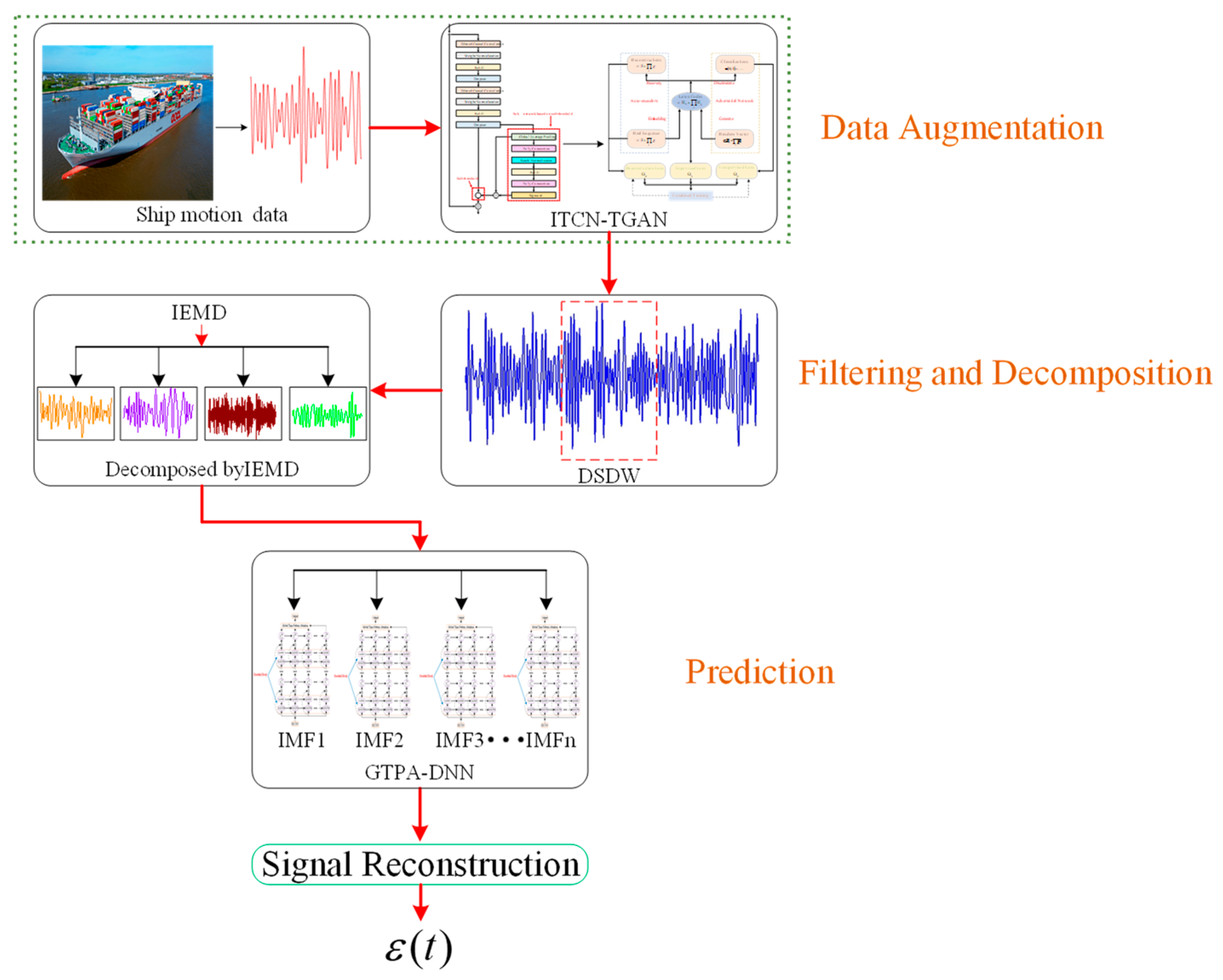
The simulation results of 1200 s of the roll and pitch angle are taken as the training data, and the other simulation results of 300 s are used as the test data for the performance test. The prediction model is developed based on Python 3.10 and Pytorch 1.13. The validation test of the DSDW, ITCN-TGAN, and IEMD, and the performance test of GTPA-TNN, are carried out in this section. In each test, is used to presented the navigation angle.
