
Missing Data Imputation in Internet of Things Gateways


Abstract
:1. Introduction
2. Related Work
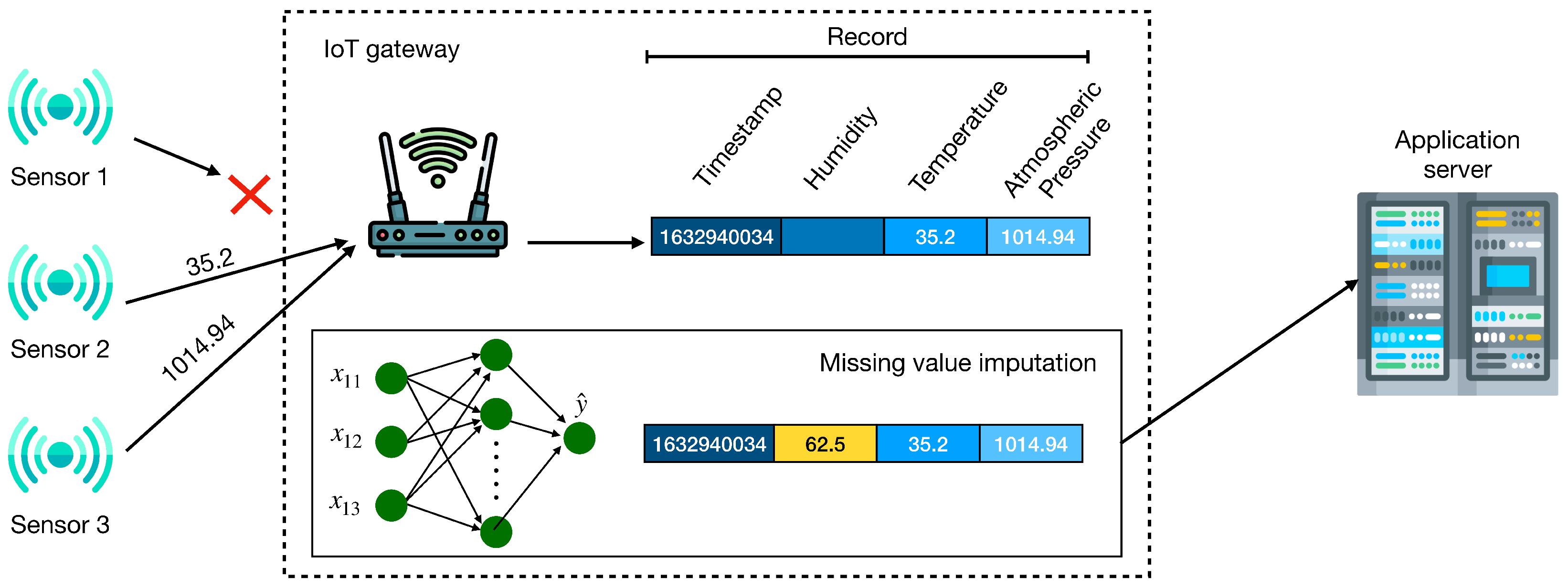
3. Imputation Method Based on Neural Networks
4. Evaluation Methodology
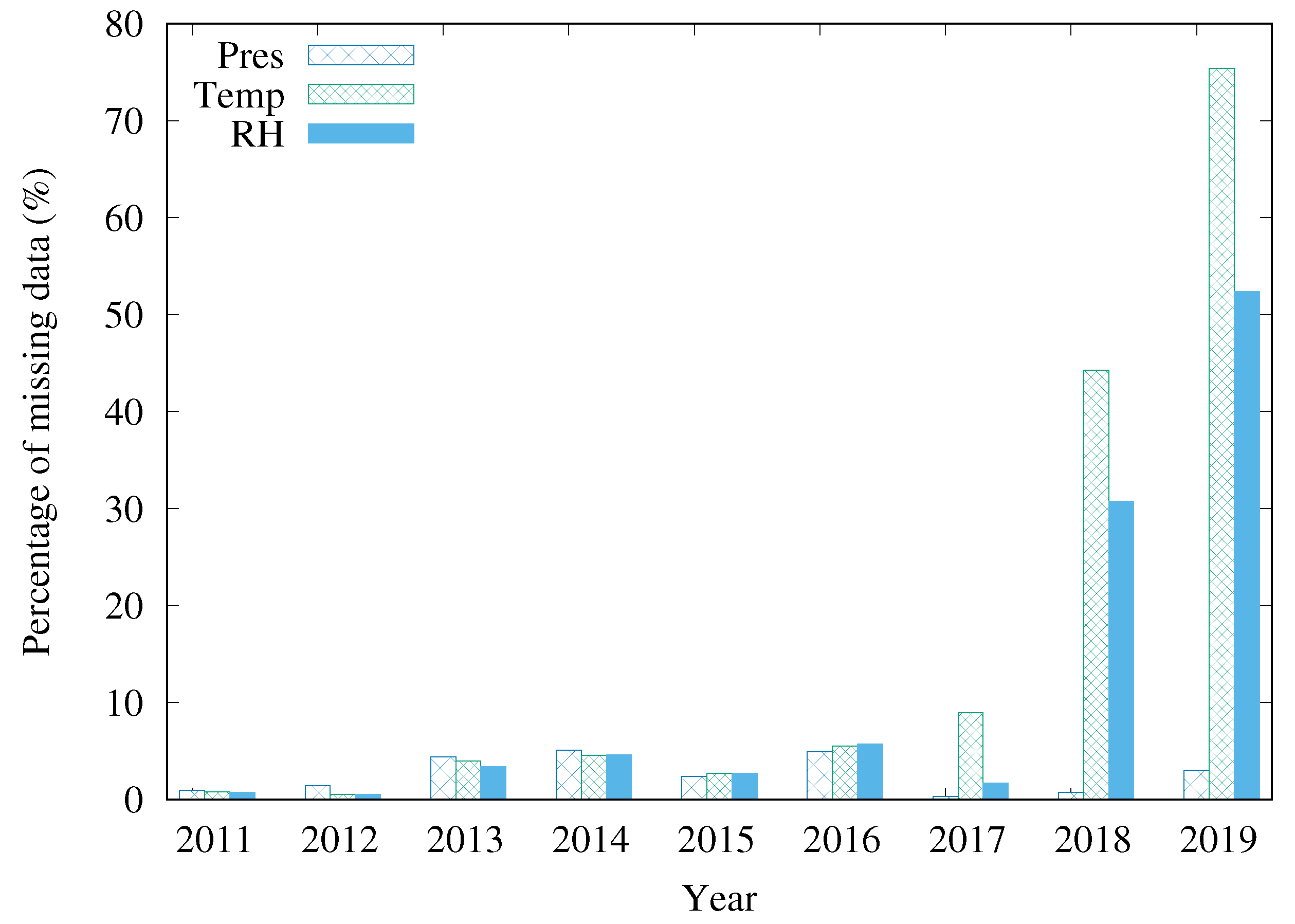
4.1. MonitorAr Dataset
4.2. Missing Data Insertion
4.3. Baseline Imputation Methods
- Average ()—we replace the missing value with the average of all previously received values for the corresponding attribute;
- Average of input data ()—we replace the missing value with the average of inputs (i.e., the average of the last three measures of the corresponding attribute);
- Average of input data ()—we replace the missing value with the average of inputs (i.e., the average of the last three measures and the previous day’s value at the same hour of the corresponding attribute);
- Repetition of the last received value ()—we replace the missing value with the last received value of the corresponding attribute.
