
Multihead Average Pseudo-Margin Learning for Disaster Tweet Classification




Abstract
1. Introduction
- 1.
- We are the first to adapt and compare multiple semi-supervised learning methods on multimodal disaster tweet classification tasks.
- 2.
- We introduce a new SSL method by extending the Multihead Co-Training framework with self-adaptive thresholds based on the Average Pseudo-Margins score.
- 3.
- We achieve state-of-the-art results on both the Humanitarian as well as the Informative CrisisMMD [2] classification tasks, and we prove the feasibility of our approach in low-resource settings.
- 4.
- We provide an in-depth analysis of the training process and failure cases for the baseline SSL methods in the context of highly imbalanced classes.
2. Related Work
2.1. Semi-Supervised Learning
2.2. Disaster Tweet Classification
3. Methods
3.1. Baseline Supervised Models
3.2. Baseline Semi-Supervised Methods
3.2.1. FixMatch for Multimodal Data
3.2.2. FixMatch LS
3.2.3. FlexMatch
3.2.4. FreeMatch
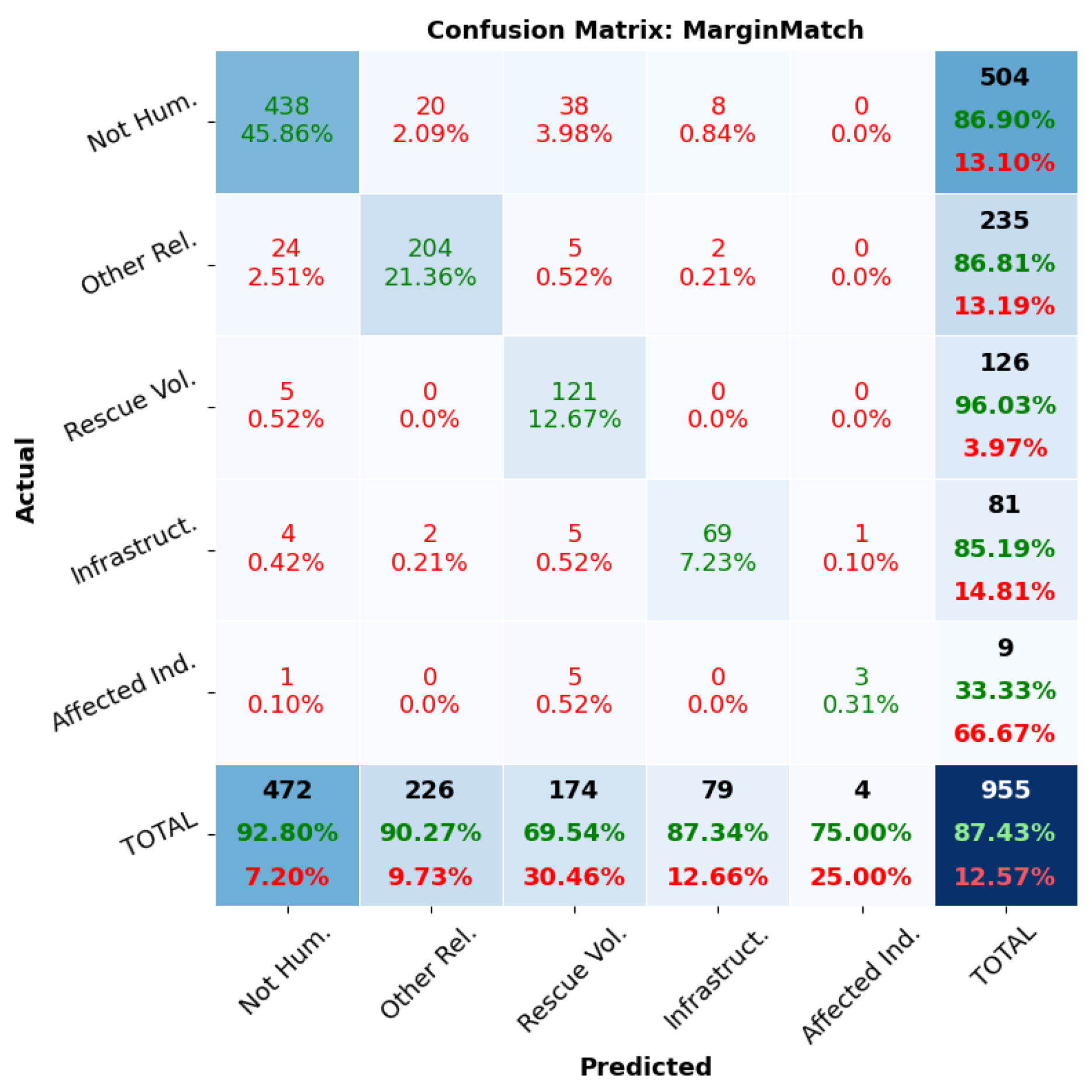
3.2.5. MarginMatch
3.2.6. Multihead Co-Training
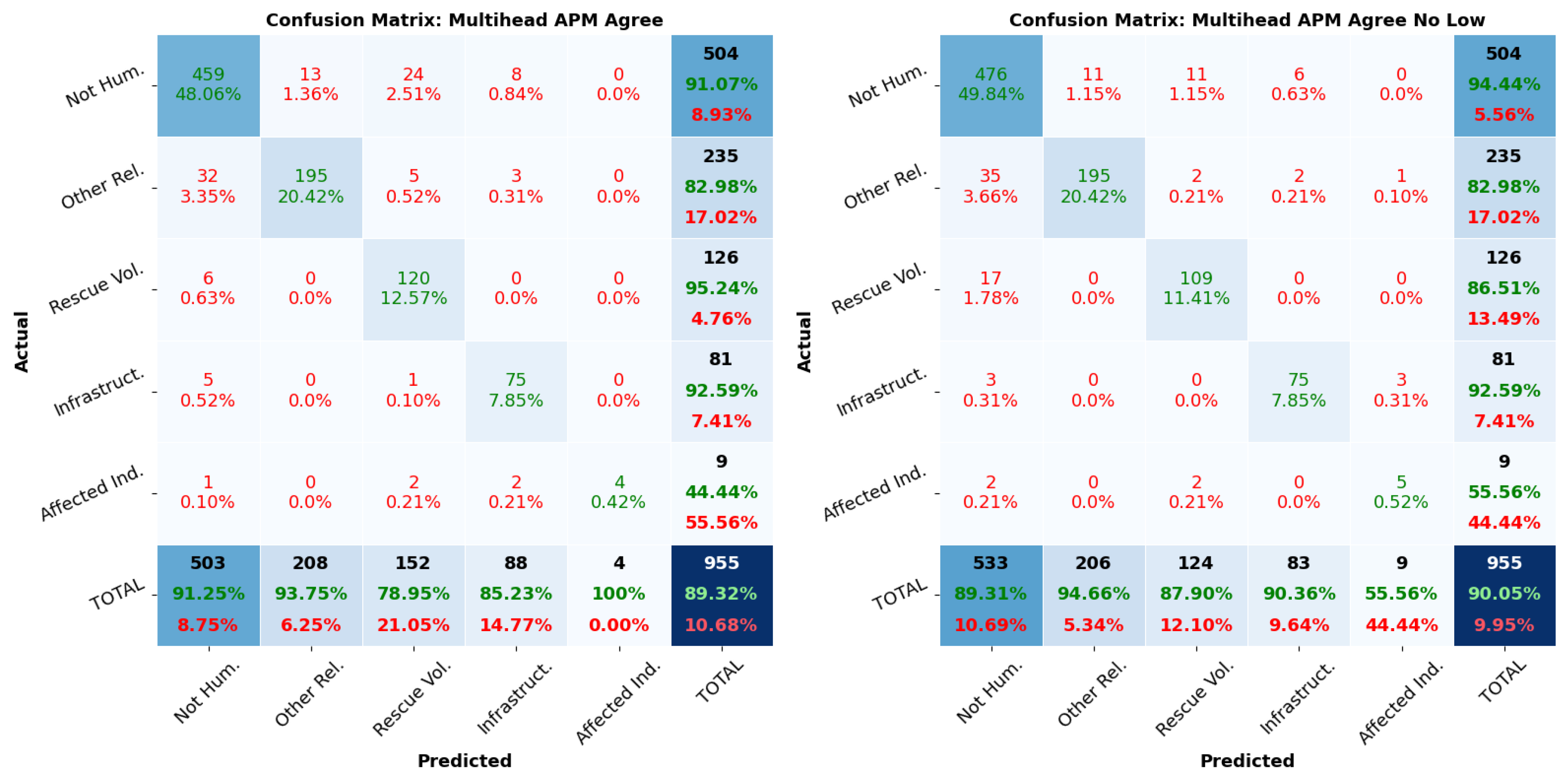
3.3. Multihead Average Pseudo-Margin
- APM is used only for disagreements, and we set an additional threshold lower bound of 0 (Multihead APM No Agree).
