1. Introduction
Syndrome differentiation is a core concept in Traditional Asian Medicine (TAM) and plays a crucial role in guiding the diagnostic and therapeutic process [
1]. Unlike Western medicine, which often focuses on identifying the primary diseases, TAM differentiates syndromes to assess the overall symptom patterns and constitutional tendencies of a patient [
2]. This method enables practitioners to understand the comprehensive physiological and pathological state of the individual. Syndrome differentiation involves categorizing the patient’s signs and symptoms into specific patterns that reflect the body’s imbalance, which can be influenced by factors such as organ dysfunction, emotional state, and environmental conditions [
3]. This approach allows for personalized treatment plans that go beyond addressing the disease itself, ensuring that both the root cause and symptomatic patterns are targeted [
4]. For instance, if a patient presents with emotional instability along with symptoms like headache, chest pain, and menstrual irregularities, the practitioner may diagnose liver Qi stagnation, a syndrome characterized by the stagnation of liver Qi [
5]. The syndrome-based diagnosis informs the choice of treatment, guiding the practitioner to select interventions that help to disperse stagnant Qi, such as acupuncture or herbal remedies. In TAM, practitioners not only diagnose the underlying disease but also simultaneously perform syndrome differentiation to tailor treatment to the patient’s unique clinical presentation.
Despite the importance of syndrome differentiation in TAM, the current educational environment focuses more on the transmission of knowledge rather than its practical application. Securing standardized patients involves training individuals to present specific clinical phenotypes, providing students with opportunities to engage in realistic clinical practice scenarios [
6,
7]. This approach offers valuable hands-on experience, closely mirroring actual patient interactions. However, it requires significant time and resources, making it challenging to incorporate multiple practice sessions involving various diseases and syndromes, particularly in the early or intermediate stages of learning. On the other hand, rule-based chatbots offer a more accessible alternative by allowing students to practice simulated interviews through pre-programmed questions and responses [
8,
9]. However, the rule-based chatbots often struggle with handling synonyms, and they lack the capability to evaluate students’ clinical reasoning during interaction, limiting their effectiveness in fostering deeper diagnostic skills. As a result, there is a growing need for innovative tools that can simulate real clinical settings and provide students with opportunities to practice and refine their clinical reasoning skills in the context of syndrome differentiation, thus enhancing the effectiveness of TAM education.
The emergence of large language models (LLMs) like GPT has significantly impacted fields such as healthcare, law, and education, offering powerful reasoning capabilities through natural language processing [
10,
11]. Models like ChatGPT-4, which leverage vast datasets and reinforcement learning with human feedback, have demonstrated expert-level performance in exams such as the USMLE and MBA programmes [
12,
13]. These advancements suggest the potential for developing artificial intelligence (AI)-driven tools to support clinical reasoning in TAM education, particularly for syndrome differentiation and disease diagnosis. A key factor in harnessing the full potential of LLMs is prompt engineering, the process by which queries are structured to optimize the model’s response [
14,
15]. Studies have shown that in Korean medical exams, the accuracy of ChatGPT’s responses improved from 51.82% to 66.18% with the application of prompt engineering techniques, such as the use of specialized terminology and self-consistency approaches [
16]. This demonstrates that prompt engineering enhances AI’s ability to reason effectively in specialized domains like TAM. Therefore, the integration of LLMs into education, guided by well-constructed prompts, presents a promising opportunity to create interactive tools that teach clinical reasoning. Such tools could offer personalized, scalable, and practical clinical reasoning experiences that address the limitations of traditional hands-on training, such as the need for standardized patients or role-playing scenarios.
In this study, we propose a novel framework for TAM using knowledge-guided generative AI. To this end, we developed an educational tool that integrates disease diagnosis and syndrome differentiation, using fatigue as a case study. As a first step, we constructed a dataset composed of keywords that frequently appear in clinical phenotypes for both diseases and syndromes. Next, we generated example questions and responses, symptom summaries, and personas that represent various combinations of diseases and syndromes. Using prompt engineering, we created a virtual patient capable of engaging in question-and-answer interactions that realistically reflect history-taking scenarios. Finally, we developed both quantitative assessment modules to evaluate how well students asked about the patient’s disease and syndrome features, and qualitative assessment modules to measure the effectiveness of their clinical reasoning. Through this process, students can practice clinical reasoning by conducting history-taking on patients exhibiting clinical phenotypes and making diagnostic inferences about diseases and syndromes.
The presented model is expected to make three main contributions. First, the first dual-axis case library for TAM education is curated by systematically pairing five fatigue-related Western diseases with seven high-prevalence TAM syndromes, yielding 28 clinically vetted scenarios. Second, we introduce a reproducible knowledge-guided prompt framework that fuses expert phenotype keywords with LLM to generate virtual-patient dialogues that remain symptom-consistent while preventing answer leakage and hallucination. Third, we design an automatic two-layer assessment module that scores question coverage quantitatively and produces qualitative feedback on students’ diagnostic reasoning, giving instructors objective, actionable metrics. Finally, we have openly released the code, prompt templates, and annotated dataset so that other educators can easily adapt Gen-SynDi to new symptom clusters, languages, and teaching contexts.
