1. Introduction
Apples are one of the most important economic fruit crops worldwide, and their efficient harvesting is crucial in improving fruit quality and maximizing growers’ profits [
1]. However, the harvesting process is highly dependent on manual labor, making it a labor-intensive agricultural activity. In recent years, rising labor costs and the migration of rural labor to urban areas have exacerbated labor shortages in fruit harvesting, constraining the sustainable development of the industry and driving research into automated harvesting technologies [
2,
3]. With the rapid advancement of agricultural robotics, harvesting robots have been developed for various fruits and vegetables, including tomatoes [
4], strawberries [
5], and apples [
6,
7]. Research on apple harvesting robots has made significant progress in structural optimization [
8], fruit recognition and localization [
9], task planning [
10], and path planning [
11].
In recent years, the integration of picking robots into new agricultural practices has become a new trend in industry development [
12]. Apple orchards are characterized by large operational spaces and randomly distributed, densely packed fruits. When facing large-scale operational scenarios, single-arm robots often require frequent path adjustments, resulting in repetitive tasks and low efficiency. To address this issue, an increasing amount of research [
13,
14,
15] has focused on adopting multi-arm configurations to improve picking efficiency and operational coverage. Notably, modern standard apple orchards have a spatial distribution of fruits more closely resembling 2D fruit walls, significantly improving the accessibility and visibility of fruits compared to traditional orchards [
16]. This improvement provides a favorable environment for research and development in picking robots.
Although multi-arm robots offer greater operational space and potential, they also introduce greater complexity compared to single-arm robots in two key aspects. Their collaborative performance necessitates task planning. When multiple arms are involved in completing a task, optimizing the sequence of actions can minimize the time required for harvesting and reduce idle times and redundant actions. Barnett et al. [
17] implemented a task partitioning algorithm based on key functions and sorting operators to achieve optimal or near-optimal task division in kiwifruit picking, addressing multi-arm task allocation and accessibility issues to minimize picking time. Arikapudi et al. [
16] optimized multi-arm cooperative picking efficiency by defining the impact of maximum linear acceleration and velocity on the PCT. Yang et al. [
18] proposed an approach integrating an improved local density bidirectional clustering algorithm, a genetic algorithm, and a modified ant colony algorithm incorporating an auction mechanism, to address multi-arm collaborative picking path planning. Their method can find a stable optimal solution in relatively short timeframes. Meanwhile, Zhi et al. [
19] adopted a BSO (Brain Storm Optimization) algorithm to plan the picking sequence, constructed a dual-arm parameter model, and performed collision detection and obstacle avoidance based on this model. Simulation and experimental results indicated that their method effectively planned dual-arm picking tasks, achieving an average success rate of approximately 86.67%.
From these studies, it is clear that multi-arm cooperative planning involves both task distribution and the planning and coordination of fruit-picking sequences. These problems are typically classified as operation research optimization problems and are NP-hard. As the number of target fruits increases, the scale of the problem grows exponentially, making it extremely challenging to find exact solutions within polynomial time.
Some scholars have attempted to solve such problems using heuristic algorithms. Polina et al. applied the Traveling Salesman Problem (TSP) to task scheduling by optimizing the harvest order, thus improving crop picking efficiency [
10]. B. Zion proposed an approximation algorithm based on genetic algorithms and a local search for task allocation among multiple arms, optimizing the picking sequence [
20]. In our previous research, we modeled the multi-arm apple-picking robot cooperative task planning problem as a Multi-TSP (mTSP) and successfully improved picking efficiency by 4.25 times by incorporating asynchronous overlap constraints and using a dual-chromosome genetic algorithm [
6].
Although heuristic methods offer feasible and effective solutions for task planning, they still face challenges such as long solution times, local optimal solutions, and difficulties in analytically describing the interrelationships among tasks [
21]. Particularly in actual harvesting operations, unforeseen dynamic changes such as fruit drop and picking failure require online task adjustment, making this problem even more complex [
22]. Currently, few studies have fully considered this scenario.
Deep Reinforcement Learning (DRL), a cutting-edge method that combines the powerful fitting ability of deep neural networks with reinforcement learning theory, has shown tremendous potential in dynamic optimization problems [
23]. Compared to traditional optimization methods (e.g., genetic algorithms, particle swarm algorithms), DRL can make real-time decisions in dynamic environments and continuously improve strategies through interaction with the environment. This makes reinforcement learning particularly suitable for tasks that require decision-making in time-series contexts. The deep neural network in DRL can effectively handle input data through multi-layer non-linear mappings, improving the efficiency and accuracy of task execution. In traditional reinforcement learning, many tasks possess time-sequential properties [
24]. Long Short-Term Memory (LSTM) networks, with their specialized gating mechanisms, enable models to retain historical information in long-term tasks, effectively solving the “long-term dependency” problem [
25].
However, existing research mainly focuses on static environments or single-arm robots, lacking the in-depth exploration of task planning for multi-arm harvesting robots in dynamic environments. This deficiency makes it difficult for robots to promptly adjust task plans when the environment changes or uncertain factors arise, resulting in idle robotic arms, reduced harvesting efficiency, and insufficient task adaptability and ultimately limiting the overall system performance. To address these issues, this study develops a reinforcement learning-based online task planning framework for multi-arm orchard picking. Additionally, to overcome the slow convergence and instability frequently encountered in conventional reinforcement learning approaches, a new deep reinforcement learning-based online planning method is introduced. This method is designed for multi-arm fruit-picking decision-making, improving overall system robustness and adaptability in real-world applications.
The contributions of this paper are as follows:
We propose an innovative task planning and cooperative control method for multi-arm collaborative picking tasks in complex and dynamic environments. This method effectively addresses the limitations of traditional algorithms in dynamic environments, especially in cases of fruit mispositioning, picking accuracy deviations, and environmental changes. It adapts to different operational conditions through online re-planning.
