1. Introduction
Degenerative Cervical Myelopathy (DCM) is the most common form of spinal cord injury worldwide [
1], and is associated with substantial impairment of patient quality of life. DCM manifests in patients as progressively worsening pain, numbness, dexterity loss, gait imbalance, and sphincter dysfunction [
2], the result of degenerative compression of the cervical spinal cord. Timely diagnosis of DCM is critically important to minimize neurological deterioration, but is challenging because the symptomatology of DCM overlaps with many other common diseases [
3]. DCM symptoms often do not appear until neurological damage has already occurred [
4,
5], and patients who receive treatment after a longer prodrome of neurological deficits may have worse long-term prognosis [
6]. Surgical decompression is the mainstay of treatment, with 1.6 per 100,000 people requiring surgery to treat DCM in their lifetime [
7]. In addition to a thorough history and physical examination, routine MRI of the cervical spine is an essential diagnostic test that confirms the presence and extent of spinal cord compression [
8].
Once DCM has been diagnosed, patients and their care provides must decide whether to proceed with surgical treatment via surgical decompression. Predictive outcome modeling through computationally aided MRI analysis in this scenario is an attractive possibility, but is currently in its infancy. Current analysis tools include the Functional Magnetic Resonance Imaging of the Brain (FMRIB) Software Library [
9], Statistical Parametric Maps [
10], and the Medical Image NetCDF format [
11]. These tools, however, tend to be generalized and lack the specificity required for spinal cord analyses. Although logistic regression models have been tested and have demonstrated limited success [
12], there remains room for improvement. Spinal cord segmentation analysis using qMRI imaging data of patients by tools such as the Spinal Cord Toolbox (SCT) [
13] has recently been shown to provide improved predictive power [
14], but these tools tend to break down when analyzing damaged spinal cords [
15]. Studies which did find success in predicting myelopathic outcomes opted instead to manually inspect the spinal cord [
4,
16] or manually correct the output of automated analyses [
17], reducing the benefits these automated processes provide. To optimize their use, it is imperative to evaluate the extent and source of these limitations. To this end, we assessed the SCT software package for its analytical capabilities in predicting disease severity of DCM. We applied this software package to routinely acquired MRI images from a subset of patients who went on to receive clinical diagnoses of DCM across Alberta, Canada.
2. Methods
2.1. Computational Tools Used
The program versions for the methods used below were as follows:
Spinal Cord Toolbox, v.5.0.1 [
13],
3D Slicer v.4.10.2 [
18],
SciKit-Learn v.0.23.2 [
19],
SciPy v.1.5.2 [
20],
matplotlib v.3.3.2 [
21],
seaborn v.0.11.1 [
22],
numpy v.1.19.2 [
23], and
pandas v.1.2.0 [
24]. As
CovBat was still in development at time of this paper’s publication [
25], its state at the time of this analysis can be replicated by using the GitHub commit
23a0429, available at
https://github.com/andy1764/CovBat_Harmonization/commit/23a0429c2a81e7682da94ff2d0f5e634ab91b429 (accessed on 9 June 2020).
2.2. Data Preparation
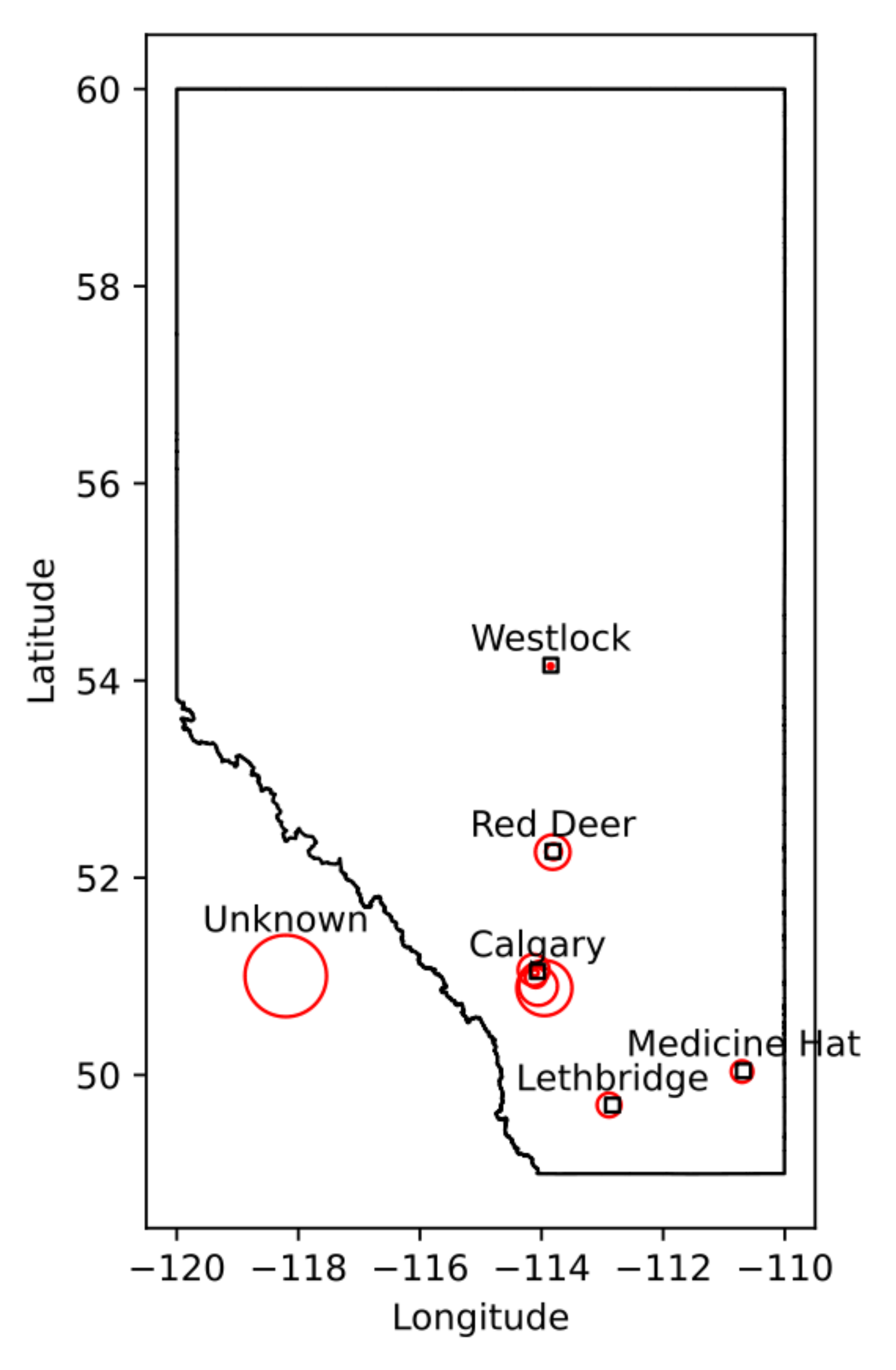
We identified cervical spine MRI images that were used to diagnose 328 patients with DCM who were serially enrolled in the Canadian Spine Outcomes and Research (CSORN) longitudinal registry (initiated in 2016, ongoing [
8]). Data were obtained from multiple clinics across the province of Alberta (
Figure 1); each clinic had their own procedures and protocols, resulting in variation in image quality and resolution. This was accounted for, to some extent, via batch effect compensation (see
Section 2.4).
