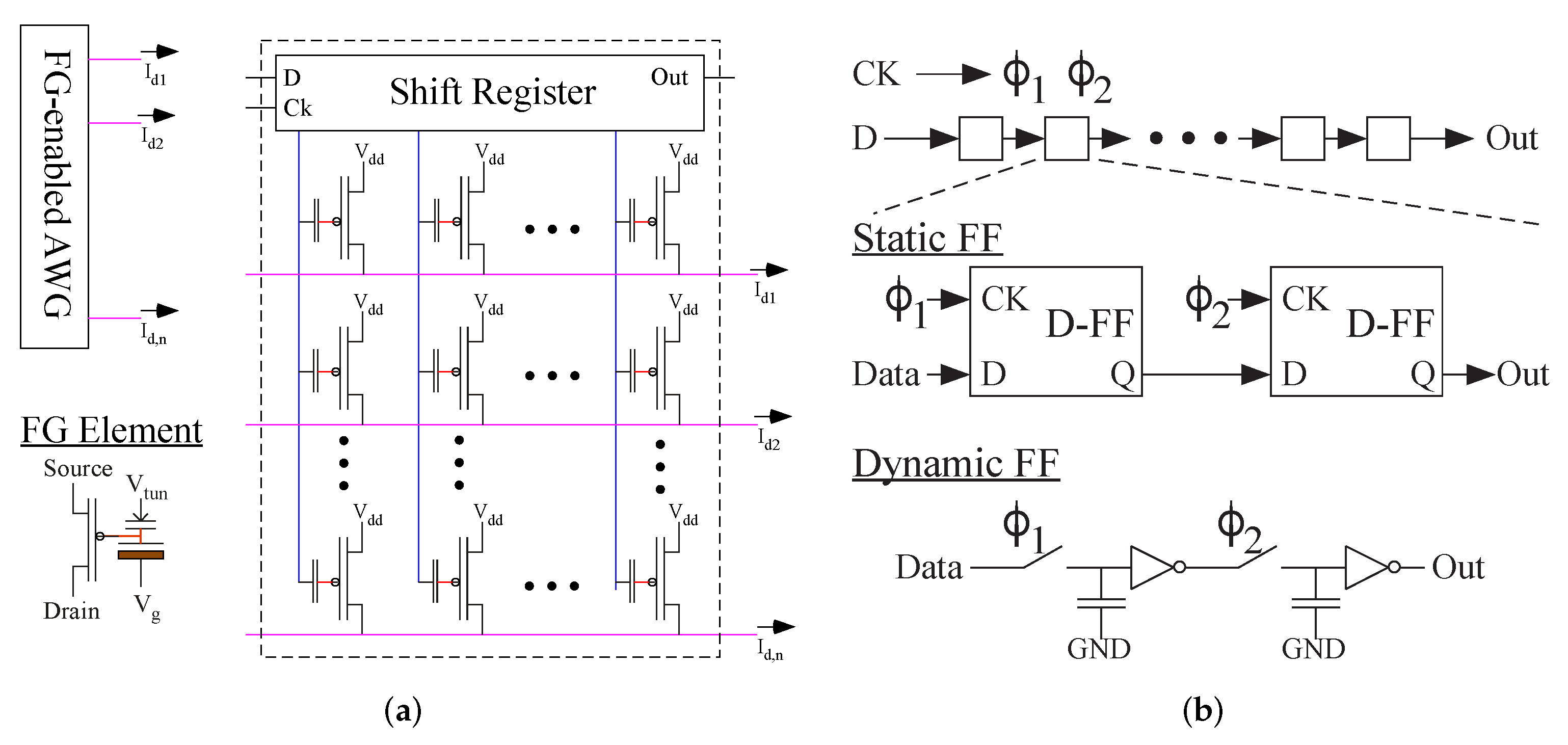
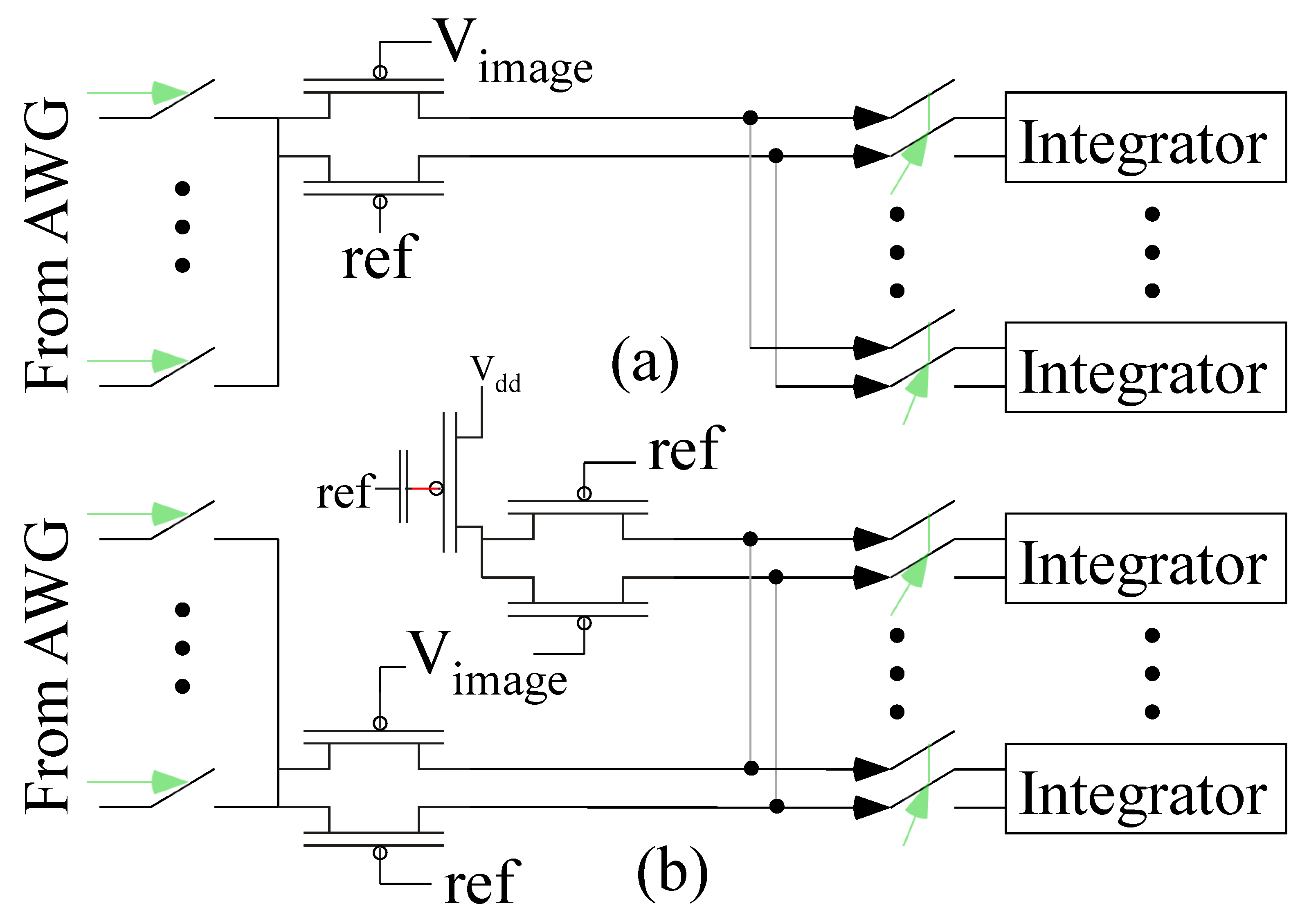
3.1. Arbitrary Waveform Generator (AWG)
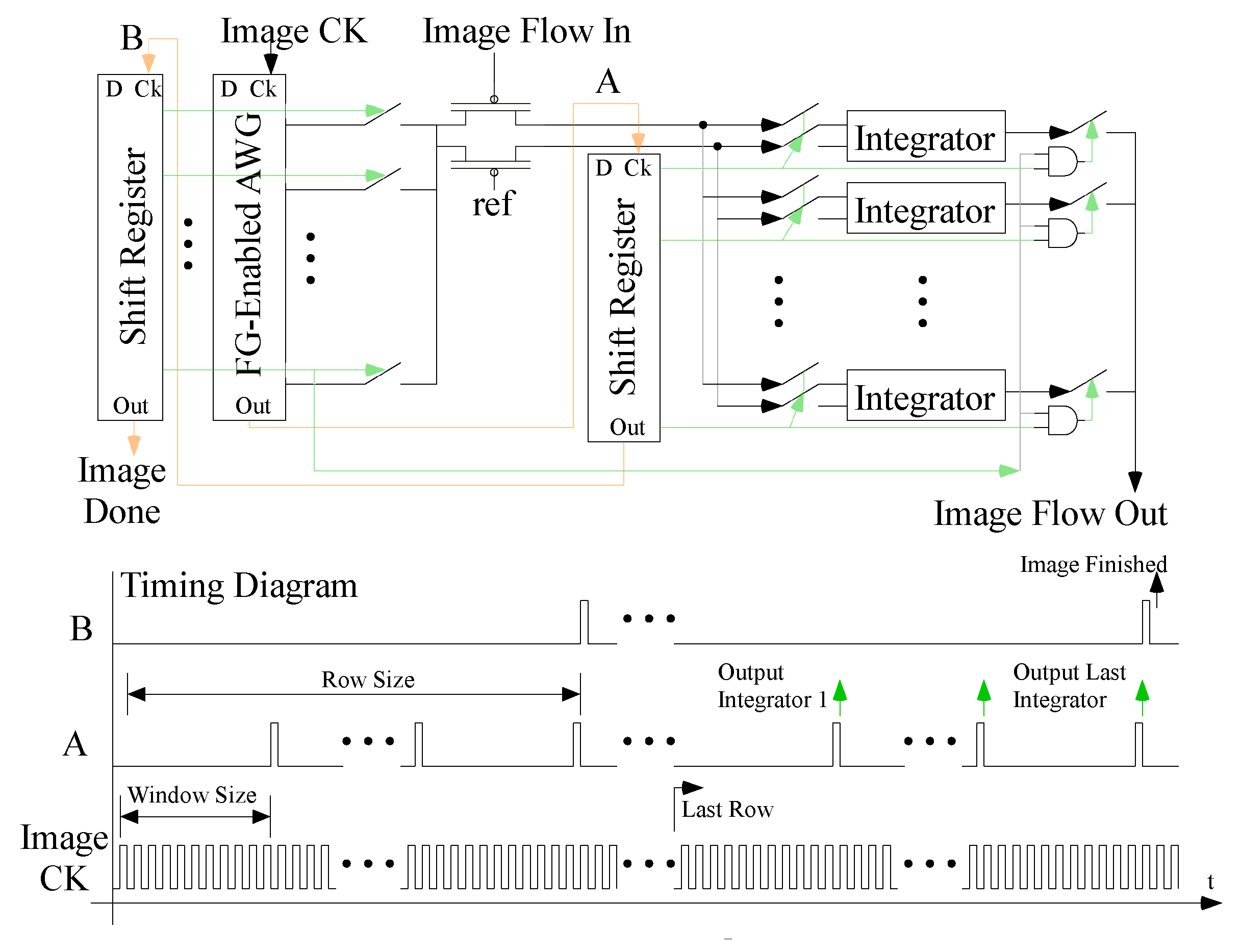
3.2. The Full System for the First Layer
