
Advanced Default Risk Prediction in Small and Medum-Sized Enterprises Using Large Language Models


Abstract
1. Introduction
- Innovating an indicator system: This study engages with company bill default data and emphasizes non-financial data, such as registration information, legal documentation, and sentiment assessed in news articles. This approach helps us to formulate a new barometer for risk assessment.
- Evaluating the effectiveness of different data standardization techniques: This study explores the impact of three unique data standardization methods on the experimental outcomes, offering new insights for enterprise risk analysis. Identifying the most suitable standardization technique to optimize the model represents an innovative addition to the research.
- Incorporating large language models: Our cutting-edge combination of large language model prompts into company credit risk assessment offers a novel research perspective. This serves as an innovative approach towards corporate risk prediction.
2. Related Work
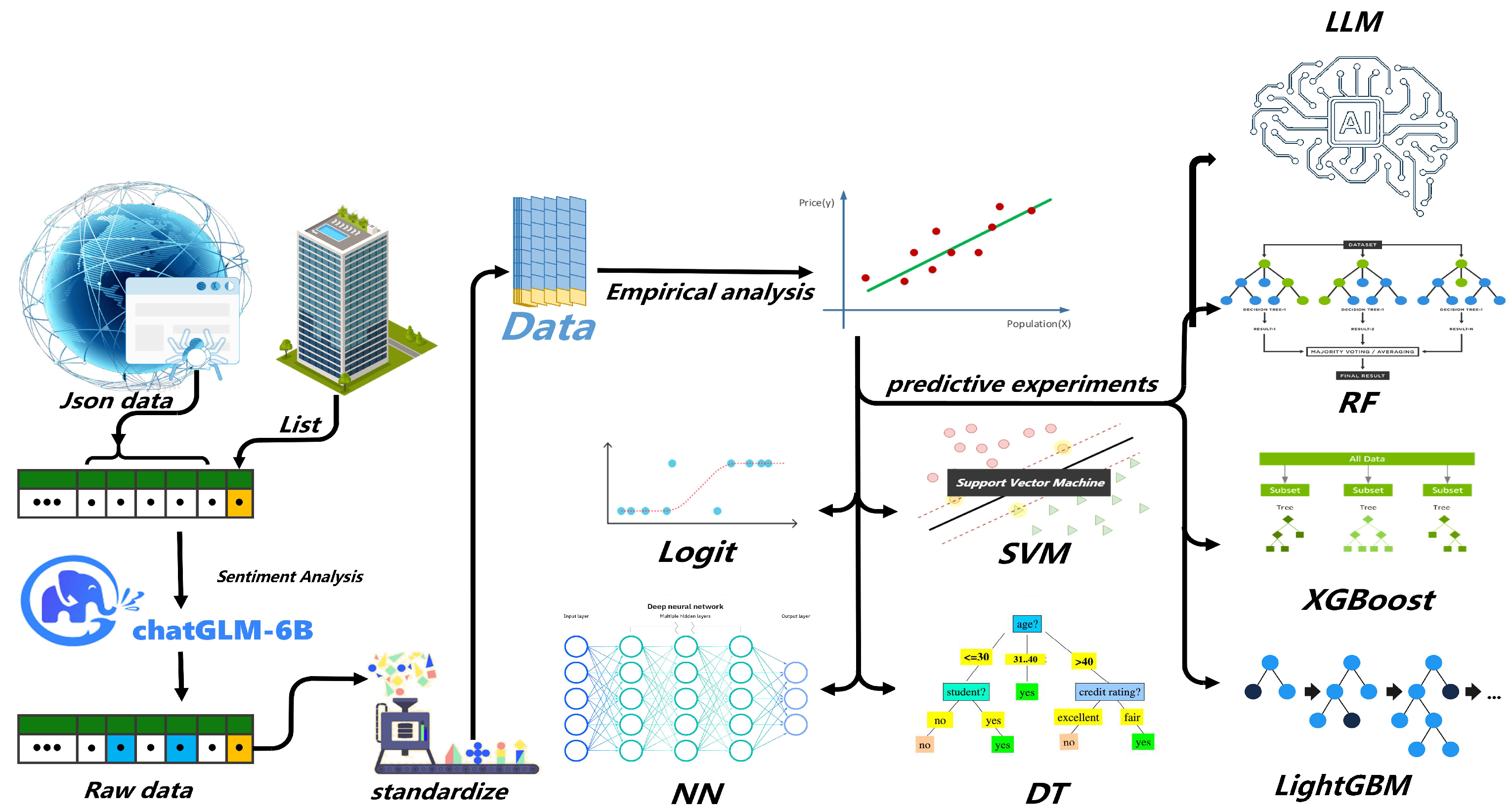
3. Dataset and Methods
3.1. Dataset
3.1.1. Data Types and Sources
Commercial Paper Data
Corporate Business Data
Judicial Document Data
Corporate News Data
3.1.2. Data Processing
Data Format Transformation
Data Normalization Process
- MinMax ScalingThis method scales features to a specified range, usually between 0 and 1. It is suitable when features have similar ranges or when a specific range is required.