3.1. The Validation Test of the Dynamic Sliding Data Window (DSDW)
In this part, the DSDW will be verified first, for it determines whether the integrated model can achieve online prediction, which is the basis for the further research. The initial length of the DSDW is 45, which is set according to the experience of multiple experiments.
Considering the high correlation between the length of the input sequence and the prediction accuracy of the neural network, the Static Sliding Data Window will lead to sharp fluctuations in the prediction accuracy. When the navigation angle is 90°, the roll angle has the most remarkable nonlinear characteristic, which makes the prediction difficulty much higher than other conditions. Therefore, the test data of this experiment are the roll angle under the sea state of level 6 with a navigation angle of 90°; the speed is 18 Kn; the prediction period is 60 s; the Static Sliding Data Window (SSDW) is taken as a reference, the length of which is 10 s, 15 s, and 20 s, respectively; and the prediction model used in the test is GTPA-TNN to avoid influence on the accuracy by other factors. The test results of the SSDW and DSDW are shown in
Figure 14, and the error of different sliding data windows at each time step is shown in
Figure 15.
It can be seen from the
Figure 14 that the prediction accuracy of SSDWs with different lengths is lower than that of the DSDW. The accuracy of the SSDW with three lengths is basically the same, which is in continuous large fluctuation. In particular, when the roll angle reaches its maximum value, the error of the SSDW reaches its peak, which indicates that a high correlation exists between the input sequence and the prediction accuracy. Due to the strong nonlinear characteristic of ship rolling in harsh sea conditions, the optimal length of the input sequence is not a constant value. Therefore, no matter what the length of the SSDW is, it cannot guarantee high adaptability between the length of the input sequence and the output value, which makes the fitting ability of the model using the SSDW always be in a large fluctuation. In contrast, the model based on the DSDW has an extremely high degree of agreement between the prediction value and the samples, which is also much higher than that of the SSDW with different lengths. Its prediction accuracy has no significant fluctuation during the whole period, which suggests that the DSDW keeps the adaptability between the length of the input sequence and the output value at an extremely high level during the period. When the waveform of the input sequence changes, the DSDW can accurately determine the turning point of the trend change of the sequence and determine the optimal input sequence length at the current time step.
It can be seen from
Figure 15 that the errors of SSDW_10s, SSDW_15s, and SSDW_20s are always in fluctuation during the prediction period, and the fluctuation amplitude and frequency of the errors of these models are not much different; in contrast, the error of the model with the DSDW is basically stable during the period. The value of the error is much lower than those of the three models, which is consistent with the results shown in
Figure 14. The fluctuation and frequency of it are also much lower than those of other models. These phenomena indicate that the DSDW significantly improves the prediction accuracy and computational stability of the prediction model, and the validity of it is further proven.
The correlation coefficients between the predicted and sample value of the DSDW and the SSDW with three different lengths in different periods are shown in
Table 3.
It can be seen from
Table 3 that the amplitude of the fluctuation in the correlation coefficients of SSDW_10s, SSDW_15s, and SSDW_20s in the different periods is 11.93%, 12.61%, and 13.78%, but that of the DSDW is only 0.32%, which is much lower than that of the former models. It also proves that, compared with the SSDW, the DSDW can dramatically enhance the prediction stability by adaptively adjusting the length of the input sequence when the model structure is the same. In addition, the correlation coefficient of the DSDW in any time period is much higher than that of the three models with the SSDW, which further proves that the length of the input sequence adjusted by the DSDW is the optimal length, which has the optimal adaptability with the output, which makes the model have a higher correlation coefficient. The change in the length of the DSDW during the prediction is shown in
Figure 16.
In
Figure 16, n is the length of the DSDW at the current time step. It can be seen that the length of the DSDW varies in (18–50), but the amplitude of the change is small at each 15 s, which makes it only take 0.0186 s in each time step. This further indicates that the DSDW can adjust the length of input sequence adaptively in real time depending on the waveform of the input sequence, so the suitability between input sequence length and output variable is kept stable.
Above all, the length of the DSDW can be adjusted online according to the characteristic of the input data, and its length is the optimal length for the current structure; therefore, the validation of the DSDW is verified.
