Abstract
In recent years, advancements in artificial intelligence (AI) have become an essential study for machine learning. The use of AI with the Robot Operating System (ROS) enables mobile robots to learn and move autonomously. Mobile robots can now be widely used in industrial and service sectors. Generally, robots have been operated on fixed paths requiring set points to function. This study utilizes Deep Q-Network (DQN) incorporating filtering to train and reward AprilTag images, paths, and obstacle avoidance. Training is conducted in a Gazebo simulation environment, and the collected data is verified on physical mobile robots. The DQN network excels in computing complex functions; AprilTag provides X, Y, Z, Pitch, Yaw, and Roll data. By employing DQN methods, recognition and path accuracy are simultaneously enhanced. The constructed DQN network can endow mobile robots with autonomous learning capabilities.
1. Introduction
As artificial intelligence technology rapidly advances, many service and industrial sectors are increasingly integrating AI systems, with the ROS (Robot Operating System) [1,2] becoming a crucial platform for applying machine learning and AI. Through the ROS, technologies such as service robots, robotic arms, disinfection robots, and logistics robots can be effectively implemented. However, traditional mobile robot systems require pre-built maps for global and local path planning [2]. When using Move base, obstacles often cause collisions, limiting the system’s flexibility. To overcome these limitations, this research has designed a self-learning mobile robot system that leverages machine learning, integrating DQN (Deep Q-Network), SLAM (Simultaneous Localization and Mapping), and AprilTag algorithms. This system allows robots to adapt to environments and navigate autonomously without the need to rebuild maps, improving mobility efficiency and accuracy while ensuring that robots can reliably reach their goals and autonomously dock for recharging [3].
Furthermore, to address the shortcomings of traditional mobile robots in complex environments, this study focuses on enhancing the robot’s autonomous decision-making capabilities through AI technology. Particularly, it enables the robot to adapt to changing environments without frequently rebuilding maps. The system integrates DQN deep reinforcement learning, allowing the robot to continuously interact with the environment for autonomous learning and route optimization, but also incorporates SLAM technology, enabling precise localization and map building in dynamic environments. The AprilTag algorithm further enhances the accuracy and stability of marker recognition, ensuring the robot can navigate and dock for charging in complex environments. Additionally, by combining image recognition and radar-based obstacle avoidance training, the robot gains stronger environmental awareness and autonomous obstacle avoidance capabilities, significantly boosting the intelligence level of mobile robots and making them perform better in diverse application scenarios.
Beyond these technological integrations, this research also focuses on developing a comprehensive hardware and software architecture to support these advanced machine learning and AI technologies. On the hardware side, high-performance processors and various sensors, including cameras, radars, and IMUs (Inertial Measurement Units), are employed to ensure the robot can accurately perceive its surroundings and perform complex computations. The data from these sensors are integrated into the ROS framework, enabling real-time map construction and localization through SLAM [3], and allowing the robot to navigate autonomously. The software architecture adopts a modular design, facilitating future expansions and upgrades. For example, the results of DQN algorithm training can be transmitted and applied through ROS, not only accelerating the deployment of machine learning models but also allowing the system to flexibly adjust when faced with different tasks [4].
Additionally, to meet the demands of various application scenarios, this research explores multiple potential applications, such as in service robots, enabling them to autonomously navigate complex and dynamically changing indoor environments, or in industrial robots, to enhance the efficiency and accuracy of automated production lines. These applications demonstrate the system’s broad applicability and potential, contributing to the advancement of robotics technology and providing technical support for the development of future smart factories and intelligent homes. Ultimately, these efforts aim to create a more thoughtful, efficient, and reliable robotic system capable of playing a crucial role in various complex real-world applications [5].
2. Deep Q-Network Methodology
2.1. Localization and Differential Wheel Control
Navigation technology and machine learning have rapidly developed in recent years. The most common kinematics model for mobile robots is differential control, as depicted in Figure 1. The equations for differential control, centered on the two-wheel axis, are shown in (1)–(3). The distance from the center of the arc motion trajectory to the wheel centers is described by Equations (4)–(6), accomplished through odometry and Map–Server synchronization. The motion equations translate odometry data to the robot’s coordinates, as shown in Equation (5).
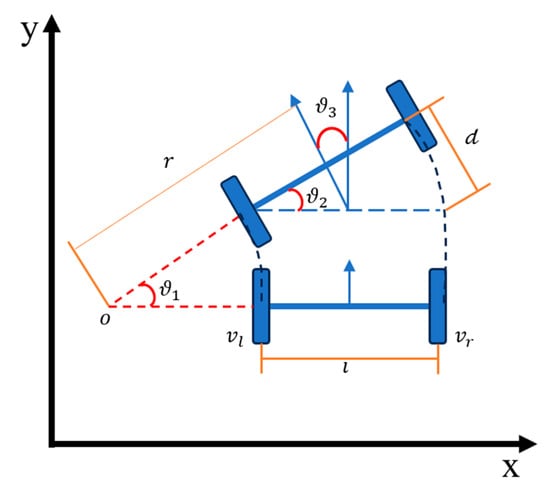
Figure 1.