Our sample set consisted of a diverse number of imaging methodologies. For example, 257 of our 328 patients records used a magnetic field strength of 1.5T, while the remaining 71 used a field strength of 3T. In general, images were also acquired at a relatively low resolution, with T2 weighted, sagittally oriented images primarily with a center-to-center slice thickness of 3 mm (318 images), 2 mm (52 images), with the remaining images (21 images) ranging from 0.9 mm to 5 mm. Axially oriented T2 weighted images were more diverse, but also relatively low resolution: they primarily consisted of images with a 2.5 mm (164 images), 4 mm (128 images), 3 mm (124 images), and 2 mm (90 images) slice thickness, with the remainder varying between 1.4 mm and 5 mm (54 images).
Digital Imaging and Communications in Medicine (DICOM) data were evaluated, anonymized, and converted into the NIfTI file format, resulting in 1335 total MRI sequences. Imaging files were then manually inspected to confirm data integrity (presence of required files and lack of substantial imaging motion or aliasing), and converted into a BIDS-compliant format [
26]. This resulted in 3 patient records and 151 imaging files being excluded, leaving the dataset at 1184 imaging files across 325 patient records. The majority of files dropped were excluded due to excessive noise being present in the image or motion artifacts/patient movement between samples. Other reasons for image exclusion were mislabeling (the MRI images being of the tubular spine, rather than the cervical spine) and insufficient slice count (resulting in the inability for segmentation algorithms to make accurate estimates of spinal cord metrics). Axial images were particularly low quality, making up two thirds of the excluded set (101 of the 151 excluded images).
2.3. Spinal Cord Segmentation
Spinal cord segmentation (masking the contents of the spinal cord vs. the other contents of the image) was done manually for a subset of 50 patients, containing a total of 195 images, as to provide a control against automated segmentation techniques (discussed below). These were done via manual inspection across all images by one person using the 3D Slicer application [
