
An Underwater Image Restoration Deep Learning Network Combining Attention Mechanism and Brightness Adjustment

 , ,
, ,
Abstract
:1. Introduction
- The light-scattering impact of water molecules and different microorganisms: light reflection scatters after passing through water, resulting in blurred images and loss of details.
- The different wavelength frequencies cause different degrees of absorption underwater, resulting in bluish and greenish underwater images. Therefore, obtaining clear and non-color-cast underwater images without relying on special equipment is a significant technical challenge that needs to be solved.
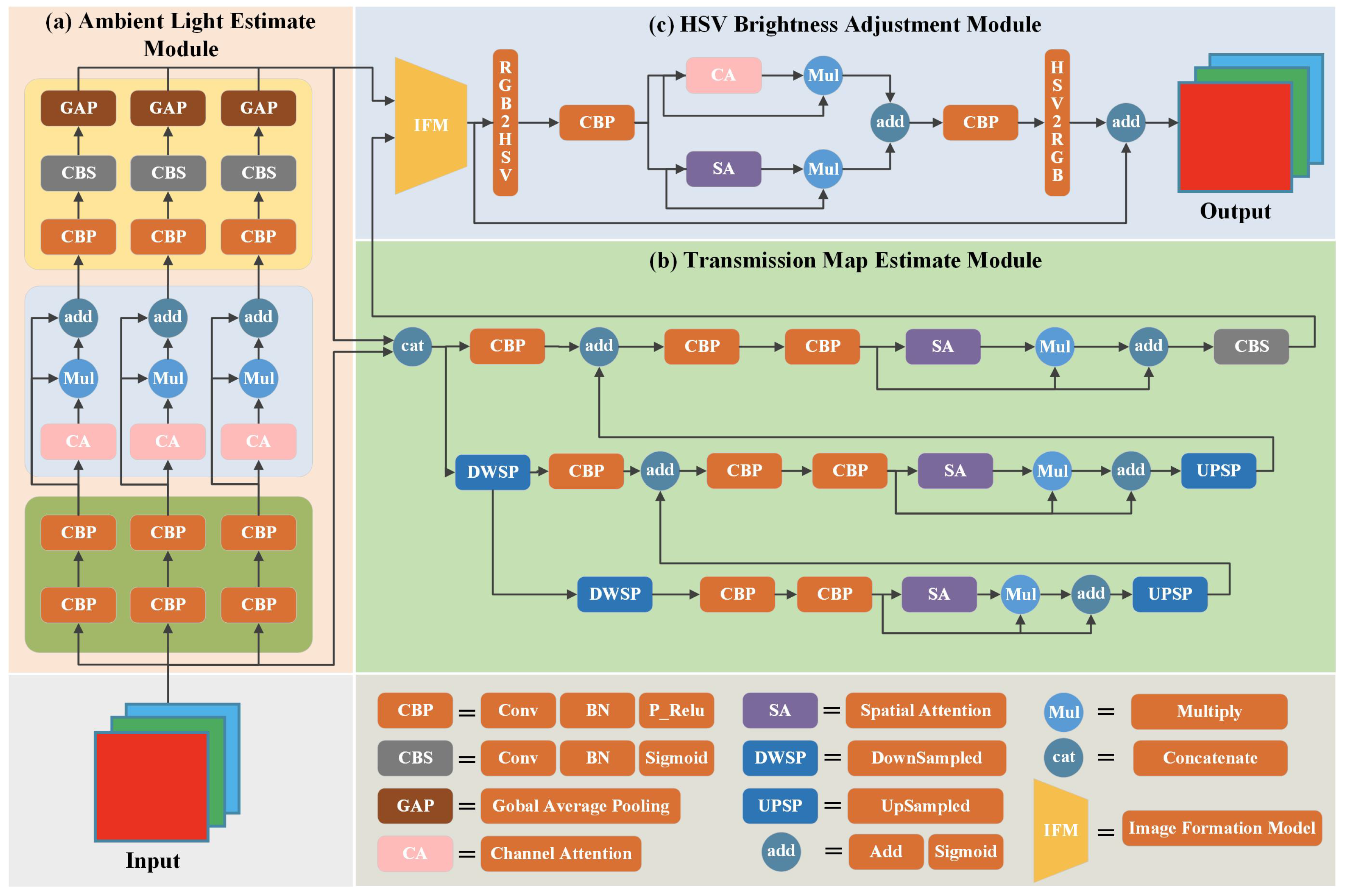
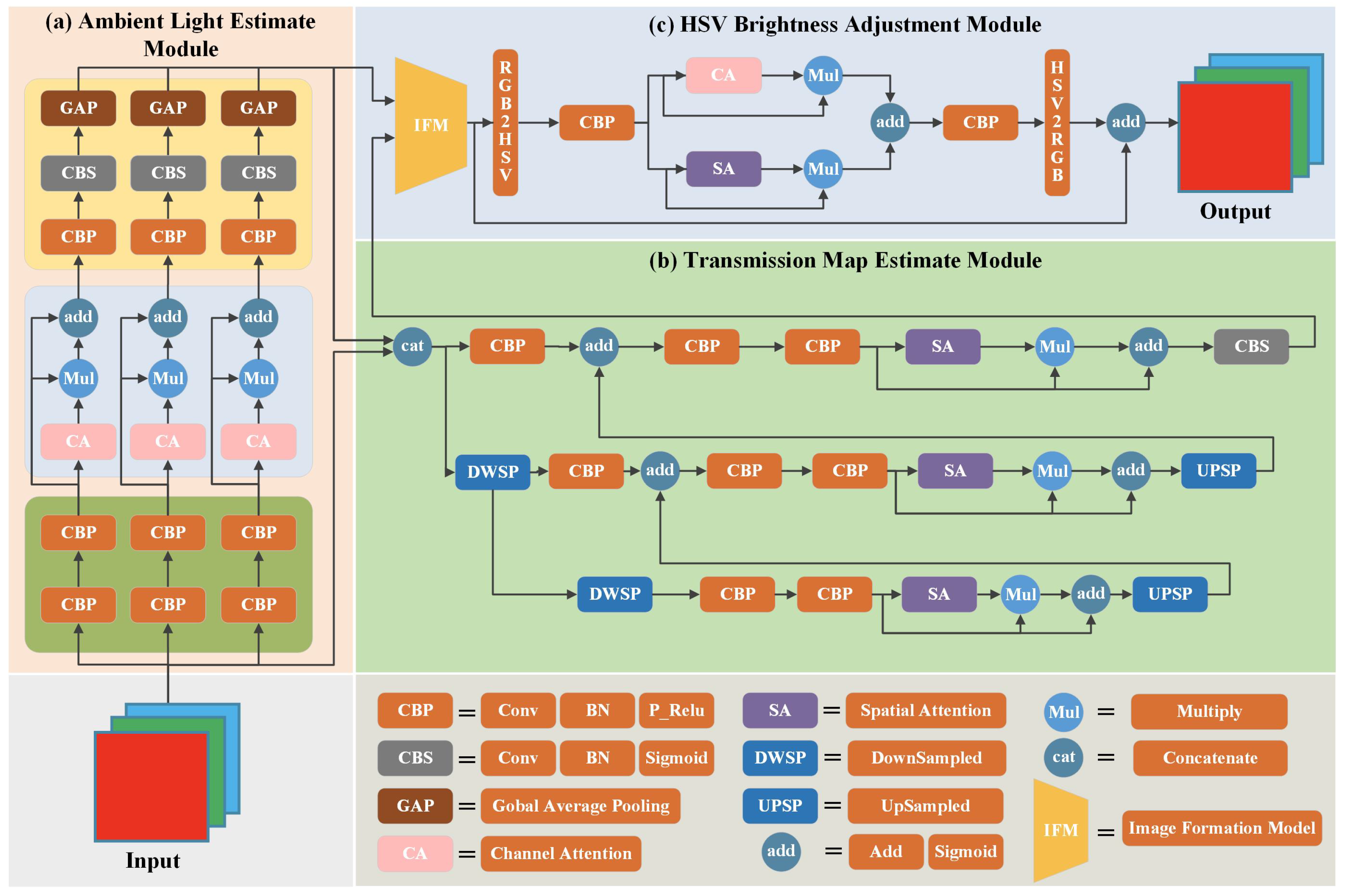
- Ambient light () estimation: The ambient light accurate estimation module achieves an accurate estimation of by designing a separate feature extraction network for each color channel and highlighting the most representative features through the channel attention [10] structure so that the network can fully uncover the scene information in the image.
- Transmittance map (TM) estimation: The complexity of underwater scenes was fully considered during the transmittance map estimation. So, in the design of the transmission map estimation module, the spatial attention [10] structure and the coder-decoder structure were combined. The features with rich layers and a global perception field were obtained through convolutional deconvolution and feature fusion operations. Finally, the estimated accurate and accurate TM are substituted into the underwater image formation model to obtain a preliminary recovered underwater image.
- HSV brightness adjustment: The recovered underwater images’ brightness is further adjusted by converting the underwater images to HSV color space and adjusting the brightness of the images.
- We present a multi-branch ambient light accurate estimation module that independently applies the convolution module with channel attention mechanism for each color channel, achieving multiple layers combination features, and adaptively selecting the most representative features to precisely estimate the .
- We propose an encoder-decoder transmission map estimation module that combines attention structures. Feature extraction of different layers is achieved through a series of downsampled and convolution operations with a spatial attention mechanism. The upsampling and feature fusion operations incorporate different layers of features into a unified structure to estimate the TM accurately.