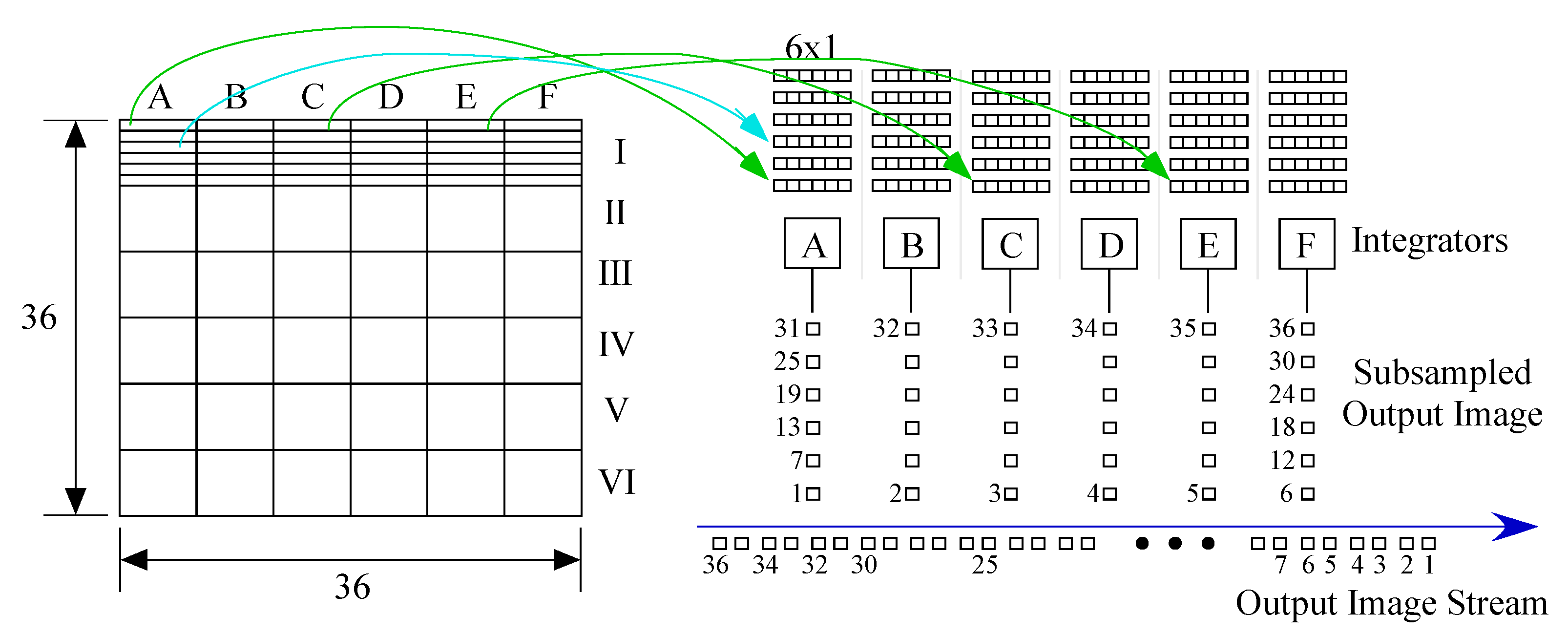
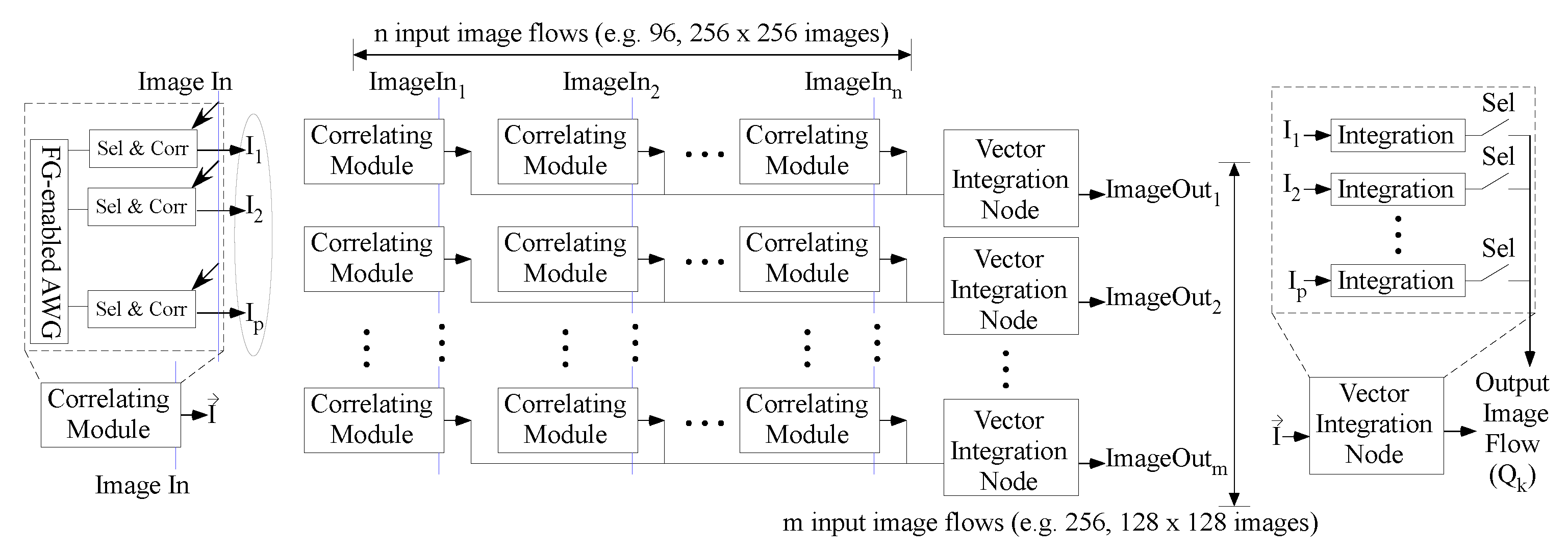
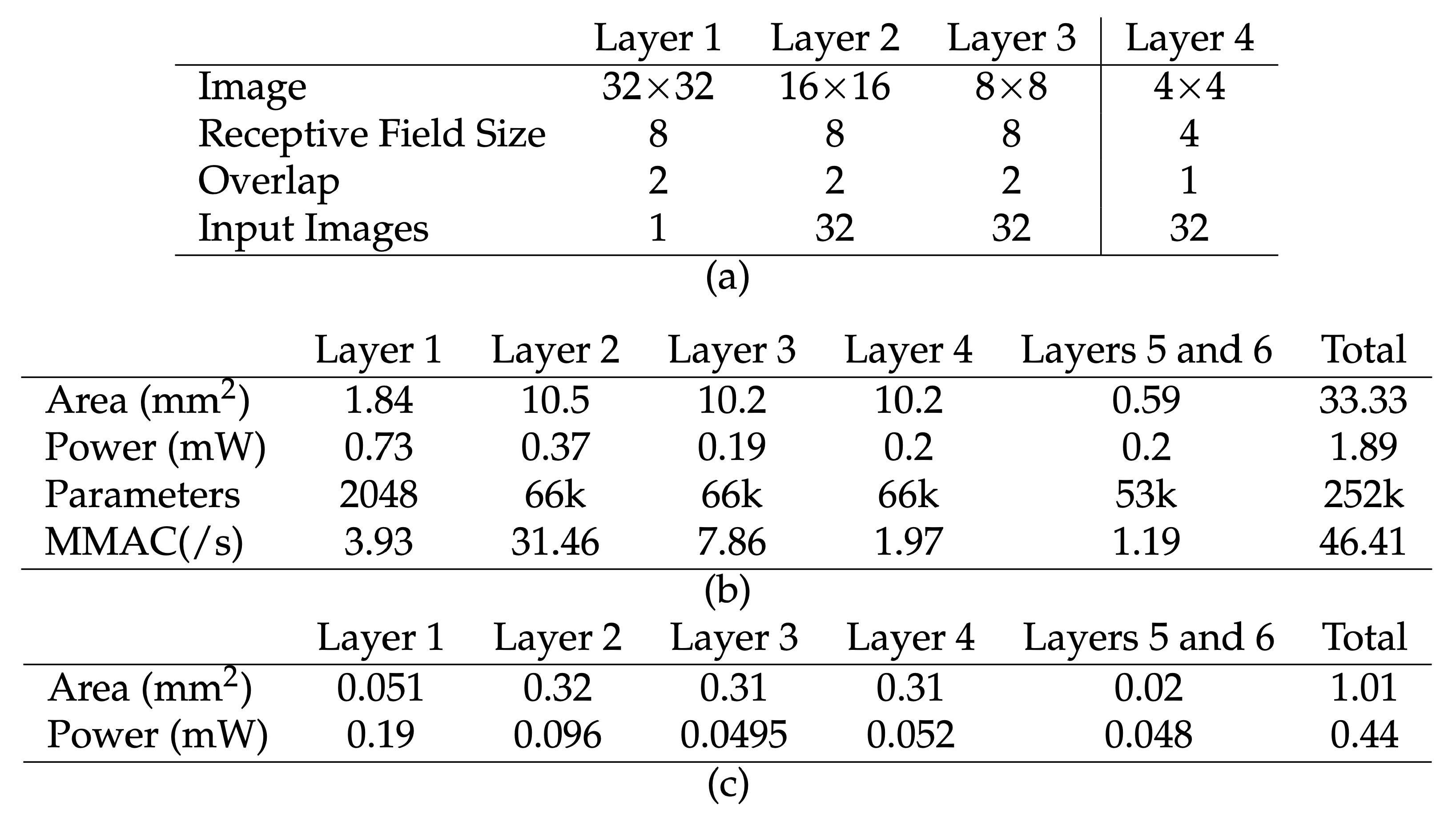
4. Additional Convolutional Layers

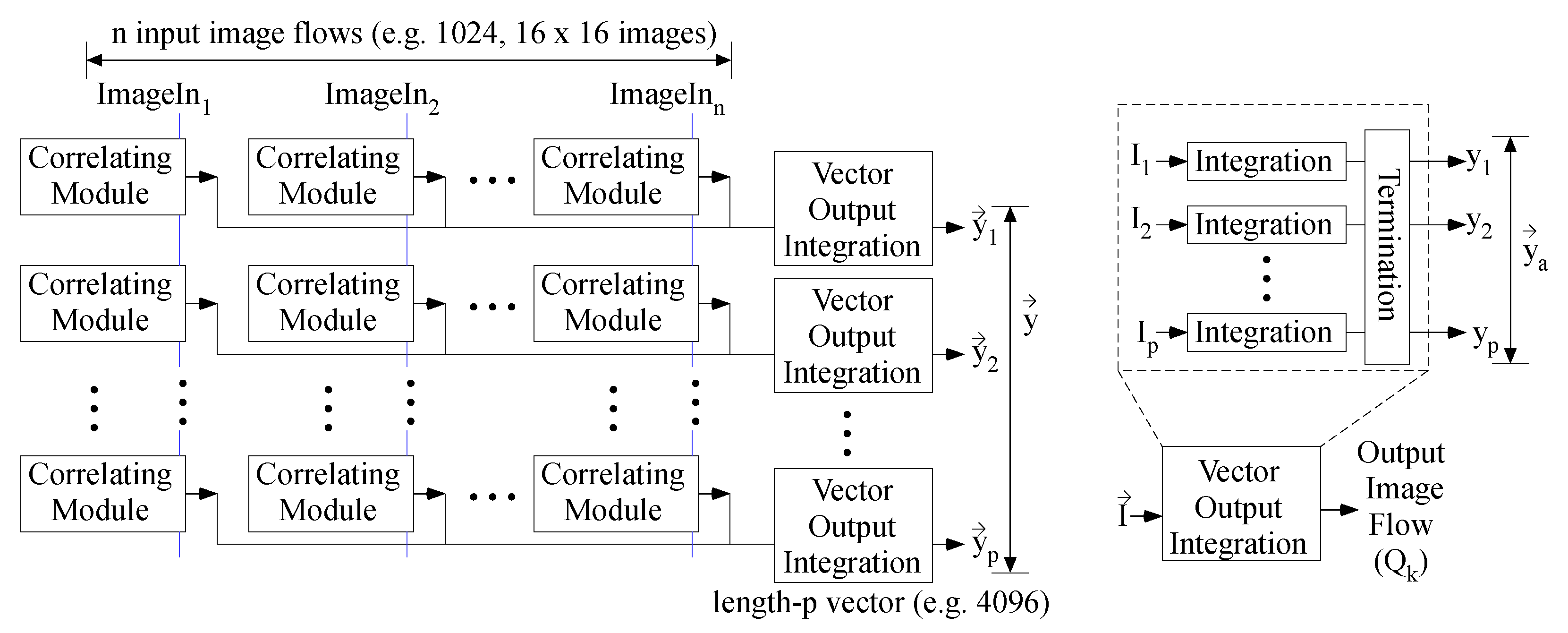
5. Convolution to First Fully Connected Layer
