Attention-Aware Adversarial Network for Person Re-Identification

Abstract
:1. Introduction
- We propose an attention-aware adversarial network for person re-ID, in which data augmentation is implemented on the feature map level.
- An attention assignment mechanism is proposed to re-assign attentions to more important regions.
- The proposed method is evaluated on two large benchmark datasets and achieves promising results.
2. Related Work
2.1. Person Re-ID
2.2. Data Augmentation
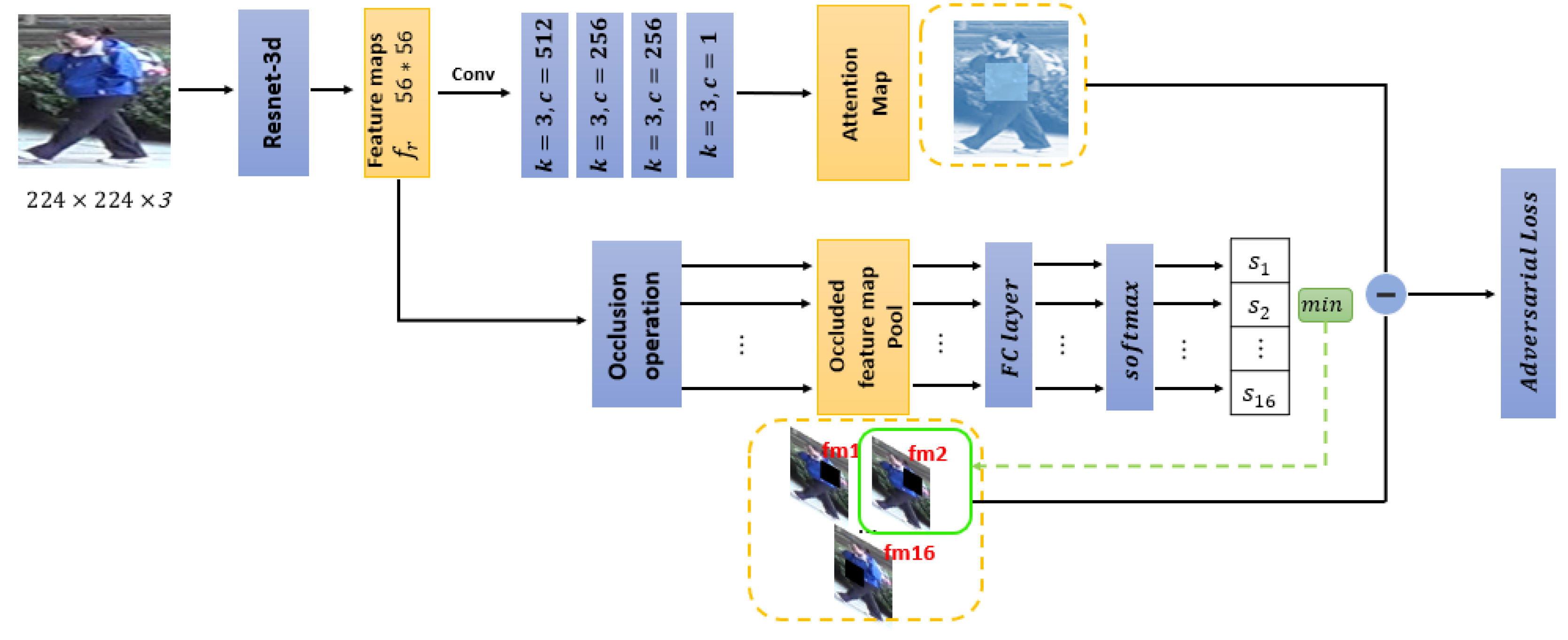
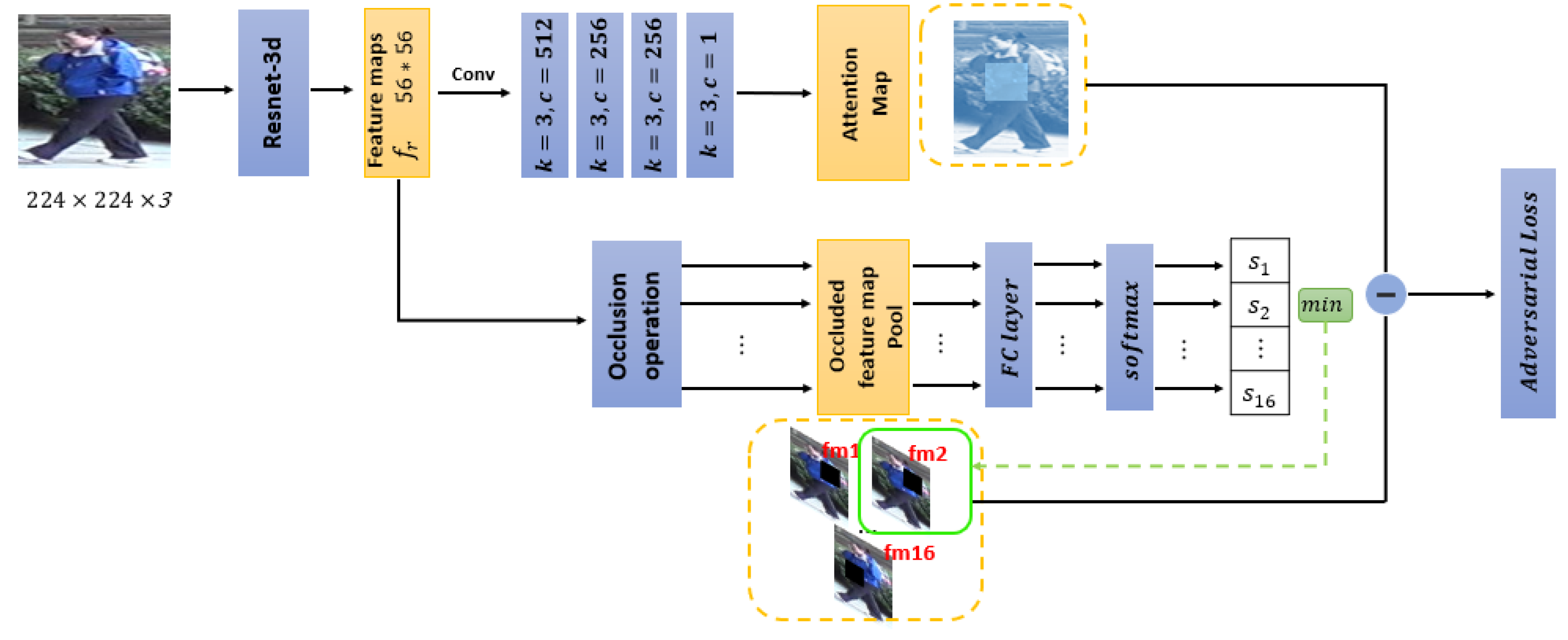
3. Method
3.1. Baseline Network
3.2. Attention Assignment Network
| Algorithm 1 The training strategy of the attention assignment network. |
| Input: Nperson images; Whiledo 1: The feature maps of the middle layer are divided equally into 16 with a square grid; 2: Each grid in the feature maps is occluded and reproduced in sequence; 3: These 16 groups of feature maps are entered together into the classification network; 4: Select the feature maps with the lowest classification probability to guide the generation of feature maps of the attention assignment mechanism; 5: Update the parameters of the attention assignment mechanism; 6: ; end Retain the weight of the overall network structure |
3.3. Attention-Aware Adversarial Network
| Algorithm 2 The training strategy of the attention-aware adversarial network. |
| Input: Nperson images; Whiledo 1: The feature maps obtained by the pre-training attention assignment mechanism are used as 0-1 attention mask; 2: The feature maps of the middle layer multiplied by the 0-1 mask as occluded feature maps; 3: The occluded feature maps are entered into the classification network along with the original feature maps to obtain , which is the classification probability of the original feature maps, and , which is the classification of occluded feature maps 4: Update parameters of the entire network by combining and with adversarial loss; 5: ; end |
4. Experimental Results
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Analysis of the Parameters
4.4. Location of Generating Occluded Feature Maps
4.5. Influence of the Attention Assignment Network
4.6. Evaluation with the State-of-the-Art Algorithms
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially Occluded Samples for Person Re-Identification. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5098–5107. [Google Scholar]
- Zhuo, J.; Chen, Z.; Lai, J.; Wang, G. Occluded Person Re-identification. arXiv, 2018; arXiv:1804.02792. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-fast-rcnn: Hard positive generation via adversary for object detection. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 3039–3048. [Google Scholar]