- We introduce a parallel brightness adjustment module combining channel and spatial attention in HSV color space to achieve further image correction. Additionally, we propose a loss function that combines MSE, L1, SSIM, and HSV loss, deriving the optimal weighting coefficients for this function through extensive experimentation.
2. Relate Work
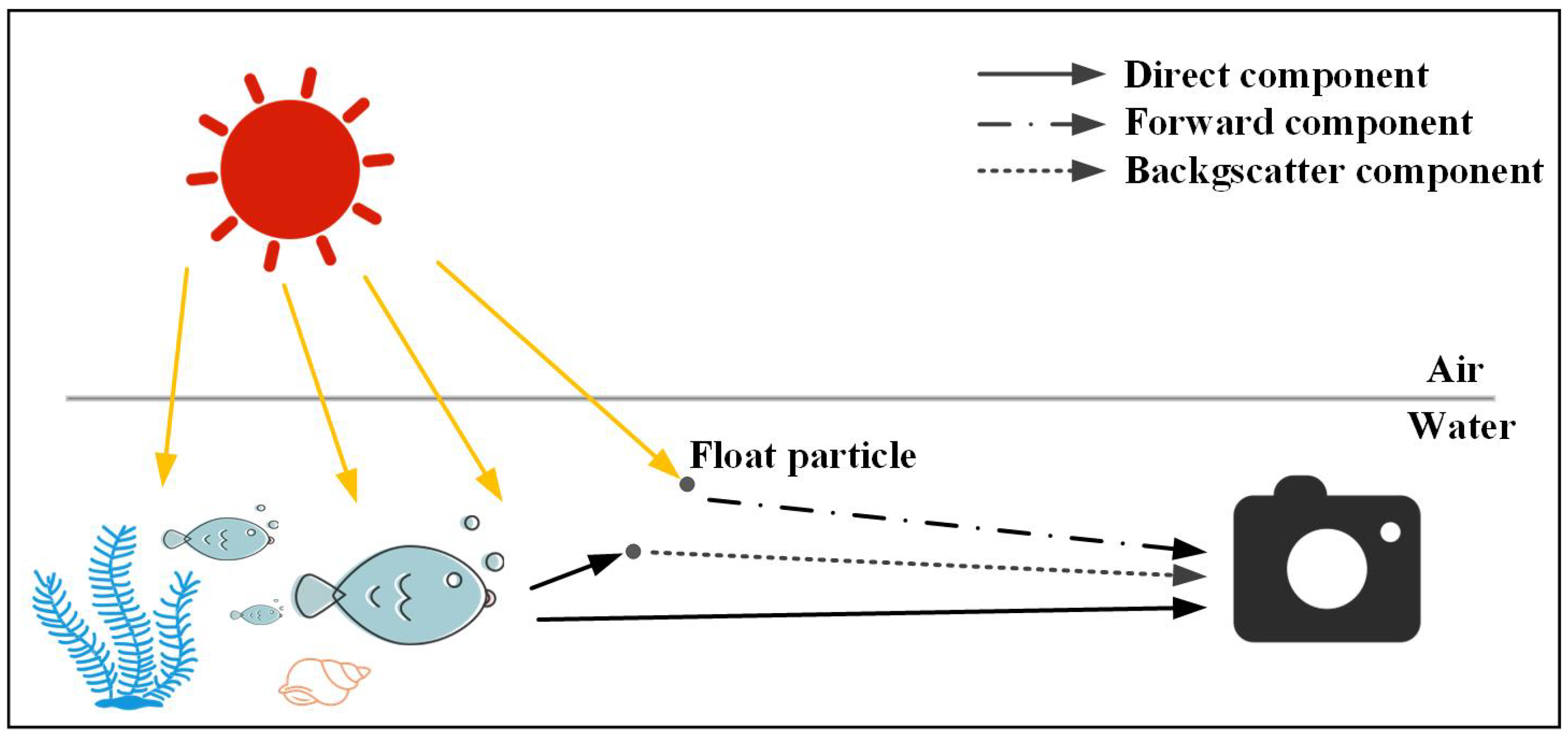
2.1. Underwater Image Formation Model
- The direct component: The reflected light from the scene that reaches the camera after being attenuated during propagation. This represents the underwater image to be recovered.
- The forward component: The part of the light that reaches the camera after small angle scattering during propagation after reflection from the scene surface, which is the leading cause of blurred underwater images. In the underwater shooting process, the camera is close to the subject, and its impact on the process can be negligible.
- The backward scattering component: The portion of the light that reaches the camera just after being scattered by suspended particles. This component is the main contributor to the deterioration of the image contrast.
2.2. Ambient Light Estimation
2.3. Transmission Map Estimation
3. Proposed Method
3.1. Ambient Light Estimate Module
3.2. Transmission Map Estimate Module
- Encoder module: The underwater image and are first concentrated. Two downsamples are performed to obtain three levels of feature representation. The output obtained from each downsample is subjected to two simple feature extractions to complete the extraction of preliminary features.
