A Study on Development of the Camera-Based Blind Spot Detection System Using the Deep Learning Methodology

Abstract
:1. Introduction
2. Related Work
3. Methodologies and Research Framework
3.1. Dataset Preprocessing
- Preliminary testing was conducted using the video recorded by the smartphone camera shown in Figure 4 prior to actual testing on a real road. For this reason, only vehicle images with front and front-left angles were extracted due to the viewing angles of the blind spot shown in Figure 5, and a total of 2000 images out of 8144 images were selected.
- After the banner and other vehicles in the background were removed, the background was filled in with white.
- All selected images were edited by the sharpen function to have outstanding image quality.
3.2. Data Reduction and Representation Learning
3.3. Histogram of Oriented Gradients (HOG)
3.4. Deep Neural Networks and Fully Connected Network
- Input: X ∈
- Output: Y ∈
- FCN
- -
- ReLu activation function:
- -
- Y =
- Softmax output layer: , where i = 1, …, 3 and is defined as the number of layers, and j = 1, …, K and is defined as output classes
- Categorical cross-entropy objective function: , where m is the batch size, Y is an actual output, and Y’ is a predicted output
- Empirical loss function:
- Machine Name: n1-standard-4
- Virtual CPUs: 4
- Memory: 15 GB
- Hard Disk Drive = 200 GB
- the number of inputs (features): 1188 images
- the number of hidden layers: 2
- the number of units in hidden layers: 1188 in the first hidden layer and 594 in the second hidden layer
- learning rate = 1 × 10
- epoch = 10