Differential control.
Current SLAM technologies heavily rely on cameras and LiDAR sensors for environmental perception and map construction. Common mapping methods include Hector SLAM, Gmapping SLAM, Cartographer SLAM, and ORB-SLAM, with ORB-SLAM specifically designed for visual SLAM. Self-localization techniques, such as odometry, accumulate positional data using wheel encoders [6,7]. For navigation and localization, Adaptive Monte Carlo Localization (AMCL) is a widely adopted approach that utilizes particle filtering to estimate the robot’s pose by maintaining and updating a set of weighted particles representing possible locations. The AMCL algorithm dynamically adjusts the number of particles based on localization uncertainty, refining the robot’s pose estimation. Moreover, LiDAR sensors improve localization accuracy by offering high-resolution environmental perception.
Path tracking and stabilization are crucial for ensuring the accuracy and efficiency of autonomous navigation. The authors of [8] demonstrated that an effective path-tracking algorithm significantly improves the stability and accuracy of autonomous guided vehicles (AGVs). This study integrates machine learning with Monte Carlo Localization (MCL), along with the Deep Q Network (DQN) algorithm, to enhance the robot’s trajectory refinement and navigation precision. Specifically, MCL provides a probabilistic estimation of the robot’s pose, ensuring a stable localization foundation, while the DQN model learns optimal navigation strategies based on input velocity and angular adjustments. By combining probabilistic inference with reinforcement learning-based decision-making strategies, this approach effectively enhances the robot’s trajectory tracking and navigation accuracy.
The robot’s average speed. and are the speeds of the right and left wheels respectively. By adding the speeds of the two wheels and dividing by 2, we obtain the robot’s average speed.
The difference in speed between the two wheels is related to the robot’s wheelbase (the distance between the two wheels). w is the robot’s angular velocity, and l is the robot’s wheelbase. This formula indicates that the greater the difference in speed between the two wheels, the greater the robot’s angular velocity.
The robot’s turning radius. The turning radius is equal to the ratio of the robot’s average speed to its angular velocity. When the speeds of the right and left wheels are different, the robot moves along an arc, and the radius of this arc is the turning radius.
The robot’s turning radius . The turning radius is equal to the ratio of the robot’s average speed to its angular velocity. When the speeds of the right and left wheels are different, the robot moves along an arc, and the radius of this arc is the turning radius.
The robot’s displacement in the x and y directions are described below, where is the robot’s forward speed, is the current direction angle, and Δt is the time step. By calculating the component of v in the x and y directions and multiplying it by the time step, the new x and y coordinates are obtained as in (5) and (6). Here, and represent the robot’s previous positions in the x and y directions, respectively. These terms are crucial for calculating the updated position, ensuring the continuity of the robot’s trajectory.
Also, the robot’s direction angle is described in (7), where is the current direction angle, is the robot’s angular velocity, and Δt is the time step. By multiplying the angular velocity by the time step, the change in the direction angle is obtained, and the robot’s direction angle is updated.
2.2. Q-Learning
Q-Learning, as shown in Figure 2, guides machine learning to select the best path based on the current state (such as the target position of the field). This selection is based on a reward called “Q-value”, which represents a certain value under a specific state; the goal of the algorithm is to maximize the overall reward (Q value) and learn the best action strategy [9]. Q Learning is a value-based reinforcement learning method. Its core is to learn a value function Q(s, a) that represents the expected future reward for acting in state s, as in (8), which shows the formula Q(s, a) for obtaining the updated value of Q for Q-Learning; the individual meanings are shown in Table 1 [10,11,12,13,14].
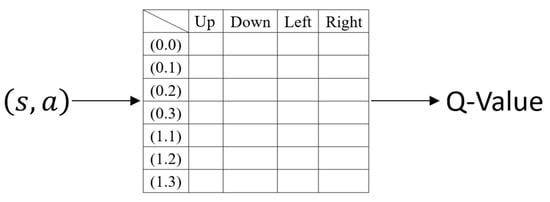
Figure 2.
Q-Learning.

Table 1.
Q-Learning individual meanings.
