A Video-Based Fire Detection Using Deep Learning Models


Abstract
:1. Introduction
- (1)
- We propose a deep learning-based fire detection method that avoids the time-consuming efforts to explore hand-crafted features. Because it automatically generates a set of useful features after training, it is sufficient to construct the proper deep learning model and to gather a sufficient amount of training data. Therefore, we have constructed a large fire dataset which contains diverse still images and video clips, including the data from well-known public datasets. Not only is the dataset used for the training and testing of our experiment, but it also could be an asset for future computer vision-based fire detection research.
- (2)
- Our deep learning-based method emulates a human process of fire detection called DTA, in that SRoFs are detected in one scene and the temporal behaviors are continuously monitored and accumulated to finally decide whether it is a fire or not. In the method, Faster R-CNN is used to detect SRoFs against non-fire objects with their spatial features, and LSTM temporally accumulates the summarized spatial features by using the weighted Global Average Pooling (GAP), where the weight is given by the confidence score of a bounding box. The initial decision is made in a short period, and the final decision is made by the majority voting of the series of decisions in a long period.
- (3)
- The proposed method has been experimentally proven to provide excellent fire detection accuracy by reducing the false detections and misdetections. Also, it successfully interprets the temporal SRoF behavior, which may reduce false dispatch of firemen.