18].
Automated segmentation for the full set of spinal cord images was then completed using SCT [
13]. SCT was selected over its alternatives for two reasons. First, it is the only all-in-one package we are aware of that is specialized for application on the spinal cord, rather than being generalized to MR imaging in general [
9,
10]. Second, it is well documented and open source, making it easy to use and apply in clinical practices without major legal difficulties or financial burden. SCT provides two primary ways to initially segment the spinal cord; ‘PropSeg’ [
27] and ‘DeepSeg’ [
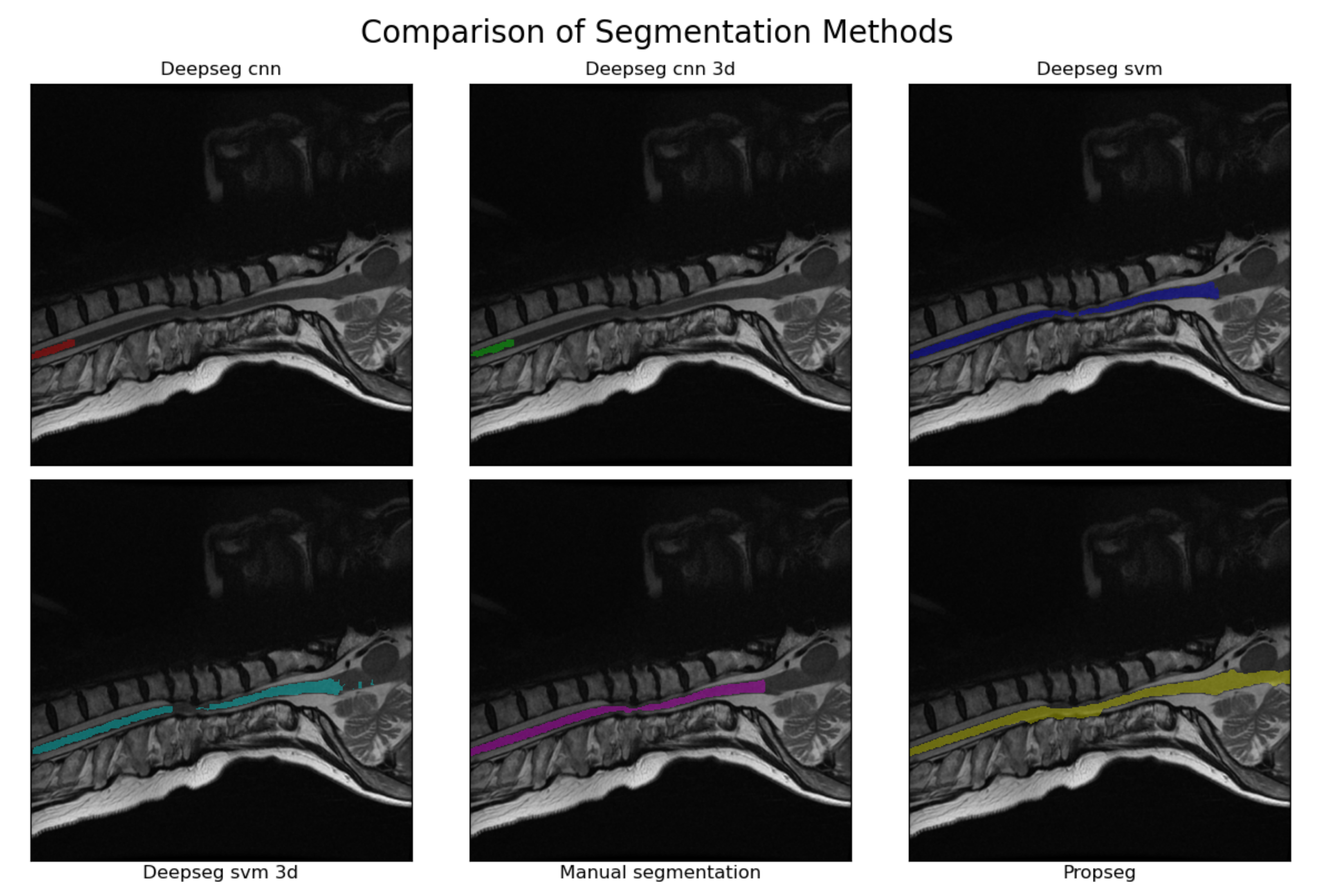
28]. PropSeg functions by initially detecting an initial slice of the spinal cord, then propagating that slice across the remainder of the spinal cord, adjusting as it goes. DeepSeg, in contrast, tries to identify the entire segmentation simultaneously, using either a Convolutional Neural Network (CNN) or Support Vector Machine (SVM) to do so. The model can also take into account only data in a given 2D slice, or the entire 3D image; we chose to test all combinations available. This resulted in 5 different automated segmentation methods being assessed in total. A segmentation method comparison, performed on a sagittal MRI image slice from a patient with severe DCM, is shown in
Figure 2.
SCT can fail to produce a segmentation outright; there seems to be no discernible trend as to what causes this. In these cases, the segmentation method was simply skipped for the image, with subjects for which all methods failed being excluded. This resulted in 1 patient record being dropped, leaving 324 patients records containing 1066 total images for further analysis.
2.4. Metric Extraction and Standardization
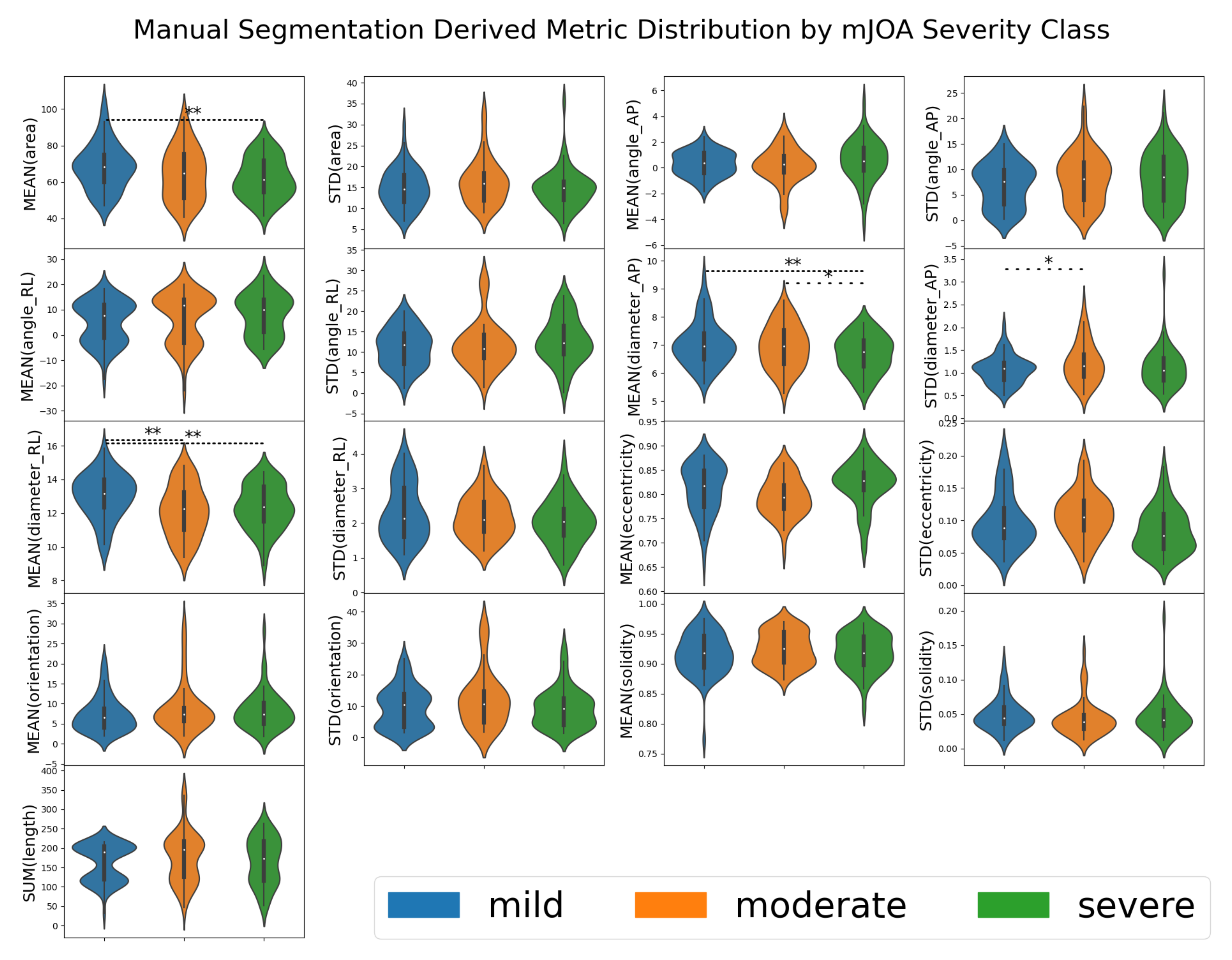
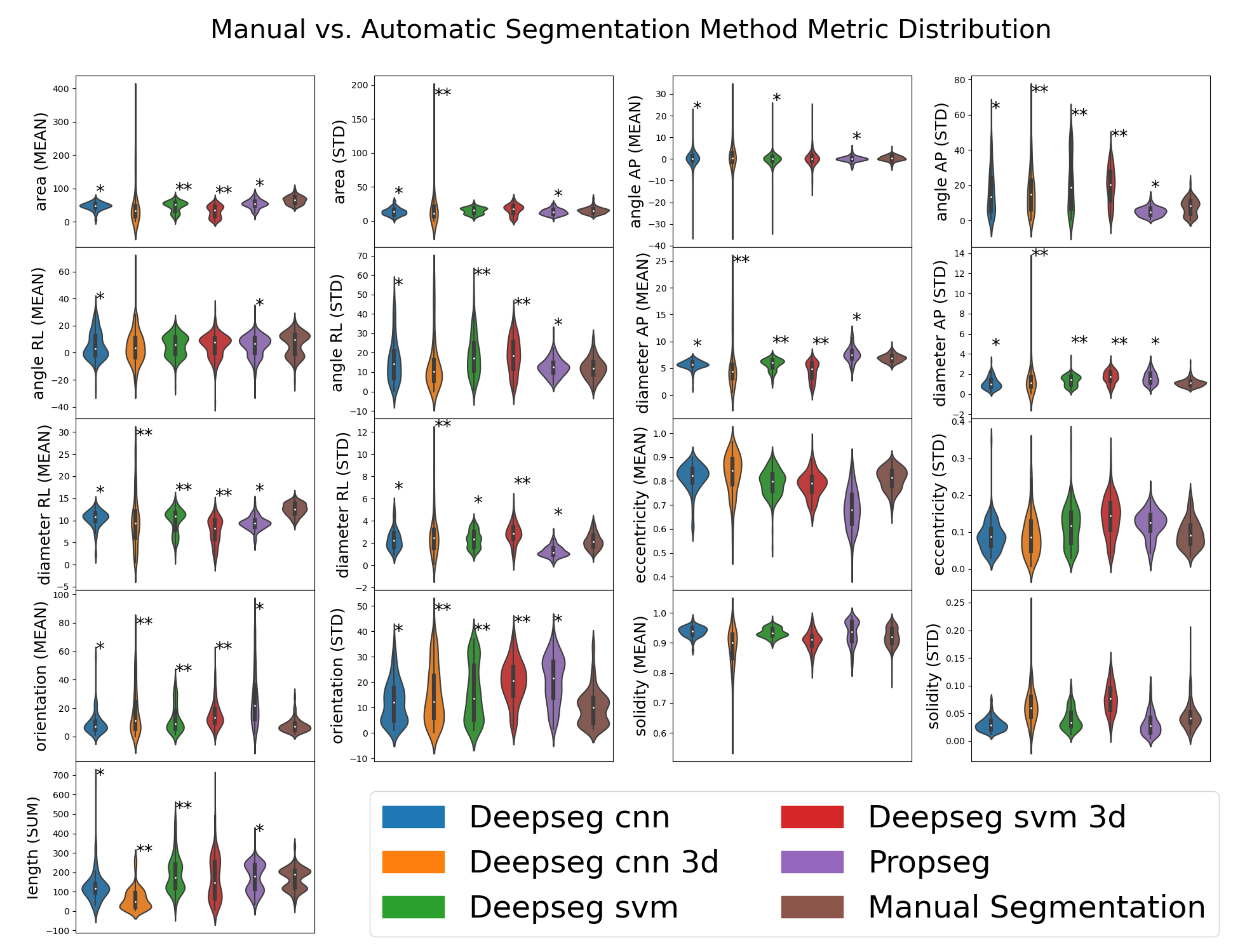
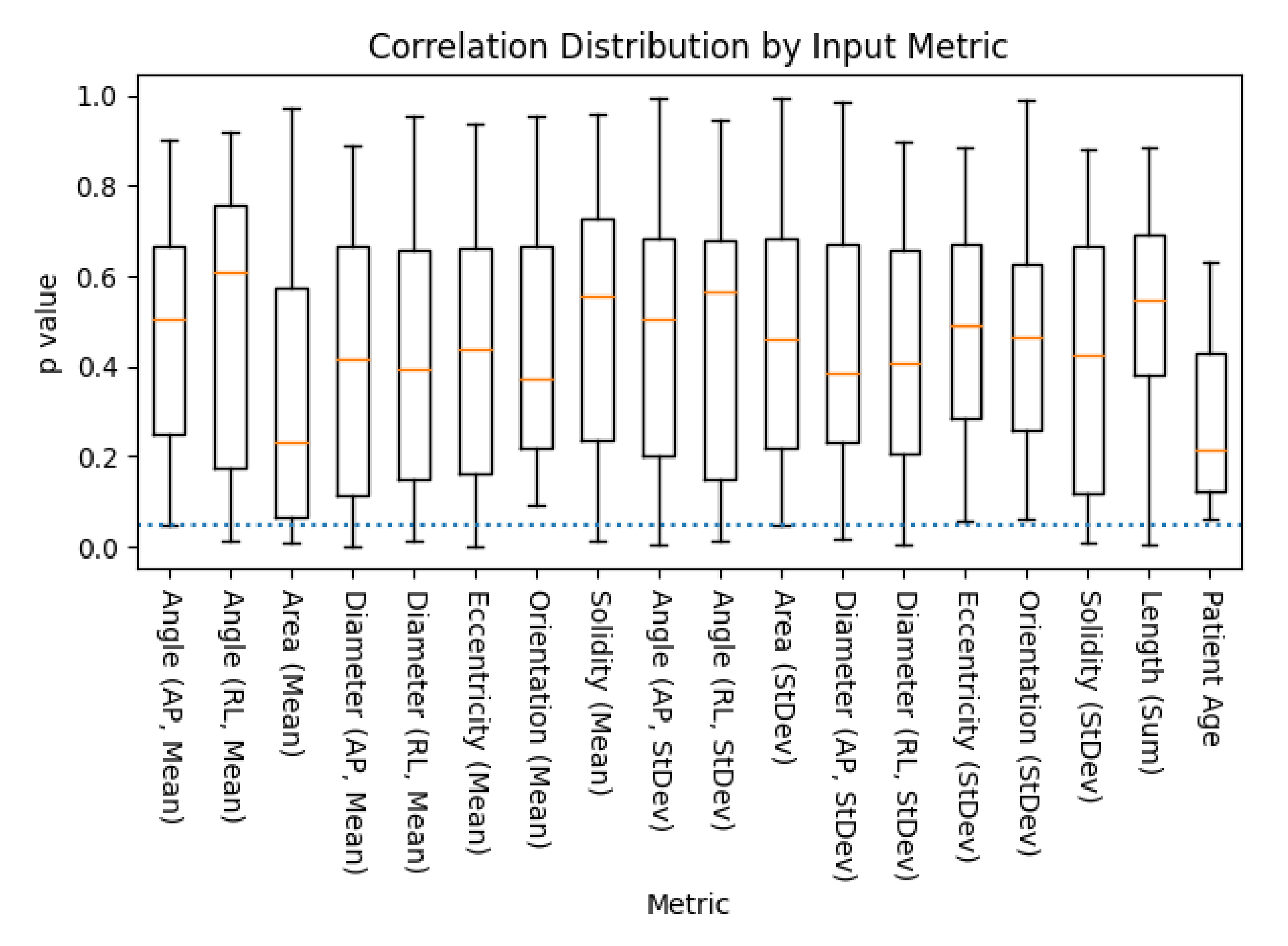