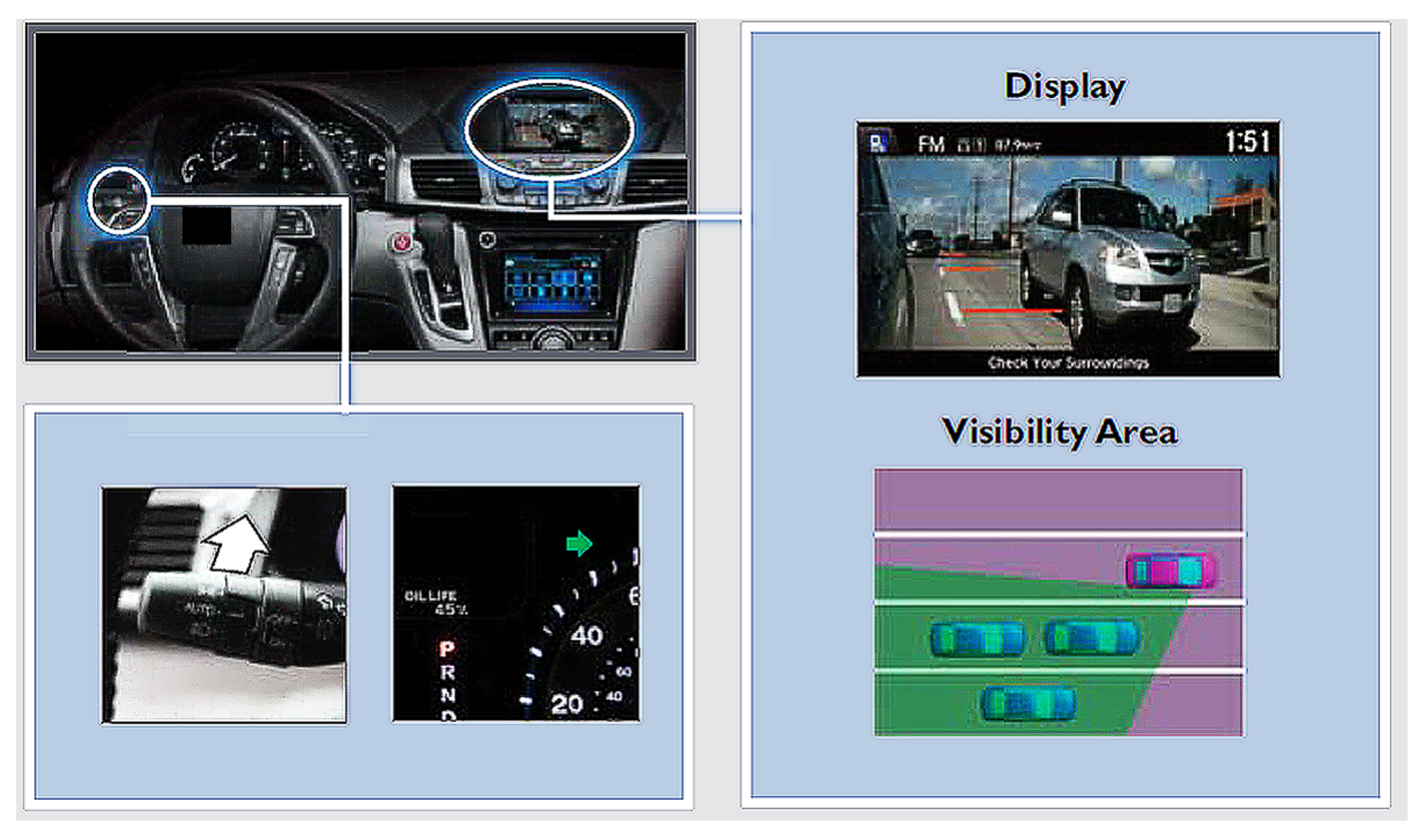
3.5. Blind Spot Setting for Vehicle Detection
3.6. False Positive Reduction
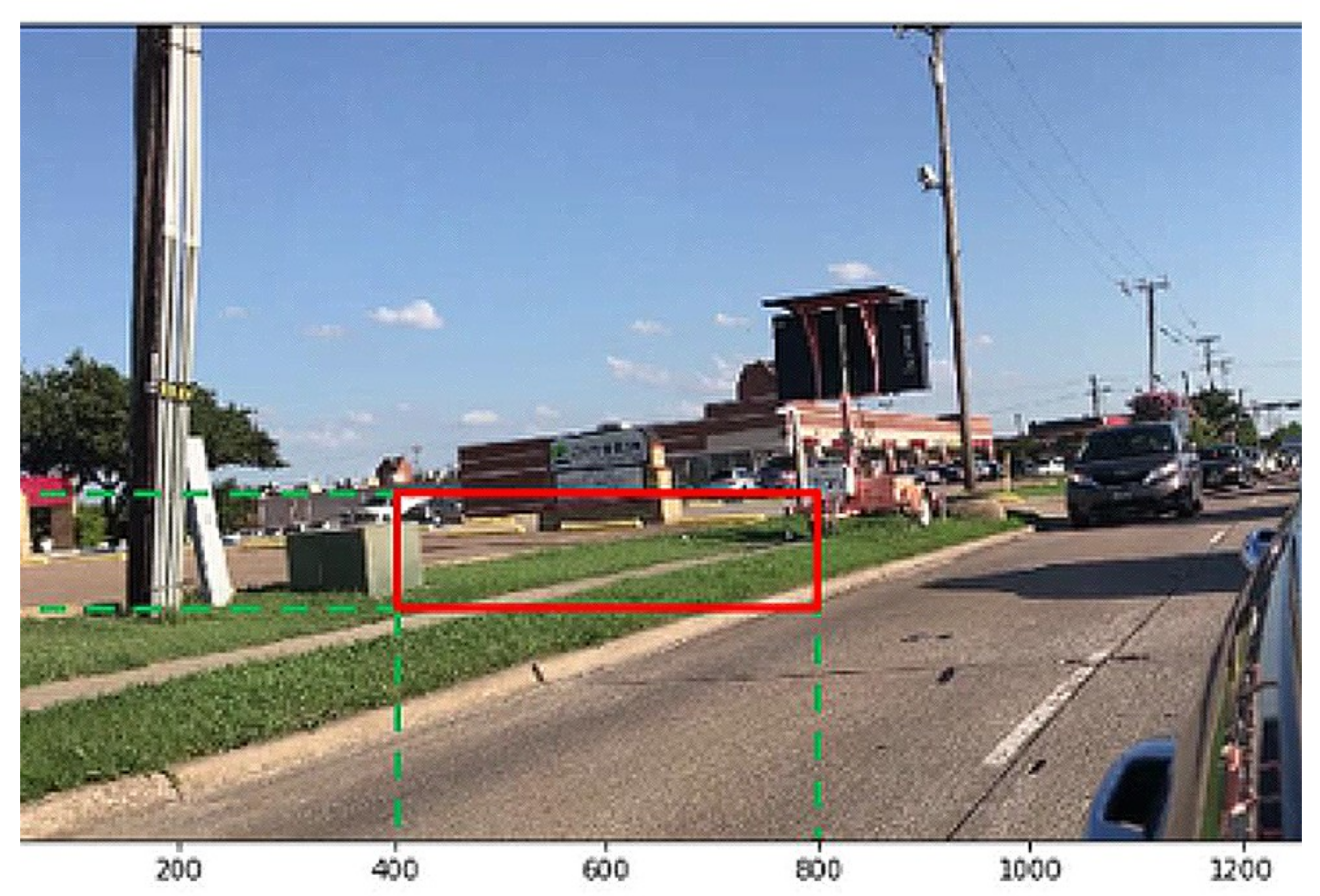
4. Experiments with Record Video Images
- the size of a rectangle box: 9000
- the threshold value: 10
- the size of detection memory: 4
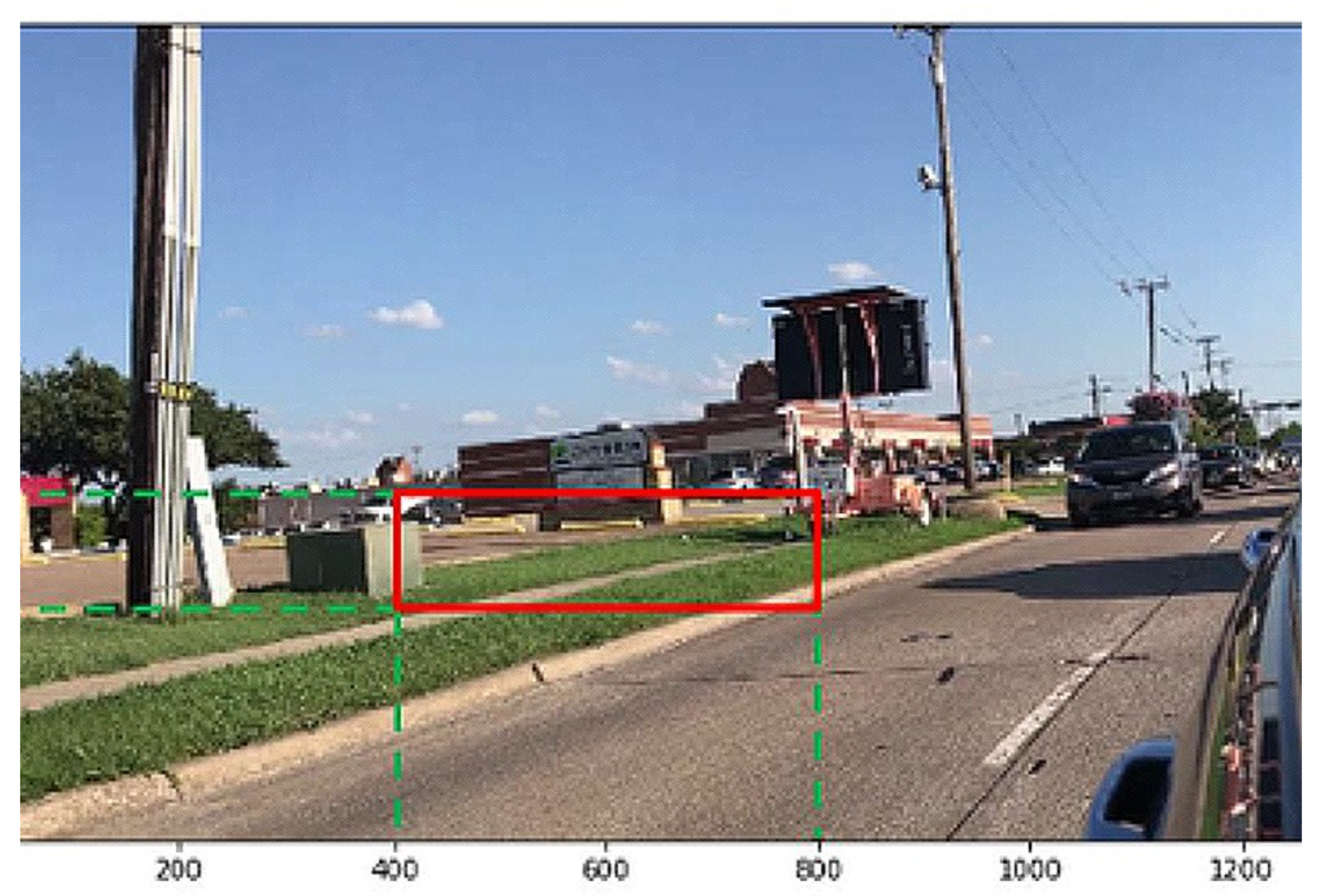
5. Experiments on a Real Road
- the size of a rectangle box: 6000
- the threshold value: 2
- the size of detection memory: 10
6. Conclusions, Limitations, and Future Work
- More than ten thousand images including vehicles, motorcycles, and any other non-vehicle objects will be secured for both training and testing. By doing so, training and testing accuracy of a deep learning model will be improved. In addition, the system will be optimized for no false positives.