2. Materials and Methods
2.1. Dataset Construction
A dataset for constructing virtual patients was developed using standardized patient information from the Clinical Performance Examination (CPX) modules provided by the National Institute for Korean Medicine Development (NIKOM) [
17]. NIKOM offers various resources related to TAM through the National Korean Medicine Clinical Information Portal, including clinical practice guidelines, drug interaction databases, and CPX modules. The CPX modules, developed between 2019 and 2021, encompass approximately 30 diseases focusing on common symptoms such as fatigue, headache, and dizziness. These modules were obtained through coordination with the project manager of the Korean Medicine Innovation Technology Development Initiative. For this study, modules concerning fatigue were prioritized because both the diseases (chronic fatigue syndrome, sleep disorders, fibromyalgia, depression, hyperthyroidism) and their accompanying TAM syndromes are reported with high frequency in clinical-phenotype literature on fatigue [
18,
19]. All CPX files are pre-anonymised educational materials and contain no identifiable patient data; therefore, their secondary use did not require separate IRB approval. This dataset, based on CPX data for fatigue patients, was structured and curated through expert review to ensure its suitability for history-taking. Common syndromes, diseases, syndrome-specific, and system-specific keywords, along with disease characteristics, were selected based on existing schemas and reviewed by CPX developers. Each disease and syndrome was mapped to key components such as chief complaints, current medical history, associated symptoms, aggravating and relieving factors, past medical history, family history, social history, and system-specific reviews of symptoms. Symptoms and patient responses were linked to relevant keywords and categories, enabling the AI model to generate appropriate answers during simulated interactions.
2.2. Generation of Educational Content
The collected dataset was refined and processed to create an educational tool that allows for realistic history-taking while representing a diverse range of disease–syndrome associations in clinical phenotypes. Five diseases commonly associated with fatigue were selected: chronic fatigue syndrome, sleep disorders, fibromyalgia, depression, and hyperthyroidism, along with seven KM syndromes: qi and blood deficiency, spleen qi deficiency, liver and kidney yin deficiency, spleen deficiency with dampness encumbrance, heart and spleen deficiency, liver depression and spleen deficiency, and shaoyang half-exterior half-interior syndrome. For each disease–syndrome pair, key clinical questions and associated keyword-based responses were compiled and transformed into natural, conversational language using the GPT-4o language model. Prompt engineering was applied to maintain consistency with the assigned disease and syndrome, enabling students to engage in meaningful practice of history-taking and clinical reasoning.
2.3. Creation of Patient Personas
Detailed patient personas were developed to enrich the simulations, including demographic information, personality traits, emotional states, and current life circumstances relevant to the clinical scenarios. For example, a patient might be a 35-year-old female experiencing increasing anxiety due to persistent fatigue affecting her work and family life. These personas provided context and depth to the simulated interactions, enhancing their authenticity and educational impact. By combining the disease and syndrome datasets with enriched patient personas, a series of virtual patient cases was created. This approach enabled the practice of integrating disease diagnosis with syndrome differentiation, reflecting the holistic approach of TAM. The method aimed to enhance students’ clinical skills by providing practical, context-rich scenarios for immersive learning experiences.
2.4. Clinical Reasoning Evaluation Process
To evaluate student performance in the simulated clinical environment, a structured assessment process was developed, leveraging both quantitative and qualitative metrics. The evaluation assessed the accuracy and completeness of students’ history-taking abilities, particularly in diagnosing diseases and differentiating syndromes based on KM diagnosis principles. The constructed dataset included various disease and syndrome presentations, incorporating key symptoms and their respective KM syndromes. Each patient case comprised chief complaints, associated symptoms, and relevant medical history, synthesized into example questions and ideal responses. The evaluation process consisted of two main components: quantitative evaluation and qualitative evaluation. The quantitative evaluation assessed student interactions with the virtual patient by comparing the number of correct responses against the total number of ideal responses, providing a numerical measure of how comprehensively the student addressed the necessary diagnostic criteria. The qualitative evaluation involved an analysis of which key questions were asked by the students, and which were omitted, with detailed feedback being offered on the completeness and depth of the student’s history-taking process. For instance, if a student’s questions adequately covered symptom areas such as fatigue and sleep quality but failed to address critical aspects like the patient’s emotional state or digestive symptoms, these omissions were highlighted in the qualitative feedback. A prompt was designed to guide the AI in comparing student-generated questions and responses against ideal ones derived from the dataset. The AI evaluated both disease diagnosis and syndrome differentiation, providing feedback on the accuracy and completeness of the student’s performance.
