1. Introduction
Deep Neural Networks (DNNs) are currently used as an effective solution for multiple complex problems, especially those from computer vision [
1]. The effectiveness of DNNs arises from the ability to extract non-linear information from the underlying data distribution by executing a training step over a database. As such, DNNs usually achieve better performance than rule-based solutions on scenarios with an expressive number of variables [
2]. Among typical use cases, it is possible to observe the implementation of Intelligent Transport Systems (ITSs), on which different participating devices produce highly heterogeneous data. These devices may have hardware limitations and can be used to sense the environment or even to control a vehicle [
3].
The increasing requirements in performance impose deeper and consequently more complex configurations for DNNs. As a consequence, more computational power is needed, representing a challenge for resource-constrained devices [
4]. In ITS scenarios, mobile devices with constraints on computational and energy resources are often used to cite an example. To circumvent this issue, we can employ a traditional approach that moves computational tasks to the cloud, allowing mobile devices to transfer the burden of running the DNN [
5]. This solution, however, has challenges when considering network load and inference time. Mobile devices must send the collected data to the cloud, adding network bottlenecks and increasing inference time. Additionally, this approach faces well-known resiliency issues, given the centralized computation at the cloud [
6], and exposes users’ private data. These risks impact on applications that directly operate in critical scenarios, such as autonomous driving and healthcare [
7,
8].
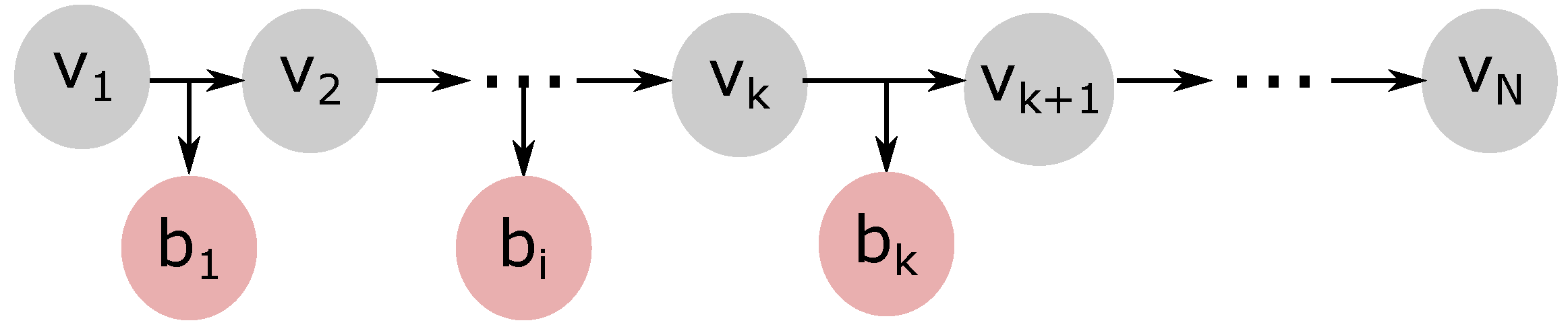
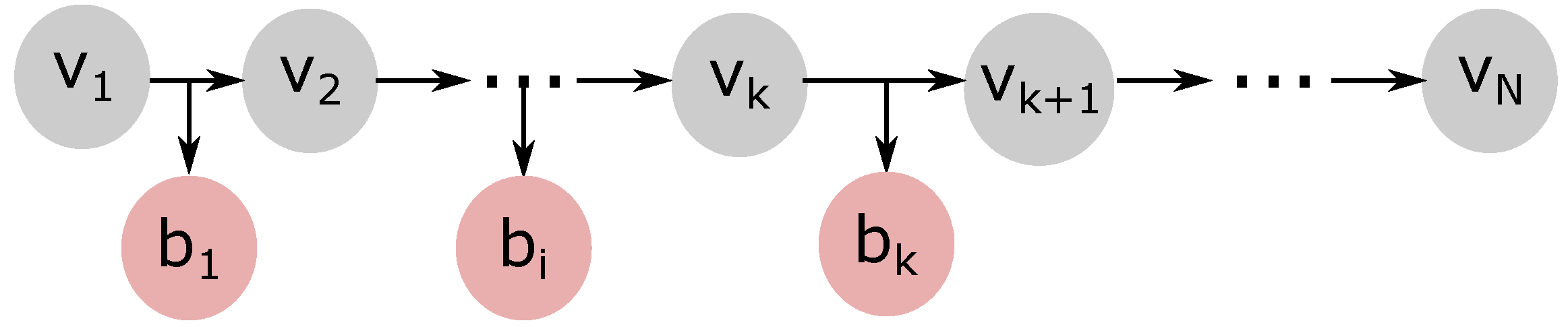
Early-exit DNNs, such as BranchyNets [
9,
10], emerges as a possible solution to the cloud centralization problem. These DNNs can perform early inference by leveraging side branches inserted in predetermined intermediate layers. This new structure allows these DNNs to stop inference if the classification confidence obtained in a side branch is superior to a threshold. Since there is no need to go through all the layers of a DNN, we can leave part of the DNN’s layers at the network edge and part at the cloud. As a consequence, the use of early exits can reduce the overall inference time and, in the meantime, avoid data transmissions to the cloud. While strategies regarding side branch positioning in DNNs are under investigation [
11], the performance evaluation of these strategies is still an open issue.