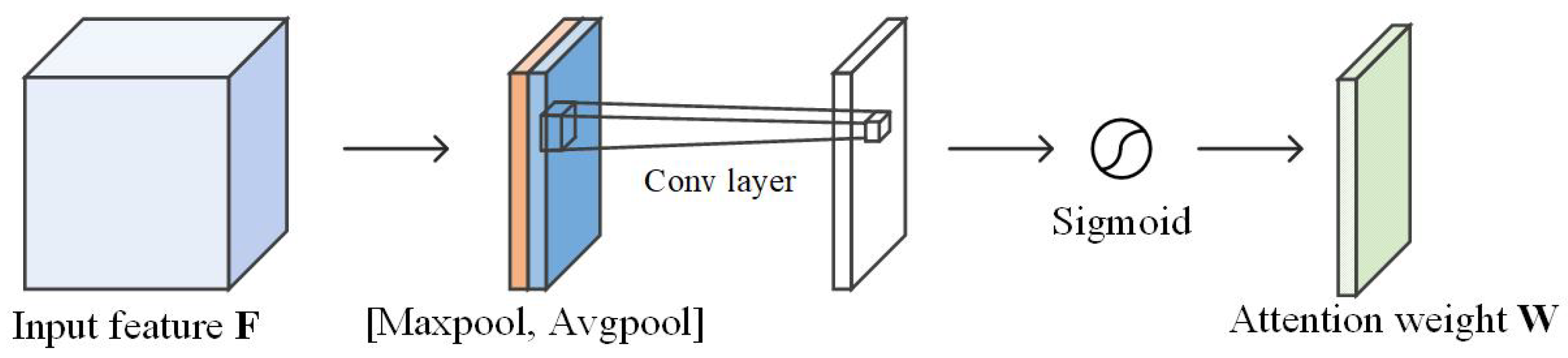
- Deep feature extraction combining spatial attention mechanism module: The preliminary extracted features are first subjected to maximum and global average pooling, generating two feature descriptors for each spatial location. Then, the two feature descriptors are superimposed, and a 7 × 7 size convolution kernel and Sigmoid function are used to generate a spatial attention map. Finally, the spatial attention map is multiplied with the preliminary feature map to complete the extraction of essential information and detailed features of underwater images.
- Decoder module: The extracted deep features are upsampled and expanded to the same size as the previous level features. Then, they are subjected to a feature extraction of the previous level combined with the spatial attention mechanism to integrate features from different levels.
3.3. HSV Brightness Adjustment Module
3.4. Loss Function
4. Experimental Results
4.1. Network Training Details
4.2. Subjective Evaluation
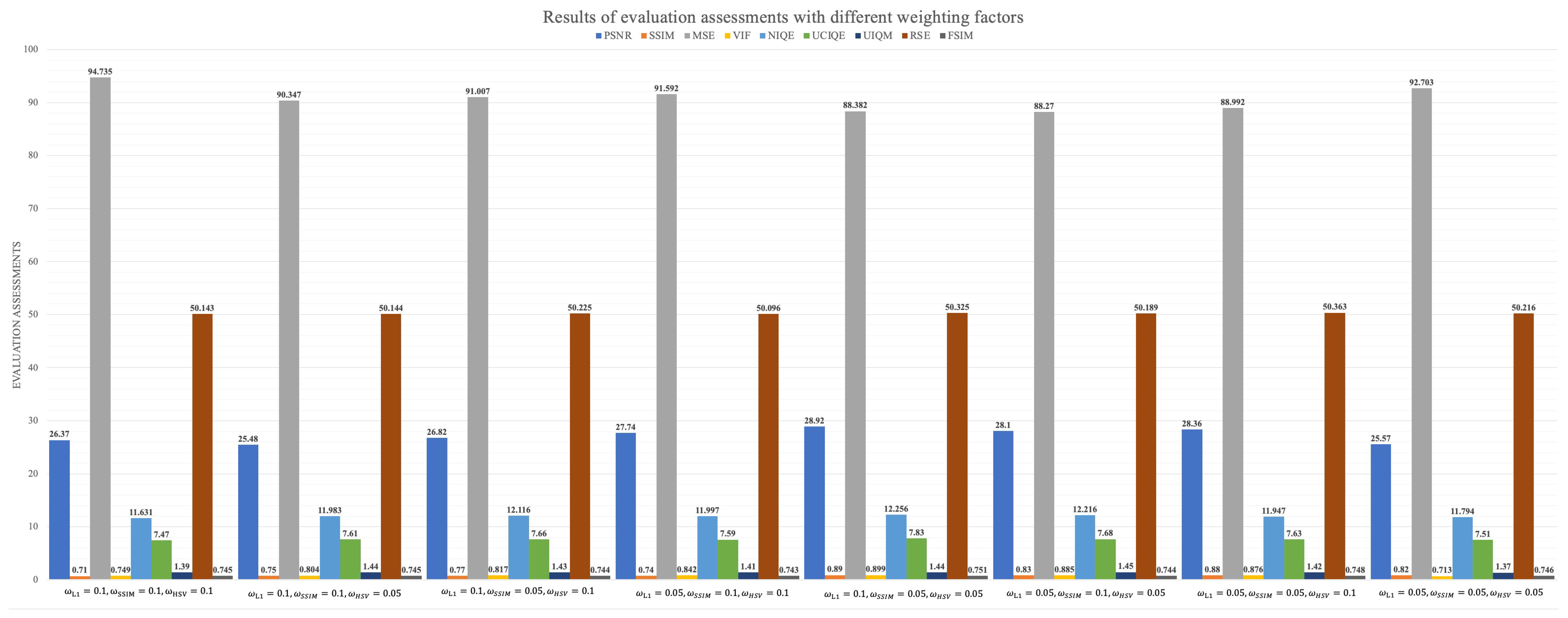
4.3. Objective Assessment
4.4. Application
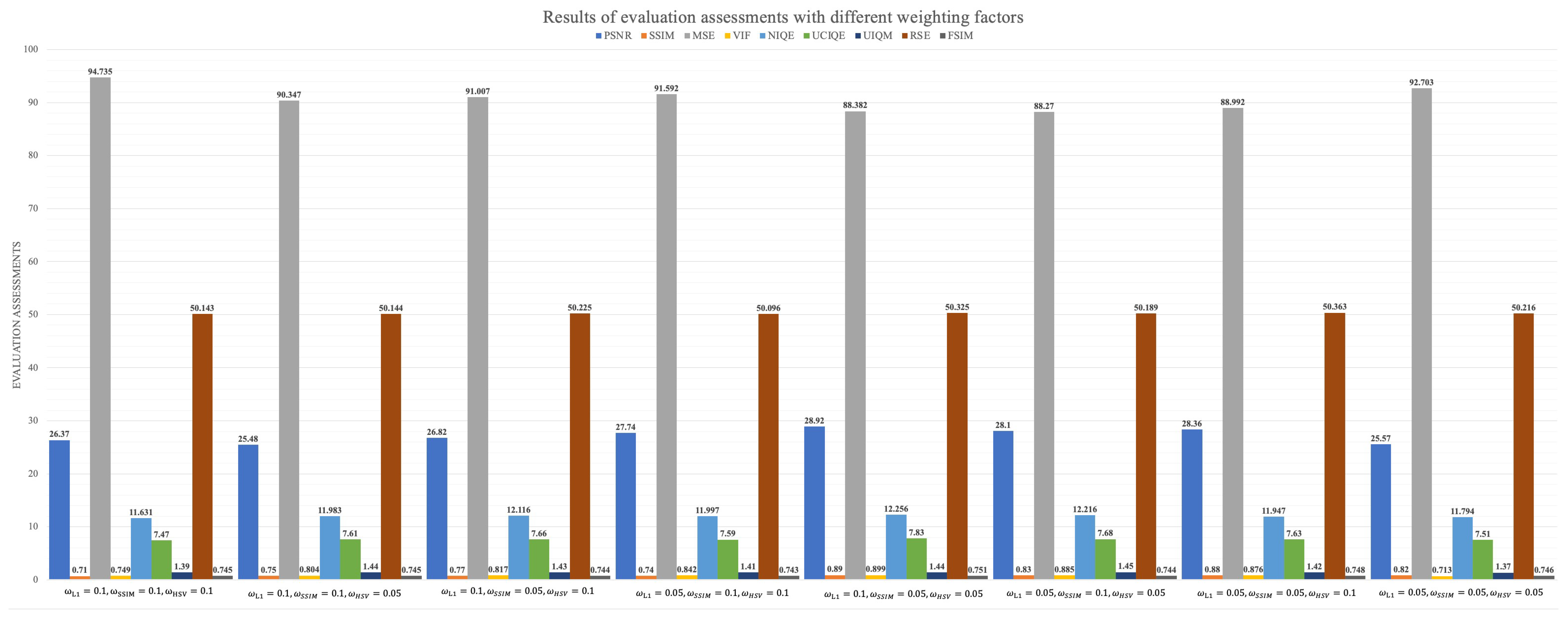
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Jiang, Q.; Liu, P.; Gao, S.; Pan, X.; Zhang, C. Underwater Image Enhancement Using Deep Transfer Learning Based on a Color Restoration Model. IEEE J. Ocean. Eng. 2023, 48, 489–514. [Google Scholar] [CrossRef]
- Zhang, W.; Jin, S.; Zhuang, P.; Liang, Z.; Li, C. Underwater image enhancement via piecewise color correction and dual prior optimized contrast enhancement. IEEE Signal Process. Lett. 2023, 30, 229–233. [Google Scholar] [CrossRef]
- Dasari, S.K.; Sravani, L.; Kumar, M.U.; Rama Venkata Sai, N. Image Enhancement of Underwater Images Using Deep Learning Techniques. In Proceedings of the International Conference on Data Analytics and Insights; Springer: Berlin/Heidelberg, Germany, 2023; pp. 715–730. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Shi, S.; Zhang, Y.; Zhou, X.; Cheng, J. A novel thin cloud removal method based on multiscale dark channel prior (MDCP). IEEE Geosci. Remote Sens. Lett. 2021, 19, 1001905. [Google Scholar] [CrossRef]
- Tang, Q.; Yang, J.; He, X.; Jia, W.; Zhang, Q.; Liu, H. Nighttime image dehazing based on Retinex and dark channel prior using Taylor series expansion. Comput. Vis. Image Underst. 2021, 202, 103086. [Google Scholar] [CrossRef]
- Zhou, Y.; Gu, X.; Li, Q. Underwater Image Restoration Based on Background Light Corrected Image Formation Model. J. Electron. Inf. Technol. 2022, 44, 1–9. [Google Scholar]
- Chai, S.; Fu, Z.; Huang, Y.; Tu, X.; Ding, X. Unsupervised and Untrained Underwater Image Restoration Based on Physical Image Formation Model. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2774–2778. [Google Scholar]
