Double Deep Autoencoder for Heterogeneous Distributed Clustering

Abstract
:1. Introduction
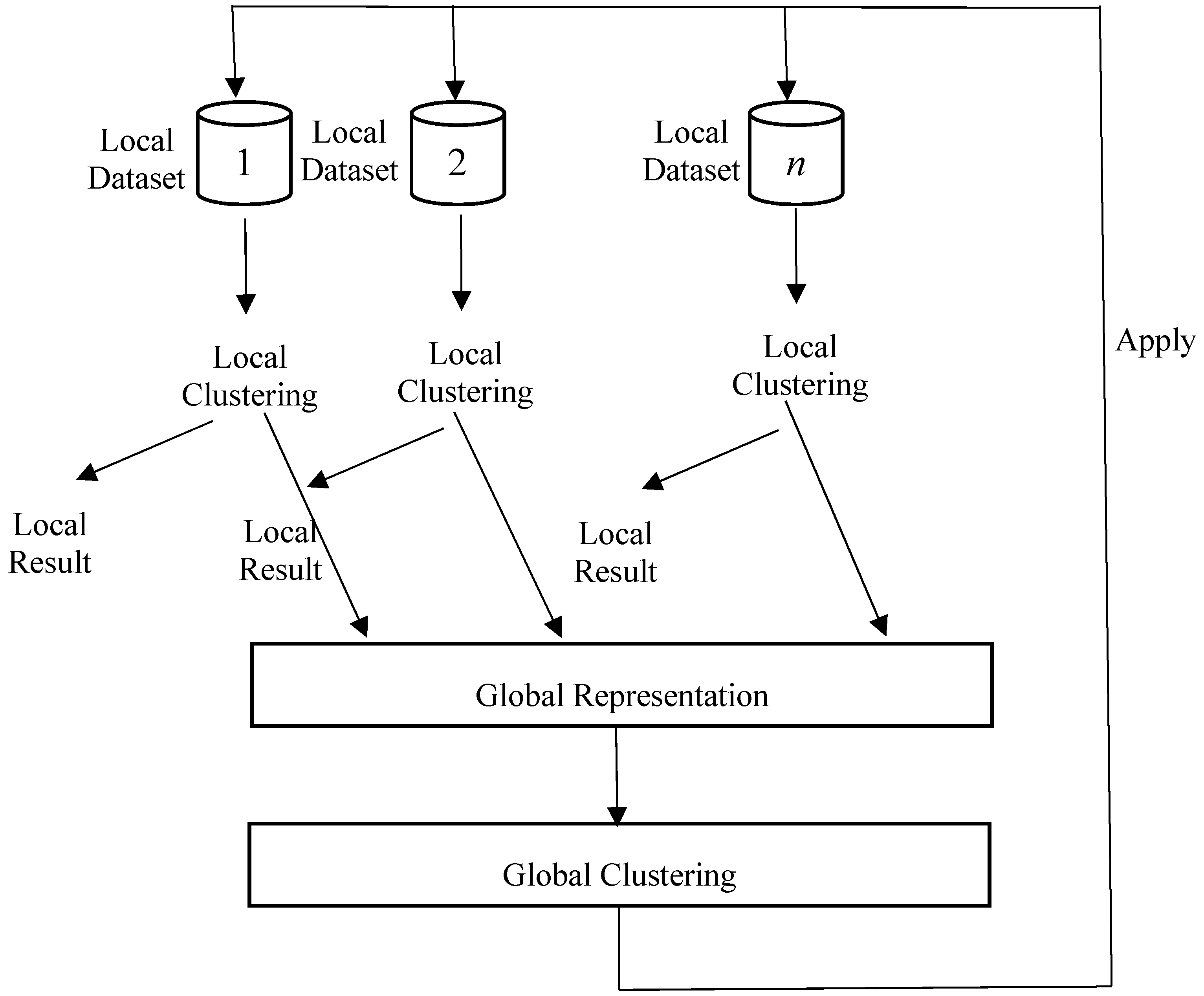
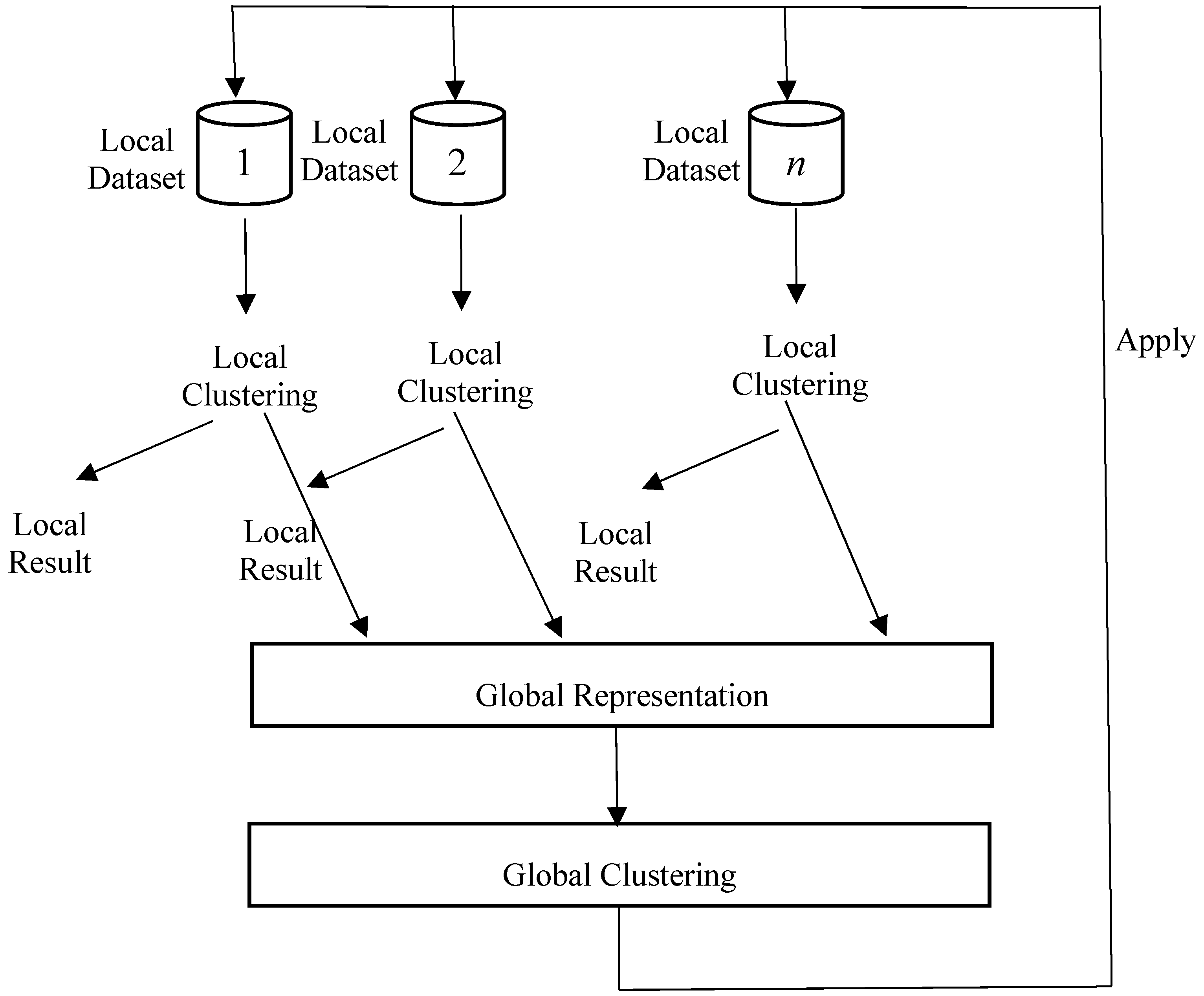
2. Distributed Clustering Algorithms
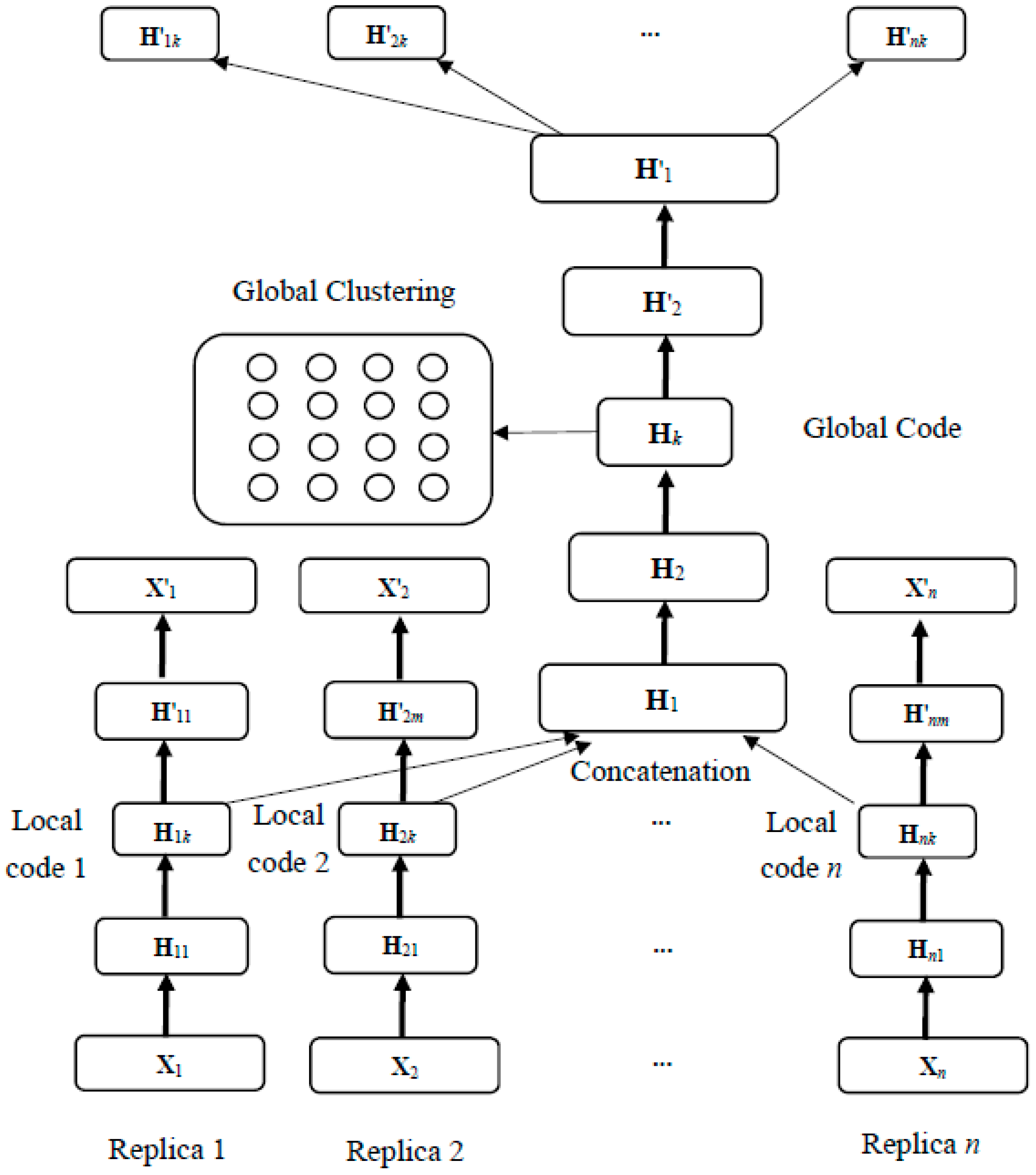
3. Double Deep Autoencoder
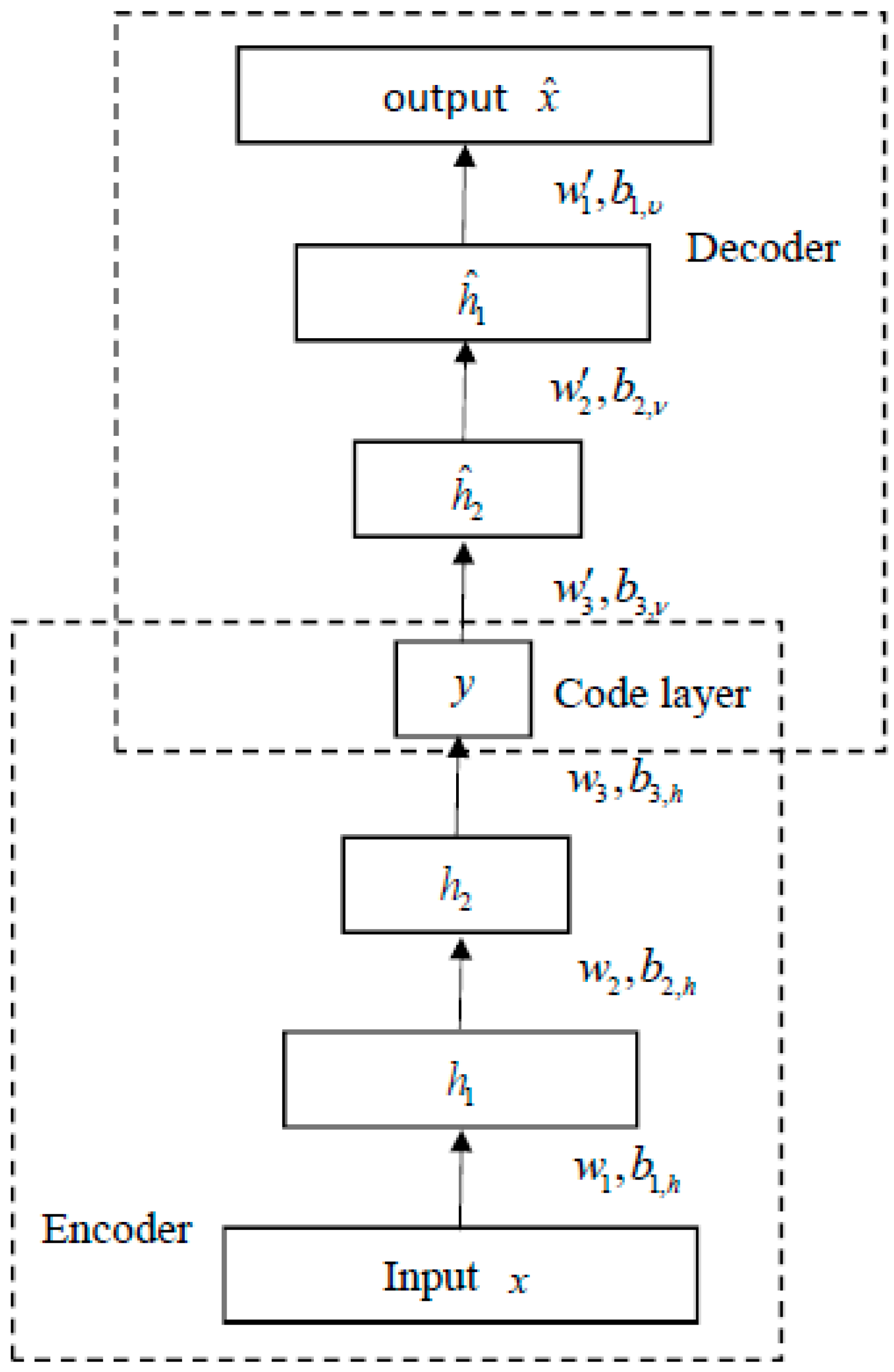
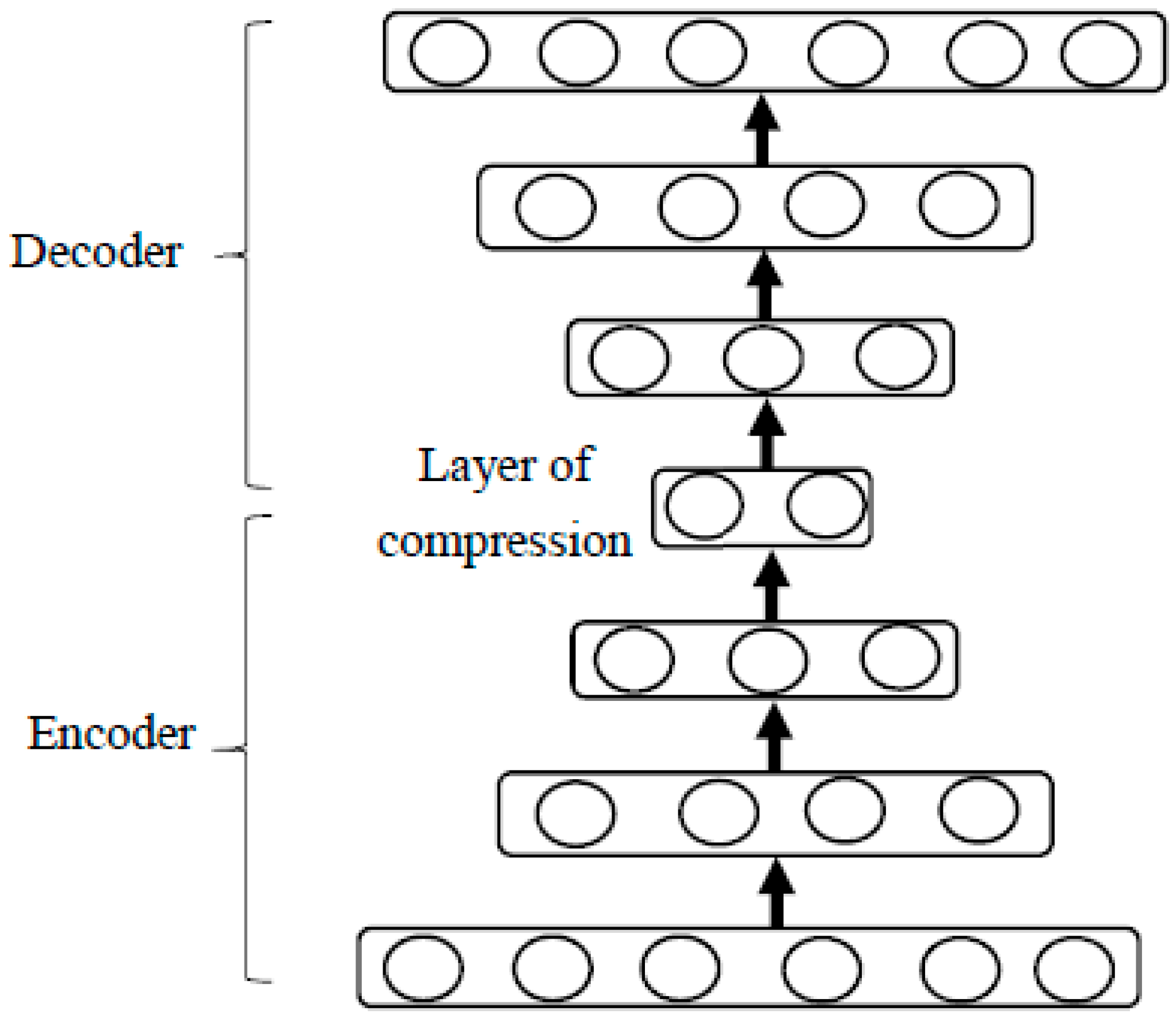
3.1. Deep Autoencoder
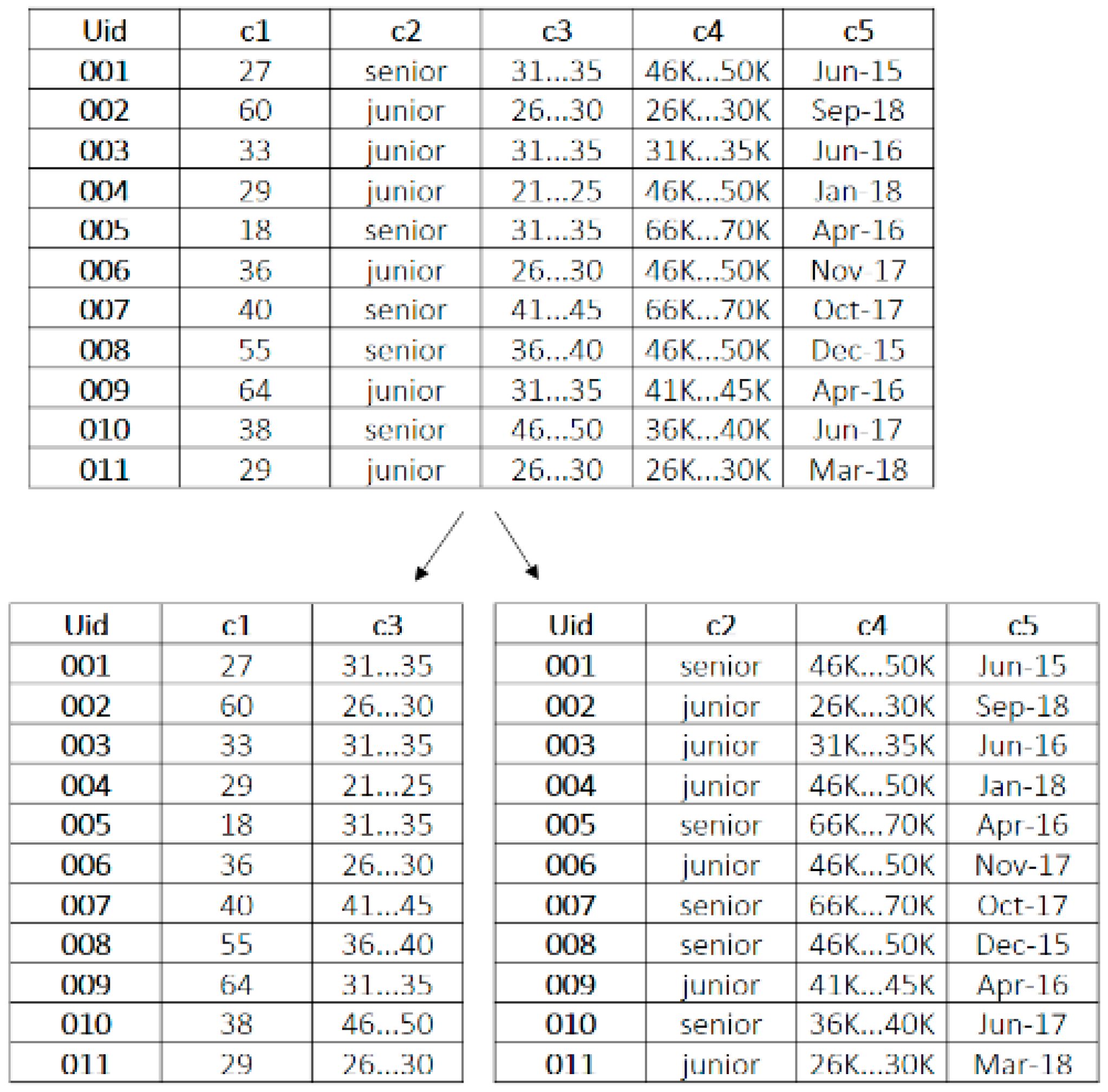
3.2. Replica Neural Network
3.3. Server Neural Network
3.4. Optimization Algorithms
3.5. Summary of the Proposed Algorithm
| Algorithm 1: double deep autoencoder |
| Input: Replica data samples Method: Replica Neural Networks:
|
3.6. Performance Measurement
4. Experiments