- One of the issues during system testing was that camera angles continuously changed due to a strong wind while the vehicle was driving at high speed. Furthermore, image quality from the camera was not good enough. Hence, a camera which has better hardware specifications will be mounted with fixed angles underneath the side mirror, and further experiments under various conditions will be conducted. In addition, two cameras on both sides will be adopted for testing.
- Target vehicles were detected by a rectangle box, but this would be replaced with a blind spot icon. Specifically, this icon will be displayed on the screen when target vehicles are detected in the blind spot. Moreover, the system will give both visual and audible alarms.
- The reason for employing the FCN model in this research was that the adopted off-the-shelf embedded board had the power limit, thus this resulted in fewer cores and less parallelization. Due to this constraint, we decided to experiment the simplest one among a variety of deep learning methodologies. Moreover, the total amount of the images to be processed for classification was reduced by the sliding window technique. Since our goal was to identify the features of a vehicle in a particular area within a given image, this remarkably reduced the need of having complex networks with enhanced classification capabilities. However, it is highly meaningful to compare and analyze differences from the system developed on FCN basis by adopting different deep learning methodologies, so a new vehicle blind spot detection system will be developed by adopting various deep learning methodologies.
- To make fewer and faster computations on the embedded board, we skipped representation learning. However, we believe that a different approach to handle dimensionality curse was taken. As mentioned above, the sliding window technique used to identify the features of a vehicle was applied to only process the blind spot area. A relatively small rectangular window was processed at the overlapping horizontal and vertical locations of the image. It is important to note that the size of window is much smaller than the size of a vehicle in blind spot. In addition, a heat map was created out of all the windows identifying features. The rectangular localization was obtained out of the heat map pixels having heat beyond a threshold level. This not only helped to overcome dimensionality curse, but also required substantially less computation power because matrix multiplications could be done on a smaller matrix. However, it is also worthwhile to employ a methodology such as the RBMs to see how representation/feature learning can change the processing of our model.
Author Contributions
Funding
Conflicts of Interest
References
- Yeomans, G. Autonomous vehicles: handing over control—Opportunities and risks for insurance. Lloyds 2014, 18, 4–23. [Google Scholar]
- Litman, T. Autonomous Vehicle Implementation Predictions; Victoria Transport Policy Institute: Victoria, CO, Canada, 2017. [Google Scholar]
- National Transportation Safety Board (NTSB). Highway Accident Report: Collision between a Car Operating with Automated Vehicle Control Systems and a Tractor-Semitrailer Truck; NTSB: Washington, DC, USA, 2016. [Google Scholar]
- Brown, B.; Laurier, E. The trouble with autopilots: Assisted and autonomous driving on the social road. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 416–429. [Google Scholar]
- Bulumulle, G.; Bölöni, L. Reducing Side-Sweep Accidents with Vehicle-to-Vehicle Communication. J. Sens. Actuator Netw. 2016, 5, 19. [Google Scholar] [CrossRef]
- Schneider, M. Automotive radar–status and trends. In Proceedings of the German Microwave Conference, Ulm, Germany, 5–7 April 2005; pp. 144–147. [Google Scholar]