- Z-Score NormalizationThis method adjusts data to be centered at zero with a standard deviation of one. It is useful for models sensitive to input scales, allowing each feature to have equal influence in distance calculations.
- Log ScalingLog transformation reduces data skewness and mitigates the effects of outliers, making the data distribution more symmetric. It is particularly effective for data spanning multiple orders of magnitude.
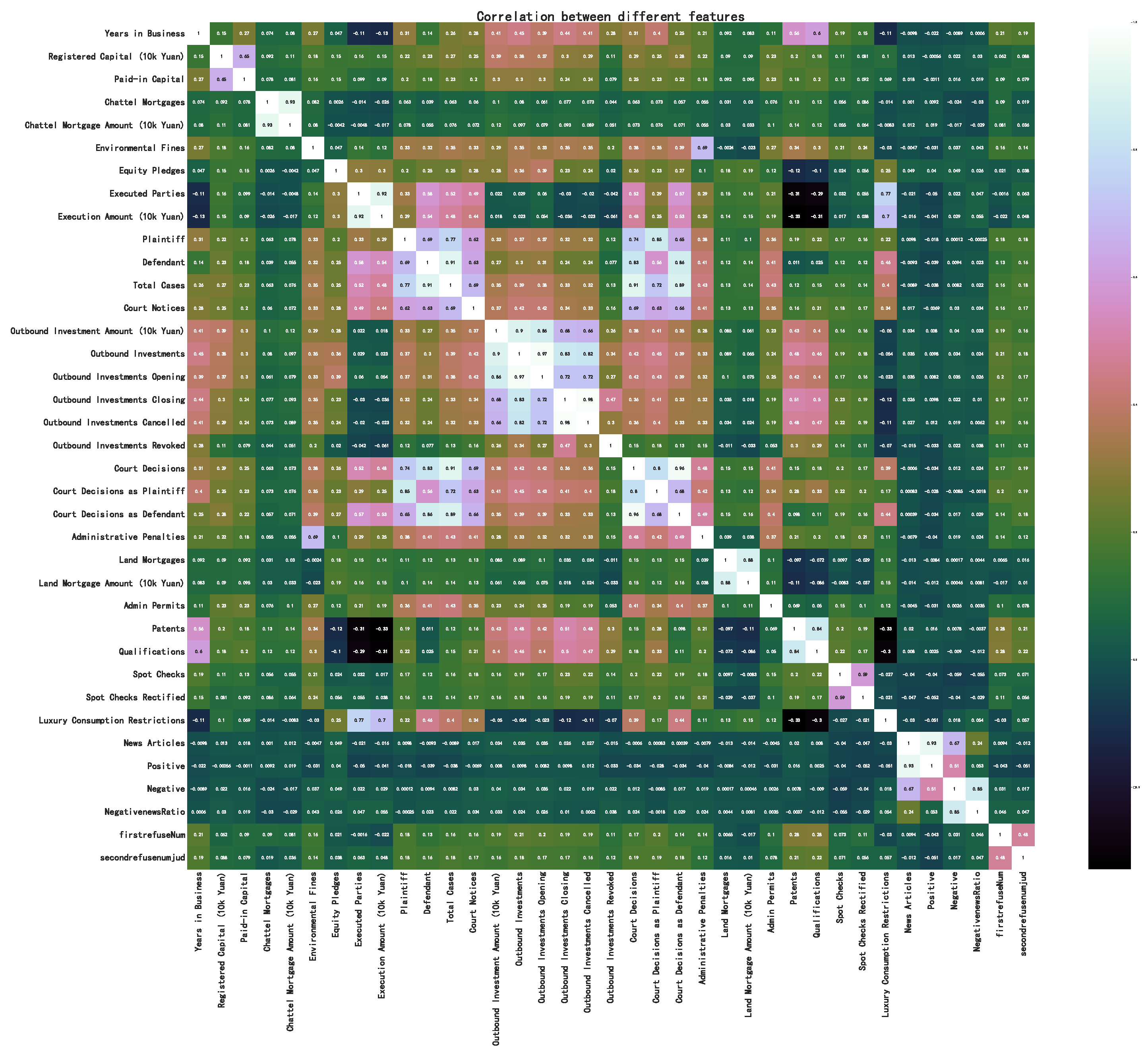
3.1.3. Correlation Analysis of Data
3.2. Methods
3.2.1. Empirical Analysis
Econometric Regression
3.2.2. Machine Learning Methods
Logistic Regression
Support Vector Machines
Neural Networks
Decision Tree
Random Forests
XGBoost
LightGBM
3.2.3. Prompt Learning of Large Language Models
3.2.4. LLM Sentiment Analysis
4. Experiments and Results
4.1. Quantitative Analysis
4.1.1. Indicator Selection and Model Design
4.1.2. Baseline Regression Results
4.1.3. Heteroscedasticity Analysis
4.1.4. Robustness Test
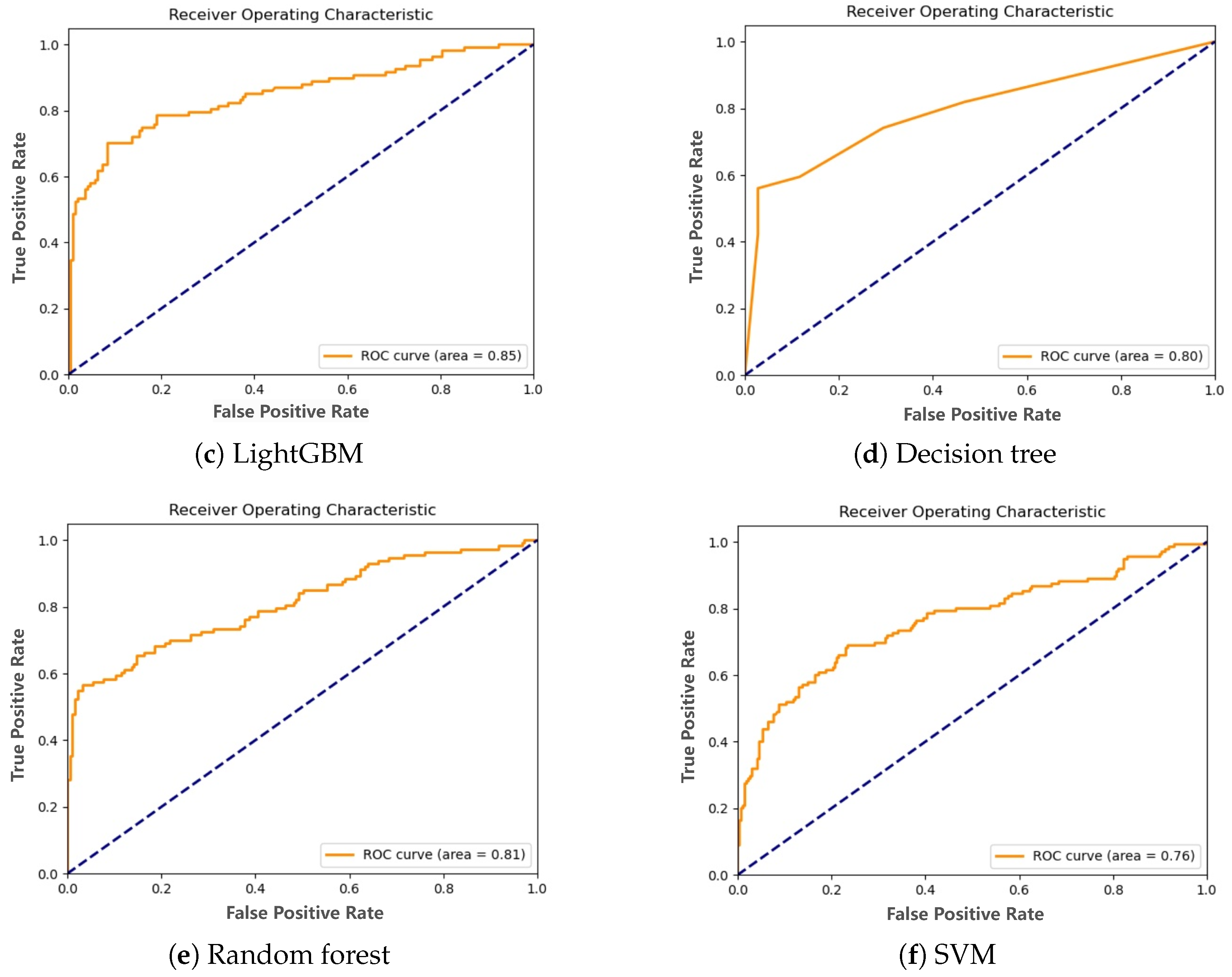
4.2. Machine Learning Methodology
4.2.1. Experimental Setup
4.2.2. Results
4.3. LLM Section
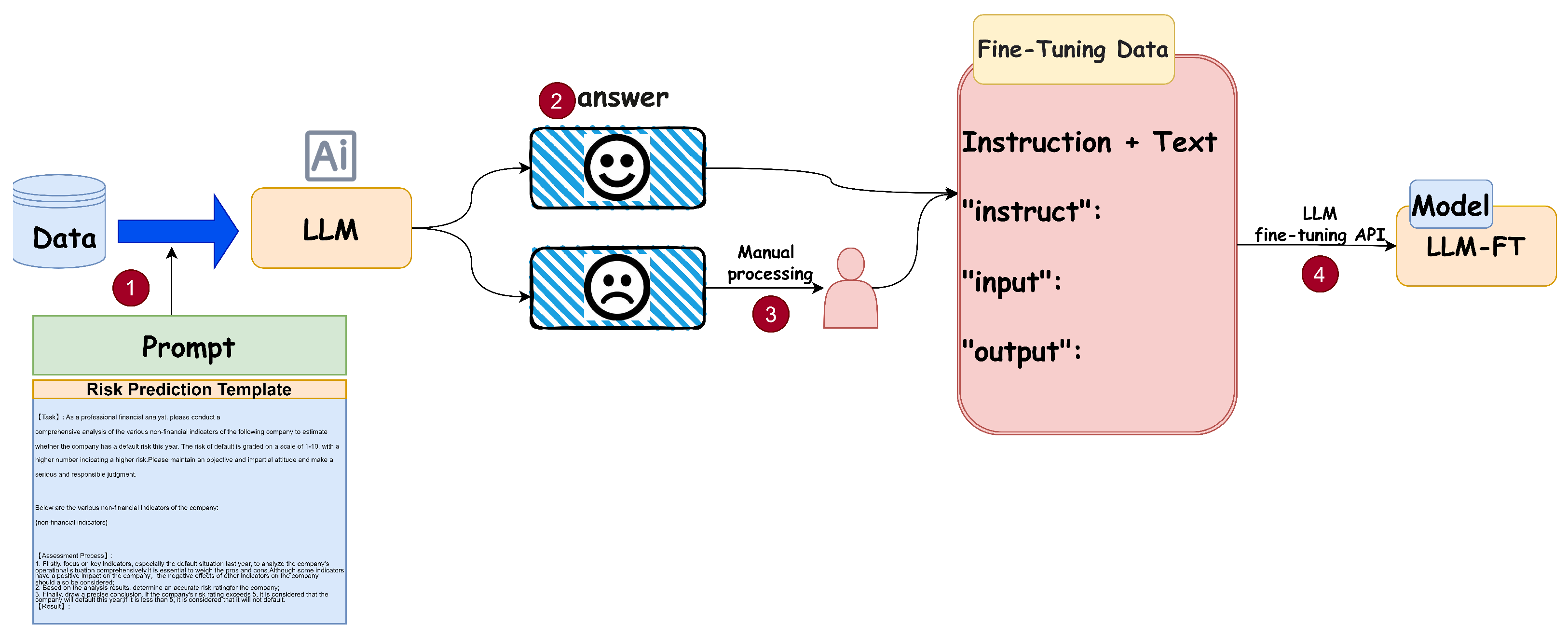
4.3.1. Experimental Setup
4.3.2. Fine-Tuning Procedure
- Construct a prompt template based on the dataset.
- Randomly select 1000 samples and utilize the LLM to obtain their risk prediction results.
- Directly employ correctly predicted results; manually correct the incorrect ones to obtain the fine-tuned dataset.
- Invoke the LLM fine-tuning API to train the model. Firstly, upload and format the fine-tuned dataset, then train the model, and finally employ the model. Specific fine-tuning procedures can be referenced from OpenAI’s official documentation. (https://platform.openai.com/docs/guides/fine-tuning (accessed on 6 August 2024)).
4.3.3. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Output |
|---|---|
| Task: Please act as a professional financial analyst and analyze whether the following news has a positive, negative, or neutral short-term impact on Hainan Agile Property Development Co., Ltd. News: According to reports, recently, during a network inspection conducted by the Hainan Internet Information Office, it was discovered that Hainan Agile Property Development Co., Ltd., and related real estate service websites have been persistently posting false advertisements online, suspected of misleading public consumption and causing adverse effects. Upon investigation, Hainan Agile Property Development Co., Ltd., and related… Please strictly adhere to the following format when responding: Reason: Result: | Reason:The news of Hainan Agile Property Development Co., Ltd. being found posting false advertisements online and suspected of misleading public consumption is likely to have a negative short-term impact on the company. Such actions can undermine the company’s reputation and erode investor confidence. Investors may perceive the company as engaging in unethical or deceitful practices, which could lead to decreased demand for its properties, potential regulatory scrutiny, and even legal consequences. As a result, the company’s stock price may face downward pressure in the short term. Result: Negative |