Following segmentation, we used SCT’s ‘sct_process_segmentation’ script to extract metrics from each spinal cord image’s segmentations (both automated and manual). All metrics were taken from the entire spinal cord volume, and included the means and standard deviations of the cross-sectional area of the spinal cord segmentation slices (mm squared), anterior/posterior angle (degrees), right/left angle (degrees), anterior/posterior diameter (mm), right/left diameter (mm), eccentricity (ratio of two prior diameter measurements), orientation (relative angle, image to spine), and solidity (ratio of true and convex-fit cross-sectional area). The total length of the spinal cord (mm) was also obtained, being produced by the same analysis pipeline; given its tenuous-at-best relation to the morphology associated with DCM, this was kept to evaluate SCT’s options in full. That is to say, we did not expect length (sum) to be useful to any model, but included for the sake of being thorough.
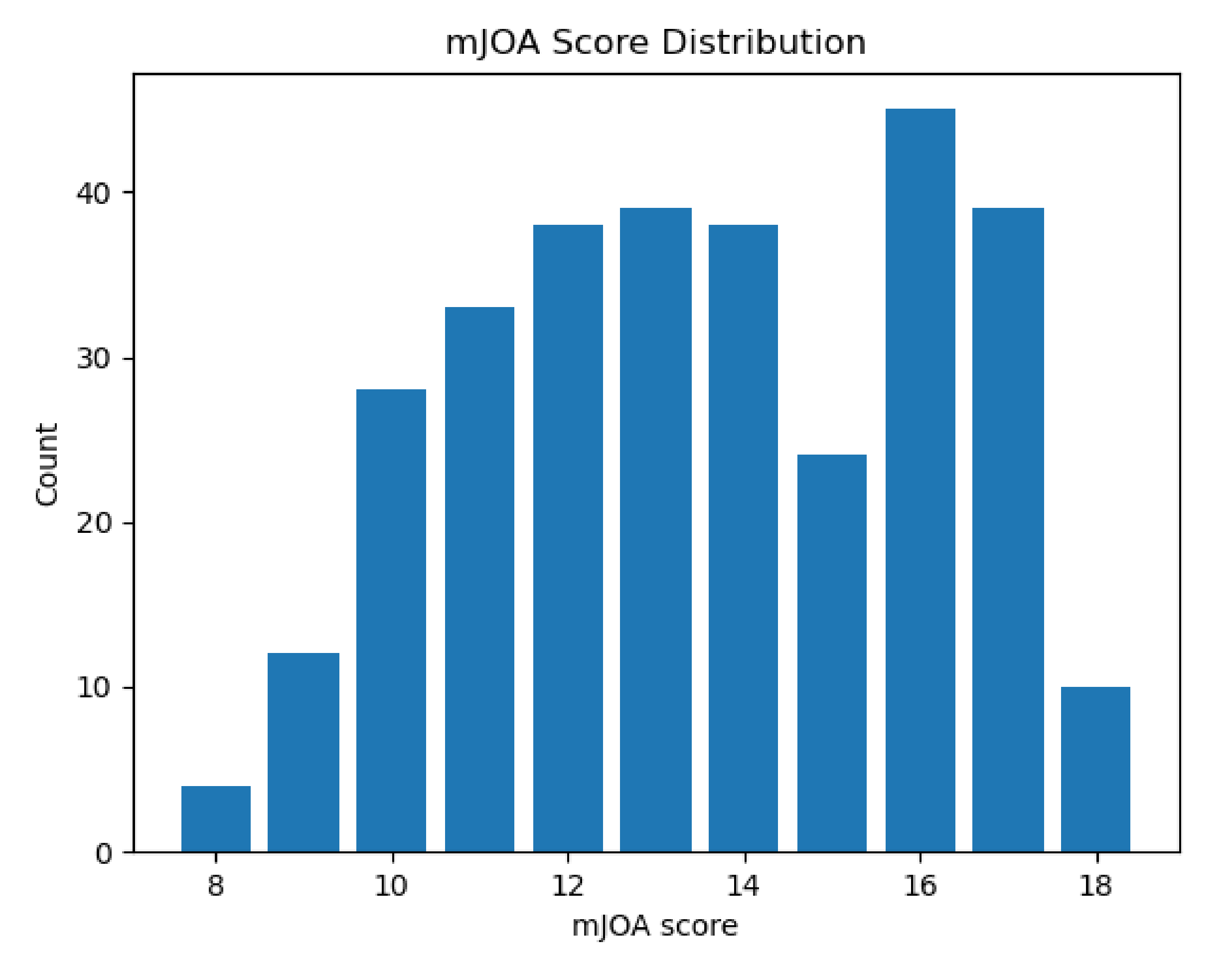
Collected metrics from each automated segmentation were grouped by “imaging methodology” (the combination of segmentation method, MRI contrast, and MRI orientation) and joined with their respective patient’s modified Japanese Orthopedic Association (mJOA) score. The mJOA is a clinician-reported instrument that measures the symptoms and disability of patients suffering from DCM, whereby lower mJOA scores indicate greater impairment and worse disease severity. It is the recommended and most commonly used metric to assess disability caused by DCM [
29]. Scores can range from 18 (healthy) to 0 (inability to move hands or legs, total loss of urinary sphincter control, and complete loss of hand sensation). mJOA scores are also classified categorically as mild (a score of 15 or greater), moderate (a score of 12 to 14), or severe (a score or 11 or less) [
30].
We then opted to harmonize the data to remove any effects unique to each scanner in our sample set. This was done using the
CovBat harmonization program [