2. Related Work
2.1. Computer Vision-Based Fire Detection
2.2. Deep Learning-Based Approach
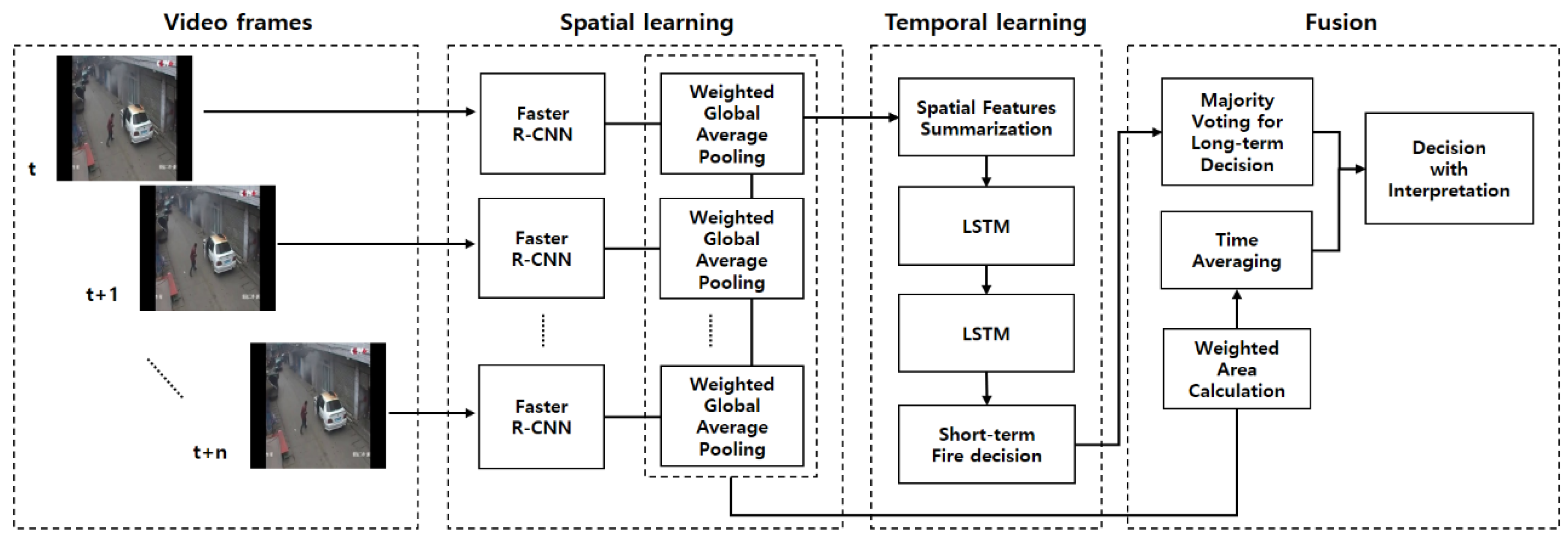
3. Proposed Method
3.1. Network Architecture
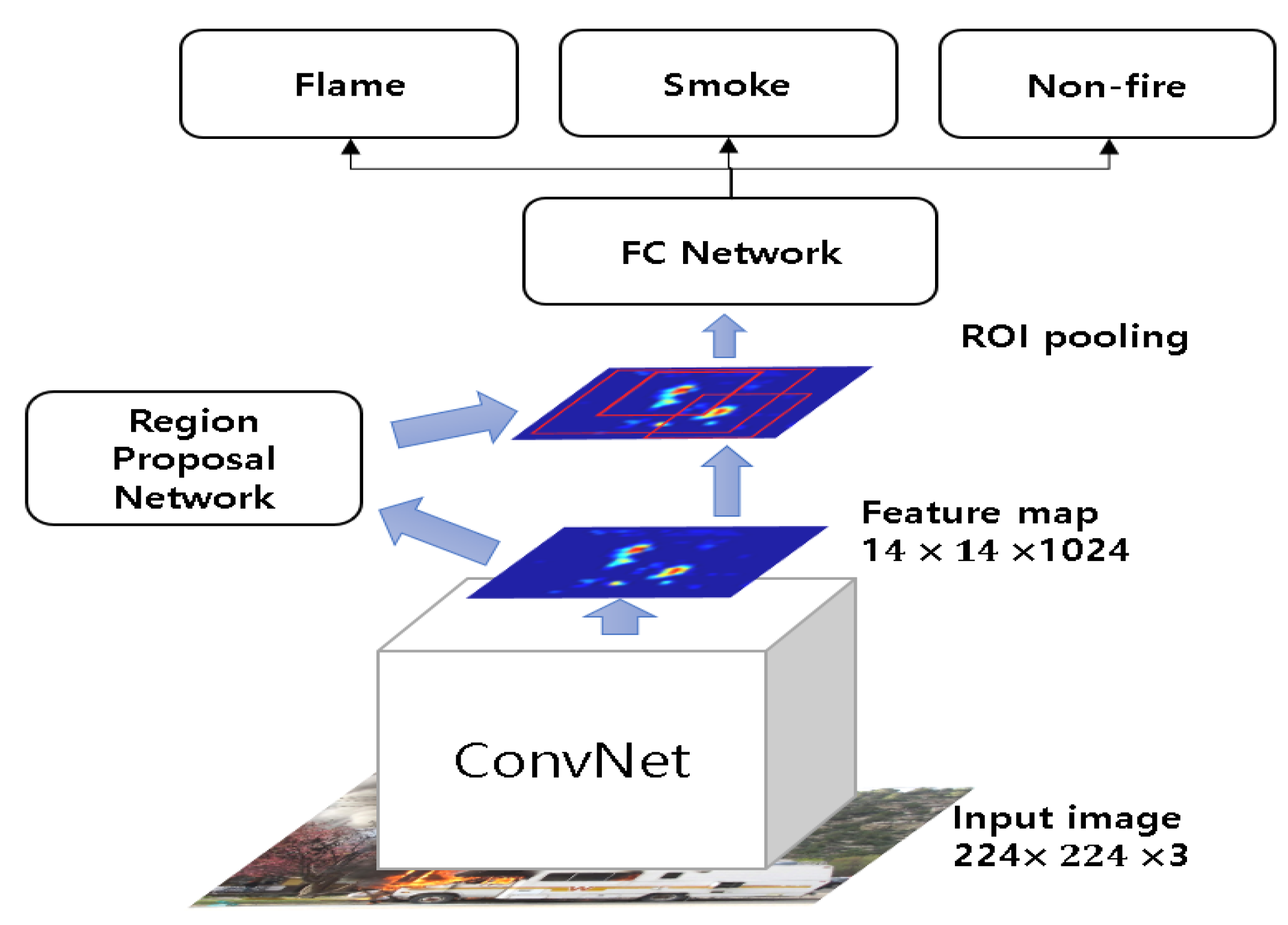
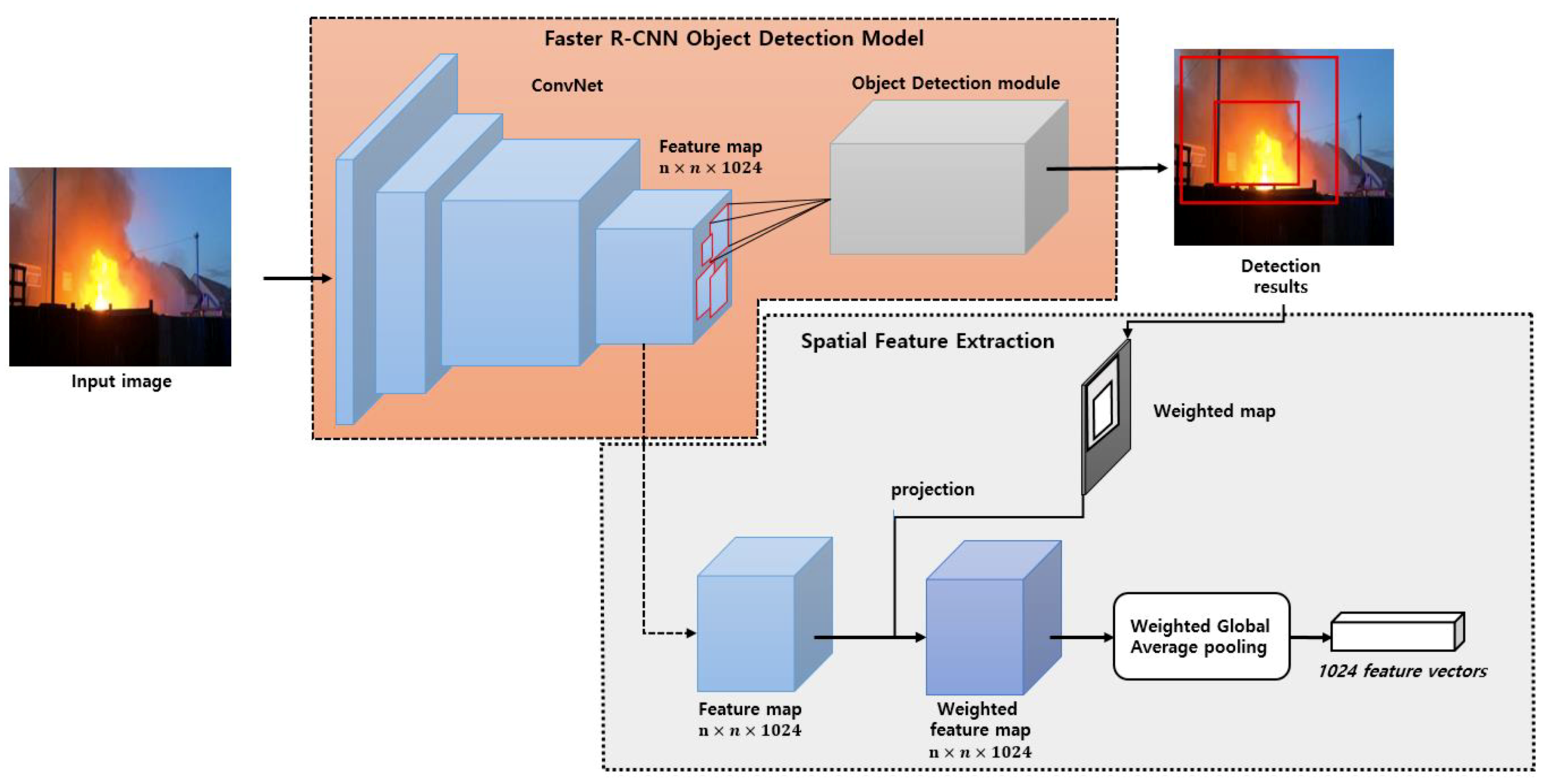
3.2. Fire Object Detection Based on Faster Region-Based Convolutional Neural Network (R-CNN)
3.3. The Spatial Features Extration
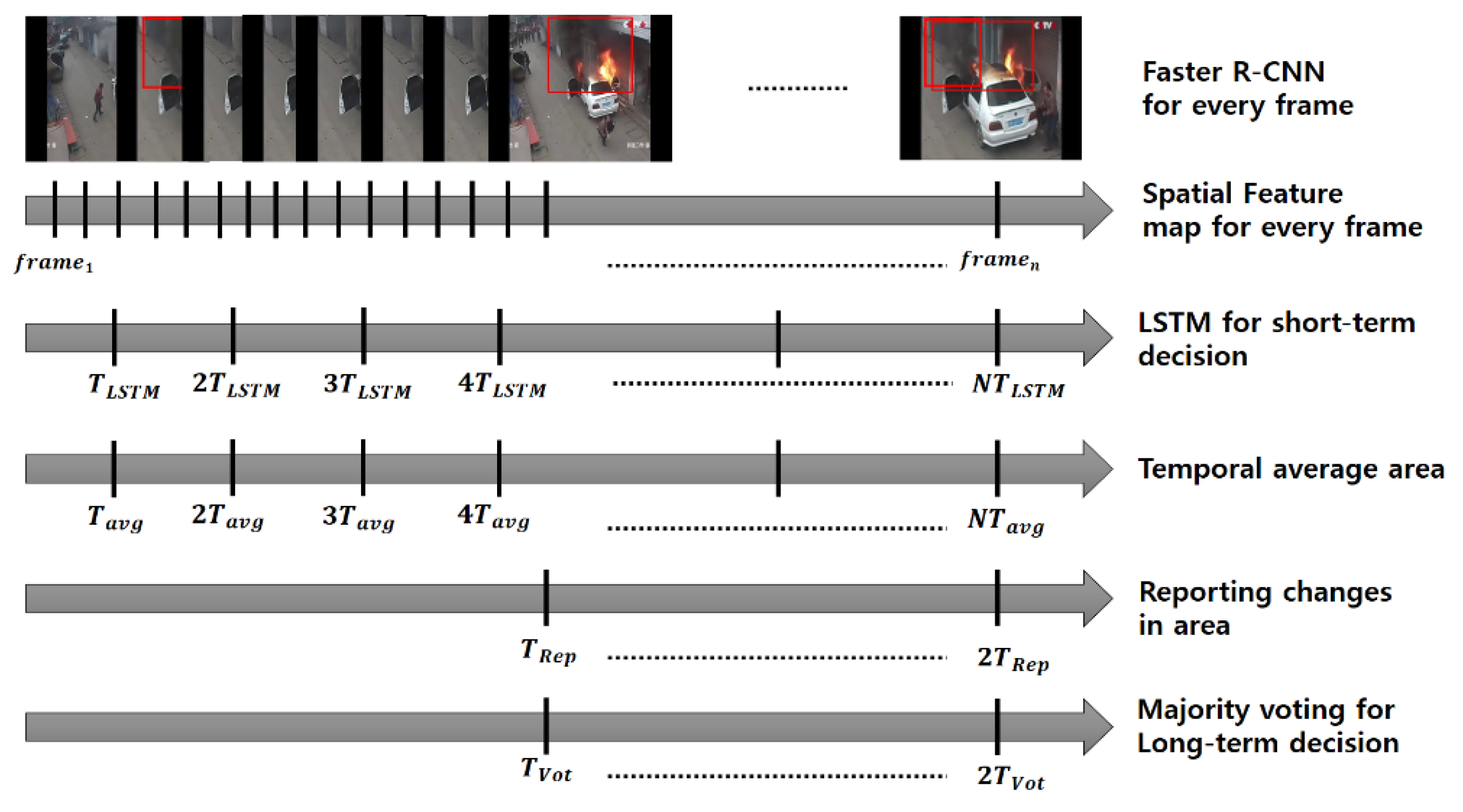
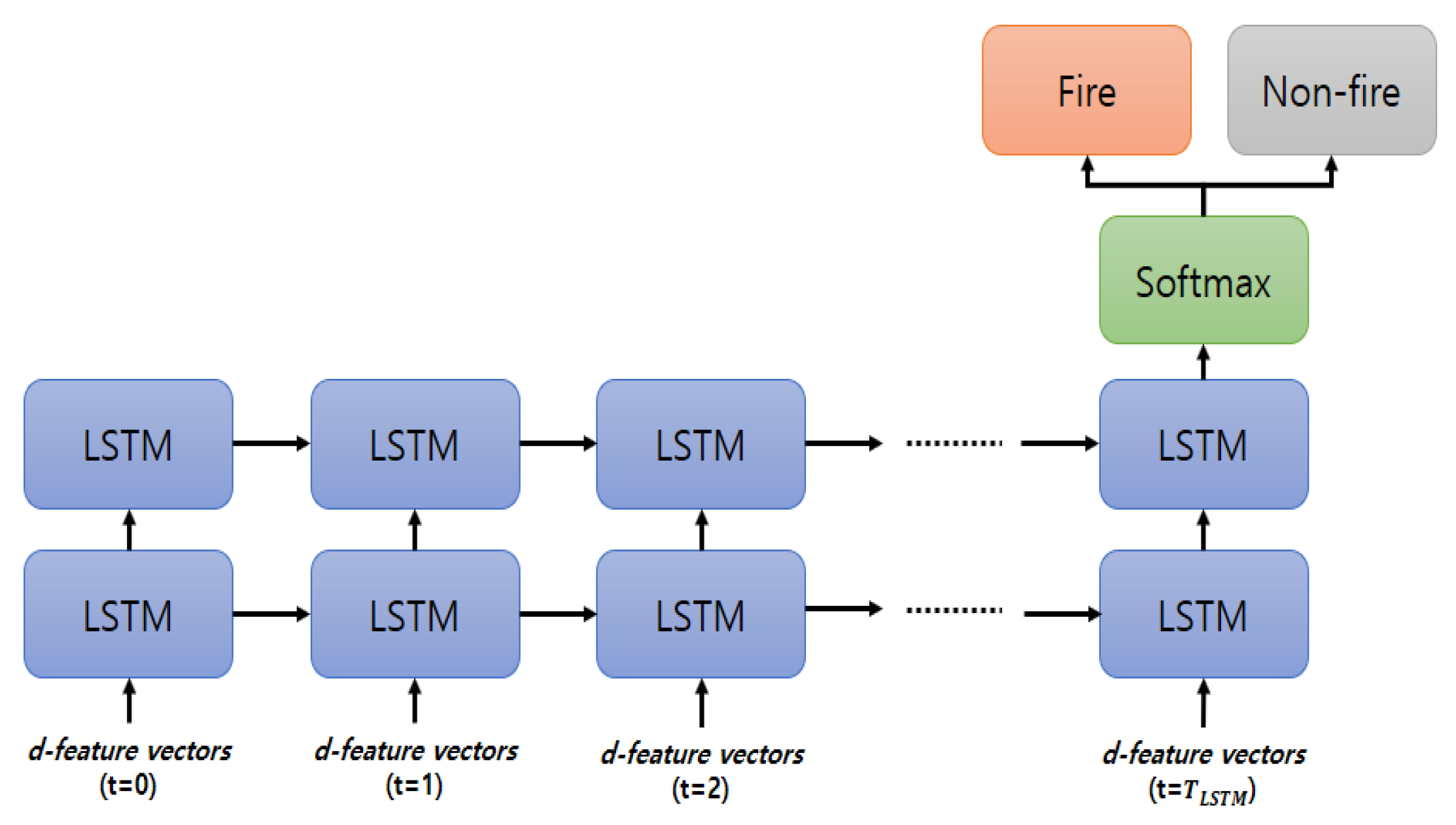
3.4. Long Short-Term Memory (LSTM) Network for Fire Features in a Short-Term
3.5. Majority Voting for Fire Decision
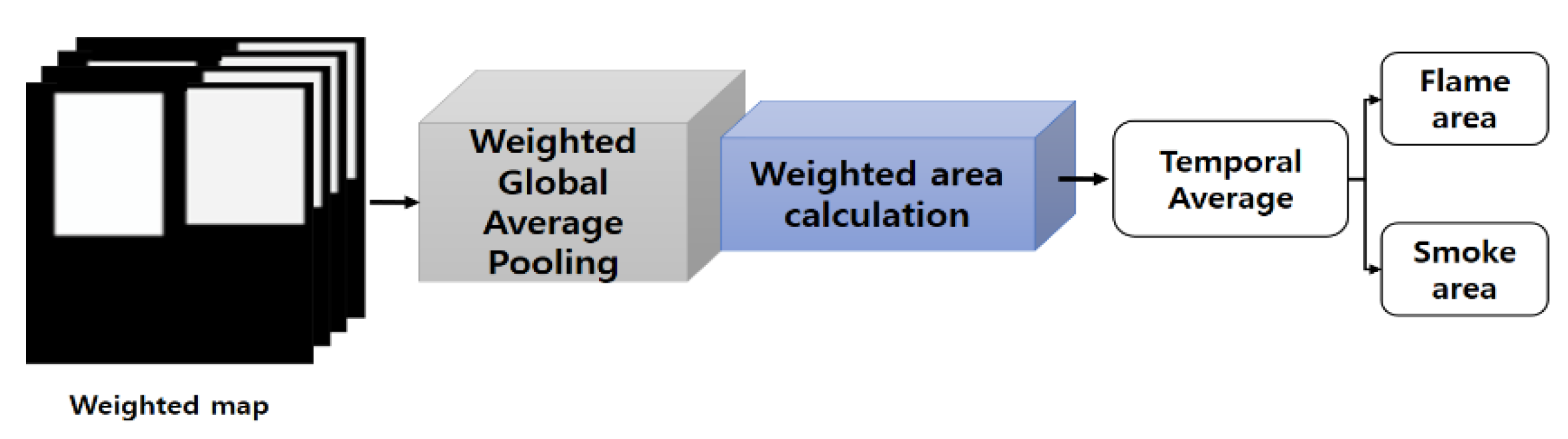
3.6. The Time Average over Weighted Areas of Suspected Regions of Fire (SRoFs)
4. Experiments and Results
4.1. Training Faster R-CNN and Its Accuracy
4.2. Training LSTM and Its Performance
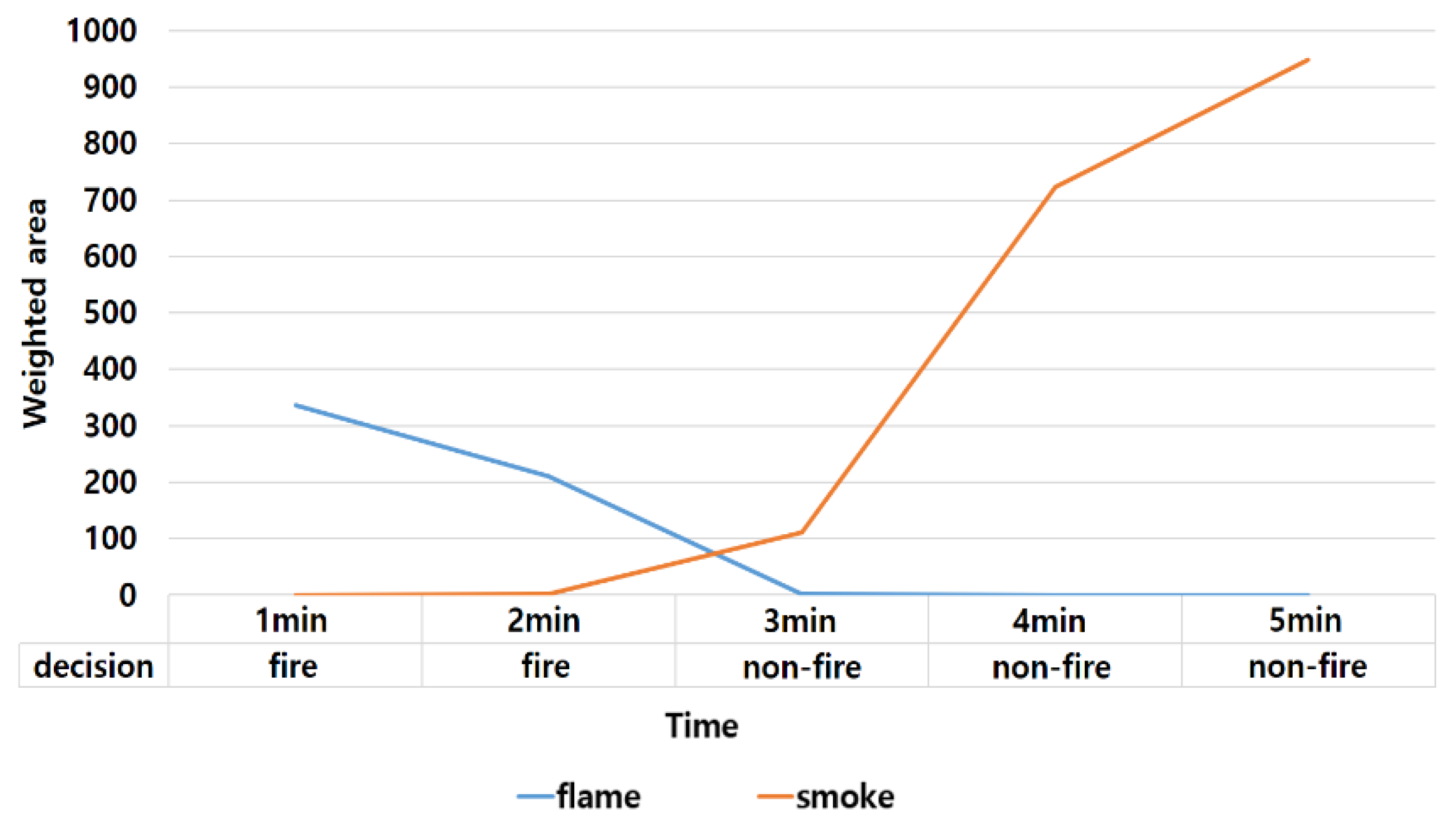
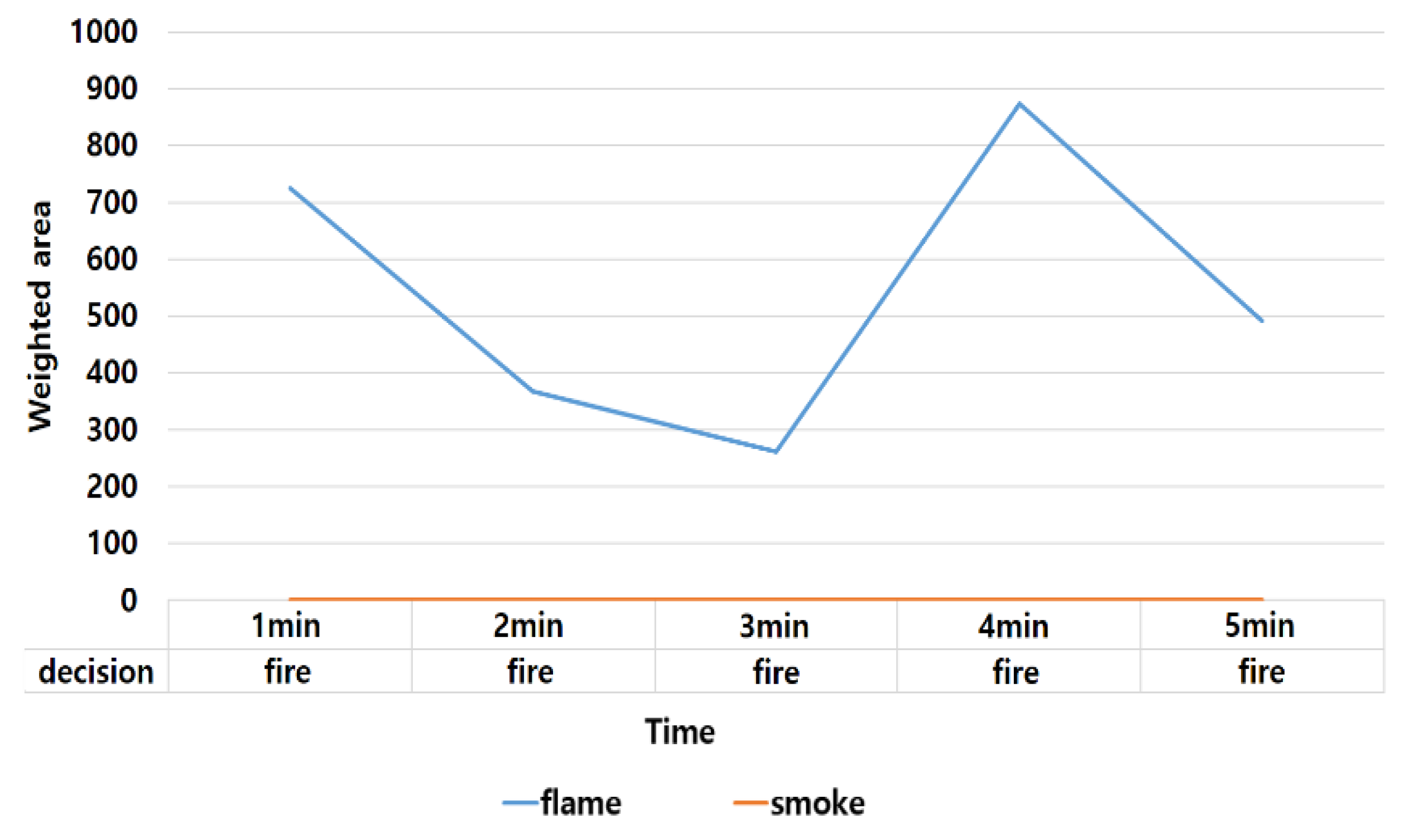
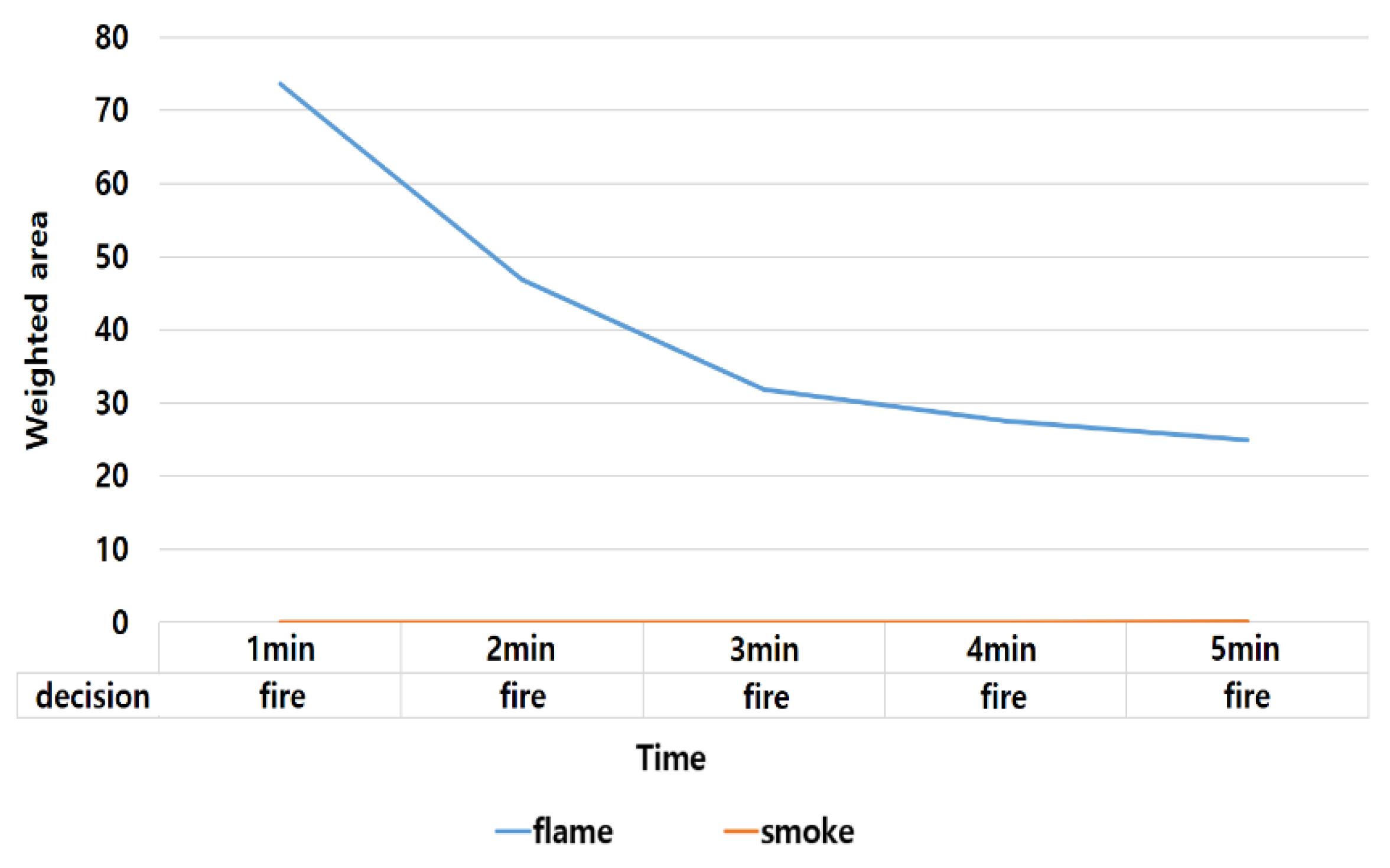
4.3. Majority Voting and Interpretation of Fire Behavior
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chi, R.; Lu, Z.M.; Ji, Q.G. Real-time multi-feature based fire flame detection in video. IET Image Process. 2016, 11, 31–37. [Google Scholar] [CrossRef]
- Evarts, B. Fire loss in the United States during 2017; National Fire Protection Association, Fire Analysis and Research Division: Quincy, MA, USA, 2018. [Google Scholar]
- Qiu, T.; Yan, Y.; Lu, G. An autoadaptive edge-detection algorithm for flame and fire image processing. IEEE Trans. Instrum. Meas. 2012, 61, 1486–1493. [Google Scholar] [CrossRef]
- Liu, C.B.; Ahuja, N. Vision based fire detection. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; pp. 134–137. [Google Scholar]