To overcome the challenges of slow convergence and instability in traditional reinforcement learning models, we incorporate Long Short-Term Memory (LSTM) networks into the Proximal Policy Optimization (PPO) algorithm. By combining LSTM with PPO, we significantly improve both learning speed and stability, particularly in dynamic and time-dependent environments.
We develop an innovative deep reinforcement learning (DRL)-based task planning framework. This framework enables robots to perform online re-planning in dynamic environments. Numerical simulation results show that the framework outperforms traditional task planning methods in terms of task completion time and adaptability, demonstrating superior performance.
2. Preliminary Details
2.1. Robotic System Structure
The subject of this study is a dual-arm apple-picking robot based on a Cartesian coordinate system, as shown in
Figure 1. The robot consists primarily of two picking arms, labeled as the upper and lower arms based on their relative positions. In addition, the robot comprises several subsystems, including a wheeled mobile platform, a fruit transport device, a visual sensing system, a power system, and a central control system.
The picking arms are powered by a hybrid pneumatic–electric drive system. Each arm includes a three-degree-of-freedom electric-driven Cartesian coordinate robotic arm and a pneumatic cylinder. The arms employ a two-stage telescoping motion to facilitate efficient and frequent back-and-forth movements of the gripper between the tree canopy and the robot body. The pneumatic drive is used for extending and retracting the robot body relative to the edge of the tree canopy, while precise positioning within the canopy is achieved by an electric servo-driven telescoping mechanism. Each motor is equipped with a driver and an encoder, enabling precise control over joint positions and speeds. The end effector is custom-designed and consists of three 3D-printed curved fingers with two degrees of freedom (twisting and opening/closing), allowing the gripper to perform rotation and grasping actions to efficiently detach the target fruit.
The visual sensing system primarily consists of an RGB-D camera and an edge computing module. First, the RGB-D camera captures the color and depth images at the current position. The YOLOv8 vision detection model is then applied to detect apples in the RGB image, generating 2D bounding boxes and masks. A point cloud is generated by fusing the color and depth images, and the mask is used to extract the corresponding portion of the point cloud in order to obtain 3D information on the apples. The fruit transport system consists of two fruit bins and a vertical conveyor device. The bins move along the robot’s Z-axis, transferring the harvested fruit to the conveyor belt of the vertical transport device.
2.2. Overall Workflow
Each picking arm can independently complete the entire picking process. Since fruits naturally hang down under the force of gravity, they are primarily distributed below the branches and leaves. To minimize fruit occlusion, each arm performs the picking action with an upward inclined posture. Each picking cycle involves five consecutive actions:
Approach (A): Move the horizontal and vertical joints to align with the target fruit.
Extend (E): Extend the telescoping joints and pneumatic cylinder to approach the target fruit, then open the gripper to envelop the target fruit.
Grasp (G): Close the gripper to grasp the target fruit and perform a twisting action to detach the fruit from the branch.
Retract (R): Retract the telescoping joints and pneumatic cylinder.
Collect (C): Move the horizontal and vertical joints to position the gripper near the fruit bin on the horizontal rail, then open the gripper to release the target fruit into the bin.
These actions are executed in the sequence A-E-G-R-C, as shown in
Figure 2. Each fruit can only be harvested by one arm at a time. It is important to note that action E does not need to wait for the completion of action A, but it must be ensured that action A is finished before action E begins. Additionally, actions E and A must align the gripper with the target fruit before action G can be executed. Action C does not need to wait for action R to be completed but it must be ensured that action R is completed before action C.
Based on this sequence, we define the action group E-G as the pick action and the action group R-C as the place action. The pick action represents the process in which the arm moves from its starting position to the target fruit and performs the harvesting, while the place action represents the movement of the arm from the target fruit to the fruit bin to place the harvested fruit inside.
However, in actual harvesting operations, interference from tree branches and the gripper possibly capturing leaves or branches during fruit grasping may cause failures in the pick action. Additionally, rigid collisions between the arm and branches or fruits during the operation could also result in unexpected fruit drop.
The robot in this study consists of two arms capable of independently completing harvesting tasks. However, these two arms share a
Z-axis and do not operate independently. This design is intended to enhance the operational range of each arm while reducing the overall weight and cost of the robot. Due to mechanical interference, the vertical distance between the upper and lower arms along the
Z-axis is required to be greater than 300 mm. This leads to the creation of a “dead zone” between the two arms when their distance along the
Z-axis reaches the minimum threshold. In this zone, neither arm can directly reach and execute a harvesting task, as shown in
Figure 3.
Thus, compared to high-degree-of-freedom robots, the movement of the two arms occurs within a constrained, shared space. For example, as shown in
Figure 4, interference in the motion path of the upper arm due to joint coupling and mechanical constraints cannot be resolved by optimizing the motion path, resulting in situations where one arm is active while the other remains idle during task execution. This inevitably increases the overall time required to complete the task. When the number of target fruits is small, task planning remains relatively simple. However, as the number of target fruits increases, the complexity of task planning grows exponentially. Moreover, higher fruit density further exacerbates the challenge of coordinating the movements of the robotic arms. When fruits are closely spaced, the likelihood of path intersections increases, leading to a higher risk of mechanical interference. Additionally, densely packed fruit distributions elevate the probability of accidental contact with surrounding fruits during harvesting, which may result in premature fruit detachment and ultimately affect overall harvesting efficiency and yield. Therefore, it is essential to develop more intelligent planning strategies to optimize the performance of the robotic system under such conditions.
2.3. Working Conditions
The fruit trees in this study are of the spindle-shaped standard tree form [
25], with high spindle-shaped canopies. Each tree has approximately 25 branches growing along wire ropes. The row spacing is 3500 mm, and the plant spacing is 1000 mm, with a tree height of 3000–3500 mm. During the fruit-bearing period, the tree canopy width ranges from 1000 to 1500 mm, with a side thickness of 400 to 500 mm. The crowns of adjacent trees intersect and form a vertical “fruit wall”, with the robot navigating between the rows of trees to harvest fruits from both sides of the fruit wall (see
Figure 5a,b).