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tsoumakas, G.; Vlahavas, I. Distributed data mining. In Database Technologies: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2009; pp. 157–164. [Google Scholar]
- Zeng, L.; Li, L.; Duan, L.; Lu, K.; Shi, Z.; Wang, M.; Wu, W.; Luo, P. Distributed data mining: A survey. Inf. Technol. Manag. 2012, 13, 403–409. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Steinbach, M.; Karypis, G.; Kumar, V. A comparison of document clustering techniques. KDD Workshop Text Min. 2000, 400, 525–526. [Google Scholar]
- Beil, F.; Ester, M.; Xu, X. Frequent term-based text clustering. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; p. 436. [Google Scholar]
- Ghanem, S.; Kechadi, M.T.; Tari, A.K. New approach for distributed clustering. In Proceedings of the 2011 IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services (ICSDM 2011), Fuzhou, China, 29 June–1 July 2011; pp. 60–65. [Google Scholar]
- Ahmad, F.; Chakradhar, S.T.; Raghunathan, A.; Vijaykumar, T.N. Tarazu: Optimizing MapReduce on heterogeneous clusters. In ACM SIGARCH Computer Architecture News; ACM: New York, NY, USA, 2012; p. 61. [Google Scholar]
- Johnson, E.L.; Kargupta, H. Collective, Hierarchical Clustering from Distributed, Heterogeneous Data. In Advances in Nonlinear Speech Processing; Springer Nature: Basingstoke, UK, 2000; Volume 1759, pp. 221–244. [Google Scholar]
- Kargupta, H.; Huang, W.; Sivakumar, K.; Johnson, E. Distributed Clustering Using Collective Principal Component Analysis. Knowl. Inf. Syst. 2001, 3, 422–448. [Google Scholar] [CrossRef]
