1. Introduction
In order to meet the needs of safety and economy of marine structures, uncertainty as a key factor in the design and manufacture of marine structures has been widely studied. Uncertainty in marine engineering includes aleatory uncertainty and epistemic uncertainty [
1,
2]. Aleatory uncertainty is caused by the inherent randomness of relevant variables in structures and ocean environments, which is usually described by an accurate probability distribution. Epistemic uncertainty is caused by the lack of sufficient knowledge or incomplete information about the variables, which can be described in the form of intervals and probabilistic methods [
3].
In the past decades, aleatory uncertainty associated with marine structures has been a subject of extensive research. The traditional reliability assessment method is to use the FORM or the second-order reliability method (SORM) to calculate the structural reliability index after quantifying the uncertainty of random variables using probabilistic models [
4], and the continuous development of reliability theory provides new tools for the reliability analysis of marine structures. Homaei and Najafzadeh [
5] combined the artificial intelligence method and Monte Carlo sampling (MSC) to analyze the reliability of pile group scour depth being less than a limit value under regular waves. Aghatise Okoro et al. [
6] used the polynomial chaos expansion (PCE) and Kriging method to construct a metamodel of the limit state function and reduced the computational time by the MSC method. Ming Cai Xu et al. [
7] used the model correction factor method (MCFM) to constantly revise the results at the design points in the FORM iteration process to ensure that the results of the simplified model were close to the real model. The above research focuses on how to construct a surrogate model that is closer to the real model. However, their random variable distributions are usually based on empirical assumptions.
In fact, obtaining the accurate distribution of random variables requires a large number of sample data, which is difficult to achieve in practical engineering applications. In addition, it is often difficult to eliminate the uncertainty caused by structural manufacturing, installation errors and parameter measurement errors. To facilitate calculations, the aforementioned epistemic uncertainties are transformed into deterministic factors in many cases, leading to errors in the reliability assessment of marine structures. Debiao Meng et al. [
8] analyzed the fatigue of offshore wind turbine structures and showed that a reliability assessment framework that considers both aleatory and epistemic uncertainties is more accurate and conservative. Therefore, it is necessary to incorporate the analysis method of epistemic uncertainty into the reliability assessment of marine structures.
In 1989, Ben-Haim and Elishakoff [
9] proposed the idea of a non-probabilistic reliability model. Based on their study and the traditional probability theory, researchers began to propose a variety of non-probability models to describe the epistemic uncertain variables affecting structural reliability, such as interval theory [
10,
11], convex set theory [
12,
13], evidence theory [
14,
15] and p-box theory [
16,
17,
18], etc. In many non-probabilistic models, it is simple and feasible to describe epistemic uncertain variables by using the interval model or the convex set model. The interval model and the convex set model envelope sample data points to obtain a hypercube or a super ellipsoid, which is the description of the epistemic uncertain variable. However, the interval model or the convex model only uses the edge data of the sample data, but does not make full use of information such as the dense distribution of internal data. This may lead to an overestimation of the epistemic uncertain variable and furthermore an excessively large interval of analysis results. The final result provides no effective guidance for solving practical engineering problems. Moreover, technicians can effectively estimate the distribution of epistemic uncertainty variables in some cases with their engineering experience and the analytical results of similar structures. However, this reference information cannot be effectively utilized with the interval model or the convex set model due to their theoretical limitations. As a new type of non-probability model theory, p-box theory describes the epistemic uncertain variable through the upper and lower probability boxes of the cumulative distribution function (CDF). Regardless of whether the distribution form is unknown or known, epistemic uncertain variables can be described by the p-box model [
16]. In addition, p-box theory is compatible with other common non-probability theories. That is, other non-probability models can be transformed to the p-box model to some extent. Therefore, p-box theory can be used to establish a non-probability model with broader applicability for structural reliability analysis with epistemic uncertain variables. Research on the p-box model is burgeoning. Zhang et al. [
19] obtained the statistical moments and the CDF of a response function with a non-parametric p-box variable based on the cumulative distribution function discretization (CDFD) method. Li and Jiang [
20] combined the stochastic processes with p-box theory to propose a p-box-based imprecise stochastic process model, which is used for uncertainty analysis of structures under uncertain dynamic excitations or time-variant factors. Xiao et al. [
21] proposed a collaborative interval quasi-Monte Carlo method (CIMCM) to deal with the reliability model with multiple types of epistemic uncertainty unified by p-boxes variables, combining Rosen’s gradient projection method (RGPM) and collaborative optimization strategy, making the simulation convergence faster.