2.5. Prompt Engineering
Prompt engineering operates across three stages—virtual-patient generation, simulated dialogue, and performance evaluation—and relies on a triplet of prompt types: system, user, and assistant. The system prompt is deliberately layered: (i) a clinical-context header that fixes the chosen disease–syndrome facts; (ii) a safety prompt that blocks symptom drift or premature disclosure of the correct diagnosis; and (iii) a persona block that encodes the virtual patient’s demographics, affect, and communication style. During case creation, GPT-4o is seeded with demographic data, medical history, symptom lists, and emotional state, ensuring every generated scenario aligns with its assigned disease–syndrome pair. In the dialogue stage, the same system prompt—unchanged—sets the patient role, while user prompts are the learner’s questions, and assistant prompts produce the patient’s natural-language replies. Finally, the evaluation stage reuses the system prompt to compare the learner’s inferred disease and syndrome against the expected answers, measuring both question coverage and reasoning quality. All text was generated with OpenAI gpt-4o-2024-08-06—an LLM generally reported to exceed other models, such as GPT-3.5 and Anthropic Claude, in reasoning accuracy [
20]. The API was run with its default parameters (temperature = 1.0, max_tokens = 1024, top_p = 1.0).
2.6. Expert Evaluation
To evaluate the validity, educational effectiveness, and usability of Gen-SynDi, an expert evaluation was conducted involving domain specialists in TAM. This evaluation aimed to assess the appropriateness of Gen-SynDi’s structure and content for virtual patient history-taking and clinical reasoning, its effectiveness in enhancing students’ competencies in these areas, and its overall usability from the perspective of TAM education experts. A structured questionnaire was developed based on prior validated studies and modified to suit the goals of this research. The questionnaire consisted of three main categories: validity, educational effectiveness, and usability [
21,
22]. Items for each category were adapted from previous research to align with the specific features of Gen-SynDi and the TAM educational context.
The evaluation procedure involved the following steps: First, each expert was provided with access to the Gen-SynDi platform and instructed to explore its features through direct use. Following the hands-on session, experts were invited to complete an online evaluation survey. The collected responses were analyzed using descriptive statistics, with mean and standard deviation calculated for each item to summarize expert perceptions across the three categories. A total of 16 experts participated in the evaluation. All held doctoral degrees and had substantial experience in clinical practice and education within TAM. Their areas of specialization included Korean internal medicine, acupuncture and moxibustion, pediatrics, rehabilitation medicine, pathology, herbal medicine, and education. The participants held positions such as professors, lecturers, and hospital physicians, with an average of 12 years of research experience, providing a well-rounded and experienced perspective on the framework’s applicability and value in educational contexts.
3. Results
3.1. Overview of the Model
In this study, we developed a knowledge-guided generative AI framework to construct 28 virtual patient scenarios for Traditional Asian Medicine (TAM) education, focusing on fatigue-related conditions. These scenarios were generated by systematically combining five diseases commonly associated with fatigue with seven TAM syndromes while ensuring clinical plausibility for each combination.
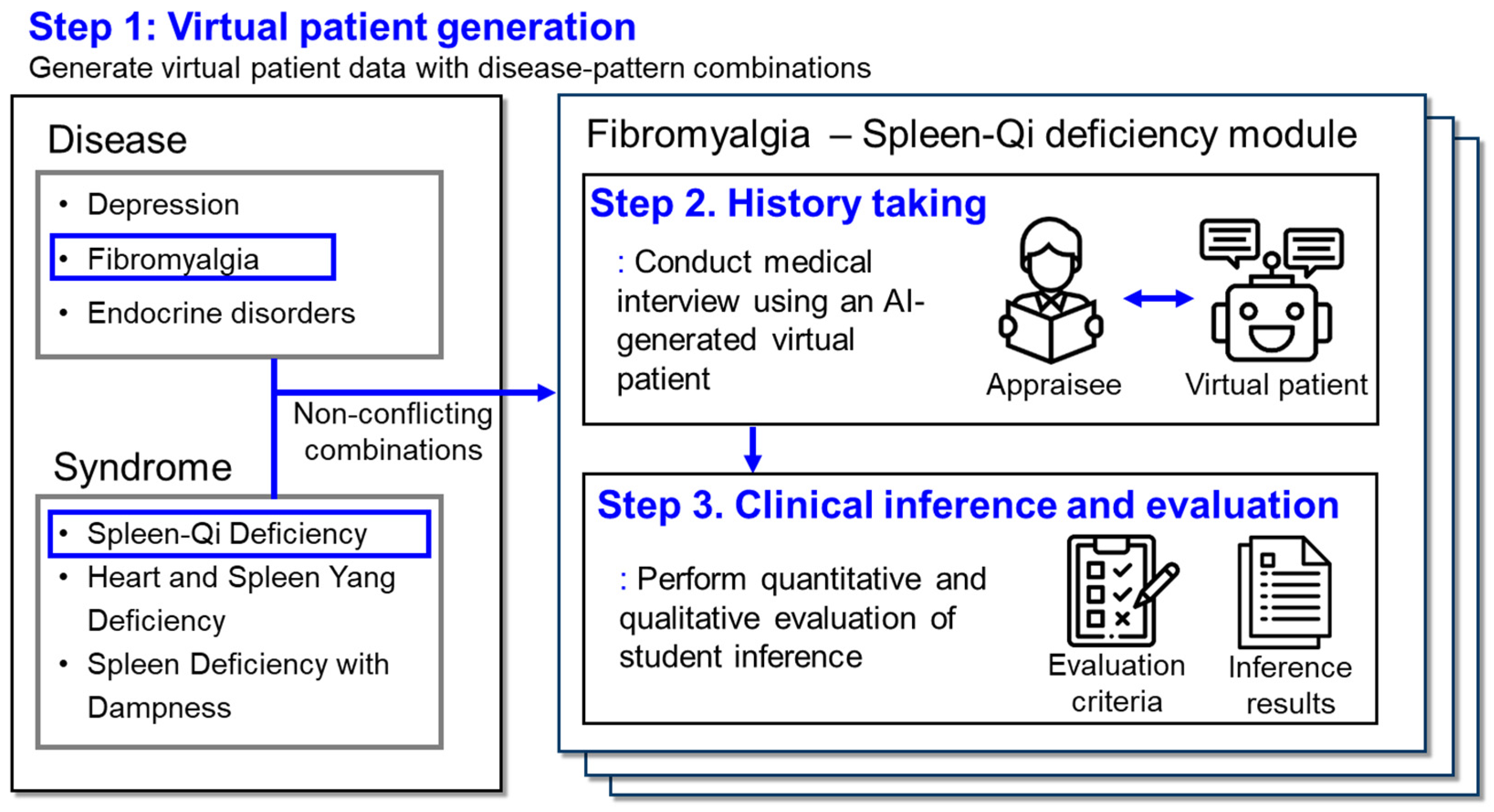
Our framework consists of three key stages: virtual patient generation, medical interview, and evaluation (
Figure 1). The process begins with virtual patient generation, involving the selection of diseases and syndromes from a constructed dataset of clinical features, and combining them to create diverse virtual patients. Subsequently, the virtual patient engages in interactive Q&A sessions with students, simulating realistic history-taking scenarios. Finally, the framework provides an integrated evaluation of students’ diagnostic skills through both quantitative assessment of question coverage and qualitative assessment of clinical reasoning.