- Celik, T.; Demirel, H.; Ozkaramanli, H.; Uyguroglu, M. Fire detection using statistical color model in video sequences. J. Vis. Commun. Image Represent. 2007, 18, 176–185. [Google Scholar] [CrossRef]
- Ko, B.C.; Ham, S.J.; Nam, J.Y. Modeling and formalization of fuzzy finite automata for detection of irregular fire flames. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1903–1912. [Google Scholar] [CrossRef]
- Chen, T.H.; Wu, P.H.; Chiou, Y.C. An early fire-detection method based on image processing. In Proceedings of the International Conference on Image Processing (ICIP), Singapore, 24–27 October 2004; pp. 1707–1710. [Google Scholar]
- Wang, T.; Shi, L.; Hou, X.; Yuan, P.; Bu, L. A new fire detection method based on flame color dispersion and similarity in consecutive frames. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 151–156. [Google Scholar]
- Borges, P.V.K.; Izquierdo, E. A probabilistic approach for vision-based fire detection in videos. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 721–731. [Google Scholar] [CrossRef]
- Mueller, M.; Karasev, P.; Kolesov, I.; Tannenbaum, A. Optical flow estimation for flame detection in videos. IEEE Trans. Image Process. 2013, 22, 2786–2797. [Google Scholar] [CrossRef] [PubMed]
- Foggia, P.; Saggese, A.; Vento, M. Real-time fire detection for video surveillance applications using a combination of experts based on color, shape, and motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 877–882. [Google Scholar]
