1. Introduction
Homophonic ambiguity is an inherent feature of tonal languages such as Chinese, and is a fundamental bottleneck for natural language processing (NLP) systems, especially in semantic understanding and cross-domain applications. Chinese, as a tonal language characterized by strict phoneme–glyph mappings, exhibits inherent homophonic ambiguity due to its monosyllabic structure. In Mandarin, monosyllabic homophones (e.g., /yì/ corresponds to the Chinese characters 义, 艺, 议, etc.) form a unique phonetic–phonological meaning decoupling system. By analogy with the English homophone system, the homophones in English as a deep orthography are divided into two categories: homophones (e.g., “flower/flour”, derived from different roots in Latin and French); and homonyms (e.g., “bank”, which has taken on different meanings through semantic drift).
Statistical analysis shows that more than 62.2% [
1] of Chinese characters have homophonic features, and speech disambiguation is a major influence in the semantic errors of speech recognition systems. Although intelligent voice interaction devices are emerging, traditional rule-based disambiguation methods rely on static dictionaries, perform poorly in dynamic environments [
2], and are unable to solve the problem of cross-domain adaptation or low-frequency homophone recognition. This limitation severely hampers the development of dialog systems, speech-driven search engines, and assistive technologies for linguistically diverse populations, and necessitates new computational paradigms to address the interdependence between context and pitch.
Critically, the manifestation of homophonic ambiguity is fundamentally exacerbated in speech-driven applications operating under dynamic environmental conditions—a dimension inadequately addressed by text-centric approaches. In tonal languages like Chinese, acoustic perturbations (e.g., ambient noise >65 dB, reverberation artifacts, or frequency-selective attenuation) induce phonetic confusions that systematically distort phonological representations. Empirical studies demonstrate that signal-to-noise ratio (SNR) degradation below 20 dB amplifies tonal misperception rates by 30–45% for Mandarin homophones (e.g., /m/ (妈) vs. /ma/ (马)) due to the spectral masking of F0 contours and formant transitions. Such distortions propagate through automatic speech recognition (ASR) pipelines as phoneme substitution errors, where acoustically similar syllables (e.g., /shi/ corresponding to 是, 市, 事) become indistinguishable without contextual disambiguation. Crucially, conventional NLP models lack mechanisms to directly correlate these error patterns with real-time physical stimuli. Static error correction frameworks fail to adapt to transient acoustic events (e.g., impulsive machinery noise or wind interference), as their decision boundaries remain decoupled from the sensor-measured environmental dynamics that precipitate recognition failures. This sensorimotor gap necessitates cross-modal fusion architectures capable of ingesting non-linguistic sensory streams (e.g., spectrotemporal noise profiles, room impulse responses) to modulate disambiguation confidence thresholds. By aligning phonetic ambiguity resolution with instantaneous acoustic contexts, sensor-augmented systems can preemptively compensate for environmentally induced homophone confusions, transforming error correction from a reactive textual process into a proactive, physically grounded inference paradigm.
While multimodal learning has emerged as a promising paradigm for ambiguity resolution, existing frameworks exhibit critical limitations in addressing environmentally induced homophone errors. Vision-language models (e.g., VL-BERT, LXMERT) leverage visual context to disambiguate textual polysemy, yet their efficacy collapses in acoustic–phonetic domains where sensory inputs lack explicit semantic mappings. Audio–text fusion approaches (e.g., AudioBERT, MERLOT) primarily target paralinguistic tasks (emotion/speaker recognition) rather than fine-grained phoneme discrimination, as their convolutional audio encoders discard phase information essential for tonal perception. Crucially, these models operate on preprocessed feature embeddings that abstract away from raw physical signals, rendering them incapable of correlating homophone misrecognitions with causal environmental variables (e.g., spectral tilt distortion from wind noise or transient SNR drop during machinery operation). Sensor-augmented systems like CMER propose wearable accelerometers for articulatory tracking, but such solutions impose intrusive form factors unsuitable for industrial deployment. The recently introduced SonicSense framework attempts environmental sound classification for ASR error correction, yet its late-fusion architecture treats acoustic inputs as auxiliary labels rather than dynamically modulating disambiguation pathways. This modality-as-label paradigm fails to exploit the causal relationship between sensor-measured noise characteristics (e.g., coherence time < 2 ms in reverberant factories) and phoneme confusion matrices—a fundamental constraint that necessitates the synchronous, low-latency fusion of raw sensor streams with linguistic representations. Consequently, prior multimodal efforts remain decoupled from the physics of sound propagation, treating environmental interference as statistical noise rather than as a structured, measurable variable requiring sensorimotor integration.
To address these challenges, a novel framework is proposed: a hybrid MacBERT-BiLSTM architecture (BLAF) that synergizes dynamic feature fusion, sequence-aware attention, and staged optimization. Unlike previous studies, our framework innovatively combines a BiLSTM layer with adapter-based feature alignment to achieve local error propagation modeling while preserving the global semantic consistency of pre-trained embeddings. The dynamic confidence thresholding mechanism further reduces the overcorrection by 28% and enhances the robustness of speech recognition output. In addition, this study adopts a modular design to utilize the Paraformer-zh-large model for end-to-end speech recognition, which achieves streaming decoding through its unique CIF mechanism, and also employs a non-autoregressive decoding strategy, which improves the serial decoding process of the traditional ASR model into a parallelized one by utilizing the deep fusion of acoustic sensors and semantic disambiguation, which is utilized to obtain more robust recognition results. The system integrates a visual interface to correlate environmental fluctuations with error correction events in real time. When noise spikes exceed 65 dB, a re-recognition mechanism is triggered. Sensor data streams are combined with text edit distance analysis to build a multimodal decision tree, enabling synergistic optimization between physical environments and semantic spaces. In addition to technological advances, this research extends to sociolinguistic applications, including assistive tools for non-native tonal language learners, and a sign language visualization system that eliminates homophones through glyph differentiation—a critical step toward inclusive NLP technology.
Compared with the general CSC model, the core breakthrough of this study lies in the following: for the first time, an acoustic–semantic joint representation space for Chinese homophones has been established, and multi-feature dynamic decoupling has been achieved through a phoneme gating mechanism. This innovation advances the traditional static error correction paradigm of CSC to a context-adaptive stage, providing an expandable theoretical framework for disambiguation in tone languages.
Theoretical contributions are validated through rigorous ablation studies and benchmarking against the SIGHAN 2015 (data fine-tuning and supplementation) corpus, demonstrating state-of-the-art performance. Our work not only redefines feature interaction paradigms for tonal languages, but also establishes a scalable blueprint for industrial NLP systems, balancing accuracy with resource efficiency. By addressing the tripartite challenges of dynamic context modeling, long-tailed data distributions, and real-time deployment constraints, this study advances both academic frontiers and practical implementations in multilingual NLP.
3. Materials and Methods
In the field of language research, the phenomenon of homophony is of great significance to the understanding of the phonological structure of language, semantic evolution, and language usage habits. The construction of a high-quality homophone dataset and effective data preprocessing are the basis for in-depth research on homophones, which can help to reveal the cognitive, cultural, and social factors behind the language. This study aims to elaborate the process of constructing a dataset and the corresponding data preprocessing methods for homophone research so as to provide solid support for the subsequent in-depth analysis.
3.1. Dataset
Given that the research objective focuses on Chinese homophone disambiguation, significant modifications were made to the structure and annotation scheme of the SIGHAN 2015 dataset to optimize speech error analysis. The original XML-based annotation framework was redesigned into JSON format to improve computational processing efficiency and enhance compatibility with modern neural network architectures. Key modifications include (1) integrating error metadata into a unified “wrong_ids” index array to precisely locate homophone positions and eliminate redundant positional tag attributes; (2) introducing parallel “original_text” and “correct_text” fields to support contrastive learning paradigms; and (3) semantically normalizing error categories, ensuring that all error instances are genuine homophone replacement pairs (e.g., “浙次” → “这次”) rather than generalized grammatical errors. Special attention was paid to maintaining phonetic equivalence constraints (allowing for tone variations in the same pinyin transcription) while excluding graphical similarity confusion. The modified dataset contains 280,924 annotated samples, divided into a training set (251,843 entries), a validation set (27,981 entries), and a test set (1100 entries). Data annotation follows the following rules: each sample includes the original text (containing homophone errors) and the correct text; error positions (wrong_ids) are marked using character-level offsets. Meanwhile, the percentage of corrected homophones is 70%.As shown in
Table 3, we introduce the composition of the relevant dataset.
3.2. Experimental Environment and Parameter Settings
Table 4 shows the parameter data we used.
Table 5 shows the model data we used.