This paper evaluates the impact of different parameters on the number of samples classified at the network edge. We focus on the threshold value used to determine the confidence target for sample classification at each side branch, the number of side branches, and their position at the DNN. The configuration of these parameters must consider the tradeoff between inference time and confidence. For instance, low confidence threshold values increase the number of sample classifications at the network edge, reducing the inference time. Nevertheless, the inference confidence can be positively affected by the number of DNN layers used. Yet, adding more side branches to the DNN can increase the chances of earlier classification, but at the cost of additional processing time. Each side branch introduces more computations to the inference process, possibly hindering the gains in classification confidence after a specific practical limit. In this case, it may be more advantageous to offload the data to the cloud for further DNN processing.
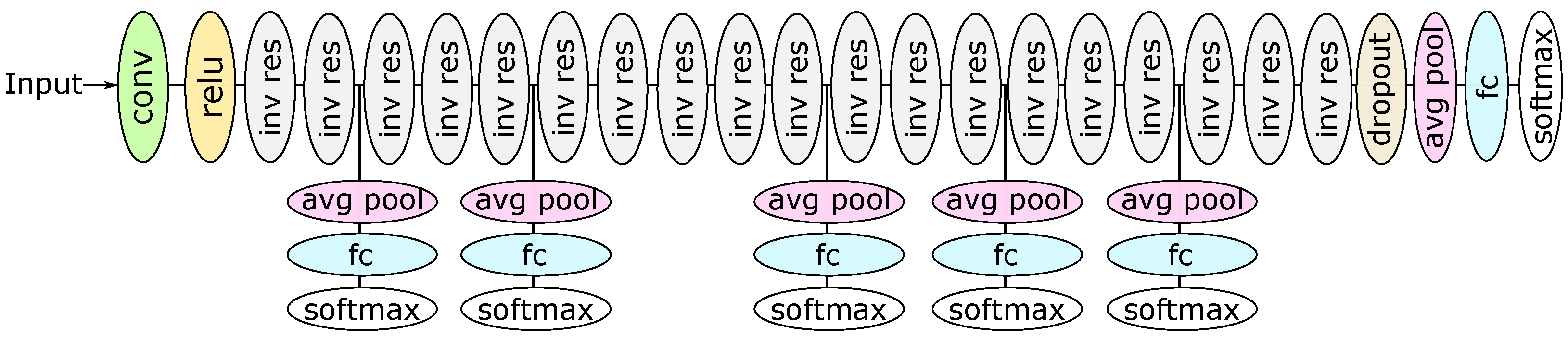
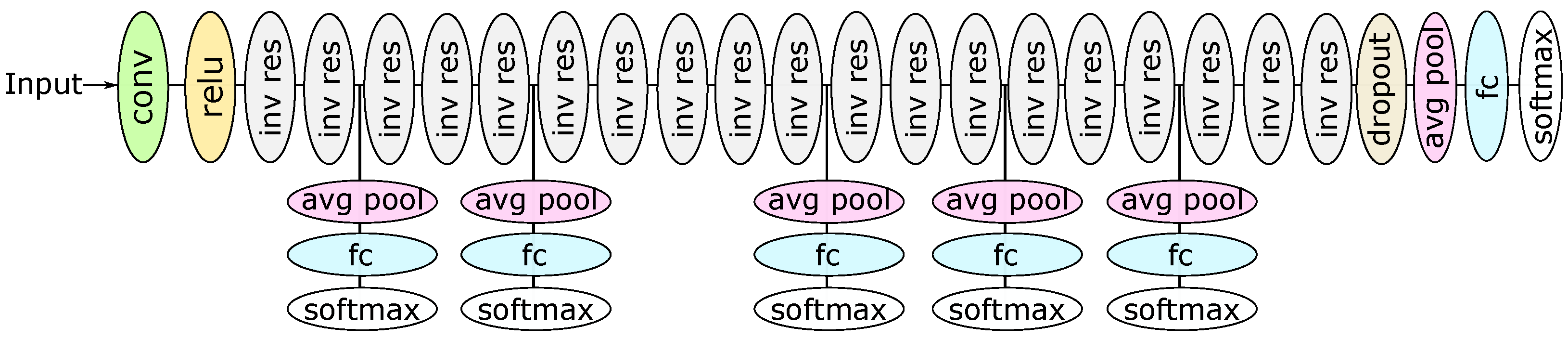
This work considers a Convolutional Neural Network (CNN), a DNN type widely employed in computer vision. More specifically, we employ a MobileNetV2 [
12] model using the Caltech-256 image recognition dataset [
13]. First, we add side branches to MobileNetV2, investigating how the number of side branches affects the chances of classifying the image at the edge, when varying the confidence threshold. Next, we perform experiments using Amazon EC2 instances to check how these choices affect inference time. Using a real edge-based scenario, we show that employing an early-exit DNN can reduce the inference time by approximately 27% to 61% compared to a cloud-only processing scenario. In this last one, the cloud processes all DNN layers. Moreover, we show that the confidence threshold configuration plays a key role to determine the inference time. Therefore, adjusting this threshold is vital to balance inference time and classification confidence. Finally, we show that inserting side branches indiscriminately saturates the number of images classified on them, serving only to introduce processing delay.