The dataset was designed using structured categories of symptom inquiry, reflecting both syndrome and disease dimensions. This allowed us to create a comprehensive representation of clinical features across systematic categories, such as general symptoms, mental health, sleep patterns, and gastrointestinal issues. Specifically, the data related to each TAM syndrome were organized into a structured framework of symptoms (
Supplementary Table S1), and the dataset for disease-specific symptoms—including chronic fatigue syndrome, sleep disorders, fibromyalgia, depression, and hyperthyroidism (
Supplementary Table S2). Each disease and syndrome were described through consistent categories of symptom inquiry, providing a thorough understanding of each clinical presentation.
Additionally, reference clinical inferences were constructed for each scenario to guide expected diagnostic reasoning (
Supplementary Table S3). These inferences represent the ideal answers for each disease–syndrome combination, against which the students’ responses are evaluated. The evaluation module automatically assesses students’ diagnostic inferences, providing both quantitative scores and qualitative feedback to help students understand their strengths and areas for improvement. These reference inferences serve as benchmarks for evaluating student performance in identifying the correct disease diagnosis from the given syndrome and disease features.
3.2. Detailed Example Case: Fibromyalgia with Spleen-Qi Deficiency
To illustrate the practical application of our framework, we present a detailed example using the combination of fibromyalgia and Spleen-Qi deficiency (脾氣虛) syndrome. This combination was selected because both fibromyalgia and Spleen-Qi deficiency (脾氣虛) share symptoms of fatigue, muscle weakness, and digestive issues, frequently observed in Traditional Asian Medicine (TAM) clinics. This case study demonstrates the process of virtual patient creation, the generation of natural language responses, and the subsequent application in simulated interactions.
3.2.1. Simulated Patient Creation
Relevant symptom data were first extracted for both the disease (fibromyalgia) and the syndrome (Spleen-Qi deficiency) from our dataset (
Table 1). After identifying the key symptoms for each, we then combined the keywords for each question to ensure the symptoms from both the disease and the syndrome were represented. Based on this, we applied prompt engineering techniques to transform these combined keywords into coherent, natural language responses. For example, for the question, “Could you please describe specifically what you mean by feeling tired?”, we extracted keywords such as “stiffness in all joints upon waking” (from fibromyalgia) and “drowsiness, decreased concentration” (from Spleen-Qi deficiency). Using prompt engineering, these keywords were combined to create a natural response: “When I wake up in the morning, all my joints feel stiff and achy. Throughout the day, I often feel drowsy and have trouble concentrating on my tasks”. This approach allowed us to generate responses that accurately reflect the patient’s experience, integrating symptoms from both perspectives. This process was applied systematically across all questions in
Table 1, combining symptom keywords for each question and utilizing prompt engineering to create natural, patient-centred responses.
3.2.2. Interactive History-Taking
Building upon the generated patient summary and situation guidelines, we developed a simulated patient interaction module that enables realistic history-taking sessions with the virtual patient. This module leverages the capabilities of LLMs to produce dynamic and contextually appropriate patient responses during interactive dialogues with students. By incorporating the patient’s demographic information, symptomatology, emotional state, and personality traits into the system prompt, we ensured that the virtual patient responds consistently with the established profile.
