
A Simplified Machine Learning Model for Predicting Reduced Kidney Function in Thai Patients with Type 2 Diabetes: A Retrospective Study

Abstract
1. Background
2. Methods
2.1. Data Source
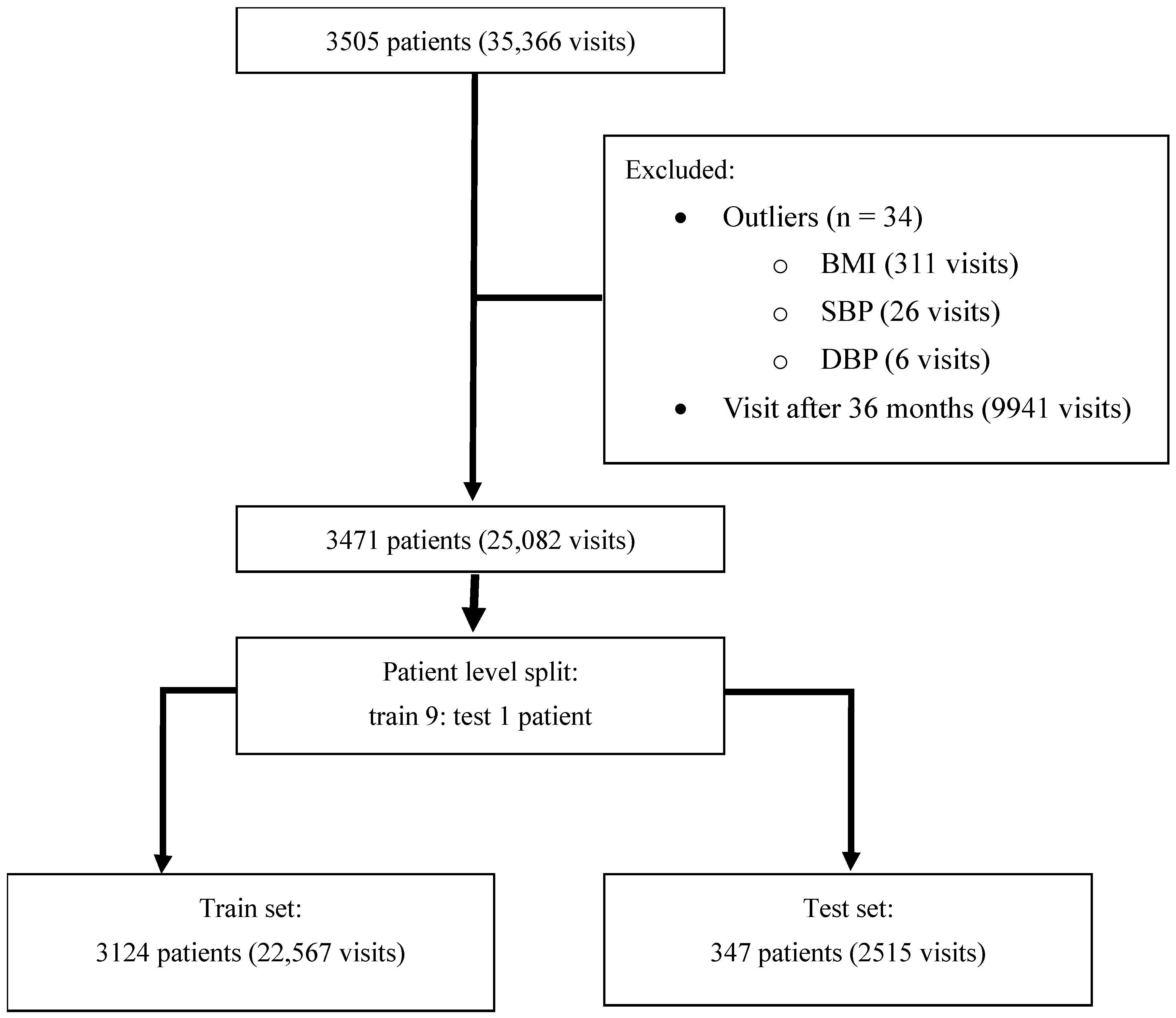
2.2. Study Populations
2.3. Feature Selection and Labeling
2.4. Data and Null Value Management
2.5. Model Development and Evaluation
- The decision tree algorithm [20]: In this algorithm, the dataset is divided into subsets on the basis of different criteria, and at each internal node, a decision is made according to the value of a certain attribute. The “leaves” of the “tree” represent classifications or decisions. Because of its simplicity in design and interpretability, this model is useful for initial analysis.
- The random forest algorithm [21]: In this ensemble method, multiple decision trees are constructed during the training phase. For classification tasks, the output is the mode of the classes (the class selected by the most trees), and for regression, it is the average prediction of the individual trees. The random forest method improves the model accuracy and overcomes the overfitting issue common with single-decision trees.
- The extreme gradient boosting (XGBoost) algorithm [22]: This highly efficient and scalable implementation of gradient boosting improves upon the traditional boosting method by incorporating regularized learning to prevent overfitting, which makes the model robust in a variety of data scenarios. Its execution speed and model performance are attributable to its advanced handling of sparse data and ability to run on various hardware platforms.