- Cheng, D.; Chang, X.; Liu, L.; Hauptmann, A.G.; Gong, Y.; Zheng, N. Discriminative Dictionary Learning With Ranking Metric Embedded for Person Re-Identification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence—IJCAI 2017, Melbourne, Australia, 19–25 August 2017; pp. 964–970. [Google Scholar]
- Chen, J.; Wang, Y.; Qin, J.; Liu, L.; Shao, L. Fast Person Re-identification via Cross-Camera Semantic Binary Transformation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5330–5339. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning Deep Context-Aware Features over Body and Latent Parts for Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7398–7407. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-Learned Part-Aligned Representations for Person Re-identification. In Proceedings of the IEEE International Conference on Computer Vision—ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 3239–3248. [Google Scholar]
- Deng, W.; Zheng, L.; Kang, G.; Yang, Y.; Ye, Q.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification. arXiv, 2017; arXiv:1711.07027. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. arXiv, 2017; arXiv:1711.08565. [Google Scholar]
- Yao, H.; Zhang, S.; Zhang, Y.; Li, J.; Tian, Q. Deep Representation Learning with Part Loss for Person Re-Identification. arXiv, 2017; arXiv:1707.00798. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for Pedestrian Retrieval. In Proceedings of the IEEE International Conference on Computer Vision—ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 3820–3828. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Person Re-Identification by Deep Joint Learning of Multi-Loss Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence—IJCAI 2017, Melbourne, Australia, 19–25 August 2017; pp. 2194–2200. [Google Scholar]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle Net: Person Re-identification with Human Body Region Guided Feature Decomposition and Fusion. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 907–915. [Google Scholar]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. GLAD: Global-Local-Alignment Descriptor for Pedestrian Retrieval. In Proceedings of the 2017 ACM on Multimedia Conference—MM 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 420–428. [Google Scholar]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose Invariant Embedding for Deep Person Re-identification. arXiv, 2017; arXiv:1701.07732. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated Siamese Convolutional Neural Network Architecture for Human Re-identification. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 791–808. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv, 2015; arXiv:1503.03832. [Google Scholar]
