1. Introduction
In the contemporary era of national fitness, there has been a notable increase in the emphasis and integration of physical activity into lifestyle practices, recognized as a pivotal strategy for enhancing physical fitness and promoting mental well-being [
1]. Yoga, a form of exercise combining flexibility, strength training, and balance, has gained worldwide popularity for its unique physical and mental conditioning effects. A notable sequence of yoga, Surya Namaskar, comprises a series of 12 asanas [
2], which have been shown to effectively enhance core strength, coordination, and whole-body function. This sequence has demonstrated significant benefits in the fields of athletic training and rehabilitation through the synergistic effect of breath and movement. However, in practice, due to a lack of professional guidance, some practitioners tend to have problems such as irregular movements and uneven load distribution, which not only reduce the training effect but also may lead to muscle injury or joint burden. Consequently, the development of an artificial-intelligence-based movement recognition and real-time feedback system is imperative to optimize the yoga training process.
This paper proposes an improved YOLOv11-ECA detection model, which optimizes the feature extraction architecture through the integration of the C3k2 and C2PSA modules and incorporates the Efficient Channel Attention (ECA) mechanism to enhance channel-wise feature dependency. These enhancements significantly improve detection accuracy for small objects and complex backgrounds while maintaining a lightweight model structure. Furthermore, the DeepSORT multi-object tracking algorithm is integrated into the YOLOv11 framework, forming a unified detection-tracking system capable of continuous dynamic analysis and evaluation of Sun Salutation movements. Compared to existing studies, the innovations of this work lie in two main aspects: First, the introduction of the ECA attention mechanism into YOLOv11 strengthens channel modeling capability. Combined with the use of small convolution kernels and a dynamic anchor strategy, the model demonstrates enhanced robustness in detecting small and occluded objects. Second, the integration of a lightweight DeepSORT tracking module enables efficient and stable motion trajectory analysis and continuity recognition in multi-person scenarios. Experiments conducted on the newly released 2024 Yoga Sun Salutation Dataset (SND2024) show that the system achieves a real-time processing speed of 45.7 FPS on an RTX 3060 platform, providing a reliable technical solution for intelligent feedback in exercise training.
2. Related Research
In recent years, the extensive utilization of AI technology in the domain of sports training has substantially accelerated the advancement of movement analysis and real-time feedback technology, particularly in the domain of yoga movement recognition and tracking, which has witnessed remarkable progress. In 2021, Wei et al. [
3] substantiated the technical superiority of AI in simulating training scenarios and optimizing exercise performance through a case study. In 2022, Zhang et al. [
4] proposed the KELM-MFF algorithm for action recognition through multi-dimensional spatio-temporal feature fusion, achieving a micro-motion recognition rate of 92.4%.
In order to promote the development of AI algorithms in the field of motion analysis, Verma et al. [
5] constructed the Yoga-82 dataset in 2020, thus establishing an important data foundation for the field of motion analysis. The dataset employs a three-tiered hierarchical labeling system for the purpose of fine-grained annotation of 82 types of yoga postures, encompassing 6618 high-resolution images. These images are distributed across five primary postures, including standing, sitting, and inverted postures, among others. The dataset also employs a dual annotation strategy of human skeletal keypoints and contour masks, providing substantial data support for subsequent multimodal modeling and recognition tasks. Subsequent to the analysis of this dataset, Yadav et al. [
6] constructed HybridNet, a hybrid model consisting of EfficientNet-B4 and DenseNet-121, in 2023. This enhanced the discriminative ability of the model through the feature channel reweighting mechanism, and its Top-1 classification accuracy reached 93.28%. However, the single-frame processing time of the HybridNet model is as high as 3.2 s, which makes it difficult for it to meet real-time requirements.
In order to address the trade-off between structural lightness and real-time performance, the Mediapipe pose estimation model proposed by Sharma et al. [
7] in 2022 combined with MobileNetV3 achieves high frame rate recognition (up to 45 FPS) for 12 phases of the Bay Day style. Despite its proficiency in single-target recognition, the system’s accuracy exhibits a decline of up to 19.7% in multi-target scenarios. This finding suggests that the single-target paradigm may not be readily adaptable to intensive multi-person training scenarios. Sim et al. [
8] further proposed a real-time workout tracking system based on MediaPipe in 2024, which achieves push-ups, pull-ups, and pull-ups through a multilayer perceptual machine (MLP) with an angle-constraint rule on the HSiPu2 data set and pull-ups with 87.6% accuracy, providing a new paradigm for low-complexity exercise feedback systems.