The remainder of this article is organized as follows.
Section 2 reviews the related work.
Section 3 briefly reviews convolutional neural networks and early-exit DNNs, discussing our design choices and the DNN architecture with part of the layers at the edge and part of the layers at the cloud. Next,
Section 4 presents the methodology used to analyze early-exit DNNs in an edge-based scenario.
Section 5 discusses the experimental results, emphasizing the impact on the overall system performance of different parameters.
Section 6 evaluates the early-exit DNNs in a real edge-based scenario and demonstrates that employing early-exit DNNs can reduce inference time. Finally,
Section 7 concludes this work and presents future research directions.
2. Related Work
Cloud-based and edge-computing-based solutions create contrasting challenges for applications deployed at the network edge [
14,
15]. In mobile scenarios, on the one hand, cloud computing becomes dependent on network conditions, which can be an obstacle to applications with low latency requirements. On the other hand, edge devices can introduce computing delays because of hardware limitations compared with the cloud. Several approaches to accelerate DNN inference at the edge devices, including a hardware-based approach that uses hardware implementation to tackle this issue [
16]. For example, Eyeriss v2 [
17] designs an accelerator for DNNs on mobile devices, while Karras et al. [
18] employ an FPGA board to accelerate DNN inference. However, this paper focuses on tackling the DNN inference acceleration using DNN partitioning.
DNN partitioning determines which DNN’s layers must be processed at the network edge and which layers can be processed at the cloud. As such, Kang et al. propose the Neurosurgeon system, which builds a predictive model to determine layer-wise inference times at the edge and the cloud [
19]. Neurosurgeon performs an exhaustive search to determine which partitioning scheme minimizes inference time. In a different approach, Hu et al. propose DADS (Dynamic Adaptive DNN Surgery), a system that models DNNs as graphs and handles DNN partitioning as a minimum cut problem [
20]. Both works strive to minimize the inference time by finding the appropriate partitioning scheme, but they do not focus on the model performance.
Unlike previous works, Pacheco and Couto approach optimal early-exit DNN partitioning between edge devices and the cloud to minimize inference time [
21]. To handle that, the authors model early-exits DNNs and possible partitioning decisions as a graph. Then, they use the graph to solve the partitioning problem as a shortest path problem. Their work employs a well-known CNN called AlexNet [
22]. In another work, Pacheco et al. propose early-exit DNNs with expert side branches to make inference more robust against image distortion [
23]. To this end, they propose expert side branches trained on images with a particular distortion type. In an edge computing scenario with DNN partitioning, they show that this proposal can increases the estimated accuracy of distorted images on edge, improving the offloading decisions. Both works focus on decision-making aspects of early-exits, having a different focus than the present work. Hence, they do not perform a sensibility analysis, considering the impact of the number of side branches and the confidence threshold. Laskaridis et al. considers the confidence threshold in their study, but with a fixed number of side branches [
11].
Passalis et al. use the concept of feature vectors to leverage the relationship between the vector content learned from previous side branches to predict samples at the deeper layers of the DNN [
24]. Their proposal is evaluated using five different datasets and implementing a hierarchical chain of side branches. They achieve superior performance when compared to independent early-exit implementations. However, despite their contribution to aggregation methods, i.e., methods that use information learned from previous side branches, the learning model is not generalized to low latency applications. This occurs because the results computed by a side branch must finish before the computation performed by the deeper layers can take place.
Early-exit DNNs have been deployed in different scenarios. In industrial settings, for instance, it is possible to observe multiple applications. Li et al. implement DeepIns to minimize latency on industrial process inspection tasks [
25]. Their system leverages the concept of early-exit DNNs directly. Nevertheless, the hardware limitations of industrial edge devices are far less expressive than other IoT-based scenarios. Furthermore, DeepIns does not evaluate the use of multiple early-exits inside the local network or even at the edge device. Instead, the authors try to optimize the system performance by using a single decision point. At this possible exit point, the data can be directly inferred or sent to the cloud.