25], grouping the data by scanner used to acquire it. The scanner of a given image was determined from the DICOM headers of the images, similar to the methods used in the original assessment of the
CovBat program [
25]. Specifically, images were deemed to share the same scanner if they shared the same scanner manufacturer, scanner model, and magnetic field strength. Please note that geography was
not accounted for, unlike in Chen et al.’s [
25] original presentation of the tool. This was because per clinic differences in how the scanner was operated were assumed to be minimal, given the shared health care zone all data was collected within. Not filtering by geography also has the convenient side-effect of keeping our dataset nearly completely intact, as the
CovBat harmonization process requires that at least 3 elements exist in every group; only one methodology failed to reach this count, leading to only 2 segmentations total being lost. Thus, all patients and images remaining from prior filters remained represented in at least one methodology in the resulting set.
2.5. Model Metric Selection
External non-image derived metrics (such as age, sex, and other demographic information) were available, but were intentionally left out from both the data preparation processes prior and the data modeling below. This was to allow our models to evaluate the predictive merit of current automated image processing techniques, without external bias from said parameters. It has already been established that external metrics such as patient demographics are partially effective at predicting DCM severity in patients [
31], and creating a composite model runs the risk of over-fitting the data and reducing diagnostic power.
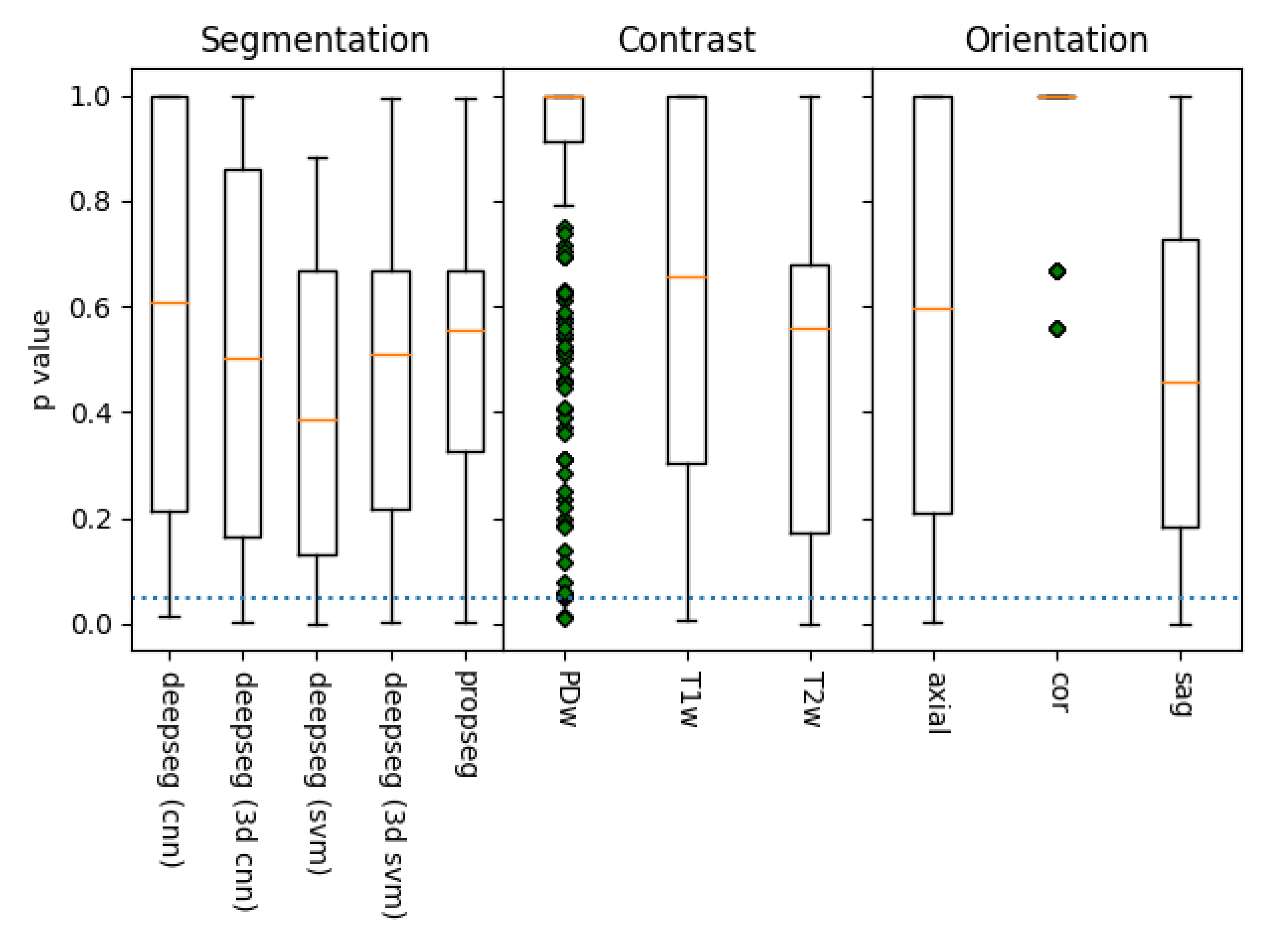
