3-D People Counting with a Stereo Camera on GPU Embedded Board

Abstract
1. Introduction
2. Proposed Method
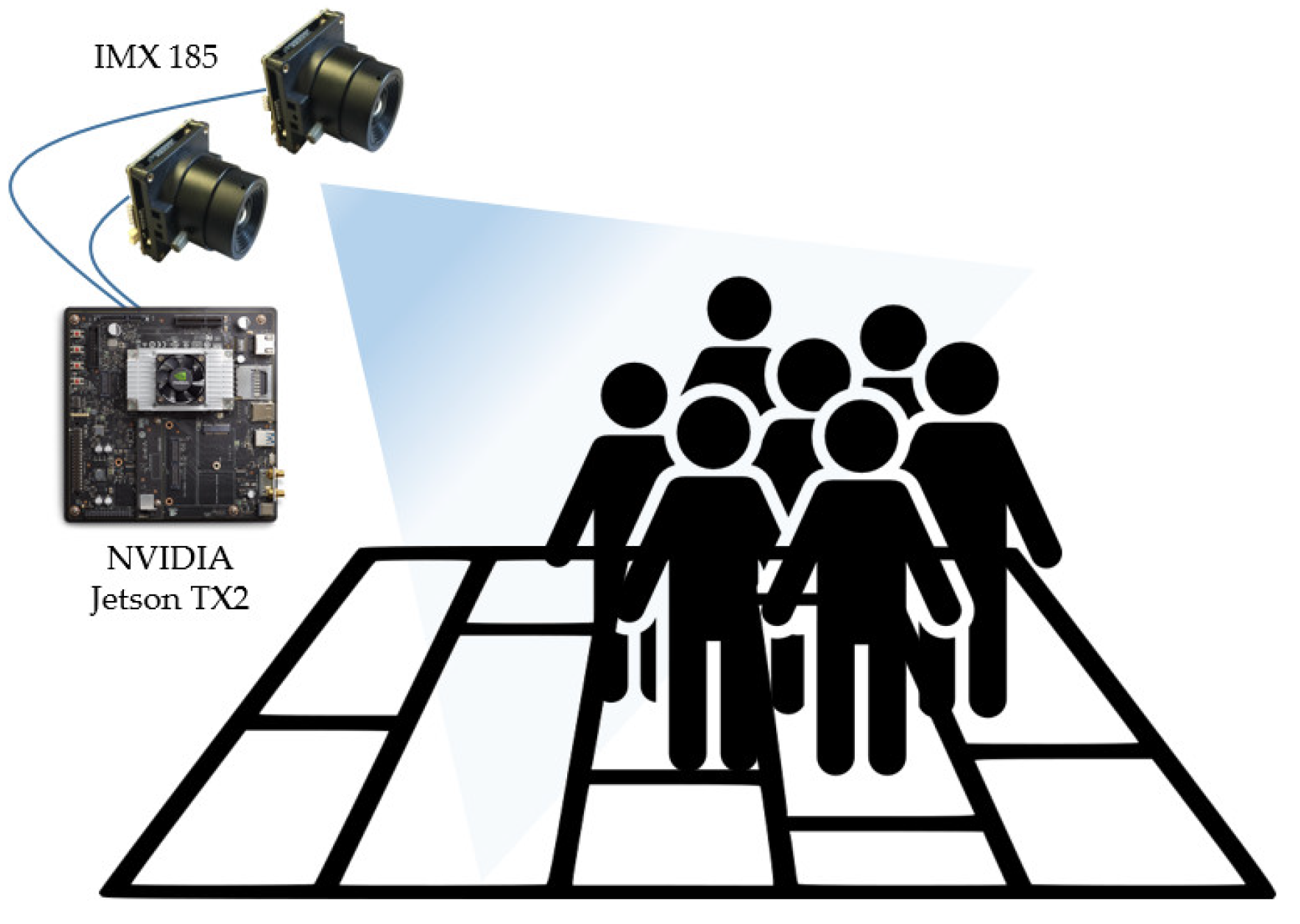
2.1. Stereo Camera Configuration
2.2. Camera Calibration
2.3. Disparity Map Extraction Using Stereo Matching
2.4. Moving Object Detection
2.5. View Projection
2.6. Object Tracking and People Counting
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, X.; Tu, P.H.; Rittscher, J.; Perera, A.; Krahnstoever, N. Detecting and counting people in surveillance applications. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance 2005 (AVSS 2005), Como, Italy, 15–16 September 2005. [Google Scholar]
- Zeng, C.; Ma, H. Robust head-shoulder detection by pca-based multilevel hog-lbp detector for people counting. In Proceedings of the 2010 20th International Conference on Pattern Recognition (ICPR 2010), Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Jolliffe, I. Principal component analysis. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ren, P.; Fang, W.; Djahel, S. A novel YOLO-Based real-time people counting approach. In Proceedings of the 2017 International Smart Cities Conference (ISC2 2017), Wuxi, China, 14–17 September 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Noone, D.R.; Bergman, A.S.; Lynch, R.K. Method and System for People Counting Using Passive Infrared Detectors. U.S. Patent No. 9,183,686, 10 November 2015. [Google Scholar]
- Liu, J.; Liu, Y.; Zhang, G.; Zhu, P.; Chen, Y.Q. Detecting and tracking people in real time with RGB-D camera. Pattern Recognit. Lett. 2015, 53, 16–23. [Google Scholar] [CrossRef]
- Kristoffersen, M.S.; Dueholm, J.V.; Gade, R.; Moeslund, T.B. Pedestrian counting with occlusion handling using stereo thermal cameras. Sensors 2016, 16, 62. [Google Scholar] [CrossRef] [PubMed]
- Nalpantidis, L.; Sirakoulis, G.C.; Gasteratos, A. Review of stereo matching algorithms for 3D vision. In Proceedings of the 16th International Symposium on Measurement and Control in Robotics, Warsaw, Poland, 21–23 June 2007. [Google Scholar]
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/buy/jetson-tx2 (accessed on 7 September 2018).
- Zhang, X.; Yan, J.; Feng, S.; Lei, Z.; Yi, D. Water filling: Unsupervised people counting via vertical kinect sensor. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance (AVSS 2012), Beijing, China, 18–21 September 2012. [Google Scholar]
- LI-IMX185-MIPI-M12. Available online: https://www.mouser.com/ProductDetail/Leopard-Imaging/LI-IMX185-MIPI-M12?qs=AQlKX63v8Rv6fHaveNakhw==&gclid=CjwKCAjw2rjcBRBuEiwAheKeLxB1YNpcw85c-47urgTP1Vyi1rv8OaUU-UpCNeK7DrzPtb1KqK9dnBoCw_IQAvD_BwE (accessed on 7 September 2018).