- Zhang, Q.; Xu, J.; Guo, H. Deep convolutional neural networks for forest fire detection. In Proceedings of the 2016 International Forum on Management, Education and Information Technology Application, Guangzhou, China, 30–31 January 2016; Atlantis Press: Paris, France, 2016. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Localization in Video Surveillance Applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 99, 1–16. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 1997; pp. 473–479. [Google Scholar]
- Hu, C.; Tang, P.; Jin, W.; He, Z.; Li, W. Real-Time Fire Detection Based on Deep Convolutional Long-Recurrent Networks and Optical Flow Method. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 9061–9066. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Object Detection: Speed and Accuracy Comparison (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLO). Available online: https://medium.com/@jonathan_hui/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo-5425656ae359 (accessed on 28 March 2018).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Torralba, A.; Oliva, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Chino, D.Y.T.; Avalhais, L.P.S.; Rodrigues, J.F.; Traina, A.J.M. Bowfire: detection of fire in still images by integrating pixel color and texture analysis. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Verstockt, S.; Beji, T.; De Potter, P.; Van Hoecke, S.; Sette, B.; Merci, B.; Van De Walle, R. Video driven fire spread forecasting (f) using multi-modal LWIR and visual flame and smoke data. Pattern Recognit. Lett. 2013, 34, 62–69. [Google Scholar] [CrossRef]
- Bedo, M.; Blanco, G.; Oliveira, W.; Cazzolato, M.; Costa, A.; Rodrigues, J.; Traina, A.; Traina, C., Jr. Techniques for effective and efficient fire detection from social media images. arXiv preprint 2015, arXiv:1506.03844. [Google Scholar]