Finally, in the same way as [
11,
21,
23], we consider early-exit DNNs employed in an adaptive offloading scenario with DNN partitioning. In this case, an early-exit DNN model is split into two parts. One part is processed at the edge, while the second is processed at the cloud server. Unlike the previous works, we analyze how much early-exit DNNs can reduce the inference time to make feasible latency-sensitive applications.
6. Real Scenario Experiments
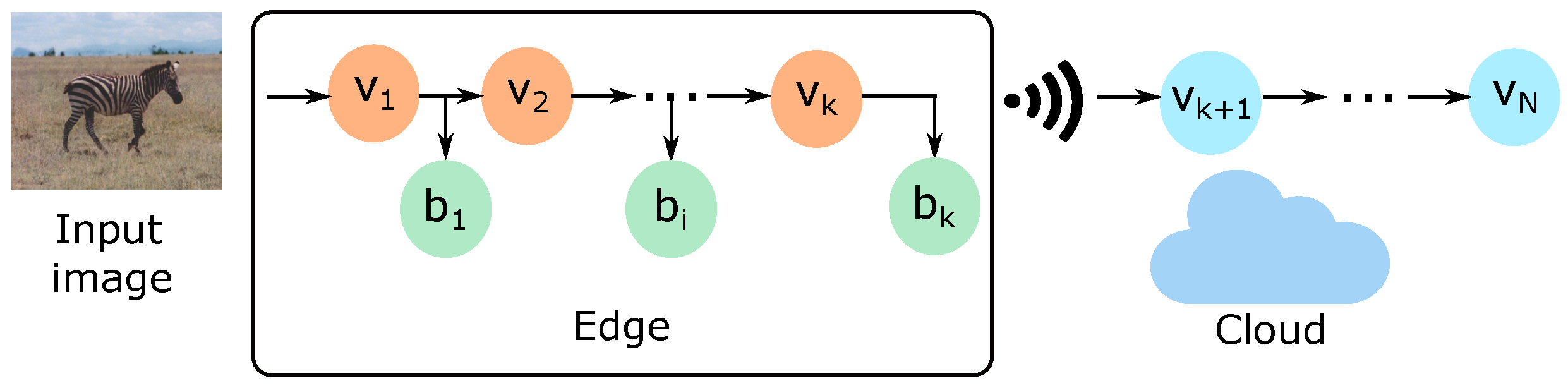
This section evaluates the inference time considering the adaptive offloading scenario presented in
Figure 2. Hence, the edge and the cloud work collaboratively to perform early-exit DNN inference for image classification tasks. The inference time is defined as the time needed to complete a DNN inference (i.e., to infer the class corresponding to an input image) after the reception of an image. If the input is classified on a side branch, this is the time needed to run the inference at the edge entirely. Otherwise, the inference time is the sum of the processing time and networking time. The first one is the time to process the DNN layer on the edge and on the cloud. The second one is the time to send the image from the edge to the cloud plus the time to send the DNN output to the edge.
The experiment employs a local server as edge and an Amazon EC2 virtual machine as the cloud server to emulate a real edge computing application. The edge and the cloud server are developed using Python Flask 2.0.1, and they communicate using the HTTP protocol. The edge server emulates the role of an end device or even an intermediate one, such as an access point on a radio base station. On the one hand, the edge server is the same one as employed in
Section 5.3, located in Rio de Janeiro, Brazil. On the other hand, the cloud server is an Amazon EC2
g4dn.xlarge instance running Ubuntu 20.04 LTS. This cloud server is equipped with four vCPUs from an Intel Cascade Lake CPU and an NVIDIA Tesla T4 GPU. For this experiment, the cloud server is located in São Paulo (i.e., sa-east-1 AWS region), also in Brazil, approximately 430 km away from Rio de Janeiro. We chose this location because it is the closest AWS region to our edge, which would be a consistent choice in a real latency-sensitive application. In this experiment, we implement a MobileNetV2 model with five side branches as our early-exit DNN. However, as shown in
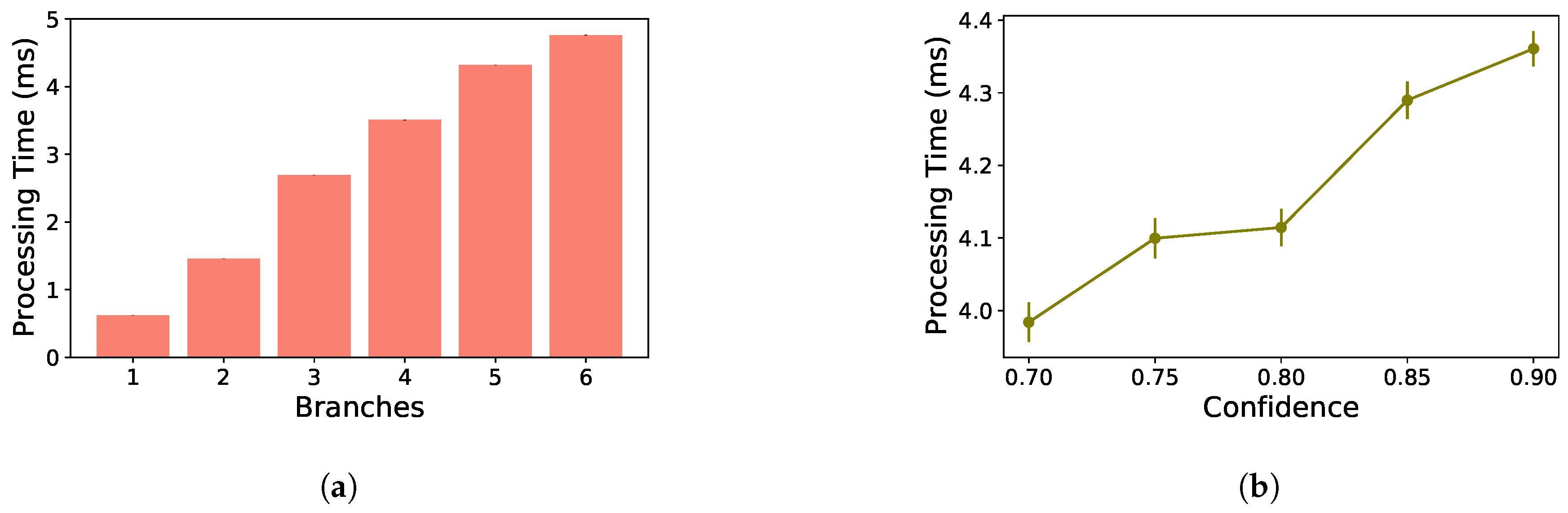
Figure 4, the first and second side branches cannot classify a considerable portion of the images from the test set. Thus, these side branches only introduce processing delay. To solve it, we remove these first two side branches in this analysis.