- Hasch, J. Driving towards 2020: Automotive radar technology trends. In Proceedings of the Microwaves for Intelligent Mobility (ICMIM), Heidelberg, Germany, 27–29 April 2015; pp. 1–4. [Google Scholar]
- Forkenbrock, G.; Hoover, R.L.; Gerdus, E.; Van Buskirk, T.R.; Heitz, M. Blind Spot Monitoring in Light Vehicles—System Performance; Technical Report; National Highway Traffic Safety Administration: Washington, DC, USA, 2014. [Google Scholar]
- Oshida, K.; Watanabe, T.; Nishiguchi, H. Vehicular Imaging Device. USA Patent 9,294,657, 22 March 2016. [Google Scholar]
- Sotelo, M.Á.; Barriga, J.; Fernández, D.; Parra, I.; Naranjo, J.E.; Marrón, M.; Alvarez, S.; Gavilán, M. Vision-based blind spot detection using optical flow. In Proceedings of the International Conference on Computer Aided Systems Theory, Las Palmas de Gran Canaria, Spain, 12–16 February 2007; pp. 1113–1118. [Google Scholar]
- Saboune, J.; Arezoomand, M.; Martel, L.; Laganiere, R. A visual blindspot monitoring system for safe lane changes. In Proceedings of the International Conference on Image Analysis and Processing, Ravenna, Italy, 14–16 September 2011; pp. 1–10. [Google Scholar]
- Jung, K.H.; Yi, K. Vision-based blind spot monitoring using rear-view camera and its real-time implementation in an embedded system. J. Comput. Sci. Eng. 2018, 12, 127–138. [Google Scholar] [CrossRef]
- Zhao, Y.; Bai, L.; Lyu, Y.; Huang, X. Camera-Based Blind Spot Detection with a General Purpose Lightweight Neural Network. Electronics 2019, 8, 233. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 4th International IEEE Workshop on 3D Representation and Recognition (3dRR-13), Sydney, Australia, 2 December 2013. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Arróspide, J.; Salgado, L.; Nieto, M. Video analysis-based vehicle detection and tracking using an mcmc sampling framework. EURASIP J. Adv. Signal Process. 2012, 2012, 2. [Google Scholar] [CrossRef]
- Uhm, D.; Jun, S.H.; Lee, S.J. A classification method using data reduction. Int. J. Fuzzy Log. Intell. Syst. 2012, 12, 1–5. [Google Scholar] [CrossRef]
- Chao, W.L. Dimensionality Reduction; Graduate Institute of Communication Engineering, National Taiwan University: Taipei City, Taiwan, 2011. [Google Scholar]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Clust. Comput. 2017, 1–13. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Nam, J.; Herrera, J.; Slaney, M.; Smith, J.O. Learning Sparse Feature Representations for Music Annotation and Retrieval. In Proceedings of the 13th International Society for Music Information Retrieval Conference, Porto, Portugal, 8–12 October 2012; pp. 565–570. [Google Scholar]
- Mousas, C.; Anagnostopoulos, C.N. Learning Motion Features for Example-Based Finger Motion Estimation for Virtual Characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Churchill, M.; Fedor, A. Histogram of Oriented Gradients for Detection of Multiple Scene Properties. 2014. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Abdi, M.; Nahavandi, S. Multi-residual networks: Improving the speed and accuracy of residual networks. arXiv 2016, arXiv:1609.05672. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Jiang, S.; de Rijke, M. Why are Sequence-to-Sequence Models So Dull? Understanding the Low-Diversity Problem of Chatbots. arXiv 2018, arXiv:1809.01941. [Google Scholar]
- Rekabdar, B.; Mousas, C.; Gupta, B. Generative Adversarial Network with Policy Gradient for Text Summarization. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 204–207. [Google Scholar]
- Kim, M.; Lee, W.; Yoon, J.; Jo, O. Building Encoder and Decoder with Deep Neural Networks: On the Way to Reality. arXiv 2018, arXiv:1808.02401. [Google Scholar]
- Ng, A. CS229 Lecture Notes; 2000; Volume 1, pp. 1–3. Available online: https://www.researchgate.net/publication/265445023_CS229_Lecture_notes (accessed on 20 July 2019).