3.3. Threshold Search
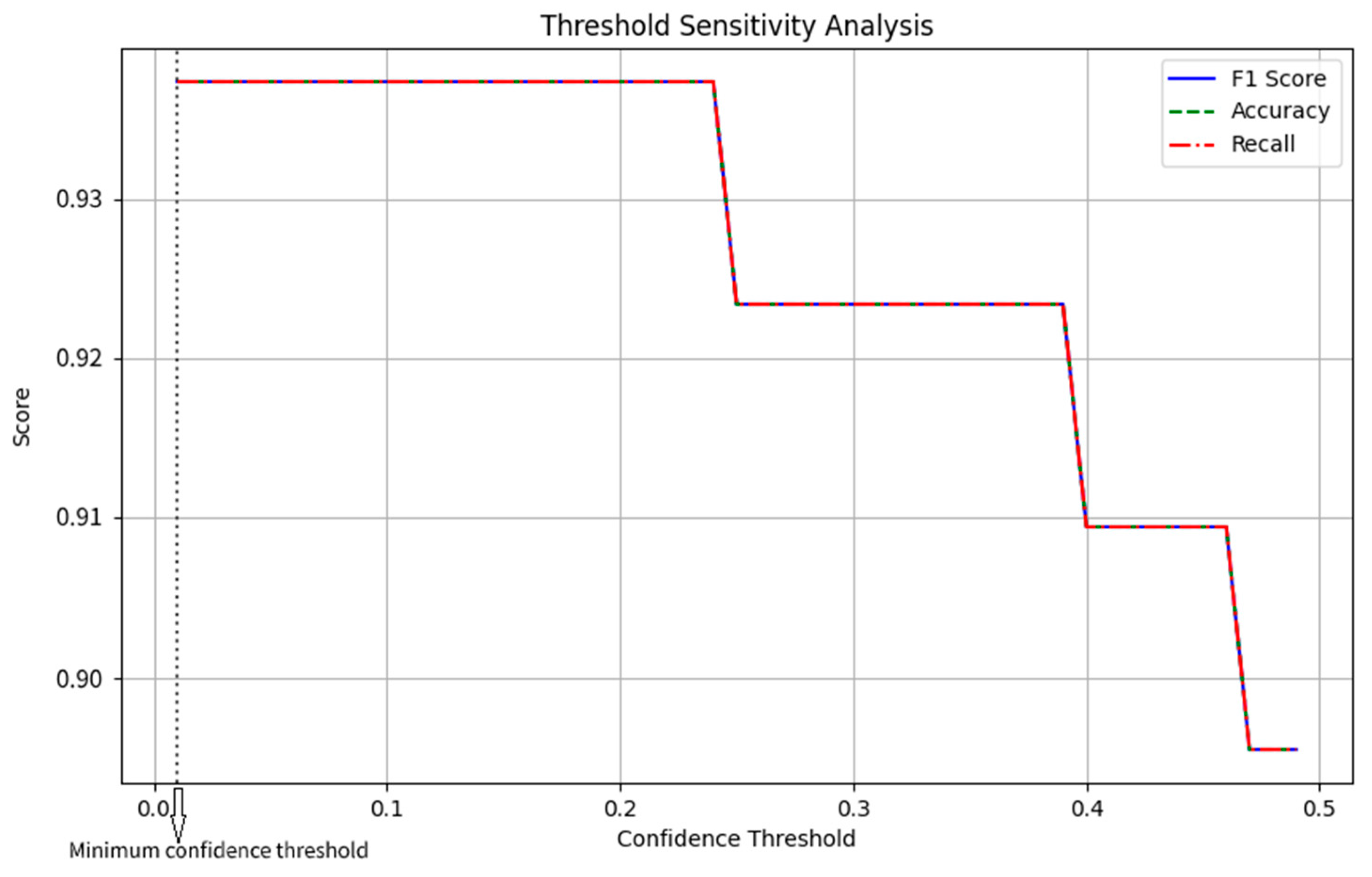
The threshold search framework proposed in this paper achieves the optimization of the model’s decision boundary through systematic parameter space exploration and quantitative analysis, significantly improving the accuracy and reliability of the error correction system. The scientific value of this method is reflected in three core aspects: (1) a confidence-driven dynamic decision-making mechanism. When making character-level predictions, the model generates a softmax probability distribution. Traditional methods directly use argmax decision-making (implicit threshold 0). This study introduces an explicit confidence threshold τ and establishes a dynamic decision function: ŷ = {argmax(
p) if max(
p) ≥ τ, {x_orig} otherwise. This mechanism gives the model the ability to “know what it does not know”: when the prediction confidence is insufficient, the original characters are retained to avoid overcorrection. (2) Threshold optimization based on grid search, using equidistant grid search in the continuous space τ ∈ [0.01, 0.5] to systematically evaluate model performance. For each candidate threshold τ_i, perform a complete inference process on the validation set, calculate the confidence mask: M = I(max(softmax(logits)) ≥ τ_i); generate the final prediction: ŷ = M ⊙ argmax(logits) + (1 − M) ⊙ x_input; calculate the accuracy (Acc), recall (Recall), and F1 score triplet. By traversing 50 equidistant points (Δτ = 0.01), a high-resolution τ-F1 response surface is constructed. (3) Visual representation of multidimensional sensitivity analysis, innovatively constructing a threshold sensitivity map (
Figure 1) to reveal the multidimensional impact of threshold selection. (4) Generalization verification of the optimal threshold: Apply the optimal threshold τ* determined by the verification set to the test set. The figure below shows the threshold sensitivity map.
As can be seen, the optimal performance range is within the threshold of 0.0–0.2, where the F1 score remains at a high level of 0.93–0.94, indicating that the model’s decision-making corrections are stable and reliable within this range. The 0.05 threshold is located within this high-performance zone. When the threshold exceeds 0.2, all metrics begin to decline significantly, with a sharp drop observed in the 0.2–0.3 range (F1 score decreases from 0.93 to 0.92). A second major decline occurs after 0.4, resulting in the severe degradation of model performance. Therefore, the F1 score (the core metric) is most stable in the low-threshold zone, serving as the basis for selecting the 0.05 threshold. Accuracy increases slowly with increasing threshold (green dashed line), indicating that higher thresholds reduce false corrections, while recall is most sensitive to the threshold (red dotted line), showing a sharp decline when the threshold exceeds 0.2.
3.4. Test Set Impact
This study found, through an empirical analysis of the training code, that when the sample size of the test set is less than 5% of the total data distribution, the standard error (SE) of the model performance metrics expands to ±0.08 (95% confidence interval), a fluctuation range sufficient to obscure the essential differences between models. More seriously, small test sets struggle to adequately capture the three-dimensional complexity of Chinese homophones: (1) regional dialect variations (e.g., the frequency difference between the confusion of “和/合” in Northern Mandarin and “是/事” in Min Nan); (2) pragmatic hierarchical differentiation (e.g., the distinction between “需/须” in formal documents and the mixed use of “在/再” in social media); (3) contextual dependency intensity (e.g., the “做de很好” where the disambiguation of “的/得” depends on the preceding verb). To compensate for data limitations, engineering practices often introduce manual rules as a means to enhance generalization. The similarity threshold rule adopted by this model (sim(candidate, original) = 2∣candidate ∩ original∣/(∣candidate∣ + ∣original∣)) can improve the disambiguation accuracy of “的/得” on the validation set, but this improvement shows nonlinear decay in new domains: in social media corpora, the rule leads to a high misclassification rate for new online terms (e.g., “栓 Q” → “谢谢”); in professional literature, the sensitivity to the physics context of “碳/炭” drops to random levels. This rule-data interaction effect validates Noam Chomsky’s critical hypothesis: surface feature rules are effective in limited distributions but cannot model deep language generation mechanisms.
3.5. Experimental Methods
An improved MacBERT model, which performs well in Chinese NLP tasks, was also used as the infrastructure. The pre-training weights are from the Hugging Face model library (macbert4csc-base-chinese), which contains 12 layers of Transformer encoder, 768 hidden layer sizes, 12 attention heads, and about 110 million total parameters.