Additionally, we also implement a cloud-only processing scenario, in which the cloud processes all neural layers of a regular DNN (i.e., without side branches). This scenario works as a performance baseline for our adaptive offloading scenario under analysis. In the cloud-only scenario, we implement a regular MobileNetV2 for the sake of consistent comparison.
Before running the experiment, we evaluate the network conditions between the edge server and the Amazon EC2 instance. To this end, we measure the throughput and RTT (Round-Trip Time) between the edge server and the cloud instance using, respectively, iPerf3 and ping. In this case, the measured throughput and RTT are 94 Mbps and 12.8 ms, respectively. It is important to emphasize that these values only illustrate the network conditions since they may change during the experiment.
For each image from the test set, the edge server starts a timer to measure the inference time and run the early-exit DNN inference, as described in
Section 3. If any of the side branches implemented at the edge can reach the confidence threshold
, the inference terminates earlier at the edge, finishing the timer. Otherwise, the edge server sends the intermediate results to the cloud server, which processes the remaining DNN layers. In this case, the edge server waits for the HTTP response from the cloud to finish the inference timer. In contrast, in the cloud-only processing scenario, the experiment starts a timer to measure the inference time and send the image directly to the cloud server, which runs the DNN inference. Then, the edge waits for an HTTP response from the cloud to finish the inference timer. These procedures are run for each image from the test set, for each
value, and for each number of side branches at the edge. For each setting, we compute the mean inference time with confidence intervals of 95%.
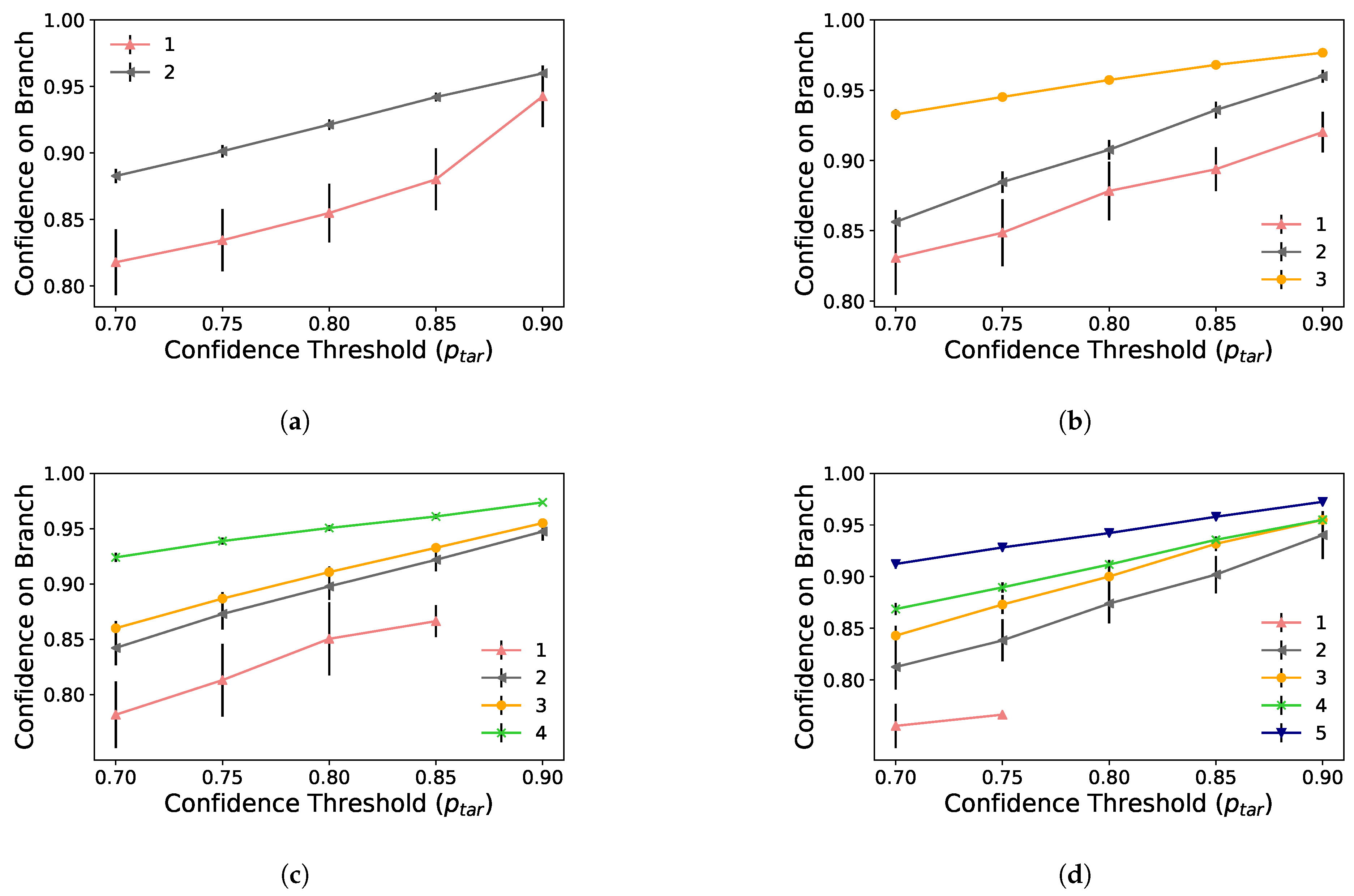
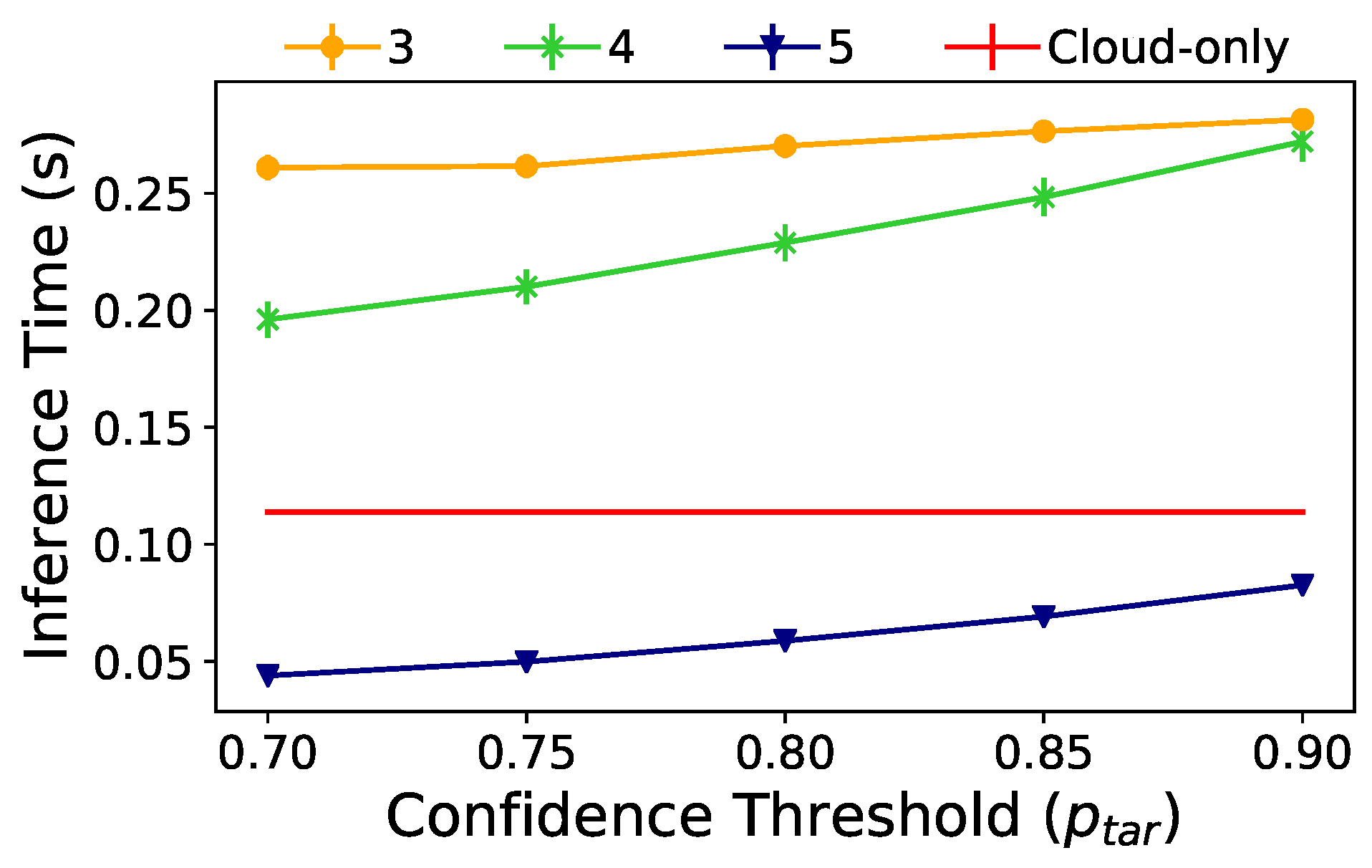
Figure 7 presents the inference time results according to the
value configuration. Each curve in this figure is the inference time result for an early-exit DNN with a different number of side branches at the edge, using the same reasoning of
Section 5.1. However, branches one and two are always deactivated. For example, the yellow curve shows the inference time considering that the DNN has only the third branch at the edge, while the green curve shows a DNN with the third and fourth branches. In contrast, the red line represents the cloud-only processing scenario, which serves as a performance baseline. At first glance, we can notice that the inference time increases as we set