2.6. Statistical Analysis
3. Results
3.1. Dataset Characteristics
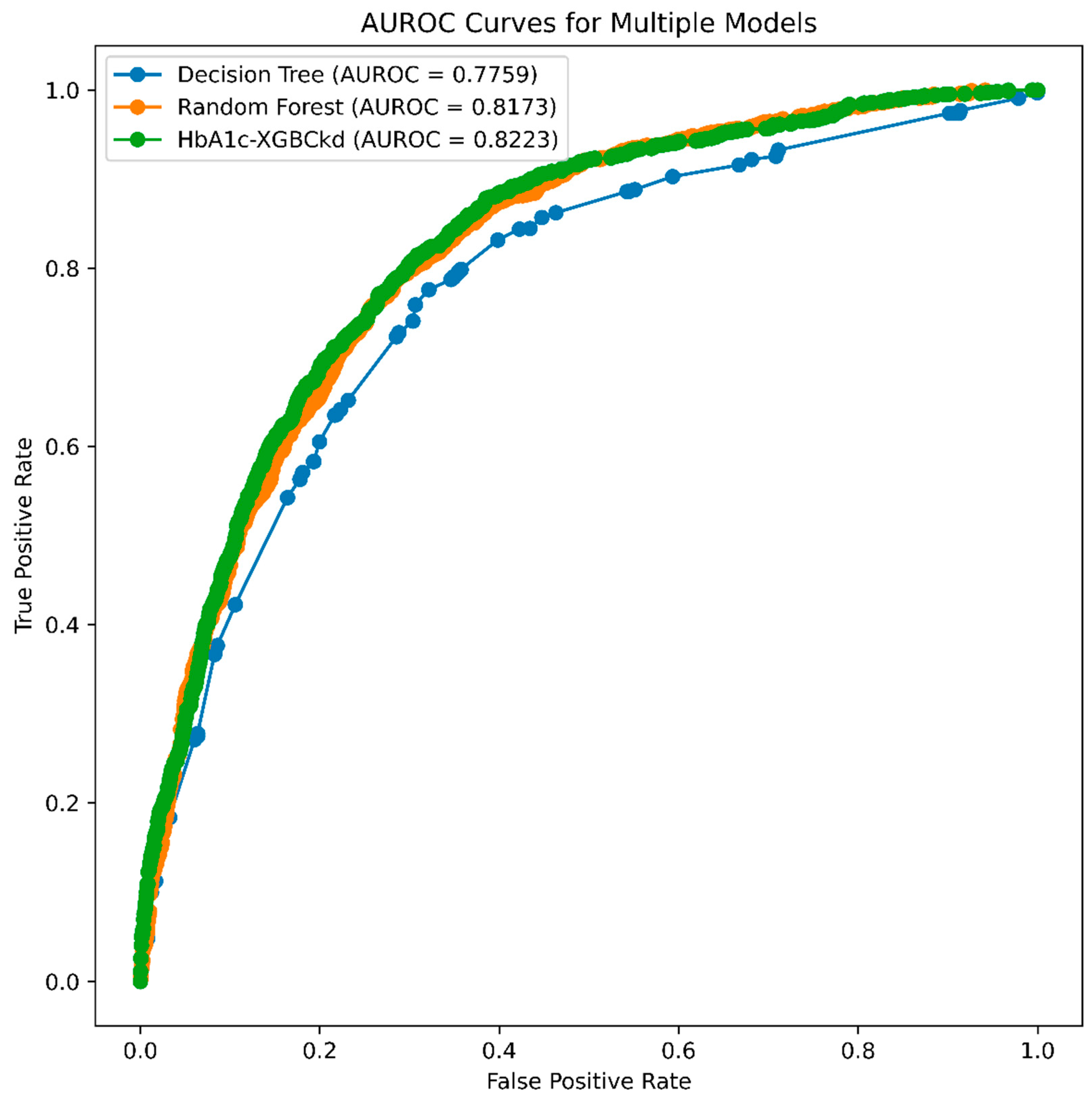
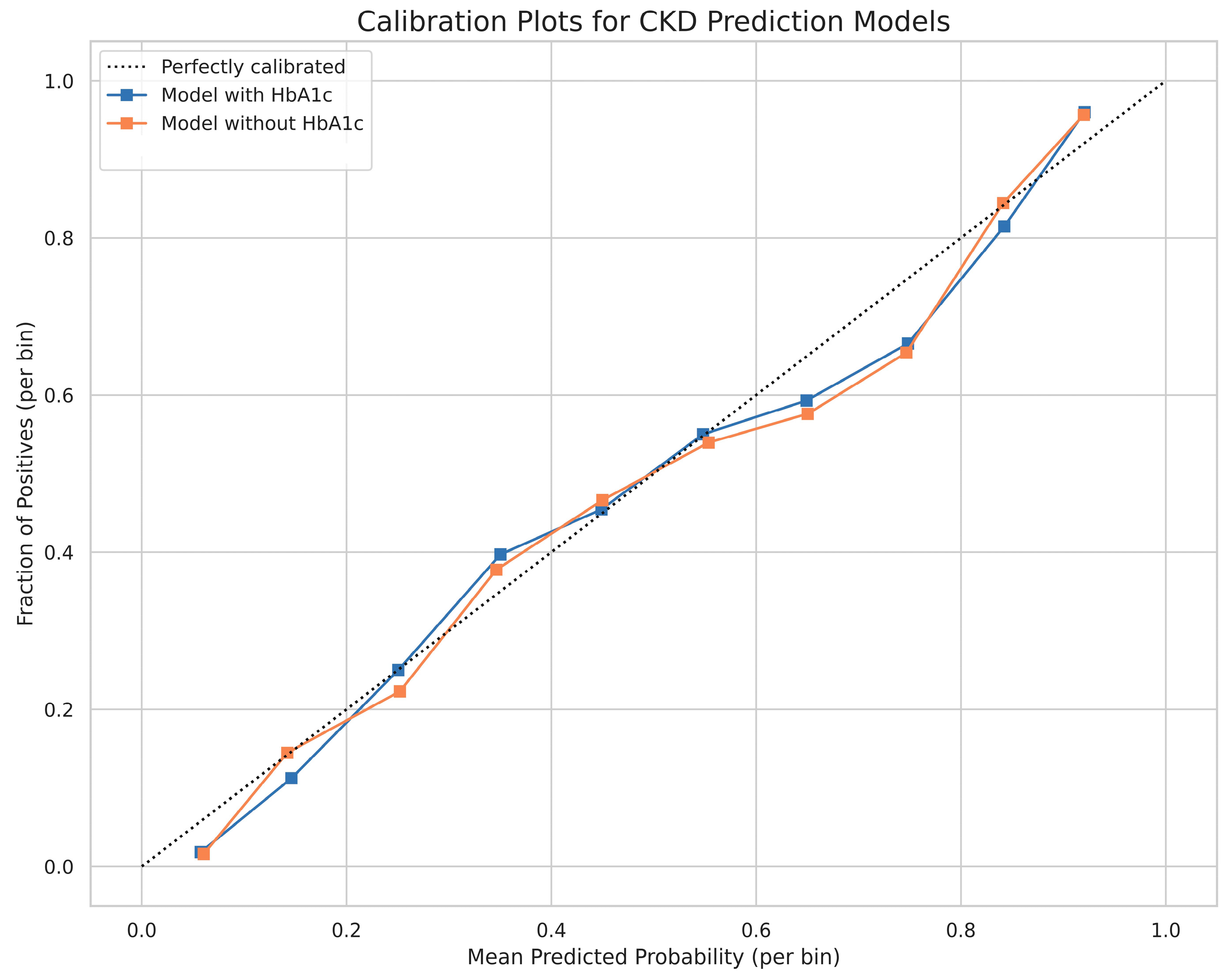
3.2. Model Performance
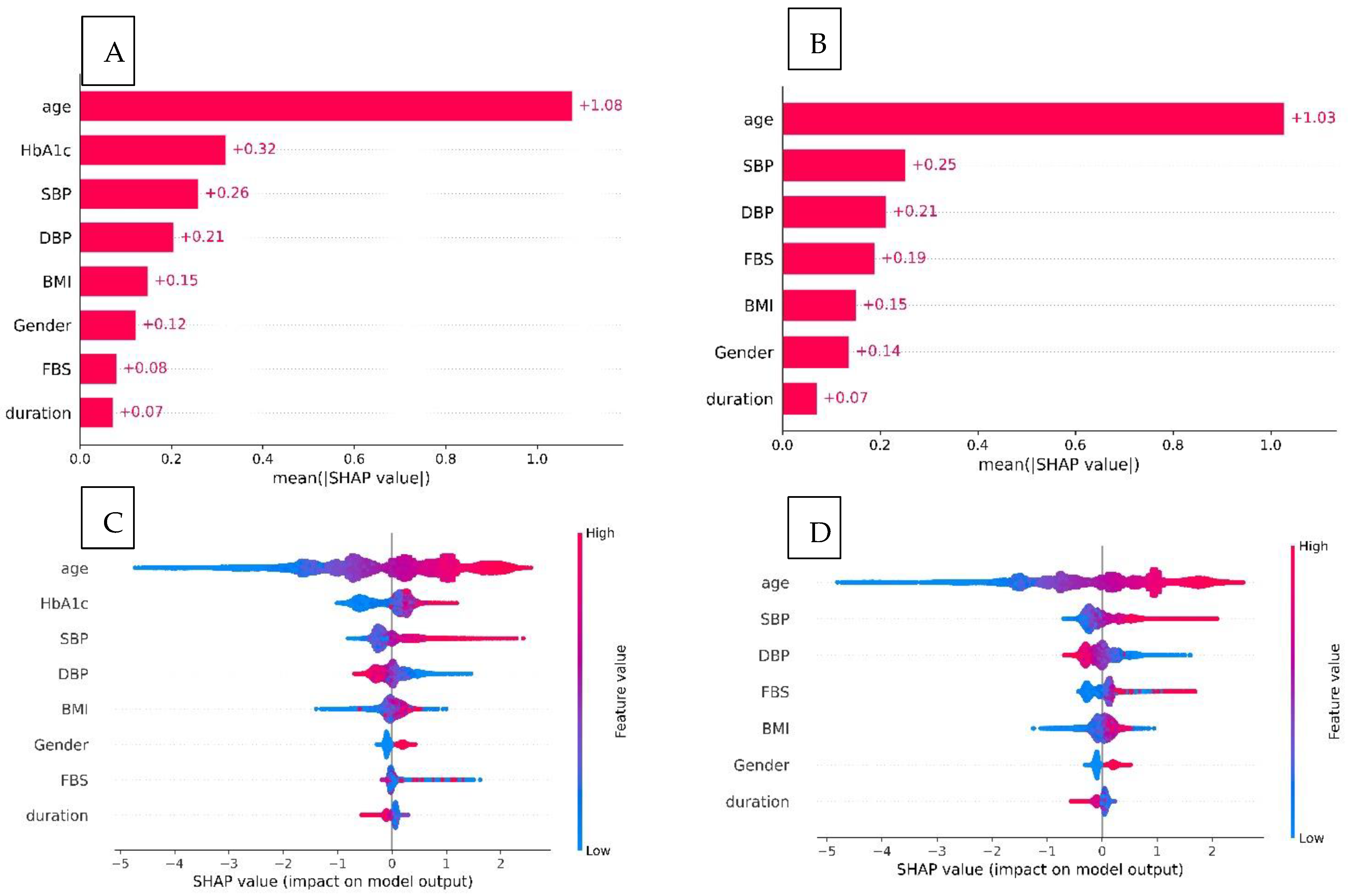
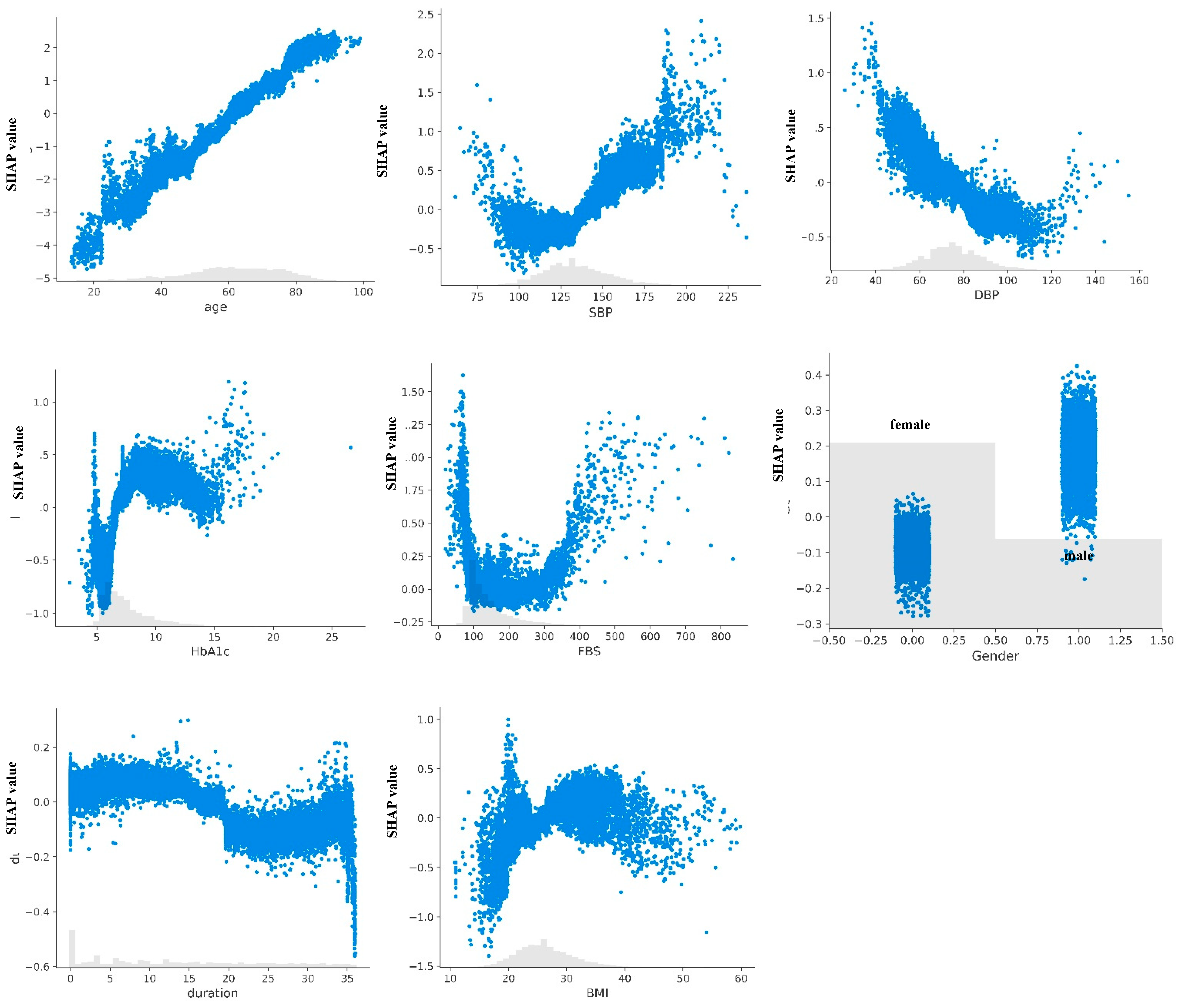
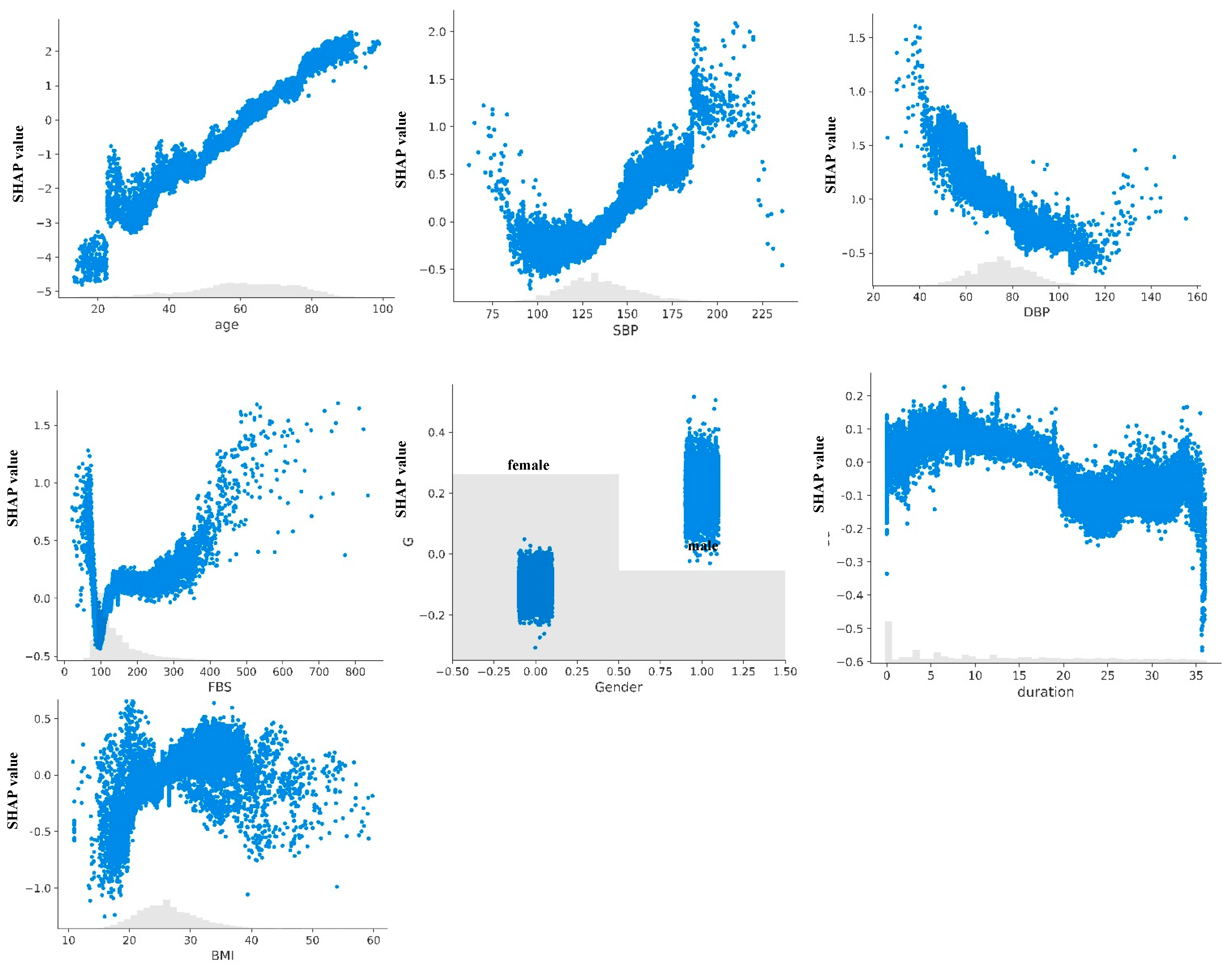
3.3. Model Explanation
3.4. Risk Stratification Results
4. Discussion
4.1. Clinical Interpretation of Model
4.2. Performance in Context and Clinical Utility
4.3. Perspectives for Clinical Practice
4.4. Limitations and Strengths
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUROC | Area under the receiver operating characteristic curve |
| CKD | Chronic kidney disease |
| CVD | Cardiovascular disease |
| DBP | Diastolic blood pressure |
| eGFR | Estimated glomerular filtration rate |
| ESKD | End-stage kidney disease |
| FBG | Fasting blood glucose |
| HbA1c | Glycated hemoglobin |
| ICD | International Classification of Diseases |
| LR+ | Positive likelihood ratio |
| mHealth | Mobile health |
| ML | Machine learning |
| NPV | Negative predictive value |
| PPV | Positive predictive value |
| RAAS | Renin–angiotensin–aldosterone system |
| SBP | Systolic blood pressure |
| SHAP | Shapley additive explanations |
| T2D | Type 2 diabetes |
| XGBoost | Extreme gradient boosting |
References
- Shah, A.; Isath, A.; Aronow, W.S. Cardiovascular complications of diabetes. Expert. Rev. Endocrinol. Metab. 2022, 17, 383–388. [Google Scholar] [CrossRef] [PubMed]
- Zakir, M.; Ahuja, N.; Surksha, M.A.; Sachdev, R.; Kalariya, Y.; Nasir, M.; Kashif, M.; Shahzeen, F.; Tayyab, A.; Khan, M.S.M.; et al. Cardiovascular Complications of Diabetes: From Microvascular to Macrovascular Pathways. Cureus 2023, 15, e45835. [Google Scholar] [CrossRef] [PubMed]