Multi-object tracking (MOT) remains a key research focus in the field of computer vision. Although recent studies have increasingly explored the use of large-scale models [
9] to enhance detection and tracking performance, the Tracking-by-Detection (TBD) paradigm—particularly frameworks based on the YOLO series [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20] detectors—continues to dominate due to its superior balance between accuracy and real-time efficiency. The YOLO architecture, known for its unified and lightweight design, has been widely adopted in MOT systems and consistently serves as a strong baseline in real-time perception tasks such as defect detection [
21], aerial imagery analysis [
22], and intelligent transportation systems [
23]. In 2022, Pujara and Bhamare [
24] systematically demonstrated the technical advantages of the fusion framework of the YOLO series algorithms and DeepSORT proposed by Wojke et al. [
25] in 2017 for multi-target tracking. Their proposed background suppression algorithm on the MOT20 dataset [
26] resulted in a reduction in ID switching rate by 22.4%, providing theoretical support for complex scene tracking. In 2024, Jati et al. [
27] conducted a comparative analysis of the performance of YOLO-NAS and YOLOv7/v8 in a football robotics scenario. The findings revealed that YOLO-NAS attained 91.7% of mAP in the goal alignment task. However, it exhibited suboptimal performance in the dynamic target tracking task. This observation underscores the pivotal interplay between model architecture and task suitability, highlighting the critical impact of model architecture and task relevance on performance outcomes.
With regard to detector structure optimization, Patil et al. [
28] proposed a C3-module-optimized feature pyramid structure based on YOLOv7x [
16], which achieves 88.6% mAP on a self-built dataset. However, the computational complexity of 2.4G FLOPs restricts the feasibility of its deployment on mobile. In their seminal work, Khanam and Hussain [
29] proposed a feature pyramid structure using the YOLOv11 model. This structure was developed to compress the number of model parameters to 1.8M through the C3k2 module. The authors then combined this with a dynamic anchor frame clustering algorithm. This combination was implemented to improve the AP50 of the COCO dataset by 2.3%.
In order to enhance the detection and tracking of targets by deep learning algorithms, scholars have explored the fusion strategy of lightweighting and feature enhancement in several directions. For instance, the utilization of light field technology has been demonstrated to enhance the feature expression ability and achieve improvement in image processing accuracy [
30,
31,
32]. Zhang et al. [
33] combined block labeling with an adaptive saliency mechanism to effectively improve the detection accuracy of the model. Ji et al. [
34] enhanced the model’s ability to model fine-grained targets through complex feature pyramid design. Moreover, the incorporation of the attention mechanism, particularly the emergence of lightweight modules, presents a novel opportunity to regulate the computational resource overhead while preserving model performance.
The concept of spatial attention was initially introduced by Google [
35] in 2018. This theoretical framework simulates the human capacity to allocate cognitive resources to salient regions through an effective weighting mechanism. Spatial attention has found extensive application in various domains, including image classification, target detection, and semantic segmentation, to name a few. The spatial attention module has been developed to target specific regions, thereby enhancing the precision of feature expression. The spatial attention model is concerned with the delineation of salient locations and has been demonstrated to enhance the efficacy of feature representation by directing the network to prioritize critical regions. Notable contributions in this domain include the CBAM module, as proposed by Woo et al. [
36], and the BAM structure, as proposed by Park et al. [
37]. Lightweight attention mechanisms, exemplified by SimAM [
38] and Shuffle Attention [
39], have been shown to prioritize performance optimization in scenarios where computational resources are limited. These mechanisms have emerged as a pivotal research direction for the deployment of edge devices.
In recent years, considerable attention has been directed towards channel attention (CA) mechanisms. The ECA (Efficient Channel Attention) module [
40] enhances the network’s feature selection capability without substantial increases in model complexity through local cross-channel interactions and parameter-free gating mechanisms. This module has demonstrated robust adaptability and generalization in structures such as YOLOv5 [
14], YOLOv7 [
16], and other structures that exhibit comparable adaptability and generalization.
Table 1 summarizes the aforementioned studies.