2.3. DQN (Deep Q-Network)
The Deep Q-Network (DQN) extends traditional Q-learning by leveraging deep learning to approximate the Q-value function, allowing it to handle high-dimensional state spaces more effectively. As illustrated in Figure 3, Q-learning becomes computationally impractical in large state spaces due to excessive memory requirements for storing Q-values. DQN addresses this limitation by integrating deep neural networks, experience replay, and a fixed target network, which together enhance training stability and improve convergence efficiency. In the DQN framework [13], two neural networks are utilized: an online network, which continuously updates based on training data, and a fixed target network, which is used to estimate the Q-value formula. The target network undergoes periodic updates to reduce instability and prevent oscillations as shown in Table 2. The DQN model receives the current environmental state as input and outputs the Q-value associated with each possible action in that state. The action with the highest Q-value is selected, forming the basis of the decision-making process. A key component of DQN is the experience replay mechanism, which helps address the instability of Q-learning. Unlike standard Q-learning, which updates the neural network using only the most recent experience, DQN stores past experiences in a memory buffer and randomly samples batches for training, breaking data correlation and improving learning stability. By incorporating these enhancements, DQN is effectively applied to path determination in robotics, enabling autonomous mobile robots to learn navigation behaviors through reinforcement learning. Recent studies have demonstrated the feasibility of integrating deep neural networks into robotic navigation systems, optimizing real-time decision-making in ROS-based platforms [14]. Additionally, multi-task convolutional neural networks have been explored to enhance advanced driving assistance by embedding spatial coordinate data for robust inference [15]. Before deployment, the AMR undergoes extensive training in a simulated environment, where it explores its surroundings and learns optimal actions based on a reward function. The performance of the trained model is evaluated based on the robot’s ability to navigate toward a target location while avoiding obstacles. This approach allows the AMR to autonomously select the most efficient actions based on a DQN-based scoring system, enhancing its ability to avoid obstacles and precisely reach charging stations [16].
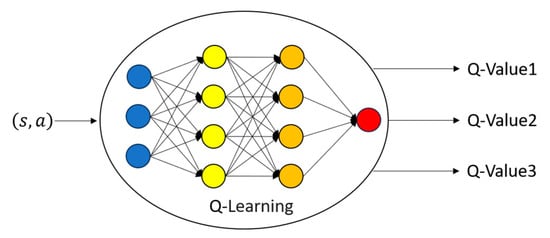
Figure 3.
Deep Q-Network model architecture.
Table 2.
DQN individual meanings.
Although alternative reinforcement learning (RL) approaches, such as Proximal Policy Optimization (PPO), Soft Actor-Critic (SAC), and Deep Deterministic Policy Gradient (DDPG), have been widely applied in robotic control, DQN was selected for this study due to several key advantages. First, DQN is inherently designed for discrete action spaces, making it particularly suitable for AMR docking and path planning tasks, where the robot selects from a predefined set of movement actions. In contrast, PPO, SAC, and DDPG are primarily designed for continuous control problems, requiring additional modifications, such as action discretization, which can introduce unnecessary complexity and reduce training efficiency. Second, DQN is computationally efficient for real-time applications. Unlike policy gradient methods (e.g., PPO, SAC), which require extensive sampling and concurrent optimization of actor and critic networks, DQN adopts a value-based learning approach, reducing computational overhead and making it more feasible for real-time control scenarios and embedded robotic systems. Finally, DQN has demonstrated proven effectiveness in robotic navigation. The results of this study confirm that DQN successfully enables AMRs to perform docking and obstacle avoidance, reinforcing its suitability for mobile robotics. While DQN performed effectively in this study, it is acknowledged that alternative RL methods, such as PPO, SAC, and DDPG, may offer advantages in specific scenarios. Future research will focus on conducting a comparative analysis of these RL algorithms to assess their effectiveness in AMR docking and navigation tasks. This comparative evaluation will provide deeper insights into the trade-offs between value-based and policy-based reinforcement learning approaches, contributing to further advancements in autonomous robotics applications [17].
2.4. AprilTag
As shown in Figure 4, AprilTag is an open-source visual positioning system developed by the April Laboratory at Michigan State University. It uses QR-code-like markers for precise spatial localization and is widely applied in autonomous mobile robots, drone navigation, and robotic applications. By enabling coordinate transformation between the world and camera coordinate systems, AprilTag enhances a robot’s ability to perceive its environment with high accuracy. In this study, AprilTag has been modified and integrated to support full-field self-localization, providing six-degrees-of-freedom (6-DoF) pose estimation, including X, Y, and Z coordinates, as well as Pitch, Yaw, and Roll angles. Each tag contains a unique ID, allowing dual verification to ensure robust recognition, high reliability, and improved accuracy. With this 3D pose information, autonomous robots can execute precise docking maneuvers with enhanced positioning.

Figure 4.
Tag36h11 of AprilTa.
Furthermore, visual servoing techniques play a key role in improving localization and navigation accuracy. Who developed a tracking system incorporating visual servoing, this study integrates AprilTag to enhance 3D pose estimation and docking precision. During detection, the system calculates the relative position and orientation between the tag and the camera. As illustrated in Figure 5, it determines the spatial distance and three-dimensional coordinates of the tag relative to the camera. Additionally, since AprilTag encodes two-dimensional marker data, it enables precise computation of rotation angles for both the tag and the camera, further enhancing localization accuracy and system robustness.