3.3. The Validation Test of IEMD
According to the
Figure 13, after the ITCN-TGAN, the enhanced data are entered into the filter, in which the data with strong nonlinear characteristics are decomposed to the IMFs, which are easier to predict. IEMD directly determines the prediction difficulty of the GTPA-TNN; therefore, its validation tests take place before the validation tests of the GTPA-TNN.
In order to make the test data more suitable for the ship roll and pitch motion data under real sea conditions, the Gaussian noise is added to all the test data, the input data of IEMD and EMD are the time series in the DSDW, and their lengths are all adjusted by the DSDW, which prevents the other factors from influencing the results.
The mode mixing and endpoint effect occur in the IMFs of EMD, and the noise cannot be separated from the signal, which makes it propagate in the IMF during the decomposition process. For the above problems, the Improved Empirical Mode Decomposition algorithm is proposed, and the validation test is executed in this section.
The roll angle of KCS when
under the sea state of level 6 is taken as the test data, EMD is used as control, and the results of the test are offered in
Figure 23 and
Figure 24.
In
Figure 23 and
Figure 24, (a) and (b) are the IMF and the residual of the decomposition by IEMD and EMD. The test results indicate that as the decomposition progresses, the IMFs decomposed by EMD still have significant nonlinear characteristics and much noise, and its period is not obvious. The amplitude of each IMF is also much larger than that of the corresponding IMF decomposed by IEMD. The waveforms of IMF3 and IMF4 decomposed by EMD near the endpoint are quite different from those in the middle, which also indicates that the serious problem of endpoint effect exists in the IMFs of EMD. The deviation generated in the above decomposition process increases the errors of the IMFs, and the superposition of the errors causes the larger deviation in the value predicted by EMD after reconstruction.
In contrast, the decomposition results of IEMD indicate that the period of the decomposed IMFs is obvious, the nonlinear characteristic of each IMF is significantly weakened, the noise in the IMFs is obviously reduced, and the amplitude and frequency of each IMF are much lower than the corresponding IMFs decomposed by EMD, which makes the IMFs significantly easier to predict and improves the final accuracy. In addition, the waveforms near the endpoints and the middle of IMFs decomposed by IEMD are basically the same, which suggests that IEMD avoids the problem of the endpoint effect during the decomposition by the adaptive waveform extension method, which makes the IMFs able to more accurately reflect the frequency characteristic of the input signal. Compared with the IMF3–IMF6 decomposed by IEMD and EMD, the difference in nonlinear characteristics between the same level of IMFs becomes more obvious as the decomposition progresses, which indicates that the difference in decomposition efficiency between the two gradually increases and further proves that IEMD avoids the problem of noise propagation in the decomposition process. The amplitude spectrum of each IMF decomposed by IEMD and EMD is shown in
Figure 25 to further compare the decomposition efficiency of IEMD and EMD.
In
Figure 25, (a)–(f) are the amplitude spectrums of IMF1–IMF6 of IEMD and EMD. It can be seen from
Figure 24 that the mode mixing occurs in the IMFs decomposed by EMD, especially in IMF1, IMF2, and IMF3, where four different frequency components exist at the same time, and there are also three, three, and two different frequency components in IMF4–IMF6, respectively. The mode mixing makes the IMFs not accurately reflect the frequency characteristic of the input signal, which is likely to cause the loss of important information in the original signal during the decomposition process. The amplitude spectrum of the IMFs of EMD is more scattered, which indicates that its IMFs not only have the problem of mode mixing but also have a certain amount of noise.
In contrast, there is only one frequency component in the IMFs of IEMD, and their frequency distribution is much more concentrated, which suggests that mode mixing does not occur in the IMFs. They do not interfere with each other, which can accurately characterize the frequency feature of the input sequence. On the other hand, it indicates that there is little noise in the IMFs, and the problem of noise propagation between IMFs during the decomposition process is avoided.
Finally, in order to intuitively reflect the degree of nonlinearity of the IMFs of IEMD and EMD, they are all predicted by the GTPA-TNN model. The prediction period is 60 s, the assessment index of the prediction error is the Root Mean Square Error (RMSE), and its definition is presented in Equation (46):
In Equation (41),
is the number of the samples, and
and
are the sample value and prediction value. The prediction results of IMF1–IMF6 are shown in
Figure 26.