To summarize, although extant studies have achieved a certain degree of success in the detection and tracking of multiple targets in dynamic scenarios, there are two fundamental limitations that persist. Firstly, the majority of systems are predicated on offline analysis and are devoid of real-time feedback functionality. Secondly, prevailing frameworks demonstrate an inadequate adaptation to yoga-type scenes, which are characterized by occlusion and significant interference from multiple targets. The present study proposes a detection framework based on the YOLOv11-ECA improved model, which is fused with the DeepSORT tracker to construct a multi-target detection and tracking system that is capable of both real-time and accurate operation. The introduction of a dynamic anchor frame optimization strategy and a lightweight channel attention module has been demonstrated to enhance the MOTA in a high-density scene (target spacing <15 px) to 58.3% while maintaining a real-time processing speed of 45FPS. This outcome serves to substantiate the efficacy and practicality of the proposed methodology.
3. Model Introduction
The YOLOv11 [
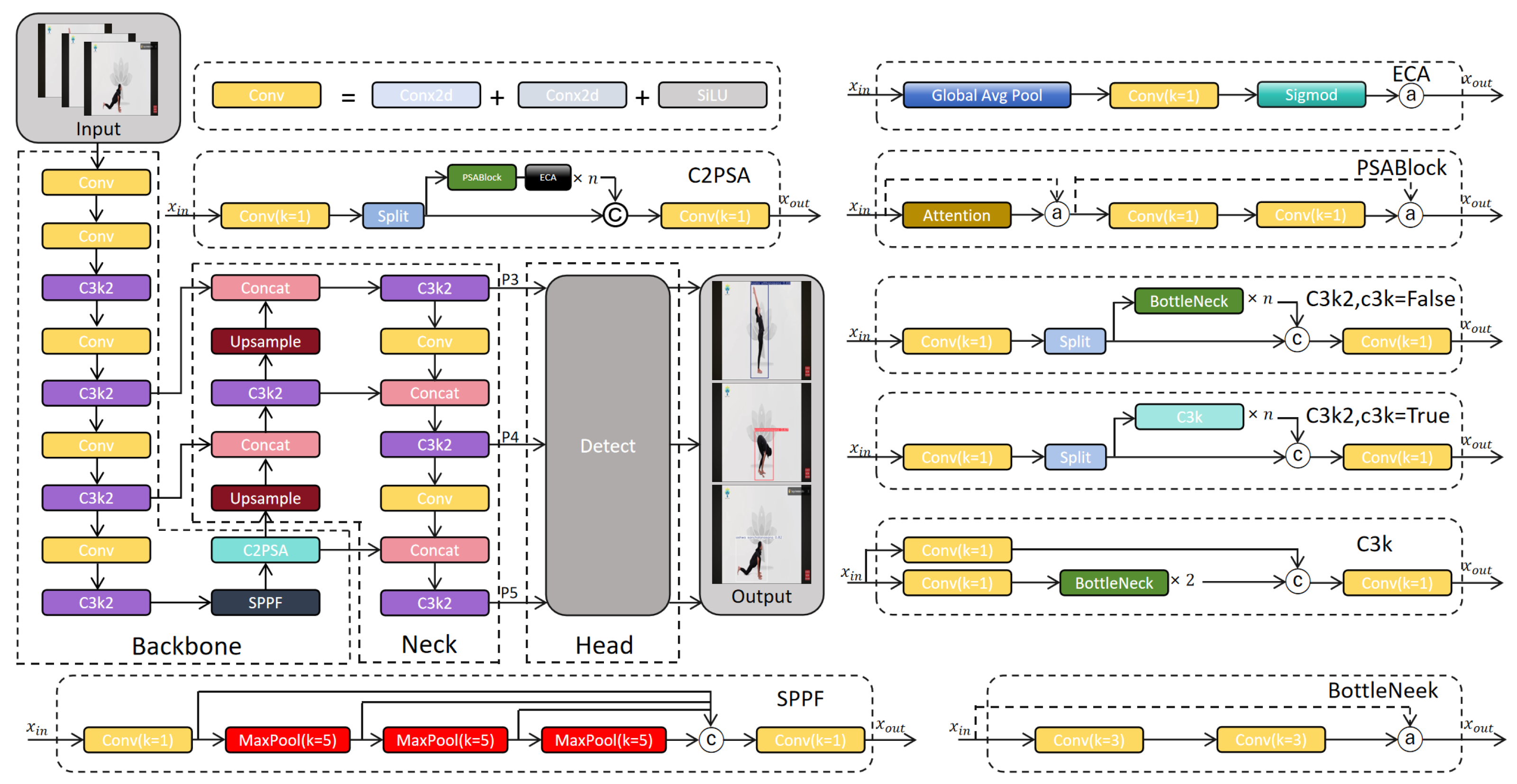
20] model employed in this study is built upon the official open-source implementation provided by Ultralytics, utilizing its Python3.9.0 interface (ultralytics==11.0.0) for model training and inference. The core codebase is derived from its GitHub repository. The model follows a three-stage architecture consisting of a backbone, a Feature Pyramid Network (neck), and a Detection Head. The conventional C2f module is replaced with the C3k2 module, which incorporates small convolution kernels and cross-stage connections to enhance feature extraction accuracy while maintaining lightweight performance. Innovatively, the model integrates a Parallel Spatial Attention mechanism (C2PSA) to improve adaptability in multi-object scenarios. Additionally, depthwise separable convolutions (DWConv) are deployed in the detection head, significantly reducing the number of parameters while preserving the advantages of multi-scale detection. This results in a synergistic improvement in both detection accuracy and inference speed.