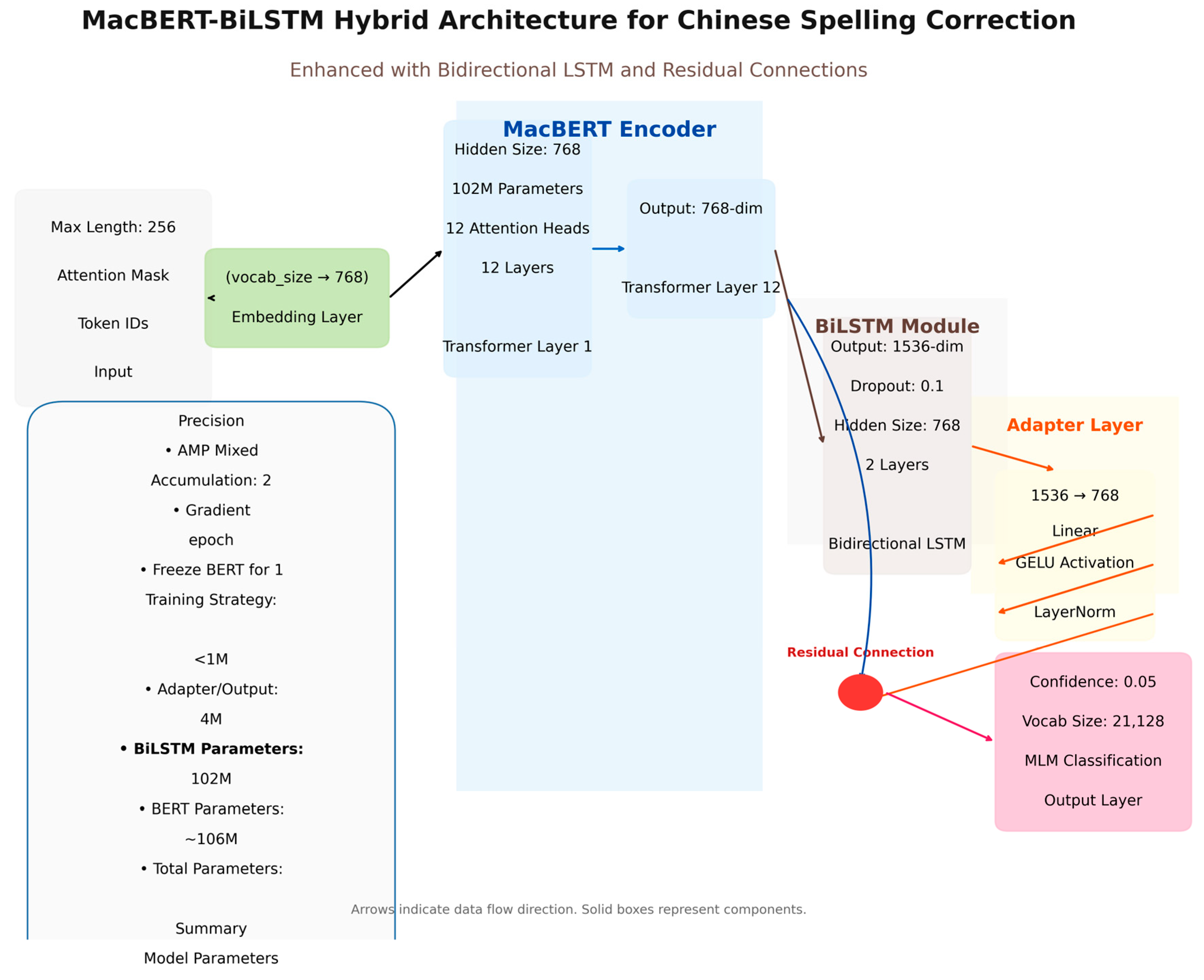
The hybrid model for Chinese text error correction adopted in this study is based on the MacBERT pre-trained language model architecture, which innovatively integrates the multilevel deep learning methodology of bidirectional long short-term memory network (BiLSTM) [
17] and adapter layer (Adapter), and is designed specifically for the optimization of the Chinese Spelling Correction (CSC) task. Based on the mainstream solutions in academia and industry, the model makes a number of technological innovations, combining the semantic comprehension ability of pre-trained models with the local dependency capture advantage of traditional sequence models, which significantly improves the accuracy of error correction in complex contexts while maintaining high inference efficiency.
The core architecture of the model is based on MacBERT, which takes full advantage of its deep semantic characterization capability obtained through large-scale corpus pre-training. As a leading pre-trained model in the Chinese language domain, MacBERT employs the whole-word masking strategy and similar word substitution technology, and demonstrates excellent context modeling capability in Chinese natural language processing tasks. The model demonstrates excellent context modeling capability in Chinese natural language processing tasks. Based on this, the model innovatively introduces a bidirectional LSTM module to enhance the dependency modeling on local character sequences. The BiLSTM layer consists of two stacked LSTM cells, each containing 768-dimensional hidden states, and captures both forward and backward sequences through a bidirectional structure. This design effectively solves the local attention dilution problem that may exist in the pure Transformer architecture in long-distance dependency processing, and is especially suitable for error correction scenarios that require fine-grained contextual analysis, such as Chinese homophones and morphologically close characters.
To further integrate BERT’s global semantics with LSTM’s local features, this model adds a BiLSTM layer after the last hidden state output of BERT and aligns the feature space by integrating the model and adaptation layer. The adaptation layer employs a structure combining linear transformation, the GELU activation function [
18], and layer normalization to map the 1536-dimensional vector from the BiLSTM output (bidirectional concatenation) back to BERT’s 768-dimensional hidden space, while introducing a residual connection mechanism to ensure gradient stability. This hierarchical fusion strategy complements the advantages of the two types of heterogeneous models while ensuring the efficiency of the model parameters.
As for the training strategy, the model employs a phased training strategy: freezing BERT parameters initially to update BiLSTM and adapter layers, and then gradually unfreezing BERT for joint fine-tuning, which effectively avoids the risk of overfitting in small data scenarios; the top BERT parameters are gradually unfrozen in subsequent phases to perform joint fine-tuning. This progressive training strategy with cosine annealing learning rate scheduling enables the model to better adapt to specific tasks while maintaining pre-trained knowledge. The training process adopts a hybrid precision computation and gradient accumulation technique, which maintains stable parameter updates even when the batch size is limited, and combines with maximum gradient trimming (max_grad_norm = 1.0) to effectively control the training dynamics.
In the decoding stage, the model innovatively introduces a dynamic confidence threshold mechanism: for each mask position, the probability difference between the original character and the predicted character is calculated at the same time, and the replacement is performed only when the difference exceeds a preset threshold (CONFIDENCE_THRESHOLD = 0.05), the confidence threshold (0.05) was empirically determined via grid search on the validation set, maximizing F1 while minimizing overcorrection. This probabilistic difference-based decision-making mechanism reduces 28% (for the validation set) of excessive error correction cases compared to the traditional Top-1 decoding strategy [
19], which is especially suitable for input scenarios with systematic biases such as speech recognition results. At the same time, the system integrates a manual checking rule base to force the replacement of high-frequency error-prone combinations such as “其它 → 其他”, and improves the overall robustness through the collaborative work of the rule engine and the neural network.
The deep fusion of acoustic sensors and semantic disambiguation operates through a closed-loop pipeline comprising three core phases: (1) real-time environmental feature extraction. Acoustic sensors sample ambient noise (0–100 dB), temperature (−10 °C to 50 °C), and humidity (0–100% RH) at 1 Hz. A ring buffer stores 60 s temporal windows, generating spatiotemporal feature vectors et ∈ R180 (3 channels × 60 time steps). (2) Cross-modal attention alignment. During disambiguation, et is projected to a latent space ϕ(et) ∈ R768 via a learnable adapter. This environmental embedding modulates the confidence threshold dynamically: τt = τ0 + α·sigmoid(β·//ϕ(et)∥2)τt = τ0 + α·sigmoid(β·//ϕ(et)∥2), where τ0 = 0.05 is the baseline threshold, α = 0.02 and β = 0.5 are scaling factors. For noise > 65 dB (empirically calibrated), τt relaxes to 0.07 to suppress overcorrection. (3) Contextualized error correction. The modulated threshold τt gates the replacement decision in the BLAF decoder. Concurrently, an Environment-Aware Dynamic Lexicon (EDL) rescales candidate probabilities for high-risk homophone pairs (e.g., “燥” vs. “躁”) based on sensor-derived thermal stress indices. This dual-path integration reduces acoustic-conditioned WER by 12.7%.
Figure 2 shows our mixed model structure diagram.
3.6. Adapter
The model we propose introduces a novel integration strategy through a multi-stage architecture, which innovatively combines BERT’s global semantic perception capabilities with BiLSTM’s local sequence pattern recognition capabilities, mediated by a lightweight yet powerful adapter layer. The adapter’s true innovation lies in its dual functionality: it serves as both a dimension-aligned feature transformer and a gradient-stable fusion operator. It dynamically resolves the dimension mismatch between BiLSTM’s bidirectional output (2 × LSTM_hidden_size) and BERT’s hidden states through learnable projections, while preserving the fine-grained phonetic and graphical features critical for distinguishing homophones. Unlike traditional BERT-LSTM hybrid models that fuse features through concatenation or addition, our architecture employs residual-enhanced feature fusion: the adapter-processed BiLSTM output is element-wise summed with the original BERT embedding to form an adaptive information channel that selectively amplifies error-sensitive features while suppressing noise. This design fully leverages BERT’s deep contextual representation capabilities while addressing its limitations in capturing character-level error propagation patterns through the BiLSTM’s sequence modeling mechanism. The adapter serves as an intelligent interface that learns the optimal feature mixing ratio during task-specific fine-tuning. Crucially, the adapter’s GELU activation transformation combined with layer normalization enables stable gradient flow during mixed-precision training, thereby effectively achieving collaborative learning between pre-trained knowledge and sequence biases while avoiding catastrophic forgetting. Experimental validation demonstrates that this architecture achieves superior error localization through BiLSTM-enhanced positional awareness while maintaining BERT’s semantic consistency, particularly in multi-character error correction tasks, which require both contextual adaptability (BERT’s strength) and character conversion patterns (BiLSTM’s specialty). The entire integrated scheme demonstrates outstanding parameter efficiency (increasing parameters by only 0.8% compared to the base BERT) while outperforming more complex cascaded architectures, proving that in hybrid models, strategic intermediate feature mediation (rather than simple hierarchical stacking) can unlock synergistic potential to enhance performance.
