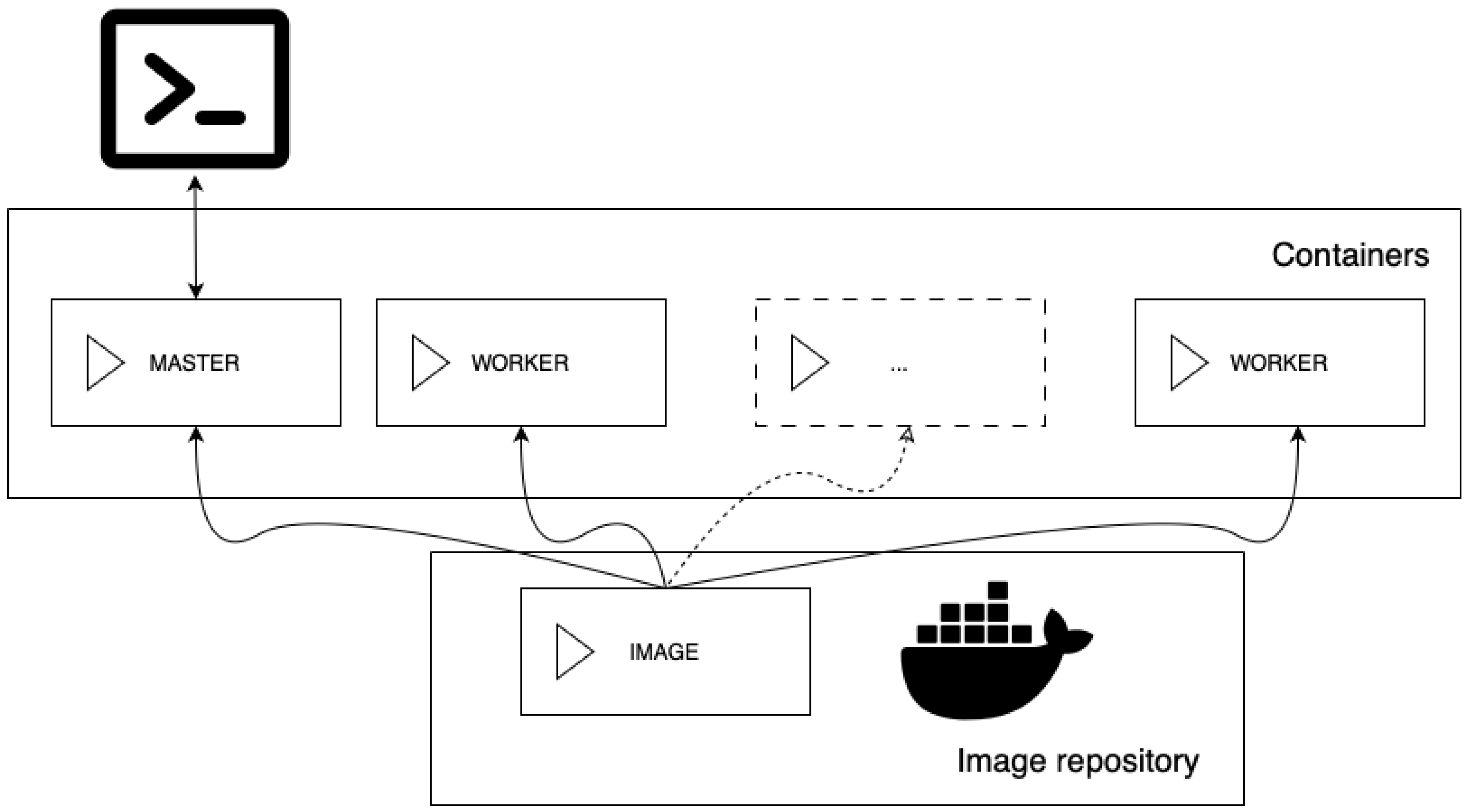
This section introduces an anomaly-detection pipeline that stresses both compute and communication layers of the container cluster.
4.2.1. Problem, Data, and Model
Data for the analysis were taken from the work in [
39]. The article [
40] describes the functioning of a web application providing access to a virtual stock exchange. The application was launched in several Docker containers in a distributed mode for load balancing. The server was subjected to artificial stress tests. Meanwhile, hardware resource usage was monitored. In each container, the percentage of CPU and RAM usage was measured every second. The results were recorded as system logs. A system administrator is always interested in these logs, especially in identifying moments of unusual activity. Knowledge of such periods helps identify times when the application did not operate as expected, e.g., due to programming errors, stability loss, or response time overruns in responding to user requests. Real-time anomaly analysis of such logs could also be part of a server’s security system. In the event of abnormal readings, the administrator would be promptly informed, after which they would have to assess the situation and possibly react to prevent ongoing attacks on the IT infrastructure, such as denial-of-service attacks.
System logs are stored in CSV file format. The first line is a header with column names. The remaining lines contain comma-separated values, including a Unix timestamp, percentage CPU load, percentage RAM usage, and a UUID identifier of the container instance for which the measurement was taken. With this data structure, two important issues should be considered:
- ‑
the data are unlabeled—it is unknown which samples are anomalies;
- ‑
the samples form time sequences—there are interdependencies between them, so they cannot be analyzed separately.