5. Results
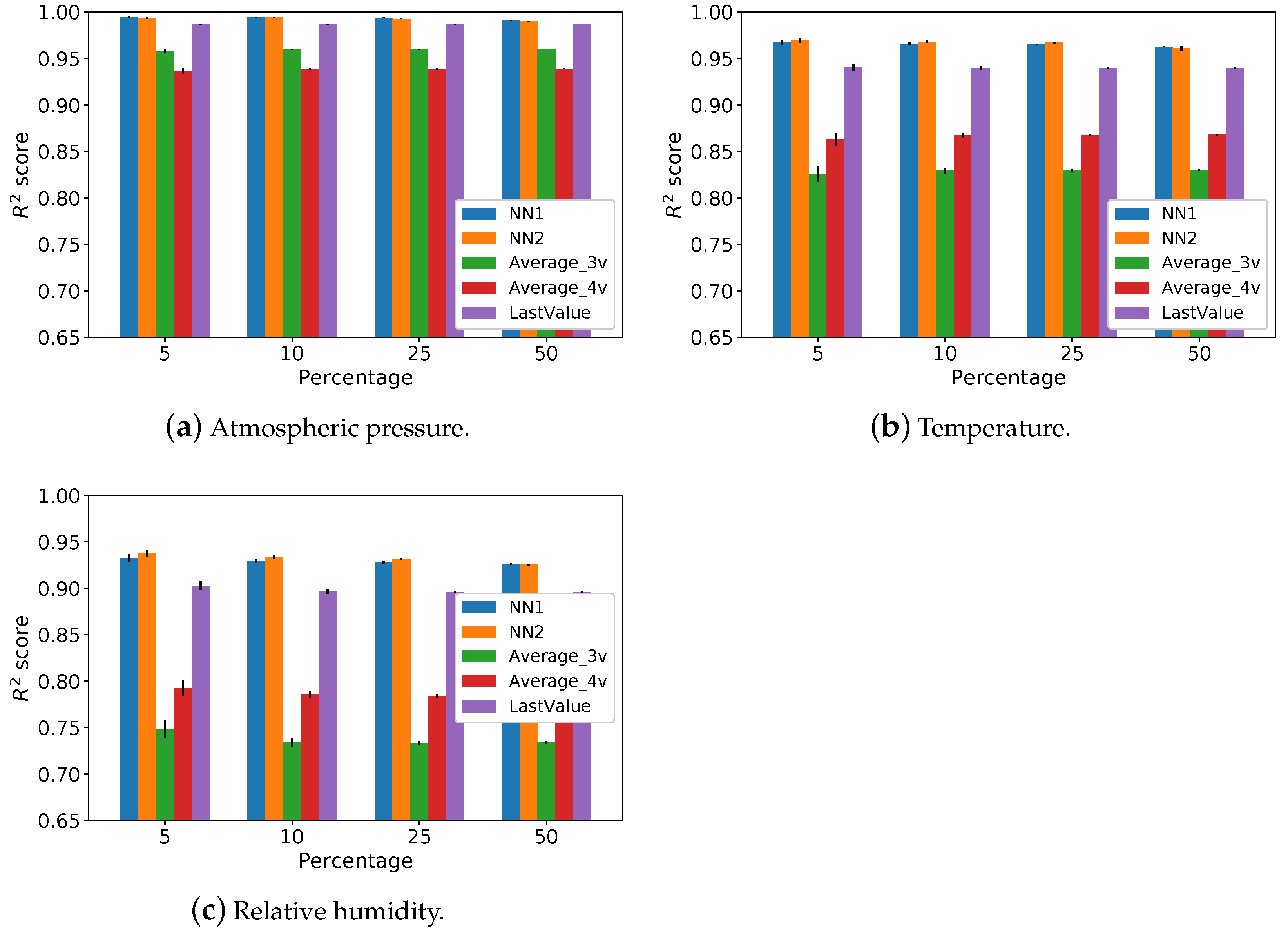
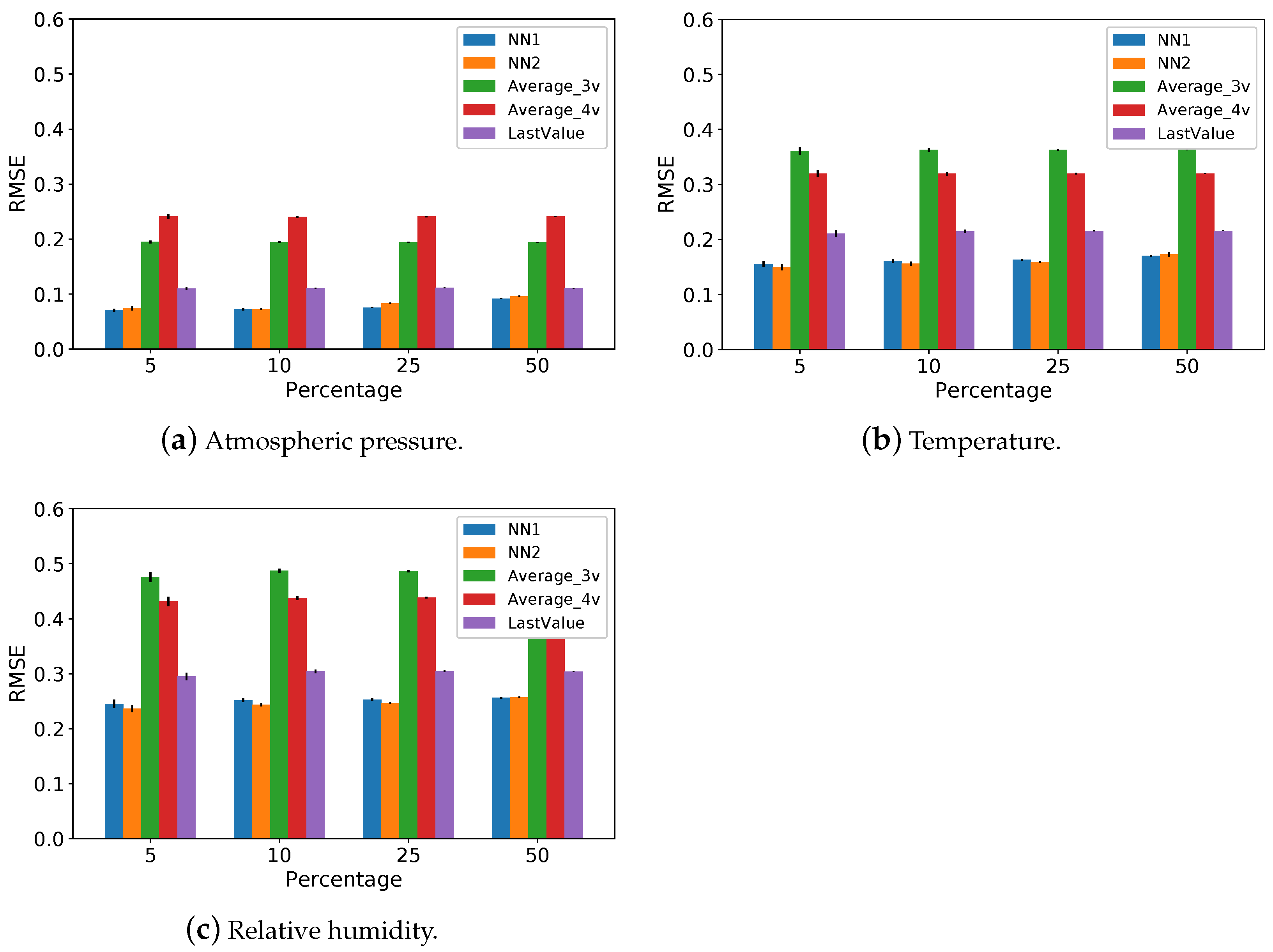
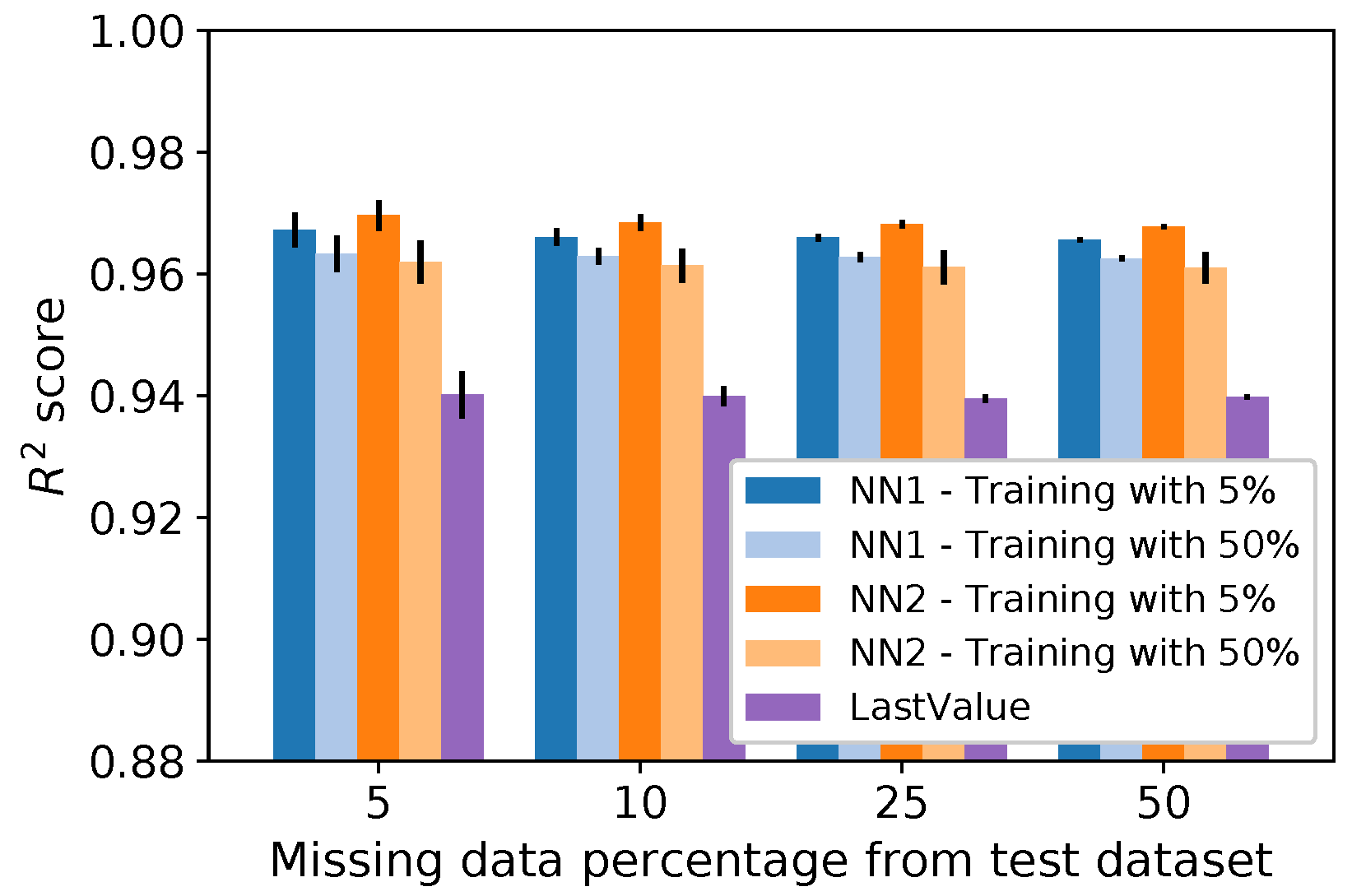
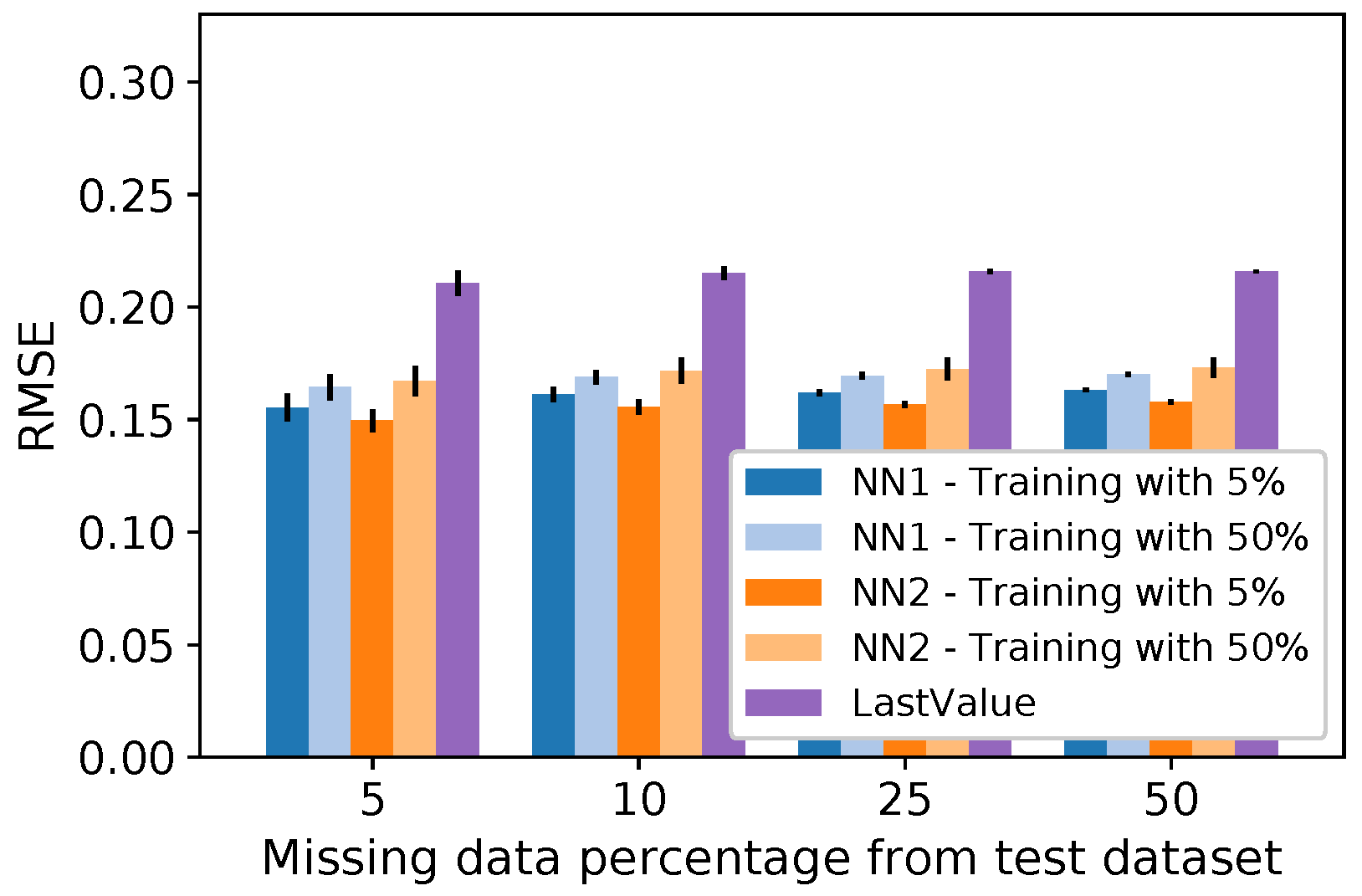
5.1. Imputation Methods Performance
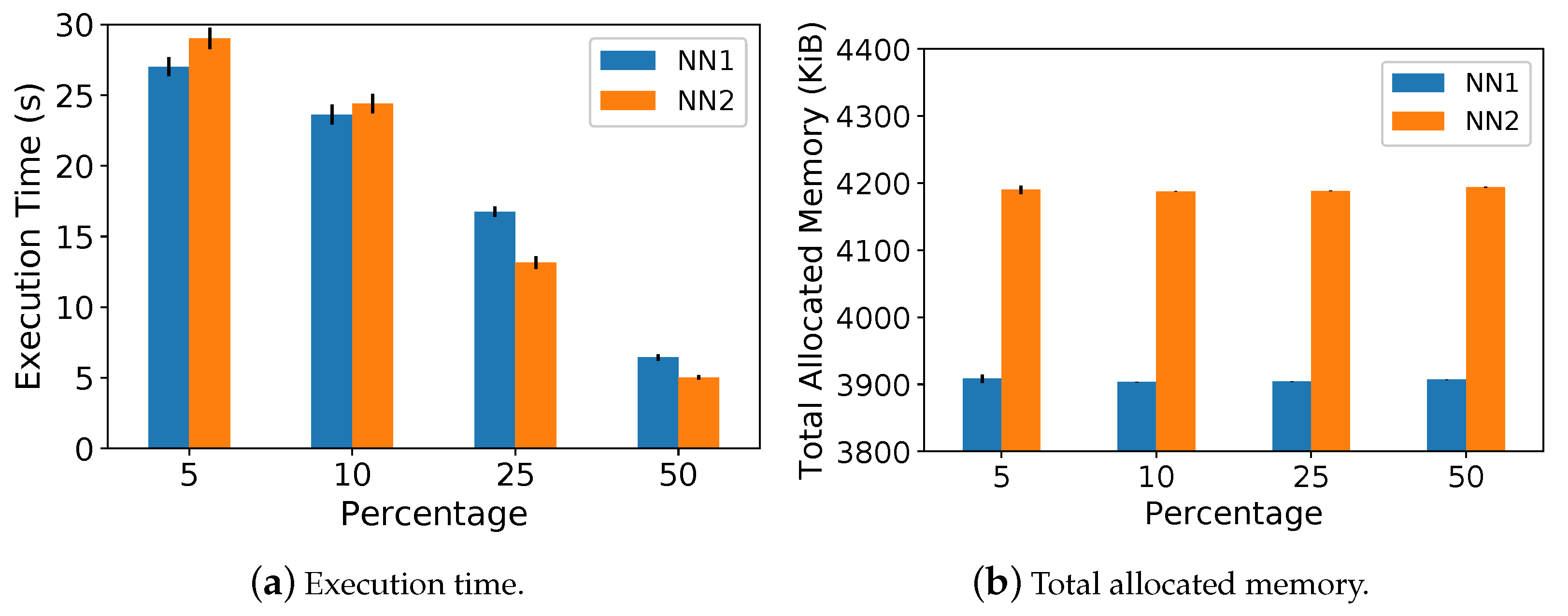
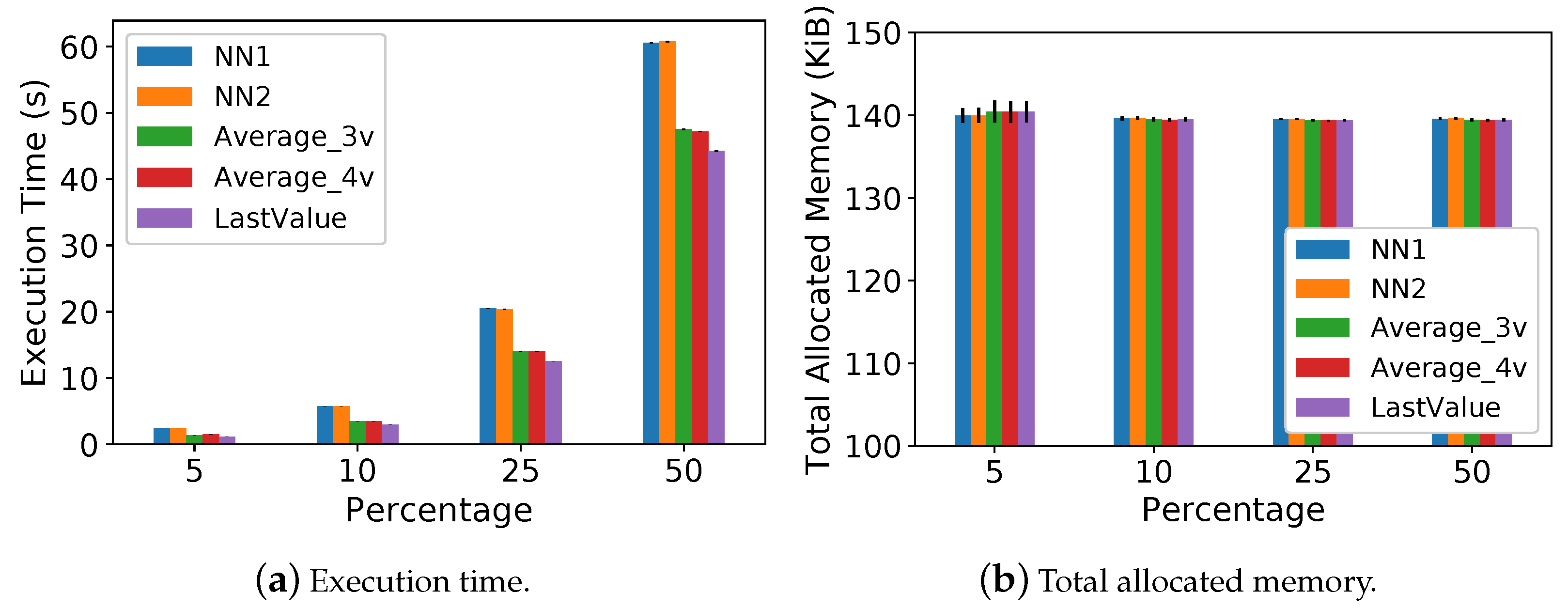
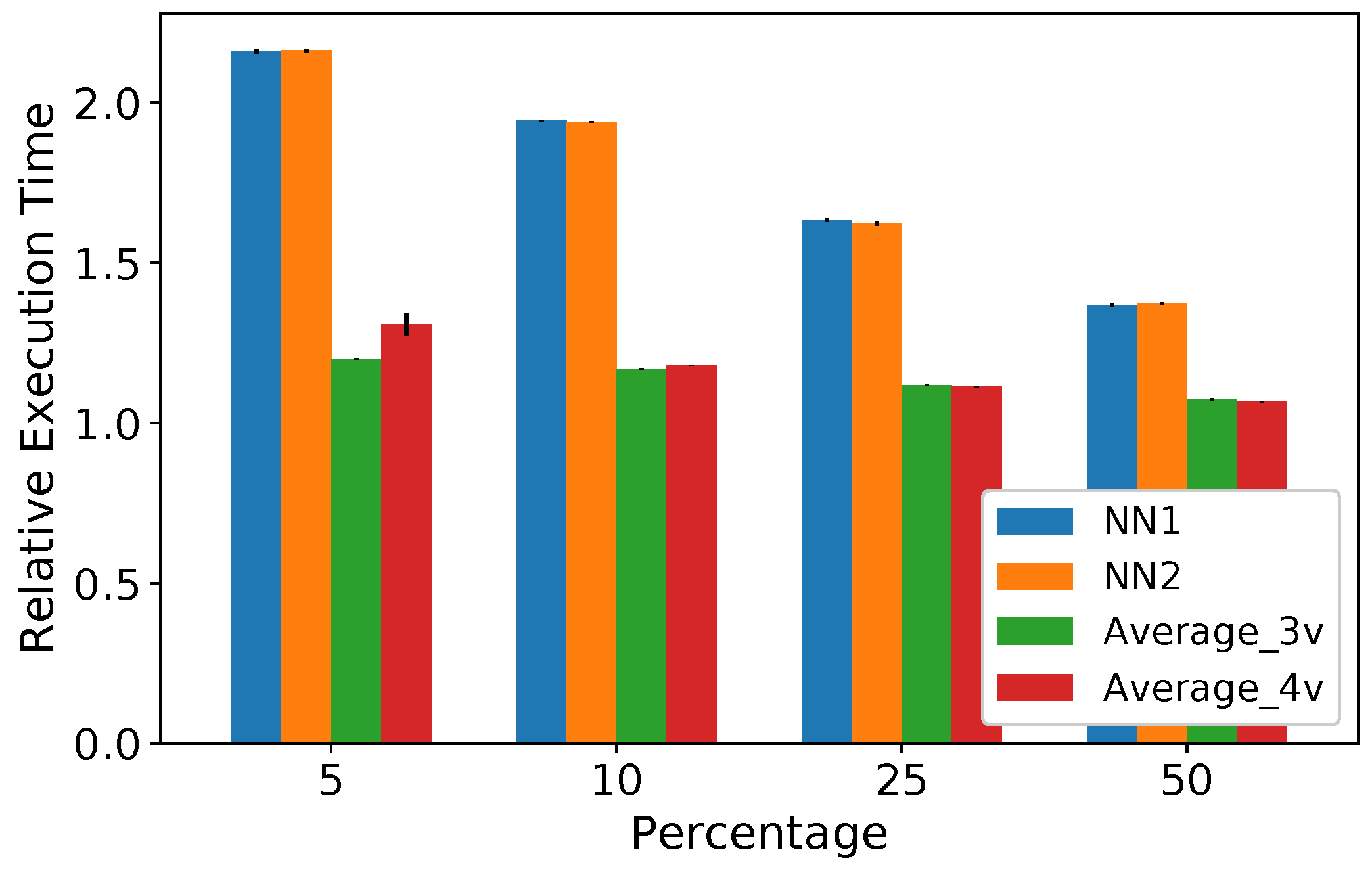