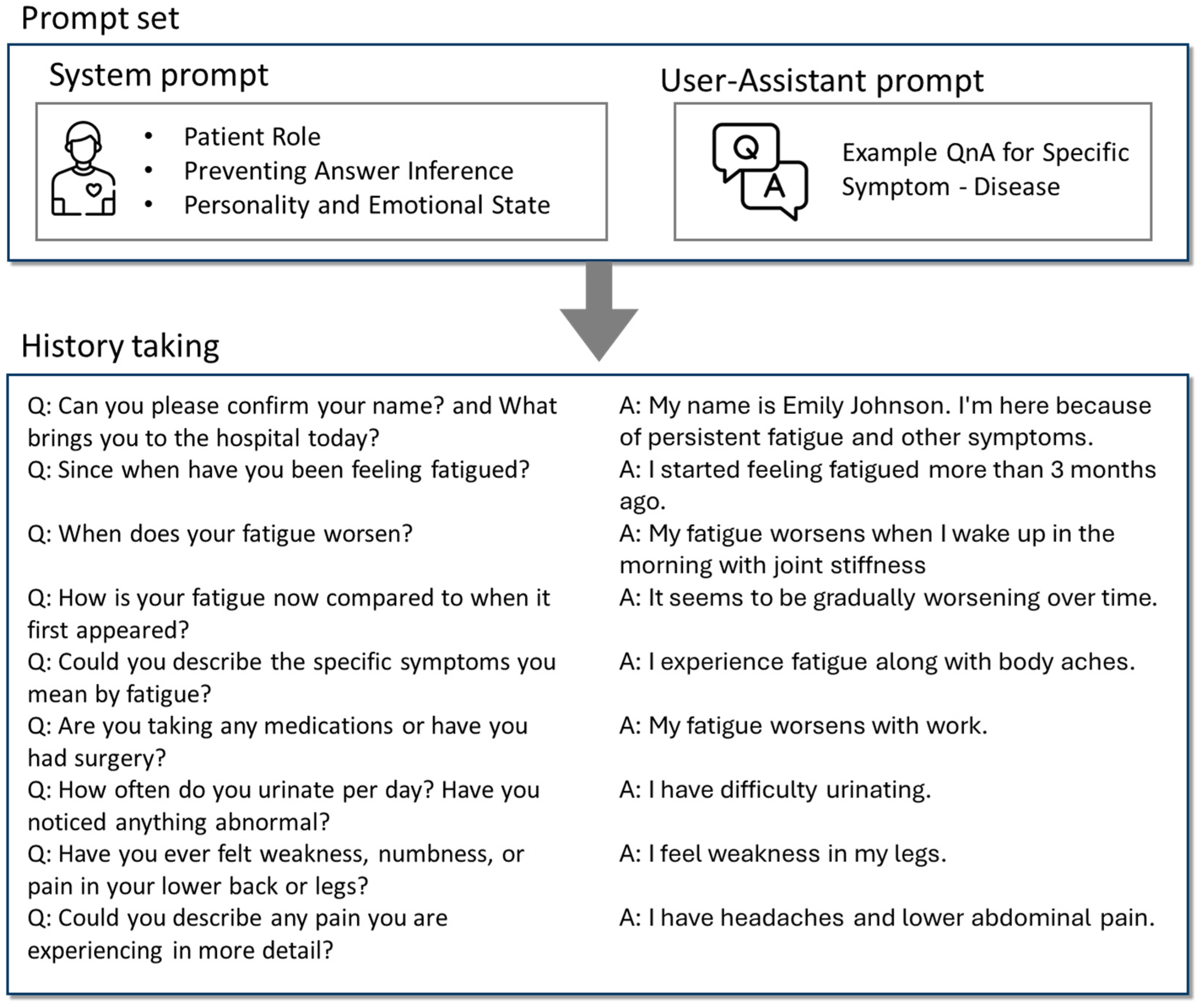
Prompt engineering was applied to guide the language model in assuming the role of the patient, ensuring that the patient’s simulated responses remained focused on the information derived from the specific disease–syndrome combination (
Figure 2). We configured the system prompt to guide the LLM in assuming the role of the patient, ensuring that the simulated patient’s responses stay focused on the information derived from the disease–syndrome combination. In addition to the system prompt, we used an assistant-user prompt to integrate the disease (fibromyalgia) and syndrome (Spleen-Qi deficiency) characteristics into the interaction. This ensures that the model generates responses that align with the previously defined symptomatology for each condition. For example, responses related to fatigue or muscle pain follow the nuances of both fibromyalgia and Spleen-Qi deficiency as per the assistant-user prompt’s structure. The virtual patient is designed to respond concisely, providing answers in the target language and avoiding the disclosure of the underlying disease or syndrome directly. The responses are contextually accurate, maintaining consistency without introducing conflicting information.