- APM is used for both agreements and disagreements, and we set an additional threshold lower bound of 0 (Multihead APM Agree).
- APM is used only for disagreements without a lower bound (Multihead APM No Agree No Low).
- APM is used for both agreements and disagreements with no lower bound (Multihead APM Agree No Low).
4. Experiments
4.1. Datasets
4.1.1. Labeled Data
4.1.2. Unlabeled Data
4.2. Augmentation
4.3. Low-Data Regimes
4.4. Experimental Setup
4.5. Hyperparameters
4.6. Efficiency Considerations
5. Results
5.1. Humanitarian Task
5.2. Informative Task
5.3. Low-Data Regimes
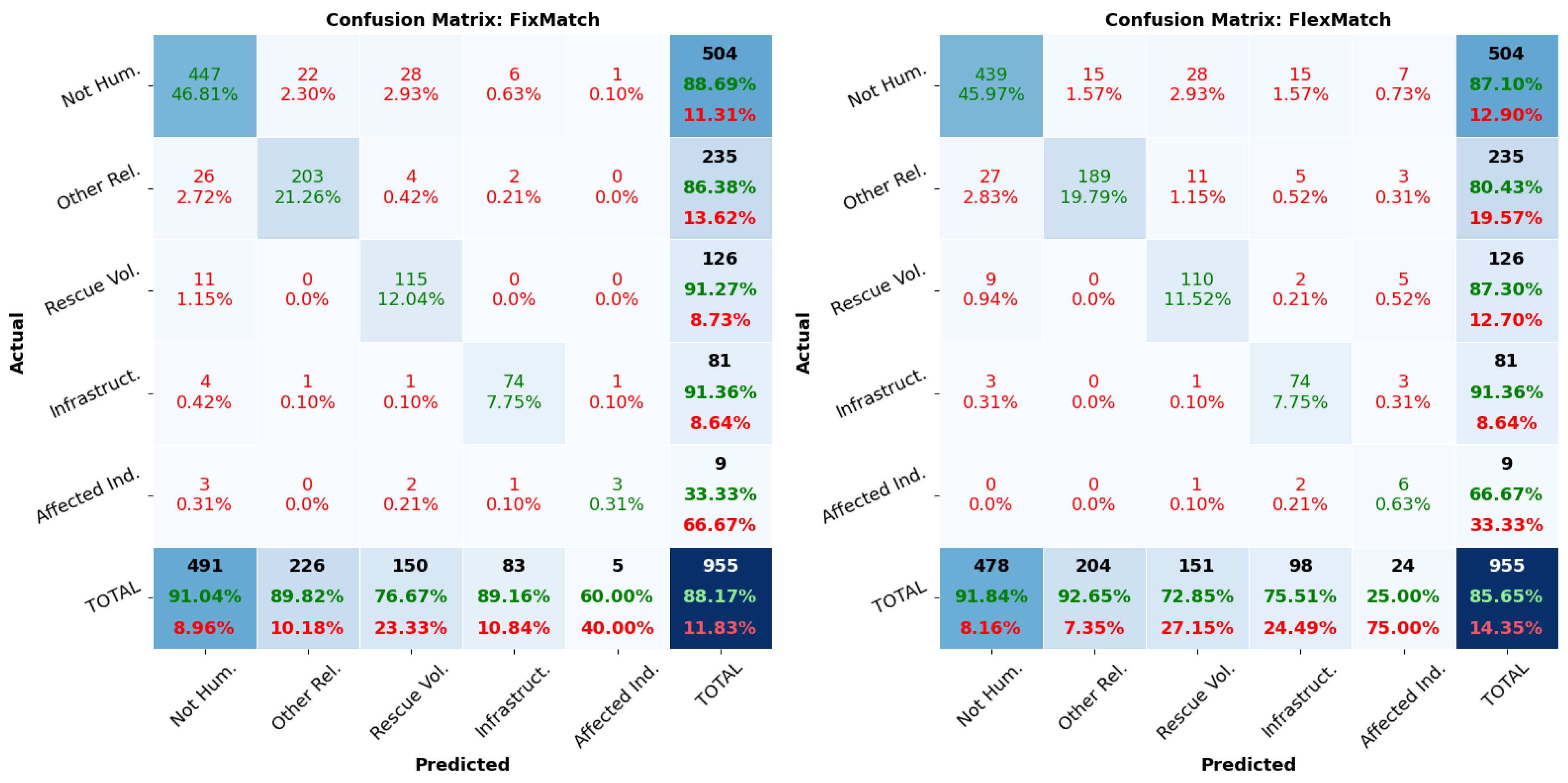
6. Confidence Thresholds Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| APM | Average Pseudo-Margin |
| AUM | Area Under the Margin |
| EDA | Easy Data Augmentation |
| SSL | Semi-Supervised Learning |
References
- Centre for Research on the Epidemiology of Disasters (CRED). 2023 Disasters in Numbers: A Significant Year of Disaster Impact; Technical Report; Institute Health and Society—UCLouvain: Brussels, Belgium, 2024. [Google Scholar]
- Alam, F.; Ofli, F.; Imran, M. CrisisMMD: Multimodal Twitter Datasets from Natural Disasters. In Proceedings of the 12th International AAAI Conference on Web and Social Media (ICWSM), Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Ashktorab, Z.; Brown, C.; Nandi, M.; Culotta, A. Tweedr: Mining twitter to inform disaster response. In Proceedings of the 11th International ISCRAM Conference, University Park, PA, USA, 18–21 May 2014; pp. 269–272. [Google Scholar]
- Zou, H.P.; Zhou, Y.; Zhang, W.; Caragea, C. Decrisismb: Debiased semi-supervised learning for crisis tweet classification via memory bank. arXiv 2023, arXiv:2310.14577. [Google Scholar]
- Zou, H.P.; Caragea, C.; Zhou, Y.; Caragea, D. Semi-supervised few-shot learning for fine-grained disaster tweet classification. In Proceedings of the 20th International ISCRAM Conference, ISCRAM 2023, Omaha, NE, USA, 28–31 May 2023. [Google Scholar]
- Sirbu, I.; Sosea, T.; Caragea, C.; Caragea, D.; Rebedea, T. Multimodal Semi-supervised Learning for Disaster Tweet Classification. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; International Committee on Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2711–2723. [Google Scholar]
- Sohn, K.; Berthelot, D.; Li, C.L.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv 2020, arXiv:2001.07685. [Google Scholar]
- Zhang, B.; Wang, Y.; Hou, W.; Wu, H.; Wang, J.; Okumura, M.; Shinozaki, T. FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling. Adv. Neural Inf. Process. Syst. 2021, 34, 18408–18419. [Google Scholar]
- Wang, Y.; Chen, H.; Heng, Q.; Hou, W.; Fan, Y.; Wu, Z.; Wang, J.; Savvides, M.; Shinozaki, T.; Raj, B.; et al. FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning. arXiv 2023, arXiv:2205.07246. [Google Scholar]