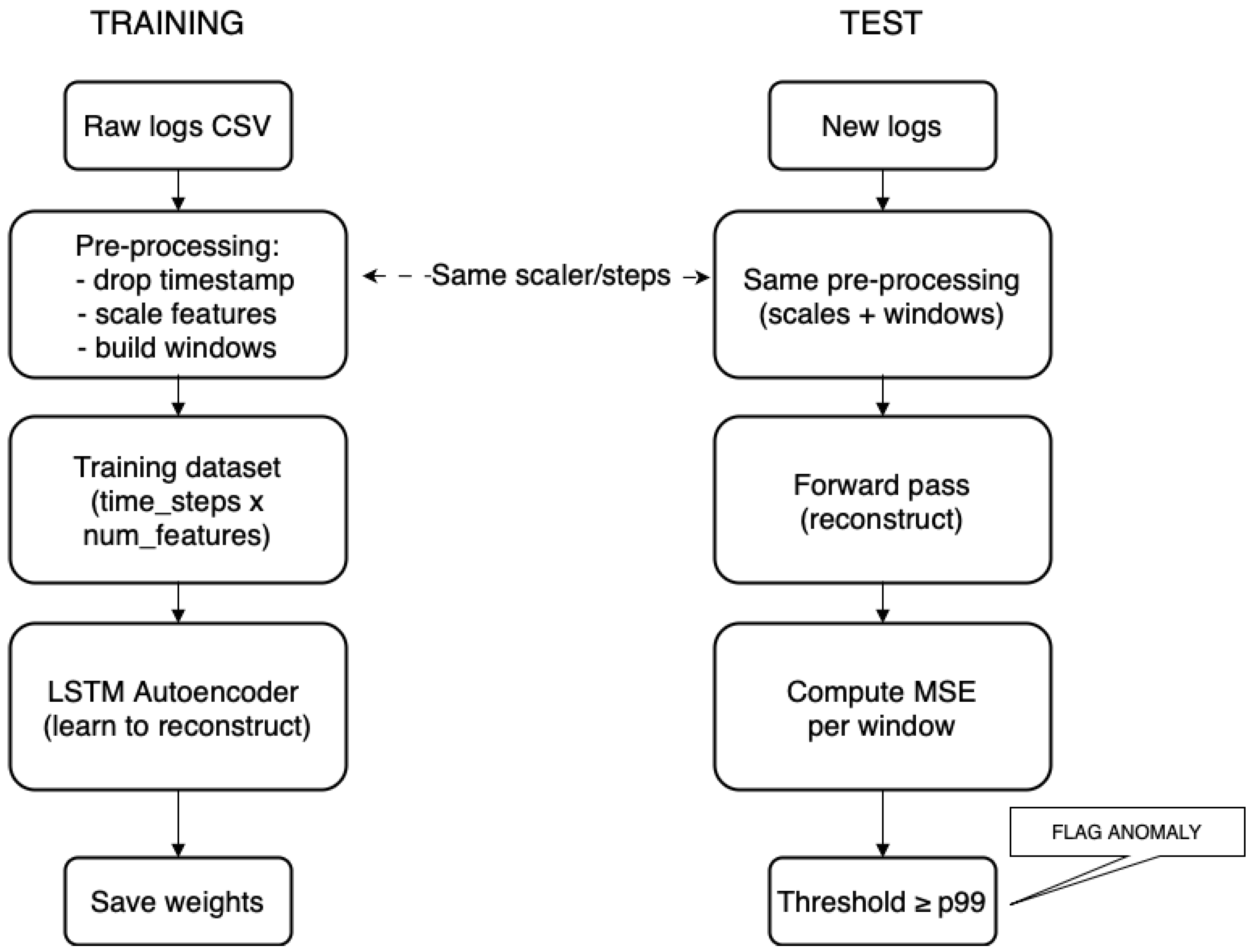
For anomaly detection, an
LSTM autoencoder neural network was used
Figure 2. The
LSTM network is considered an extension of recurrent neural networks, but it is resistant to the phenomena of vanishing and exploding gradients [
41]. As a recurrent network, it is applicable to all types of time series and has short-term memory, which transfers retained information from a certain past point in time to the current one. Additionally, it is enhanced with long-term memory, storing all previously retained information (differing from short-term memory, where one piece of information comes from a specific point) and making it available to the neuron in the current state. Internally, LSTM cells assess which information is important to remember in the context of the task being performed and update their internal state accordingly, and they can forget some information if it is deemed unnecessary after a certain time [
42].
An
autoencoder is a type of neural network trained without supervision. Its operation focuses on encoding unlabeled data. During the learning process, the autoencoder internally creates representations of the input data by discarding redundant and irrelevant information [
42]. The autoencoder has a standard sequential structure, with input, hidden, and output layers, but the most characteristic division is the encoding, decoding, and bottleneck parts. The encoding part includes the initial layers from the input side, which are responsible for transforming the input data and placing them in the bottleneck, i.e., the hidden space of reduced dimensionality. In this configuration, data dimensionality reduction occurs, effectively compressing the data. In a typical autoencoder, this is achieved because the bottleneck layer contains fewer neurons than the others. The decoding part receives the encoded information from the bottleneck and performs the reverse transformation, which becomes the output of the entire network. The role of the autoencoder is to reproduce the input data as faithfully as possible at the output.