After the establishment of the non-probabilistic hybrid reliability model of the structure by using the traditional probabilistic model and the non-probability model, a hybrid structure reliability analysis is needed. At present, most of the literature needs to establish a two-layer nested optimization model [
22,
23,
24]. The outer layer is the process of traditional structural reliability optimization, and the inner layer is the optimization model of the limit value of the LSF with the epistemic uncertain variables as the optimization vector. Due to the existence of the inner optimization structure, this nested optimization structure requires a large number of calls to the LSF, resulting in an inefficient calculation.
Referencing the FORM, this paper deals with the case of epistemic uncertainty variables with small uncertainty and combines the linear approximation (LA) model and the two-point adaptive nonlinear approximation (TANA) model to approximate the upper and lower limits of the response of the LSF. Consequently, a de-nesting analysis method of the non-probabilistic hybrid reliability index based on an approximation model is proposed. In this paper, the U space (standard normal distribution space) is converted back to original space of the LSF, and the boundary of the corresponding p-box variable is obtained. The approximation method eliminates the inner layer of the original nested optimization structure. The outer layer of the original nested optimization structure of the hybrid reliability analysis is transformed into a traditional optimization problem, with the constraint that the inner layer is expressed as an approximate formulation developed at the design point. The speed of non-probabilistic hybrid reliability analysis of structures will be effectively improved because of the elimination of nested structures. Finally, the proposed reliability assessment method is applied to a numerical example and two common marine structures to verify its effectiveness and superiority.
2. Non-Probabilistic Hybrid Structural Reliability
2.1. P-Box Theory
In p-box theory, the p-box model is a probability box enveloped by the upper and lower limits of the CDF, and a precise distribution form of variable distribution is difficult to obtain. When the distribution type of the variable is known, a more accurate p-box model can be obtained by estimating the interval of the distribution parameters of the distribution type. If the distribution type of the variable cannot be obtained, the Chebyshev inequality can be used to rigorously derive the upper and lower limits of the CDF of the variable, using information such as the origin moment of the sample data.
If the variable
y is described by the p-box model, it can be expressed as Equation (1) and
Figure 1.
The p-box model can be called a parametric p-box model when the distribution type of the epistemic uncertain variable is known and the distribution parameter is an estimation interval. When only the upper and lower limits of the CDF of the uncertain variable are known, the p-box model can be called a free p-box model.
The acquisition method of the free p-box model is generally Chebyshev’s inequality, and the upper and lower limits of the CDF of the variable Y can be expressed as Equation (2a,b).
as well as
where
and
are the upper and lower limits of the CDF of the variable
y, respectively, and
and
are the mean and standard deviation of the epistemic uncertain variable
in the sample data.
For the parametric p-box model, the CDF of the variable y can be expressed as Equation (3).
where
is the distribution parameter of the distribution type that the variable
y follows. Due to the small amount of sample data and other possible reasons, this parameter is generally impossible to obtain accurately, but it can be estimated by the interval
.
2.2. Analytical Method
In the structural reliability analysis process, if the variable affecting the structural reliability contains
n random variables
(the exact CDF is known) and
p-box variables
(the exact CDF is unknown), the LSF
of the structure can be obtained.
To use FORM for structural reliability analysis, it is necessary to convert the LSF from the original space to the standard normal space (U space). The LSF in U space can be obtained by probability conversion, i.e., (, ) are independent standard normal distribution variables.
The independent variables
and
after converting from the original space to the U space are given by
where
is the CDFs of the random variables
,
is the CDFs of the p-box variables
and
is the inverse of the standard normal distribution.
According to Equation (5), there is,
where
is the inverse functions of the CDFs of the random variables
, and
is the inverse function of the CDFs of the p-box variables
.
and
are, respectively, the inverse functions of the upper and lower limits of the CDFs of the p-box variables
, and
and
are the lower and upper value limits of the p-box variables
.
Further, the LSF for the structure can be expressed as Equation (7).