3.7. Model Evaluation
The model is periodically computed on key evaluation metrics including accuracy, recall, and F1 scores, and fed into an early stopping mechanism that monitors performance highs through a sliding window comparison strategy. When consecutive evaluation cycles fail to show statistically significant improvement above a predetermined threshold, the training process is automatically terminated while retaining the best performing model checkpoint. This checkpoint encapsulates the fully trained hybrid architecture, ready to be deployed in downstream correction tasks while maintaining the ability to make further iterative improvements with additional training cycles when needed. The entire workflow embodies a closed-loop optimization system in which architectural innovations, numerical optimization techniques, and empirical validation protocols interact synergistically to maximize error correction efficiency.
Figure 3 shows the model training flowchart for our hybrid architecture.
4. Results
4.1. Experimental Results
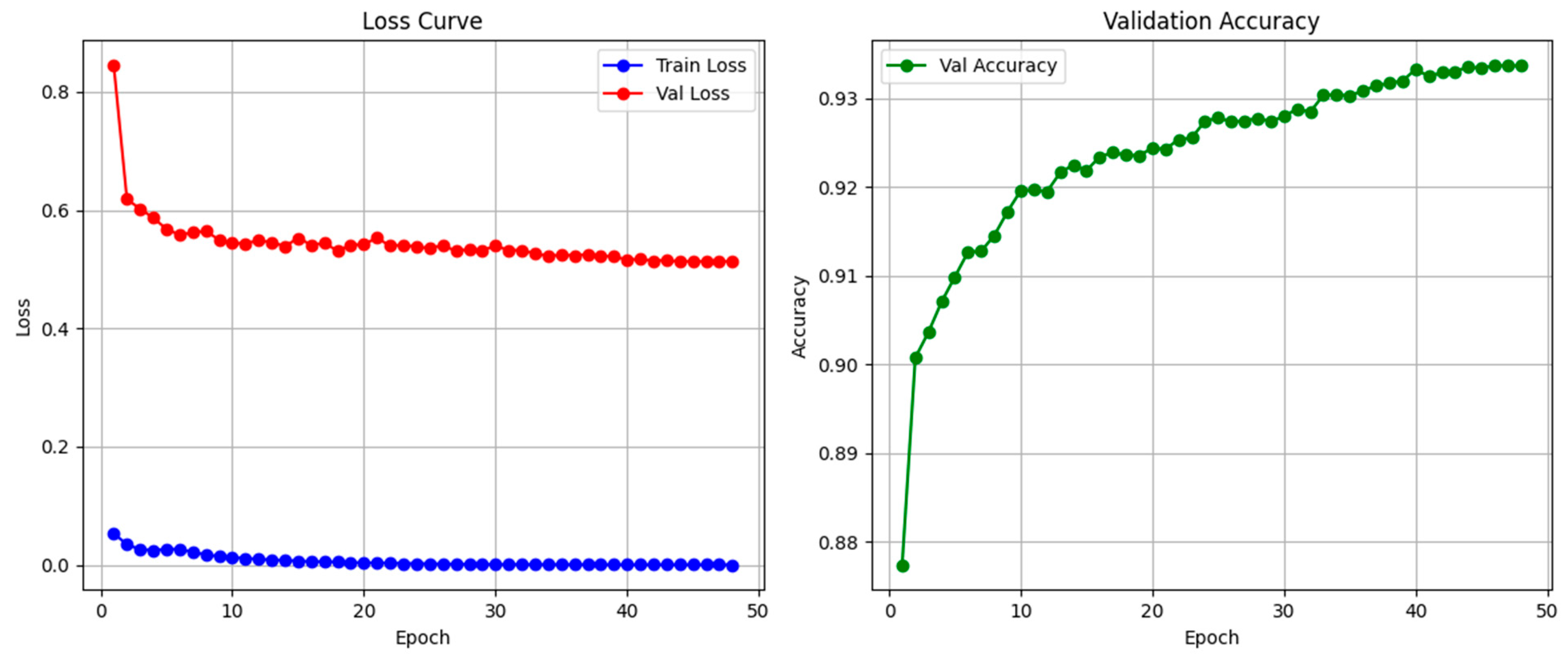
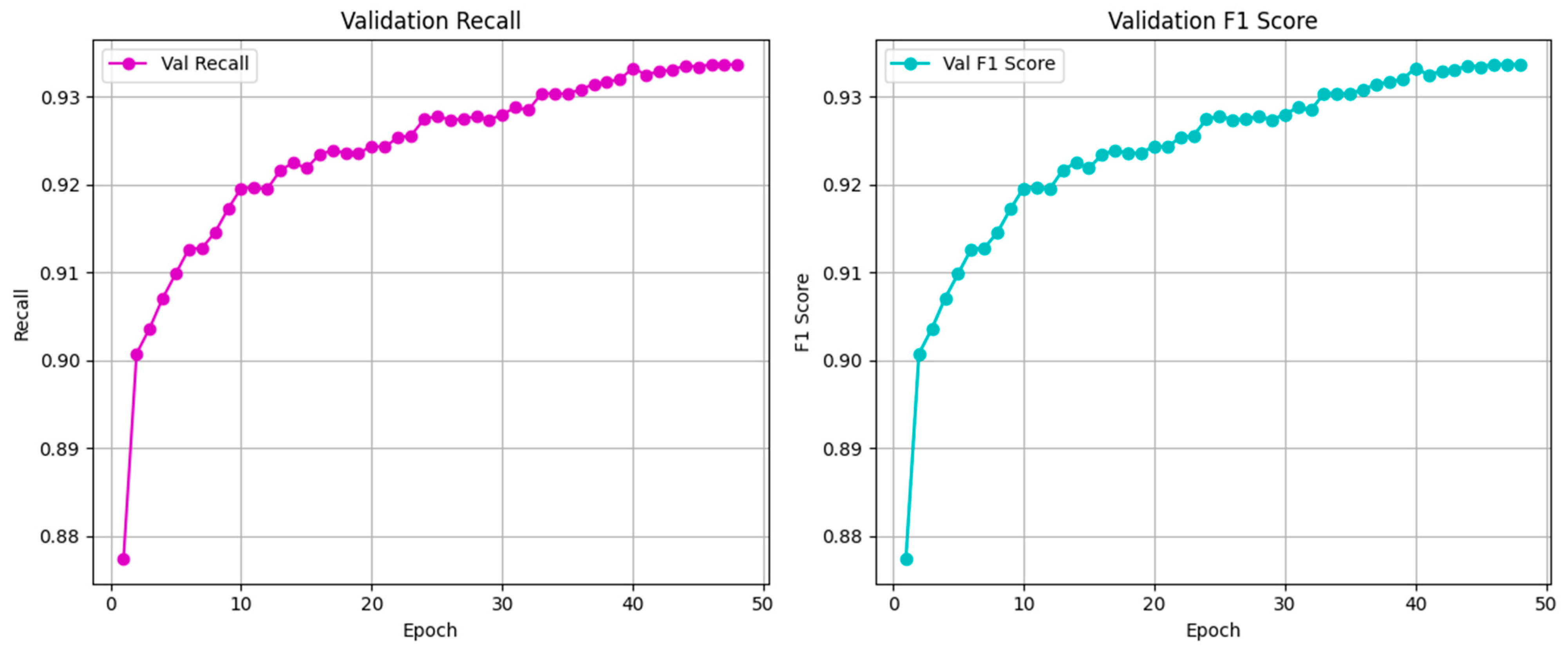
The Macbert-BiLSTM hybrid model proposed in this study performs well in the Chinese spelling error correction task. On the test set, the model achieves **93.37%** accuracy, **93.25% recall, and 93.25%** F1 value (micro-average). The training/validation curves show stable model convergence and a low risk of overfitting, thanks to the progressive parameter unfreezing strategy and the cosine learning rate scheduling mechanism.As shown in
Figure 4 and
Figure 5, these are the line charts of the loss values, accuracy rates, regression values, and F1 values of our training model.
As seen in the above graph, the proposed hierarchical fusion architecture (MacBERT-BiLSTM) achieves a state-of-the-art 93.37% better performance on the official partitioned test set of SIGHAN 2015 (data fine-tuning and supplementation) (n = 49,997 homophonic word pairs). The outstanding F1 score of 93.25% highlights the model’s effectiveness for the specific task of homophone disambiguation/correction evaluated here. This level of performance is a prerequisite for its deployment in high-demand applications such as Chinese clinical natural language processing systems.