6. Fully Connected Layers
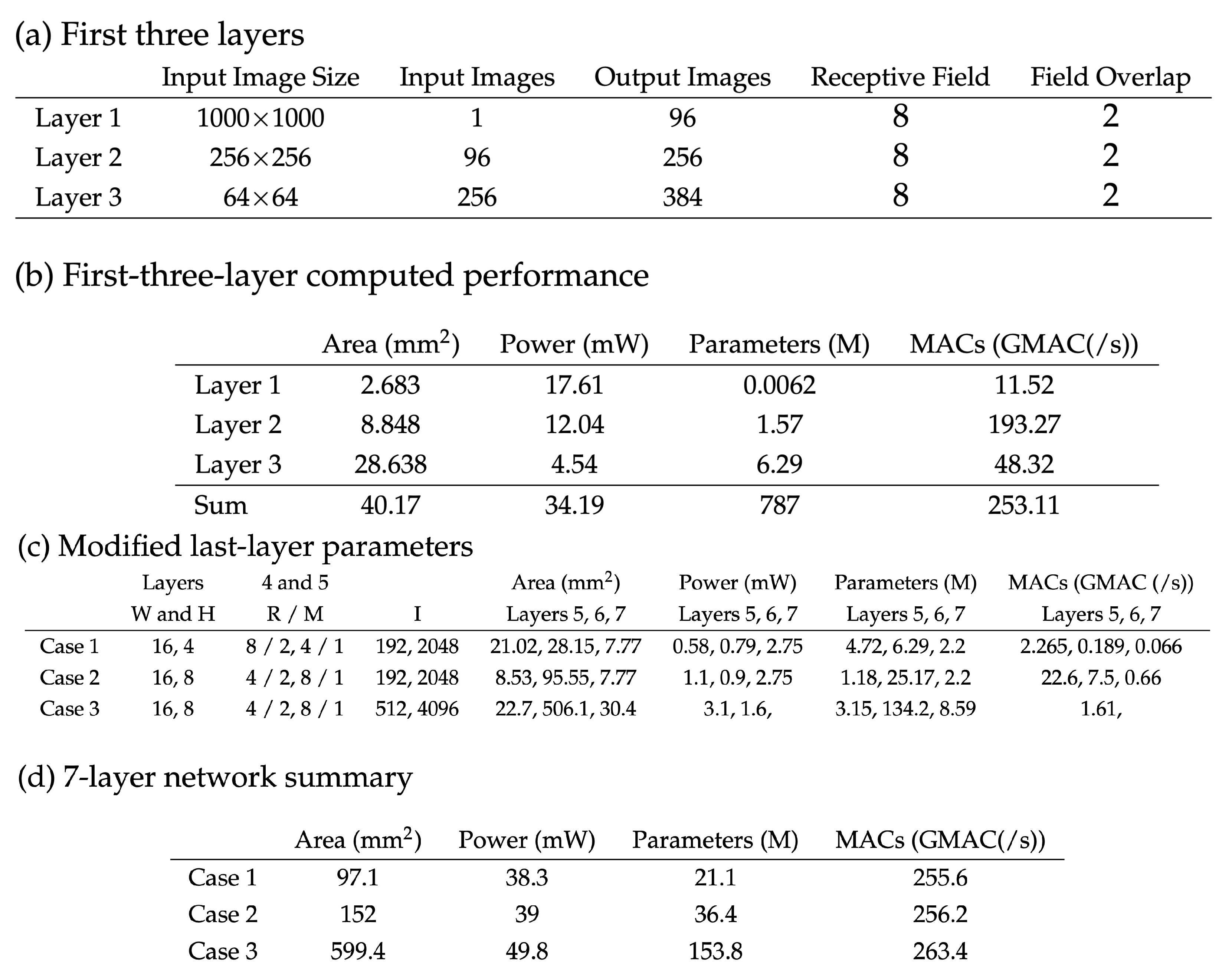
7. Analog ConvNN System Analysis
7.1. Intractable System-Level SPICE Simulations
7.2. Robust Analog Computation in the Presence of Environmental Conditions