The interaction is facilitated through a dialogue loop where the student inputs questions, and the virtual patient generates appropriate responses. The conversation continues until the student decides to end the session. Throughout the interaction, the module maintains a record of the dialogue, allowing for post-session analysis and evaluation of the student’s history-taking skills and clinical reasoning. For example, when a student asks, “When did your symptoms begin?”, the virtual patient might respond, “I’ve been feeling unusually tired and achy for about three months now, and it’s been getting progressively worse”. This approach allows students to practice and refine their clinical interviewing techniques in a simulated environment that closely mirrors real-world patient interactions.
3.2.3. Evaluation of History-Taking Session
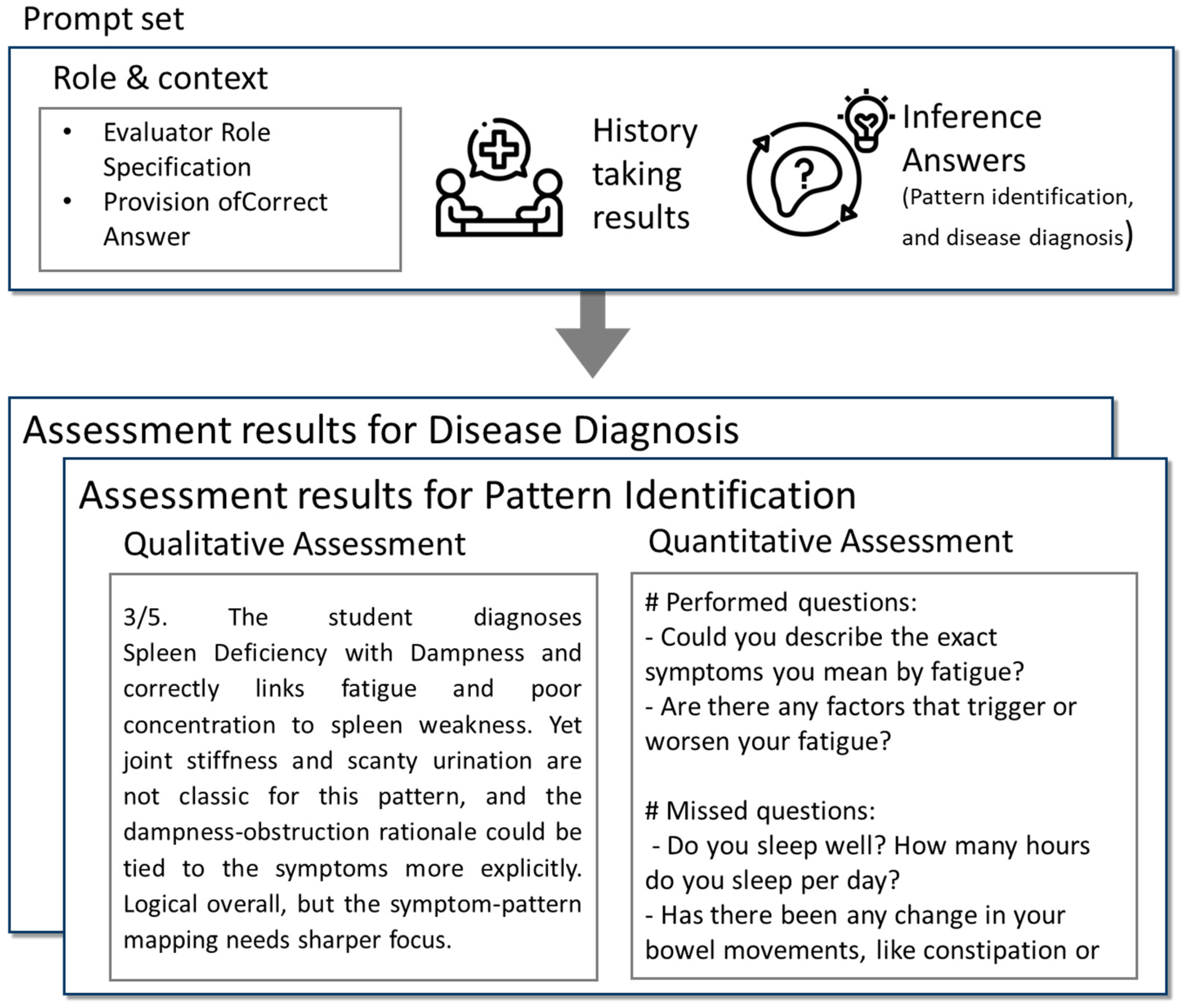
Following the interactive history-taking session, we proposed an evaluation module to assess the student’s performance in eliciting relevant clinical information and forming accurate diagnostic inferences (
Figure 3). This module analyzes the recorded dialogue between the student and the virtual patient, focusing on both the quality of the questions posed and the accuracy of the student’s diagnostic reasoning. A two-tiered evaluation approach was employed: qualitative assessment of the student’s diagnostic conclusions and quantitative analysis of the coverage of key clinical inquiries. For the qualitative assessment, students were required to infer the likely disease and syndrome based on the information gathered during the interaction. Their inferences were compared to reference answers derived from established diagnostic criteria for fibromyalgia and Spleen-Qi deficiency. This comparison evaluated the accuracy of the diagnosis, the logical coherence of their reasoning, and the inclusion of pertinent patient symptoms in their rationale. Feedback was provided to highlight strengths and suggest areas for improvement, enhancing the learning experience and promoting critical thinking. In the quantitative analysis, we compared the students’ questions to a predefined set of essential questions necessary for diagnosing both the disease and the syndrome. These ideal questions were extracted from our dataset and represented critical inquiries that a practitioner should make to reach an accurate diagnosis. The students’ dialogue was reviewed to determine the extent to which these key areas were addressed. This analysis provided a quantitative measure of the completeness and thoroughness of the history-taking process.