It can be seen from
Figure 26 that the RMSE value of the IMFs of the IEMD is significantly lower than that of the IMFs of the EMD when predicted by the same model. The errors of the IMFs of EMD fluctuate in the 60 s time period, especially IMF1 and IMF2. The amplitude and frequency of their RMSE are much higher than those of other IMFs. According to
Figure 23b and
Figure 25, this is due to the strong nonlinear characteristic of the IMF1 and IMF2 decomposed by EMD and the serious problem of mode mixing, which significantly increases the prediction difficulty. Although the nonlinear characteristics of IMF3–IMF6 are weaker than those of IMF1–IMF3, the mode mixing and noise still exist in the IMFs, which results in the large value and amplitude of the RMSE.
For the IMFs decomposed by IEMD, the RMSE value is basically kept stable in the prediction cycle, and it is much lower than that of the corresponding IMFs decomposed by EMD. Only slight fluctuation exists at the low level, and the amplitude and frequency of the fluctuation are much lower than those of the IMFs of the same order of EMD. Compared with the IMFs of EMD, the RMSE value of the IMFs of IEMD is reduced by 46.37% at most, which further suggests that the IMFs decomposed by IEMD can accurately describe the frequency feature of the input sequence. The IMFs are independent of each other, with a high ratio of signal to noise, which verifies the validation of IEMD in avoiding the endpoint effect by the adaptive