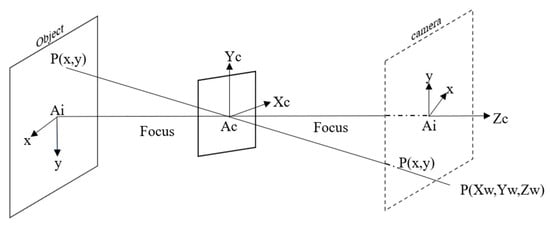
Figure 5.
Camera projection principle.
3. Autonomous Mobile Robot Design
In this section, we introduce the autonomous mobile robot (AMR) design concept. It will first describe the hardware architecture and the software based on the Robot Operating System (ROS). Each has a core layer and application layer, which will be introduced below. Finally, the detailed process of the AI path is introduced [18,19,20,21].
3.1. Design Idea
The AMR is designed to be lightweight and fast-moving, ensuring that the machine remains compact enough to navigate through narrow spaces while quickly reaching its target location. While in motion, the Velodyne VLP-16 LiDAR facilitates high-resolution mapping and real-time obstacle detection. With its autonomous decision-making capability, the AMR can efficiently avoid obstacles when encountered. Additionally, the CMP10A IMU helps to reduce drift errors in dead reckoning, enhancing motion tracking accuracy. The Realsense D435 RGB-D Camera is installed for AprilTag recognition, ensuring precise self-localization and repositioning [22].
3.2. Hardware Architecture
As shown in Figure 6, the AMR has a length, width, and height of 40 cm. The RGB-D Realsense D435 camera is used for tag recognition, enabling precise self-localization. A CMP10A-IMU, positioned on the left side of the Velodyne VLP-16, helps eliminate movement errors and improves motion accuracy. The chassis features a differential wheel motion system and a 150-watt servo drive, ensuring smooth and continuous operation. A removable 24 V/36 Ah battery allows the robot to operate for up to 8 h, enhancing its practicality and endurance. To achieve high-precision mobility, the Velodyne VLP-16 LiDAR provides 16 laser beams, a detection range of up to 100 m, and a scanning rate of 300,000 points per second, ensuring detailed mapping and obstacle detection. For enhanced safety, three ultrasonic sensors are installed at the bottom of the robot. When an obstacle is detected, the robot will automatically stop and resume route planning once the obstacle is cleared. Additionally, an emergency stop button is installed, allowing immediate power cutoff to the motor in case of an emergency, ensuring that the AMR stops movement instantly to prevent potential hazards.
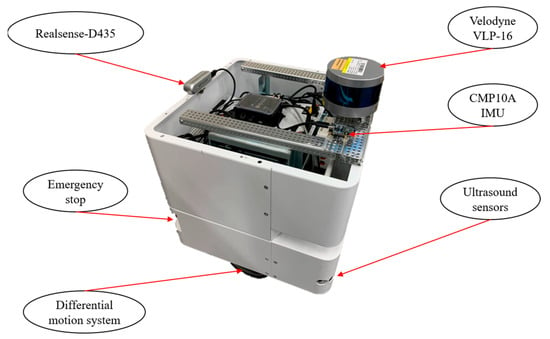
Figure 6.
Autonomous mobile robot platform.
3.3. Software Architecture
The software design architecture of the AMR is based on ROS (Robot Operating System) communication and consists of three main layers: the drive layer, the control layer, and the application layer. As shown in Figure 7, the drive layer is responsible for handling the robot’s hardware actuation and sensory input, including the DC servo, which controls the movement of the wheels, the camera for perception and object recognition such as AprilTag identification, the BMS (Battery Management System) for power distribution and battery monitoring, and the 3D laser and ultrasonic sensors, where the Velodyne VLP-16 LiDAR provides high-resolution 3D mapping and obstacle detection, while ultrasonic sensors enhance close-range safety by stopping the robot when obstacles are detected. The control layer is responsible for decision-making, navigation, and adaptive control, integrating multiple algorithms to enhance autonomy. It includes AMCL (Adaptive Monte Carlo Localization) and Deep Q Network (DQN), where AMCL enables probabilistic localization within a map, and DQN optimizes navigation and path planning through reinforcement learning. The AprilTag docking module utilizes the Realsense D435 RGB-D Camera for AprilTag recognition, enabling precise docking and positioning. Additionally, the adaptive motion controller adjusts the robot’s movement based on environmental feedback, improving stability and responsiveness. The ROS application layer serves as the communication backbone, facilitating real-time data exchange between the drive and control layers, ensuring seamless operation of the robotic system. The overall architecture ensures that the AMR can efficiently navigate, avoid obstacles, and accurately dock using AprilTags, making it well-suited for autonomous operations in dynamic environments.