3. Method
3.1. Problem Description
This study models and solves the task planning problem for a dual-arm robot that cooperates in a constrained workspace to complete the apple harvesting task. Specifically, we consider a scenario involving two robotic arms and several apples distributed on one side of a fruit wall: the two arms must work collaboratively and efficiently to harvest apples located at varying positions and heights and then place them at designated collection points as required. The scenario is subject to several practical constraints, including the following:
Robotic Arm Motion Constraints: These include the motion speed, the vertical working range, and the minimum safety distance between the two arms.
Action Sequence Constraints: The arms need to perform actions such as approaching, extending, picking, retracting, and placing in a specified order, with each action having a fixed time, cost, and success condition.
Fruit Allocation Constraints: Different robotic arms cannot select the same target fruit simultaneously.
Further, we model this problem as a Markov Decision Process (MDP) and solve it using reinforcement learning (RL) techniques. The agent learns a policy to address the above constraints and optimization goals.
3.2. RL Definition
In reinforcement learning, during the training process, the components of the system—State (S), Action (A), and Reward (R)—are represented as <S, A, R>. Directly capturing the working view of the dual-arm apple-picking robot in a constrained space and its corresponding encoding can be quite complex due to operational environment restrictions. Therefore, this study adopts a feature-based state vector representation method. Specifically, the orchard space is divided into several grids, with apples potentially distributed in each grid. The current position and action state of each robotic arm are also included in the state representation. In this research, a discrete time step simulation environment is designed to simulate the dual-arm apple picking task. The entire harvesting process is carried out on a discretized time scale, where the environment simulates the arm’s action execution and state transitions in discrete time steps. Each time step corresponds to a fixed duration in the real world, allowing us to map the actions performed in the environment to real-world time.
The state representation includes the position of the apples
, their picking state
(0 for not picked, 1 for picked, 2 for requiring re-picking, −1 for fruit disappearance), the position of the arms
, the action states
(0, idle; 1, approaching target; 2, picking; 3, placing), and whether the arm is holding an apple
(0, not holding; 1, holding). The current state
can thus be represented as a vector:
where
denotes the number of fruits that need to be picked.
The action space
definition involves the discrete actions that each arm can perform at each time step, including approaching a specific apple, picking, placing, or remaining idle. Therefore, the action space can be represented as follows:
where
denotes the action of approaching the
apple,
denotes the picking action,
denotes the placing action, and
denotes the idle action. The joint action of both arms constitutes the system’s decision at each time step:
The reward function
is designed to guide the algorithm toward optimizing task completion efficiency and quality. Immediate rewards
include penalties
for travel time costs, idle state
, action execution
, collisions
, rewards for successful picks
, and task completion rewards
, expressed as follows:
Travel Cost Penalty: This encourages the robot to minimize travel distance and time to improve picking efficiency. The weight coefficient for travel cost is denoted as
:
where
, and
Idle State Penalty: This encourages the robot to remain active and reduce the idle time for the robotic arms. The penalty coefficient for the idle state is
= 0.5:
Action Execution Penalty: This penalizes the execution time for grasping, retracting, and placing actions:
Collision Penalty: A high penalty is imposed for collision behavior, encouraging the agent to avoid spatial conflicts between the robotic arms. This penalty is triggered when the distance
:
Successful Picking Reward: A positive reward is provided when an arm successfully completes the harvesting of an apple:
Task Completion Reward: An additional reward is granted when all apples have been harvested and placed, and both robotic arms are idle. The first term is a fixed task completion reward, while the second term encourages the agent to complete the task as quickly as possible:
In the dual-arm apple-picking robot task planning environment, commonly used evaluation metrics include the total completion time, arm idle time, and task efficiency. This study selects the total task completion time as the reward value for environmental feedback. The objective of reinforcement learning training is to minimize the cumulative completion time, particularly to shorten the total time required to complete all picking tasks. During the evaluation phase, the shorter the total completion time, the higher the task execution efficiency and overall picking efficiency. Thus, the total completion time directly reflects the quality of the task planning strategy.
3.3. LSTM-PPO Agent Design and Implementation
In this study, an improved Proximal Policy Optimization (PPO) algorithm is employed to control the multi-arm apple-picking robot for task planning. Due to the sequential nature of apple distribution and robotic arm movements, the Long Short-Term Memory (LSTM) network is utilized to capture temporal dependencies, such as past action sequences of the robotic arms and historical picking records of apples. These features are used by the policy and value networks to estimate optimal actions.
PPO is an algorithm derived from the Trust Region Policy Optimization (TRPO) concept. By improving the computational approach of TRPO, PPO has become one of the most widely used deep reinforcement learning algorithms [
26]. This study employs the PPO-Clip method, which is an optimization strategy designed to prevent excessively large updates to policy parameters.
To enhance sample efficiency, PPO employs importance sampling, which avoids resetting experience data after each update and ensures sample reuse across different training iterations. A key mathematical formulation in PPO is as follows:
where the variable
follows a distribution
, and
denotes the expectation. To solve this, importance sampling introduces a more computationally convenient distribution
. Using this alternative distribution, the expectation of
under
can be computed using samples drawn from
.
corresponds to the old policy
, while
corresponds to the new policy
.
The PPO algorithm introduces the concept of a truncated ratio, which measures the relative change between the old and new policies. The ratio function is defined as follows:
where
represents the new policy parameters, and
denotes the old policy parameters.
The final objective function can be expressed as follows:
where
is the advantage function that indicates the effectiveness of action
. A larger function value implies a higher expected reward. The parameter
serves as a clipping coefficient that constrains the change in
within the range
.