- Di Lascio, R.; Greco, A.; Saggese, A.; Vento, M. Improving fire detection reliability by a combination of video analytics. In Proceedings of the International Conference Image Analysis and Recognition, Vilamoura, Portugal, 22–24 October 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Habiboğlu, Y.H.; Günay, O.; Çetin, A.E. Covariance matrix-based fire and flame detection method in video. Mach. Vis. Appl. 2012, 23, 1103–1113. [Google Scholar] [CrossRef]
- Rafiee, A.; Dianat, R.; Jamshidi, M.; Tavakoli, R.; Abbaspour, S. Fide and smoke detection using wavelet analysis and disorder characteristics. In Proceedings of the 2011 3rd International Conference on Computer Research and Development (ICCRD), Shanghai, China, 11–13 March 2011; pp. 262–265. [Google Scholar]
- Jadon, A.; Omama, M.; Varshney, A.; Ansari, M.S.; Sharma, R. FireNet: A Specialized Lightweight Fire & Smoke Detection Model for Real-Time IoT Applications. arXiv 2019, arXiv:1905.11922. [Google Scholar]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Ahmed, S.H.; Baik, S.W. Efficient Fire Detection for Uncertain Surveillance Environment. IEEE Trans. Ind. Inform. 2019, 15, 3113–3122. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Method |
|---|---|
| Iteration | 150,000 |
| Step size | 100,000 |
| Weight decay | 0.00004 |
| Learning rate | 0.01 |
| Learning rate decay | 0.00001 (iteration equal step size) |
| Batch size | 256 |
| Pre-train weight | ResNet-101 |
| mAP | Flame | Smoke | Non-fire |
|---|---|---|---|
| 88.3% | 89.4% | 87.5% | 88.1% |