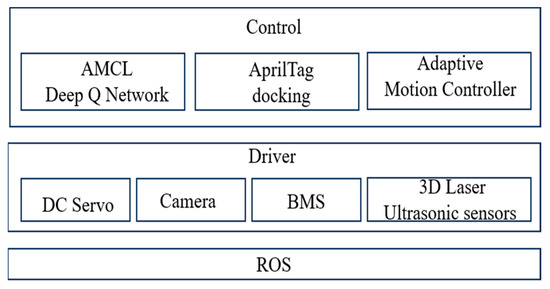
Figure 7.
Software design architecture.
3.4. The Training Scenarios
To verify the robot training results, we conducted a total of six experiments with different training iterations: untrained (0 iterations), 100 iterations, 200 iterations, 300 iterations, 400 iterations, and 500 iterations. The simulated training was designed in a sandbox environment, as shown in Figure 8 [17]. This approach prevents potential damage to the physical robot during the training process. Therefore, the TurtleBot3 in the Gazebo environment was used for training. Once the training achieves satisfactory performance, the results can be applied to the physical robot for validation [23].

Figure 8.
The Turtlebot in the Gazebo simulation environment.
4. Experiments
4.1. Results of Training with 32 Neurons
The training scenario using 32 neurons is shown in Figure 9. Initially, without prior training, the system underwent 250 iterations, during which the DQN failed to process input parameters 95 times due to the lack of prior experience. Afterward, 500 successful training iterations were fed into the DQN, and the model was retrained accordingly. As a result, the initial 500 failures were significantly reduced to only 10 failures. These findings indicate that incorporating more successful training data helps reduce failure rates and optimize execution time. As shown in Figure 10, experimental verification demonstrated that 500 training iterations were sufficient to achieve a stable success rate, as shown in Figure 11.
Figure 9.
Scene for 32 neurons.
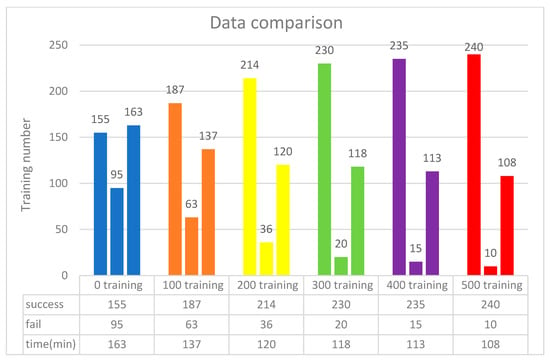
Figure 10.
Data integration for 32 neurons.
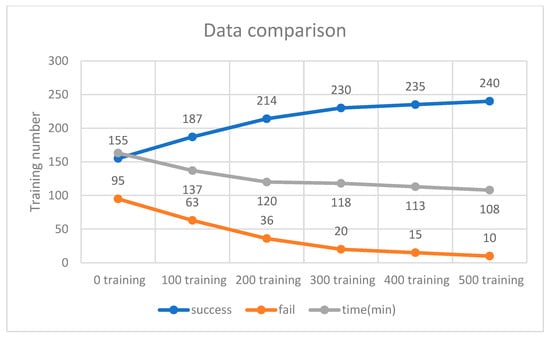
Figure 11.
Success and failure rates for 32 neurons.
4.2. Results of Training with 50 Neurons
The training scenario using 50 neurons is shown in Figure 12. Initially, without prior training, the system underwent 250 iterations, during which the DQN failed to process input parameters 34 times due to the lack of prior experience. Afterward, 500 successful training iterations were fed into the DQN, and the model was retrained accordingly. As a result, the initial 500 failures were significantly reduced to just one. These findings indicate that incorporating more successful training data helps minimize failure rates and optimize execution time. As shown in Figure 13, experimental verification demonstrated that 500 training iterations were sufficient to achieve a stable success rate, as shown in Figure 14.

Figure 12.
Scene for 50 neurons.
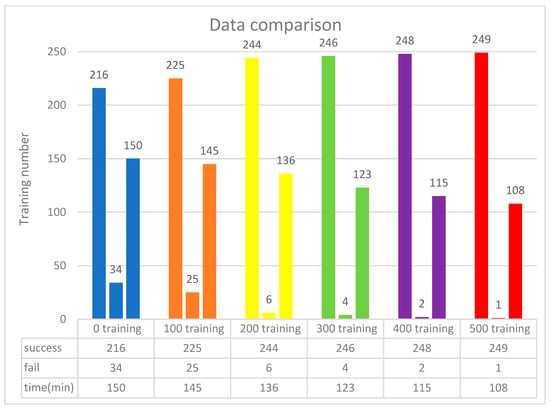
Figure 13.
Data integration for 50 neurons.