- Cui, Y.; Sun, Y.; Jian, M.; Zhang, X.; Yao, T.; Gao, X.; Li, Y.; Zhang, Y. A novel underwater image restoration method based on decomposition network and physical imaging model. Int. J. Intell. Syst. 2022, 37, 5672–5690. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- McGlamery, B. A computer model for underwater camera systems. In Proceedings of the Ocean Optics VI; SPIE: Bellingham, WA, USA, 1980; Volume 208, pp. 221–231. [Google Scholar]
- Yang, H.Y.; Chen, P.Y.; Huang, C.C.; Zhuang, Y.Z.; Shiau, Y.H. Low complexity underwater image enhancement based on dark channel prior. In Proceedings of the 2011 Second International Conference on Innovations in Bio-inspired Computing and Applications, Shenzhen, China, 16–18 December 2011; pp. 17–20. [Google Scholar]
- Chao, L.; Wang, M. Removal of water scattering. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Technology, Chengdu, China, 16–18 April 2010; Volume 2, pp. V2-35–V2-39. [Google Scholar]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Yu, H.; Li, X.; Lou, Q.; Lei, C.; Liu, Z. Underwater image enhancement based on DCP and depth transmission map. Multimed. Tools Appl. 2020, 79, 20373–20390. [Google Scholar] [CrossRef]
- Wang, H.G.; Zhang, Y.Q. Deep sea image enhancement method based on the active illumination. Acta Photonica Sin. 2020, 49, 0310001. [Google Scholar]
- Muniraj, M.; Dhandapani, V. Underwater image enhancement by combining color constancy and dehazing based on depth estimation. Neurocomputing 2021, 460, 211–230. [Google Scholar] [CrossRef]
- Shin, Y.S.; Cho, Y.; Pandey, G.; Kim, A. Estimation of ambient light and transmission map with common convolutional architecture. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–7. [Google Scholar]
- Peng, Y.T.; Cosman, P.C. Single image restoration using scene ambient light differential. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Woo, S.M.; Lee, S.H.; Yoo, J.S.; Kim, J.O. Improving color constancy in an ambient light environment using the Phong reflection model. IEEE Trans. Image Process. 2017, 27, 1862–1877. [Google Scholar] [CrossRef] [PubMed]
- Cao, K.; Peng, Y.T.; Cosman, P.C. Underwater image restoration using deep networks to estimate background light and scene depth. In Proceedings of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018; pp. 1–4. [Google Scholar]
- Yang, S.; Chen, Z.; Feng, Z.; Ma, X. Underwater image enhancement using scene depth-based adaptive background light estimation and dark channel prior algorithms. IEEE Access 2019, 7, 165318–165327. [Google Scholar] [CrossRef]
