1. Introduction
Glaucoma remains a leading cause of irreversible blindness worldwide, affecting over 90 million individuals globally [
1], with projections indicating an increase to 111.8 million people by 2040 [
2,
3]. The progressive nature of this optic nerve degenerative condition, coupled with its asymptomatic presentation until significant vision loss occurs, underscores the critical importance of early detection and intervention [
4,
5,
6].
Traditional diagnostic methods, including intraocular pressure measurement, optical coherence tomography (OCT), and visual field tests, while effective [
7,
8], present significant limitations in terms of accessibility, cost, and the requirement for skilled interpretation [
9]. These challenges are particularly pronounced in resource-constrained settings, where access to specialized equipment and trained professionals is limited [
10,
11]. Furthermore, the subjective nature of clinical evaluations introduces considerable inter- and intra-observer variability, potentially affecting diagnostic accuracy and consistency [
12,
13].
Recent advances in artificial intelligence (AI) and machine learning (ML) have shown promising potential in addressing these challenges through automated glaucoma detection systems, deeming it a valuable tool for screening, diagnosing, and referring patients with ophthalmologic concerns [
14,
15,
16,
17,
18,
19]. For example, algorithms such as EyeArt (from Eyenuk), AEYEDS (from AEYE Health), and LumineticsCore (from Digital Diagnostics, formerly IDx-DR) have demonstrated clinical-grade performance in detecting diabetic retinopathy from fundus images and have been FDA-approved for clinical use in DR screening [
20]. However, no such FDA-approved diagnostic device currently exists for the detection or staging of glaucoma.
This gap is particularly important given the structural changes that precede functional loss in glaucoma. Morphological indicators of early glaucoma can include an increased cup-to-disc ratio (CDR), thinning of the neuro-retinal rim (NRR), and/or alterations in optic nerve head (ONH). Though these signs may prove critical in early glaucoma detection, they are often overlooked on routine manual inspections and may go unnoticed until patients experience symptoms. However, these features are visually accessible on color fundus photography, forming a promising foundation for AI-based detection systems trained using deep learning architectures like convolutional neural networks (CNNs) [
21]. Additionally, while traditional glaucoma risk assessment has focused on intraocular pressure and optic nerve head morphology, recent studies have highlighted the role of systemic features in predicting disease progression, particularly rapid retinal nerve fiber layer (RNFL) thinning [
22].
Recent studies have demonstrated that various ML architectures, including CNNs and deep neural networks (DNNs), have demonstrated remarkable capabilities in analyzing retinal fundus images for glaucomatous morphology [
23,
24,
25]. These architectures, often pretrained on large-scale image repositories, enable feature extraction and classification in an end-to-end fashion. However, deep learning models often require significant data volumes and may suffer from poor interpretability or limited generalization to new clinical settings [
26].
In contrast, classical ML models, such as Naïve Bayes and Support Vector Machines, depend more heavily on well-curated, lower-dimensional features. In such settings, feature selection and discretization techniques can dramatically affect model performance. For instance, recent studies have demonstrated that feature selection methods can significantly enhance classification accuracy by refining feature boundaries and improving class separability, particularly in the context of heart disease prediction models [
27]. Additionally, bio-inspired optimization algorithms like the Cuttlefish Algorithm have proven effective in selecting optimal feature subsets to reduce dimensionality and boost learning efficiency in complex domains [
28]. These approaches highlight the importance of intelligent preprocessing, even when working with features derived from deep learning backbones.
Despite these advances, several critical challenges persist in the development and implementation of ML-based glaucoma detection systems. These include issues related to data heterogeneity, model interpretability, and the tendency for overfitting when dealing with diverse datasets [
14,
29]. In the case of integrated or ensemble methods, overfitting can also be mitigated by adjusting the architecture of the component networks, such as modifying the number or structure of neurons, to improve generalization performance. Additionally, the limited availability of high-quality labeled data and the need for robust cross-dataset validation pose significant challenges to developing clinically applicable solutions [
30,
31,
32].
