
File System Support for Privacy-Preserving Analysis and Forensics in Low-Bandwidth Edge Environments


 ,
, 
 and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
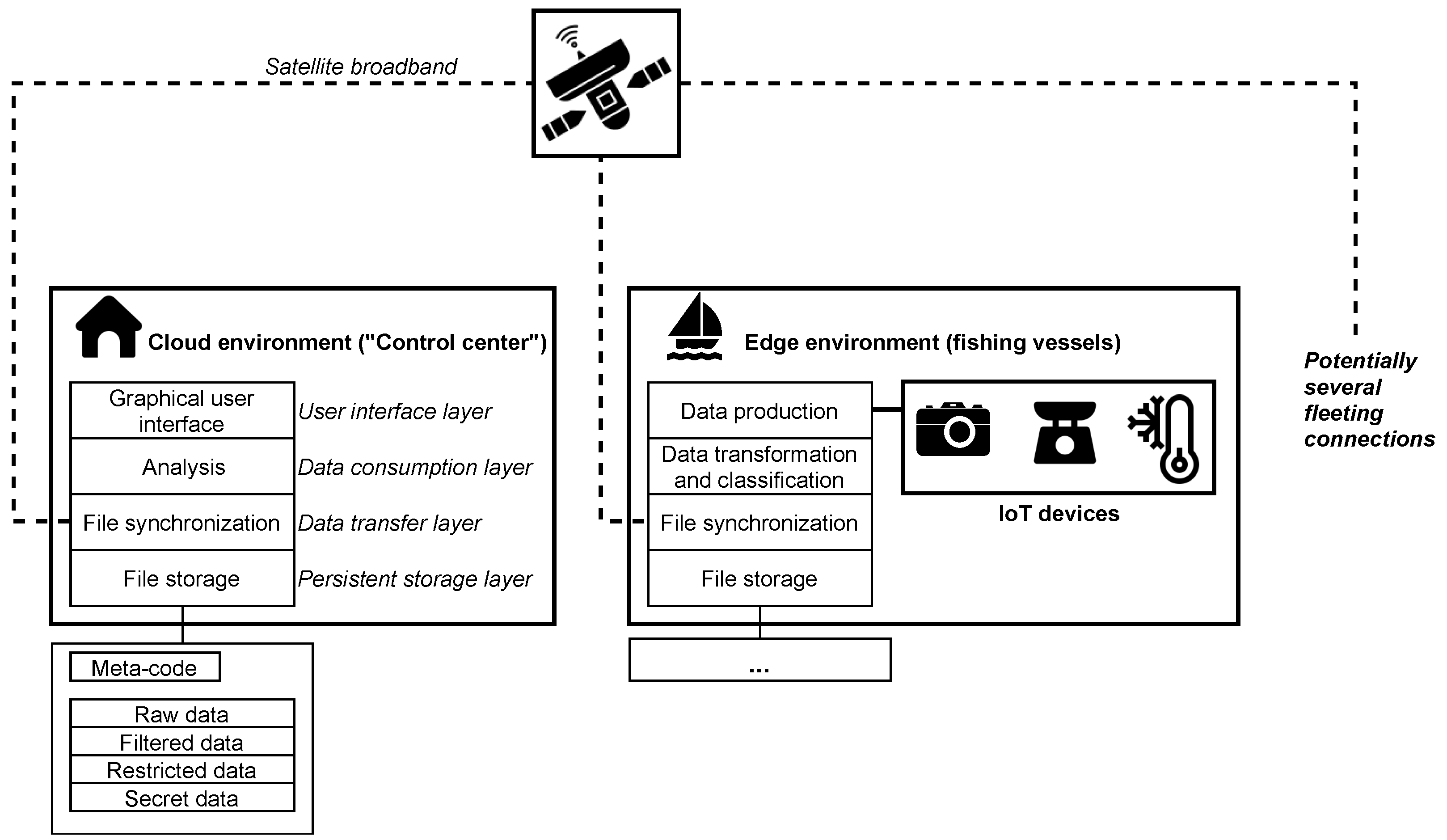
2. A Mobile AI Edge System at Sea
2.1. Geo-Distribution
2.2. Vertical Distribution
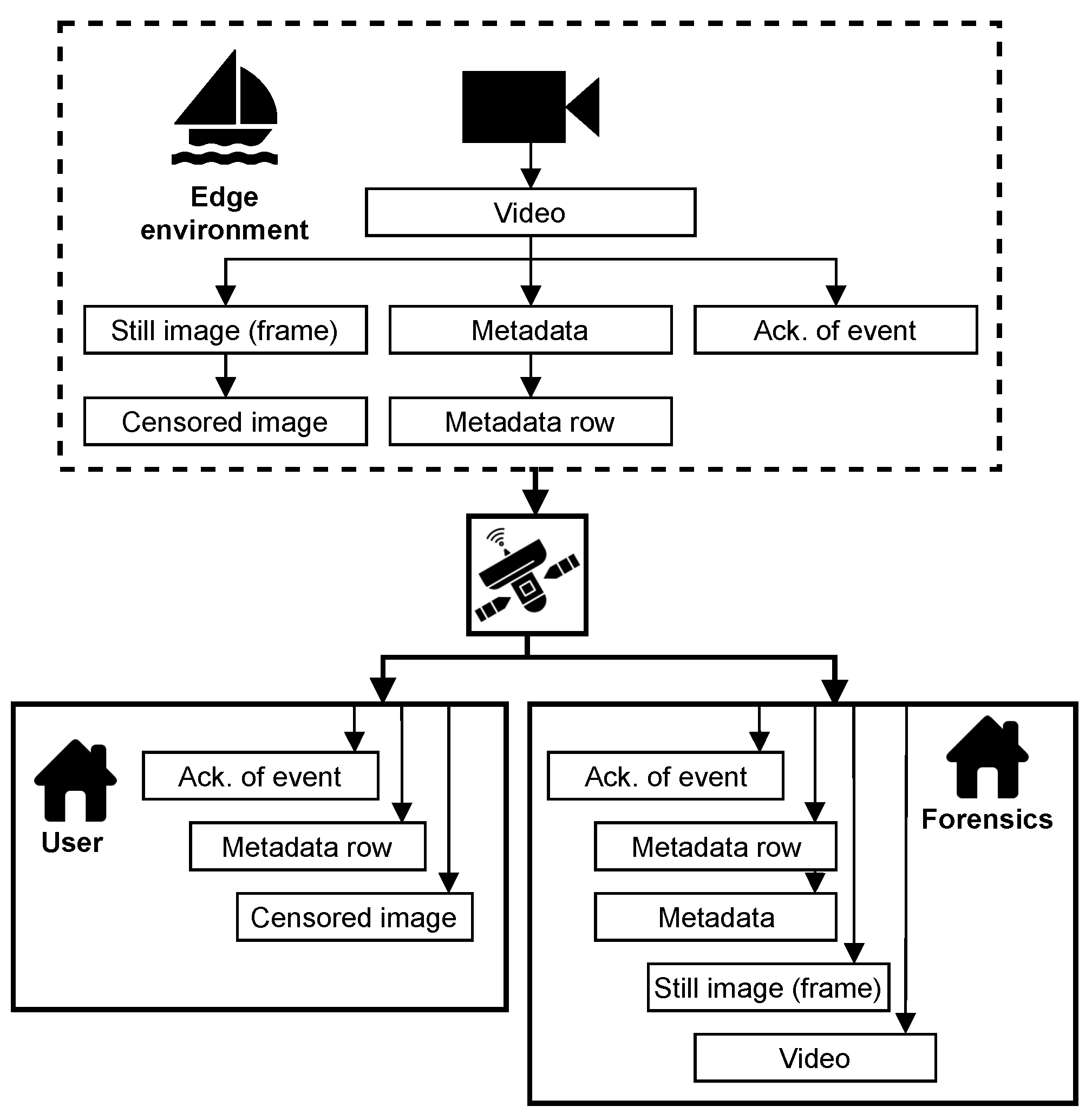
2.3. Multimedia Data Pipeline
3. System Properties and Architecture
3.1. System Requirements
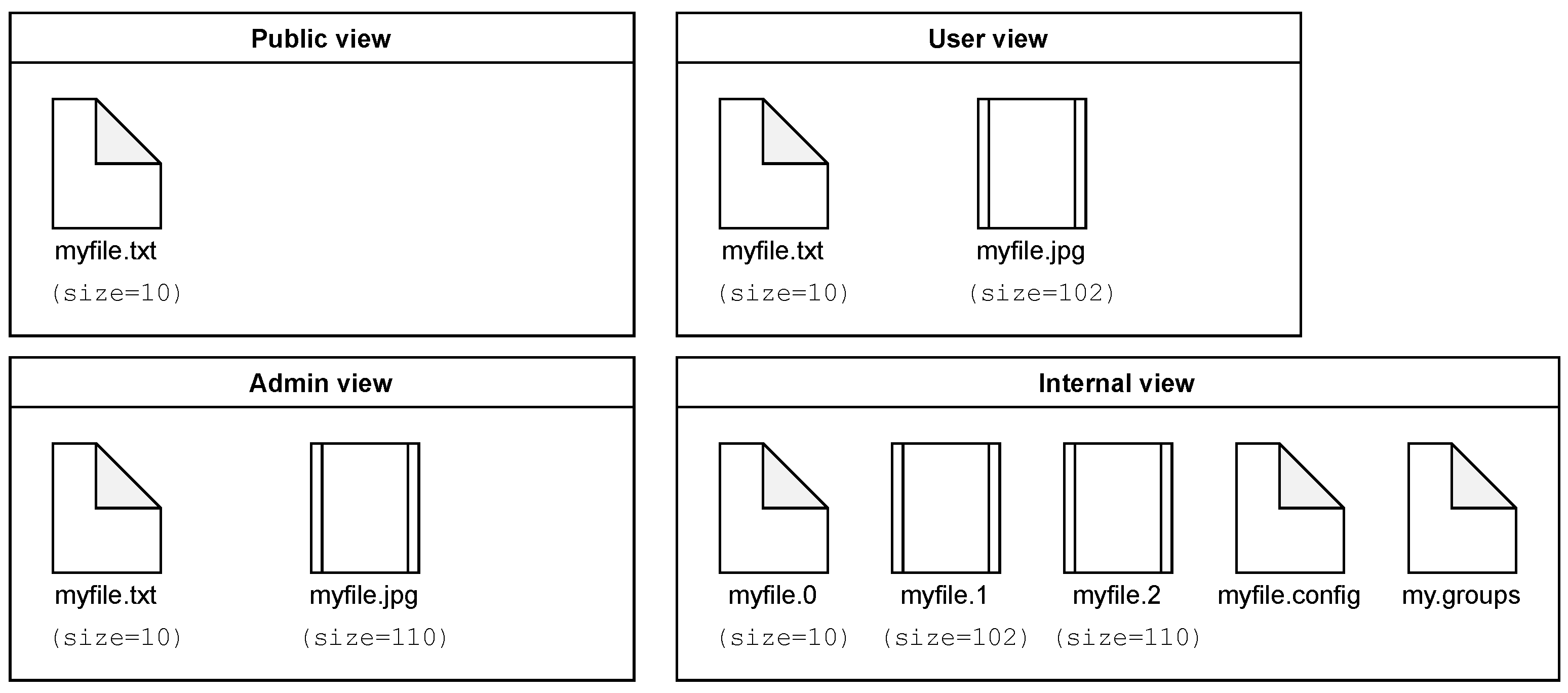
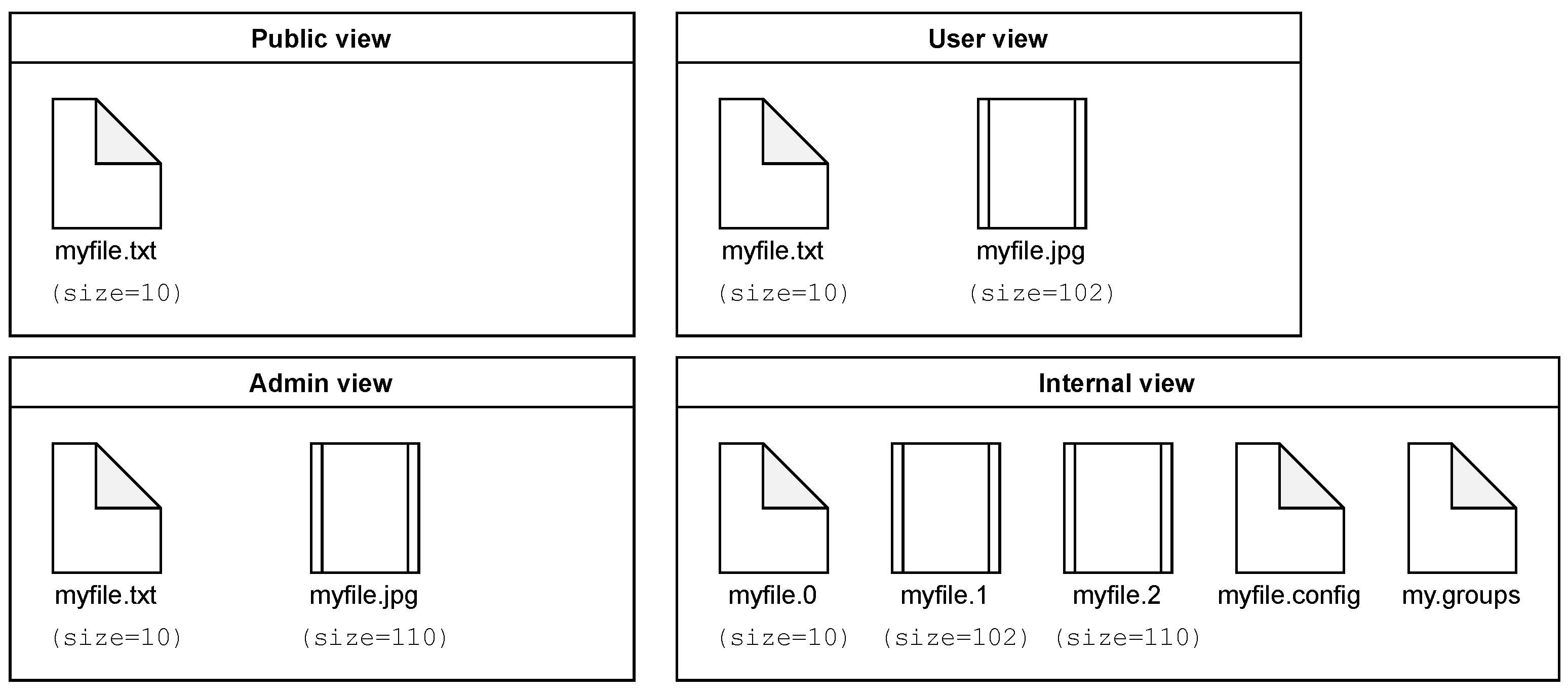