Long Short-Term Memory (LSTM) networks are a specialized type of recurrent neural network (RNN) capable of solving long-term dependency problems. Integrating LSTM into PPO significantly enhances the ability of reinforcement learning agents to capture long-term dependencies. Each LSTM unit operates with three components: input, forget, and output gates, which regulate information retention and updates through different mechanisms. The internal structure and computational equations of the LSTM used in this study are as follows:
where
represents the input feature vector, while
and
denote the hidden state and cell state, respectively. The matrices
and bias terms
correspond to network weights and biases.
Given the sequential nature of both apple distribution and robotic arm movements, historical information is incorporated into the state representation. The LSTM network captures temporal dependencies such as past robotic arm actions and apple picking records, allowing the agent to retain crucial information over extended periods. This enables the efficient learning of exploration strategies, accelerating convergence and ultimately completing the picking task efficiently.
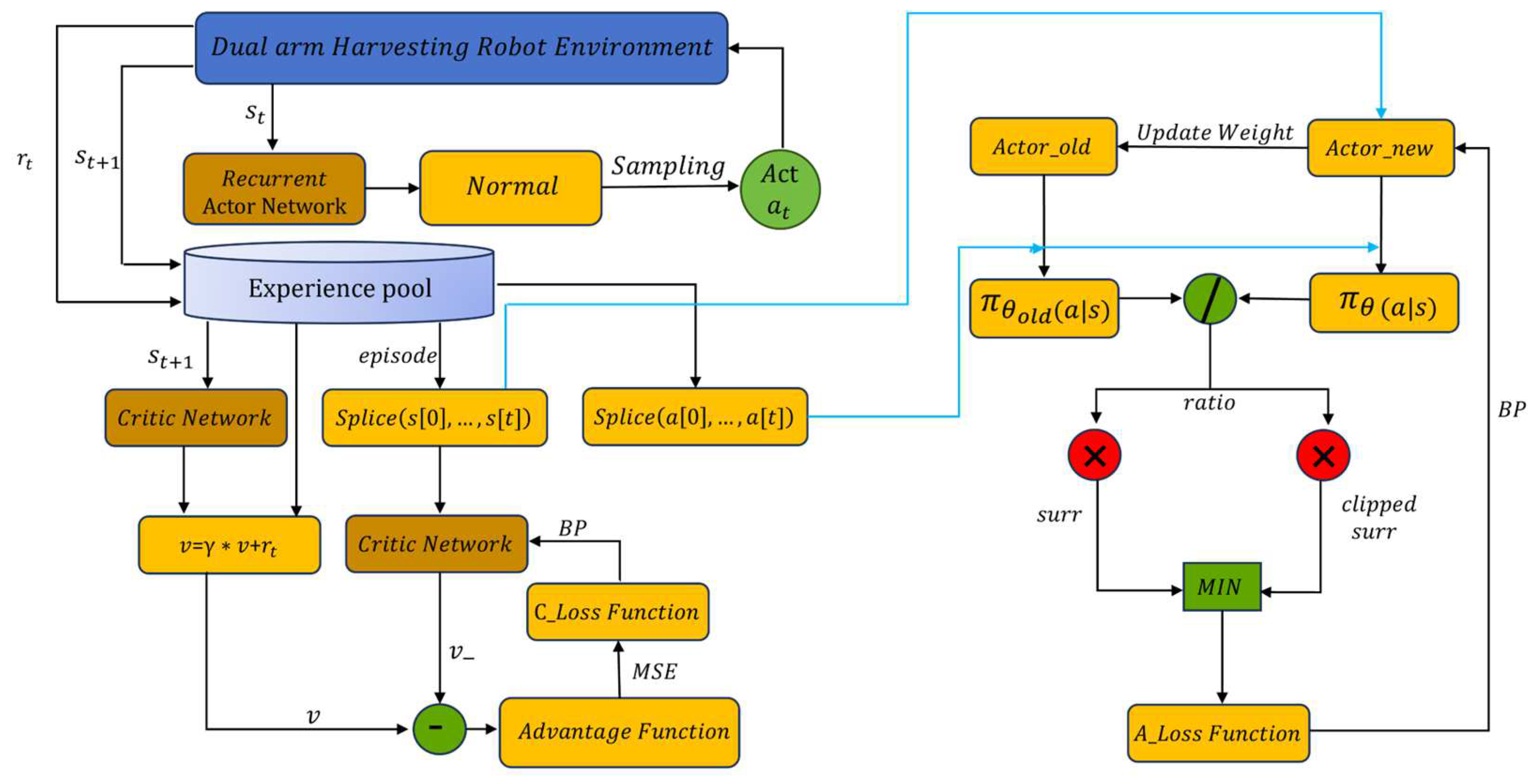
The workflow of the LSTM-PPO model is illustrated in
Figure 6. The current state is first input into the LSTM-based Actor-New network, which generates an action distribution. An action is then sampled from this distribution and executed in the environment, leading to a new state and reward. All actions, states, and rewards are stored in an experience buffer for subsequent model updates. The Actor-New network is compared with Actor-Old to compute updates to the policy parameters. After several iterations, the weights of Actor-New are transferred to Actor-Old, continuously optimizing the strategy to improve agent performance.
4. Simulations and Experiments
The experiments detailed in this study were conducted on an Ubuntu 20.04 system using Python 3.9, PyTorch 1.8.2, and the Gymnasium framework. These processes were executed on a computer configured with a 12th Gen Intel(R) Core(TM) i7-12700H 2.70 GHz processor, 32 GB RAM, and an NVIDIA GeForce RTX 3060 GPU.
We developed a Gymnasium-based simulation environment for the apple picking task. This simulation environment accurately replicates the robot’s operation by simulating target coordinates, robotic arm motion trajectories, and multi-arm collaborative behaviors (such as avoidance, waiting, and competition). Specifically, the simulator can generate a specified number of picking targets either at random or at predefined positions, as required. Furthermore, to simulate real-world conditions such as fruit falling or picking failures, each picking target is designed with adjustable picking success rates or required repeat counts. The workspace of the two robotic arms is modeled to match real-world environments, with a minimum distance of 300mm between the Z-axes of the arms. The robotic arms are required to execute actions in sequence throughout the entire picking process. The environment can automatically execute the actions specified by the agent, update the environment state, and simulate dynamic interactions through flexible interfaces during training.