| Input | Output |
|---|---|
| Task: As a professional financial analyst, please conduct a comprehensive analysis of the various non-financial indicators of the following company to estimate whether the company has a default risk this year. The risk of default is graded on a scale of 1–10, with a higher number indicating a higher risk. Please maintain an objective and impartial attitude and make a serious and responsible judgment. Below are the various non-financial indicators of the company: Years in Business: 6.7 NegativenewsRatio: 0.0 firstrefuseNum: 0 Luxury Consumption Restrictions: 0 Defendant: 1 Plaintiff: 8 Assessment Process:
| Based on the provided non-financial indicators and the assessment process outlined, let’s analyze each indicator and its potential impact on the default risk of the company:
Conclusions: Based on the risk rating falling below 5, it’s unlikely that the company will default this year. However, continuous monitoring of financial and non-financial indicators is crucial to assess evolving risks accurately. |
References
- Black, F.; Scholes, M. The pricing of options and corporate liabilities. J. Polit. Econ. 1973, 81, 637–654. [Google Scholar] [CrossRef]
- Merton, R.C. On the pricing of corporate debt: The risk structure of interest rates. J. Financ. 1974, 29, 449–470. [Google Scholar]
- Cheng, X.; Sun, Z.; Bao, W. Study on credit risk of real estate industry based on genetic algorithm KMV model. J. Phys. Conf. Ser. 2020, 1629, 012072. [Google Scholar] [CrossRef]
- Trustorff, J.H.; Konrad, P.M.; Leker, J. Credit risk prediction using support vector machines. Rev. Quant. Financ. Account. 2011, 36, 565–581. [Google Scholar] [CrossRef]
- Teles, G.; Rodrigues, J.; Rabê, R.A.; Kozlov, S.A. Artificial neural network and Bayesian network models for credit risk prediction. J. Artif. Intell. Syst. 2020, 2, 118–132. [Google Scholar] [CrossRef]
- Zhao, Y.; Wei, S.; Guo, Y.; Yang, Q.; Kou, G. FisrEbp: Enterprise Bankruptcy Prediction via Fusing its Intra-risk and Spillover-Risk. arXiv 2022, arXiv:2202.03874. [Google Scholar]
- Li, L.; Yang, J.; Zou, X. A study of credit risk of Chinese listed companies: ZPP versus KMV. Appl. Econ. 2016, 48, 2697–2710. [Google Scholar] [CrossRef]
- Chen, Y.; Chu, G. Estimation of Default Risk Based on KMV Model—An Empirical Study for Chinese Real Estate Companies. J. Financ. Risk Manag. 2014, 3, 40–49. [Google Scholar] [CrossRef]
- Yi, W. Z-score Model on Financial Crisis Early-Warning of Listed Real Estate Companies in China: A Financial Engineering Perspective. Syst. Eng. Procedia 2012, 3, 153–157. [Google Scholar] [CrossRef]