3.2. Data Classification
4. Implementation Details
4.1. FUSE
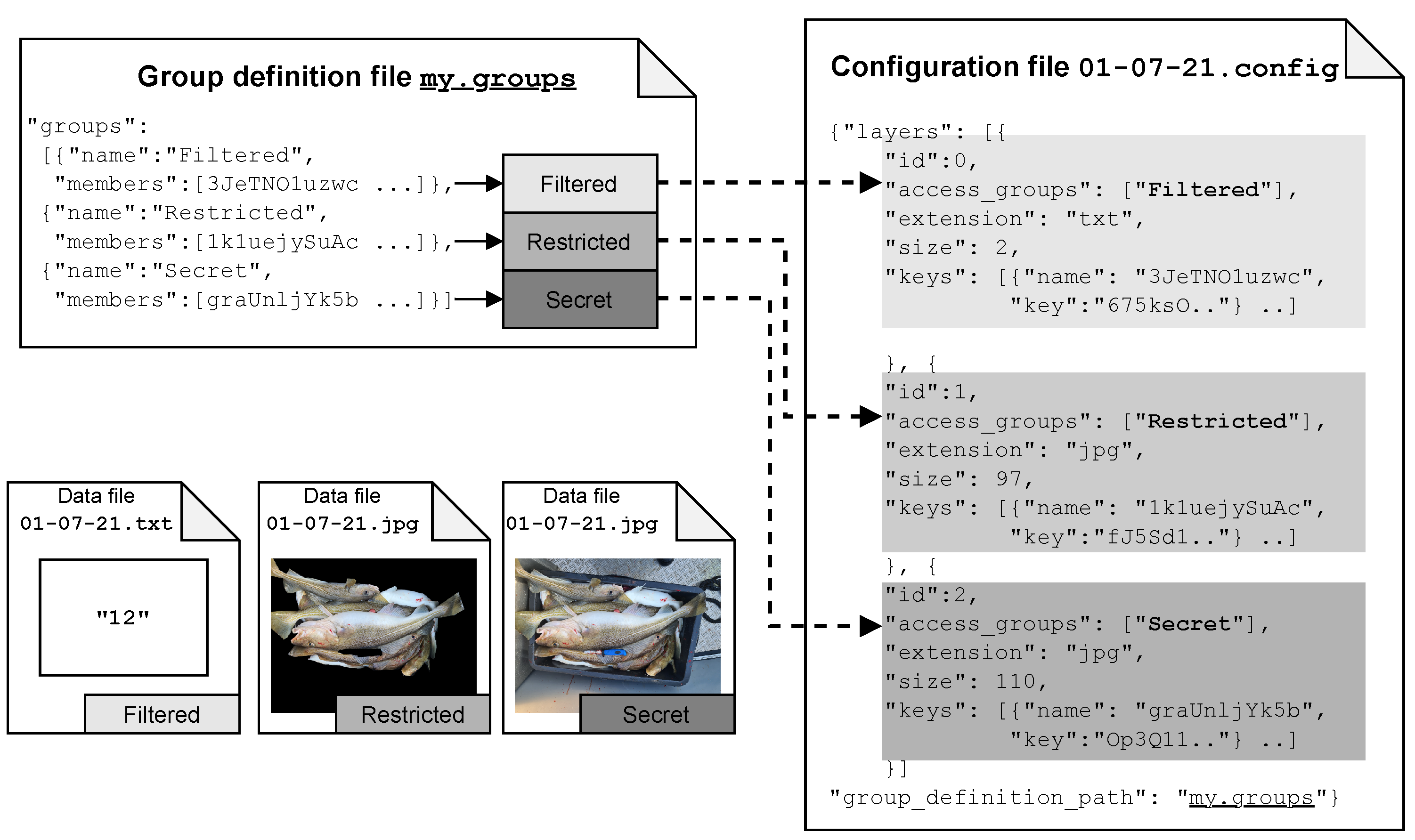
4.2. File Definitions
4.3. Encryption
5. Experiments and Results
5.1. I/O Speed and Overhead Measurement
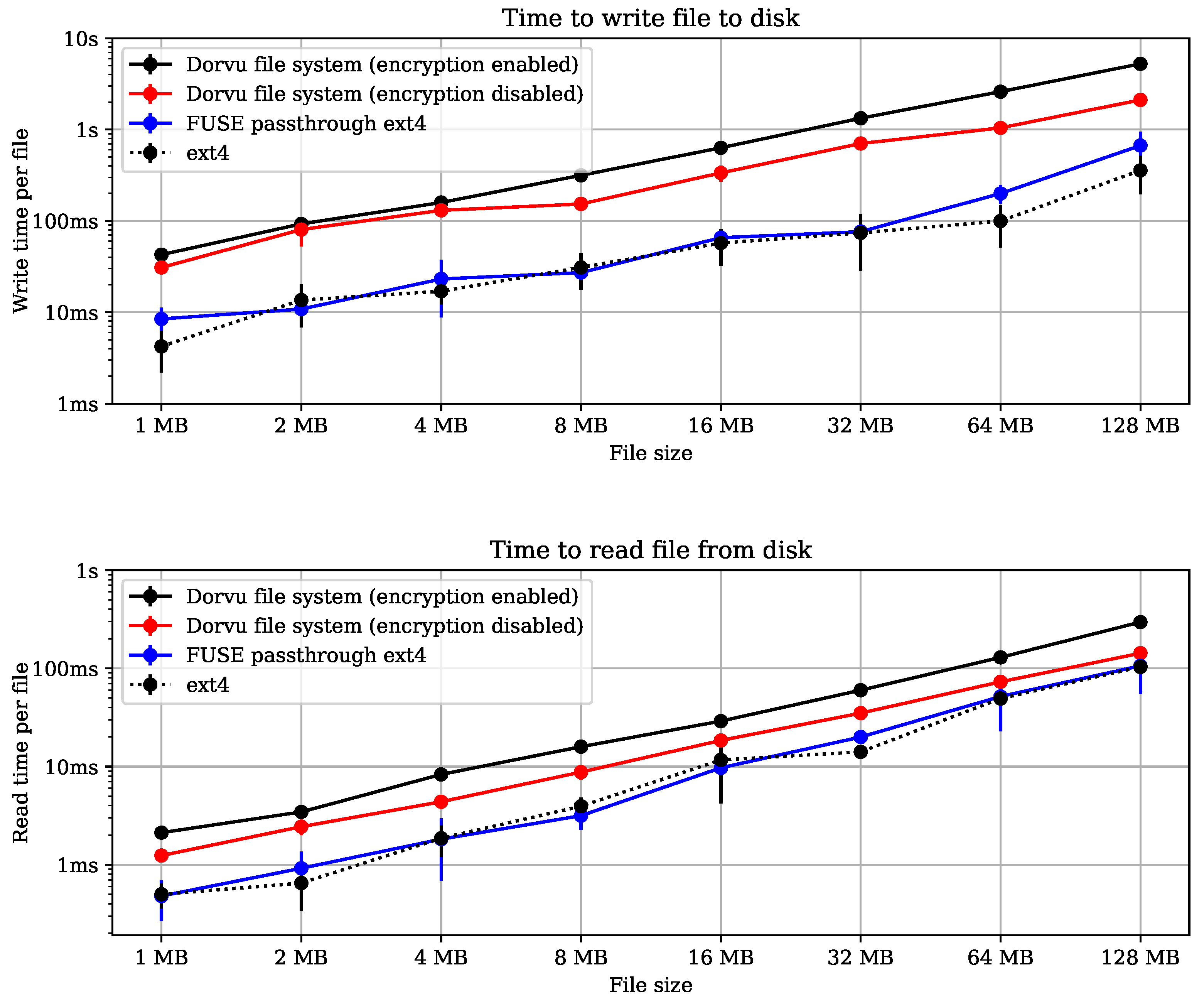
5.1.1. Experimental Setup
5.1.2. Results
5.2. Satellite Latency and Bandwidth
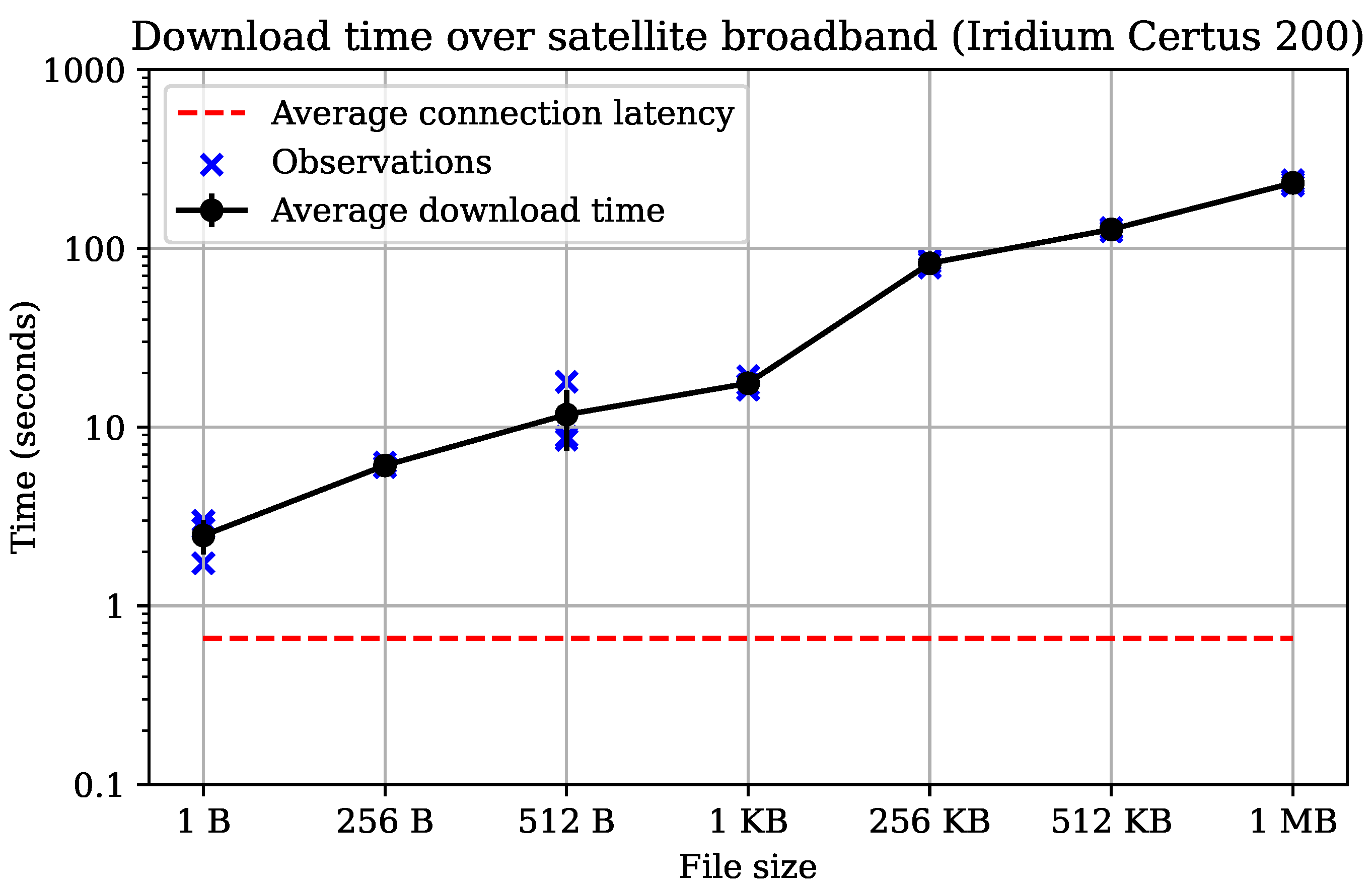
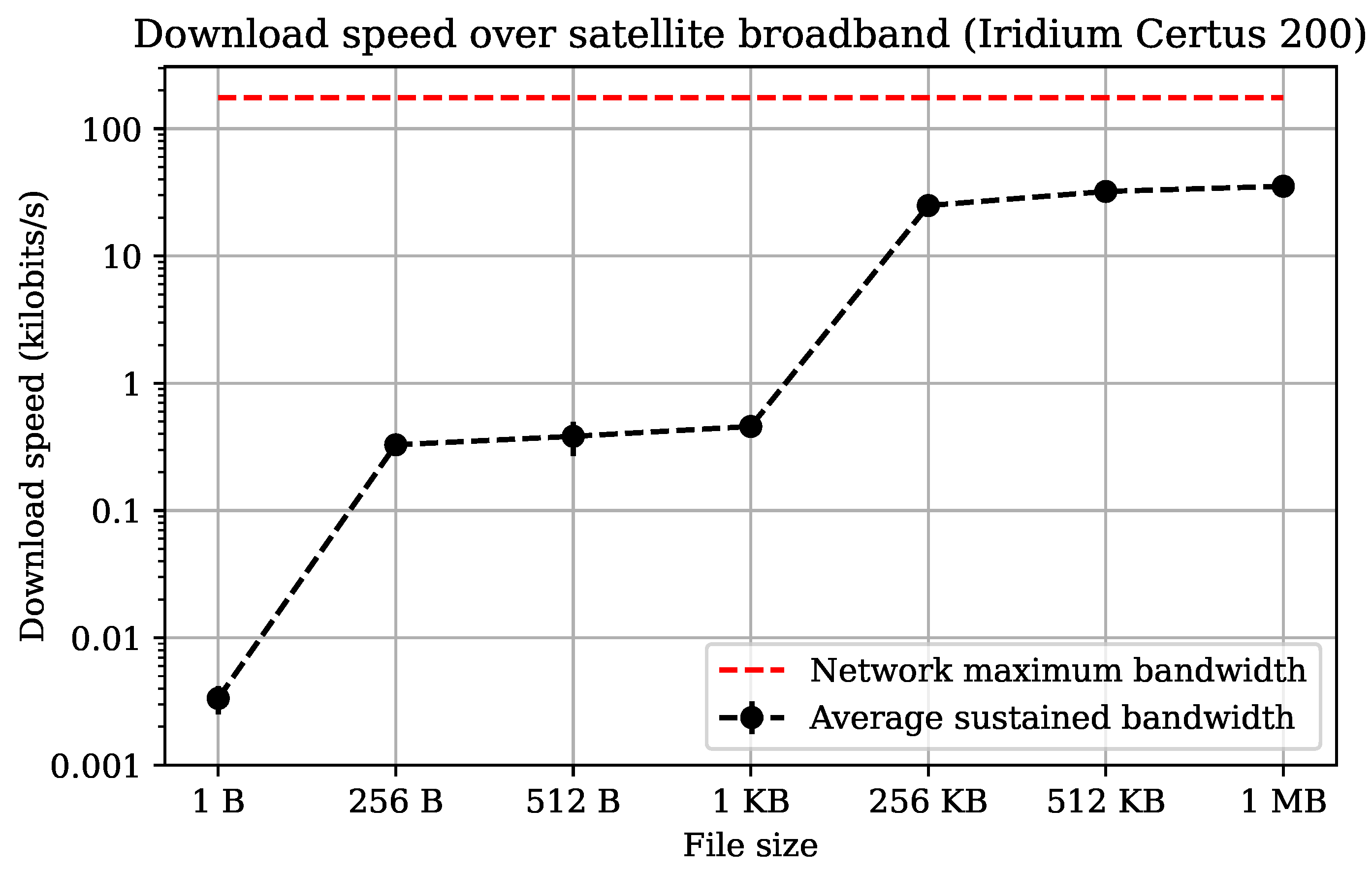
5.2.1. Experimental Setup
5.2.2. Results
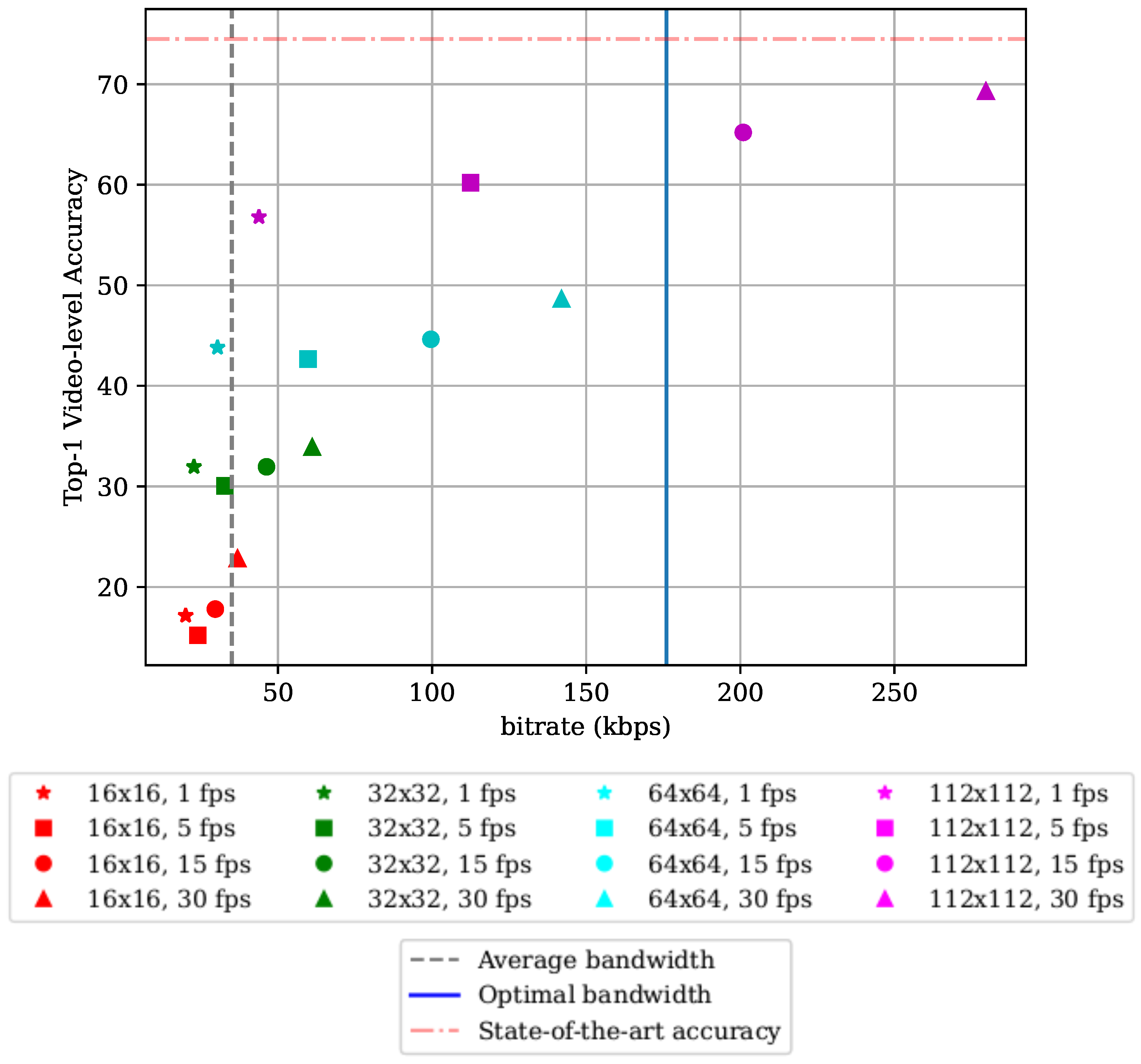
5.3. Machine Learning Workloads on the Edge vs. a Centralized Hub