waveform extension method and filtering noise by calculating the Hausdorff distance of the input signal. In addition, the signal time-step calculation times of IEMD and EMD are 0.013 s and 0.0125 s, respectively. It can be seen that the calculation time of the two algorithms is basically the same, which can meet the need of rapid prediction.
In summary, the IEMD proposed in this study can decompose the input sequence with strong nonlinear characteristics into multiple IMFs that are easy to predict. The mode mixing, endpoint effect, and noise propagation during the decomposition all disappear due to the adaptive waveform extension method and filtering the noise. The valid information is maintained in the IMFs, which makes the IMFs able to accurately reflect the frequency characteristic of the input signal and significantly reduce the prediction difficulty of it, and the calculation period can meet the need of rapid prediction. So far, the input data are decomposed into multiple IMFs, which are easier to predict.
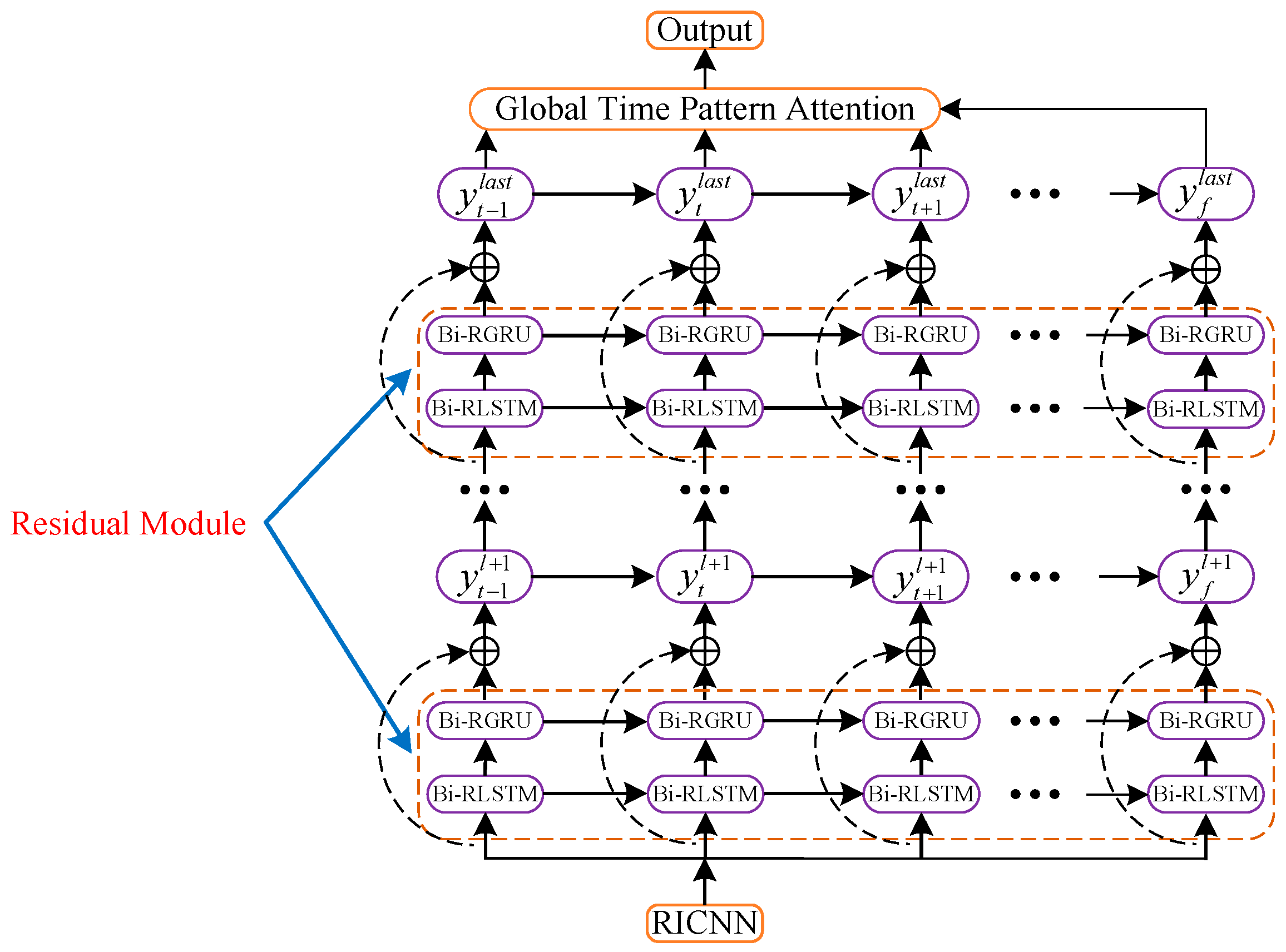
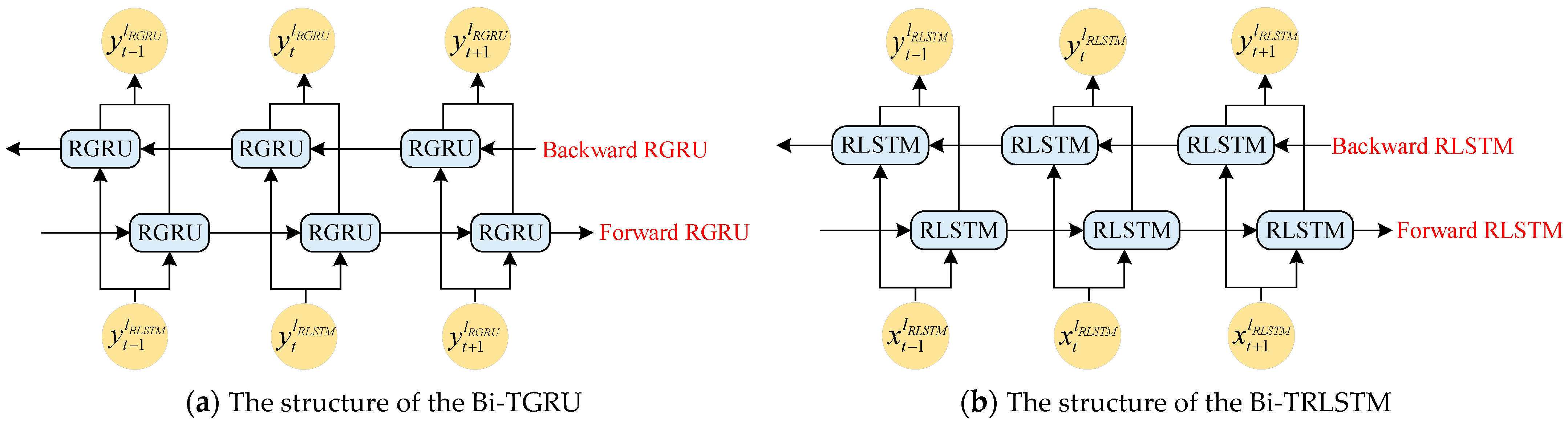
3.4. The Validation Test of the GTPA-TNN
According to
Figure 13, the final part of the integrated model is the GTPA-TNN, which is used to predict the IMFs decomposed by IEMD. It can be seen that the DSDW, ITCN-TGAN, and IEMD of the integrated model are verified; therefore, if the validation of the TGPA-TNN can be verified, the whole integrated model can be regarded as feasible.