5.2. Execution Time and Memory Usage Analysis
5.3. Neural Network Training Analysis
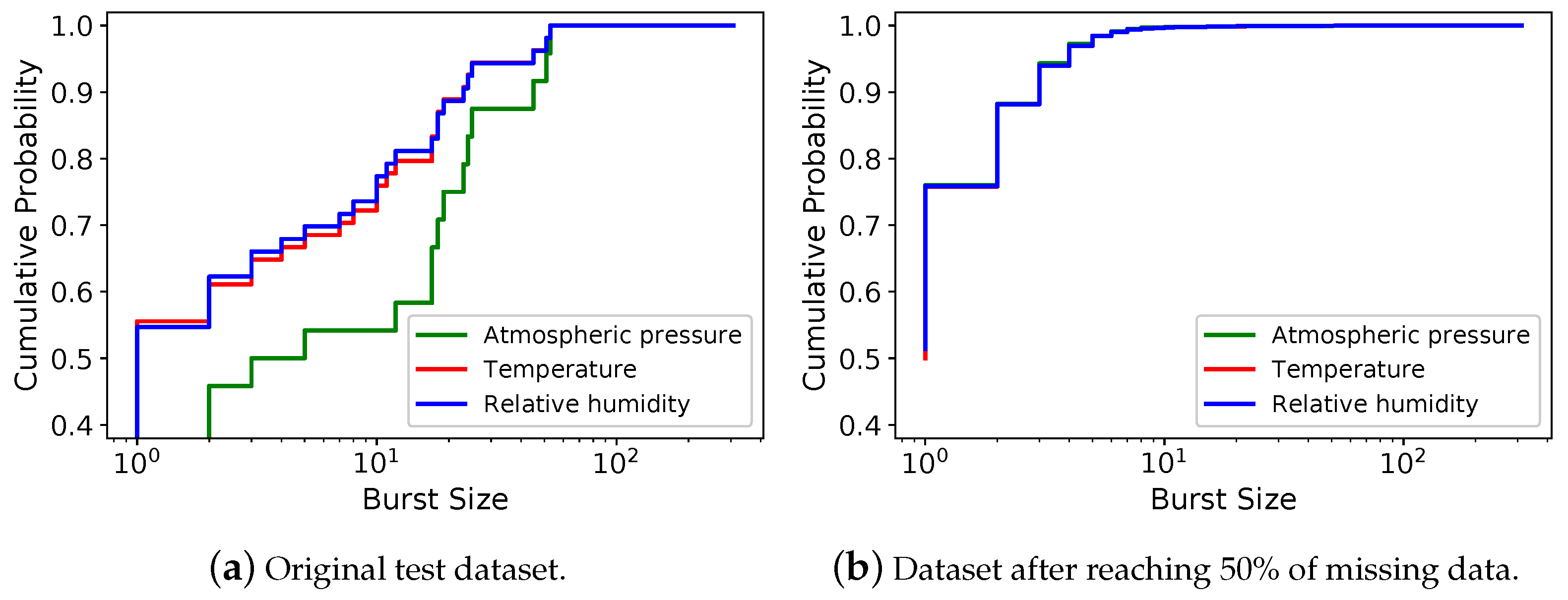
5.4. Case Study—Clustering Application
- After imputing missing data, records previously considered valid become outlier;
- PosInf sets have the same outliers as ;