to higher values. This behavior occurs because a higher
value reduces the probability of performing inference at the edge. Hence, the edge sends more images to the cloud, introducing network delay more often. The cloud-only curve is constant since its DNN in independent of
.
We can instantly observe the benefit of adding side branches by looking at the blue curve, which reduces inference time by using five side branches. Notably, the additional processing time at the edge device must provide enough gain to justify not sending the data to the cloud to reduce overall inference time. Additionally, we show that there is a tendency for the early-exit DNN to increase overall inference time with a high enough confidence threshold. Therefore,
, which is already application-dependent, must be carefully selected to minimize inference time while satisfying possible Service Level Agreements (SLAs). For example, we can highlight that the DNN with five side branches at the edge meets the 0.1 s latency requirement, which is required for a cognitive assistance application [
28].
At this stage, we have demonstrated that, in an adaptive offloading scenario, the early-exit DNN can significantly reduce the inference time and outperform the cloud-only processing scenario. Moreover, our results show that the early-exit DNN model represents a fundamental approach for meeting the requirements of latency-sensitive applications.
Author Contributions
Conceptualization, R.G.P. and R.S.C.; methodology, R.G.P.; software, R.G.P.; validation, R.G.P., K.B., M.S.G., R.S.C. and M.E.M.C.; formal analysis, R.G.P., K.B., M.S.G., R.S.C. and M.E.M.C.; resources, R.G.P., K.B., M.S.G., R.S.C. and M.E.M.C.; investigation, R.G.P., K.B., M.S.G., R.S.C. and M.E.M.C.; data curation, R.G.P.; writing—original draft preparation, R.G.P., K.B., M.S.G., R.S.C. and M.E.M.C.; writing—review and editing, R.G.P., K.B., M.S.G., R.S.C. and M.E.M.C.; visualization, R.G.P.; supervision, R.S.C. and M.E.M.C.; project administration, R.S.C. and M.E.M.C.; funding acquisition, R.S.C. and M.E.M.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financed in part by CNPq, FAPERJ Grants E-26/203.211/2017, E-26/202.689/2018, and E-26/211.144/2019. This work was also supported by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior Brasil (CAPES), Finance Code 001; Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP), process n° 15/24494-8, and Rede Nacional de Ensino e Pesquisa (RNP).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Ioannidou, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. Deep Learning Advances in Computer Vision with 3D Data: A Survey. ACM Comput. Surv. 2017, 50, 1–38. [Google Scholar] [CrossRef]