- Hauwanga, W.N.; Abdalhamed, T.Y.; Ezike, L.A.; Chukwulebe, I.S.; Oo, A.K.; Wilfred, A.; Khan, A.; Chukwuwike, J.; Florial, E.; Lawan, H.; et al. The Pathophysiology and Vascular Complications of Diabetes in Chronic Kidney Disease: A Comprehensive Review. Cureus 2024, 16, e76498. [Google Scholar] [CrossRef] [PubMed]
- Rossing, P.; Caramori, M.L.; Chan, J.C.; Heerspink, H.J.; Hurst, C.; Khunti, K.; Liew, A.; Michos, E.D.; Navaneethan, S.D.; Olowu, W.A.; et al. KDIGO 2022 Clinical Practice Guideline for Diabetes Management in Chronic Kidney Disease. Kidney Int. 2022, 102, S1–S127. [Google Scholar] [CrossRef]
- Stevens, P.E.; Ahmed, S.B.; Carrero, J.J.; Foster, B.; Francis, A.; Hall, R.K.; Herrington, W.G.; Hill, G.; Inker, L.A.; Kazancıoğlu, R.; et al. KDIGO 2024 Clinical Practice Guideline for the Evaluation and Management of Chronic Kidney Disease. Kidney Int. 2024, 105, S117–S314. [Google Scholar]
- Bikbov, B.; Purcell, C.A.; Levey, A.S.; Smith, M.; Abdoli, A.; Abebe, M.; Adebayo, O.M.; Afarideh, M.; Agarwal, S.K.; Agudelo-Botero, M.; et al. Global, regional, and national burden of chronic kidney disease, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2020, 395, 709–733. [Google Scholar] [CrossRef]
- Jankowski, J.; Floege, J.; Fliser, D.; Böhm, M.; Marx, N. Cardiovascular Disease in Chronic Kidney Disease: Pathophysiological Insights and Therapeutic Options. Circulation 2021, 143, 1157–1172. [Google Scholar] [CrossRef]
- Aekplakorn, W.; Chariyalertsak, S.; Kessomboon, P.; Assanangkornchai, S.; Taneepanichskul, S.; Putwatana, P. Prevalence of Diabetes and Relationship with Socioeconomic Status in the Thai Population: National Health Examination Survey, 2004–2014. J. Diabetes Res. 2018, 2018, 1654530. [Google Scholar] [CrossRef]
- Nata, N.; Rangsin, R.; Supasyndh, O.; Satirapoj, B. Impaired Glomerular Filtration Rate in Type 2 Diabetes Mellitus Subjects: A Nationwide Cross-Sectional Study in Thailand. J. Diabetes Res. 2020, 2020, 6353949. [Google Scholar] [CrossRef]