| Parameter | Method |
|---|---|
| Input size | 1024 |
| Time step | 60 |
| LSTM cell unit | 128/256/512/1024 |
| Learning rate | 0.001 |
| Learning rate decay | 0.0001 (epoch equal 120) |
| Weight decay | 0.0004 |
| Dropout | 0.5 |
| Batch size | 256 |
| Weight initialization | Xavier initialization |
| epoch | 200 |
| Method | Accuracy (%) |
|---|---|
| SRoF-LSTM, Hidden cell unit = 128 | 92.12 |
| SRoF-LSTM, Hidden cell unit = 256 | 93.87 |
| SRoF-LSTM, Hidden cell unit = 512 | 95.00 |
| SRoF-LSTM, Hidden cell unit = 1024 | 93.50 |
| Video Name | Resolution | Fames | Frame Rate | Fire | Description |
|---|---|---|---|---|---|
| Fire1 | 320 × 240 | 705 | 15 | Yes | A fire generated into a bucket and a person walking near it. |
| aFire2 | 320 × 240 | 116 | 29 | Yes | A fire very far from the camera generated into a bucket. |
| Fire3 | 400 × 256 | 255 | 15 | Yes | A big fire in a forest. |
| Fire4 | 400 × 256 | 240 | 15 | Yes | See the notes of the video Fire3. |
| Fire5 | 400 × 256 | 195 | 15 | Yes | See the notes of the video Fire3. |
| Fire6 | 320 × 240 | 1200 | 10 | Yes | A fire generated in a red ground. |
| Fire7 | 400 × 256 | 195 | 15 | Yes | See the notes of the video Fire3. |
| Fire8 | 400 × 256 | 240 | 15 | Yes | See the notes of the video Fire3. |
| Fire9 | 400 × 256 | 240 | 15 | Yes | See the notes of the video Fire3. |
| Fire10 | 400 × 256 | 210 | 15 | Yes | See the notes of the video Fire3. |
| Fire11 | 400 × 256 | 210 | 15 | Yes | See the notes of the video Fire3. |
| Fire12 | 400 × 256 | 210 | 15 | Yes | See the notes of the video Fire3. |
| Fire13 | 320 × 240 | 1,650 | 25 | Yes | A fire in a bucket in indoor environm ent. |