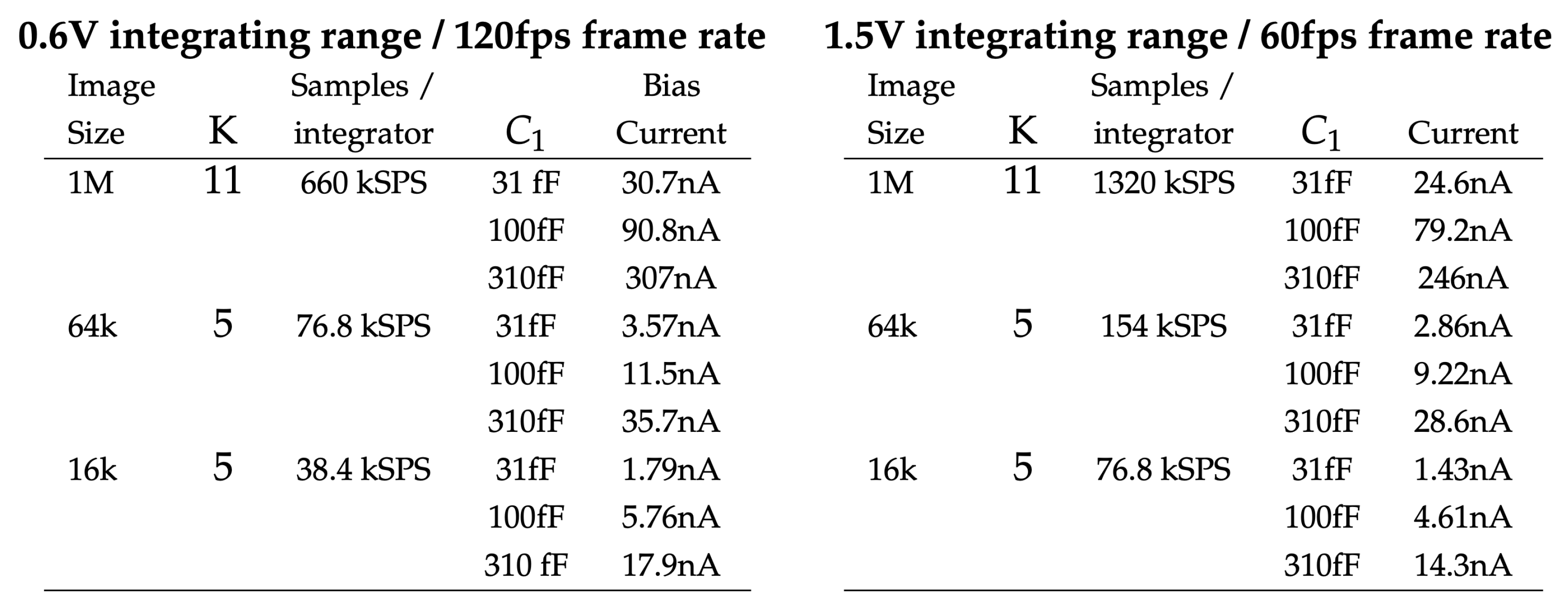
7.3. Detailed System Analysis for a Convolutional Network Layer
- of AWG blocks;
- integrators;
- Diff-pair;
- 2R + (W/K) M shift register blocks.