- Li, S.; Lin, H.; Chen, L. Factor-cluster analysis of financial risk evaluation of real estate listed enterprise. In Proceedings of the 2011 2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce (AIMSEC), Zhengzhou, China, 8–10 August 2011; pp. 1120–1123. [Google Scholar]
- Patel, K.; Vlamis, P. An Empirical Estimation of Default Risk of the UK Real Estate Companies. J. Real Estate Financ. Econ. 2006, 32, 21–40. [Google Scholar] [CrossRef]
- Nguyen, C.V.; Nguyen, T.N.; Le, T.T.O.; Nguyen, T.T. Determining the impact of financial performance factors on bankruptcy risk: An empirical study of listed real estate companies in Vietnam. Invest. Manag. Financ. Innov. 2019, 16, 307. [Google Scholar]
- Kumar, D.; Meghwani, S.S.; Thakur, M. Proximal support vector machine based hybrid prediction models for trend forecasting in financial markets. J. Comput. Sci. 2016, 17, 1–13. [Google Scholar] [CrossRef]
- Sukono, A.S.; Mamat, M.; Prafidya, K. Credit scoring for cooperative of financial services using logistic regression estimated by genetic algorithm. Appl. Math. Sci. 2014, 8, 45–57. [Google Scholar] [CrossRef]
- Wang, D.n.; Li, L.; Zhao, D. Corporate finance risk prediction based on LightGBM. Inf. Sci. 2022, 602, 259–268. [Google Scholar] [CrossRef]
- Liu, C.; Chan, Y.; Alam Kazmi, S.H.; Fu, H. Financial fraud detection model: Based on random forest. Int. J. Econ. Financ. 2015, 7, 178–188. [Google Scholar] [CrossRef]
- Svabova, L.; Michalkova, L.; Durica, M.; Nica, E. Business failure prediction for Slovak small and medium-sized companies. Sustainability 2020, 12, 4572. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, T.; Wei, M.X.; Wei, Z.K.; Tang, L.J. Predicting chain’s manufacturing SME credit risk in supply chain finance based on machine learning methods. Sustainability 2023, 15, 1087. [Google Scholar] [CrossRef]
- Yang, Y.; Chu, X.; Pang, R.; Liu, F.; Yang, P. Identifying and predicting the credit risk of small and medium-sized enterprises in sustainable supply chain finance: Evidence from China. Sustainability 2021, 13, 5714. [Google Scholar] [CrossRef]
- Sun, X.; Lei, Y. Research on financial early warning of mining listed companies based on BP neural network model. Resour. Policy 2021, 73, 102223. [Google Scholar] [CrossRef]
- Yang, S.; Zhang, Z.; Zhou, J.; Wang, Y.; Sun, W.; Zhong, X.; Fang, Y.; Yu, Q.; Qi, Y. Financial Risk Analysis for SMEs with Graph-based Supply Chain Mining. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4661–4667. [Google Scholar]
- Kaya, O. Determinants and consequences of SME insolvency risk during the pandemic. Econ. Model. 2022, 115, 105958. [Google Scholar] [CrossRef]
- Gao, Y.; Jiang, B.; Zhou, J. Financial Distress Prediction for Small and Medium Enterprises Using Machine Learning Techniques. arXiv 2023, arXiv:2302.12118. [Google Scholar]