- Liu, H.; Feng, J.; Qi, M.; Jiang, J.; Yan, S. End-to-End Comparative Attention Networks for Person Re-identification. arXiv, 2016; arXiv:1606.04404. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person Re-identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond Triplet Loss: A Deep Quadruplet Network for Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1320–1329. [Google Scholar]
- Mignon, A.; Jurie, F. PCCA: A new approach for distance learning from sparse pairwise constraints. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2666–2672. [Google Scholar]
- Kai Li, Z.D. Discriminative Semi-coupled Projective Dictionary Learning for Low-Resolution Person Re-Identification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- He, L.; Liang, J.; Li, H.; Sun, Z. Deep Spatial Feature Reconstruction for Partial Person Re-identification: Alignment-Free Approach. arXiv, 2018; arXiv:1801.00881. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. arXiv, 2017; arXiv:1708.04896. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. In Proceedings of the European Conference on Computer Vision workshop on Benchmarking Multi-Target Tracking, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Jose, C.; Fleuret, F. Scalable Metric Learning via Weighted Approximate Rank Component Analysis. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 875–890. [Google Scholar]
- Chen, D.; Yuan, Z.; Chen, B.; Zheng, N. Similarity Learning with Spatial Constraints for Person Re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1268–1277. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a Discriminative Null Space for Person Re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1239–1248. [Google Scholar]
- Zhou, S.; Wang, J.; Wang, J.; Gong, Y.; Zheng, N. Point to Set Similarity Based Deep Feature Learning for Person Re-Identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5028–5037. [Google Scholar]
- Chen, Y.C.; Zhu, X.; Zheng, W.S.; Lai, J.H. Person Re-Identification by Camera Correlation Aware Feature Augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 392–408. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Ren, L.; Lu, J.; Feng, J.; Zhou, J. Consistent-Aware Deep Learning for Person Re-identification in a Camera Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3396–3405. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. End-to-End Deep Learning for Person Search. arXiv, 2016; arXiv:1604.01850. [Google Scholar]
- Schumann, A.; Stiefelhagen, R. Person Re-identification by Deep Learning Attribute-Complementary Information. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1435–1443. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Pedestrian Alignment Network for Large-scale Person Re-identification. arXiv, 2017; arXiv:1707.00408. [Google Scholar]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Yang, Y. Improving Person Re-identification by Attribute and Identity Learning. arXiv, 2017; arXiv:1703.07220. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Values of | Rank-1 on BL+ Euclidean | Rank-1 on BL + XQDA | Rank-1 on BL + KISSME | |||