- Jha, V.; Al-Ghamdi, S.M.G.; Li, G.; Wu, M.S.; Stafylas, P.; Retat, L.; Card-Gowers, J.; Barone, S.; Cabrera, C.; Garcia Sanchez, J.J. Global Economic Burden Associated with Chronic Kidney Disease: A Pragmatic Review of Medical Costs for the Inside CKD Research Programme. Adv. Ther. 2023, 40, 4405–4420. [Google Scholar] [CrossRef]
- Park, J.I.; Baek, H.; Jung, H.H. CKD and Health-Related Quality of Life: The Korea National Health and Nutrition Examination Survey. Am. J. Kidney Dis. 2016, 67, 851–860. [Google Scholar] [CrossRef] [PubMed]
- Sguanci, M.; Mancin, S.; Gazzelloni, A.; Diamanti, O.; Ferrara, G.; Morales Palomares, S.; Parozzi, M.; Petrelli, F.; Cangelosi, G. The Internet of Things in the Nutritional Management of Patients with Chronic Neurological Cognitive Impairment: A Scoping Review. Healthcare 2024, 13, 23. [Google Scholar] [CrossRef] [PubMed]
- Kitsiou, S.; Gerber, B.S.; Buchholz, S.W.; Kansal, M.M.; Sun, J.; Pressler, S.J. Patient-Centered mHealth Intervention to Improve Self-Care in Patients With Chronic Heart Failure: Phase 1 Randomized Controlled Trial. J. Med. Internet Res. 2025, 27, e55586. [Google Scholar] [CrossRef] [PubMed]
- Gerber, B.S.; Biggers, A.; Tilton, J.J.; Smith Marsh, D.E.; Lane, R.; Mihailescu, D.; Lee, J.; Sharp, L.K. Mobile Health Intervention in Patients With Type 2 Diabetes: A Randomized Clinical Trial. JAMA Netw. Open 2023, 6, e2333629. [Google Scholar] [CrossRef]
- Kitsiou, S.; Paré, G.; Jaana, M.; Gerber, B. Effectiveness of mHealth interventions for patients with diabetes: An overview of systematic reviews. PLoS ONE 2017, 12, e0173160. [Google Scholar] [CrossRef]