- Bochie, K.; Gilbert, M.S.; Gantert, L.; Barbosa, M.S.M.; Medeiros, D.S.V.; Campista, M.E.M. A Survey on Deep Learning for Challenged Networks: Applications and Trends. J. Netw. Comput. Appl. 2021, 194, 103213. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 712–733. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Son, Y.; Jeong, J.; Lee, Y. An Adaptive Offloading Method for an IoT-Cloud Converged Virtual Machine System Using a Hybrid Deep Neural Network. Sustainability 2018, 10, 3955. [Google Scholar] [CrossRef] [Green Version]
- Baccarelli, E.; Scarpiniti, M.; Momenzadeh, A.; Ahrabi, S.S. Learning-in-the-Fog (LiFo): Deep Learning Meets Fog Computing for the Minimum-Energy Distributed Early-Exit of Inference in Delay-Critical IoT Realms. IEEE Access 2021, 9, 25716–25757. [Google Scholar] [CrossRef]
- Kocić, J.; Jovičić, N.; Drndarević, V. An End-to-End Deep Neural Network for Autonomous Driving Designed for Embedded Automotive Platforms. Sensors 2019, 19, 2064. [Google Scholar] [CrossRef] [Green Version]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 2017, 19, 1236–1246. [Google Scholar] [CrossRef]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. BranchyNet: Fast inference via early exiting from deep neural networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2464–2469. [Google Scholar] [CrossRef] [Green Version]
- Scardapane, S.; Scarpiniti, M.; Baccarelli, E.; Uncini, A. Why Should We Add Early Exits to Neural Networks? Cogn. Comput. 2020, 12, 954–966. [Google Scholar] [CrossRef]
- Laskaridis, S.; Venieris, S.I.; Almeida, M.; Leontiadis, I.; Lane, N.D. SPINN: Synergistic Progressive Inference of Neural Networks over Device and Cloud. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking (MobiCom’20), London, UK, 21–25 September 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Griffin, G.; Holub, A.; Perona, P. Caltech-256 Object Category Dataset; CalTech Report; California Institute of Technology: Pasadena, CA, USA, 2007. [Google Scholar]
- Hobfeld, T.; Schatz, R.; Varela, M.; Timmerer, C. Challenges of QoE management for cloud applications. IEEE Commun. Mag. 2012, 50, 28–36. [Google Scholar] [CrossRef]
- Ahmed, E.; Rehmani, M.H. Mobile Edge Computing: Opportunities, solutions, and challenges. Future Gener. Comput. Syst. 2017, 70, 59–63. [Google Scholar] [CrossRef]