The model configuration in this study is based on the original YOLOv11n architecture, with the integration of the Efficient Channel Attention (ECA) mechanism (Wang et al., 2020 [
40]). ECA computes channel interaction weights using an adaptive 1D convolution kernel, effectively avoiding the computational redundancy associated with fully connected layers. This reduces the complexity of channel feature recalibration from O(
) to O(C), thereby enhancing the representation of critical information.
Figure 1 illustrates the architecture of the improved model. The black box in the C2PSA module highlights the newly added ECA component, which is embedded at the end of the backbone in a plug-and-play manner. This integration enhances the model’s small object detection performance without significantly increasing computational overhead.
As shown in
Figure 1, the detection and classification process of the YOLOv11-ECA model begins by feeding input image frames into the backbone network enhanced with the Efficient Channel Attention (ECA) module. This module improves the model’s ability to represent both channel and spatial features, thereby enhancing the perception of key motion regions. The extracted multi-scale features are then fused and passed to the detection head, which outputs detection results, including bounding boxes, class probability distributions, and confidence scores. During classification, the model may predict multiple candidate bounding boxes for each frame, with each box associated with a probability distribution over eight yoga pose categories. The final classification result is determined by filtering out all boxes below a predefined confidence threshold and selecting the box with the highest confidence score as the representative pose for the current frame. The category corresponding to the highest class probability within this box is then assigned as the predicted pose. If no detection box meets the confidence threshold, the system concludes that no pose has been detected. This process ensures that the model accurately determines whether the current image contains a correct yoga pose based on the most reliable prediction.
The C2PSA module of the YOLOv11 model employs the SE (Squeeze-and-Excitation) channel attention mechanism, a sophisticated technique that enhances the model’s capacity to discern significant features through the adaptable adjustment of channel weights. The specific steps involved are as follows: firstly, the spatial information of each channel is compressed into a scalar using global average pooling (Squeeze) to obtain the channel description vector
. The channel attention coefficients
are then generated using a two-layer fully connected network (Excitation) modeling. Finally, the channel-by-channel multiplication of
with the original feature map is performed to achieve feature recalibration.
The SE module (Squeeze-and-Excitation) has been demonstrated to facilitate the enhancement of focus on important channel features at a reduced computational cost [
41]. However, it should be noted that this module has dual limitations: firstly, the lack of spatial information modeling capability leads to insufficient capture of local feature correlations; secondly, the dense parameters of the fully connected layer lead to a significant increase in computational overhead when processing high-dimensional features [
40]. To address these limitations, this study proposes the ECA (Efficient Channel Attention) module. The ECA module enhances the spatial-channel synergistic perception capability of YOLOv11 while preserving the benefit of channel attention. This is achieved by substituting the fully connected operation with a lightweight 1D convolution.