- Waki, K.; Nara, M.; Enomoto, S.; Mieno, M.; Kanda, E.; Sankoda, A.; Kawai, Y.; Miyake, K.; Wakui, H.; Tsurutani, Y.; et al. Effectiveness of DialBetesPlus, a self-management support system for diabetic kidney disease: Randomized controlled trial. npj Digit. Med. 2024, 7, 104. [Google Scholar] [CrossRef]
- Haug, C.J.; Drazen, J.M. Artificial Intelligence and Machine Learning in Clinical Medicine, 2023. N. Engl. J. Med. 2023, 388, 1201–1208. [Google Scholar] [CrossRef]
- Mesquita, F.; Bernardino, J.; Henriques, J.; Raposo, J.F.; Ribeiro, R.T.; Paredes, S. Machine learning techniques to predict the risk of developing diabetic nephropathy: A literature review. J. Diabetes Metab. Disord. 2024, 23, 825–839. [Google Scholar] [CrossRef]
- Sabanayagam, C.; He, F.; Nusinovici, S.; Li, J.; Lim, C.; Tan, G.; Cheng, C.Y. Prediction of diabetic kidney disease risk using machine learning models: A population-based cohort study of Asian adults. elife 2023, 12, e81878. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Powers, D. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. Mach. Learn. Technol. 2008, 2, 2229–3981. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Siddiqui, K.; George, T.P.; Joy, S.S.; Alfadda, A.A. Risk factors of chronic kidney disease among type 2 diabetic patients with longer duration of diabetes. Front. Endocrinol. 2022, 13, 1079725. [Google Scholar] [CrossRef] [PubMed]
- Harjutsalo, V.; Groop, P.H. Epidemiology and risk factors for diabetic kidney disease. Adv. Chronic Kidney Dis. 2014, 21, 260–266. [Google Scholar] [CrossRef]
- Abdel-Fattah, M.A.; Othman, N.A.; Goher, N. Predicting Chronic Kidney Disease Using Hybrid Machine Learning Based on Apache Spark. Comput. Intell. Neurosci. 2022, 2022, 9898831. [Google Scholar] [CrossRef]