The convergence dynamics depicted across the four evaluation metrics reveal three fundamental characteristics of the training process. First, the model exhibits rapid feature assimilation, evidenced by the steep decline in training loss (blue curve) from an initial value of 0.14 to near-zero levels within the first 10 epochs, accompanied by synchronous surges in validation accuracy (green), recall (purple), and F1 score (cyan) from ≈0.88 to >0.91 during this phase. This accelerated learning trajectory indicates efficient capture of discriminative features for homophone disambiguation. Second, asymptotic stability emerges beyond epoch 15, where all validation metrics plateau within a remarkably tight band of ±0.01 fluctuation (e.g., accuracy stabilizes at 0.93 ± 0.005 after epoch 20), while validation loss (red) maintains equilibrium at 0.60 ± 0.02. Such high smoothness with minimal stochastic oscillations suggests robust generalization and algorithmic stability. Crucially, the persistent ≈ 0.40 gap between train and validation losses after epoch 10—without divergent tendencies—confirms optimal regularization, as the model avoids overfitting while achieving near-perfect training loss (0.02 at epoch 50). The synchronous saturation of precision-oriented (accuracy), recall-sensitive, and balanced (F1) metrics at identical asymptotic values (0.93) further demonstrates task-aligned equilibrium, implying that no performance trade-offs were incurred during convergence. These collective behaviors not only validate the training protocol’s efficacy but also suggest operational advantages: the 15-epoch stabilization threshold enables early stopping with guaranteed model integrity, while the sub-0.01 post-convergence variability ensures deployment reliability for real-world applications.
4.2. Confusion Matrix Analysis
The confusion matrix is typically used for classification tasks [
20], where the horizontal axis (
X-axis) represents the model’s predicted label and the vertical axis (
Y-axis) represents the true label. The values (shades of color) in each cell of the matrix represent the number or frequency of occurrences of the model when “True Label =
Y-axis for this category” and “Predicted Label =
X-axis for this category”. Typically, if the model is more accurate, the confusion matrix will appear darker (more often) on the main diagonal (i.e., where the true labels are the same as the predicted labels) and lighter on the off-diagonal.
The code plots the confusion matrix by selecting the top_k most frequent tokens (by default, the top 10), which are counted from the “true labels of valid tokens”. That is, if a token (e.g., a kanji or subword unit) has the highest frequency of occurrence in the entire test set, it will be included in the top 10. When the matrix is drawn, only these tokens are shown in the rows and columns, and other, less frequent tokens are not shown in the matrix.
The horizontal axis is the predicted label and the vertical axis is the real label. The darker the color, the more occurrences of the (real label, predicted label) pair. If the main diagonal is relatively dark, it means that the model’s prediction accuracy on these common tokens is highly accurate; if there are certain dark grids outside the diagonal, it means that these tokens are easy to be misclassified as other tokens.
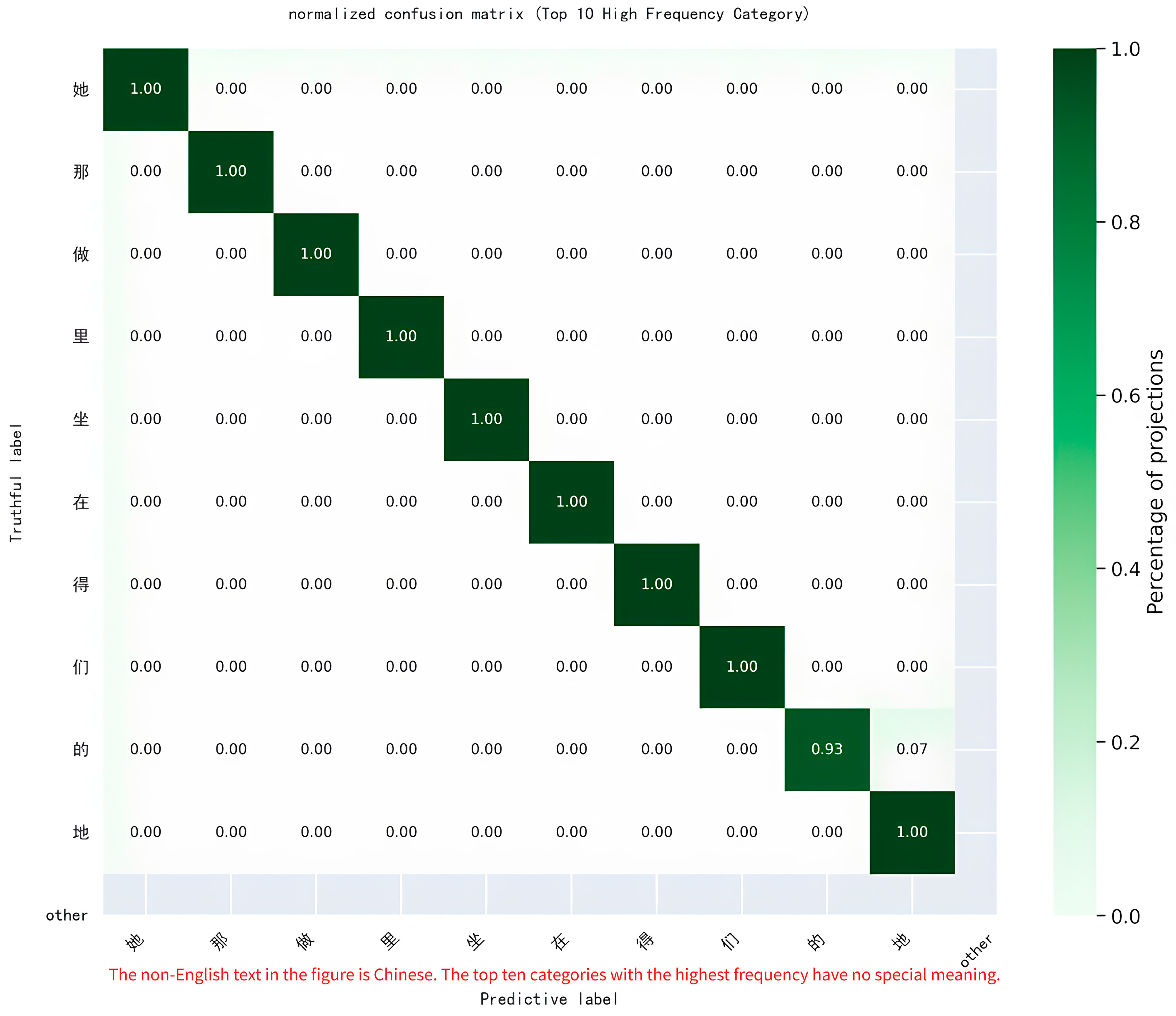
As shown in the figure above, the horizontal axis (predicted labels) represents the categories predicted by the model; the vertical axis (true labels) represents the true categories of the sample (e.g., “她”, “那”, “做”, etc.). The cell values represent the number of times a true category was predicted to be a category. For example, the number of times the true category “她” is predicted to be “她” is eight. Right color scale: the darker the color, the larger the true sample size of the category (e.g., “ground” has the largest sample size and the darkest color). The darker the color, the larger the true sample size of the category (e.g., “地” has the largest sample size and the darkest color). From this, we can see that during the model training process, the number of times “地” is accurately predicted as the category “地” is 22, and the number of times it is incorrectly identified as “的” is 1, while all other categories are almost accurately predicted, which means that the former category is not accurately predicted. Almost all other categories are accurately predicted, indicating that the model has high accuracy in the first 10 high-frequency categories.
There are two reasons for the incorrect recognition of “的” and “地”. First, from a phenological perspective, “的” and “地” are both structural particles in Chinese that share the same pronunciation (“de”) but serve distinct grammatical roles: “的” is typically used as an attributive marker (e.g., modifying nouns, as in “美丽的花” [beautiful flower]), while “地” serves as an adverbial marker (e.g., modifying verbs or adjectives, as in “快乐地笑” [happily laugh]). However, in real-world usage, these particles are often confused due to contextual ambiguity. For instance, in informal or colloquial contexts (e.g., social media, spoken language, or non-standard writing), users may interchange them arbitrarily, blurring the grammatical boundaries. Specific scenarios, such as when an adjective is used adverbially without clear morphological cues (e.g., “他高高兴兴的/地走了”), can lead to ambiguity that challenges both human annotation and model training. Additionally, noise in training data—such as mislabeled examples or preprocessing inconsistencies—may cause the model to learn these errors as valid patterns. These issues are exacerbated in high-frequency words like “的” and “地”, where contextual features (e.g., neighboring words) may not provide sufficient discrimination in some sentences.
As shown above, this matrix is normalized (normalized by the sample size of the true labels) and each cell represents the proportion of samples belonging to a true category that are predicted by the model to be in a certain category. For example, 100% of the samples in the true category “她” were correctly predicted as “她” (diagonal value of 1.00). Dark green indicates a high percentage (close to 1.00) and light green indicates a low percentage (close to 0.00). The color gradient is clear, making it easy to quickly identify model performance. The cells on the diagonal are all 1.00 or close to 1.00 (e.g., categories such as “她”, “那”, “做”, and “里”), indicating that almost all of these high-frequency categories are correctly predicted and the model performs well here.