- Zhai, K.; Boyd-Graber, J.; Asadi, N.; Alkhouja, M.L. Mr. LDA: A flexible large scale topic modeling package using variational inference in mapreduce. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 879–888. [Google Scholar]
- Vishalakshi, C.; Singh, B. Effect of developmental temperature stress on fluctuating asymmetry in certain morphological traits in Drosophila ananassae. J. Biol. 2008, 33, 201–208. [Google Scholar] [CrossRef]
- Huang, J.-J. Heterogeneous distributed clustering by the fuzzy membership and hierarchical structure. J. Ind. Prod. Eng. 2018, 35, 189–198. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, G. Research on distributed heterogeneous data PCA algorithm based on cloud platform. In AIP Conference Proceedings; AIP Publishing: Melville, NY, USA, 2018; Volume 1967, p. 020016. [Google Scholar]
- HajHmida, M.B.; Congiusta, A. Parallel, distributed, and grid-based data mining: Algorithms, systems, and applications. In Handbook of Research on Computational Grid Technologies for Life Sciences, Biomedicine, and Healthcare; IGI Global: Hershey, PA, USA, 2012. [Google Scholar]
- Roosta, S.H. Parallel Processing and Parallel Algorithms: Theory and Computation; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Januzaj, E.; Kriegel, H.P.; Pfeifle, M. Towards effective and efficient distributed clustering. In Proceedings of the Workshop on Clustering Large Data Sets (ICDM2003), Melbourne, FL, USA, 19 November 2003. [Google Scholar]
- Januzaj, E.; Kriegel, H.-P.; Pfeifle, M. DBDC: Density Based Distributed Clustering. In Advances in Nonlinear Speech Processing; Springer Nature: Basingstoke, UK, 2004; Volume 2992, pp. 88–105. [Google Scholar]
- Coletta, L.F.S.; Vendramin, L.; Hruschka, E.R.; Campello, R.J.G.B.; Pedrycz, W. Collaborative Fuzzy Clustering Algorithms: Some Refinements and Design Guidelines. IEEE Trans. Fuzzy Syst. 2012, 20, 444–462. [Google Scholar] [CrossRef]
- Visalakshi, N.K.; Thangavel, K.; Parvathi, R. An Intuitionistic Fuzzy Approach to Distributed Fuzzy Clustering. Int. J. Comput. Theory Eng. 2010, 2, 295–302. [Google Scholar] [CrossRef]
- Rahimi, A.; Recht, B. Clustering with normalized cuts is clustering with a hyperplane. Stat. Learn. Comput. Vis. 2004, 56–69. Available online: http://groups.csail.mit.edu/vision/vip/papers/rahimi-ncut.pdf (accessed on 17 April 2019).