- Iparraguirre-Villanueva, O.; Espinola-Linares, K.; Flores Castañeda, R.O.; Cabanillas-Carbonell, M. Application of Machine Learning Models for Early Detection and Accurate Classification of Type 2 Diabetes. Diagnostics 2023, 13, 2383. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, Q.; Ke, Y.; Zhang, W.; Hong, Q.; Liu, C.; Liu, X.; Yang, J.; Xi, Y.; Shi, J.; et al. Prediction of 3-year risk of diabetic kidney disease using machine learning based on electronic medical records. J. Transl. Med. 2022, 20, 143. [Google Scholar] [CrossRef]
- Liu, X.Z.; Duan, M.; Huang, H.D.; Zhang, Y.; Xiang, T.Y.; Niu, W.C.; Zhou, B.; Wang, H.L.; Zhang, T.T. Predicting diabetic kidney disease for type 2 diabetes mellitus by machine learning in the real world: A multicenter retrospective study. Front. Endocrinol. 2023, 14, 1184190. [Google Scholar] [CrossRef]
- Sammut-Powell, C.; Sisk, R.; Silva-Tinoco, R.; de la Pena, G.; Almeda-Valdes, P.; Juarez Comboni, S.C.; Goncalves, S.; Cameron, R. External validation of a minimal-resource model to predict reduced estimated glomerular filtration rate in people with type 2 diabetes without diagnosis of chronic kidney disease in Mexico: A comparison between country-level and regional performance. Front. Endocrinol. 2024, 15, 1253492. [Google Scholar] [CrossRef]
- Sammut-Powell, C.; Sisk, R.; Vazquez-Mendez, E.; Vasnawala, H.; Goncalves, S.; Edge, M.; Cameron, R. Global Validation of a Model to Predict Reduced Estimated GFR in People With Type 2 Diabetes Without Diagnosis of CKD. Kidney Int. Rep. 2024, 9, 2047–2055. [Google Scholar] [CrossRef]
- Makino, M.; Yoshimoto, R.; Ono, M.; Itoko, T.; Katsuki, T.; Koseki, A.; Kudo, M.; Haida, K.; Kuroda, J.; Yanagiya, R.; et al. Artificial intelligence predicts the progression of diabetic kidney disease using big data machine learning. Sci. Rep. 2019, 9, 11862. [Google Scholar] [CrossRef] [PubMed]