4.1. Training Process
The training process utilizes 20 to 30 picking targets, simulating scenarios where some targets require re-picking or may disappear during the operation. Each training episode begins after the environment is reset and ends when all apples are picked or the maximum number of steps is reached. The total number of training steps was set to 2 × 10
6. Hyperparameter selection involved testing multiple configurations and fine-tuning to achieve optimal performance. We tested different learning rates in the range of 1 × 10
−4 to 1 × 10
−3, starting with a lower learning rate to avoid model divergence and gradually increasing it to determine the best balance between learning speed and stability. After multiple training iterations, we found that a learning rate of 3 × 10
−4 provided a good balance. For the batch size, we experimented with sizes similar to or slightly larger than the network width, ultimately finding that a batch size of 128 provided a good balance. The discount factor was empirically set to 0.99. The key hyperparameters for training are summarized in
Table 1. The algorithm flowchart is shown in
Figure 7.
4.2. Comparative Experiments Based on Different Algorithms
To validate the superiority of the proposed algorithm in dynamic task planning for dual-arm picking robots, this study aimed to minimize the task completion time and conducted a comparative analysis between the proposed algorithm and the PPO algorithm. All experiments were conducted in the same simulation orchard environment, which consisted of a fixed number of picking targets. To ensure fairness, the hyperparameters of PPO were kept consistent with those of the proposed algorithm.
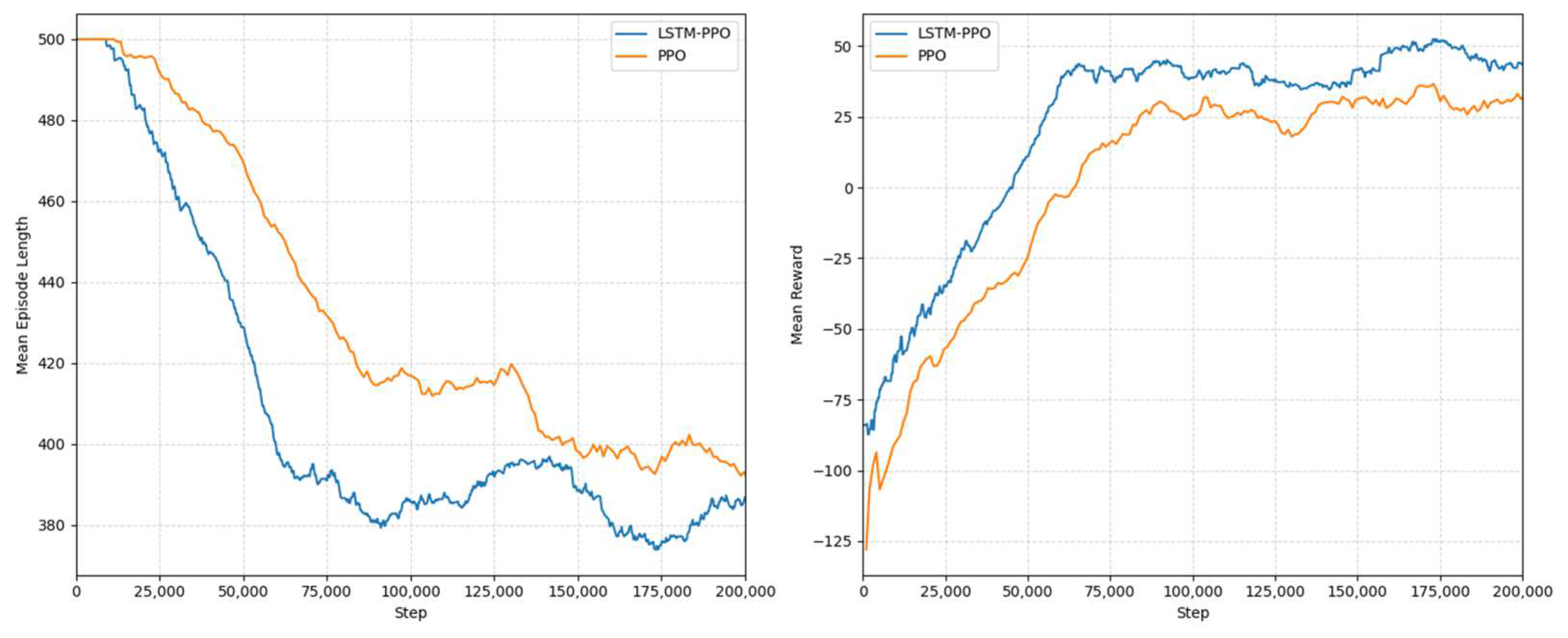
In this study, “Mean Episode Length” was used to measure the number of decision steps taken from environment reset until all picking targets were completed or the termination condition was met. Since each decision step typically corresponds to a fixed control time interval, a reduction in episode length directly leads to a shorter task completion time. Additionally, “Mean Reward” was used to evaluate the execution efficiency and success rate of the agent during the picking process. A higher reward value indicates an improved picking efficiency and success rate.
As shown in
Figure 8, the proposed LSTM-PPO algorithm consistently achieves a lower average episode length than PPO, indicating that it can complete tasks more quickly in most scenarios. In terms of average reward, LSTM-PPO exhibits faster convergence in the early training phase and achieves a higher and more stable convergence level than PPO in the mid-training phase. Overall, the proposed algorithm outperforms PPO in terms of convergence speed, mean reward, and decision steps, demonstrating a higher learning efficiency and shorter final episode length. This not only enhances the algorithm’s learning performance in the simulation environment but also effectively reduces the task completion time in real-world applications, thereby validating its superiority in dynamic task planning for orchard picking and similar applications.