An LSTM autoencoder applies the autoencoder concept to a setup of LSTM neurons. In an LSTM autoencoder, both the encoding and decoding parts contain layers that are LSTM networks. LSTM autoencoders are successfully used to detect anomalies in various types of time series [
42,
43,
44]. To find outliers, the data are subjected to the network, and then the reconstruction error is assessed, calculating how much the output data deviate from the input. A common measure of error in LSTM autoencoders is the mean squared error. It is necessary to establish a certain error threshold, beyond which the tested data are classified as anomalies. The underlying hypothesis is that if the network was infrequently trained using certain data or not at all, then accurately reconstructing these data would be difficult or impossible. Therefore, the larger the error, the more likely it is that the samples are anomalous. During network testing, detection was conducted on a large dataset (in a long sequence of measurements), and it was assumed that a certain percentage of anomalies existed within it, i.e., a percentile of the error distribution was rigidly chosen, with values to the left considered normal and those to the right as outliers.
The implementation of the LSTM autoencoder and anomaly detection was programmed in Python using
TensorFlow, an open-source platform dedicated to ML, especially deep learning of neural networks. TensorFlow allows for the use of state-of-the-art ML methods, providing a rich set of tools and libraries commonly used in this field. It enables the execution of time-consuming calculations in parallel on multiple processors and graphics cores. While TensorFlow itself offers the option of distributed computing on multiple machines, according to the authors of the paper [
45], this task is not the easiest and requires significant input from the programmer.
Horovod is a library that significantly simplifies the process of distributing calculations in TensorFlow. It supports the standard MPI for running parallel processes. Using it requires only minor modifications to the existing code. Internally, it operates by executing the
ring-allreduce algorithm between training epochs, which is used here to average the gradients of the neural network distributed across multiple computing nodes. At the same time,
ring-allreduce optimally utilizes the entire bandwidth of the computer network, while ensuring a sufficiently large buffer [
45]. In short, in this algorithm, each of the
n nodes communicates only with two neighbors. First, in
iterations, a node adds received values to its local buffer, and in the next
iterations, it replaces the values in its buffer with those received.
4.2.2. Design and Environment
The application directory app, located in the same location as the compose.yml file of the virtual cluster, contains the folder src with Python scripts, the file requirements.txt with a list of required dependencies, and the folder data with training data. One of the files in this folder, used during this research, is named data.csv. It stores exactly 1820 samples taken from five containers, translating to 1805 training sequences with two attributes and a length of four time steps.
The script for building the container image with the anomaly detection application is presented in Listing 1. It employs a three-stage division, as used in the presented Dockerfiles. The resulting image extends a chosen cluster node image. In the first stage, the dependencies needed in the second stage and the final image are installed: the Python interpreter version 3.9.2, and tools for building and installing the Python modules (distutils) used by the TensorFlow library.
In the second stage, Python’s package manager pip, the virtual environment tool venv, and cmake, necessary for building the Horovod module, are installed. Using venv, a virtual environment is created in the standard project folder /home/user/mpi, and its location is added to the beginning of the PATH environment variable. This ensures that tools from this environment have priority over those in the global namespace when invoked. Then, the requirements.txt file containing the application’s dependency list is copied to the container. The package manager pip reads it and downloads the indicated packages. Horovod must be installed separately as it requires manual activation of MPI and TensorFlow support using environment variables prefixed with HOROVOD_WITH. Additionally, one of the source files of the Horovod module required a small correction (line 20). Horovod automatically determines the installed MPI implementation based on the text displayed by the command mpirun --version. In newer versions of MPICH, this command displays, among other things, the word HYDRA, the name of the new process manager, which Horovod does not yet recognize. The if condition responsible for detecting the MPI implementation was modified so that Horovod also accepts this current manager.
In the last stage, the PATH environment variable from the second stage is restored to reactivate the virtual environment. A command exporting this extended variable is added to the /etc/profile shell profile, ensuring it is always available, even after logging in via SSH.
| Listing 1. Dockerfile for the anomaly detection. |
![Applsci 15 07433 i001]() |
Finally, from the second stage to the third, the prepared virtual environment is copied, and the remaining application files (scripts and training data) are transferred from the host system.
4.2.3. Implementation
This subsection only describes the most important parts of the source code of the anomaly detection application. In the project, training the neural network and detecting anomalies are divided into two separate scripts. For clarity, the code presented here is slightly modified and shortened, without additional helper functions, and all parameters stored in variables are hardcoded. In reality, most of these parameters can be changed from the command line.
Listing 2 shows a section of the code responsible for importing the necessary modules and setting parameters for ML and anomaly detection. The value normal_percentile=0.99 was chosen after a grid search (0.90–0.995) that maximized the F1-score on a hand-labeled validation subset; lower percentiles produced excessive false positives, whereas 0.995 missed short spikes.
| Listing 2. Importing modules and functions. ML and anomaly detection parameters. |
![Applsci 15 07433 i002]() |
The variables in Listing 2 have the following purposes:
- ‑
csv_file—name of the file containing training data,
- ‑
time_steps—number of samples in a single training sequence,
- ‑
learning_rate—learning rate coefficient,
- ‑
optimizer—optimization algorithm used for calculating new weights during neural network training (Adam algorithm uses stochastic gradient descent),
- ‑
loss_function—loss function (MSE—Mean Squared Error),
- ‑
epochs—number of epochs (complete training cycles using the entire training set),
- ‑
callbacks—list of callbacks controlling the learning process,
- ‑
batch_size—size of the training batch (amount of data taken at once from the dataset during training),
- ‑
normal_percentile—the percentile of the error distribution, above which values will be classified as anomalies.