- Wu, S.; Luo, T.; Jiang, G.; Yu, M.; Xu, H.; Zhu, Z.; Song, Y. A Two-Stage underwater enhancement network based on structure decomposition and characteristics of underwater imaging. IEEE J. Ocean. Eng. 2021, 46, 1213–1227. [Google Scholar] [CrossRef]
- Carlevaris-Bianco, N.; Mohan, A.; Eustice, R.M. Initial results in underwater single image dehazing. In Proceedings of the Oceans 2010 Mts/IEEE Seattle, Seattle, WA, USA, 20–23 September 2010; pp. 1–8. [Google Scholar]
- Li, C.Y.; Guo, J.C.; Cong, R.M.; Pang, Y.W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef]
- Pan, P.w.; Yuan, F.; Cheng, E. Underwater image de-scattering and enhancing using dehazenet and HWD. J. Mar. Sci. Technol. 2018, 26, 6. [Google Scholar]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2822–2837. [Google Scholar] [CrossRef]
- Song, W.; Wang, Y.; Huang, D.; Liotta, A.; Perra, C. Enhancement of underwater images with statistical model of background light and optimization of transmission map. IEEE Trans. Broadcast. 2020, 66, 153–169. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, T.; Ren, W.; Zhang, D.; Zhang, W. Underwater image restoration via depth map and illumination estimation based on a single image. Opt. Express 2021, 29, 29864–29886. [Google Scholar] [CrossRef]
- Liu, K.; Liang, Y. Enhancement of underwater optical images based on background light estimation and improved adaptive transmission fusion. Opt. Express 2021, 29, 28307–28328. [Google Scholar] [CrossRef]
- Li, T.; Zhou, T. Multi-scale fusion framework via retinex and transmittance optimization for underwater image enhancement. PLoS ONE 2022, 17, e0275107. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Lin, Y.; Zhou, J.; Ren, W.; Zhang, W. Autonomous underwater robot for underwater image enhancement via multi-scale deformable convolution network with attention mechanism. Comput. Electron. Agric. 2021, 191, 106497. [Google Scholar] [CrossRef]
- Wang, J.; Li, P.; Deng, J.; Du, Y.; Zhuang, J.; Liang, P.; Liu, P. CA-GAN: Class-condition attention GAN for underwater image enhancement. IEEE Access 2020, 8, 130719–130728. [Google Scholar] [CrossRef]
- Yang, H.H.; Huang, K.C.; Chen, W.T. Laffnet: A lightweight adaptive feature fusion network for underwater image enhancement. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 685–692. [Google Scholar]
- Dorothy, R.; Joany, R.M.; Rathish, R. Image enhancement by histogram equalization. Int. J. Nano Corros. Sci. Eng. 2015, 2, 21–30. [Google Scholar]
- Mohan, S.; Simon, P. Underwater image enhancement based on histogram manipulation and multiscale fusion. Procedia Comput. Sci. 2020, 171, 941–950. [Google Scholar] [CrossRef]
- Ma, Z.; Oh, C. A Wavelet-Based Dual-Stream Network for Underwater Image Enhancement. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2769–2773. [Google Scholar]