- Minski, M.L.; Papert, S.A. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Werbos, P.J. The Roots of Backpropagation: From Ordered Derivatives to Neural Networks and Political Forecasting; John Wiley & Sons: Hoboken, NJ, USA, 1994; Volume 1. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Barter, R.L.; Yu, B. Superheat: An R package for creating beautiful and extendable heatmaps for visualizing complex data. arXiv 2015, arXiv:1512.01524. [Google Scholar] [CrossRef]
- Samek, W.; Binder, A.; Montavon, G.; Lapuschkin, S.; Müller, K.R. Evaluating the visualization of what a deep neural network has learned. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2660–2673. [Google Scholar] [CrossRef]
- Senthilkumaran, N.; Vaithegi, S. Image segmentation by using thresholding techniques for medical images. Comput. Sci. Eng. Int. J. 2016, 6, 1–13. [Google Scholar] [CrossRef]
- Chaubey, A.K. Comparison of The Local and Global Thresholding Methods in Image Segmentation. World J. Res. Rev. 2016, 2, 1–4. [Google Scholar]
- Von Zitzewitz, G. Deep Learning and Real-Time Computer Vision for Mobile Platforms. Available online: https://www.researchgate.net/publication/331839269_Deep_Learning_and_Real-Time_Computer_Vision_for_Mobile_Platforms (accessed on 20 July 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Levels | Description |
|---|---|
| Level 0 No Automation | The driver fully takes responsibility to operate the vehicle. |
| Level 1 Driver Assistance | The driver operates the vehicle with some driving assistance features included in the vehicle. |
| Level 2 Partial Automation | Automated features such as auto-steering, auto-acceleration, etc. need to be installed in the vehicle, and the driver needs to engage in driving the vehicle and monitoring the environment. |
| Level 3 Conditional Automation | The driver is not required to monitor the environment but needs to control the vehicle when necessary. |
| Level 4 High Automation | The driver is required to optionally control the vehicle, and all the driving functions in the vehicle are operated under certain conditions. |
| Level 5 Full Automation | The driver is required to optionally control the vehicle, and all the driving functions in the vehicle are operated under all conditions. |
| Epoch | Training Loss | Training Accuracy | Testing Loss | Testing Accuracy |
|---|---|---|---|---|
| 1 | 0.5111 | 78.8% | 0.2019 | 87.8% |
| 2 | 0.1750 | 93.4% | 0.1337 | 95.6% |
| 3 | 0.1254 | 96.3% | 0.1014 | 96.9% |
| 4 | 0.0982 | 97.3% | 0.0817 | 97.4% |
| 5 | 0.0782 | 98.1% | 0.0692 | 97.8% |
| 6 | 0.0636 | 98.5% | 0.0593 | 98.1% |
| 7 | 0.0527 | 98.9% | 0.0522 | 98.3% |
| 8 | 0.0448 | 99.1% | 0.0498 | 98.5% |
| 9 | 0.0379 | 99.3% | 0.0443 | 98.8% |
| 10 | 0.0321 | 99.4% | 0.0389 | 99.0% |
| Scenarios | Detection Accuracy | False Positives |
|---|---|---|
| When target vehicles passed the system-equipped vehicle at a speed of 35 MPH | 75%, Two vehicles out of eight vehicles were missed | No false positives |
| When the system-equipped vehicle passed a black pick up truck at a speed of 35 MPH | 100% | No false positives |
| When the system-equipped vehicle passed three semi-trailers at a speed of 75 MPH | 100% | 2 false positives |
| When the system-equipped vehicle was driving at a same speed of 75 MPH with a grey hatchback | 100% | 1 false positive |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, D.; Malaiya, R.; Yoon, G.; Ryu, J.-T.; Pi, S.-Y. A Study on Development of the Camera-Based Blind Spot Detection System Using the Deep Learning Methodology. Appl. Sci. 2019, 9, 2941. https://doi.org/10.3390/app9142941
Kwon D, Malaiya R, Yoon G, Ryu J-T, Pi S-Y. A Study on Development of the Camera-Based Blind Spot Detection System Using the Deep Learning Methodology. Applied Sciences. 2019; 9(14):2941. https://doi.org/10.3390/app9142941
Chicago/Turabian StyleKwon, Donghwoon, Ritesh Malaiya, Geumchae Yoon, Jeong-Tak Ryu, and Su-Young Pi. 2019. "A Study on Development of the Camera-Based Blind Spot Detection System Using the Deep Learning Methodology" Applied Sciences 9, no. 14: 2941. https://doi.org/10.3390/app9142941
APA StyleKwon, D., Malaiya, R., Yoon, G., Ryu, J.-T., & Pi, S.-Y. (2019). A Study on Development of the Camera-Based Blind Spot Detection System Using the Deep Learning Methodology. Applied Sciences, 9(14), 2941. https://doi.org/10.3390/app9142941