5.3.1. Experimental Setup
5.3.2. Results
6. Related Work
6.1. Privacy-Preserving Surveillance
6.2. File Systems
6.3. Extensibility
6.4. Data Transmission
6.5. Centralized Data Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Satyanarayanan, M.; Simoens, P.; Xiao, Y.; Pillai, P.; Chen, Z.; Ha, K.; Hu, W.; Amos, B. Edge analytics in the internet of things. IEEE Pervasive Comput. 2015, 14, 24–31. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A survey on mobile edge networks: Convergence of computing, caching and communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards federated learning at scale: System design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Zhang, Y.; McQuillan, F.; Jayaram, N.; Kak, N.; Khanna, E.; Kislal, O.; Valdano, D.; Kumar, A. Distributed Deep Learning on Data Systems: A Comparative Analysis of Approaches. Proc. VLDB Endow. 2021, 14. Available online: http://www.vldb.org/pvldb/vol14/p1769-zhang.pdf (accessed on 12 October 2021).
- Nordmo, T.A.S.; Ovesen, A.B.; Johansen, H.D.; Riegler, M.A.; Halvorsen, P.; Johansen, D. Dutkat: A Multimedia System for Catching Illegal Catchers in a Privacy-Preserving Manner. In Proceedings of the 2021 Workshop on Intelligent Cross-Data Analysis and Retrieval, Taipei, Taiwan, 12–15 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 57–61. [Google Scholar]
- Costello, C.; Cao, L.; Gelcich, S.; Cisneros-Mata, M.Á.; Free, C.M.; Froehlich, H.E.; Golden, C.D.; Ishimura, G.; Maier, J.; Macadam-Somer, I.; et al. The future of food from the sea. Nature 2020, 588, 95–100. [Google Scholar] [CrossRef]
- UNODC. Fisheries Crime: Transnational Organized Criminal Activities in the Context of the Fisheries Sector; 2016. Available online: https://www.unodc.org/documents/about-unodc/Campaigns/Fisheries/focus_sheet_PRINT.pdf (accessed on 12 October 2021).
- Ingilæ, Ø. Fiskere settes under overvåkning. In Kyst og Fjord; 2020; Available online: https://www.kystogfjord.no/nyheter/forsiden/Fiskere-settes-under-overvaakning (accessed on 12 October 2021).