- Sosea, T.; Caragea, C. MarginMatch: Improving Semi-Supervised Learning with Pseudo-Margins. arXiv 2023, arXiv:2308.09037. [Google Scholar]
- Chen, M.; Du, Y.; Zhang, Y.; Qian, S.; Wang, C. Semi-Supervised Learning with Multi-Head Co-Training. arXiv 2021, arXiv:2107.04795. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-supervised Learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 8934–8954. [Google Scholar] [CrossRef]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. Adv. Neural Inf. Process. Syst. 2016, 29, 1163–1171. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- McLachlan, G.J. Iterative reclassification procedure for constructing an asymptotically optimal rule of allocation in discriminant analysis. J. Am. Stat. Assoc. 1975, 70, 365–369. [Google Scholar] [CrossRef]
- Zhou, S.; Tian, S.; Yu, L.; Wu, W.; Zhang, D.; Peng, Z.; Zhou, Z.; Wang, J. FixMatch-LS: Semi-supervised skin lesion classification with label smoothing. Biomed. Signal Process. Control 2023, 84, 104709. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, F.; Wang, C.; Han, B. Pixelfixmatch: A Semi-Supervised Image Segmentation Method Based on Fixmatch with Pixel Attention. In Proceedings of the 2024 IEEE International Symposium on Biomedical Imaging (ISBI), Athens, Greece, 27–30 May 2024; pp. 1–5. [Google Scholar]
- Ihler, S.; Kuhnke, F.; Kuhlgatz, T.; Seel, T. Distribution-Aware Multi-Label FixMatch for Semi-Supervised Learning on CheXpert. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 2295–2304. [Google Scholar]
- Pleiss, G.; Zhang, T.; Elenberg, E.R.; Weinberger, K.Q. Identifying Mislabeled Data using the Area Under the Margin Ranking. Adv. Neural Inf. Process. Syst. 2020, 33, 17044–17056. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Qiao, S.; Shen, W.; Zhang, Z.; Wang, B.; Yuille, A. Deep Co-Training for Semi-Supervised Image Recognition. arXiv 2018, arXiv:1803.05984. [Google Scholar]
- Zou, H.P.; Caragea, C. JointMatch: A Unified Approach for Diverse and Collaborative Pseudo-Labeling to Semi-Supervised Text Classification. arXiv 2023, arXiv:2310.14583. [Google Scholar]
- Yin, J.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using social media to enhance emergency situation awareness. IEEE Intell. Syst. 2012, 27, 52–59. [Google Scholar] [CrossRef]
- Guan, X.; Chen, C. Using social media data to understand and assess disasters. Nat. Hazards 2014, 74, 837–850. [Google Scholar] [CrossRef]
- Kryvasheyeu, Y.; Chen, H.; Obradovich, N.; Moro, E.; Van Hentenryck, P.; Fowler, J.; Cebrian, M. Rapid assessment of disaster damage using social media activity. Sci. Adv. 2016, 2, e1500779. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Caragea, D.; Caragea, C.; Herndon, N. Disaster response aided by tweet classification with a domain adaptation approach. J. Contingencies Crisis Manag. 2018, 26, 16–27. [Google Scholar] [CrossRef]