- Ngo, D.; Lee, S.; Ngo, T.M.; Lee, G.D.; Kang, B. Visibility Restoration: A Systematic Review and Meta-Analysis. Sensors 2021, 21, 2625. [Google Scholar] [CrossRef]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Karras, K.; Pallis, E.; Mastorakis, G.; Nikoloudakis, Y.; Batalla, J.M.; Mavromoustakis, C.X.; Markakis, E. A hardware acceleration platform for AI-based inference at the edge. Circuits Syst. Signal Process. 2020, 39, 1059–1070. [Google Scholar] [CrossRef]
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. ACM Comput. Archit. News (SIGARCH) 2017, 45, 615–629. [Google Scholar] [CrossRef] [Green Version]
- Hu, C.; Bao, W.; Wang, D.; Liu, F. Dynamic Adaptive DNN Surgery for Inference Acceleration on the Edge. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 1423–1431. [Google Scholar]
- Pacheco, R.G.; Couto, R.S. Inference Time Optimization Using BranchyNet Partitioning. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Pacheco, R.G.; Oliveira, F.D.V.R.; Couto, R.S. Early-exit deep neural networks for distorted images: Providing an efficient edge offloading. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6, Accepted for publication. [Google Scholar]
- Passalis, N.; Raitoharju, J.; Tefas, A.; Gabbouj, M. Efficient adaptive inference for deep convolutional neural networks using hierarchical early exits. Pattern Recognit. 2020, 105, 107346. [Google Scholar] [CrossRef]
- Li, L.; Ota, K.; Dong, M. Deep Learning for Smart Industry: Efficient Manufacture Inspection System With Fog Computing. IEEE Trans. Ind. Inform. 2018, 14, 4665–4673. [Google Scholar] [CrossRef] [Green Version]
- Satyanarayanan, M. The emergence of edge computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Hobert, L.; Festag, A.; Llatser, I.; Altomare, L.; Visintainer, F.; Kovacs, A. Enhancements of V2X communication in support of cooperative autonomous driving. IEEE Commun. Mag. 2015, 53, 64–70. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, W.; Wang, J.; Zhao, S.; Amos, B.; Wu, G.; Ha, K.; Elgazzar, K.; Pillai, P.; Klatzky, R.; et al. An empirical study of latency in an emerging class of edge computing applications for wearable cognitive assistance. In Proceedings of the Second ACM/IEEE Symposium on Edge Computing, San Jose, CA, USA, 12–14 October 2017; p. 14. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Pacheco, R.G.; Couto, R.S.; Simeone, O. Calibration-Aided Edge Inference Offloading via Adaptive Model Partitioning of Deep Neural Networks. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, USA, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1321–1330. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Pacheco, R.G.; Bochie, K.; Gilbert, M.S.; Couto, R.S.; Campista, M.E.M. Available online: https://github.com/pachecobeto95/early_exit_dnn_analysis (accessed on 8 October 2021).
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}