- Zheng, J.; Yang, G.; Liu, S.; Cao, L.; Zhang, Z. Accurate estimation of underwater image restoration based on dual-background light adaptive fusion and transmission maps. Trans. Chin. Soc. Agric. Eng. 2022, 38, 174–182. [Google Scholar]
- Chen, X.; Zhang, P.; Quan, L.; Yi, C.; Lu, C. Combining deep learning and image formation model for underwater image enhancement. Comput. Eng. 2022, 48, 243–249. [Google Scholar]
- Liu, S.; Fan, H.; Lin, S.; Wang, Q.; Ding, N.; Tang, Y. Adaptive Learning Attention Network for Underwater Image Enhancement. IEEE Robot. Autom. Lett. 2022, 7, 5326–5333. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Kumar, N.N.; Ramakrishna, S. An Impressive Method to Get Better Peak Signal Noise Ratio (PSNR), Mean Square Error (MSE) Values Using Stationary Wavelet Transform (SWT). Glob. J. Comput. Sci. Technol. Graph. Vis. 2012, 12, 34–40. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Saxena, S.; Singh, Y.; Agarwal, B.; Poonia, R.C. Comparative analysis between different edge detection techniques on mammogram images using PSNR and MSE. J. Inf. Optim. Sci. 2022, 43, 347–356. [Google Scholar] [CrossRef]
- Dimitri, G.M.; Spasov, S.; Duggento, A.; Passamonti, L.; Lio’, P.; Toschi, N. Multimodal image fusion via deep generative models. bioRxiv 2021. [Google Scholar] [CrossRef]
- Peng, C.; Wu, M.; Liu, K. Multiple levels perceptual noise backed visual information fidelity for picture quality assessment. In Proceedings of the 2022 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Penang, Malaysia, 22–25 November 2022; pp. 1–4. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Jiang, Q.; Shao, F.; Gao, W.; Chen, Z.; Jiang, G.; Ho, Y.S. Unified no-reference quality assessment of singly and multiply distorted stereoscopic images. IEEE Trans. Image Process. 2018, 28, 1866–1881. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef] [PubMed]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Tanchenko, A. Visual-PSNR measure of image quality. J. Vis. Commun. Image Represent. 2014, 25, 874–878. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Full-Reference Quality Assessment | No-Reference Quality Assessment | Average Processing Time per Image of Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | MSE | VIF | FSIM | SRE | NIQE | UCIQE | UIQM | ||
| HE | 28.203 | 0.751 | 98.577 | 0.809 | 0.74 | 49.883 | 12.41 | 7.018 | 1.352 | 0.08 s |
| MulFusion | 28.09 | 0.672 | 101.19 | 0.816 | 0.729 | 49.963 | 12.505 | 5.676 | 1.424 | 1.14 s |
| WBDS | 28.59 | 0.61 | 104.447 | 0.641 | 0.695 | 49.441 | 15.128 | 5.648 | 0.883 | 3.59 s |
| UDCP | 27.869 | 0.507 | 106.409 | 0.798 | 0.674 | 50.148 | 13.903 | 7.586 | 0.418 | 35.50 s |
| IBLA | 28.127 | 0.566 | 100.921 | 0.741 | 0.728 | 47.221 | 13.253 | 2.231 | 0.316 | 91.29 s |