- Hernandez-Juarez, D.; Chacón, A.; Espinosa, A.; Vázquez, D. Embedded real-time stereo estimation via semi-global matching on the GPU. Procedia Comput. Sci. 2016, 80, 143–153. [Google Scholar] [CrossRef]
- Harville, M. Stereo person tracking with adaptive plan-view templates of height and occupancy statistics. Image Vis. Comput. 2004, 22, 127–142. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Kernel-based object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 564–577. [Google Scholar] [CrossRef]
- Su, H.; He, B. A simple rectification method of stereo image pairs with calibrated cameras. In Proceedings of the 2010 2nd International Conference on Information Engineering and Computer Science (ICIECS 2010), Wuhan, China, 25–26 December 2010. [Google Scholar]
- Sun, J.; Li, Y.; Kang, S.B.; Shum, H.Y. Symmetric stereo matching for occlusion handling. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- PEX Connectors. Available online: https://www.i-pex.com/ (accessed on 7 September 2018).
- Martins, H.A.; Birk, J.R.; Kelley, R.B. Camera models based on data from two calibration planes. Comput. Graph. Image Process. 1981, 17, 173–180. [Google Scholar] [CrossRef]
- Alghoniemy, M.; Tewfik, A.H. Geometric distortion correction through image normalization. In Proceedings of the 2000 IEEE International Conference on Multimedia and Expo (ICME 2000), New York, NY, USA, 30 July–2 August 2000. [Google Scholar]
- Abraham, S.; Förstner, W. Fish-eye-stereo calibration and epipolar rectification. ISPRS J. Photogramm. Remote Sens. 2005, 59, 278–288. [Google Scholar] [CrossRef]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994. [Google Scholar]
- Kuhl, A. Comparison of Stereo Matching Algorithms for Mobile Robots; Centre for Intelligent Information Processing System, The University of Western Australia: Crawley, Australia, 2005; pp. 4–24. [Google Scholar]
- Piccardi, M. Background subtraction techniques: A review. In Proceedings of the Systems, Man and Cybernetics 2004, Hague, The Netherlands, 10–13 October 2004. [Google Scholar]
- Fernandez-Sanchez, E.J.; Diaz, J.; Ros, E. Background subtraction based on color and depth using active sensors. Sensors 2013, 13, 8895–8915. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 26 August 2004. [Google Scholar]
- LI-JETSON-KIT-IMX185-X. Available online: https://leopardimaging.com/product/li-jetson-kit-imx185-x/ (accessed on 7 September 2018).