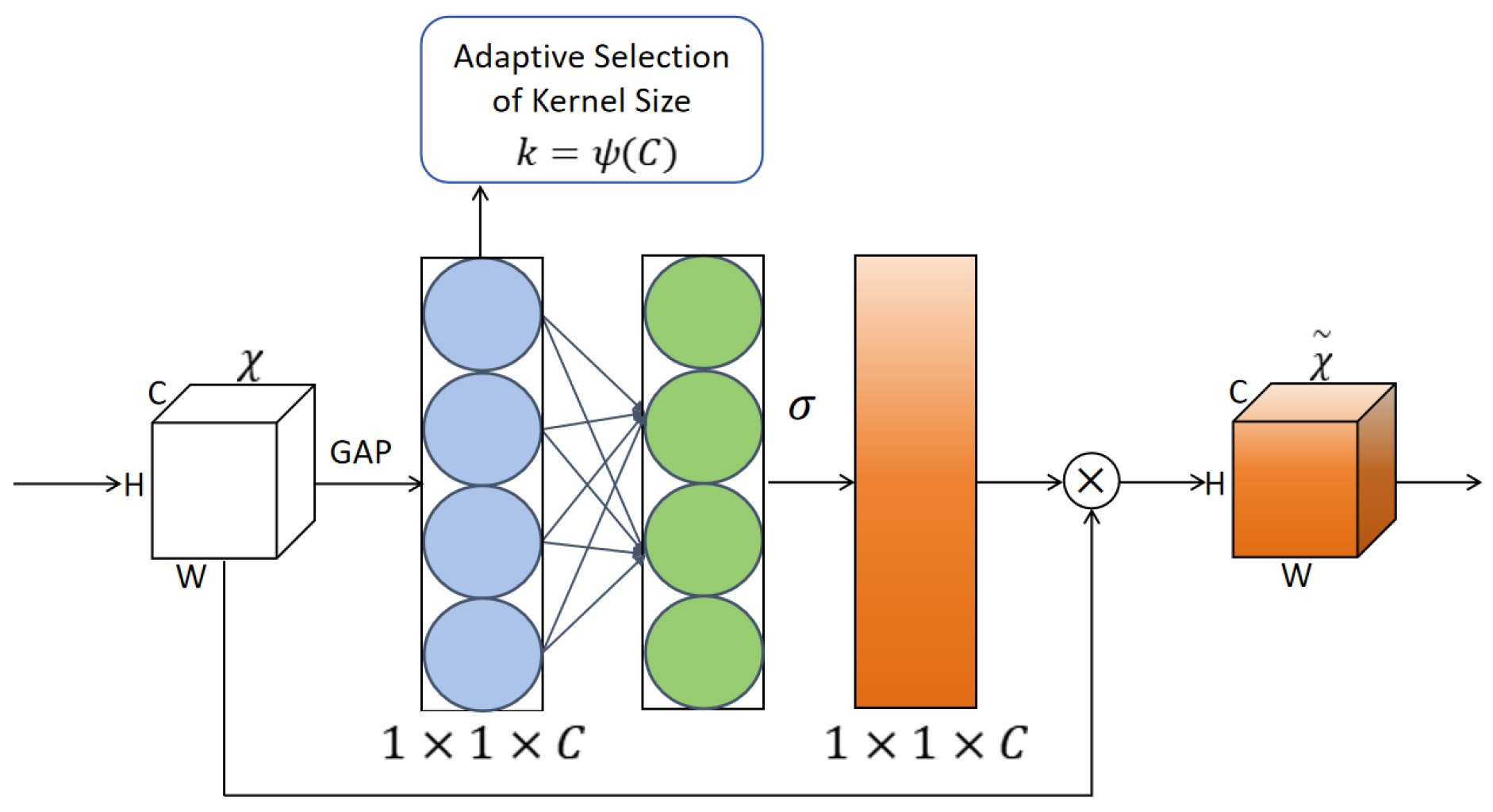
The flow of the module is as follows: firstly, the channel description vector
is obtained using global average pooling. Subsequently, local interaction is performed using 1D convolution to obtain the channel weight distribution. Finally, the channel weights are multiplied channel-by-channel with the original feature map to recalibrate the features. The formula for the ECA module is as follows:
The ECA module is responsible for the calculation of the channel interaction weights through the utilization of an adaptive 1D convolutional kernel. This process successfully avoids the computational redundancy that is typically caused by the fully connected operation. Consequently, this enhances the efficiency of the attention mechanism and ensures optimal performance in real-time target detection. The specific structure of the ECA module is illustrated in
Figure 2. The incorporation of ECA within the C2PSA module of YOLOv11 facilitates the optimization of channel weighting through local interactions, thereby ensuring that the model can allocate more precise attention to the target area, particularly in scenarios characterized by complex backgrounds and the detection of diminutive targets. Concurrently, the lightweight design of ECA maintains the real-time performance of YOLOv11, rendering it suitable for environments with limited resources.
YOLOv11 integrates the ECA algorithm into the object detection framework, which has been proven to enhance its performance in detection tasks [
42]. In mining experiments, the architecture demonstrated outstanding results even under low illumination and target occlusion scenarios, achieving a mAP@0.5 of 95.8%, significantly outperforming comparative models. The model maintains a high frame rate of 59.6 FPS while ensuring accuracy, highlighting its robustness and practical value under complex conditions.