- Katwal, P.C.; Jirjees, S.; Htun, Z.M.; Aldawudi, I.; Khan, S. The Effect of Anemia and the Goal of Optimal HbA1c Control in Diabetes and Non-Diabetes. Cureus 2020, 12, e8431. [Google Scholar] [CrossRef] [PubMed]
- Cavagnolli, G.; Pimentel, A.L.; Freitas, P.A.; Gross, J.L.; Camargo, J.L. Factors affecting A1C in non-diabetic individuals: Review and meta-analysis. Clin. Chim. Acta 2015, 445, 107–114. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total | Non-CKD Group | CKD Group | p-Value | |
|---|---|---|---|---|
| Number of patients | 3471 | 1607 | 1864 | |
| Age, year | 59.9 (49.8, 70.4) | 51.5 (41.9, 59.1) | 67.9 (59.3, 75.1) | <0.0001 |
| Gender, female | 2367 (68.2%) | 1125 (70.0%) | 622 (66.6%) | 0.0332 |
| BMI, kg/m2 | 25.9 (22.7, 29.3) | 25.8 (22.7, 29.8) | 26.0 (22.9, 28.9) | 0.3979 |
| SBP, mmHg | 132 (120, 145) | 111 (95, 161) | 131 (100, 171) | <0.0001 |
| DBP, mmHg | 75 (67, 83) | 77 (69, 85) | 74 (65, 81) | <0.0001 |
| FBS, mg/dL | 121 (98, 170) | 111 (95, 161) | 131 (100, 177) | <0.0001 |
| HbA1c, % | 6.7 (5.9, 8.3) | 6.3 (5.7, 7.9) | 7.1 (6.1, 8.5) | <0.0001 |
| Training Dataset | Testing Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | AUROC (95% CI) | Accuracy (95% CI) | Precision (95% CI) | Recall (95% CI) | F1-Score (95% CI) | |
| Dataset with HbA1c data | |||||||||
| DT | 0.73 | 0.73 | 0.73 | 0.73 | 0.781 (0.761–0.792) | 0.71 (0.698–0.728) | 0.70 (0.670–0.719 | 0.72 (0.704–0.735) | 0.70 (0.689–0.729) |
| RF | 0.81 | 0.81 | 0.81 | 0.81 | 0.818 (0.801–0.832) | 0.75 (0.735–0.764) | 0.73 (0.720–0.748) | 0.74 (0.729–0.758) | 0.74 (0.723–0.752) |
| XGB | 0.77 | 0.77 | 0.77 | 0.77 | 0.824 (0.808–0.836) | 0.75 (0.740–0.768) | 0.74 (0.724–0.751) | 0.75 (0.731–0.761) | 0.74 (0.726–0.755) |
| Dataset without HbA1c data | |||||||||
| XGB | 0.76 | 0.76 | 0.76 | 0.76 | 0.819 (0.804–0.833) | 0.75 (0.737–0.765) | 0.74 (0.723–0.751) | 0.75 (0.735–0.764) | 0.74 (0.727–0.755) |