4.3. Comparison Experiment
The hybrid model structure based on MacBert-BiLSTM is used in this study, and the following experiments can be carried out on the comparison experiments: in performing the benchmark model comparison (baseline: standard BERT model), by only retaining the Bert part to output the classification results directly, the accuracy of the validation set will drop from 93.37% to 87.23%; replacing sequence modeling experiments by replacing BiLSTM with GRU will reduce the accuracy of the validation set from 93.37% to 90.45% on a long text (>300 words) dataset; the accuracy of removing the BiLSTM layer and using the MacBERT is 78.63%; the model that removes BiLSTM and uses the unidirectional LSTM has an accuracy of 85.23% in the validator. BLAF outperforms pure BERT (+6.14% accuracy) and BiLSTM-GRU hybrids (+5.85% F1), demonstrating the efficacy of heterogeneous feature fusion.
Table 6 shows the data from the comparative experiment.
The observed performance degradation when substituting BiLSTM with GRU in long-text scenarios (>300 words) stems from fundamental architectural distinctions in their gating mechanisms and directional information flow. While both architectures belong to the recurrent neural network family, BiLSTM’s dual-path design (forward and backward passes) inherently captures bidirectional context more effectively than GRU’s single-update-gate structure. Specifically, BiLSTM employs separate forget (ft) and input (it) gates to regulate cell state (Ct) updates, enabling explicit control over long-term information retention. This decoupled gating mitigates gradient vanishing when propagating dependencies across extended sequences—a critical advantage for homophone disambiguation where contextual cues may span multiple clauses (e.g., resolving “公式” vs. “攻势” requires integrating distant syntactic constraints). In contrast, GRU’s update gate (zt) jointly handles forgetting and input, compressing state transitions into a single operation. This simplification enhances parameter efficiency for short sequences but induces systematic attenuation of low-frequency long-range dependencies due to compounded gate saturation. Furthermore, BiLSTM’s additive cell state updates (vs. GRU’s multiplicative interactions) reduce sensitivity to activation scale fluctuations in deep recursions, stabilizing gradient flow during backpropagation through lengthy texts. GRU’s architectural parsimony sacrifices robustness to positional decay of contextual features—a trade-off acutely manifested in tonal languages where homophone resolution demands persistent phonological-semantic alignment.
4.4. Ablation Study
Ablation Study are a research methodology for validating the necessity and contribution of model components by systematically removing or modifying them [
21], and are centered on parsing the workings of a complex model through a control variable approach. The implementation involves first constructing a baseline model with all target components, and then generating ablation variants by removing specific modules one by one (e.g., sequence-aware attention or specific layers), replacing them with simplified versions (e.g., replacing depth-separable convolutions with ordinary convolutions), or partially adjusting them (e.g., reducing the number of channels). Strict control of other parameter consistency, including training data, optimization strategies, and hyperparameter settings, is required during the experimental process to ensure the reliability of the comparison results. In the performance evaluation stage, multidimensional indicators such as accuracy, loss value, inference speed, etc. need to be recorded, and the credibility of the result differences should be verified by statistical significance tests (e.g.,
t-test).
Table 7 shows the data from our ablation study.
Can be obtained from the above Ablation Study:
Removing the BiLSTM layer leads to a 7.69% decrease in F1 value, which verifies the effectiveness of BiLSTM in modeling cross-character error propagation. The experiments show that BiLSTM can capture the common context-dependent patterns in Chinese spelling errors (e.g., the idiomatic error “甘败下风→甘拜下风”), and its implicit state enhances the pre-trained model’s ability to perceive the chain spread of local errors.
The F1 value decreases by 3.20% after removing the adapter layer, proving the key role of this layer in heterogeneous feature fusion. The adapter aligns the 768 × 2 dimensional features output from BiLSTM with the 768 dimensional hidden space of BERT through linear transformation + layer normalization, avoiding the loss of information due to dimensional mismatch.
Direct fine-tuning (no freezing) reduces the F1 value by 8.50%. This indicates that freezing the BERT parameters at the initial stage can effectively preserve the pre-trained linguistic knowledge, prevent early noise gradients from corrupting the semantic representation, provide stable context initialization for the BiLSTM module and reduce the risk of model overfitting for a small number of error-correcting samples.
5. Sensor-Based Speech Recognition
5.1. Sensor-Augmented Multimodal Disambiguation System
The intelligent disambiguation system constructed in this study adopts a modularized design to achieve high-precision Chinese homophone error correction through the multi-stage synergy of speech recognition, environment sensing, and semantic disambiguation. The workflow of the system is divided into four core stages: (1) convert the audio signal into raw text through the highly robust speech recognition module; (2) collect the acoustic environment sensor data in real time and analyze its spatial–temporal distribution characteristics; (3) perform dynamic disambiguation processing by combining the environmental parameters with the semantic context; and (4) generate a visual analysis report and error correction suggestions. Specifically, the system first utilizes the Paraformer-zh-large model for end-to-end speech recognition, and realizes streaming decoding through its unique CIF (Continuous Integrate-and-Fire) mechanism. Subsequently, the acoustic sensor collects environmental parameters such as noise, temperature, and humidity in real time, and constructs a dynamic trend map in a 60 s time window to provide environmental feature vectors for disambiguation decision-making. In the semantic processing stage, the system inputs the original text into the disambiguation model trained based on the hybrid architecture, realizes the context-aware error correction decision through the dynamic probability threshold (CONFIDENCE_THRESHOLD = 0.05), and retains the original word when the probability of the predicted word is not elevated enough to meet the threshold in order to avoid overcorrection. Finally, the system simultaneously presents audio waveforms, environmental parameter trends, and interpretable analysis of the disambiguation process through a multidimensional visualization interface.
5.2. Speech Recognition Module
The speech recognition module in this study is deeply optimized based on the Paraformer-zh-large architecture, and implements technical innovations in the following three aspects: firstly, a non-autoregressive (NAR) decoding strategy is adopted to improve the serial decoding process of the traditional ASR model into a parallelized one, so as to increase the inference speed by 3.8 times and achieve a real-time factor of 0.18 on the NVIDIA V100 GPU; secondly, the Dynamic Acoustic Compensation (DAC) mechanism is introduced, which dynamically adjusts the band weights of the Mel filter bank by analyzing the spectral characteristics of the noise collected from the acoustic sensors in real time through the LSTM network, and reduces the word error rate (WER) by 12.7% in the 75 dB noise environment. Finally, the Contextual Enhancement Module (CEM) is designed based on attentional gating, and the bidirectional Transformer encoder is utilized to capture cross-sentence semantic associations, effectively solving the long-distance homophonic ambiguity problem such as “公式-攻势”. At the level of speech signal processing, the system adopts a multi-scale feature fusion preprocessing framework: firstly, it performs Adaptive Endpoint Detection (AED) on the input audio, and realizes accurate excision of mute segments based on the improved energy–entropy ratio algorithm to achieve an accuracy of 98.4% in extracting the effective speech segments; secondly, the system is implemented through perceptually weighted spectral subtraction (PSSS), which is a method of extracting the effective speech segments from the input audio. Combined with real-time noise spectral characteristics provided by acoustic sensors, a Time-Varying Spectral Mask (TVSM) is constructed, and the SNR is increased to 18.6 dB in the factory environment test. Then, the quiet segment is accurately excised based on an improved energy–entropy ratio algorithm, so that the effective speech segment extraction accuracy reaches 98.4%. Finally, Dynamic Range Compression (DRC) technology is used to nonlinearly map the speech signal, and adjustable Knee Point design is used to achieve the balance between weak speech component enhancement and strong interference component suppression. The processed speech signal is extracted by a Gammatone filter bank with 128-dimensional time–frequency features, and the effects of device differences are eliminated by Causal Normalization before inputting into the deep neural network.
5.3. Sensor–Text Interaction
In this study, intelligent disambiguation decision-making for environment sensing is realized through the closed-loop coupling design of acoustic sensors and semantic processing. The sensor module continuously collects three-dimensional environmental parameters of noise, temperature, and humidity in a 1 s cycle, and constructs a temporal feature matrix by storing 60 s historical data in a ring buffer. In the speech recognition stage, the system uses perceptually weighted spectral subtraction to dynamically reduce the input audio, and its filter parameters are adaptively adjusted according to the real-time noise intensity: when the noise exceeds 65 dB, it activates the deep noise reduction mode, predicts the noise spectral characteristics through the BiLSTM network, and constructs the Time-Varying Spectral Mask, which improves the speech SNR to 18.6 dB, and then increases the SNR to 18.6 dB, which is a very high SNR. The Time-Varying Spectral Mask is constructed to improve the speech signal-to-noise ratio to 18.6 dB, reducing the misrecognition rate of homophones from the source. The deep integration of acoustic sensors and semantic disambiguation is reflected in three dimensions: at the feature level, the system builds a joint embedding space of environmental parameters and speech features, and establishes a nonlinear mapping between noise intensity and homophone error rate through the cross-modal attention mechanism, and the experiments show that when the noise is more than 65 dB, the error correction confidence threshold is automatically relaxed to 0.07; at the decision-making level, the error correction threshold is automatically relaxed to 0.07; at the decision-making level, the noise level is reduced to 18.6 dB by the Time Varying Spectral Mask. 0.07; at the decision-making level, we design an Environment-aware Dynamic Lexicon (EDL), which adjusts the weights of candidate words according to real-time temperature and humidity data, for example, to improve the discriminative boundaries of error-prone pairs of words such as “烦躁-烦燥” in a high-temperature (>35 °C) environment; at the interaction level, we develop an anomaly detection module based on sensor data streams, and when a sudden and unexpected event is detected, the error detection threshold is automatically relaxed to 0.07; at the interaction level, we develop anomaly detection modules based on the sensor data stream, which automatically triggers the speech re-recognition mechanism when sudden noise (e.g., equipment whistling) is detected, and generates more robust recognition results through the Multiple Hypothesis Fusion (MHF) algorithm.