4. Testing Experiment
4.1. Configuration
The experiment employs a high-performance device that is equipped with an Intel Core i7-12700H processor, an NVIDIA GeForce RTX 3060 graphics card, 16GB DDR5-4800 RAM, and a 512GB PCIe 4.0 SSD. The graphics card delivers up to 140W of performance, which stably supports large-scale YOLOv11 training and inference, and ensures the stability of long-time high-load operation through the dual-fan + 5 heatpipe cooling design.
4.2. Data Presentation
The present study was trained using the open-source Surya Namaskar dataset [
43], provided by Roboflow, which contains 2954 high-quality yoga bhajans images covering eight classical postures with labeled frames. The images originate from a diverse range of sources, encompassing both indoor yoga practice and natural environments.
The YOLO model imposes specific requirements on the data format; the present paper converts and preprocesses the data, chiefly by converting the annotation files to YOLO format. Subsequent to the conversion process, it is the case that each image is now aligned with a single annotation file, with each line comprising the object category number, center coordinates, and width- and height-normalized values in the following format:
[class_id center_x center_y width height]
In this study, class_id denotes the action class number (0–7), corresponding to the eight yoga actions in the dataset. centre_x and centre_y are the normalized coordinates of the center point of the target detection frame with respect to the width and height of the image, and width and height are the normalized dimensions of the target detection frame with respect to the width and height of the image.
Following processing, the dataset is divided into a training set, a validation set and a test set at a ratio of 8:1:1. The training set is used for model parameter optimization and contains diverse yoga action scenes and background data; the validation set is responsible for hyper-parameter tuning and monitoring model performance dynamics; and the test set rigorously tests the model’s actual generalization ability through independent samples. The rigorous process of data preprocessing ensures the standardization of inputs and, by extension, the enhancement of model training accuracy.
4.3. Parameter Selection
The present study is grounded in the YOLOv11 model, which has been utilized for the detection of yoga movements and the optimization of exercise training. The primary hyperparameter configurations employed during the training process are delineated in
Table 2.
During the training process, the AdamW optimizer and Automatic Mixed Precision (AMP) were employed to enhance training efficiency and reduce GPU memory consumption. The input image size was set to 640, balancing computational cost and detection accuracy. To mitigate the risk of overfitting in small-sample scenarios, weight decay (weight_decay = 0.0005) and a momentum factor (momentum = 0.937) were introduced as regularization techniques to constrain excessive parameter fluctuations, thereby improving the model’s generalization ability. Additionally, an early stopping mechanism was activated to automatically terminate training when no significant improvement was observed on the validation set over several consecutive epochs, effectively preventing overfitting. The learning rate was decayed according to the following strategy:
In this strategy, denotes the learning rate at the current epoch t, lr0 is the initial learning rate, T represents the total number of epochs, and is the decay factor. Experimental results demonstrate that the model exhibits consistent and stable performance on both the training and validation sets, ultimately achieving 98.6% mAP@0.5 on the validation set. This indicates that the overall training strategy effectively balances performance and generalization.
4.4. Evaluation Framework
To comprehensively evaluate the performance of the YOLOv11-ECA model in object detection and pose classification tasks, this study adopts a multi-dimensional evaluation framework encompassing detection accuracy, computational complexity, and multi-object tracking stability. In terms of detection performance, key evaluation metrics include the precision–recall (PR) curve, F1 curve, and mAP@0.5. The PR curve illustrates the trade-off between detection precision and recall at varying confidence thresholds. For each class, the model outputs predicted bounding boxes and associated confidence scores. By adjusting the confidence threshold, different pairs of precision and recall can be computed to generate the PR curve. The area under this curve represents the Average Precision (AP) for the corresponding class, which quantitatively reflects the overall detection performance of that class. The F1 curve captures the trend of F1 scores across different thresholds, indicating the model’s balanced performance between precision and recall. By averaging the AP values across all classes, the mean Average Precision at an Intersection over Union (IoU) threshold of 0.5 (mAP@0.5) is computed and used as the principal metric to assess overall detection accuracy.
For evaluating the model’s computational complexity and multi-object tracking performance, this study employs metrics such as FLOPs (Floating Point Operations), MOTA (Multiple Object Tracking Accuracy), and IDF1 (ID F1 Score). FLOPs quantify the number of floating-point operations required during a single forward inference pass. A lower FLOPs value indicates a more lightweight model, making it more suitable for real-time inference scenarios. MOTA provides an overall measure of tracking accuracy by accounting for missed detections, false positives, and identity switches. IDF1 evaluates the consistency of identity preservation by computing the F1 score based on correct target ID matches, thereby reflecting the quality and robustness of the tracking process.
where
is the number of false negatives at frame
t,
is the number of false positives,
denotes ID switches, and
is the number of ground truth objects.
where IDTP is the number of correctly identified detections, IDFP is the number of false positive identities, and IDFN is the number of missed ground-truth identities.