8. Summary and Discussion
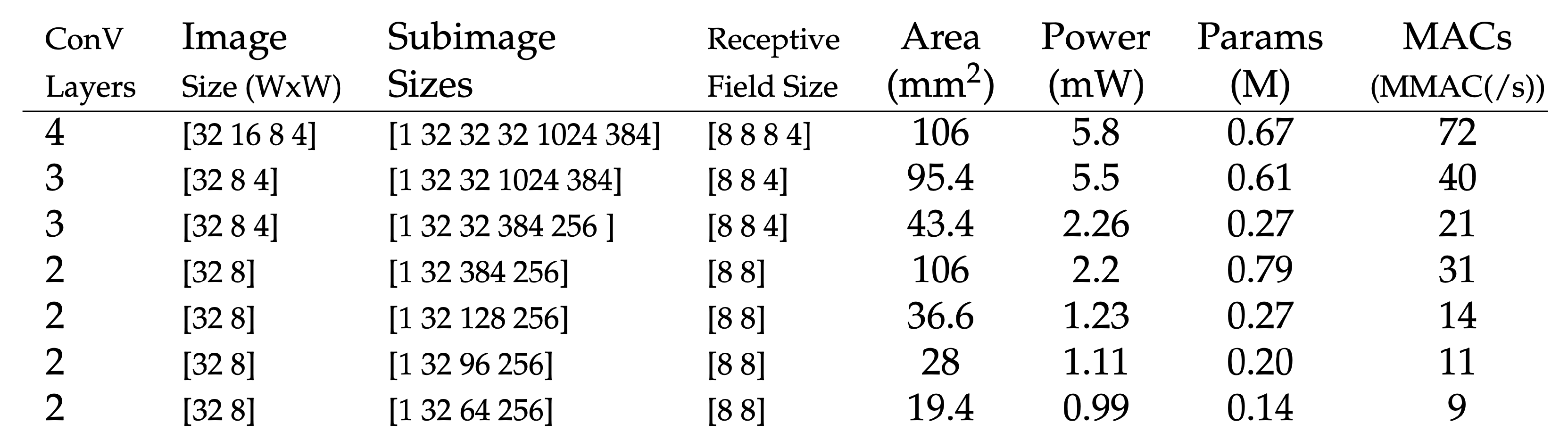
8.1. Opportunities for On-Chip ConvNN Learning
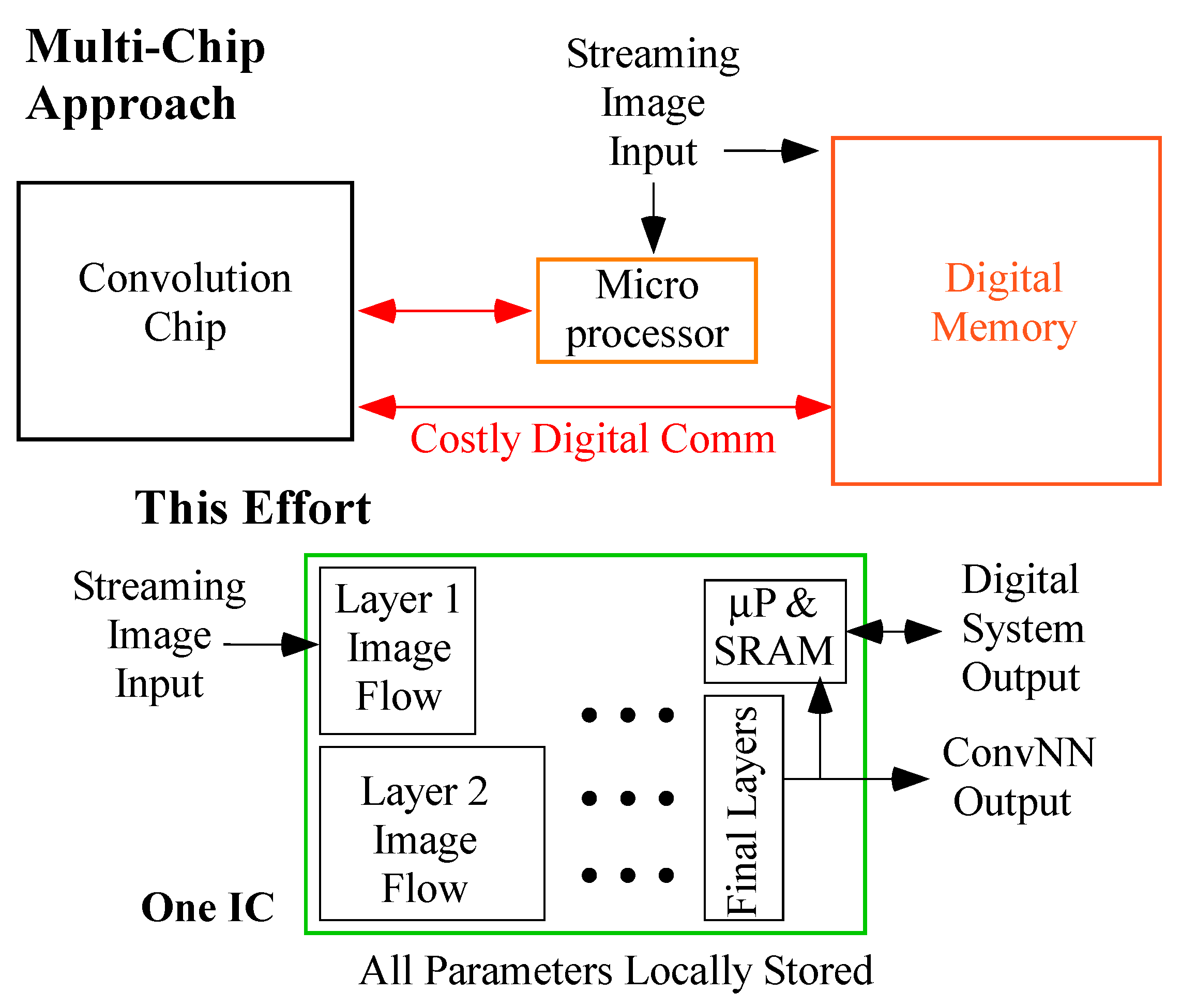
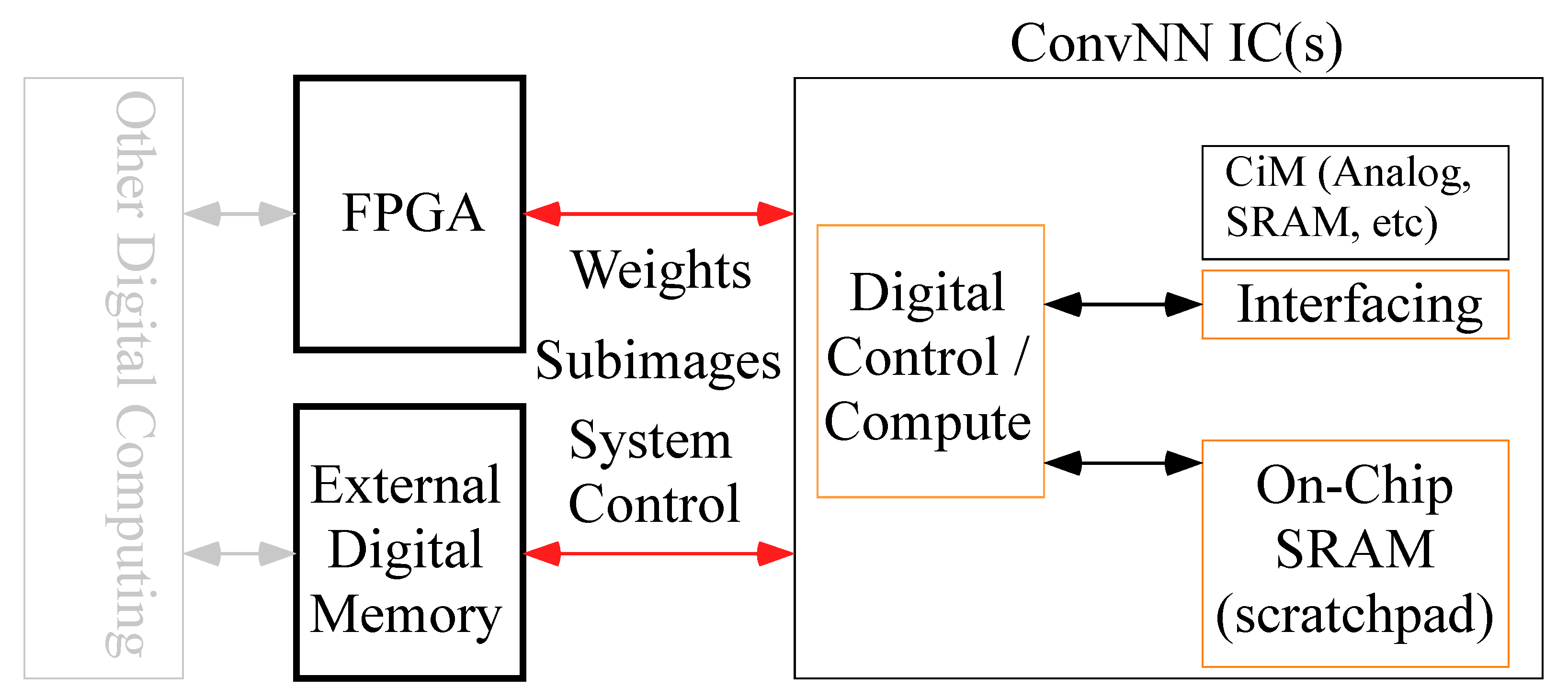
8.2. External Digital Memory ConvNN Architectures
8.3. Comparison with Memory-Efficient Analog ConvNN Architectures
- Analog-Friendly Physical ConvNN Implementations: This discussion starts to formulate what an Analog-Friendly implementation is. Since the start of NN implementations and their potential analog implementations, often the phrasing has involved finding an analog-friendly NN implementation. The convolutional NN structure illustrates the tradeoffs and what works given the current analog implementation, particularly with standard cell frameworks, FPAAs, FGs, and programming.