- Lagerstrom, R.; Arzhaeva, Y.; Szul, P.; Obst, O.; Power, R.; Robinson, B.; Bednarz, T. Image Classification to Support Emergency Situation Awareness. Front. Robot. AI 2016, 3, 54. [Google Scholar] [CrossRef]
- Alam, F.; Imran, M.; Ofli, F. Image4act: Online social media image processing for disaster response. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, Sydney, Australia, 31 July–3 August 2017; pp. 601–604. [Google Scholar]
- Nguyen, D.T.; Ofli, F.; Imran, M.; Mitra, P. Damage assessment from social media imagery data during disasters. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, Sydney, Australia, 31 July–3 August 2017; pp. 569–576. [Google Scholar]
- Li, X.; Caragea, D.; Zhang, H.; Imran, M. Localizing and quantifying infrastructure damage using class activation mapping approaches. Soc. Netw. Anal. Min. 2019, 9, 44. [Google Scholar] [CrossRef]
- Li, X.; Caragea, D.; Caragea, C.; Imran, M.; Ofli, F. Identifying Disaster Damage Images Using a Domain Adaptation Approach. In Proceedings of the 16th International Conference on Information Systems for Crisis Response and Management (ISCRAM 2019), Valencia, Spain, 19–22 May 2019. [Google Scholar]
- Gautam, A.K.; Misra, L.; Kumar, A.; Misra, K.; Aggarwal, S.; Shah, R.R. Multimodal analysis of disaster tweets. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 94–103. [Google Scholar]
- Nalluru, G.; Pandey, R.; Purohit, H. Relevancy classification of multimodal social media streams for emergency services. In Proceedings of the 2019 IEEE International Conference on Smart Computing (SMARTCOMP), Washington, DC, USA, 12–15 June 2019; pp. 121–125. [Google Scholar]
- Agarwal, M.; Leekha, M.; Sawhney, R.; Shah, R.R. Crisis-DIAS: Towards Multimodal Damage Analysis-Deployment, Challenges and Assessment. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 346–353. [Google Scholar]
- Abavisani, M.; Wu, L.; Hu, S.; Tetreault, J.; Jaimes, A. Multimodal Categorization of Crisis Events in Social Media. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14679–14689. [Google Scholar]
- Hao, H.; Wang, Y. Leveraging Multimodal Social Media Data for Rapid Disaster Damage Assessment. Int. J. Disaster Risk Reduct. 2020, 51, 101760. [Google Scholar] [CrossRef]
- Sosea, T.; Sirbu, I.; Caragea, C.; Caragea, D.; Rebedea, T. Using the Image-Text Relationship to Improve Multimodal Disaster Tweet Classification. In Proceedings of the 18th International Conference on Information Systems for Crisis Response and Management (ISCRAM 2021), Blacksburg, VA, USA, 23–26 May 2021. [Google Scholar]