The validation test of the GTPA-TNN is conducted in this subsection. Considering the conventional operating sea conditions of container ships and the influence of the navigation angle, the roll and pitch angle prediction test for KCS at the sea state levels of 4 and 6 with navigation angles of 0°, 45°, and 90° is carried out. The speed of KCS is 20 Kn. The TNN (the deep time-varying residual recurrent neural network without GTPA), the LSTM, and the GRU, which are widely used in time series prediction, are taken as the contrast to prove the validation of the GTPA and time-space residual connection architecture. All the test data are decomposed into multiple IMFs by IEMD, and the settings of the four models are presented in
Table 4.
In
Table 4, the RMSprop is the Root Mean Square Propagation algorithm, and the input of the GTPA-TNN and TNN are both multivariate time series, which is the reason why there are three units in the input layer. The prediction periods are all 60 s. The test results of the four models for navigation angles of 0°, 45°, and 90° are presented in
Figure 27,
Figure 28 and
Figure 29, in which (1) and (2) are the prediction curves of the roll angle and pitch angle, and (a), (b), and (c) correspond to the sea state levels of 4, 5, and 6.
The results of the validation tests show that the GTPA-TNN can accurately predict the ship roll and pitch under the severe sea state, the prediction accuracy at each operating condition is significantly higher than that of other models, and its fluctuation amplitude is much lower than that of other models. The accuracy of the LSTM and the GRU, which are both neural networks with static structure, is far worse than that of the TNN and the GTPA-TNN. It can be seen from
Table 5,
Table 6 and
Table 7 that there is almost no fluctuation in their correlation coefficient, which is significantly smaller than that of the TNN and the GTPA-TNN. Especially for the roll angle when
and the pitch angle when
, the correlation coefficient of the LSTM and the GRU decreases significantly with the deterioration in sea state, which is much higher than that of the TNN and the GTPA-TNN.
It can be seen from the prediction curves shown in
Figure 25,
Figure 26 and
Figure 27 that the accuracy fluctuation of the LSTM and the GRU in the prediction period is also much higher than that of the TNN and the GTPA-TNN. On the one hand, the wave has the most outstanding effect on the roll and pitch under the two conditions, and the nonlinear feature of the roll angle and pitch angle are significantly stronger than those of other ship motions, which makes it extremely difficult to predict; on the other hand, the LSTM and the GRU are all static models, the suitability between the architecture and the sample in the DSDW gradually decreases over time, and the rate of decline gradually increases.
In contrast, due to the time-varying structure based on the NNSOA algorithm, the TNN and GTPA-TNN can adaptively adjust the number of residual blocks according to the sample data in the DSDW to maintain the adaptability between the sample data and the model structure at an extremely high level, which verifies the validation of the time-varying architecture based on the NNSOA.
The sequential connection between hidden layers is also the reason for the low accuracy of the LSTM and the GRU. In order to avoid the gradient explosion or gradient disappearance during model training, the hidden layers are too few, which results in insufficient longitudinal depth of the model and a lack of fitting ability in predicting strong nonlinear time series. But for the TNN and the GTPA-TNN, the space–time residual connection makes their vertical depth improve significantly and avoids the above problems. Compared with the LSTM and the GRU, the correlation coefficient of the TNN and the GTPA-TNN decreases by up to 12.66% and by at least 8.87%, which suggests that spatio-temporal residual architecture improves the fitting ability for the nonlinear time series by extending the vertical depth of the neural network, and the single time-step calculation time of the TNN and the GTPA-TNN is 0.023 s and 0.025 s, respectively, which further proves that the neural network with spatio-temporal residual architecture can realize rapid prediction. In summary, the validation of the space–time residual connection architecture is preliminarily proven.