4.3. Simulation Experiments
In the static environment, the states of the robotic arms and targets remained mostly constant to simulate the harvesting process under normal operating conditions. For each experimental round, 15, 20, or 25 picking targets were randomly generated in the environment to simulate the operational process of the robotic system in the orchard. Each strategy was tested multiple times under the same conditions, and the results were averaged to ensure reliability. In the dynamic environment, various disturbances and uncertainties were introduced to simulate real-world working conditions. These included harvesting failures caused by errors in fruit coordinate information or insufficient arm precision, as well as unexpected fruit drop due to trunk vibrations, rigid collisions, and other factors. In each experimental round, 20 or 25 picking targets were randomly generated, and each method was tested over three rounds to evaluate the algorithm’s ability to reschedule and make decisions under dynamic conditions.
4.3.1. Static Environment
In the static experiments, the proposed algorithm was compared with three other strategies:
Random Strategy: No task planning rules are applied, and each robotic arm randomly selects a target to pick. This simulates an operation mode with no task planning.
Greedy Strategy: Each robotic arm operates solely to maximize its own reward without considering coordination between arms or global efficiency, simulating a scenario with a lack of cooperative optimization.
Genetic Algorithm-Based Strategy (Tao et al., [
27]): This strategy adjusts the picking order based on the priority of the targets, aiming to optimize the task completion time.
The experimental results in the static environment are shown in
Table 2 and
Figure 9. The random strategy exhibited the longest task completion time and significant fluctuation across multiple trials, indicating low efficiency when no planning strategy was applied. The greedy strategy, while better than the random strategy, tended to become stuck in local optima when faced with more complex tasks. It failed to effectively utilize environmental information for global planning, which resulted in a decreased harvesting efficiency.
In contrast, the genetic algorithm-based strategy proposed by Tao was able to adjust the picking order according to target priority, thus reducing the task completion time to some extent. However, the genetic algorithm’s limitation lies in the substantial computational cost of its optimization process, and it still faces stability and adaptability issues when confronted with dynamically changing targets.
The proposed algorithm outperformed all other strategies in every metric. This algorithm can dynamically adjust decisions based on real-time feedback, gradually optimizing its strategy, which results in shorter task completion times for each task. Compared to other strategies, the proposed algorithm reduced the average task completion time by 18.54%, and the robotic arms’ idle time was reduced by an average of 17.7 s.
Figure 9 presents the motion trajectories of the two end joints of the robotic system. As observed in the figures, the proposed algorithm clearly outperforms the other strategies in terms of task completion time, demonstrating its efficiency in static environments. Through this experiment, we further confirmed the advantages of the proposed algorithm in static task planning.
4.3.2. Dynamic Environment
In the dynamic experiment, we further validated the adaptability of the proposed LSTM-PPO algorithm in real-world scenarios. Unlike static environments, dynamic conditions simulate potential failures in fruit picking caused by fruit position deviations, robotic arm execution inaccuracies, and trunk vibrations during orchard harvesting. To better reflect real operational conditions, we assumed an approximate 10% failure probability in the experiments to evaluate the performance of different strategies under uncertainty.
We compared the proposed LSTM-PPO algorithm with the method proposed by Tao for 20 and 25 picking targets, conducting three experimental rounds for each method to ensure result reliability. As shown in
Table 3, we recorded key performance metrics, including Total Time Cost, Average Time Cost per Fruit, and Remaining Fruits (missed targets). The results demonstrate that the LSTM-PPO algorithm outperforms the baseline method in all these metrics, exhibiting superior adaptability and fault tolerance. Compared to Tao’s method, the proposed algorithm achieved an 11.21% reduction in average task completion time, while effectively addressing fruit disappearance and re-picking scenarios, significantly reducing the number of missed targets.
Furthermore, in the dynamic experiments, we specifically analyzed the failure scenarios in fruit picking.
Figure 10 illustrates how the LSTM-PPO algorithm leverages its reinforcement learning-based dynamic decision-making mechanism to rapidly adjust strategies when a picking failure occurs. By dynamically re-planning the optimal path, the algorithm maximizes the overall picking success rate. Overall, the LSTM-PPO algorithm demonstrated significantly better performance in dynamic environments, underscoring its advantages in complex and ever-changing conditions and providing strong support for practical applications in agricultural robotics task planning.
4.4. Field Experiments
We deployed a dual-arm harvesting robot in a real-world orchard to compare the performance of the proposed algorithm with that of the Genetic Algorithm (GA) in the actual environment. First, the actual positions and distributions of 20 apples within the operational space were obtained, and spatial information about the apples was collected using a sensor system. Given the challenges of conducting repeatable tests in a fully realistic orchard environment, a simulated environment was used to ensure the controllability of experimental conditions and the reliability of the results. We used magnets to simulate the process of fruit detachment from the stem and introduced potential dynamic changes, such as grasping failures or accidental fruit loss, to replicate real-world complexities like trunk vibrations and fruit position errors that can affect task execution.
Next, the proposed decision-making algorithm and the GA were used to generate the motion trajectories of the robotic arms, which were then mapped onto the actual robot system to replicate the entire picking process. The primary objective of this experiment was to assess the performance of the proposed algorithm in a real-world application and evaluate its effectiveness in comparison with traditional algorithms.
In the field experiments, three main metrics were compared: total picking time, average picking time, and planning time. These metrics comprehensively assess the algorithm’s performance in the actual environment, including overall task completion efficiency, the time spent on picking individual targets, and the time overhead in the planning process.
The experimental results, shown in
Table 4 and
Table 5, and
Figure 11, demonstrate that the proposed algorithm not only performs better in terms of task completion time but also exhibits greater flexibility in making adjustments in complex environments due to its dynamic decision-making mechanism. The field experiment results confirm the high efficiency and stability of the proposed algorithm in practical applications, further validating its broad applicability in orchard picking tasks.