Since the variables
are p-box variables, the structural LSF can be written as Equation (8), and
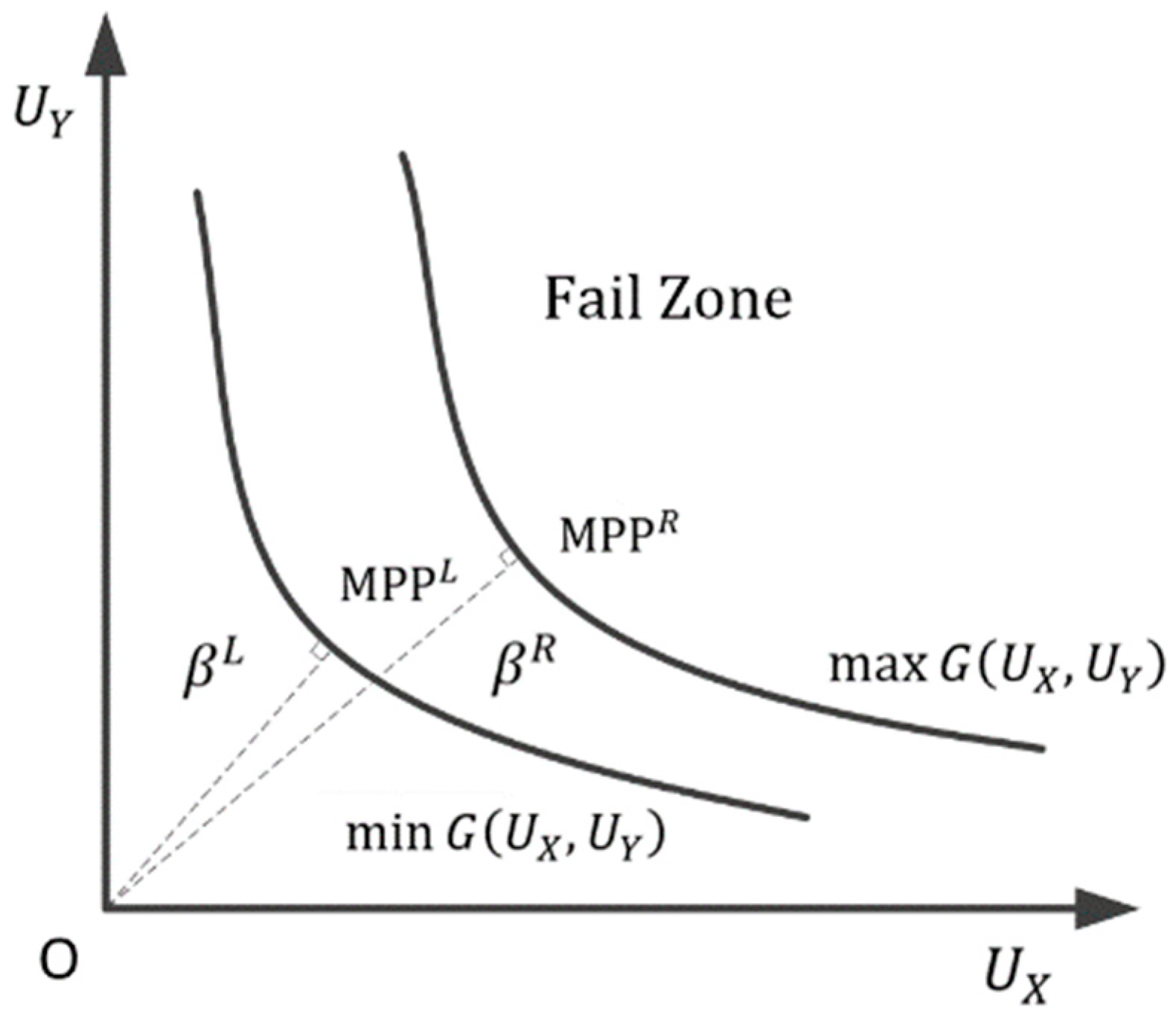
Figure 2 shows the surfaces of the non-probability hybrid LSF in the U space.
where
, and
.