- Ghesmoune, M.; Lebbah, M.; Azzag, H. Micro-Batching Growing Neural Gas for Clustering Data Streams Using Spark Streaming. Procedia Comput. Sci. 2015, 53, 158–166. [Google Scholar] [CrossRef]
- Chowdary, N.S.; Prasanna, D.S.; Sudhakar, P. Evaluating and analyzing clusters in data mining using different algorithms. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 86–99. [Google Scholar]
- Achtert, E.; Böhm, C.; Kröger, P. DeLi-Clu: Boosting robustness, completeness, usability, and efficiency of hierarchical clustering by a closest pair ranking. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2006; pp. 119–128. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.-R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Feng, X.; Zhang, Y.; Glass, J. Speech feature denoising and dereverberation via deep autoencoders for noisy reverberant speech recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Adelaide, Australia, 4–9 May 2014; pp. 1759–1763. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Xu, J.; Xiang, L.; Liu, Q.; Gilmore, H.; Wu, J.; Tang, J.; Madabhushi, A. Stacked sparse autoencoder (SSAE) for nuclei detection on breast cancer histopathology images. IEEE Trans. Med Imaging 2016, 35, 119–130. [Google Scholar] [CrossRef]
- Chu, W.; Cai, D. Stacked Similarity-Aware Autoencoders. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Beijing, China, 18–21 June 2017; pp. 1561–1567. [Google Scholar]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, X.; Bai, S.; Yao, C.; Bai, X. Deep Learning Representation using Autoencoder for 3D Shape Retrieval. Neurocomputing 2016, 204, 41–50. [Google Scholar] [CrossRef]
- Tan, C.C.; Eswaran, C. Reconstruction and recognition of face and digit images using autoencoders. Neural Comput. Appl. 2010, 19, 1069–1079. [Google Scholar] [CrossRef]
- Zhang, J.; Hou, Z.; Wu, Z.; Chen, Y.; Li, W. Research of 3D face recognition algorithm based on deep learning stacked denoising autoencoder theory. In Proceedings of the 2016 8th IEEE International Conference on Communication Software and Networks (ICCSN), Beijing, China, 4–6 June 2016; pp. 663–667. [Google Scholar]
- Görgel, P.; Simsek, A. Face recognition via Deep Stacked Denoising Sparse Autoencoders (DSDSA). Appl. Math. Comput. 2019, 355, 325–342. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; Université de Montréal: Montreal, QC, Canada, 2007; pp. 153–160. [Google Scholar]
- Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Le, Q.V.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ng, A.Y. Large scale distributed deep networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2012; pp. 1223–1231. [Google Scholar]
- Duchi, J.; Jordan, M.I.; McMahan, B. Estimation, optimization, and parallelism when data is sparse. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2013; pp. 2832–2840. [Google Scholar]