- Kou, G.; Xu, Y.; Peng, Y.; Shen, F.; Chen, Y.; Chang, K.; Kou, S. Bankruptcy prediction for SMEs using transactional data and two-stage multiobjective feature selection. Decis. Support Syst. 2021, 140, 113429. [Google Scholar] [CrossRef]
- Atidhira, A.T.; Yustina, A.I. The Influence of Return on Asset, Debt to Equity Ratio, Earnings per Share, and Company Size on Share Return in Property and Real Estate Companies. J. Appl. Account. Financ. 2017, 1, 128–146. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Cheong, I.; Xia, K.; Feng, K.K.; Chen, Q.Z.; Zhang, A.X. (A) I Am Not a Lawyer, But...: Engaging Legal Experts towards Responsible LLM Policies for Legal Advice. In Proceedings of the The 2024 ACM Conference on Fairness, Accountability, and Transparency, Rio de Janeiro, Brazil, 3–6 June 2024; pp. 2454–2469. [Google Scholar]
- Orenstrakh, M.S.; Karnalim, O.; Suarez, C.A.; Liut, M. Detecting LLM-generated text in computing education: Comparative study for ChatGPT cases. In Proceedings of the 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), Osaka, Japan, 2–4 July 2024; pp. 121–126. [Google Scholar]
- Nejjar, M.; Zacharias, L.; Stiehle, F.; Weber, I. LLMs for science: Usage for code generation and data analysis. J. Softw. Evol. Process. 2023, e2723. [Google Scholar] [CrossRef]
- Fan, Z.; Tang, J.; Chen, W.; Wang, S.; Wei, Z.; Xi, J.; Huang, F.; Zhou, J. Ai hospital: Interactive evaluation and collaboration of llms as intern doctors for clinical diagnosis. arXiv 2024, arXiv:2402.09742. [Google Scholar]
- Romanko, O.; Narayan, A.; Kwon, R.H. ChatGPT-Based Investment Portfolio Selection. Oper. Res. Forum 2023, 4, 91. [Google Scholar] [CrossRef]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. Bloomberggpt: A large language model for finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Niszczota, P.; Abbas, S. GPT has become financially literate: Insights from financial literacy tests of GPT and a preliminary test of how people use it as a source of advice. Financ. Res. Lett. 2023, 58, 104333. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 18 November 2016).
- Hunt, E.B.; Marin, J.; Stone, P.J. Experiments in induction. Am. J. Psychol. 1966, 80. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Arora, N.; Kaur, P.D. A Bolasso based consistent feature selection enabled random forest classification algorithm: An application to credit risk assessment. Appl. Soft Comput. 2020, 86, 105936. [Google Scholar] [CrossRef]
- Rao, C.; Liu, M.; Goh, M.; Wen, J. 2-stage modified random forest model for credit risk assessment of P2P network lending to “Three Rurals” borrowers. Appl. Soft Comput. 2020, 95, 106570. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Fan, H. A two-stage hybrid credit risk prediction model based on XGBoost and graph-based deep neural network. Expert Syst. Appl. 2022, 195, 116624. [Google Scholar] [CrossRef]
- Rao, C.; Liu, Y.; Goh, M. Credit risk assessment mechanism of personal auto loan based on PSO-XGBoost Model. Complex Intell. Syst. 2023, 9, 1391–1414. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 52. [Google Scholar]