- Utilize higher-resolution weights: Analog is not imprecise or, at least with FG elements, does not need to be imprecise. Analog multiplication has a resolution. NN computation for VMMs requires the least in analog numerics of many operations, so one expects better digital dynamics, and yet, the analog approach maps well, as expected by analog numerics. Analog can be 1-bit as well as 14-bit with little difference in the inference computation. The original networks were developed as ways to make networks work for digital computation, particularly in FPGAs requiring low precision, compensating for resolution with multiple layers. No surprise approaches allow for low precision, and yet, other approaches are possible.
- Minimize local memory/integrating memory: Memory is larger than a MAC unit, and more memory results in larger amounts of communication.
- Parameters must be local: Minimize communication costs.
- Larger receptive fields over more layers: Parameters are not everything; computation is also important. The summation of coherent signals improves the SNR with multiple items.
- Minimize communication and MAC cost: Analog rapidly decreases the local MAC cost. Minimizing the number of layers helps in this direction.
- These concepts enable not just efficient local computation but also efficient system-level implementations.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hasler, J. Large-Scale Field Programmable Analog Arrays. IEEE Proc. 2020, 108, 1283–1302. [Google Scholar] [CrossRef]
- Hasler, J. Analog Architecture and Complexity Theory to Empowering Ultra-Low Power Configurable Analog and Mixed Mode SoC Systems. J. Low Power Electron. Appl. 2019, 9, 4. [Google Scholar] [CrossRef]
- Mead, C. Neuromorphic electronic systems. Proc. IEEE 1990, 78, 1629–1636. [Google Scholar] [CrossRef]
- Chawla, R.; Bandyopadhyay, A.; Srinivasan, V.; Hasler, P. A 531 nW/MHz, 128×32 current-mode programmable analog vector-matrix multiplier with over two decades of linearity. In Proceedings of the CICC, Orlando, FL, USA, 6 October 2004; p. 651. [Google Scholar]
- Schlottmann, C.; Hasler, P. A highly dense, low power, programmable analog vector-matrix multiplier: The FPAA implementation. IEEE J. Emerg. CAS 2011, 1, 403–411. [Google Scholar] [CrossRef]
- Hasler, J.; Marr, H.B. Finding a roadmap to achieve large neuromorphic hardware systems. Front. Neurosci. 2013, 7, 118. [Google Scholar] [CrossRef]
- Demler, M. Mythic Multiplies in a Flash: Analog In-Memory Computing Eliminates DRAM Read/Write Cycles. Microprocessor Report, 27 August 2018. [Google Scholar]
- Hasler, P.; Akers, L. Implementation of analog neural networks. In Proceedings of the Annual International Conference on Computers and Communications, Scottsdale, AZ, USA, 27–30 March 1991; pp. 32–38. [Google Scholar]
- Hasler, P.; Diorio, C.; Minch, B.A.; Mead, C.A. Single transistor learning synapses. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; pp. 817–824. [Google Scholar]
- Kucic, M.; Hasler, P.; Dugger, J.; Anderson, D. Programmable and adaptive analog filters using arrays of floating-gate circuits. In Proceedings of the Advanced Research in VLSI, Salt Lake City, UT, USA, 14–16 March 2001; pp. 148–162. [Google Scholar]
- Srinivasan, V.; Serrano, G.J.; Gray, J.; Hasler, P. A precision CMOS amplifier using floating-gate transistors for offset cancellation. IEEE JSSC 2007, 42, 280–291. [Google Scholar] [CrossRef]
- Srinivasan, V.; Serrano, G.; Twigg, C.; Hasler, P. Floating-Gate-Based Programmable CMOS Reference. IEEE Trans. CAS I 2008, 55, 3448–3456. [Google Scholar] [CrossRef]
- Kim, S.; Hasler, J.; George, S. Integrated Floating-Gate Programming Environment for System-Level ICs. IEEE Trans. VLSI 2016, 24, 2244–2252. [Google Scholar] [CrossRef]
- Shah, S.; Hasler, J. Tuning of Multiple Parameters with a BIST System. J. Low Power Electron. Appl. 2017, 64, 1772–1780. [Google Scholar] [CrossRef]
- Hasler, J.; Ayyappan, P.R.; Ige, A.; Mathews, P.O. A 130 nm CMOS Programmable Analog Standard Cell Library. IEEE Circuits Syst. I 2024, 71, 2497–2510. [Google Scholar]
- Mathews, P.O.; Ayyappan, P.R.; Ige, A.; Bhattacharyya, S.; Yang, L.; Hasler, J. A 65nm and 130nm CMOS programmable analog standard cell library for scalable system synthesis. In Proceedings of the IEEE Custom Integrated Circuits Conference, Denver, CO, USA, 21–24 April 2024; pp. 1–2. [Google Scholar]
- Hasler, J.; Wang, H. A Fine-Grain FPAA fabric for RF + Baseband. In Proceedings of the GOMAC, St. Louis, MO, USA, 23–26 March 2015. [Google Scholar]
- Hasler, J. Scalable Analog Standard Cells for Mixed-Signal Processing and Computing. In Proceedings of the GOMAC, Charleston, SC, USA, 18–21 March 2024. [Google Scholar]
- Hasler, J. The Potential of SoC FPAAs for Emerging Ultra-Low-Power Machine Learning. J. Low Power Electron. Appl. 2022, 12, 33. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. Hum. Neurobiol. 1985, 4, 219–227. [Google Scholar]
- Niebur, E.; Koch, C. A model for the neuronal implementation of selective visual attention based on temporal correlation among neurons. J. Comput. Neurosci. 1994, 1, 141–158. [Google Scholar] [CrossRef]
- Tsotsos, J.K.; Culhane, S.M.; Kei Wai, W.Y.; Lai, Y.; Davis, N.; Nuflo, F. Modeling visual attention via selective tuning. Artif. Intell. 1995, 78, 507–545, Special Volume on Computer Vision. [Google Scholar] [CrossRef]
- Niebur, E.; Koch, C. Control of Selective Visual Attention: Modeling the “Where” Pathway. In Proceedings of the Advances in Neural Information Processing Systems; Touretzky, D., Mozer, M., Hasselmo, M., Eds.; MIT Press: Cambridge, MA, USA, 1996; Volume 8, pp. 802–808. [Google Scholar]
- Horiuchi, T.; Morris, T.; Koch, C.; DeWeerth, S. Analog VLSI Circuits for Attention-Based, Visual Tracking. In Proceedings of the Advances in Neural Information Processing Systems; Mozer, M., Jordan, M., Petsche, T., Eds.; MIT Press: Cambridge, MA, USA, 1996; Volume 9. [Google Scholar]
- Morris, T.; Horiuchi, T.; DeWeerth, S. Object-based selection within an analog VLSI visual attention system. IEEE Trans. Circuits Syst. II 1998, 45, 1564–1572. [Google Scholar] [CrossRef]
- Morris, T.; Wilson, C.; DeWeerth, S. An analog VLSI focal-plane processing array that performs object-based attentive selection. In Proceedings of the Midwest Symposium on Circuits and Systems, Sacramento, CA, USA, 3–6 August 1997; Volume 1, pp. 43–46. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Horiuchi, T.; Niebur, E. Conjunction Search Using a 1-D, Analog VLSI based, Attentional Search/Tracking Chip. In Proceedings of the Advanced Research in VLSI; DeWeerth, S.P., Wills, D.S., Eds.; IEEE Computer Society Press: Los Alamitos, CA, USA, 1999; pp. 276–290. [Google Scholar]
- Wilson, C.; Morris, T.; DeWeerth, S. A two-dimensional, object-based analog VLSI visual attention system. In Proceedings of the 20th Anniversary Conference on Advanced Research in VLSI, Atlanta, GA, USA, 21–24 March 1999; pp. 291–308. [Google Scholar]
- Itti, L.; Koch, C. A saliency-based search mechanism for overt and covert shifts of visual attention. Vis. Res. 2000, 40, 1489–1506. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C. Computational Modeling of Visual Attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef]