Prior to fitting each model to their associate methodology dataset, data were grouped by the associated image’s acquisition contrast (T1w, T2w, or PDw), segmentation method (options listed prior), and imaging orientation (axial, sagittal, or coronal); the resulting combination is referred to as the “assessment methodology” from this point forward. Initially, as a result of the combinations of these categories, there were potentially 45 different assessment methodologies, though only 30 of these were actually present in our data set. Assessment methodologies with fewer than 3 samples were dropped from the data set, as their lower sample size could lead to inaccurate or misleading results. This resulted in 3 further assessment methodologies being dropped, leaving 27.
Before fitting to models, each assessment methodology was then processed using False Discovery Rate Feature Selection via SciKit-Learn’s SelectFdr function. The scoring function was set to the F-test score of the metric to the mJOA score (evaluated with SciKit-Learn’s ‘f_regression’ function) or DCM severity category (evaluated with SciKit-Learn’s ‘f_classif’ function). The F-test was selected for its ability to evaluate whether data would conform well in a regression model; as we kept to simple regression-based models for this study (see below), this fit our use case perfectly. The allowable probability of false discovery was set to . This feature selection process served both to reduce the list of spinal cord morphological metrics to only those anticipated to be correlated with our target metric (our mJOA score or the mJOA severity categories), but also to filter out assessment methodologies which are likely to be ineffective (by selecting 0 features for them). This resulted in a drastic reduction in valid assessment methodologies, with at most 3 passing this stage per severity category and model type (linear or categorical) and proceeding to the final model assessment.
2.6. mJOA Correlation and Categorization Model Assessment