| Model | Risk Tier | Subjects | Events | PPV (95% CI) | LR+ (95% CI) | Cochran–Armitage Test |
|---|---|---|---|---|---|---|
| HbA1c-XGBckd | <0.001 | |||||
| Low | 1268 | 110 | 0.087 (0.071–0.102) | 0.16 (0.13–0.20) | ||
| Moderate | 839 | 261 | 0.311 (0.280–0.342) | 0.77 (0.66–0.91) | ||
| High | 836 | 477 | 0.571 (0.537–0.604) | 2.28 (1.95–2.65) | ||
| Very high | 603 | 459 | 0.761 (0.727–0.795) | 5.46 (4.47–6.66) | ||
| Non-HbA1c-XGBckd | <0.001 | |||||
| Low | 1252 | 103 | 0.083 (0.067–0.097) | 0.15 (0.12–0.19) | ||
| Moderate | 775 | 232 | 0.299 (0.267–0.332) | 0.73 (0.62–0.87) | ||
| High | 916 | 523 | 0.571 (0.539–0.603) | 2.28 (1.97–2.64) | ||
| Very high | 603 | 449 | 0.745 (0.710–0.779) | 4.99 (4.11–6.07) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pongsittisak, W.; Suraamornkul, S. A Simplified Machine Learning Model for Predicting Reduced Kidney Function in Thai Patients with Type 2 Diabetes: A Retrospective Study. J. Clin. Med. 2025, 14, 4735. https://doi.org/10.3390/jcm14134735
Pongsittisak W, Suraamornkul S. A Simplified Machine Learning Model for Predicting Reduced Kidney Function in Thai Patients with Type 2 Diabetes: A Retrospective Study. Journal of Clinical Medicine. 2025; 14(13):4735. https://doi.org/10.3390/jcm14134735
Chicago/Turabian StylePongsittisak, Wanjak, and Swangjit Suraamornkul. 2025. "A Simplified Machine Learning Model for Predicting Reduced Kidney Function in Thai Patients with Type 2 Diabetes: A Retrospective Study" Journal of Clinical Medicine 14, no. 13: 4735. https://doi.org/10.3390/jcm14134735
APA StylePongsittisak, W., & Suraamornkul, S. (2025). A Simplified Machine Learning Model for Predicting Reduced Kidney Function in Thai Patients with Type 2 Diabetes: A Retrospective Study. Journal of Clinical Medicine, 14(13), 4735. https://doi.org/10.3390/jcm14134735