In
Figure 2, MMP
L and MMP
R represent the maximum possible failure points (MPPs) of the lower LSF
and upper LSF
, respectively.
and
are the upper and lower limits of the reliability index
. According to the FORM, the structural reliability index
can be obtained, that is,
It can be known from Equations (8) and (9) that the non-probability hybrid reliability index
can be written as
. Further, two nested optimization functions related to the upper and lower limits of the reliability index
can be obtained, as shown in Equation (10a,b).
and
At the same time, it is necessary to discern the sign of the
. This requires obtaining the sign of the LSF at the origin of the standard normal space. According to Equation (11), the correct sign of
can be determined.
In Equation (11), sgn represents a function that indicates the sign of .
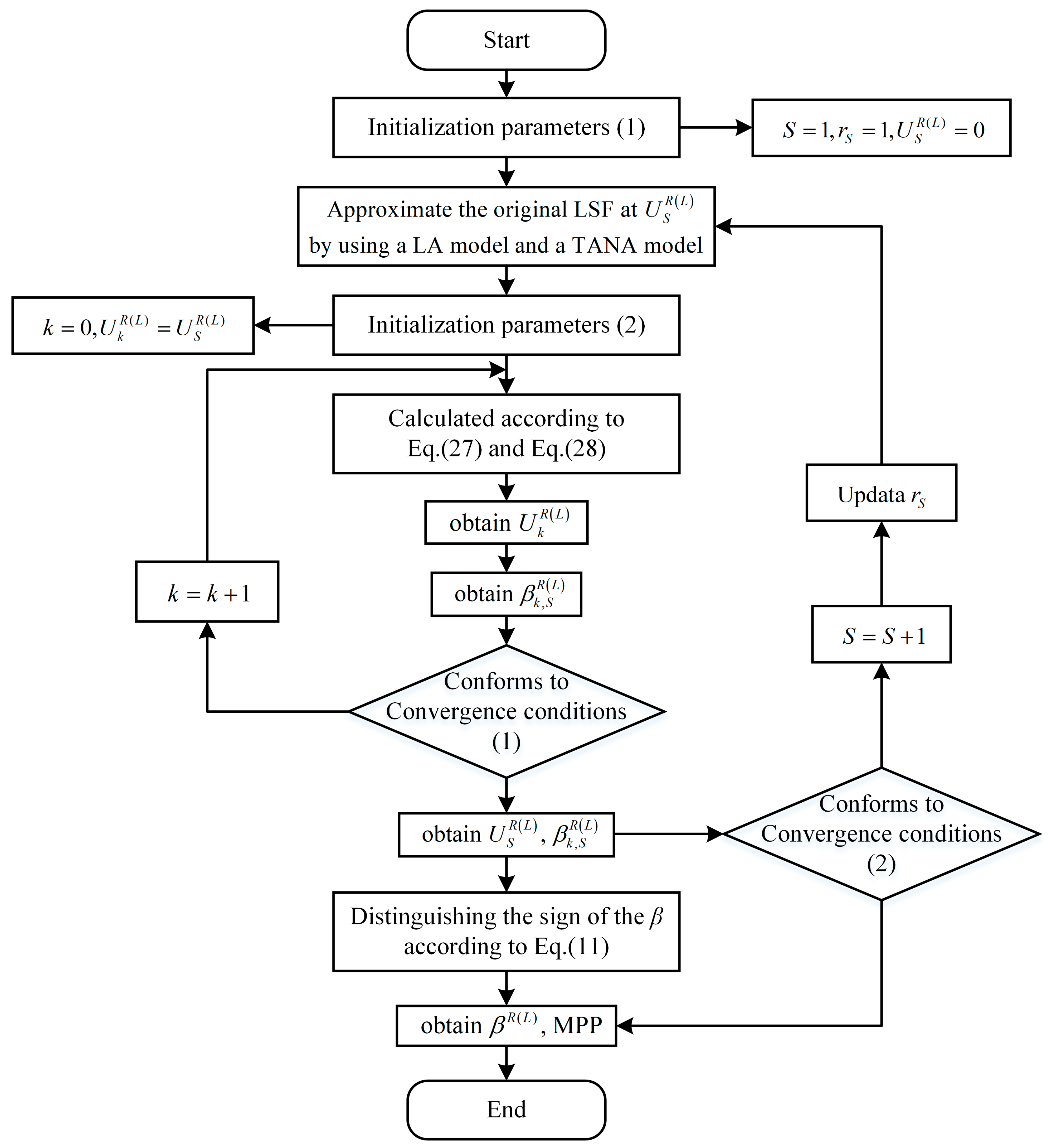
It can be known from Equation (10a,b) that the problem of hybrid structural reliability analysis with the p-box variables is a nested optimization problem. The inner layer is the process of solving the extremum of the LSF. For the above nested optimization problem, the computational workload of the traditional optimization algorithm is too heavy. In order to improve the calculation speed, the idea of an approximation model is used to approximate the upper and lower limits of the LSF. As such, the double-layer nested optimization structure is eliminated, the original optimization problem is transformed into a general optimization problem and finally a non-probabilistic hybrid reliability analysis method with p-box variables is constructed.