- Itti, L. Automatic Foveation for Video Compression Using a Neurobiological Model of Visual Attention. IEEE Trans. Image Process. 2024, 13, 1304–1318. [Google Scholar] [CrossRef]
- Dziemian, S.; Bujia, G.; Prasse, P.; Bara?czuk-Turska, Z.; Jager, L.; Kamienkowski, J.; Langer, N. Saliency Models Reveal Reduced Top-Down Attention in Attention-Deficit/Hyperactivity Disorder: A Naturalistic Eye-Tracking Study. JAACAP Open 2024, 3, 192–204. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H. Cortical neurobiology: A slanted historical perspective. Annu. Rev. Neurosci. 1982, 5, 363–370. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Brain and Visual Perception: The Story of a 25-Year Collaboration; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Alonso, J.M. My recollections of Hubel and Wiesel and a brief review of functional circuitry in the visual pathway. J. Physiol. 2009, 587, 2783–2790. [Google Scholar] [CrossRef] [PubMed]
- Barlow, H. David Hubel and Torsten Wiesel: Their contributions towards understanding the primary visual cortex. Trends Neurosci. 1982, 5, 145–152. [Google Scholar] [CrossRef]
- Wurtz, R.H. Recounting the impact of Hubel and Wiesel. J. Physiol. 2009, 587, 2817–2823. [Google Scholar] [CrossRef]
- Wiesel, T.N.; Hubel, D.H. Effects of visual deprivation on morphology and physiology of cells in the cat’s lateral geniculate body. J. Neurophysiol. 1963, 26, 978–993. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of cells in striate cortex of very young, visually inexperienced kittens. J. Neurophysiol. 1963, 26, 994–1002. [Google Scholar] [CrossRef]
- Wiesel, T.N.; Hubel, D.H. Single-cell responses in striate cortex of kittens deprived of vision in one eye. J. Neurophysiol. 1963, 26, 1003–1017. [Google Scholar] [CrossRef]
- Wiesel, T.N.; Hubel, D.H. Comparison of the effects of unilateral and bilateral eye closure on cortical unit responses in kittens. J. Neurophysiol. 1965, 28, 1029–1040. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Binocular interaction in striate cortex of kittens reared with artificial squint. J. Neurophysiol. 1965, 28, 1041–1059. [Google Scholar] [CrossRef]
- Wiesel, T.N.; Hubel, D.H. Extent of recovery from the effects of visual deprivation in kittens. J. Neurophysiol. 1965, 28, 1060–1072. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Brain Mechanisms of Vision. Sci. Am. 1979, 241, 150–163. [Google Scholar] [CrossRef] [PubMed]
- Linsker, R. From basic network principles to neural architecture: Emergence of spatial-opponent cells. Proc. Natl. Acad. Sci. USA 1986, 83, 7508–7512. [Google Scholar] [CrossRef]
- Linsker, R. From basic network principles to neural architecture: Emergence of orientation-selective cells. Proc. Natl. Acad. Sci. USA 1986, 83, 8390–8394. [Google Scholar] [CrossRef]
- Linsker, R. Self-Organization in a Perceptual Network. IEEE Comput. 1988, 21, 105–117. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1–10. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Ho-Phuoc, T. CIFAR10 to Compare Visual Recognition Performance between Deep Neural Networks and Humans. arXiv 2018, arXiv:abs/1811.07270. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]
- Lang, C.; Braun, A.; Schillingmann, L.; Haug, K.; Valada, A. Self-Supervised Representation Learning From Temporal Ordering of Automated Driving Sequences. IEEE Robot. Autom. Lett. 2024, 9, 2582–2589. [Google Scholar] [CrossRef]
- Aghdam, H.H.; Gonzalez-Garcia, A.; Weijer, J.v.d.; López, A.M. Active learning for deep detection neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3672–3680. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4905–4913. [Google Scholar]
- Martinez, L.; Wang, Q.; Reid, R.C.; Pillai, C.; Alonso, J.M.; Sommer, F.; Hirsch, J. Receptive field structure varies with layer in the primary visual cortex. Nat. Neurosci. 2005, 8, 372–379. [Google Scholar] [CrossRef] [PubMed]
- Koziol, S. Reconfigurable Analog Circuits for Autonomous Vehicles. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, Georgia, 2013. [Google Scholar]
- Hasler, J. Starting Framework for Analog Numerical Analysis for Energy Efficient Computing. J. Low Power Electron. Appl. 2017, 7, 17. [Google Scholar] [CrossRef]
- Hasler, J.; Hao, C. Programmable Analog System Benchmarks Leading to Efficient Analog Computation Synthesis. ACM Trans. Reconfigurable Technol. Syst. 2024, 17, 1–25. [Google Scholar] [CrossRef]
- Hasler, J.; Natarajan, A. Continuous-time, Configurable Analog Linear System Solutions with Transconductance Amplifiers. IEEE Circuits Syst. I 2021, 68, 765–775. [Google Scholar] [CrossRef]
- Ige, A.; Yang, L.; Yang, H.; Hasler, J.; Hao, C. Analog System High-level Synthesis for Energy-Efficient Reconfigurable Computing. J. Low Power Electron. Appl. 2023, 13, 58. [Google Scholar] [CrossRef]
- Mathews, P.O.; Ayyappan, P.R.; Ige, A.; Bhattacharyya, S.; Yang, L.; Hasler, J. A 65nm CMOS Analog Programmable Standard Cell Library for Mixed-Signal Computing. IEEE Trans. VLSI 2024, 32, 1830–1840. [Google Scholar] [CrossRef]
- George, S.; Kim, S.; Shah, S.; Hasler, J.; Collins, M.; Adil, F.; Wunderlich, R.; Nease, S.; Ramakrishnan, S. A Programmable and Configurable Mixed-Mode FPAA SoC. IEEE Trans. VLSI 2016, 24, 2253–2261. [Google Scholar] [CrossRef]
- Dudek, P. Implementation of SIMD vision chip with 128×128 array of analogue processing elements. In Proceedings of the 2005 IEEE International Symposium on Circuits and Systems, Kobe, Japan, 23–26 May 2005; Volume 6, pp. 5806–5809. [Google Scholar]
- Ige, A.; Hasler, J. Analog System Synthesis for FPAAs and Custom Analog IC Design. In Proceedings of the Design, Automation, and Test in Europe Conference, Lyon, France, 31 March–2 April 2025. [Google Scholar]
- Hasler, P.; Dugger, J. An analog floating-gate node for supervised learning. IEEE Trans. Circuits Syst. I 2005, 52, 834–845. [Google Scholar] [CrossRef]
- Kauderer-Abrams, E.; Gilbert, A.; Voelker, A.; Benjamin, B.; Stewart, T.; Boahen, K. A Population-Level Approach to Temperature Robustness in Neuromorphic Systems. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Harrison, R.R.; Bragg, J.; Hasler, P.; Minch, B.A.; Deweerth, S.P. A CMOS programmable analog memory-cell array using floating-gate circuits. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process. 2001, 48, 4–11. [Google Scholar] [CrossRef]
- Sarpeshkar, R.; Delbruck, T.; Mead, C. White noise in MOS transistors and resistors. IEEE Circuits Devices Mag. 1993, 9, 23–29. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Thompson, N.C.; Greenewald, K.; Lee, K.; Manso, G.F. Deep learning’s diminishing returns: The cost of improvement is becoming unsustainable. IEEE Spectr. 2021, 58, 50–55. [Google Scholar] [CrossRef]
- Hoff, M.; Widrow, B. Adaptive switching circuits. In Proceedings of the 1960 IRE WESCON Convention Recor, Los Angeles, CA, USA, 23–26 August 1960; pp. 96–104. [Google Scholar]
- Ljung, L. Convergence of an adaptive filter algorithm. Int. J. Control. 1978, 27, 673–693. [Google Scholar] [CrossRef]
- Bell, A.; Sejnowski, T. An Information-Maximization Approach to Blind Separation and Blind Deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef] [PubMed]
- Herault, J.; Jutten, C. Space or time adaptive signal processing by neural network models. AIP Conf. Proc. 1986, 151, 206–211. [Google Scholar]