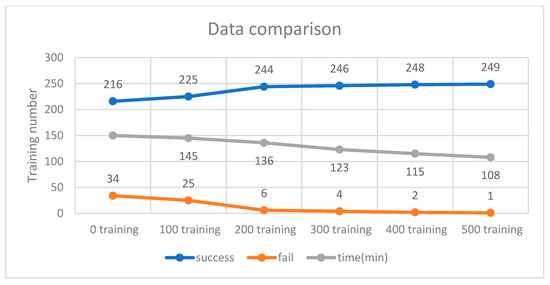
Figure 14.
Success and failure rates for 50 neurons.
4.3. Results of Training with 64 Neurons
The training scenario using 64 neurons is shown in Figure 15. Initially, without prior training, the system underwent 250 iterations, during which the DQN failed to process input parameters 170 times due to the lack of prior experience. Subsequently, 500 successful training iterations were fed into the DQN, and the model was retrained accordingly. As a result, the initial 500 failures were significantly reduced to just one. These findings indicate that incorporating more successful training data minimizes failure rates and optimizes execution time. As shown in Figure 16, experimental verification demonstrated that 500 training iterations were sufficient to achieve a stable success rate, as shown in Figure 17.

Figure 15.
Scene for 64 neurons.
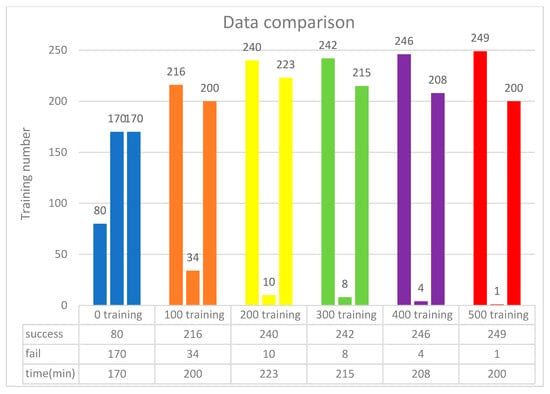
Figure 16.
Data integration for 64 neurons.
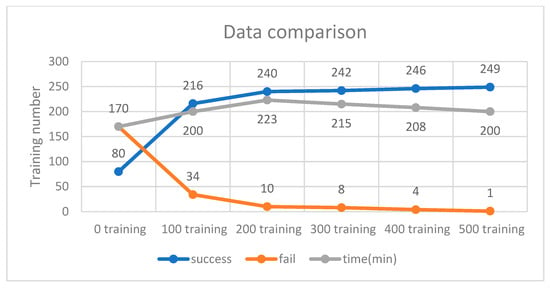
Figure 17.
Success and failure rates for 64 neurons.
4.4. Simulation Experiment Results
After training with 32, 50, and 64 neurons for 500 iterations each, a comparison was conducted. The results indicated that all training configurations achieved success rates exceeding 95%. However, the 32-neuron model recorded 10 failures, whereas both the 50-neuron and 64-neuron models had only one failure. This suggests that the 50-neuron and 64-neuron models outperformed the 32-neuron model. Additionally, the 50-neuron model required significantly less training time compared to the 64-neuron model. Therefore, the 50-neuron model demonstrated the highest success rate with the shortest training duration, as shown in Table 3. Figure 18 illustrates that incorporating filtering during the training process resulted in a smoother performance after 160 iterations, thereby enhancing training accuracy.
Table 3.
Experimental results.
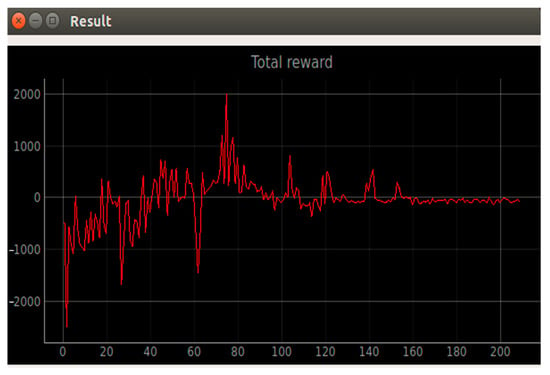
Figure 18.
Reward data.
4.5. Real Robot Experiment Results
In this experiment, it was found that after 500 iterations of training, the learning effect was better, and the training data was input into the DQN model of the real robot. In actual situations, the robot first uses a camera to detect the direction of AprilTag and then moves to the middle position. If it encounters an obstacle during the movement, it will stop first and then avoid the obstacle. After completely avoiding the obstacle, it will return to the middle. The seat completes the docking action, and then the robot moves steadily and continuously towards AprilTag, as shown in Figure 19, Figure 20, Figure 21, Figure 22 and Figure 23.

Figure 19.
Obstacle in path toward AprilTag.

Figure 20.
Initial direction of the AprilTag.

Figure 21.
When avoiding obstacles.

Figure 22.
Successful obstacle avoidance.

Figure 23.
Robot docking completed via DQN.