3. Approximation Model
In order to approximate the limit value of the LSF, it is necessary to use the approximation model. In this paper, the single-point approximation model and the two-point adaptive nonlinear approximation model are combined to approximate the LSF.
3.1. Single-Point Approximation Model
Based on the function value and gradient information at a single point, a single-point approximation model is established at the design point according to the first-order Taylor series. When using the traditional method optimization, since the search direction always needs to calculate the function value and the first derivative value in the optimization process, there is no need to add the calculation amount when constructing the single-point approximation model. There are a variety of single-point approximation models based on first-order Taylor expansion, including the linear approximation (LA) model, the reciprocal approximation model [
25] and the conservative approximation model [
26]. The single-point linear approximation model can be expressed as Equation (12).
3.2. Two-Point Adaptive Nonlinear Approximation (TANA) Model
When using the single-point approximation model based on the first-order Taylor series, as the iteration proceeds, a new approximate model needs to be reconstructed at the new design point. The analysis information of the previous iteration step will be discarded and will not be used to improve the subsequent approximation model, resulting in relatively low fitting accuracy.
The two-point adaptive nonlinear approximation model is based on not only the information of the current design point, but also the information of the previous iteration point, and the nonlinear characteristic of the TANA model is automatically adjustable by the function value and the gradient values of the known point. Therefore, the TANA model is an adaptive approximation model whose simulation accuracy is higher than the single-point approximation model. The intermediate variable
of the TANA model can be expressed as [
27,
28],
For any variable , the nonlinear index is equal to r.
When establishing a TANA model, the function values of the two points and the gradient values of the design points are necessary. First, the intermediate variable
is used to represent the first-order Taylor expansion of the design point, and the variable
is used in place of
in the extended expression. Typically, one of the two points is selected as the new design point and the other point is selected as the design point of the previous iteration. Its mathematical expression is
where
denotes the design point of the
kth iteration and
r denotes the nonlinear index. The nonlinear index will change during each iteration. The nonlinear index is determined by matching the function value at the previous design point
. That is, the difference between the approximation value and the exact value of
is zero.
In order to reduce the iterative calculation of the high-order polynomial approximation model,
r can be limited as
. This paper gives an idea of a solution. By constructing an optimization model, the nonlinear index
r is obtained.
It can be understood from Equations (11) and (13) that the LA model is a special case of the TANA model. When the nonlinear index , the TANA model is an LA model. The single-point approximation model is constructed according to the function value and the first-order derivative values at the design point, whereas in the TANA mode, the function value of another point is used to adjust the nonlinear index r such that the approximation value is equal to the exact function value. Therefore, the approximation accuracy of TANA is higher than the single-point approximation model.
Figure 3 shows a comparison of the approximation of the function using the LA model and the TANA model at design point
x = 1. Another point selected by the TANA model is
, and the nonlinear index is calculated as
. It can be seen that the LA model can only approximate the original function with linear precision, and its approximation accuracy for strong nonlinear functions is poor. The approximation accuracy of the TANA model is significantly higher than the LA model, and there is no need to calculate the high-order derivative.