- Any record considered an outlier is no longer an outlier after imputing missing data;
- Records with predicted values are defined as outliers by DBSCAN.
6. Discussion
- Analysis of and methods. These methods have the same input data as the neural networks, however, the estimated value is the average of the inputs. Our goal in adding these methods is to verify whether it is indispensable to train a neural network or if a simple average of the same input data already provides good predictions. Our results indicate that and outperforms and , thus justifying the use of neural networks;
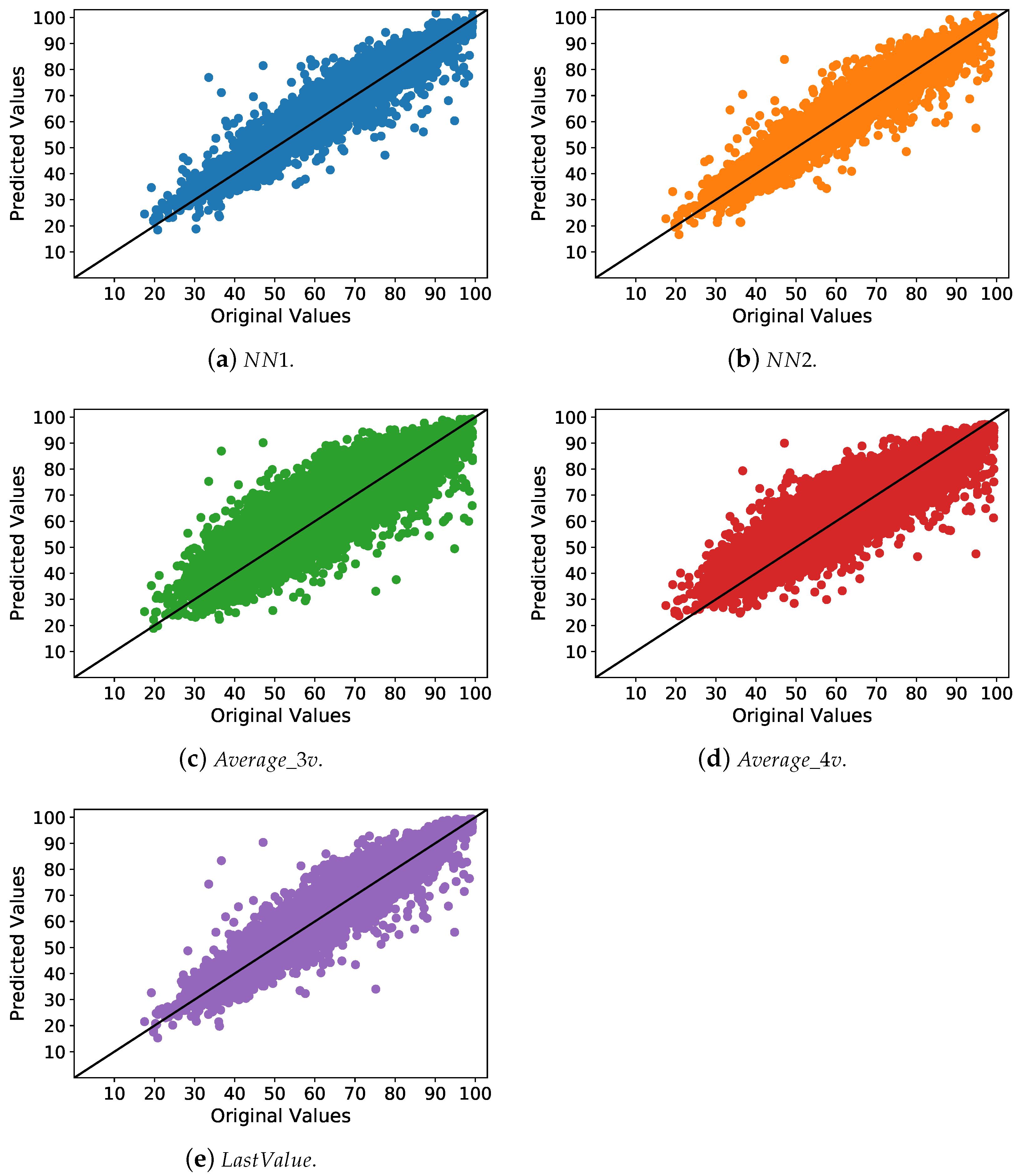
- Analysis comparing the original values with the predicted ones for all methods, as shown in Figure 6. Our idea is to analyze the results from another perspective, to add more consistency to our findings. Hence, this new analysis allows the graphical visualization of our performance improvements. This analysis has shown that and present predicted values closer to the original ones than the other methods.