Before training, the data must be read from the source and appropriately transformed. The code segment in Listing 3 accomplishes this task. Data are read from a CSV file (line 6), then the unnecessary column storing the timestamp of the measurements is removed (line 7). The feature values are normalized using the StandardScaler object, which scales them by first subtracting their means and then dividing by their standard deviations (line 11). The table is then transformed into a dictionary mapping container instance IDs to their corresponding CPU and memory usage measurements (lines 13–14).
Next, each long sequence of measurements needs to be split into smaller subsequences of size time_steps, and then all subsequences are added to a master list. This is achieved using a helper function from the Keras module (line 19). In the given time series train_series, a window of size time_steps is moved from the beginning to the end, one step at a time, extracting the contained sequences. The mentioned function returns a Dataset object, but an array of numpy.array is needed, so the received object is transformed, and then appended to the master list train_x (lines 23–25).
The sequences stored in train_x serve as both input and output data for the neural network. The network aims to replicate the given time series of size time_steps as accurately as possible. Data from train_x are fed into the network, and output values close to the input are expected. A training set train_dataset is created based on train_x (line 26), and its batch size is determined using the batch method (line 27).
| Listing 3. Code for reading and transforming training data. |
![Applsci 15 07433 i003]() |
The implementation of the LSTM autoencoder model is presented in Listing 4, and it was developed based on the article in [
46]. The network consists of sequentially arranged layers. The first layer of the network is the input, with dimensions determined by the length of the time series fragment
time_steps and the number of features
num_features. By default, the input layer accepts a matrix with dimensions of four by two. The next two layers consist of LSTM cells and serve the purpose of encoding information. The first LSTM layer has one hundred and twenty-eight cells, and the second has sixty-four. In this arrangement, data reduction (compression) occurs. Additionally, each LSTM cell recursively develops as many times as the length of the time series
time_steps (which is typically four steps). The first LSTM layer generates output signals for each individual sample taken from the time series (
return_sequences set to
True). As a result, for each of the one hundred and twenty-eight LSTM cells, four outputs are generated. In the second LSTM layer, cells have only one output each, and the signal is only generated after processing the last (fourth) sample from a given sequence.
A RepeatVector layer, serving as a kind of ‘bridge’, separates the encoding and decoding parts. It replicates the signals received from the output of the encoding part (from the second LSTM layer) as many times as the length of the time series time_steps. This step is necessary because the second LSTM layer merges the input matrix and removes the dimensions determined by time_steps, meaning that it returns a vector of encoded information at the output. The third and fourth LSTM layers decode information and have sixty-four and one hundred and twenty-eight cells, respectively, each developing four times (which resembles the encoding part, but arranged in the opposite direction). Both generate output signals for each processed sample (return_sequences is true). The final layer is a densely connected neural network (Dense), with a number of neurons equal to the number of features specified by num_features. There is also an intermediate TimeDistributed layer before Dense. At each timestep, the fourth LSTM layer produces one hundred and twenty-eight output signals simultaneously. Simply put, TimeDistributed combines these signals into single outputs, consequently leading to four outputs for each Dense neuron. In this way, the autoencoder ultimately returns a matrix at its output with the same dimensions as the input matrix.
Before training and using the neural network, its model must be compiled using the compile method (line 13). In the arguments of this function, the optimization algorithm and the loss function are set. The fit method (line 16) initiates the neural network training process. This requires the training set to be passed. Additionally, the number of epochs (epochs) and the list of callbacks (callbacks), which is normally empty, are specified. Callbacks allow for intervention in the training process and are triggered at various stages. They can be used, for example, to prematurely terminate training (if subsequent epochs do not improve the quality of the neural network) or to create checkpoints (especially useful for networks requiring time-consuming training). The fit function returns a History object that contains information about the training process. Among other things, it allows one to read how the metrics evaluating how well the neural network is replicating input values have changed over the epochs.