- Vittoz, E.; Arreguit, X. CMOS Integration of Herault-Jutten Cells for Separation of Sources. In Analog VLSI Implementation of Neural Systems; Springer: Boston, MA, USA, 1989. [Google Scholar]
- Hasler, P.; Akers, L. Circuit implementation of a trainable neural network using the generalized Hebbian algorithm with supervised techniques. In Proceedings of the International Joint Conference on Neural Networks, Baltimore, MD, USA, 7–11 June 1992; Volume 1, pp. 160–165. [Google Scholar]
- Cohen, M.; Andreou, A. Current-mode subthreshold MOS implementation of the Herault-Jutten autoadaptive network. IEEE J. Solid-State Circuits 1992, 27, 714–727. [Google Scholar] [CrossRef]
- Cohen, M.; Andreou, A. Analog CMOS integration and experimentation with an autoadaptive independent component analyzer. EEE Trans. Circuits Syst. II Analog Digit. Signal Process. 1995, 42, 65–77. [Google Scholar] [CrossRef]
- Gharbi, A.; Salam, F. Implementation and test results of a chip for the separation of mixed signals. In Proceedings of the ISCAS’95—International Symposium on Circuits and Systems, Washington, DC, USA, 30 April–3 May 1995; Volume 1, pp. 271–274. [Google Scholar]
- Cichocki, A.; Unbehauen, R. Robust neural networks with on-line learning for blind identification and blind separation of sources. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1996, 43, 894–906. [Google Scholar] [CrossRef]
- Yao, E.; Hussain, S.; Basu, A.; Huang, G. Computation using mismatch: Neuromorphic extreme learning machines. In Proceedings of the 2013 IEEE BioCAS, Rotterdam, The Netherlands, 31 October–2 November 2013; pp. 294–297. [Google Scholar]
- Patil, A.; Shen, S.; Yao, E.; Basu, A. Hardware Architecture for Large Parallel Array of Random Feature Extractors applied to Image Recognition. arXiv 2015, arXiv:1512.07783. [Google Scholar] [CrossRef]
- Lefebvre, M.; Bol, D. MANTIS: A Mixed-Signal Near-Sensor Convolutional Imager SoC Using Charge-Domain 4b-Weighted 5-to-84-TOPS/W MAC Operations for Feature Extraction and Region-of-Interest Detection. IEEE J. Solid-State Circuits 2025, 60, 934–948. [Google Scholar] [CrossRef]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. In Proceedings of the ACM/IEEE International Symposium on Computer Architecture, Seoul, Republic of Korea, 18–22 June 2016; pp. 14–26. [Google Scholar]
- Seo, J.O.; Seok, M.; Cho, S. A 44.2-TOPS/W CNN Processor with Variation-Tolerant Analog Datapath and Variation Compensating Circuit. IEEE J. Solid-State Circuits 2024, 59, 1603–1611. [Google Scholar] [CrossRef]
- Bankman, D.; Yang, L.; Moons, B.; Verhelst, M.; Murmann, B. An always-on 3.8 μJ/86% CIFAR-10 mixed-signal binary CNN processor with all memory on chip in 28nm CMOS. In Proceedings of the IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 11–15 February 2018; pp. 222–224. [Google Scholar]
- Kneip, A.; Lefebvre, M.; Verecken, J.; Bol, D. IMPACT: A 1-to-4b 813-TOPS/W 22-nm FD-SOI Compute-in-Memory CNN Accelerator Featuring a 4.2-POPS/W 146-TOPS/mm2 CIM-SRAM with Multi-Bit Analog Batch-Normalization. IEEE J. Solid-State Circuits 2023, 58, 1871–1884. [Google Scholar] [CrossRef]
- Desoli, G.; Chawla, N.; Boesch, T.; Avodhyawasi, M.; Rawat, H.; Chawla, H.; Abhijith, V.; Zambotti, P.; Sharma, A.; Cappetta, C.; et al. 16.7 A 40-310TOPS/W SRAM-Based All-Digital Up to 4b In-Memory Computing Multi-Tiled NN Accelerator in FD-SOI 18nm for Deep-Learning Edge Applications. In Proceedings of the 2023 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 19–23 February 2023; pp. 260–262. [Google Scholar]
- Yin, S.; Jiang, Z.; Kim, M.; Gupta, T.; Seok, M.; Seo, J.S. Vesti: Energy-Efficient In-Memory Computing Accelerator for Deep Neural Networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 48–61. [Google Scholar] [CrossRef]
- Boahen, K.A. Point-to-point connectivity between neuromorphic chips using address events. IEEE Trans. Circuits Syst. II 2000, 47, 416–434. [Google Scholar] [CrossRef]
- Choi, T.; Merolla, P.; Arthur, J.; Boahen, K.; Shi, B. Neuromorphic implementation of orientation hypercolumns. IEEE Trans. Circuits Syst. I Regul. Pap. 2005, 52, 1049–1060. [Google Scholar] [CrossRef]
- Camunas-Mesa, L.; Zamarreno-Ramos, C.; Linares-Barranco, A.; Acosta-Jimenez, A.J.; Serrano-Gotarredona, T.; Linares-Barranco, B. An Event-Driven Multi-Kernel Convolution Processor Module for Event-Driven Vision Sensors. IEEE J. Solid-State Circuits 2012, 47, 504–517. [Google Scholar] [CrossRef]
- Perez-Carrasco, J.A.; Zhao, B.; Serrano, C.; Acha, B.; Serrano-Gotarredona, T.; Chen, S.; Linares-Barranco, B. Mapping from Frame-Driven to Frame-Free Event-Driven Vision Systems by Low-Rate Rate Coding and Coincidence Processing–Application to Feedforward ConvNets. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2706–2719. [Google Scholar] [CrossRef]
- Posch, C.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Delbruck, T. Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras With Spiking Output. Proc. IEEE 2014, 102, 1470–1484. [Google Scholar] [CrossRef]
- Serrano-Gotarredona, T.; Linares-Barranco, B. Poker-DVS and MNIST-DVS. Their History, How They Were Made, and Other Details. Front. Neurosci. 2015, 9, 481. [Google Scholar] [CrossRef]
- Schlottmann, C.; Shapero, S.; Nease, S.; Hasler, P. A Digitally-Enhanced Reconfigurable Analog Platform for Low-Power Signal Processing. IEEE JSSC 2012, 47, 2174–2184. [Google Scholar] [CrossRef]
- Antolini, A.; Lico, A.; Zavalloni, F.; Scarselli, E.F.; Gnudi, A.; Torres, M.L.; Canegallo, R.; Pasotti, M. A Readout Scheme for PCM-Based Analog In-Memory Computing with Drift Compensation Through Reference Conductance Tracking. IEEE Open J. Solid-State Circuits Soc. 2024, 4, 69–82. [Google Scholar] [CrossRef]
- Wan, W.; Kubendran, R.; Schaefer, C.; Eryilmaz, S.B.; Zhang, W.; Wu, D.; Deiss, S.; Raina, P.; Qian, H.; Gao, B.; et al. A compute-in-memory chip based on resistive random-access memory. Nature 2022, 608, 504–512. [Google Scholar] [CrossRef] [PubMed]
- Ozalevli, E.; Huang, W.; Hasler, P.; Anderson, D.V. A Reconfigurable Mixed-Signal VLSI Implementation of Distributed Arithmetic Used for Finite-Impulse Response Filtering. IEEE Trans. Circuits Syst. I 2008, 55, 510–521. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasler, J.; Ayyappan, P.R. An Analog Architecture and Algorithm for Efficient Convolutional Neural Network Image Computation. J. Low Power Electron. Appl. 2025, 15, 37. https://doi.org/10.3390/jlpea15030037
Hasler J, Ayyappan PR. An Analog Architecture and Algorithm for Efficient Convolutional Neural Network Image Computation. Journal of Low Power Electronics and Applications. 2025; 15(3):37. https://doi.org/10.3390/jlpea15030037
Chicago/Turabian StyleHasler, Jennifer, and Praveen Raj Ayyappan. 2025. "An Analog Architecture and Algorithm for Efficient Convolutional Neural Network Image Computation" Journal of Low Power Electronics and Applications 15, no. 3: 37. https://doi.org/10.3390/jlpea15030037
APA StyleHasler, J., & Ayyappan, P. R. (2025). An Analog Architecture and Algorithm for Efficient Convolutional Neural Network Image Computation. Journal of Low Power Electronics and Applications, 15(3), 37. https://doi.org/10.3390/jlpea15030037