5. Conclusions
The main contribution of this study is the use of AprilTag and DQN reinforcement learning to replace traditional docking algorithms. In general robot docking control, rules, features, or landmarks are used along with tuning parameters for optimal control. However, if the robot’s parameters are not correctly adjusted, docking may fail, or recognition may be inaccurate. Therefore, we utilized the DQN machine learning method to enable human-like control behavior, allowing the robot to perform docking more accurately and naturally. However, DQN reinforcement learning requires a large amount of training data, which is time-consuming and costly to collect in real-world scenarios. To overcome this challenge, we applied the Gazebo robot simulation environment as a sandbox for pretraining. Relative pose information was obtained from AprilTag and laser data, and DQN was used for autonomous training in path planning. By configuring environment size, speed, and angular velocity, the robot was able to learn autonomously using the DQN method. Experimental results demonstrated that setting 50 neurons was sufficient to achieve docking and obstacle avoidance with excellent performance. Although DQN performed well in our study, we acknowledge that other reinforcement learning (RL) methods, such as Proximal Policy Optimization (PPO), Soft Actor-Critic (SAC), and Deep Deterministic Policy Gradient (DDPG), were not compared [24,25,26]. While DQN is suitable for discrete action spaces and provides computational efficiency, future work will explore a comparative study to assess the trade-offs between DQN and other RL approaches. This will provide a more comprehensive understanding of the effectiveness of different RL techniques in autonomous mobile robot navigation and docking.
Author Contributions
Conceptualization, C.-C.L.; methodology, C.-C.L.; software, B.-J.Y.; validation, B.-J.Y.; formal analysis, B.-J.Y.; investigation, B.-J.Y.; resources, B.-J.Y.; data curation, B.-J.Y.; writing—original draft preparation, B.-J.Y.; writing—review and editing, B.-J.Y. and C.-J.L.; visualization, B.-J.Y. and C.-J.L.; supervision, B.-J.Y. and C.-J.L.; project administration, C.-C.L. All authors have read and agreed to the published version of the manuscript.
Funding
The authors conducted this study without financial support from external organizations or funding agencies.
Data Availability Statement
The original contributions presented in this study are included in the article; further inquiries can be directed to the corresponding author.
Acknowledgments
We acknowledge Chia-Nan Ko and Kuo-Hsien Hsia for their assistance with the experiments.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, C.S.; Lin, C.J.; Lai, C.C. Non-Contact Service Robot Development in Fast-Food Restaurants. IEEE Access 2022, 10, 31466–31479. [Google Scholar] [CrossRef]
- Yan, C.; Chen, G.; Li, Y.; Sun, F.; Wu, Y. Immune Deep Reinforcement Learning-Based Path Planning for Mobile Robot in Unknown Environment. Appl. Soft Comput. 2023, 145, 110601. [Google Scholar] [CrossRef]
- Bailey, T.; Nieto, J.; Guivant, J.; Stevens, M.; Nebot, E. Consistency of the EKF-SLAM Algorithm. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Beijing, China, 9–15 October 2006; pp. 3562–3568. [Google Scholar] [CrossRef]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Da Silva, B.M.F.; Xavier, R.S.; Do Nascimento, T.P.; Goncalves, L.M.G. Experimental Evaluation of ROS-Compatible SLAM Algorithms for RGB-D Sensors. In Proceedings of the Latin American Robotics Symposium (LARS), Curitiba, Brazil, 6–10 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, F.; Wu, G. Distributed Error Correction of EKF Algorithm in Multisensory Fusion Localization Model. IEEE Access 2020, 8, 93211–93218. [Google Scholar] [CrossRef]
- Sinisa, M. Evaluation of SLAM Methods and Adaptive Monte Carlo Localization. Doctoral Dissertation, Vienna University of Technology, Vienna, Austria, 2022. Available online: https://api.semanticscholar.org/CorpusID:251380609 (accessed on 20 January 2025).