- Bizzotto, M. Fishing rules: Compulsory CCTV for certain vessels to counter infractions. In European Parliament Press Release; 2021; Available online: https://www.europarl.europa.eu/news/en/press-room/20210304IPR99227/fishing-rules-compulsory-cctv-for-certain-vessels-to-counter-infractions (accessed on 12 October 2021).
- Ministry of Trade, Industry and Fisheries. Framtidens Fiskerikontroll. NOU 19:21. 2019. Available online: https://www.advokatforeningen.no/aktuelt/horingsuttalelser/2020/mars/horing—nou-201921-framtidens-fiskerikontroll/ (accessed on 12 October 2021).
- Martinussen, T.M. Danske fiskere samler seg mot kamera-overvåkning i fiskeriene. Fiskeribladet. Available online: https://www.fiskeribladet.no/nyheter/danske-fiskere-samler-seg-mot-kamera-overvakning-i-fiskeriene/2-1-839478 (accessed on 12 October 2021).
- Van Helmond, A.T.; Mortensen, L.O.; Plet-Hansen, K.S.; Ulrich, C.; Needle, C.L.; Oesterwind, D.; Kindt-Larsen, L.; Catchpole, T.; Mangi, S.; Zimmermann, C. Electronic monitoring in fisheries: Lessons from global experiences and future opportunities. Fish Fish. 2020, 21, 162–189. [Google Scholar] [CrossRef]
- Carzaniga, A.; Rosenblum, D.S.; Wolf, A.L. Design and evaluation of a wide-area event notification service. ACM Trans. Comput. Syst. (TOCS) 2001, 19, 332–383. [Google Scholar] [CrossRef]
- Satyanarayanan, M.; Kistler, J.J.; Kumar, P.; Okasaki, M.E.; Siegel, E.H.; Steere, D.C. Coda: A highly available file system for a distributed workstation environment. IEEE Trans. Comput. 1990, 39, 447–459. [Google Scholar] [CrossRef] [Green Version]
- Johansen, D. StormCast: However, another exercise in distributed computing. Distrib. Open Syst. Perspect. 1993. Available online: https://munin.uit.no/bitstream/handle/10037/392/report.pdf?sequence=1&isAllowed=y (accessed on 12 October 2021).
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation). Off. J. Eur. Union 2016. Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 12 October 2021).
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google file system. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, Bolton Landing, NY, USA, 19–22 October 2003; pp. 29–43. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2004, 51, 107–113. [Google Scholar] [CrossRef]
- Johansen, H.D.; Birrell, E.; Van Renesse, R.; Schneider, F.B.; Stenhaug, M.; Johansen, D. Enforcing privacy policies with meta-code. In Proceedings of the 6th Asia-Pacific Workshop on Systems, Tokyo, Japan, 27–28 July 2015; pp. 1–7. [Google Scholar]
- FUSE—The Linux Kernel Documentation. Available online: https://www.kernel.org/doc/html/latest/filesystems/fuse.html (accessed on 30 August 2021).
- Vangoor, B.K.R.; Tarasov, V.; Zadok, E. To FUSE or not to FUSE: Performance of user-space file systems. In Proceedings of the 15th USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 27 February–2 March 2017; pp. 59–72. [Google Scholar]
- Iridium Certus 200. Available online: https://www.iridium.com/services/iridium-certus-200/ (accessed on 8 September 2021).
- Thales VesseLINK 200. Available online: https://www.thalesgroup.com/sites/default/files/database/document/2021-02/2807_V1_VesseLINK200_012021.pdf (accessed on 8 September 2021).
- Yu, L.; Chen, G.; Wang, W.; Dong, J. Msfss: A storage system for mass small files. In Proceedings of the 11th International Conference on Computer Supported Cooperative Work in Design, Melbourne, Australia, 26–28 April 2007; pp. 1087–1092. [Google Scholar]
- Thain, D.; Moretti, C. Efficient access to many small files in a filesystem for grid computing. In Proceedings of the 8th IEEE/ACM International Conference on Grid Computing, Austin, TX, USA, 19–21 September 2007; pp. 243–250. [Google Scholar]
- Gerard, M.; Bousquet, M. Satellite Communications Systems; Teubner: 1993. Available online: https://www.amazon.com/Satellite-Communications-Systems-Communication-Distributed/dp/0471971669 (accessed on 12 October 2021).
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. 2017. Available online: http://xxx.lanl.gov/abs/1705.06950 (accessed on 28 July 2021).
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc., 2019; pp. 8024–8035. Available online: https://papers.nips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf (accessed on 12 October 2021).
- Ashley, K. Applied Machine Learning for Health and Fitness; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Senior, A.; Pankanti, S.; Hampapur, A.; Brown, L.; Tian, Y.L.; Ekin, A.; Connell, J.; Shu, C.F.; Lu, M. Enabling video privacy through computer vision. IEEE Secur. Priv. 2005, 3, 50–57. [Google Scholar] [CrossRef]
- Newton, E.M.; Sweeney, L.; Malin, B. Preserving privacy by de-identifying face images. IEEE Trans. Knowl. Data Eng. 2005, 17, 232–243. [Google Scholar] [CrossRef] [Green Version]
- Boult, T.E. PICO: Privacy through invertible cryptographic obscuration. In Proceedings of the Computer Vision for Interactive and Intelligent Environment (CVIIE), Lexington, KY, USA, 17–18 November 2005; pp. 27–38. [Google Scholar]
- Schiff, J.; Meingast, M.; Mulligan, D.K.; Sastry, S.; Goldberg, K. Respectful cameras: Detecting visual markers in real-time to address privacy concerns. In Protecting Privacy in Video Surveillance; Springer: Berlin/Heidelberg, Germany, 2009; pp. 65–89. [Google Scholar]
- Zadok, E.; Badulescu, I.; Shender, A. Cryptfs: A stackable vnode level encryption file system. In Technical Report, Technical Report CUCS-021-98; Computer Science Department, Columbia University, 1998; Available online: https://academiccommons.columbia.edu/doi/10.7916/D82N5935 (accessed on 12 October 2021).