In response to these challenges and aligned with FDA guidelines for Good Machine Learning Practice (GMLP) [
33,
34], our study presents an evaluation of three distinct ML architectures for binary glaucoma detection: CNNs, DNNs, and a PyCaret-based automated ensemble. We specifically address the critical aspect of clinical applicability through cross-dataset validation, utilizing two diverse datasets, enabling us to assess the models’ generalization capabilities and robustness in real-world clinical scenarios.
The primary objectives of this study are to (1) evaluate the performance and reliability of different ML architectures in binary glaucoma detection, (2) assess the models’ generalization capabilities through cross-dataset validation, (3) determine the clinical applicability of these models in accordance with FDA guidelines, and (4) compare the effectiveness of various ML approaches in maintaining consistent performance across different subdatasets.
This research contributes to the growing body of knowledge in automated glaucoma detection by addressing key limitations identified in recent systematic reviews and meta-analyses, particularly regarding model generalizability and clinical validation. Our findings aim to provide insights for the development of more robust and clinically applicable ML solutions for glaucoma detection.
3. Results
The results of the study are presented in
Table 1 and
Figure 2 and
Figure 3, which summarize the performance of three ML models, i.e., the CNN, DNN, and Light Gradient Boosting Machine (LGBM), across training, validation, test, and cross-dataset evaluation scenarios. The LGBM was selected as the highest-performing model from the 14 classifiers tested using PyCaret.
Table 1 provides confusion matrices with row-wise percentages for each model and dataset, alongside key performance metrics, including accuracy, precision, recall, and F1-score. The confusion matrices illustrate the classification performance by showing the distribution of true positives, false positives, true negatives, and false negatives, with percentages calculated relative to the total number of samples in each row.
The performance metrics in
Table 1 reveal that the DNN model achieved the highest accuracy (87.0%) on the training dataset, followed by the CNN (79.3%) and LGBM (100.0%, due to overfitting). However, the DNN consistently outperformed the other models across validation and test datasets, with accuracy values of 80.1% and 79.2%, respectively. The LGBM model demonstrated perfect performance on the training dataset (due to overfitting) but exhibited a decline in generalization, as evidenced by lower accuracy and F1-scores on the validation and test datasets. The CNN model showed moderate performance across all datasets, with accuracy values ranging from 79.3% on the training dataset to 72.9% on the cross-dataset evaluation.
Figure 2 provides a visual comparison of the performance metrics (accuracy, precision, recall, and F1-score) for glaucoma detection using the three ML models across the four datasets. The figure highlights clear trends in model performance, illustrating the relative strengths and weaknesses of each model. A properly trained ML model is expected to exhibit a slight and continuous decline in these metrics when transitioning from the training dataset to validation, test, and cross-dataset evaluations, indicative of appropriate generalization to unseen data.
In this context, the CNN model demonstrates the most stable and gradual generalization behavior, with accuracy decreasing consistently from 79.3% (training) to 72.9% (cross-dataset evaluation). In contrast, the DNN model, despite achieving higher initial performance (87.0% accuracy in training), exhibits a relatively steeper decline to 80.1%, 79.2%, and finally 72.7% accuracy in subsequent datasets, indicating slightly less stable generalization. The LGBM model shows an excessively steep drop from perfect accuracy (100%) on the training dataset, which is symptomatic of significant overfitting and poor generalization. Such sharp declines or erratic fluctuations in performance across datasets are indicative of inadequately trained or overfitted machine learning models.