| Listing 4. Neural network model code for anomaly detection. Based on [46]. |
![Applsci 15 07433 i004]() |
After training the network, it can be used for anomaly detection. The code responsible for this is included in Listing 5. It is assumed that the test data stored in
test_x have the same structure as the training data in
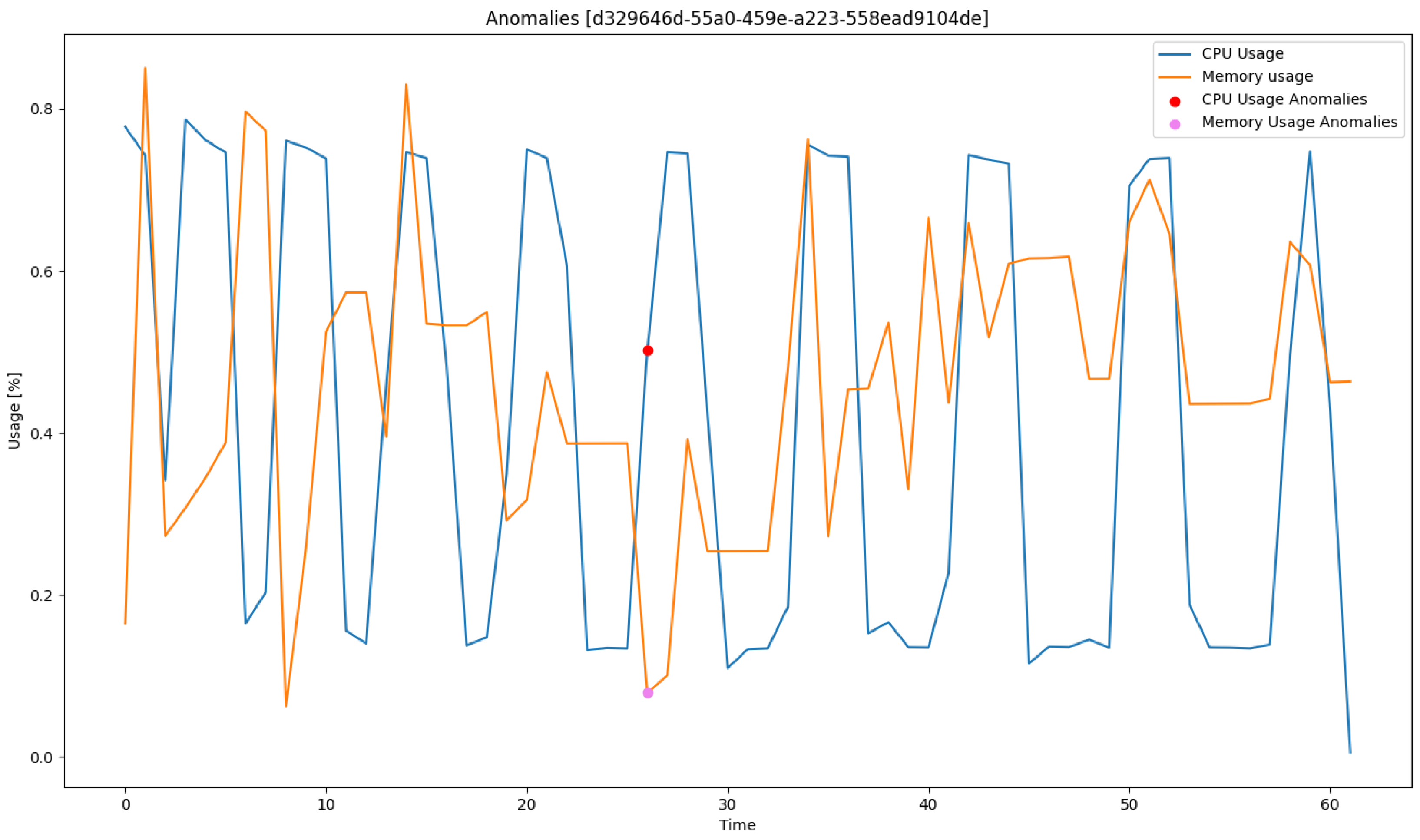
train_x and have been previously normalized. The test data are fed into the autoencoder (line 3). Based on the network’s response, mean squared errors are calculated between the received and actual time series (line 5). The resulting errors are determined separately for CPU load and memory usage measurements. Then, these errors are averaged in pairs for individual samples (line 6), resulting in a one-dimensional vector. In the distribution of errors, a percentile that separates normal values from outliers is found (line 7), based on which indices of time segments classified as anomalies are identified in the test data (line 8). Knowing these indices, outlier samples can be extracted from the original (i.e., unnormalized) test data (lines 10–14), and then visualized on a time plot, as exemplified in
Figure 3. The colored dots symbolize the occurrence of anomalies in the time plots.
| Listing 5. Code for anomaly detection with a trained network. |
![Applsci 15 07433 i005]() |
Up to this point, the implementation has only been discussed using the TensorFlow library. To enable distributed learning across multiple machines, one should add (preferably at the top of the script) the Horovod configuration code, which is presented in Listing 6. The Horovod environment is initialized (line 1), the number of parallel processes is obtained (line 2), and the rank of the current process is determined (line 3). The chosen optimization algorithm should be wrapped in a
DistributedOptimizer object (line 4), which implements an algorithm for calculating gradients at the level of a single process and updating weights only after collecting gradients from all parallel processes [
45]. In the documentation, Horovod recommends accelerating learning (in terms of the weight value increase, not time reduction) by multiplying the learning rate by the number of processes. Procedures were added to the callback list for propagating global variables from the master process to the others (line 6) and for averaging the neural network metrics (line 7).
| Listing 6. Horovod initialization and configuration. Based on [45] and documentation. |
![Applsci 15 07433 i006]() |
The Horovod platform is now ready for operation. What remains is the division of the training set among the workers, as this will enable a gain in efficiency. In the code from Listing 3, line 27 was modified to the fragment from Listing 6 at line 11. The shard method divides the dataset into as many parts as there are processes (num_workers) and selects one of them based on the rank of the process (worker_rank).