|---|---|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | Rank-1 | mAP | |
| 1, 1 | 69.6 | 50.8 | 71.2 | 52.9 | 72.7 | 53.0 |
| 0.5, 1 | 70.8 | 51.2 | 71.7 | 53.0 | 72.3 | 53.2 |
| 1, 1.5 | 70.0 | 50.4 | 72.1 | 52.8 | 72.1 | 52.6 |
| 1.5, 0.5 | 69.8 | 50.6 | 71.6 | 52.9 | 72.2 | 52.8 |
| ours (0.3, 1.7) | 71.2 | 51.3 | 73.2 | 53.2 | 72.5 | 52.9 |
| Rank-1 (KI) | |||
|---|---|---|---|
| 0.02 | 70.6 | 71.8 | 72.6 |
| 0.1 | 70.5 | 72.6 | 72.5 |
| 0.2 | 70.4 | 73.2 | 72.5 |
| 0.3 | 69.8 | 71.8 | 71.6 |
| ours (0.04) | 71.2 | 73.2 | 72.5 |
| Method | Rank-1 on BL + Euclidean | Rank-1 on BL + XQDA | Rank-1 on BL + KISSME | |||
|---|---|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | Rank-1 | mAP | |
| baseline | 77.9 | 54.8 | 78.0 | 56.5 | 78.9 | 55.6 |
| Resnet-second | 79.6 | 55.8 | 79.3 | 57.3 | 80.3 | 56.8 |
| Resnet-third | 80.3 | 57.0 | 80.2 | 59.1 | 81.5 | 58.8 |
| Resnet-fourth | 80.6 | 57.0 | 79.8 | 58.6 | 80.7 | 58.1 |
| Resnet-fifth | 79.6 | 56.0 | 78.5 | 56.7 | 79.8 | 56.9 |
| Rank-1 (K) | |||
|---|---|---|---|
| baseline | 77.9 | 78.0 | 78.9 |
| without fine-tuning | 79.5 | 78.6 | 80.7 |
| with fine-tuning | 80.3 | 80.5 | 81.5 |
| Rank-1 (K) | |||
|---|---|---|---|
| baseline | 77.9 | 78.0 | 78.9 |
| random erasing | 79.1 | 79.3 | 80.2 |
| attention-aware adversarial | 80.3 | 80.5 | 81.5 |
| Method | BOW | WARCA | SCSP | DNS | Gated | PS | CCAFA | CA | Spindle | GAN | Baseline | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | 34.4 | 45.2 | 51.9 | 61.0 | 65.9 | 70.7 | 71.8 | 73.8 | 76.9 | 78.1 | 78.9 | 81.5 |
| mAP | 14.1 | - | 26.35 | 35.7 | 39.6 | 70.7 | 45.5 | 47.1 | - | 56.2 | 55.6 | 58.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, A.; Wang, H.; Wang, J.; Tan, H.; Liu, X.; Cao, J. Attention-Aware Adversarial Network for Person Re-Identification. Appl. Sci. 2019, 9, 1550. https://doi.org/10.3390/app9081550
Shen A, Wang H, Wang J, Tan H, Liu X, Cao J. Attention-Aware Adversarial Network for Person Re-Identification. Applied Sciences. 2019; 9(8):1550. https://doi.org/10.3390/app9081550
Chicago/Turabian StyleShen, Aihong, Huasheng Wang, Junjie Wang, Hongchen Tan, Xiuping Liu, and Junjie Cao. 2019. "Attention-Aware Adversarial Network for Person Re-Identification" Applied Sciences 9, no. 8: 1550. https://doi.org/10.3390/app9081550
APA StyleShen, A., Wang, H., Wang, J., Tan, H., Liu, X., & Cao, J. (2019). Attention-Aware Adversarial Network for Person Re-Identification. Applied Sciences, 9(8), 1550. https://doi.org/10.3390/app9081550