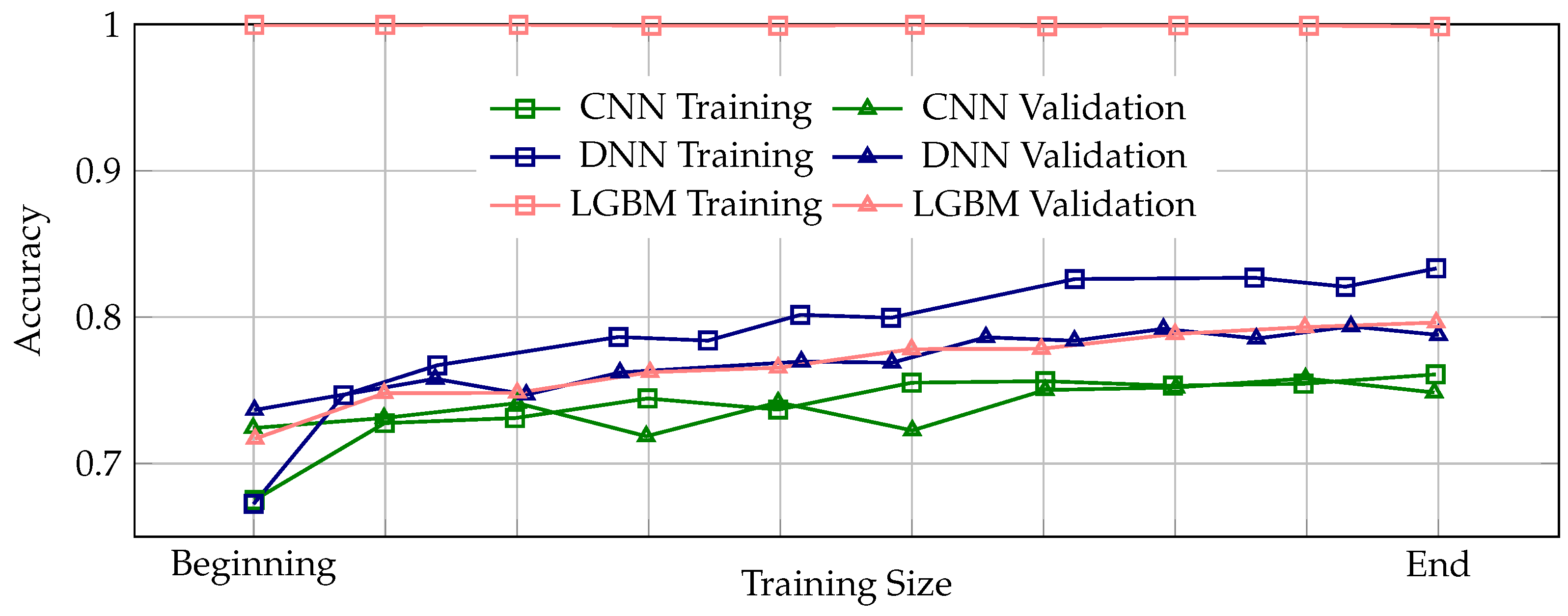
Figure 3 presents the learning curves illustrating the progression of training and validation accuracy across the entire training process for the CNN, DNN, and LGBM models. Learning curves are essential for assessing the stability and reliability of the training process, as they reveal how well a model learns from the data and generalizes to unseen samples. A properly trained model is expected to exhibit a consistent pattern where validation accuracy remains slightly below training accuracy throughout training, indicating stable and appropriate generalization. Among the three models, the DNN demonstrates the most stable and appropriate generalization behavior, with validation accuracy consistently tracking slightly below the training accuracy across all epochs. In contrast, the CNN model shows instances where validation accuracy intermittently rises above the training accuracy, suggesting potential issues in the training process, which may lead to unreliable generalization performance. The LGBM model exhibits perfect training accuracy from the beginning to the end of training, accompanied by a significant and persistent gap between training and validation accuracy, clearly indicative of severe overfitting and poor generalization capability.
Overall, the combined insights from
Figure 2 and
Figure 3 reinforce the conclusion that the DNN model provides the best balance between high performance and stable generalization, while the CNN model offers moderate but consistent performance. The LGBM model, despite its initially high training accuracy, suffers from severe overfitting, limiting its practical clinical utility. These visualizations underscore the importance of evaluating both absolute performance metrics and training dynamics to ensure robust and clinically applicable ML models for glaucoma detection.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}