The remaining assessment methodologies were then fit to either SciKit-Learn’s ‘LinearRegression’ model (for linear metric to mJOA score models) or ‘LogisticRegression’ model (for DCM severity classification models). These simple models fit linearly to each parameter, allowing for metrics to be evaluated sans-interaction effects, and does so very quickly. This made them ideal for rapid, diverse, and simple assessments, perfect for evaluating the SCT derived metrics on their own. All groups were split into train-test groups using 5-fold shuffle split grouping, and cross-validated by fitting the modeling method to each group in turn. Each resulting model’s effectiveness was then evaluated using for the linear regression models, and using receiver operating characteristic area under curve (ROC AUC) for categorical models. The effectiveness of the model type was then assessed via the mean score of all resulting models. To confirm that the somewhat experimental CovBat method worked correctly, all processes prior were run on both the standardized-only metric sets and the CovBat-harmonized metric sets as well. Categorical imbalance was also evaluated for each model type via assessing the accuracy of a “dummy” model, which simply guessed the most common category at all times.
4. Discussion and Conclusions
In this work, we explored predictive outcome modeling using computationally aided MRI analysis. We attempted to extract metrics used by trained surgeons from MRI images of the human cervical spine to predict disease severity. Most of these derived metrics simply lack sufficient differentiation across mJOA score severity. Variation appears to be mostly patient-specific rather than related to DCM severity. This is likely a result of the metrics being sampled across the entirety of the spinal cord, whereas morphological differences related to DCM often only effect a portion of the spinal cord, with the remainder appearing ‘healthy’. Although there were some interesting trends within the data, these useful trends appear to be masked by natural inter-individual variance between each of the patients enrolled in this study. As a result, our machine learning systems had difficulty pulling out said meaningful trends, resulting in over-fitting to patient variation and lower overall accuracy.