5. Discussion
The experimental results demonstrate the superiority of the proposed LSTM-PPO-based task planning algorithm over conventional methods in both static and dynamic environments. In the static environment, the algorithm reduced total task completion time by 18.54% compared to baseline methods, while also decreasing the robotic arm idle time by 17.7 s on average. These improvements indicate that the proposed approach effectively optimizes task scheduling, reduces inefficiencies in single-arm task execution, and enhances multi-arm coordination.
Compared to the genetic algorithm (GA)-based method proposed by Tao et al., our approach exhibits superior task planning efficiency. The GA-based method optimizes the picking sequence based on target priorities; however, it incurs high computational costs and lacks adaptability to dynamic environments. In contrast, the proposed LSTM-PPO framework continuously refines decision policies based on real-time feedback, effectively adapting to environmental changes such as fruit disappearance and re-picking scenarios. The dynamic simulation results further confirm this adaptability, showing an 11.21% reduction in average task completion time compared to the GA-based approach. Additionally, the proposed method significantly decreased the number of missed fruit targets, verifying its robustness in complex orchard conditions.
Despite these advantages, some challenges remain. First, this study specifically targets dual-arm robots and their typical operating scenarios. In future work, when considering multiple robotic arms collaborating or applying the approach to larger-scale orchards, computational complexity will become a crucial issue requiring further optimization. Future research could explore techniques such as pruned neural networks or parallel computing to reduce computational complexity and enhance scalability. Second, while the LSTM-PPO model exhibits strong adaptability in simulations, real-world conditions—such as variable lighting, unpredictable weather, and mechanical wear—may introduce additional challenges. For different types of fruit trees, the core challenges lie primarily in the design of the visual localization system and the gripper strategies. This paper focuses on collaborative strategies in task execution. By integrating multiple sensors, the accuracy and real-time performance of fruit distribution information acquisition can be significantly improved, which is crucial for task planning algorithms and multi-arm coordination, serving as the foundation and guarantee of efficient collaboration. Future research could further enhance the perception system’s accuracy in acquiring fruit distribution information under various operational conditions by combining stereo vision with LiDAR or hyperspectral imaging, thereby providing more precise data support for the robot’s task decision-making system and improving overall execution efficiency and task completion quality.
In our field experiments, we observed that the actual motion trajectories of the robotic arms exhibited certain deviations from their simulated counterparts. While the simulation environment provides a controlled testing platform, it inevitably simplifies many complex real-world factors, such as sensor noise, actuator response delays, environmental dynamics, and unintended interactions. These discrepancies may impact the transferability of simulation-trained models and planned trajectories to real-world applications. To further bridge the Sim-to-Real gap, our future research will focus on refining the simulation model by incorporating more realistic actuator dynamics, improving sensor noise modeling, and developing advanced adaptive trajectory re-planning mechanisms. Additionally, we plan to integrate motion tracking sensors into field experiments to quantitatively analyze trajectory deviations between simulated and actual execution, thereby enhancing the alignment between simulation and reality and improving the practical applicability of our approach.
Furthermore, while this study focuses on apple picking, the proposed method could be extended to other agricultural automation tasks, such as multi-robot collaboration in greenhouse farming or harvesting different fruit types with varying spatial distributions. Investigating the scalability of reinforcement learning for heterogeneous robotic systems represents a promising direction for future research.
6. Conclusions
Our study proposed an LSTM-PPO-based task planning algorithm for multi-arm apple-picking robots, aiming to enhance task execution efficiency in complex orchard environments. The experimental results demonstrate that the proposed approach significantly outperformed conventional methods, reducing the total task completion time by 18.54% in static environments and 11.21% in dynamic environments, while also effectively minimizing the robotic arm idle time and improving scheduling adaptability and robustness. It is important to note that the impact of tree shape and agricultural management practices in this study primarily affects fruit distribution. During interactive training, the study incorporates approximately five types of fruit distribution scenarios to validate the adaptability of the robot planning algorithm to different distributions. By simulating complex distribution patterns such as branch occlusion and fruit clustering, which may lead to picking failures and fruit drops under real-world conditions, the experimental results further support the generalization conclusions. Unlike traditional genetic algorithm-based or heuristic planning methods, the proposed algorithm optimizes task execution dynamically based on real-time feedback. By integrating LSTM, the model enhances long-term decision-making, enabling the robot to efficiently handle fruit disappearance, re-picking, and environmental uncertainties. The results further confirm the algorithm’s stability and effectiveness across different levels of complexity, highlighting its potential for agricultural automation.
Our research provides a technological foundation for intelligent agricultural robotics and contributes to future advancements in autonomous harvesting systems, multi-robot collaboration, and smart farm management. Future work will focus on improving real-time computational efficiency and integrating advanced perception systems to drive the development of more efficient, intelligent, and adaptive agricultural robots.