- Ruifan, L.; Zhiyu, W.; Yuantao, F.; Shuqin, Y.; Guangwei, Z. Enhanced Prompt Learning for Few-shot Text Classification Method. Beijing Xue Xue Bao 2024, 60, 1–12. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. DualGCN: Exploring syntactic and semantic information for aspect-based sentiment analysis. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 7642–7656. [Google Scholar] [CrossRef]
- Ye, S.; Zhai, Z.; Li, R. Enhanced machine reading comprehension method for aspect sentiment quadruplet extraction. In Proceedings of the 26th European Conference on Artificial Intelligence 2023, Kraków, Poland, 30 September–4 October 2023; IOS Press: Amsterdam, The Netherlands, 2023; pp. 2874–2881. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 2024, 25, 1–53. [Google Scholar]




| Li et al. (2016) [7] | Chen et al. (2014) [8] | Nguyen et al. (2019) [12] | Cheng et al. (2022) [3] | Proposed Method | |
|---|---|---|---|---|---|
| Research Object | Chinese listed companies | Chinese listed real estate companies | Vietnamese listed real estate companies | Chinese listed real estate companies | Chinese SMEs |
| Data Type | Financial data | Financial data | Financial data | Financial and stock trading data | Non-financial data (e.g., registration info, news sentiment) |
| Method/Model | KMV model | KMV model + time-varying correlation model | Logistic regression | GA-KMV algorithm | Prompt learning with large language models |
| Innovation | Proposed Zero Price Probability (ZPP) model | Combined KMV with time-varying correlation model | Developed logistic regression framework | Integrated genetic algorithm into KMV | Emphasized non-financial data + introduced LLM-based prompt learning |
| Flexibility | Limited | Limited | Limited | High | High, supports multi-scenario real-time prediction |
| Variable | Mean | Std. Dev. | Min | Max |
|---|---|---|---|---|
| Years in business | 14.92104 | 10.07476 | 1 | 74 |
| Registered capital (10k Yuan) | 98,666.12 | 634,863.5 | 0 | 2.25 × 107 |
| Paid-in capital | 81,820.22 | 626,695.6 | 0 | 2.25 × 107 |
| Chattel mortgages | 0.0552738 | 0.5111517 | 0 | 13 |
| Chattel mortgage amount | 4117.529 | 100,311.8 | 0 | 3,930,000 |
| Environmental fines | 1.790061 | 10.80403 | 0 | 270 |
| Equity pledges | 1.896045 | 12.61927 | 0 | 407 |
| Executed parties | 9.227181 | 33.90468 | 0 | 609 |
| Execution amount (10k Yuan) | 13,191.18 | 161,705.4 | 0 | 4,633,389 |
| Plaintiff | 13.62728 | 52.04615 | 0 | 1243 |
| Defendant | 51.98884 | 166.7908 | 0 | 3701 |
| Total cases | 84.93966 | 242.6499 | 0 | 4735 |
| Court notices | 12.39503 | 42.50808 | 0 | 960 |
| Outbound investment amount | 78,123.92 | 491,030.2 | 0 | 1.18 × 107 |
| Outbound investments | 5.602941 | 20.3183 | 0 | 283 |
| Outbound investments opening | 4.517241 | 17.45648 | 0 | 248 |