Non-imaging metrics, such as age, smoking status, and symptom duration have been shown to be important metrics in the development of models to predict patient outcomes after surgical treatment for DCM [
32]. MR imaging of the cervical spine plays a vital role in the diagnosis and surgical treatment planning of this patient population. Although this data is vital to a surgeon’s decision-making process, most surgeons would not consider treating a patient without and MRI confirmed diagnosis. Efforts to distill a surgeon’s acumen into an ‘imaging metric’ have fallen short in terms of predictive capabilities. Our work, while novel in computational approach, only adds to this body of literature, bringing us closer to integrating advanced imaging metrics with a patient’s clinical presentation. Such a reality could greatly improve a surgeon’s ability to treat their patients.
The models we presented in this work highlight some key features which we can use to inform future processes. Given the low accuracy of most assessment methodologies, the vast majority of metrics extracted from these segmentations did not correlate strongly with mJOA scores. However, a handful did, showing that assessment methodologies could identify statistically significant correlations. Spinal cord segmentation metrics chosen via feature selection also showed an interesting trend, with the angle and diameter of the spine being selected most commonly, followed by metrics associated with cross-sectional area and spinal cord solidity/eccentricity. This is unsurprising given that pathology of DCM results in compression of the spinal cord (i.e. reduction in diameter, often resulting in a misshapen cross-section), but it nonetheless highlights the potential for a model which focused solely on identifying key variations in these values derived directly from the image itself. It is plausible that finding a way to normalize these metrics relative to the patient’s unique spinal cord variations could be incredibly valuable for creating a diagnostic model. These techniques show potential, but appear to be hampered by the natural variance of DCM patients’ spinal cords.
There are several limitations to this study. First, all data comes from central-southern Alberta (
Figure 1), potentially leading to some implicit demographic attributes of the region influencing the analyses. Second, only relatively simple models (Linear and Logistic regression) were used, whereas more complex models may have proven more useful. Simple models simply cannot capture any significant interaction effects. Given the complexity of DCM, it is extremely likely at least one such severity influencing ‘complex’ effect exists. We limited our analyses to these simpler models to focus the study on evaluating major trends in the data to inform future model design. Third, only simple measures of accuracy were used (
simply assesses a model’s total explained variance, whereas ROC AUC measures its relative ability to predict true positives over false positives), which are likely to mask important details on how each model functions. More nuanced assessment metrics should be considered for future models aimed at diagnostic application; measurements such as false positive rate vs. false negative rate are likely to be far more significant metrics in these contexts (a false positive will be likely caught and dismissed by a clinician upon review, whereas a false negative could lead to significant health consequences for the patient). Fourth, the cross-validation procedure (5-fold) was chosen for its simple implementation in both linear and logistic regression models. A leave-one-out (linear regression) or leave-one-per-category-out (logistic regression) model would be more appropriate here, as it would replicate how a real-world implementation of similar predictive models would be required to function; with a single new patient record being submitted in varying intervals and predictions made for them. Such cross-validation may result in models more prone to over-fitting noise; however, finding noise-resistant metrics would be a must before this limitation could be resolved. Fifth, we only accounted for metrics directly extracted from MRI images. Prior studies have shown that non-imaging metrics can also influence spinal cord morphometrics within a patient [
33], and as a result it is likely some confounding or contributing effect from such non-imaging metrics may have not been accounted for. Finding a way to fold in these metrics could improve future models substantially.
Given these limitations, future studies which aim to model DCM outcomes should aim to identify metrics which are normalized to healthy patient variation. This would reduce the amount new models will overfit to natural patient variation over DCM relevant attributes. Likewise, due in part to the limited number of samples available in our dataset and the fact all were diagnosed with DCM, asymptomatic persons who display traits analogous to those of DCM were not accounted for. Prior work has shown MRI images from asymptomatic persons can appear similar to those taken from DCM patients [
34]. Increasing the number of MRIs taken from healthy individuals could reduce the likelihood of future models becoming too liberal with their DCM diagnoses. Finding metrics resilient to these forms of over-fitting is imperative if any resulting model is to be implemented in a fully autonomous manner, as to avoid incorrect diagnostic conclusions which may lead to patient harm.
Several possible solutions exist to address these limitations. First, normalizing metrics to be relative per-patient could greatly mitigate natural patient variance effects. These could include ratio metrics (i.e., minimum over maximum ratio), internal outlier detection (i.e., detecting drastic changes in spinal cord shape relative to the rest of the spine), or even dynamically generated metrics such as those produce by Principle Component Analysis. Such metrics would both provide internal normalization for patients, and (in the case of Principle Component Analysis) would be specifically selected based on their relevance to the DCM severity. Second, experimenting with more complex models stands to capture more nuanced details of DCM, such as those of interaction effects between multiple parameters. This would require said metrics to be refined beforehand, however, as such interaction effects would be particularly prone to natural noise masking true relations. Finally, folding in non-imaging derived metrics could address the issue of ‘asymptomatic’ false positives mentioned prior. Given these effects would likely need to be considered alongside spinal cord morphology metrics, this should be done after the selection of said morphological metrics and after a suitable model is chosen which can reflect these interactions. The outcome of such research could be particularly enlightening, helping to explain what distinguishes asymptomatic persons from those suffering from DCM, potentially providing improved treatment options for the latter.
Overall, it appears that modern computational methods have unmet potential in diagnostic prediction of DCM severity. With improvement of these models via the integration of external non-imaging derived metrics, deploying additional complex statistical and machine learning models, and improved morphological metric identification, it may be possible to create a system capable of working at least as effectively as the average clinician. The numerous limitations of this study will also need to be addressed should such a system come to fruition, namely the problem of models over-fitting to natural patient variation and other noise rather than DCM specific morphological characteristics. If these challenges are met, such a system being integrated in a fully automated capacity could potentially revolutionize the treatment of DCM. Such a system could allow clinicians to focus on each patient’s needs more closely, helping them come to more informed treatment decisions and mitigating risks associated with their chosen treatment. This model could also greatly improve our understanding of DCM, potentially identifying targets for new modes of treatment or discovering novel diagnostic metrics.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}