| Fire14 | 320 × 240 | 5,535 | 15 | Yes | Fire generated by a paper box. The video has been acquired by the authors near a street. |
| Fire15 | 320 × 240 | 240 | 15 | No | Some smoke seen from a closed window. A red reflection of the sun appears on the glass. |
| Fire16 | 320 × 240 | 900 | 10 | No | Some smoke pot near a red dust bin. |
| Fire17 | 320 × 240 | 1725 | 25 | No | Some smoke on the ground near a moving vehicle and moving trees. |
| Fire18 | 352 × 288 | 600 | 10 | No | Some far smoke on a hill. |
| Fire19 | 320 × 240 | 630 | 10 | No | Some smoke on a red ground. |
| Fire20 | 320 × 240 | 5,958 | 9 | No | Some smoke on a hill with red buildings. |
| Fire21 | 720 × 480 | 80 | 10 | No | Some smoke far from the camera behind some moving trees. |
| Fire22 | 480 × 272 | 22,500 | 25 | No | Some smoke behind a mountain in front of the university of salerno. |
| Fire23 | 720 × 576 | 6,097 | 7 | No | Some smoke above a mountain. |
| Fire24 | 320 × 240 | 372 | 10 | No | Some smoke in a room. |
| Fire25 | 352 × 288 | 140 | 10 | No | Some smoke far from the camera in a city. |
| Fire26 | 720 × 576 | 847 | 7 | No | See the notes of the video Fire24. |
| Fire27 | 320 × 240 | 1,400 | 10 | No | See the notes of the video Fire19. |
| Fire28 | 352 × 288 | 6,025 | 25 | No | See the notes of the video Fire18. |
| Fire29 | 720 × 576 | 600 | 10 | No | Some smoke in a city covering red buildings. |
| Fire30 | 800 × 600 | 1,920 | 15 | No | A person moving in a lab holding a red ball. |
| Fire31 | 800 × 600 | 1,485 | 15 | No | A person moving in a lab with a red notebook. |
| Methods | False Positive (%) | False Negative (%) | Accuracy (%) |