- Dinani, S.T.; Caragea, D. Disaster Image Classification Using Capsule Networks. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Hua, X.S.; Zhang, H.J. An attention-based decision fusion scheme for multimedia information retrieval. In Proceedings of the Pacific-Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1001–1010. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Khattar, A.; Quadri, S. CAMM: Cross-attention multimodal classification of disaster-related tweets. IEEE Access 2022, 10, 92889–92902. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Koshy, R.; Elango, S. Multimodal tweet classification in disaster response systems using transformer-based bidirectional attention model. Neural Comput. Appl. 2023, 35, 1607–1627. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Alam, F.; Joty, S.; Imran, M. Graph based semi-supervised learning with convolution neural networks to classify crisis related tweets. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar]
- Kiela, D.; Bhooshan, S.; Firooz, H.; Testuggine, D. Supervised multimodal bitransformers for classifying images and text. arXiv 2019, arXiv:1909.02950. [Google Scholar]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Ofli, F.; Alam, F.; Imran, M. Analysis of Social Media Data using Multimodal Deep Learning for Disaster Response. arXiv 2020, arXiv:2004.11838. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. arXiv 2019, arXiv:1909.13719. [Google Scholar]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding Back-Translation at Scale. arXiv 2018, arXiv:1808.09381. [Google Scholar]
- Wang, Y.; Chen, H.; Fan, Y.; Sun, W.; Tao, R.; Hou, W.; Wang, R.; Yang, L.; Zhou, Z.; Guo, L.Z.; et al. USB: A Unified Semi-supervised Learning Benchmark for Classification. arXiv 2022, arXiv:2208.07204. [Google Scholar]
- Andreadis, S.; Bozas, A.; Gialampoukidis, I.; Moumtzidou, A.; Fiorin, R.; Lombardo, F.; Mavropoulos, T.; Norbiato, D.; Vrochidis, S.; Ferri, M.; et al. DisasterMM: Multimedia Analysis of Disaster-Related Social Media Data Task at MediaEval 2022. In Proceedings of the MediaEval, Bergen, Norway, 13–15 January 2023. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Used Value | Details |
|---|---|---|
| Ratio of unlabeled to labeled data, | 3 | Computational limitations, as 7 should work better [7]. |
| Unlabeled loss coefficient, | 1 | Compatibility to previous work [7]. |
| Image size | 224 × 224 | Required size for the MMBT network. |
| Labeled batch size, B | 8 | Computational limitations. |
| Number of epochs, | 20 | Sufficient for all the models to converge. |
| Learning rate, | ||
| Optimizer | AdamW | |
| Layer decay rate | ||
| Weight decay rate | ||
| Confidence threshold, | For FixMatch and FlexMatch. | |
| EMA momentum, | 0.999 | For FreeMatch. Experimented with . |
| Smoothing factor | 0.997 | For MarginMatch. |
| Fixed APM cutoff | 0 | For MarginMatch. |