4.2.4. Methodology Supplement
Research with this application was only conducted for the scenario in which a parallel application operates in Docker containers, with its processes distributed among many containers in such a way that each container runs a maximum of one process. Such a distribution strategy forces the MPI implementation to engage the network stack for inter-process communication. There is a need to pass two environmental variables to the script. When running a program through docker exec in a container shell, it is possible to define custom environmental variables for it using the -e argument, as in Listing 7. The PYTHONHASHSEED variable sets the seed for the hash() hash generator. Assigning it a specific constant is one of the necessary steps to ensure reproducibility of neural network training. The TF_CPP_MIN_LOG_LEVEL variable allows filtering the messages printed by the TensorFlow module on the console screen. Assigning a value of two to it means silencing regular information and warnings, while errors will still be displayed.
| Listing 7. Executing a command in the master node’s shell with exported environmental variables. |
![Applsci 15 07433 i007]() |
To ensure that the given environmental variables are properly propagated to all parallel processes run by mpirun, it is necessary to use the appropriate option in the command line. In MPICH, this is achieved with the -genvlist argument, after which a list of variable names separated by commas is provided (Listing 8), and in OpenMPI, it is the -x argument, after which a single variable can be listed (Listing 9).
To run a single test, the command from Listing 10 is used. The script conducts neural network training on data from the data.csv file. The provided options have the following meanings:
- ‑
--distributed—distributed mode (initiates the Horovod environment and enables MPI support),
- ‑
--epochs 100—one hundred training epochs,
- ‑
--batch 64—a batch size of sixty-four sequences,
- ‑