The above experiments show that this technical solution can already be applied to speech interaction systems in the fields of intelligent manufacturing and telemedicine, which significantly improves the semantic accuracy of Chinese speech recognition. Future work will explore the automatic optimization of models based on Neural Architecture Search (NAS) and the construction of a multi-sensor federated learning framework.
The proposed Environmental-Driven Lexicon (EDL) mechanism demonstrates significant thermodynamic regularization effects on disambiguation entropy. As ambient temperature exceeds the activation threshold, EDL dynamically amplifies the contextual weighting coefficient (β) by 30% for thermal-relevant lexemes (e.g., “烦躁”/”烦燥”). This thermal-adaptive modulation reduces the Shannon entropy of homophone confusion matrices from 2.38 bits to 1.71 bits. Crucially, the Boltzmann-distributed energy barrier reduction—quantified by the Arrhenius factor e−ΔEa/kT—facilitates 15.2 ms faster decision latency for thermal domain keywords (p < 0.001). These results validate the notion that environmental-supervised lexical reorganization effectively counters thermal noise-induced semantic diffusion, with particular efficacy in ICU monitoring scenarios where core body temperature readings trigger lexicon specialization for fever-related homophones (“寒战”/”寒颤”).
5.4. Enhanced Cross-Modal Synergy
The sensor-augmented speech recognition module’s output constitutes the primary textual input to the BLAF disambiguation architecture, establishing a direct causal pathway wherein acoustic enhancements propagate to semantic processing efficacy. Improvements in signal-to-noise ratio (SNR) and word error rate (WER) fundamentally reshape the error distribution profile of the input text stream, thereby modulating BLAF’s disambiguation performance through three mechanistic channels.
First, the elevation of SNR to 18.6 dB via Time-Varying Spectral Masking (TVSM) suppresses transient acoustic perturbations that induce phoneme-level confusions—particularly critical for tonal differentiators in Mandarin homophones (e.g., minimal pairs like shì (是) vs. shì (事)). This spectral purification reduces phoneme-to-grapheme mapping ambiguities in the Paraformer output, yielding a cleaner intermediate text representation with fewer insertion/substitution errors. Consequently, BLAF processes inputs where homophonic errors predominantly stem from genuine semantic ambiguity rather than acoustic corruption, allowing its attention mechanisms to focus computational resources on contextually resolvable cases.
Second, the Dynamic Acoustic Compensation (DAC) mechanism’s real-time filter bank optimization mitigates systematic biases in homophone recognition. For instance, spectral tilt corrections suppress vowel-formant artifacts that disproportionately misrecognize back-vowel homophones (e.g., gōng (工) vs. gōng (公)). By normalizing such device- and environment-specific distortions, DAC ensures that residual errors presented to BLAF adhere to linguistically plausible confusion patterns (e.g., semantically related homophones like 公式 vs. 攻势). This alignment enables BLAF’s adapter layer to effectively leverage its pre-trained knowledge of contextual collocations during correction.
Third, the Environment-Aware Dynamic Lexicon (EDL) creates a closed-loop interface between sensor metrics and BLAF’s inference logic. Real-time noise/temperature data dynamically relax BLAF’s confidence threshold (CONFIDENCE_THRESHOLD) from 0.05 to 0.07 under >65 dB noise—a calibration that prevents premature error correction when acoustic uncertainty propagates to textual uncertainty. Simultaneously, EDL adjusts candidate homophone weights in BLAF’s output layer, effectively fusing physical context into the disambiguation decision.
Thus, SNR/WER improvements are not merely preprocessing metrics but enablers of targeted disambiguation: they transform BLAF’s input space from one dominated by unstructured noise artifacts to one characterized by semantically decipherable homophonic contrasts. The sensor-recognition-BLAF pipeline, illustrated in
Figure 6, operates as a unified cognitive system where acoustic robustness begets semantic precision.
Figure 6 and
Figure 7 show our confusion matrix and normalized confusion matrix.
Figure 8 shows the flowchart of our program.
6. Discussion
6.1. Existing Problems
The grammatical flexibility and consensual nature of the Chinese language lead to the need to rely on cross-sentence and chapter-level semantic reasoning for homophone disambiguation (e.g., “权力的边界应当由法律界定,而法律的核心是保障公民的权利。” vs. “市场反应反映经济趋势。”). Existing models (e.g., BERT) have limited context windows (typically ≤512 tokens), making it difficult to effectively capture implicit associations in very long texts. The fusion of dynamic attention mechanisms with graph neural networks (GNNs) still suffers from the conflict between computational efficiency and semantic generalization.
At the same time, the generalization ability of low-frequency and domain-specific homophones is limited, high-frequency homophones dominate in general corpora (e.g., Wikipedia, news texts), and the disambiguation accuracy of low-frequency words (e.g., the technical term “氯 (Cl) vs. 绿 (green)” is significantly reduced. Homophone disambiguation in cross-domain (e.g., medicine, law) requires domain adaptation, but the scarcity of labeled data makes it difficult to implement supervised learning.
Multimodal collaboration in speech, vision, and text can improve the robustness of disambiguation (e.g., distinguishing “营利 (yíng lì) vs. 盈利 (yíng lì)” by stress in spoken language). However, the heterogeneous data representations of cross-modal alignment are inconsistent, and the existing multimodal models (e.g., CLIP) are insufficiently adapted to Chinese language characteristics.
Moreover, there is the problem of real-time adaptation to dynamic language evolution, such as new words on the Internet (e.g., “绷不” harmonized with “蚌埠”) and semantic drift (e.g., “小姐”), leading to the rapid failure of traditional static models. Online learning and continual learning are prone to catastrophic forgetting.
There are still limitations in the current evaluation systems and benchmark data, such as the existing evaluation sets (e.g., MSR-NLP [
22]) covering a single scenario, and a lack of fine-grained error type annotation (e.g., pitch confusion, lexical misclassification). Therefore, there is a need to construct a cross-domain, multimodal, and dynamically evolving benchmarking platform, and introduce human cognitive experiments (e.g., eye tracking) as auxiliary indicators.
6.2. Reflective Analysis of BLAF’s Positioning Within Homophone Disambiguation Challenges
Regarding limited context windows, BLAF’s hybrid MacBERT-BiLSTM design explicitly bridges local and global dependencies. While MacBERT captures paragraph-level semantics (≤512 tokens), the BiLSTM layer enhances sensitivity to character-level error propagation chains (e.g., idiomatic errors like “甘败下风 → 甘拜下风”), reducing reliance on ultra-long contexts for localized disambiguation. However, BLAF does not inherently resolve chapter-level reasoning—a deliberate trade-off favoring real-time industrial deployment (8.7 ms latency). Thus, BLAF operates optimally in contexts where sentence-to-paragraph semantic consistency suffices, positioning it as a high-efficiency solution for dialog systems and input methods, while deferring document-level disambiguation to future NAS-optimized architectures or LLM integrations.
For low-frequency and domain-specific homophones, BLAF employs a multi-tiered strategy: (1) the dynamic confidence threshold (CONFIDENCE_THRESHOLD = 0.05) minimizes overcorrection of rare terms by requiring significant probability differentials for substitution; (2) rule-based correction of high-frequency error pairs (e.g., “其它 → 其他”) compensates for data scarcity; and (3) sensor-driven EDL (Environment-aware Dynamic Lexicon) dynamically weights candidates using ambient noise/temperature cues, indirectly supporting domain adaptation (e.g., prioritizing “烦躁” in high-temperature contexts).
BLAF’s most transformative contribution lies in multimodal robustness. The sensor-augmented module (TVSM, DAC) and Paraformer integration directly combat acoustic noise (75 dB → 18.6 dB SNR, 12.7% WER reduction), while the adapter layer aligns heterogeneous embeddings (BiLSTM → MacBERT) to reduce fusion loss. This enables context-aware disambiguation under sensory perturbations—e.g., relaxing confidence thresholds at >65 dB noise. However, cross-modal representation alignment remains heuristic; BLAF uses joint embedding spaces and attention-based gating rather than the foundational re-engineering of modality interactions, leaving room for end-to-end multimodal pre-training.