| DBLTM | 28.074 | 0.755 | 102.131 | 0.81 | 0.703 | 50.068 | 13.95 | 4.978 | 1.118 | 61.36 s |
| DLIFM | 28.627 | 0.846 | 90.19 | 0.822 | 0.73 | 47.545 | 15.681 | 4.166 | 1.039 | 0.51 s |
| LANet | 28.792 | 0.89 | 89.459 | 0.819 | 0.747 | 50.883 | 13.936 | 4.21 | 0.912 | 3.56 s |
| Our | 28.92 | 0.827 | 88.382 | 0.899 | 0.751 | 50.325 | 12.256 | 7.83 | 1.44 | 0.56 s |
| Full-Reference Quality Assessment | No-Reference Quality Assessment | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | MSE | VIF | FSIM | SRE | NIQE | UCIQE | UIQM | |
| Full Model | 28.92 | 0.827 | 88.382 | 0.899 | 0.751 | 50.325 | 12.256 | 7.83 | 1.44 |
| w/o AL Model | 28.675 | 0.796 | 89.322 | 0.823 | 0.571 | 41.295 | 17.031 | 3.683 | 1.067 |
| w/o TM Model | 28.623 | 0.818 | 90.361 | 0.821 | 0.634 | 44.371 | 17.23 | 4.965 | 1.192 |
| w/o HSV Model | 28.049 | 0.731 | 102.112 | 0.815 | 0.619 | 42.79 | 16.528 | 3.55 | 0.801 |
| Full-Reference Quality Assessment | No-Reference Quality Assessment | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | MSE | VIF | FSIM | SRE | NIQE | UCIQE | UIQM | |
| Full Model | 28.92 | 0.827 | 88.382 | 0.899 | 0.751 | 50.325 | 12.256 | 7.83 | 1.44 |
| w/o MSE Model | 28.672 | 0.802 | 89.495 | 0.82 | 0.691 | 46.507 | 14.947 | 3.101 | 1.184 |
| w/o L1 Model | 28.587 | 0.816 | 90.908 | 0.821 | 0.671 | 47.211 | 17.088 | 3.81 | 1.014 |
| w/o SSIM Model | 28.672 | 0.805 | 89.45 | 0.82 | 0.669 | 46.601 | 18.403 | 4.947 | 1.184 |
| w/o HSV Model | 28.654 | 0.791 | 89.643 | 0.821 | 0.674 | 45.967 | 16.929 | 3.101 | 1.088 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Zhao, R.; Yang, G.; Liu, S.; Zhang, Z.; Fu, Y.; Lu, J. An Underwater Image Restoration Deep Learning Network Combining Attention Mechanism and Brightness Adjustment. J. Mar. Sci. Eng. 2024, 12, 7. https://doi.org/10.3390/jmse12010007
Zheng J, Zhao R, Yang G, Liu S, Zhang Z, Fu Y, Lu J. An Underwater Image Restoration Deep Learning Network Combining Attention Mechanism and Brightness Adjustment. Journal of Marine Science and Engineering. 2024; 12(1):7. https://doi.org/10.3390/jmse12010007
Chicago/Turabian StyleZheng, Jianhua, Ruolin Zhao, Gaolin Yang, Shuangyin Liu, Zihao Zhang, Yusha Fu, and Junde Lu. 2024. "An Underwater Image Restoration Deep Learning Network Combining Attention Mechanism and Brightness Adjustment" Journal of Marine Science and Engineering 12, no. 1: 7. https://doi.org/10.3390/jmse12010007
APA StyleZheng, J., Zhao, R., Yang, G., Liu, S., Zhang, Z., Fu, Y., & Lu, J. (2024). An Underwater Image Restoration Deep Learning Network Combining Attention Mechanism and Brightness Adjustment. Journal of Marine Science and Engineering, 12(1), 7. https://doi.org/10.3390/jmse12010007