| Outbound investments closing | 1.0857 | 3.582649 | 0 | 61 |
| Outbound investments canceled | 0.9563895 | 3.400111 | 0 | 61 |
| Outbound investments revoked | 0.0958418 | 0.4587975 | 0 | 7 |
| Court decisions | 109.4204 | 324.5149 | 0 | 5064 |
| Court decisions as plaintiff | 19.16227 | 66.47395 | 0 | 1734 |
| Court decisions as defendant | 78.49949 | 256.3938 | 0 | 4852 |
| Administrative penalties | 2.137424 | 8.806787 | 0 | 138 |
| Land mortgages | 0.1825558 | 1.566111 | 0 | 37 |
| Land mortgage amount | 5218.097 | 57129.71 | 0 | 1,385,002 |
| Admin permits | 78.69422 | 245.4577 | 0 | 5130 |
| Patents | 139.6121 | 484.2995 | 0 | 8129 |
| Qualifications | 16.77282 | 128.4902 | 0 | 3000 |
| Spot checks | 1.373732 | 8.318482 | 0 | 279 |
| Spot checks rectified | 0.1764706 | 1.653769 | 0 | 46 |
| Luxury consumption restrictions | 7.193205 | 38.16634 | 0 | 900 |
| News articles | 74.71247 | 22.81192 | 18 | 100 |
| Positive | 19.26369 | 6.156132 | 0 | 29 |
| Negative | 2.664807 | 1.62043 | 0 | 10 |
| Neg news ratio | 0.0344477 | 0.0182807 | 0 | 0.1064 |
| 2021 refuse num | 6.732759 | 39.85085 | 0 | 707 |
| 2022 refuse num | 12.61866 | 70.38796 | 0 | 1419 |
| Total refuse ratio | 0.0356361 | 0.1070039 | 0 | 0.9437 |
| CID | TNA | NSC | NUC | TRN | TRTY | TRLY | PTR | ORR |
|---|---|---|---|---|---|---|---|---|
| No.1 | 949 | 150 | 799 | 471 | 2 | 2 | 0.4135 | 0.4963 |
| No.2 | 4726 | 3858 | 868 | 43 | 39 | 5 | 0.0114 | 0.0091 |
| No.3 | 8509 | 6994 | 1515 | 665 | 572 | 200 | 0.0867 | 0.0782 |
| No.4 | 2741 | 1981 | 760 | 1674 | 180 | 63 | 0.2487 | 0.6107 |
| No.5 | 2476 | 1964 | 512 | 945 | 117 | 68 | 0.2469 | 0.3817 |
| No.6 | 942 | 569 | 373 | 340 | 5 | 1 | 0.209 | 0.3609 |
| No.7 | 645 | 423 | 222 | 175 | 6 | 0 | 0.3825 | 0.2713 |
| No.8 | 1049 | 715 | 334 | 969 | 23 | 7 | 0.6412 | 0.9237 |
| No.9 | 888 | 578 | 310 | 709 | 30 | 0 | 0.7228 | 0.7984 |
| No.10 | 398 | 205 | 193 | 154 | 1 | 0 | 0.3353 | 0.3869 |
| Variable | Coefficient | T-Value |
|---|---|---|
| Age | 0.1267214 *** | 3.33 |
| Pla | 0.0376407 * | 2.12 |
| Nnr | 2.881501 * | 2.25 |
| Frn | 0.8146282 *** | 39.34 |
| Lcr | 0.088054 *** | 4.59 |
| Constant | −0.1043378 | −0.99 |
| N: 1972 | ||
| R-Square: 0.4776 | ||
| Adj R-Square: 0.4763 | ||
| Variable | Real Estate | Construction | Other Industries |
|---|---|---|---|
| Age | 0.012284 | 0.3644752 | 0.0881954 |
| (0.17) | (1.71) | (1.56) | |
| Pla | −0.0225164 | 0.0137361 | 0.0929062 * |
| (−0.95) | (0.19) | (3.21) | |
| Nnr | 3.005627 * | 8.428441 | 1.619403 |
| (1.50) | (1.63) | (0.73) | |
| Frn | 1.04326 *** | 0.8155993 *** | 0.7177915 *** |
| (28.30) | (13.08) | (24.36) | |
| Lcr | 0.111097 *** | 0.1653752 * | 0.0162129 |
| (5.35) | (2.36) | (0.37) | |
| Constant | 0.1352571 | −0.922278 | 0.0761388 |
| (0.82) | (−1.61) | (0.43) | |
| N | 958 | 127 | 887 |
| R-Square | 0.4937 | 0.6653 | 0.4335 |
| Adj R-Square | 0.4911 | 0.6515 | 0.4303 |
| Variable | Coefficient | T-Value |