--seed 1234—fixed setting of pseudorandom number generators’ seed (to ensure reproducibility of the resulting neural network),
- ‑
--no-early-stopping—no early termination of training before the set number of epochs,
- ‑
--no-output-model—the model will not be saved to a file (not needed for research),
- ‑
--silent—turning off the display of information about the progress of training.
| Listing 8. Running a test for the “MPICH Network” scenario. Propagation of environmental variables. |
![Applsci 15 07433 i008]() |
| Listing 9. Running a test for the “OpenMPI Network” scenario. Propagation of environmental
variables. |
![Applsci 15 07433 i009]() |
| Listing 10. Executing a single test with the anomaly detection application. |
![Applsci 15 07433 i010]() |
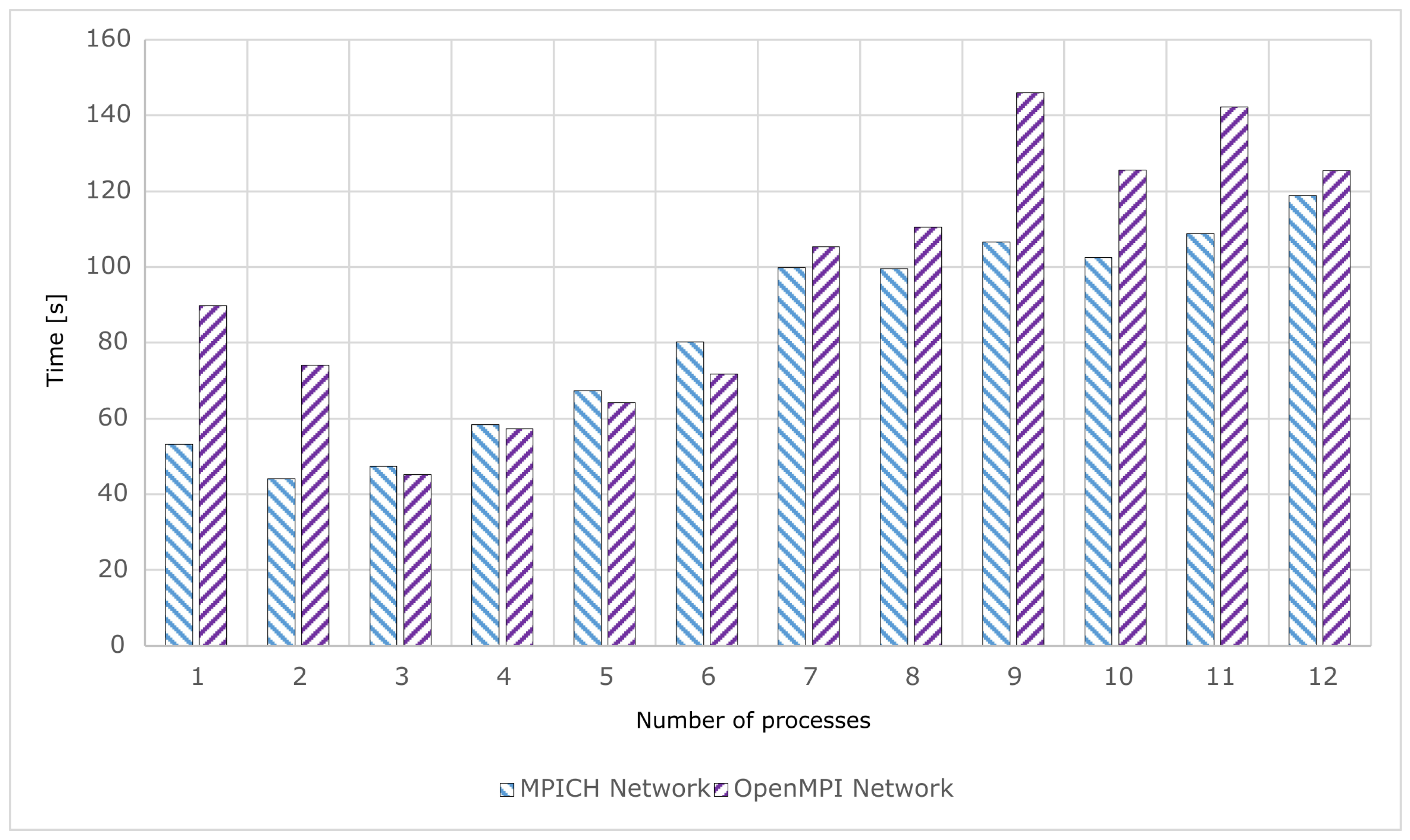
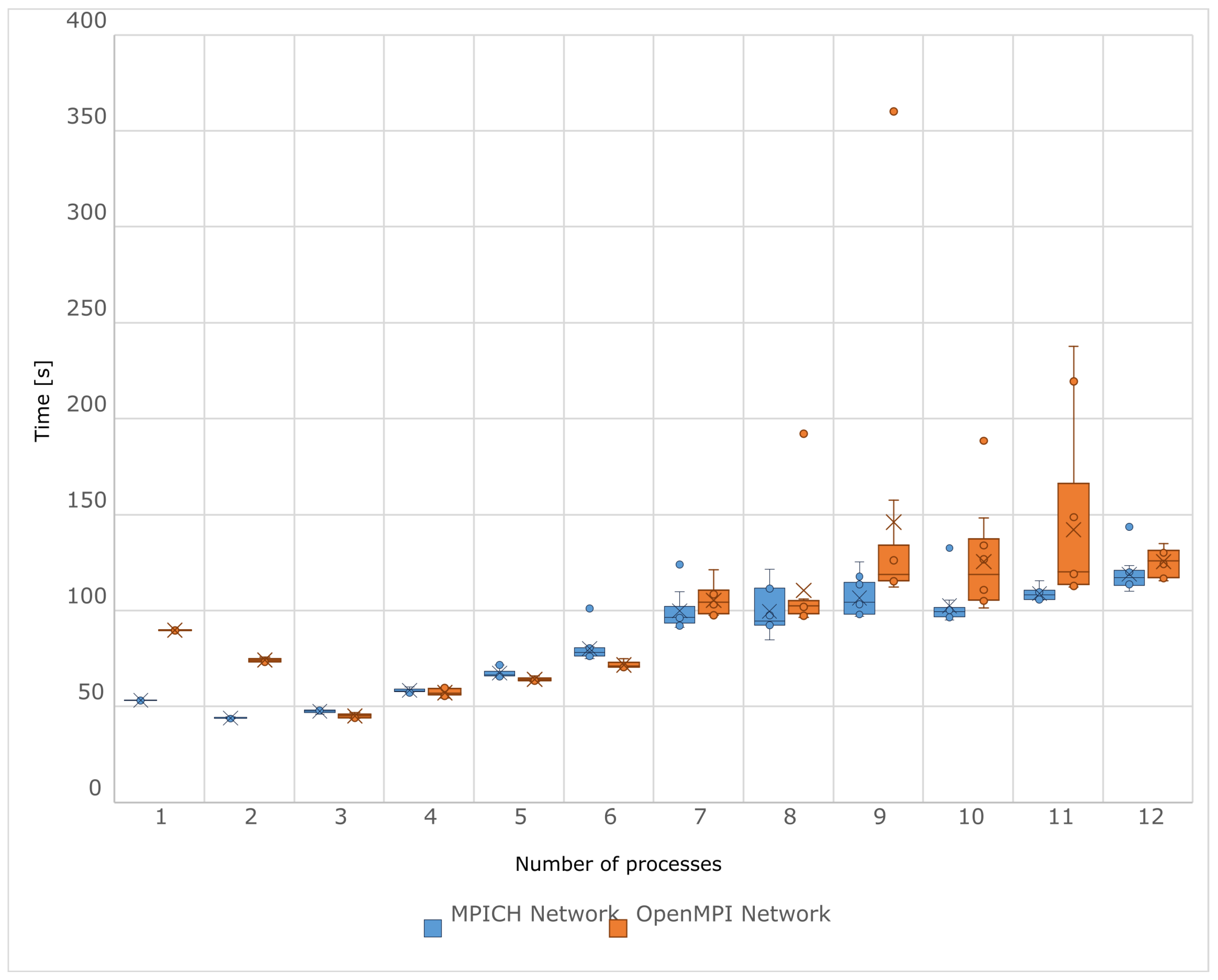
The chart in
Figure 4 shows the average execution times of the ML application for the MPICH and OpenMPI implementations. The time gain achieved due to distributed computing was not as satisfying as with applications for prime number searching and integration. With the MPICH implementation, neural network training averaged the shortest duration, with two processes, and with OpenMPI, with three processes (
Table 2). For larger numbers of processes, the average test times noticeably increased. MPICH performed worse in this regard, as the tests started to take longer from four processes upwards, compared to running exactly one process of the tested application. The same can be said for OpenMPI, but from seven processes upwards. In terms of performance, MPICH performed better than OpenMPI, especially with one and two processes. According to
Table A1, training with MPICH was almost 41% faster in those cases. For numbers of processes from three to eight, the average test times for both implementations were practically the same. Then, in the range from nine to eleven processes, significant deviations occurred, to the detriment of OpenMPI by about 23–40%.