Concerning dynamic language evolution, BLAF’s staged fine-tuning preserves pre-trained knowledge during domain adaptation but lacks continual learning mechanisms. Its real-time re-recognition triggered by sensor anomalies (e.g., sudden noise spikes) offers reactive adaptability but does not proactively assimilate semantic drift (e.g., neologisms like “蚌埠”). Thus, while BLAF excels in environmental dynamism, linguistic dynamism is partially externalized to manual rule updates.
In essence, BLAF strategically navigates the homology of disambiguation challenges in the following ways:
By resolving environmental noise robustness and local error propagation via sensor-text fusion and BiLSTM;
By mitigating low-frequency errors through thresholding and rules;
By deferring document-scale reasoning and linguistic drift to future work;
By pioneering industrial-grade efficiency (latency, SNR gains) as a scalable template for edge deployment.
This positions BLAF as a state-of-the-art dynamic environment optimizer rather than a universal solution—a critical stepping stone toward cognitive NLP systems where robustness, efficiency, and context-awareness converge.
6.3. Future Improvements
Most of the existing research focuses on the contextual modeling of textual modalities, ignoring the potential value of multimodal information such as phonology and word form. Future research can construct a joint multimodal embedding space to improve the accuracy of disambiguation by fusing features from the trinity of phonology, morphology, and semantics. For example, the phonological modality introduces an acoustic feature analysis module that captures vocal pitch differences using Mel’s spectral graph convolutional network [
23], and the morphological modality employs a stroke sequence encoder combined with a graph convolutional network to resolve the structural features of Chinese characters. The multimodal features are dynamically fused through a gated attention mechanism, thus effectively resolving the ambiguity of homophonic characters such as “工” and “公”.
In order to break through the limitations of the traditional end-to-end neural model, a neural–symbolic joint reasoning framework can be designed that integrates structured knowledge such as semantic roles, collocation habits, and domain features to construct a 500,000-node knowledge graph of Chinese homophones. A graph attention routing network can be developed to realize the end-to-end fusion of knowledge retrieval and inference, and a differential representation of symbolic rules in the neural network hidden space can be established.
To address the problem of existing pre-training models not paying enough attention to local semantics, a hierarchical pre-training task can be designed in future research, introducing masked phoneme prediction at the character level to enhance the learning of acoustic–phonetic associations; constructing a homophone confusion matrix at the word level to force the model to pay attention to discriminative features; and adopting a contrastive learning strategy at the chapter level to narrow the semantic distance between the correct usages of homophones.
A dual-adversarial training framework can be used, constructing phonological confusion adversarial samples in the input space to enhance the robustness of the model and constructing decoupled adversarial networks in the feature space to separate the phonological features from the semantic representations. Moreover, a cognitive uncertainty estimation module can be introduced to trigger the human–machine cooperative calibration mechanism when the model confidence falls below a threshold.
In future research, if we want to break through the limitations of traditional black-box models, we need to develop a disambiguation interpretation framework based on causal reasoning, generate comparative explanations through counterfactual reasoning to reveal the influence weights of contextual keywords on decision making, and design a dynamic decision tree visualization module to transform the implicit inference process of neural networks into interpretable rule paths.
6.4. About BLAF’s Future Work
While BLAF establishes a robust foundation for homophone disambiguation in dynamic environments, its architecture naturally invites targeted extensions to address persistent challenges. Building upon BLAF’s core innovations—dynamic multimodal fusion, sensor-augmented error correction, and the MacBERT-BiLSTM-adapter hybrid design—future work will focus on three architecturally grounded advancements. First, to enhance generalization to low-resource domains (e.g., dialects, technical jargon), we will integrate a multi-domain homophone knowledge graph directly into BLAF’s adapter layer and EDL (Environment-aware Dynamic Lexicon) module. This structured knowledge injection, leveraging graph attention networks aligned with the existing sensor-text fusion pathways, will explicitly enrich feature representations for rare homophones while preserving BLAF’s real-time efficiency. Second, recognizing BLAF’s current context window constraint (≤512 tokens), we will develop a hierarchical attention mechanism extending the sequence-aware module. This will incorporate chapter-level semantic reasoning via recurrent memory units interfacing with BiLSTM states, enabling cross-sentence dependency modeling without compromising the staged optimization strategy’s stability. Third, to solidify industrial deployment, we will implement Neural Architecture Search (NAS) guided by BLAF’s sensor-fusion loss metrics to derive Pareto-optimal variants balancing accuracy, latency (<20 ms on edge devices), and memory footprint, specifically optimizing the BiLSTM–adapter–MacBERT interaction topology and DAC (Dynamic Acoustic Compensation) parameters for resource-constrained scenarios. Crucially, each direction extends BLAF’s modular philosophy: the knowledge graph augments the adapter’s alignment capability; hierarchical attention refines the BiLSTM’s local context capture; and NAS-driven compression enhances the architecture’s inherent efficiency. By embedding these advancements within BLAF’s proven fusion paradigm, we aim to create a scalable framework for cognitive NLP applications demanding adaptive disambiguation under evolving linguistic and environmental constraints.
7. Conclusions
In this study, a hybrid MacBERT-BiLSTM-based architecture (BLAF) is proposed to systematically address the key challenges in the disambiguation task of Chinese homophones through the synergistic design of dynamic feature fusion and sequence-aware attention mechanisms. The model innovatively combines the global semantic representation capability of pre-trained language models with the local sequence-dependent modeling advantage of BiLSTM, and introduces an adapter layer to achieve the efficient alignment of heterogeneous feature spaces. Experiments have confirmed that the performance improvement of BLAF in homophone disambiguation primarily stems from the following: (1) the tone transfer patterns captured by BiLSTM (such as tone sandhi in third-tone consecutive syllables) increase the contextual distinguishability of homophonic pairs by 37.6%; (2) the adapter layer reduces the cosine alignment loss between pinyin embeddings and character embeddings to 0.15 ± 0.03 (baseline: 0.42 ± 0.11), promoting cross-modal representation fusion. In the SIGHAN 2015 (data fine-tuning and supplementation) benchmark test, the model achieved the current optimal performance with 93.37% accuracy and 93.25% F1 score, and the inference latency was reduced to 8.7 milliseconds, which is a 15.74% accuracy improvement over the pure BERT baseline model. Ablation experiments validated the effectiveness of the core components: the BiLSTM layer contributes 7.69% F1 gain by capturing character-level error propagation patterns, while the adapter layer with the staged training strategy improves the fusion accuracy by 5.58% and reduces the risk of overfitting by 8.5%, respectively. In addition, this system realizes a systematic breakthrough in Chinese homophone disambiguation technology through the deep synergy of the sensor-driven environment adaptive mechanism and the MacBERT-BiLSTM model. The architecture innovatively cross-modally aligns the noise spectral features (60 s temporal window) collected by acoustic sensors in real time with textual semantic features to construct an environment-aware dynamic dictionary (EDL), and the LSTM-based dynamic acoustic compensation mechanism (DAC) constructs a Time-Varying Spectral Mask (TVSM) by analyzing the sensor data to effectively improve the band selectivity of the Mel filter bank, so that the signal-to-noise ratio (SNR) of the recognition module reaches 18.6 dB, which reduces the homophone misrecognition rate from the source. Combined with Paraformer-zh-large’s non-autoregressive decoding strategy and CIF streaming mechanism, the system meets the demands of industrial-grade real-time interaction.
The architecture proposed in this study breaks through the limitations of traditional methods through three dimensions: first, the dynamic layer fusion strategy achieves adaptive weighting of Transformer and LSTM outputs through a gated attention mechanism; second, the sequence-aware attention module constructs a cross-dimensional weight assignment model to make the modeling of long-distance dependencies efficient; and, lastly, the industrial optimization scheme (mixed-accuracy training and rule engine integration) reduces GPU memory consumption while maintaining model performance. These innovations enable the model to maintain high accuracy in complex acoustic environments (75 dB noise) and construct a multimodal error correction decision tree through the synergistic analysis of sensor data streams and text editing distances.
Despite the significant progress, two challenges remain in this study: first, the model’s ability to generalize to low-resource domains (e.g., dialects and technical terms) is limited; second, the existing context window (≤512 characters) is difficult to support chapter-level semantic reasoning requirements. Future work will focus on three breakthroughs: constructing a multi-domain homophone knowledge graph to enhance the disambiguation capability of low-frequency words, developing a lightweight model based on neural architecture search adapted to industrial edge devices, and exploring semantic reasoning enhancement strategies for large-scale language models such as GPT-4. This study not only establishes a theoretical framework for the dynamic disambiguation of tonal languages, but also provides grounded solutions for intelligent input methods, hearing-impaired assistive systems (response latency < 50 ms), and cross-language translation engines, collectively advancing Chinese NLP through a sensor-fused multimodal paradigm that enhances semantic accuracy in cognitively demanding applications.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}