- Zhong, Z.; Jin, L.; Xie, Z. High performance offline handwritten chinese character recognition using googlenet and directional feature maps. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR 2015), Nancy, France, 23–26 August 2015. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Sony Diagonal 8.58 mm Type 1/1.9 Complementary Metal Oxide Semiconductor (CMOS) Image Sensor IMX185LQJ |
| Resolution | Maximum 1937 × 1217 |
| Pixel Size | 3.75 μm × 3.75 μm |
| Color | Color sensor |
| Interface | Mobile Industry Processor Interface (MIPI) output |
| Module Size | 38 mm × 38 mm |
| Weight | 56 g |
| Sequence | Ground Truth | Proposed Method | Accuracy | ||
|---|---|---|---|---|---|
| Up | Down | Up | Down | ||
| Video1 | 9 | 12 | 12 | 13 | 80.95 |
| Video2 | 5 | 9 | 15 | 9 | 28.57 |
| Video3 | 8 | 11 | 7 | 11 | 94.74 |
| Video4 | 14 | 40 | 13 | 39 | 96.30 |
| Video5 | 5 | 13 | 6 | 13 | 94.44 |
| Video6 | 8 | 22 | 10 | 20 | 100.00 |
| Video7 | 26 | 9 | 25 | 9 | 97.14 |
| Video8 | 21 | 23 | 20 | 22 | 95.45 |
| Video9 | 14 | 15 | 14 | 15 | 100.00 |
| Video10 | 16 | 10 | 16 | 10 | 100.00 |
| Video11 | 29 | 6 | 27 | 6 | 94.29 |
| Video12 | 28 | 11 | 24 | 11 | 89.74 |
| Video13 | 22 | 19 | 25 | 18 | 95.12 |
| Video14 | 21 | 15 | 21 | 14 | 97.22 |
| Video15 | 6 | 3 | 4 | 4 | 88.89 |
| Video16 | 4 | 13 | 4 | 13 | 100.00 |
| Video17 | 11 | 15 | 11 | 14 | 96.15 |
| Video18 | 14 | 7 | 12 | 7 | 90.48 |
| Video19 | 9 | 11 | 8 | 11 | 95.00 |
| Video20 | 7 | 30 | 9 | 29 | 97.30 |
| Video21 | 16 | 15 | 15 | 13 | 90.32 |
| Video22 | 5 | 15 | 5 | 16 | 95.00 |
| Video23 | 14 | 25 | 12 | 26 | 97.44 |
| Sum | 312 | 349 | 315 | 343 | 98.95% |
| Total | 661 | 658 | |||
| Models | Mono Camera | Stereo Camera | |||
|---|---|---|---|---|---|
| GoogleNet–SSD | MobileNet–SSD | Ours (VGA) | Ours (HD) | Ours (FHD) | |
| Accuracy | 76.2% | 83.0% | 95.59% | 98.95% | 98.55% |
| Mode | Resolution | Side-View | |
|---|---|---|---|
| FPS | Occupancy (%) | ||
| CPU | QVGA (320 × 240) | 15.4 | 21 |
| VGA (640 × 480) | 9.6 | 27 | |
| GPU | HD (1280 × 720) | 12.5 | GPU: 63 CPU: 18 |
| FHD (1920 × 1080) | 5.4 | GPU: 65 CPU: 19 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.-c.; Lee, S.-h.; Yoo, J. 3-D People Counting with a Stereo Camera on GPU Embedded Board. Appl. Sci. 2018, 8, 2017. https://doi.org/10.3390/app8112017
Lee G-c, Lee S-h, Yoo J. 3-D People Counting with a Stereo Camera on GPU Embedded Board. Applied Sciences. 2018; 8(11):2017. https://doi.org/10.3390/app8112017
Chicago/Turabian StyleLee, Gyu-cheol, Sang-ha Lee, and Jisang Yoo. 2018. "3-D People Counting with a Stereo Camera on GPU Embedded Board" Applied Sciences 8, no. 11: 2017. https://doi.org/10.3390/app8112017
APA StyleLee, G.-c., Lee, S.-h., & Yoo, J. (2018). 3-D People Counting with a Stereo Camera on GPU Embedded Board. Applied Sciences, 8(11), 2017. https://doi.org/10.3390/app8112017