3.3. Prompt-Component Analysis
To assess the contribution of each prompt component to the simulated-patient module’s performance, we conducted a prompt-component contribution analysis. The objective was to determine the necessity and effectiveness of the safety prompt embedded in the system prompt and the assistant-user prompt in generating accurate, contextually appropriate patient responses. Accordingly, three conditions were tested—(i) removal of the clinical-context header (the anchoring portion of the system prompt), (ii) removal of the safety prompt within the system prompt, and (iii) removal of the assistant-user prompt—and compared them with the full-prompt baseline (
Figure 4). When the clinical-context header was omitted, generated replies quickly drifted away from the intended clinical scenario. Eliminating the safety prompt caused the model to break persona consistency and reveal the correct diagnosis prematurely. Finally, suppressing the assistant-user prompt yielded generic answers that no longer reflected syndrome-specific patterns such as those seen in fibromyalgia with Spleen-Qi deficiency. These results indicate that all three elements—the clinical-context header, safety prompt, and assistant-user prompt—are indispensable for producing realistic, educationally valuable simulations, underscoring the critical role of layered prompt engineering.
3.4. Implementation and Accessibility of Our Framework
To facilitate replication and further exploration of our knowledge-guided generative AI framework, we developed a series of Python 3.10 scripts automating each stage of the simulation process: (1) virtual patient generation (Gen_SynDi_1_generate_virtual_patient.py), (2) interactive dialogue execution (Gen_SynDi_2_dialogue_execution.py), and (3) performance evaluation (Gen_SynDi_3_evaluation.py). These user-friendly and modular scripts allow educators and researchers to implement the simulation with minimal setup. The full implementation is available at
https://github.com/wonyung-lee/Gen-SynDi, (accessed on 25 November 2024) which includes detailed instructions for setup and use. By following the steps described in the README file, users can: 1. Generate virtual patients based on specific disease–syndrome combinations; 2. Engage in simulated history-taking sessions; and 3. Receive automated evaluations of their clinical reasoning skills. The implementation leverages large language models through the OpenAI API to generate natural and contextually appropriate patient responses, providing an interactive and dynamic educational experience.
3.5. Expert Evalution
The expert evaluation of Gen-SynDi was conducted to assess its validity, educational effectiveness, and usability in the context of TAM education. The validity of Gen-SynDi as a tool for virtual patient history-taking and clinical reasoning was rated positively by the experts (
Table 2). The item “Gen-SynDi is an appropriate tool for virtual patient history-taking and clinical reasoning” received a mean score of 4.38 (SD = 0.696), and the item “Gen-SynDi includes content suitable for virtual patient history-taking and clinical reasoning” also scored 4.38 (SD = 0.696). The item evaluating the format appropriateness yielded a slightly lower but still favourable score of 4.31 (SD = 0.768). Overall, the validity category showed a strong evaluation with a mean score of 4.35 (SD = 0.721).
The educational effectiveness of Gen-SynDi was highly rated. The highest score in this category was for the item “Gen-SynDi is helpful for virtual patient history-taking and clinical reasoning”, which received a mean of 4.44 (SD = 0.704). Other items, including “Gen-SynDi is effective for training” and “Using Gen-SynDi improves competency”, received mean scores of 4.31 (SD = 0.682) and 4.38 (SD = 0.599), respectively. The total mean for educational effectiveness was 4.38 (SD = 0.665), indicating that experts perceived the tool as highly beneficial for enhancing students’ clinical reasoning skills.
In terms of usability, Gen-SynDi received moderately positive evaluations. The item “Gen-SynDi is easy for users to use” had a mean score of 4.13 (SD = 0.781), and “It is easy to find the desired features or information” received 4.06 (SD = 0.827). However, the item “Gen-SynDi does not cause users to make mistakes (e.g., operational errors)” was rated lower at 3.75 (SD = 0.901). Despite this, the overall usability score remained favourable with a mean of 3.98 (SD = 0.854), suggesting that while the system is generally user-friendly, there is room for improvement in interface clarity and error prevention.
4. Discussion
In this study, we developed a virtual patient model that integrates disease diagnosis with syndrome differentiation in Traditional Asian Medicine (TAM) education. Utilizing large language models (LLMs) and expert-guided prompt engineering, we successfully generated 28 clinically plausible virtual patient cases by combining five fatigue-associated diseases with seven TAM syndromes. The model demonstrated high proficiency in producing natural, contextually appropriate patient responses that accurately reflect both biomedical symptoms and TAM symptomatology. Through the detailed example of a patient with fibromyalgia and Spleen-Qi deficiency, we illustrated the model’s ability to create realistic clinical scenarios that facilitate comprehensive history-taking and clinical reasoning practice. The prompt-component analysis further confirmed the importance of both the system prompt and the assistant-user prompt in ensuring accurate and effective simulations. Moreover, we implemented our model in a publicly accessible format, allowing educators and practitioners to easily integrate virtual patients into their educational or clinical settings.