Author Contributions
Conceptualization, Z.G.; methodology, Z.G.; software, Z.G.; validation, Z.G.; formal analysis, Z.G.; investigation, Z.G.; resources, Z.G.; data curation, H.F. and J.W.; writing—original draft preparation, Z.G.; writing—review and editing, T.L. and W.Z.; visualization, W.H. (Wenlei Huang) and W.H. (Wenkai Han); supervision, T.L.; project administration, W.Z.; funding acquisition, T.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Science and Technology Program of Tianjin, China (23YFZCSN00290), the National Key Research and Development Program of China (2024YFD2000602), the BAAFS Youth Research Foundation (QNJJ202318), the Innovation Capacity Building Project (KJCX20240502), and the International Science and Technology Cooperation Platform (2024-08).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, Q. Automation in Tree Fruit Production: Principles and Practice; CABI: Wallingford, UK, 2018. [Google Scholar]
- Li, T.; Qiu, Q.; Zhao, C.; Xie, F. Task planning of multi-arm harvesting robots for high-density dwarf orchard. Trans. CSAE 2021, 37, 1–10. [Google Scholar]
- Zhang, J.-Y.; Xia, C.; Wang, H.-F.; Tang, C. Recent advances in electrocatalytic oxygen reduction for on-site hydrogen peroxide synthesis in acidic media. J. Energy Chem. 2022, 67, 432–450. [Google Scholar] [CrossRef]
- Li, Y.; Feng, Q.; Liu, C.; Xiong, Z.; Sun, Y.; Xie, F.; Li, T.; Zhao, C. MTA-YOLACT: Multitask-aware network on fruit bunch identification for cherry tomato robotic harvesting. Eur. J. Agron. 2023, 146, 126812. [Google Scholar] [CrossRef]
- Xiong, Y.; Ge, Y.; Grimstad, L.; From, P.J. An autonomous strawberry-harvesting robot: Design, development, integration, and field evaluation. J. Field Robot. 2020, 37, 202–224. [Google Scholar] [CrossRef]
- Li, T.; Xie, F.; Zhao, Z.; Zhao, H.; Guo, X.; Feng, Q. A multi-arm robot system for efficient apple harvesting: Perception, task plan and control. Comput. Electron. Agric. 2023, 211, 107979. [Google Scholar] [CrossRef]
- Zhang, K.; Lammers, K.; Chu, P.; Li, Z.; Lu, R. An automated apple harvesting robot—From system design to field evaluation. J. Field Robot. 2023, 41, 2384–2400. [Google Scholar] [CrossRef]
- Jin, Y.; Liu, J.; Xu, Z.; Yuan, S.; Li, P.; Wang, J. Development status and trend of agricultural robot technology. Int. J. Agric. Biol. Eng. 2021, 14, 1–19. [Google Scholar] [CrossRef]
- Kim, W.-S.; Lee, D.-H.; Kim, Y.-J.; Kim, T.; Lee, H.-J. Path detection for autonomous traveling in orchards using patch-based CNN. Comput. Electron. Agric. 2020, 175, 105620. [Google Scholar] [CrossRef]
- Kurtser, P.; Edan, Y. Planning the sequence of tasks for harvesting robots. Robot. Auton. Syst. 2020, 131, 103591. [Google Scholar] [CrossRef]
- Lin, G.; Zhu, L.; Li, J.; Zou, X.; Tang, Y. Collision-free path planning for a guava-harvesting robot based on recurrent deep reinforcement learning. Comput. Electron. Agric. 2021, 188, 106350. [Google Scholar] [CrossRef]
- Zheng, Y.; Chen, B.; Lyu, H.; Kang, F.; Jiang, S. Research progress of orchard plant protection mechanization technology and equipment in China. Trans. Chin. Soc. Agric. Eng. 2020, 36, 110–124. [Google Scholar]
- Mhamed, M.; Zhang, Z.; Yu, J.; Li, Y.; Zhang, M. Advances in apple’s automated orchard equipment: A comprehensive research. Comput. Electron. Agric. 2024, 221, 108926. [Google Scholar] [CrossRef]
- Schueller, J.K. Another report from 25 years hence. Resour. Mag. 2012, 19, 16–17. [Google Scholar]
- Tibbets, J.H. Not too far from the tree. Mech. Eng. 2018, 140, 28–33. [Google Scholar] [CrossRef]
- Arikapudi, R.; Vougioukas, S.G. Robotic Tree-fruit harvesting with arrays of Cartesian Arms: A study of fruit pick cycle times. Comput. Electron. Agric. 2023, 211, 108023. [Google Scholar] [CrossRef]
- Barnett, J.; Duke, M.; Au, C.K.; Lim, S.H. Work distribution of multiple Cartesian robot arms for kiwifruit harvesting. Comput. Electron. Agric. 2020, 169, 105202. [Google Scholar] [CrossRef]
- Yang, S.; Jia, B.; Yu, T.; Yuan, J. Research on Multiobjective Optimization Algorithm for Cooperative Harvesting Trajectory Optimization of an Intelligent Multiarm Straw-Rotting Fungus Harvesting Robot. Agriculture 2022, 12, 986. [Google Scholar] [CrossRef]
- He, Z.; Ma, L.; Wang, Y.; Wei, Y.; Ding, X.; Li, K.; Cui, Y. Double-Arm Cooperation and Implementing for Harvesting Kiwifruit. Agriculture 2022, 12, 1763. [Google Scholar] [CrossRef]
- Zion, B.; Mann, M.; Levin, D.; Shilo, A.; Rubinstein, D.; Shmulevich, I. Harvest-order planning for a multiarm robotic harvester. Comput. Electron. Agric. 2014, 103, 75–81. [Google Scholar] [CrossRef]
- Pueyo Svoboda, N.C. Improving Fruit Harvesting Speed with Multi-Armed Robots; University of California: Davis, CA, USA, 2024. [Google Scholar]
- Fu, H.; Guo, Z.; Feng, Q.; Xie, F.; Zuo, Y.; Li, T. MSOAR-YOLOv10: Multi-Scale Occluded Apple Detection for Enhanced Harvest Robotics. Horticulturae 2024, 10, 1246. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Zhu, G.; Shen, Z.; Liu, L.; Zhao, S.; Ji, F.; Ju, Z.; Sun, J. AUV dynamic obstacle avoidance method based on improved PPO algorithm. IEEE Access 2022, 10, 121340–121351. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Gehring, C.; Asai, M.; Chitnis, R.; Silver, T.; Kaelbling, L.; Sohrabi, S.; Katz, M. Reinforcement learning for classical planning: Viewing heuristics as dense reward generators. In Proceedings of the International Conference on Automated Planning and Scheduling, Singapore, 13–24 June 2022; pp. 588–596. [Google Scholar]
- Huang, W.; Miao, Z.; Wu, T.; Guo, Z.; Han, W.; Li, T. Design of and Experiment with a Dual-Arm Apple Harvesting Robot System. Horticulturae 2024, 10, 1268. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}