| Number of heads | 3 | For Multihead Co-Training and Multihead APM. |
| Percentile threshold, f | For Multihead APM. Experimented with . |
| Model | Humanitarian | Informative | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | |
| MMBT Supervised Aug [51] | ||||||||
| FixMatch [7] | ||||||||
| FixMatch LS [6] | ||||||||
| FlexMatch [8] | ||||||||
| FreeMatch [9] | ||||||||
| MarginMatch [10] | ||||||||
| Multihead Co-Training [11] | ||||||||
| Multihead APM Agree | 89.74 | |||||||
| Multihead APM Agree No Low | 89.55 | 89.58 | 89.55 | 91.23 | 91.21 | 91.27 | 91.22 | |
| Multihead APM No Agree | ||||||||
| Multihead APM No Agree No Low | ||||||||
| Model | Humanitarian 50 Labels/Class | Informative 50 Labels/Class | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | |
| MMBT Supervised Aug | ||||||||
| FixMatch | ||||||||
| FixMatch LS | ||||||||
| Multihead APM Agree No Low | 74.05 | 82.32 | 74.05 | 76.74 | 83.77 | 83.59 | 83.77 | 83.22 |
| Class | Labeled Percent | Pseudo-Label Count | Threshold |
|---|---|---|---|
| Not Humanitarian | 1422 | ||
| Other relevant information | 780 | ||
| Rescue, volunteering, or donation effort | 0 | 0 | |
| Infrastructure and utility damage | 0 | 0 | |
| Affected individuals | 0 | 0 | |
| No class | − | 16,176 | − |
| Class | Labeled Percent | Pseudo-Label Count | Threshold |
|---|---|---|---|
| Not Humanitarian | 4806 | ||
| Other relevant information | 4766 | ||
| Rescue, volunteering, or donation effort | 4231 | ||
| Infrastructure and utility damage | 3892 | ||
| Affected individuals | 601 | ||
| No class | − | 82 | − |
| Class | Not Hum. | Other Rel. | Rescue Vol. | Infrastruct. | Affected Ind. |
|---|---|---|---|---|---|
| Not Humanitarian | |||||
| Other relevant information | |||||
| Rescue, volunteering, or donation effort | |||||
| Infrastructure and utility damage | |||||
| Affected individuals |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sîrbu, I.; Popovici, R.-A.; Rebedea, T.; Trăușan-Matu, Ș. Multihead Average Pseudo-Margin Learning for Disaster Tweet Classification. Information 2025, 16, 434. https://doi.org/10.3390/info16060434
Sîrbu I, Popovici R-A, Rebedea T, Trăușan-Matu Ș. Multihead Average Pseudo-Margin Learning for Disaster Tweet Classification. Information. 2025; 16(6):434. https://doi.org/10.3390/info16060434
Chicago/Turabian StyleSîrbu, Iustin, Robert-Adrian Popovici, Traian Rebedea, and Ștefan Trăușan-Matu. 2025. "Multihead Average Pseudo-Margin Learning for Disaster Tweet Classification" Information 16, no. 6: 434. https://doi.org/10.3390/info16060434
APA StyleSîrbu, I., Popovici, R.-A., Rebedea, T., & Trăușan-Matu, Ș. (2025). Multihead Average Pseudo-Margin Learning for Disaster Tweet Classification. Information, 16(6), 434. https://doi.org/10.3390/info16060434