- Analysis summarizing our main findings in Table 6. This table highlights the importance of and , showing that these methods present the best prediction performance and produce few outliers in a clustering application.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Correia, L.; Fuentes, D.; Ribeiro, J.; Costa, N.; Reis, A.; Rabadão, C.; Barroso, J.; Pereira, A. Usability of Smartbands by the Elderly Population in the Context of Ambient Assisted Living Applications. Electronics 2021, 10, 1617. [Google Scholar] [CrossRef]
- Santos, S.C.; Firmino, R.M.; Mattos, D.M.; Medeiros, D.S. An IoT rainfall monitoring application based on wireless communication technologies. In Proceedings of the 4th Conference on Cloud and Internet of Things (CIoT), Niterói, Brazil, 7–9 October 2020; pp. 53–56. [Google Scholar]
- Siddique, K.; Akhtar, Z.; Lee, H.g.; Kim, W.; Kim, Y. Toward bulk synchronous parallel-based machine learning techniques for anomaly detection in high-speed big data networks. Symmetry 2017, 9, 197. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.Y.; Jeong, Y.S.; Kim, S. Data-filtering system to avoid total data distortion in IoT networking. Symmetry 2017, 9, 16. [Google Scholar] [CrossRef] [Green Version]
- Gantert, L.; Sammarco, M.; Detyniecki, M.; Campista, M.E.M. A supervised approach for corrective maintenance using spectral features from industrial sounds. In Proceedings of the IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LO, USA, 14 June–31 July 2021. [Google Scholar]
- Cruz, P.; Silva, F.F.; Pacheco, R.G.; Couto, R.S.; Velloso, P.B.; Campista, M.E.M.; Costa, L.H.M.K. SensingBus: Using Bus Lines and Fog Computing for Smart Sensing the City. IEEE Cloud Comput. 2018, 5, 58–69. [Google Scholar] [CrossRef]
- Schmitt, P.; Mandel, J.; Guedj, M. A comparison of six methods for missing data imputation. J. Biom. Biostat. 2015, 6, 1–6. [Google Scholar]
- Yan, X.; Xiong, W.; Hu, L.; Wang, F.; Zhao, K. Missing value imputation based on gaussian mixture model for the internet of things. Math. Probl. Eng. 2015, 2015, 548605. [Google Scholar] [CrossRef]
- Liu, Y.; Dillon, T.; Yu, W.; Rahayu, W.; Mostafa, F. Missing value imputation for Industrial IoT sensor data with large gaps. IEEE Internet Things J. 2020, 7, 6855–6867. [Google Scholar] [CrossRef]
- Al-Milli, N.; Almobaideen, W. Hybrid neural network to impute missing data for IoT applications. In Proceedings of the IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019. [Google Scholar]
- Purohit, L.; Kumar, S. Web services in the internet of things and smart cities: A case study on classification techniques. IEEE Consum. Electron. Mag. 2019, 8, 39–43. [Google Scholar] [CrossRef]
- Guastella, D.A.; Marcillaud, G.; Valenti, C. Edge-Based Missing Data Imputation in Large-Scale Environments. Information 2021, 12, 195. [Google Scholar] [CrossRef]
- Pan, J.; Yang, Z. Cybersecurity Challenges and Opportunities in the New “Edge Computing+IoT” World. In Proceedings of the 2018 ACM International Workshop on Security in Software Defined Networks & Network Function Virtualization, Tempe, AZ, USA, 21 March 2018. [Google Scholar]
- Fekade, B.; Maksymyuk, T.; Kyryk, M.; Jo, M. Probabilistic recovery of incomplete sensed data in IoT. IEEE Internet Things J. 2017, 5, 2282–2292. [Google Scholar] [CrossRef]
- Li, D.; Deogun, J.; Spaulding, W.; Shuart, B. Towards missing data imputation: A study of fuzzy k-means clustering method. In International Conference on Rough Sets and Current Trends in Computing; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Mary, I.P.S.; Arockiam, L. Imputing the missing data in IoT based on the spatial and temporal correlation. In Proceedings of the IEEE International Conference on Current Trends in Advanced Computing (ICCTAC), Bangalore, India, 2–3 March 2017. [Google Scholar]
- Guzel, M.; Kok, I.; Akay, D.; Ozdemir, S. ANFIS and Deep Learning based missing sensor data prediction in IoT. Concurr. Comput. Pract. Exp. 2020, 32, e5400. [Google Scholar] [CrossRef]
- Nikfalazar, S.; Yeh, C.H.; Bedingfield, S.; Khorshidi, H.A. Missing data imputation using decision trees and fuzzy clustering with iterative learning. Knowl. Inf. Syst. 2020, 62, 2419–2437. [Google Scholar] [CrossRef]
- Kök, İ.; Özdemir, S. DeepMDP: A Novel Deep-Learning-Based Missing Data Prediction Protocol for IoT. IEEE Internet Things J. 2020, 8, 232–243. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Thorburn, P.J.; Xiang, W.; Fitch, P. SSIM—A deep learning approach for recovering missing time series sensor data. IEEE Internet Things J. 2019, 6, 6618–6628. [Google Scholar] [CrossRef]
- Turabieh, H.; Salem, A.A.; Abu-El-Rub, N. Dynamic L-RNN recovery of missing data in IoMT applications. Future Gener. Comput. Syst. 2018, 89, 575–583. [Google Scholar] [CrossRef]
- Izonin, I.; Kryvinska, N.; Tkachenko, R.; Zub, K. An approach towards missing data recovery within IoT smart system. Procedia Comput. Sci. 2019, 155, 11–18. [Google Scholar] [CrossRef]
- França, C.M.; Couto, R.S.; Velloso, P.B. Data imputation on IoT gateways using machine learning. In Proceedings of the 19th Mediterranean Communication and Computer Networking Conference (MedComNet), Ibiza, Spain, 15–17 June 2021. [Google Scholar]