- Halcrow, M.A. eCryptfs: An enterprise-class encrypted filesystem for linux. In Proceedings of the 2005 Linux Symposium, Ottawa, ON, Canada, 20–23 July 2005; Volume 1, pp. 201–218. [Google Scholar]
- VeraCrypt—Free Open Source Disk Encryption Software. Available online: https://veracrypt.fr/ (accessed on 15 August 2021).
- EncFS—An Encrypted Filesystem. Available online: https://vgough.github.io/encfs/ (accessed on 15 August 2021).
- Gocryptfs—Simple. Secure. Fast. Available online: https://nuetzlich.net/gocryptfs/ (accessed on 15 August 2021).
- Filesystem in Userspace (FUSE) with Transparent Authenticated Encryption. Available online: https://github.com/netheril96/securefs/ (accessed on 15 August 2021).
- Zadok, E.; Iyer, R.; Joukov, N.; Sivathanu, G.; Wright, C.P. On incremental file system development. ACM Trans. Storage (TOS) 2006, 2, 161–196. [Google Scholar] [CrossRef]
- Hartvigsen, G.; Johansen, D. Co-operation in a distributed artificial intelligence environment—The stormcast application. Eng. Appl. Artif. Intell. 1990, 3, 229–237. [Google Scholar] [CrossRef]
- Johansen, D.; Van Renesse, R.; Schneider, F.B. Operating system support for mobile agents. In Proceedings of the 5th Workshop on Hot Topics in Operating Systems (HotOS-V), Orcas Island, WA, USA, 4–5 May 1995; pp. 42–45. [Google Scholar]
- Nordal, A.; Kvalnes, Å.; Hurley, J.; Johansen, D. Balava: Federating private and public clouds. In Proceedings of the 2011 IEEE World Congress on Services, Washington, DC, USA, 4–9 July 2011; pp. 569–577. [Google Scholar]
- Gurrin, C.; Aarflot, T.; Johansen, D. GARDI: A Self-Regulating Framework for Digital Libraries. In Proceedings of the IEEE International Conference on Computer and Information Technology, Xiamen, China, 11–14 October 2009; pp. 305–310. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Ng, S. Principal component analysis to reduce dimension on digital image. Procedia Comput. Sci. 2017, 111, 113–119. [Google Scholar] [CrossRef]
- McCarthy, J.D.; Sasse, M.A.; Miras, D. Sharp or Smooth? Comparing the Effects of Quantization vs. Frame Rate for Streamed Video. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vienna, Austria, 24–29 April 2004; pp. 535–542. [Google Scholar]
- AI Can See Clearly Now: GANs Take the Jitters Out of Video Calls. Available online: https://blogs.nvidia.com/blog/2020/10/05/gan-video-conferencing-maxine/ (accessed on 8 September 2021).
- Wang, T.C.; Mallya, A.; Liu, M.Y. One-shot free-view neural talking-head synthesis for video conferencing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10039–10049. [Google Scholar]
- Fitwi, A.; Chen, Y.; Zhu, S.; Blasch, E.; Chen, G. Privacy-Preserving Surveillance as an Edge Service Based on Lightweight Video Protection Schemes Using Face De-Identification and Window Masking. Electronics 2021, 10, 236. [Google Scholar] [CrossRef]
- Dsouza, S.; Bahl, V.; Ao, L.; Cox, L.P. Amadeus: Scalable, Privacy-Preserving Live Video Analytics. arXiv 2020, arXiv:2011.05163. [Google Scholar]
- Rocha Neto, A.; Silva, T.P.; Batista, T.; Delicato, F.C.; Pires, P.F.; Lopes, F. Leveraging Edge Intelligence for Video Analytics in Smart City Applications. Information 2021, 12, 14. [Google Scholar]
- Hosseini, M.P.; Tran, T.X.; Pompili, D.; Elisevich, K.; Soltanian-Zadeh, H. Multimodal data analysis of epileptic EEG and rs-fMRI via deep learning and edge computing. Artif. Intell. Med. 2020, 104, 101813. [Google Scholar] [CrossRef]
- Lu, R.; Cai, Y.; Zhu, J.; Nie, F.; Yang, H. Dimension reduction of multimodal data by auto-weighted local discriminant analysis. Neurocomputing 2021, 461, 27–40. [Google Scholar] [CrossRef]
- Zhai, Y.; Ye, Q.; Lu, S.; Jia, M.; Ji, R.; Tian, Y. Multiple expert brainstorming for domain adaptive person re-identification. In Proceedings of the 16th European Conference on Computer Vision, Part VII, Glasgow, UK, 23–28 August 2020; pp. 594–611. [Google Scholar]
- Zhang, W.; Yang, D.; Zhang, S.; Ablanedo-Rosas, J.H.; Wu, X.; Lou, Y. A novel multi-stage ensemble model with enhanced outlier adaptation for credit scoring. Expert Syst. Appl. 2021, 165, 113872. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ovesen, A.B.; Nordmo, T.-A.S.; Johansen, H.D.; Riegler, M.A.; Halvorsen, P.; Johansen, D. File System Support for Privacy-Preserving Analysis and Forensics in Low-Bandwidth Edge Environments. Information 2021, 12, 430. https://doi.org/10.3390/info12100430
Ovesen AB, Nordmo T-AS, Johansen HD, Riegler MA, Halvorsen P, Johansen D. File System Support for Privacy-Preserving Analysis and Forensics in Low-Bandwidth Edge Environments. Information. 2021; 12(10):430. https://doi.org/10.3390/info12100430
Chicago/Turabian StyleOvesen, Aril Bernhard, Tor-Arne Schmidt Nordmo, Håvard Dagenborg Johansen, Michael Alexander Riegler, Pål Halvorsen, and Dag Johansen. 2021. "File System Support for Privacy-Preserving Analysis and Forensics in Low-Bandwidth Edge Environments" Information 12, no. 10: 430. https://doi.org/10.3390/info12100430
APA StyleOvesen, A. B., Nordmo, T.-A. S., Johansen, H. D., Riegler, M. A., Halvorsen, P., & Johansen, D. (2021). File System Support for Privacy-Preserving Analysis and Forensics in Low-Bandwidth Edge Environments. Information, 12(10), 430. https://doi.org/10.3390/info12100430