- Nesterov, Y. Gradient methods for minimizing composite objective function. Math. Program. 2013, 140, 125–161. [Google Scholar] [CrossRef]
- Chen, W.-Y.; Song, Y.; Bai, H.; Lin, C.-J.; Chang, E.Y. Parallel Spectral Clustering in Distributed Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 568–586. [Google Scholar] [CrossRef]
- Xu, W.; Liu, X.; Gong, Y. Document clustering based on non-negative matrix factorization. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Toronto, ON, Canada, 26 October 2010; pp. 267–273. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Mnist | Covertype | SDDD |
|---|---|---|---|
| Records | 70,000 | 581,012 | 58,509 |
| Class | 10 | 7 | 11 |
| Replica | 4 | 2 | 3 |
| Replica Attributes | 196/196/196/196 | 10/44 | 16/16/16 |
| Datasets | Mnist | Covertype | SDDD |
|---|---|---|---|
| Replica network | 196-500-300-100-10-100-300-500-196 | 10(44)-50-40-30-10-30-40-50-10(44) | 16-50-30-20-10-20-30-50-16 |
| Server network | 10-400-200-20-200-400-10 | 10-50-25-10-25-50-10 | 10-40-20-10-20-40-10 |
| Activation function | Hyperbolic tangent | Hyperbolic tangent | Hyperbolic tangent |
| Dropout rate | 0.2 | 0.2 | 0.2 |
| Mini-batch size | 100 | 100 | 100 |
| Overfitting | Sparsity regularization | Sparsity regularization | Sparsity regularization |
| Adaptive learning | Nesterov | Nesterov | Nesterov |
| Loss function | MSE | MSE | MSE |
| Stopping criterion | 600 epochs | 600 epochs | 600 epochs |
| Clustering | Mnist | Covertype | SDDD |
|---|---|---|---|
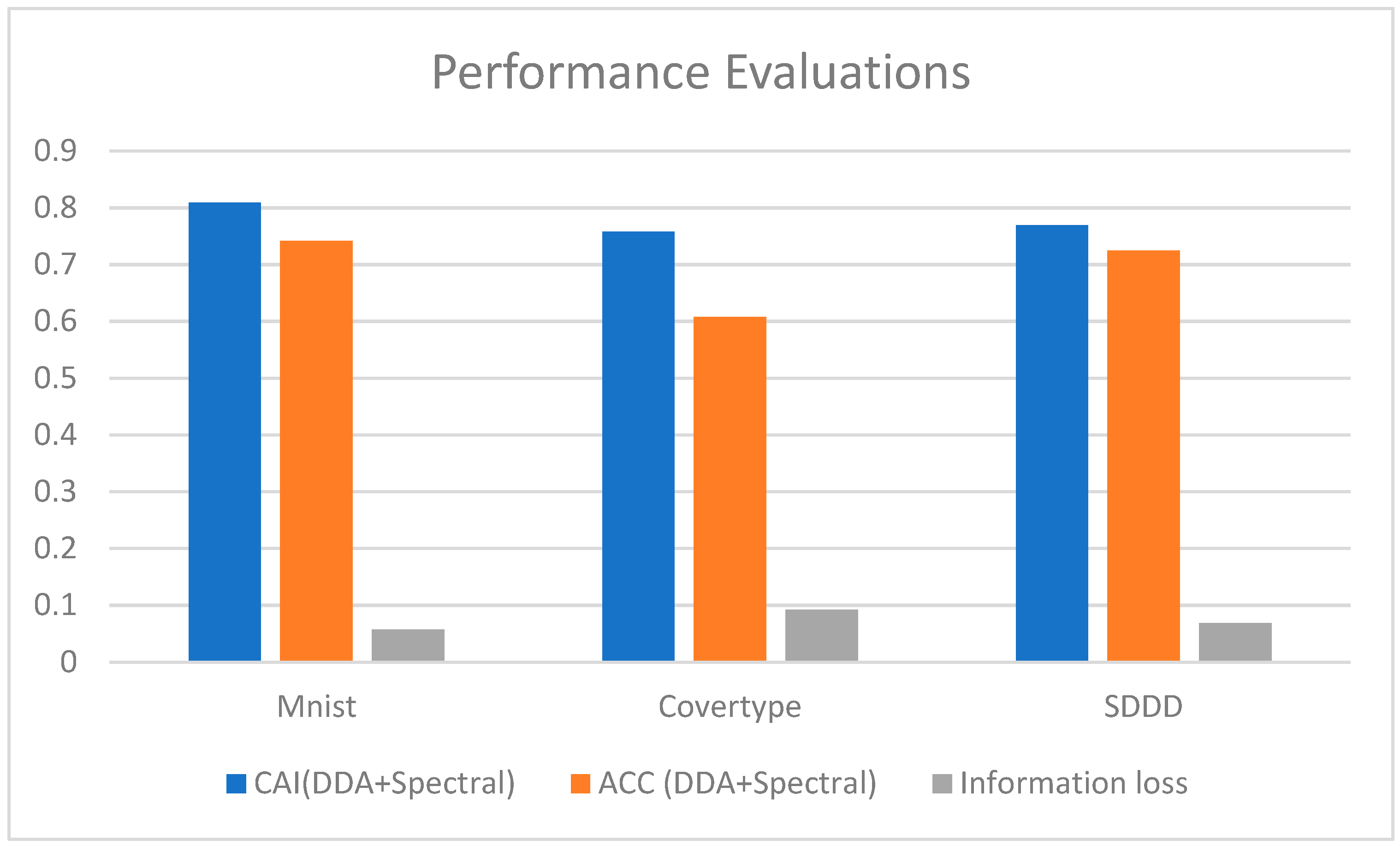
| DDA+K-means | 0.8060 | 0.6744 | 0.6837 |
| DDA+SOM | 0.6641 | 0.5427 | 0.6832 |
| DDA+Spectral | 0.8090 | 0.7576 | 0.7691 |
| ACC | Centralized DA | DDA+K-Means | Centralized DA | DDA+SOM | Centralized DA | DDA+Spectral |
|---|---|---|---|---|---|---|
| Mnist | 0.7621 | 0.7354 | 0.7315 | 0.7030 | 0.7924 | 0.7416 |
| Covertype | 0.5604 | 0.5524 | 0.4430 | 0.4347 | 0.6488 | 0.6076 |
| SDDD | 0.6630 | 0.6584 | 0.6656 | 0.6586 | 0.7506 | 0.7245 |
| Mnist | Covertype | SDDD | |
|---|---|---|---|
| Centralized DA+softmax | 0.9973 | 0.6742 | 0.7251 |
| Network structure | 784-500-300-100-10 | 54-50-40-30-10 | 48-50-30-20-10 |
| DDA+softmax | 0.9408 | 0.6123 | 0. 6754 |
| Information loss | 5.66% | 9.18% | 6.85% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-Y.; Huang, J.-J. Double Deep Autoencoder for Heterogeneous Distributed Clustering. Information 2019, 10, 144. https://doi.org/10.3390/info10040144
Chen C-Y, Huang J-J. Double Deep Autoencoder for Heterogeneous Distributed Clustering. Information. 2019; 10(4):144. https://doi.org/10.3390/info10040144
Chicago/Turabian StyleChen, Chin-Yi, and Jih-Jeng Huang. 2019. "Double Deep Autoencoder for Heterogeneous Distributed Clustering" Information 10, no. 4: 144. https://doi.org/10.3390/info10040144
APA StyleChen, C.-Y., & Huang, J.-J. (2019). Double Deep Autoencoder for Heterogeneous Distributed Clustering. Information, 10(4), 144. https://doi.org/10.3390/info10040144