However, the values obtained are quite unreliable for numbers of processes greater than four. The chart in
Figure 5 provides a better view of the analyzed measurements. With MPICH, when the number of processes did not exceed four, the distribution of measurements showed no significantly deviating values, its range was narrow, and the average values were very close to their corresponding medians. Unfortunately, for larger numbers of processes, the opposite situation was observed. The same occurred with the OpenMPI implementation, but questionable measurements only started from seven processes upwards. Particularly concerning are the outliers, such as the one obtained at nine processes with the OpenMPI implementation: one of the tests lasted almost 360 s, but the median of the measurements was about 118 s, and the minimum value was about 112 s. Overall, the OpenMPI implementation seemed more prone to measurement fluctuations with large numbers of processes. Therefore, measurements from a certain number of processes ceased to be stable and fundamentally lost quality. In this situation, instead of the average, it may be more reasonable to analyze the median, which is a measure characterized by resistance to extreme values. However, it is advisable to take the obtained results with a large dose of skepticism. Less reliable sets of measurements can be quickly recognized by a significantly elevated standard deviation.
However, the question remains as to why, at least in the current configuration, it is so difficult to obtain meaningful measurements. Special attention should be paid to the specifics of the computational process. The application creates many computational threads, the number of which is optimized depending on the available processor cores. The developers of TensorFlow wisely did not consider the case where someone would try to disperse computations on a single, local machine in a roundabout way, namely by creating multiple processes of such an application, instead of relying on built-in procedures that automatically manage parallel computations. Proceeding in this way quickly leads to the saturation of the operating system’s capacity for task management. Too many threads and processes cause excessive context switching. Additionally, the size of a neural network means that many operations are performed in an extensive memory space. Consequently, with a large number of processes, cache thrashing (a phenomenon well known for its performance costs) likely occurs too frequently.
Table 3 was used to analyze the scalability of the prepared application operating with the MPICH implementation. The graph and table confirm the earlier observations regarding the modest time gain from distributed computing. The expected characteristic diverged significantly from the points plotted for the measured times (in the worst case by almost 40% at two processes), not to mention the distance from the ideal characteristic, where the relative difference accumulated to about 96%. The increasing segments of the expected characteristic also signal weak scalability. With the OpenMPI implementation, for which an analogous
Table 4 is provided, the scalability of the application seemed less predictable, as determined by the irregular outline of the expected characteristic. Here, the greatest deviation in the time characteristic from the obtained average values reached about 41%, and for the ideal characteristic, the difference accumulated to 94%; so in this respect, OpenMPI performed similarly to MPICH.
The participation of inter-process communication in the context of the overall program is significant in the case of the currently analyzed application. This mainly results from the fact that between each training epoch, there is synchronization of processes and averaging of weights in distributed neural networks using the allreduce method. It should be remembered that the time cost of the allreduce algorithm performed between training epochs increases with the addition of more processes, because the neural network is not divided among sub-processes. Each of them has an identically sized structure. Therefore, the more processes, the more time needs to be allocated for averaging weights.
Since the mediocre scalability resulted partly from the overload of resources such as the processor, it might be possible to improve this by imposing restrictions on its use. Docker allows setting limits on the usage of processor time for containers. Listing 11 shows how to enable this function for a virtual cluster. Conventionally, the value of the cpus option denotes the maximum number of cores allocated to the container. In practice, the level of restriction affects the time allocation of the container’s tasks to the processor. For example, if there are two cores in the computer and the modification from Listing 11 is applied, the container will be able to load the processor to a maximum of 50% of its capacity per second.
| Listing 11. Limiting processor time for cluster containers. |
![Applsci 15 07433 i011]() |
After applying the changes from Listing 11, tests were repeated for both implementations. Thanks to the limitation on processor time with MPICH, the scalability was artificially slightly improved, as can be inferred from
Table 5. However, the results obtained were still not satisfactory. The minimum execution time shifted to five processes, and the expected characteristic became slightly more uniform. The greatest relative deviation in the expected characteristic from the average time dropped to about 28%. Unfortunately, the same could not be demonstrated with the OpenMPI implementation, as the time for each subsequent process always increased for unexplained reasons.
It has been shown that more advanced and practical applications (not necessarily written in C++) can be run on a virtual cluster. To some extent, it has been proven that a cluster is suitable for demonstrating the acceleration of calculations through algorithm parallelization. However, a certain weakness of containerization became apparent. Difficulties in confirming the scalability of distributed ML in Tensorflow partly stem from the use of virtualization at the operating system level. The limitation on the allocated processor time is not sufficient as isolation. If it were possible to attach virtual cores to containers, Tensorflow, having access to only a small set of cores, would create fewer threads per process.









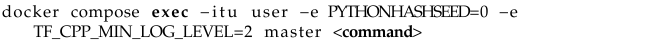
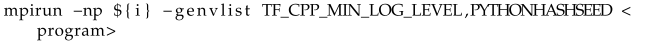
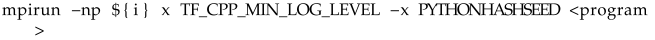
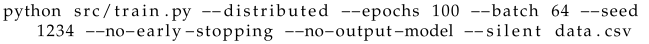




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}