- Chong, A.; Lam, K.P.; Xu, W.; Karaguzel, O.T.; Mo, Y. Imputation of missing values in building sensor data. Proc. Simbuild 2016, 6, 407–414. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Honghai, F.; Guoshun, C.; Cheng, Y.; Bingru, Y.; Yumei, C. A SVM regression based approach to filling in missing values. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Azimi, I.; Pahikkala, T.; Rahmani, A.M.; Niela-Vilén, H.; Axelin, A.; Liljeberg, P. Missing data resilient decision-making for healthcare IoT through personalization: A case study on maternal health. Future Gener. Comput. Syst. 2019, 96, 297–308. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- González-Vidal, A.; Rathore, P.; Rao, A.S.; Mendoza-Bernal, J.; Palaniswami, M.; Skarmeta-Gómez, A.F. Missing Data Imputation with Bayesian Maximum Entropy for Internet of Things Applications. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Izonin, I.; Kryvinska, N.; Vitynskyi, P.; Tkachenko, R.; Zub, K. GRNN approach towards missing data recovery between IoT systems. In International Conference on Intelligent Networking and Collaborative Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 445–453. [Google Scholar]
- Drucker, H. Improving regressors using boosting techniques. In ICML; Citeseer: Nashville, TN, USA, 1997; Volume 97, pp. 107–115. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparison of ARIMA and LSTM in forecasting time series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Wang, C.; Shakhovska, N.; Sachenko, A.; Komar, M. A New Approach for Missing Data Imputation in Big Data Interface. Inf. Technol. Control 2020, 49, 541–555. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Raza, S.M.; Jeong, J.; Kim, M.; Kang, B.; Choo, H. Empirical Performance and Energy Consumption Evaluation of Container Solutions on Resource Constrained IoT Gateways. Sensors 2021, 21, 1378. [Google Scholar] [CrossRef]
- Glória, A.; Cercas, F.; Souto, N. Design and implementation of an IoT gateway to create smart environments. Procedia Comput. Sci. 2017, 109, 568–575. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 1996, 96, 226–231. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Computation | Uses Neighbor Sensors’ Data | Used Approach | Uses Only Previous Data | Analyzes Time | Analyzes Memory |
|---|---|---|---|---|---|---|
| [8] | Not defined | - | Statistical (GMM and EM) | - | - | - |
| [9] | Cloud | - | Statistical (STL) | - | - | - |
| [12] | Edge | ✓ | Statistical | ✓ | - | - |
| [16] | Not defined | ✓ | Statistical (PCC) | - | - | - |
| [27] | Edge and Cloud | ✓ | Statistical | - | - | - |
| [28] | Not defined | - | Statistical | - | - | - |
| [29] | Edge and Cloud | ✓ | Statistical (BME) | - | ✓ | - |
| [30] | Not defined | - | Machine learning (GRNN) | - | ✓ | - |
| [14] | Not defined | - | Machine learning (K-means) and Statistical (PMF) | - | ✓ | - |
| [15] | Not defined | ✓ | Machine learning (fuzzy K-means) | - | - | - |
| [17] | Not defined | ✓ | Machine learning (recurrent neural network) and fuzzy logic | - | ✓ | - |
| [18] | Not defined | ✓ | Machine learning (decision tree and Fuzzy K-means) | - | ✓ | - |
| [19] | Edge and Cloud | ✓ | Machine learning (recurrent neural network) and fuzzy logic | - | - | - |
| [20] | Not defined | - | Machine learning (recurrent neural network) | - | - | - |
| [21] | Not defined | ✓ | Machine learning (recurrent neural network) | - | - | - |
| [34] | Not defined | - | Functional dependencies and association rules | - | ✓ | - |
| [10] | Not defined | - | Machine learning (recurrent neural network) and optimization (genetic algorithm) | - | - | - |
| This work | Edge | - | Machine learning (neural network—MLP) | ✓ | ✓ | ✓ |
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| hidden_layer_sizes | 100 | validation_fraction | 0.1 |
| activation | ReLU | tol | 0.0001 |
| solver | Adam | random_state | 1 |
| learning_rate_init | 1 | alpha | 0.0001 |
| batch_size | beta_1 | 0.9 | |
| max_iter | 500 | beta_2 | 999 |
| early_stopping | True | epsilon | 1 × 10 |
| n_iter_no_change | 4 | shuffle | True |
| min_points | PosInf- NN1 | PosInf- NN2 | PosInf- Average_3v | PosInf- Average_4v | PosInf- LastValue |
|---|---|---|---|---|---|
| 24 | 93.98 | 95.83 | 95.83 | 97.22 | 95.37 |
| 72 | 99.52 | 100.00 | 99.03 | 98.55 | 99.03 |
| 120 | 98.78 | 99.39 | 98.78 | 99.39 | 98.17 |
| 240 | 100.00 | 100.00 | 98.59 | 100.00 | 98.59 |
| 720 | 98.92 | 98.92 | 94.62 | 94.62 | 97.85 |
| Dataset | Total | Outliers | New Outliers |
|---|---|---|---|
| DropTest | 16,777 | 207 | - |
| PosInf-NN1 | 17,544 | 217 | 11 |
| PosInf-NN2 | 17,544 | 215 | 8 |
| PosInf-Average_3v | 17,544 | 219 | 14 |
| PosInf-Average_4v | 17,544 | 208 | 4 |
| PosInf-LastValue | 17,544 | 222 | 17 |
| min_points | PosInf- NN1 | PosInf- NN2 | PosInf- Average_3v | PosInf- Average_4v | PosInf- LastValue |
|---|---|---|---|---|---|
| 24 | 2.09 | 1.30 | 1.96 | 0.52 | 2.22 |
| 72 | 1.43 | 1.04 | 1.83 | 0.52 | 2.22 |
| 120 | 1.04 | 0.78 | 1.43 | 0.26 | 1.96 |
| 240 | 0.78 | 0.65 | 1.43 | 0.13 | 1.69 |
| 720 | 0.26 | 0.26 | 0.00 | 0.00 | 0.65 |
| Method | RMSE | Produce Few Outliers? | |
|---|---|---|---|
| NN1 |  | | |
| NN2 | | | |
| Average_3v |  | | |
| Average_4v | | | |
| LastValue | | | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
França, C.M.; Couto, R.S.; Velloso, P.B. Missing Data Imputation in Internet of Things Gateways. Information 2021, 12, 425. https://doi.org/10.3390/info12100425
França CM, Couto RS, Velloso PB. Missing Data Imputation in Internet of Things Gateways. Information. 2021; 12(10):425. https://doi.org/10.3390/info12100425
Chicago/Turabian StyleFrança, Cinthya M., Rodrigo S. Couto, and Pedro B. Velloso. 2021. "Missing Data Imputation in Internet of Things Gateways" Information 12, no. 10: 425. https://doi.org/10.3390/info12100425
APA StyleFrança, C. M., Couto, R. S., & Velloso, P. B. (2021). Missing Data Imputation in Internet of Things Gateways. Information, 12(10), 425. https://doi.org/10.3390/info12100425