The correlation analysis of the four models is carried out to further compare the differences in their fitting ability. Considering that ship rolling has the most important influence on navigation safety, and the nonlinear characteristic of roll angle under the sea state of level 6 is far stronger than other ship motions, which make it the most difficult to predict, it can be used as the test data to maximize the difference between the performance of the models. The correlation analysis results of the four models when
is 0°, 45°, and 90° are presented in
Figure 30. The red line is the perfect regression line.
From
Figure 30, it can be seen that the correlation of the GTPA-TNN is apparently higher than that of the other three models under the sea state of level 6. According to
Table 3,
Table 4 and
Table 5, it can be seen that, compared to other models, the correlation coefficients of the GTPA-TNN at different navigation angles are increased by at least 6.51%, 7.84%, and 8.57%, respectively. When the navigation angle is 90°, the increase in the GTPA-TNN reaches the maximum, which further proves that the GTPA-TNN can maintain high accuracy with increasing difficulty of predicting the input data, and its performance advantage will continue to increase. On the other hand, comparing the correlation coefficients of the four models when
under the sea states of levels 4 and 6, it can be seen that a distinguished contrast in the decrease in the correlation coefficient occurs between the four models, with the smallest decrease occurring in the GTPA-TNN, which is only 0.41%, while the LSTM, GRU, and TNN decrease by 2.69%, 2.36%, and 1.96%, respectively, which indicates that the correlation between the prediction accuracy and the nonlinear characteristic of the input sequence proves that the GTPA-TNN has strong robustness and more application value in real conditions. The error distribution of the four models under Lv. 6 is presented in
Figure 31 to further compare the calculation stability of the GTPA-TNN.
According to
Figure 31, it can be seen that, even for predicting ship motion under severe sea conditions, the percentage error of the GTPA-TNN is distributed between 0.8% and 2.8% and is concentrated between 1.2% and 2.5%, while the percentage errors of the LSTM, GRU, and TNN are distributed around 4~18%, 4.5~18%, and 2~11.5%, respectively, and are concentrated in 10~14.5%, 9.5~15%, and 5~10%, which suggests that the accuracy and stability of the LSTM and the GRU are extremely insufficient, and further proves that the neural network based on static structure cannot realize accurate prediction for the ship motion. In contrast, the error distribution of the TNN and the GTPA-TNN are significantly more concentrated, and the upper and lower boundaries are significantly reduced too, which further indicates that the spatio-temporal residual architecture can significantly improve the fitting capacity of the model, and the DSDW is combined with the prediction model to continuously update the sample value and adjust the number of the input data to maintain the adaptability among the sample, model structure, and sequence length.
It can be seen by comparing the percentage error of the TNN and the GTPA-TNN that the upper and lower boundaries and the length of the error distribution interval of the GTPA-TNN are all lower than those of the TNN. Even the maximum error of the GTPA-TNN is much lower than the minimum error of the TNN. On the one hand, the input sequence of the GTPA-TNN is the multivariate time series, which is composed of the ship motion data, wave height, and wave slope, which are environment factors with a high correlation with the ship motion. This makes the model mine the internal characteristics of the data from a different dimension. On the other hand, due to the GTPA, each input variable is dynamically assigned the corresponding weight, which makes the model allocate more weight to the variables with higher correlation with the output variables in the training process, and considering the global structure of the input variables, it makes the model able to accurately capture the long-term dependencies and local details between the sample data. Therefore, the length of the error distribution interval of the GTPA-TNN is basically the same when predicting the ship motion under different conditions, which indicates that the GTPA remarkably improves the accuracy and robustness of the prediction model.
In summary, the accuracy and stability of the GTPA-TNN in predicting ship motion attitudes under harsh sea states are much higher than those of the LSTM, GRU, and TNN, the performance advantage of the GTPA-TNN is more obvious with the increase in data prediction difficulty, and the prediction performance under each operating conditions is basically consistent, which proves its robustness advantage. The above results suggests that the GTPA-TNN can realize the rapid and accurate prediction of ship motion under severe sea conditions.
After verifying the validation of the DSDW, ITCN-TGAN, IEMD, and GTPA-TNN, the whole structure of the integrated model can be regarded as feasible, and an accurate and stable prediction tool for ship motion is provided.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}