While previous studies have approached the use of AI in TAM education to enhance clinical training, these efforts have often been constrained by specific limitations. A previous study proposed a rule-based chatbot for Korean Medicine education, providing students with practical experience and reducing instructors’ workload [
23]. Other researchers introduced a chatbot using LLMs for Clinical Performance Examination (CPX) practice, enabling more dynamic and flexible student interactions [
24]. Additionally, we previously assessed the potential of utilizing large language models for pattern identification education by developing a virtual patient with fatigue symptoms and a dual deficiency of the heart-spleen pattern [
25]. However, these studies faced limitations such as struggling with varied question phrasing due to rule-based designs, lacking implementations for evaluating clinical reasoning, or focusing on single cases. In contrast, Gen-SynDi closes these gaps on three fronts. (1) Dual-axis case design: each of the 28 scenarios couples a Western fatigue-related disease with a high-prevalence TAM syndrome, forcing learners to integrate biomedical and pattern-identification reasoning—an ability untouched by prior chatbots. (2) Robust prompt engineering: knowledge-guided templates preserve clinical consistency across student-led dialogues, overcoming the phrase-matching rigidity of rule-based systems and the drift seen in unconstrained LLM outputs. (3) Built-in analytics: our module returns both quantitative coverage scores and qualitative reasoning feedback, then triangulates those metrics with expert ratings. Together, these features turn Gen-SynDi into a full-cycle tutor that not only simulates realistic history-taking but also measures, explains, and improves student performance—bridging the gap between traditional TAM instruction and modern competency-based medical education.
We also addressed the potential limitations of LLMs by combining expert knowledge with prompt engineering to prevent issues like hallucinations and unintended disclosure of correct answers (disease–syndrome combinations) [
26,
27]. To mitigate the risk of hallucinations—where the LLM might generate inaccurate or nonsensical information—we anchored the model’s outputs to a curated dataset based on expert knowledge [
28,
29]. This ensured that the virtual patient consistently presented clinically accurate and educationally valuable information. Building on that technical safeguard, Gen-SynDi also offers a practical alternative to the ethical challenges highlighted in recent AI-in-medical-education literature [
30,
31]: by replacing standardized-patient actors with reproducible LLM scripts, it avoids privacy-and-consent concerns, respects emerging neurorights principles, and provides an audit trail for instructors. Although it does not eliminate all ethical questions, this expert-guided, transparent design supplies a credible complementary solution and delivers 28 diverse disease-pattern scenarios at a fraction of the logistical cost of recruiting actors and multiple experts, making it a scalable and resource-efficient tutor for TAM clinical training.
The expert review offers a nuanced picture of Gen-SynDi’s current strengths and weaknesses. Validity (M = 4.35, 95 % CI 4.03–4.67) and educational effectiveness (M = 4.38, 95 % CI 4.09–4.67) were both rated “high”, supporting our claim that the 28 scenarios are clinically plausible and pedagogically valuable. By contrast, overall usability was only “moderate” (M = 3.98, 95 % CI 3.64–4.32), with free-text feedback pointing to confusing navigation labels and the absence of guardrails against accidental input errors. These findings align with prior reports that novice users find LLM-based simulators more cognitively demanding than rule-based interfaces.
Gen-SynDi has several potential limitations that frame our next research steps. Methodological transparency awaits full confirmation through independent replications; likewise, our expert panel evaluation offers only short-term evidence, with no head-to-head trials against conventional CPX or rule-based chatbots. The current case library is confined to fatigue presentations and text-only history-taking, so key differentiators such as laboratory or immunologic markers—crucial for teasing apart fibromyalgia from ME/CFS—remain outside the simulation, and cross-cultural validity has yet to be tested beyond Korean TAM nosology. Finally, while safety prompts and audit logs curb hallucinations and privacy risks, broader questions about cognitive autonomy and over-reliance on AI still warrant scrutiny. To address these limitations, a human-in-the-loop design strategy could be adopted, whereby instructors review and adjust AI-generated evaluation feedback before it is provided to learners. Alternatively, a participatory design approach could be employed, involving both instructors and learners in the development process to ensure that the AI model is co-designed in a way that preserves learners’ cognitive autonomy. Even with these constraints, Gen-SynDi is, to our knowledge, the first openly accessible tutor that pairs disease diagnosis with TAM pattern identification and automatically provides qualitative and quantitative feedback, both questioning coverage and reasoning quality, providing an affordable bridge between phenotype-based teaching and competency-based assessment. Future work will address this by integrating multimodal inputs—laboratory panels, imaging summaries, and wearable-sensor data—to create even more realistic and diagnostically challenging scenarios.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}