- Lee, D.; Lee, S.-J.; Seo, Y.-J. Application of Recent Developments in Deep Learning to ANN-based Automatic Berthing Systems.International. J. Eng. Technol. Innov. 2020, 10, 75–90. [Google Scholar] [CrossRef]
- Yang, Y.; Li, J.; Peng, L. Multi-Robot Path Planning Based on a Deep Reinforcement Learning DQN Algorithm. CAAI Trans. Intell. Technol. 2020, 5, 177–183. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Badia, A.P.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Piot, B.; Kapturowski, S.; Tieleman, O.; Arjovsky, M.; Pritzel, A.; Bolt, A.; et al. Never Give Up: Learning Directed Exploration Strategies. arXiv 2020, arXiv:2002.06038. [Google Scholar]
- Zong, L.; Yu, Y.; Wang, J.; Liu, P.; Feng, W.; Dai, X.; Chen, L.; Gunawan, C.; Yun, S.J.; Amal, R.; et al. Oxygen-Vacancy-Rich Molybdenum Carbide MXene Nanonetworks for Ultrasound-Triggered and Capturing-Enhanced Sonocatalytic Bacteria Eradication. Biomaterials 2023, 296, 122074. [Google Scholar] [CrossRef] [PubMed]
- Sivaranjani, A.; Vinod, B. Artificial Potential Field Incorporated Deep-Q-Network Algorithm for Mobile Robot Path Prediction. Intell. Autom. Soft Comput. 2023, 35, 1135–1150. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, Z.; Wu, J.; Chen, Q.; Wang, F. Lightweight Intelligent Autonomous Unmanned Vehicle Based on Deep Neural Network in ROS System. In Proceedings of the 2022 IEEE 5th International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 23–25 September 2022; Volume 10, pp. 679–684. [Google Scholar] [CrossRef]
- Miyama, M. Robust Inference of Multi-Task Convolutional Neural Network for Advanced Driving Assistance by Embedding Coordinates. In Proceedings of the 8th World Congress on Electrical Engineering and Computer Systems and Science (EECSS), Prague, Czech Republic, 28–30 July 2022; pp. 105-1–105-9. Available online: https://api.semanticscholar.org/CorpusID:251856335 (accessed on 6 March 2025).
- Jebbar, M.; Maizate, A.; Abdelouahid, R.A. Moroccan’s Arabic Speech Training and Deploying Machine Learning Models with Teachable Machine. Procedia Comput. Sci. 2022, 203, 801–806. [Google Scholar] [CrossRef]
- Copot, C.; Shi, L.; Smet, E.; Ionescu, C.; Vanlanduit, S. Comparison of Deep Learning Models in Position-Based Visual Servoing. In Proceedings of the 2022 IEEE 27th International Conference on Emerging Technologies and Factory Automation (ETFA), Stuttgart, Germany, 6–9 September 2022; Volume 10, pp. 1–4. [Google Scholar] [CrossRef]
- Liu, J.; Rangwala, M.; Ahluwalia, K.; Ghajar, S.; Dhami, H.; Tokekar, P.; Tracy, B.; Williams, R. Intermittent Deployment for Large-Scale Multi-Robot Forage Perception: Data Synthesis, Prediction, and Planning. IEEE Trans. Autom. Sci. Eng. 2022, 21, 27–47. Available online: https://ieeexplore.ieee.org/document/9923747 (accessed on 6 March 2025). [CrossRef]
- Lai, J.; Ramli, H.; Ismail, L.; Hasan, W. Real-Time Detection of Ripe Oil Palm Fresh Fruit Bunch Based on YOLOv4. IEEE Access 2022, 10, 95763–95770. [Google Scholar] [CrossRef]
- Lin, H.Z.; Chen, H.H.; Choophutthakan, K.; Li, C.H. Autonomous Mobile Robot as a Cyber-Physical System Featuring Networked Deep Learning and Control. In Proceedings of the 2022 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Sapporo, Japan, 11–15 July 2022; Volume 10, pp. 268–274. [Google Scholar] [CrossRef]
- Mandel, N.; Sandino, J.; Galvez-Serna, J.; Vanegas, F.; Milford, M.; Gonzalez, F. Resolution-Adaptive Quadtrees for Semantic Segmentation Mapping in UAV Applications. In Proceedings of the 2022 IEEE Aerospace Conference (AERO), Big Sky, MT, USA, 5–12 March 2022; pp. 1–17. [Google Scholar] [CrossRef]
- Chen, Y.; Li, D.; Zhong, H.; Zhao, R. The Method for Automatic Adjustment of AGV’s PID Based on Deep Reinforcement Learning. J. Phys. Conf. Ser. 2022, 2320, 012008. [Google Scholar] [CrossRef]
- Chen, S.-L.; Huang, L.-W. Using Deep Learning Technology to Realize the Automatic Control Program of Robot Arm Based on Hand Gesture Recognition. Int. J. Eng. Technol. Innov. 2021, 11, 241–250. [Google Scholar] [CrossRef]
- Yin, Y.; Chen, Z.; Liu, G.; Guo, J. Mapless Local Path Planning Approach Using Deep Reinforcement Learning Framework. Sensors 2023, 23, 2036. [Google Scholar] [CrossRef] [PubMed]
- Escobar-Naranjo, J.; Caiza, G.; Ayala, P.; Jordan, E.; Garcia, C.A.; Garcia, M.V. Autonomous Navigation of Robots: Optimization with DQN. Appl. Sci. 2023, 13, 7202. [Google Scholar] [CrossRef]
- Li, J.; Chavez-Galaviz, J.; Azizzadenesheli, K.; Mahmoudian, N. Obstacle Avoidance for USVs Using Cross-Domain Deep Reinforcement Learning and Neural Network Model Predictive Controller. Sensors 2023, 23, 3572. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).