Based on the aforementioned evaluation metrics, this study conducts a comprehensive assessment of the proposed model from multiple perspectives, including detection accuracy, recall capability, inference efficiency, and multi-object tracking stability. This systematic evaluation ensures the completeness and reliability of the experimental results.
4.5. Experimental Comparisons
In this section, we perform a comprehensive comparison between the original YOLOv11 model and the improved YOLOv11-ECA model, focusing on the detection performance on the confusion matrix, normalized confusion matrix, PR curve, F1 curve, and validation set. Through detailed analyses, we find that the introduction of the ECA module significantly improves the performance of the model, especially in the detection of several key categories.
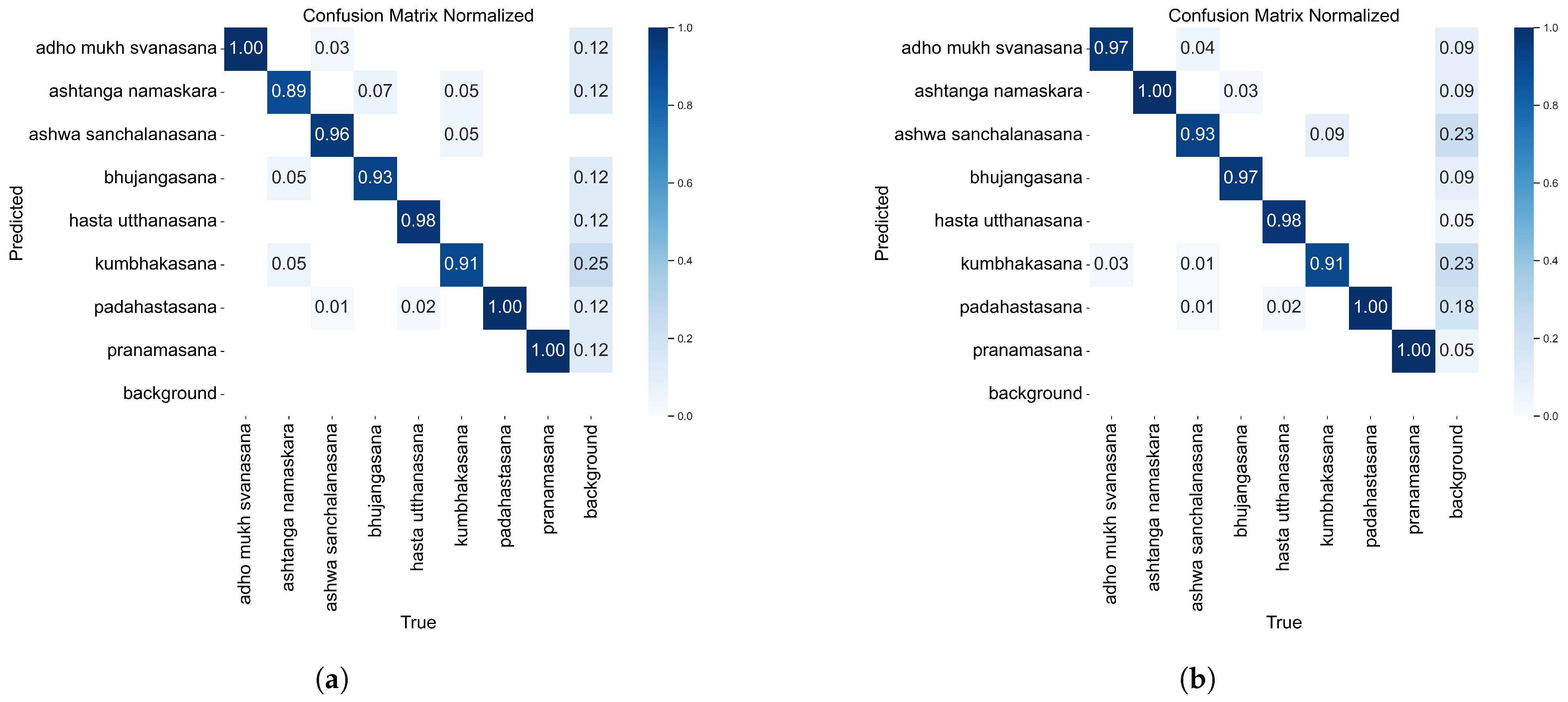
Firstly, the comparison between the confusion matrix and the normalized confusion matrix shows that the improved model achieves significant improvements in most categories. For example, in the ‘ashwa namaskara’ and ‘bhujangasana’ categories, the number of correct classifications improves from 17 and 28 to 19 and 29, respectively, and the number of misclassified samples decreases by two and one, respectively. In addition, the normalized confusion matrix for the ‘ashwa namaskara’ category shows an improvement in its correct classification rate from 89% to 100% and a significant reduction in misclassification, indicating that the improved model reduces the number of samples that would otherwise be misclassified into other categories.