|---|---|---|---|
| Proposed method (hidden unit cell = 512) | 3.04 | 1.73 | 95.00 |
| Proposed method (Majority Voting = 10 s) | 2.47 | 1.38 | 97.92 |
| Khan Muhammad et al. [14] | 8.87 | 2.12 | 94.50 |
| Foggia et al. [11] | 11.67 | 0.00 | 93.55 |
| De Lascio et al. [27] | 13.33 | 0.00 | 92.86 |
| Habibugle et al. [28] | 5.88 | 14.29 | 90.32 |
| Rafiee et al. (YUV color) [29] | 17.65 | 7.14 | 74.20 |
| Celik et al. [5] | 29.41 | 0.00 | 83.87 |
| Chen et al. [7] | 11.76 | 14.29 | 87.1 |
| Arpit Jadon et al. [30] | 1.23 | 2.25 | 96.53 |
| Khan Muhammad et al. [31] | 0 | 0.14 | 95.86 |
| Fire State Change | Interpretation | Number of Video Clips |
|---|---|---|
| Decreasing | Decreasing flame/Increasing smoke or steam | 9 |
| Increasing | Increasing flame | 9 |
| Maintaining | Sustain flame/smoke | 11 |
| Non-fire | False object | 11 |
| 30 s | 1 min | 1 min 30 s | 2 min | 2 min 30 s | 3 min |
|---|---|---|---|---|---|
| 96.73% | 99.28% | 99.64% | 99.94% | 100% | 100% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Lee, J. A Video-Based Fire Detection Using Deep Learning Models. Appl. Sci. 2019, 9, 2862. https://doi.org/10.3390/app9142862
Kim B, Lee J. A Video-Based Fire Detection Using Deep Learning Models. Applied Sciences. 2019; 9(14):2862. https://doi.org/10.3390/app9142862
Chicago/Turabian StyleKim, Byoungjun, and Joonwhoan Lee. 2019. "A Video-Based Fire Detection Using Deep Learning Models" Applied Sciences 9, no. 14: 2862. https://doi.org/10.3390/app9142862
APA StyleKim, B., & Lee, J. (2019). A Video-Based Fire Detection Using Deep Learning Models. Applied Sciences, 9(14), 2862. https://doi.org/10.3390/app9142862