6. Conclusions
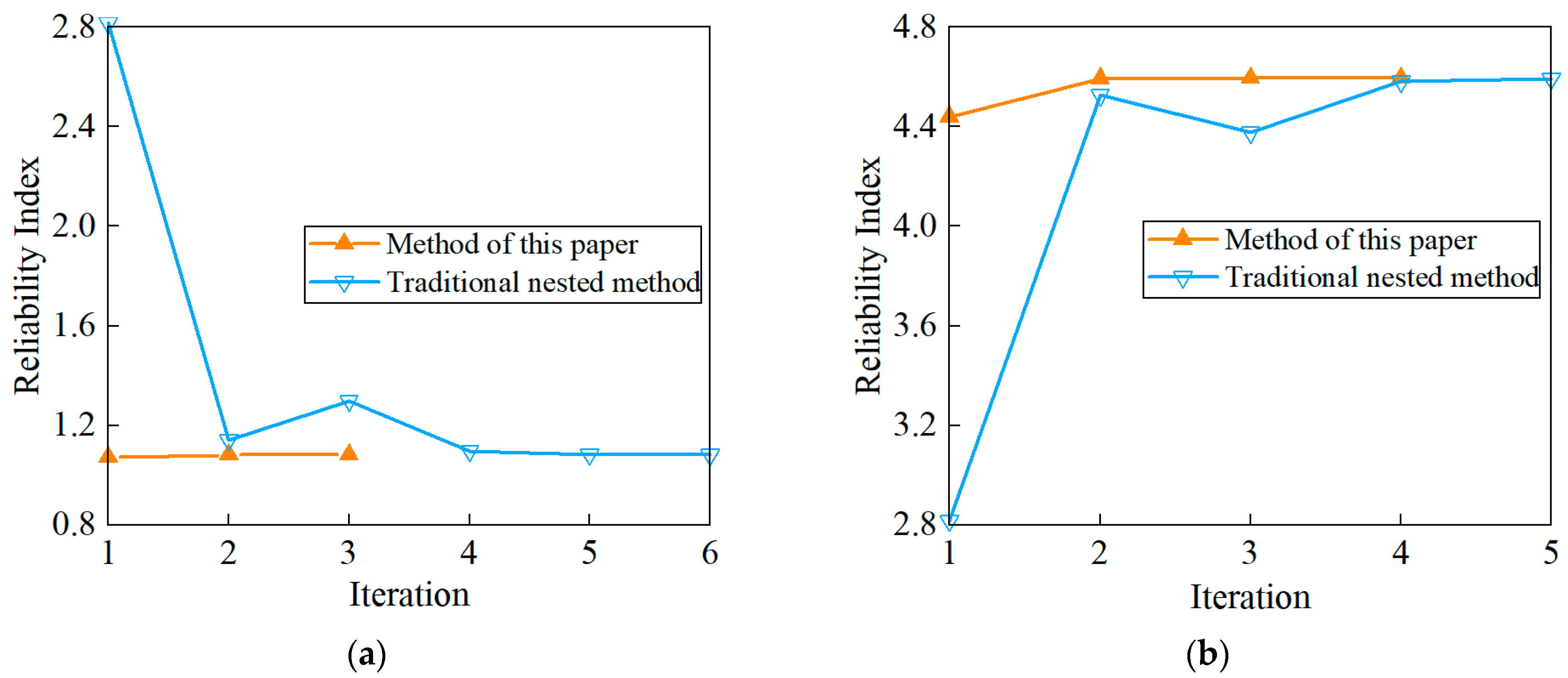
In this paper, a de-nesting analysis method of the non-probabilistic hybrid reliability index based on an approximate model is proposed for the reliability assessment of marine structures. The LA model and the TANA model are combined to approximate the extreme response value of the LSF quickly, in which it is only necessary to calculate the first-order partial derivative value of the LSF for a few times during each iteration calculation. As supported by the numerical examples and two engineering examples, as well as the comparison with the traditional nested structural reliability analysis methods, we show that the proposed method will reduce the number of LSF calls effectively and save computing resources. In cases where the LSF is an implicit structure and finite element analysis is required, an efficient reduction in the number of LSF calls means effectively reducing the number of finite element analyses and improving calculation efficiency compared to the traditional method.
In addition, the proposed method eliminates the inner structure of the traditional reliability analysis by using an LA model. Therefore, it is generally applicable to the hybrid structural reliability analysis with small uncertainty. For general marine structure problems, small uncertainty is very easy to implement, because excessive uncertainty leads to an excessively large interval of the structural reliability index, which is pointless for engineering guidance. Combined with the engineering example, the proposed algorithm has good convergence and calculation accuracy.
One limitation of the paper is that the adopted approximation method does not consider the dependence of variables when approximating the LSF extreme value by the LA model. The approximation accuracy decreases when there is strong dependence between variables. Thus, a de-nesting hybrid reliability analysis that considers strong variable dependence will be conducted in the future.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}