|---|---|---|
| Age | 0.000171 | 0.06 |
| Pla | −0.0022124 | −1.58 |
| Nnr | 0.8228015 *** | 8.14 |
| Frn | 0.019433 *** | 11.88 |
| Lcr | 0.0134422 *** | 8.86 |
| Constant | −0.0126499 | −1.52 |
| N: 1972 | ||
| R-Square: 0.1333 | ||
| Adj R-Square: 0.1311 | ||
| Model | Standard | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Logistic | Log | 75.68% | 77.29% | 69.37% | 73.45% |
| MinMax | 68.58% | 70.43% | 59.73% | 63.21% | |
| Z-score | 71.62% | 72.45% | 62.67% | 67.75% | |
| SVM | Log | 76.96% | 76.48% | 70.75% | 75.74% |
| MinMax | 71.14% | 70.38% | 61.16% | 67.33% | |
| Z-score | 68.35% | 66.16% | 57.80% | 63.90% | |
| XGBoost | Log | 80.41% | 80.61% | 73.94% | 79.18% |
| MinMax | 79.05% | 80.28% | 71.22% | 77.07% | |
| Z-score | 81.42% | 82.70% | 74.89% | 80.00% | |
| DT | Log | 79.29% | 78.74% | 73.97% | 78.62% |
| MinMax | 77.03% | 76.98% | 73.91% | 76.35% | |
| Z-score | 78.72% | 78.47% | 73.97% | 78.06% | |
| RF | Log | 81.08% | 82.77% | 76.41% | 79.90% |
| MinMax | 79.73% | 80.91% | 75.14% | 78.55% | |
| Z-score | 80.81% | 80.89% | 73.92% | 79.59% | |
| NN | Log | 71.21% | 72.36% | 69.13% | 71.64% |
| MinMax | 72.22% | 70.70% | 63.98% | 70.34% | |
| Z-score | 72.22% | 69.08% | 62.41% | 69.32% | |
| LightGBM | Log | 80.07% | 81.13% | 72.46% | 78.32% |
| MinMax | 81.08% | 82.56% | 75.25% | 79.72% | |
| Z-score | 76.35% | 76.92% | 68.99% | 74.26% |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Logistic | 71.96% | 73.39% | 63.92% | 68.14% |
| SVM | 72.15% | 71.01% | 63.24% | 68.99% |
| XGBoost | 80.29% | 81.20% | 73.35% | 78.75% |
| DT | 78.35% | 78.06% | 73.95% | 77.68% |
| RF | 80.54% | 81.52% | 75.16% | 79.35% |
| NN | 71.88% | 70.71% | 65.17% | 70.43% |
| LightGBM | 79.17% | 80.20% | 72.23% | 77.43% |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| LLM | 75.00% | 75.00% | 76.50% | 75.74% |
| LLM-FT | 82.10% | 77.00% | 84.30% | 80.41% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.; Li, J.; Zheng, C.; Chen, S.; Wang, X.; Chen, X. Advanced Default Risk Prediction in Small and Medum-Sized Enterprises Using Large Language Models. Appl. Sci. 2025, 15, 2733. https://doi.org/10.3390/app15052733
Huang H, Li J, Zheng C, Chen S, Wang X, Chen X. Advanced Default Risk Prediction in Small and Medum-Sized Enterprises Using Large Language Models. Applied Sciences. 2025; 15(5):2733. https://doi.org/10.3390/app15052733
Chicago/Turabian StyleHuang, Haonan, Jing Li, Chundan Zheng, Sikang Chen, Xuanyin Wang, and Xingyan Chen. 2025. "Advanced Default Risk Prediction in Small and Medum-Sized Enterprises Using Large Language Models" Applied Sciences 15, no. 5: 2733. https://doi.org/10.3390/app15052733
APA StyleHuang, H., Li, J., Zheng, C., Chen, S., Wang, X., & Chen, X. (2025). Advanced Default Risk Prediction in Small and Medum-Sized Enterprises Using Large Language Models. Applied Sciences, 15(5), 2733. https://doi.org/10.3390/app15052733