In the confusion matrix plot, we show the comparison of the confusion matrix between the original model and the improved model on the validation set.
Figure 3 shows the classification results for each category, visualizing the improvement in the correct classification rate.
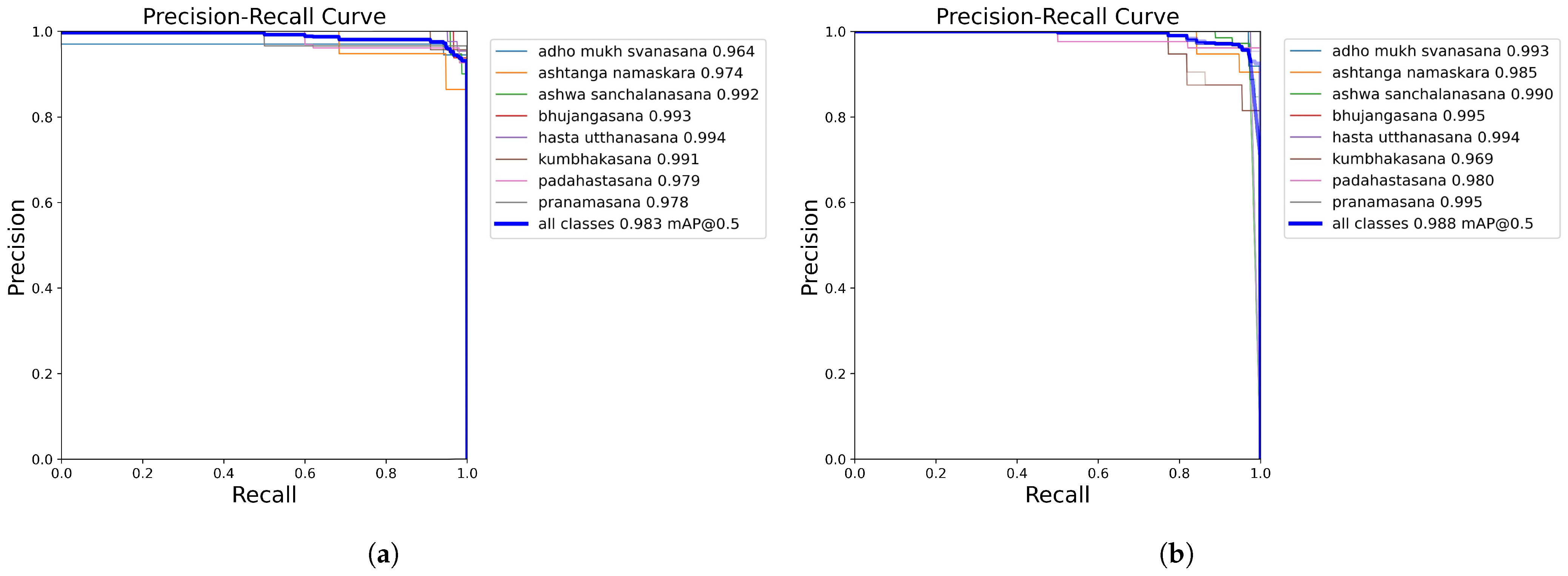
Comparing the PR curves, the improved model improves by 0.5% from 98.3% of the original model to 98.8% on mAP@0.5. Specifically, the accuracy of the ‘ashwa mukh svanasana’ category improves from 96.4% to 99.3%, and the ‘ashwa namaskara’ category also improves from 97.4% to 98.5%. Although the precision rate for the ‘kumbhakasana’ category slightly decreased, the precision rates for most categories were more consistent in the high-recall region, indicating that the improved model’s ability to capture detailed features has been enhanced.
Figure 4 shows the performance of the original model and the improved model on the PR curves, where it is clear that the improved model achieves a better balance for most categories.
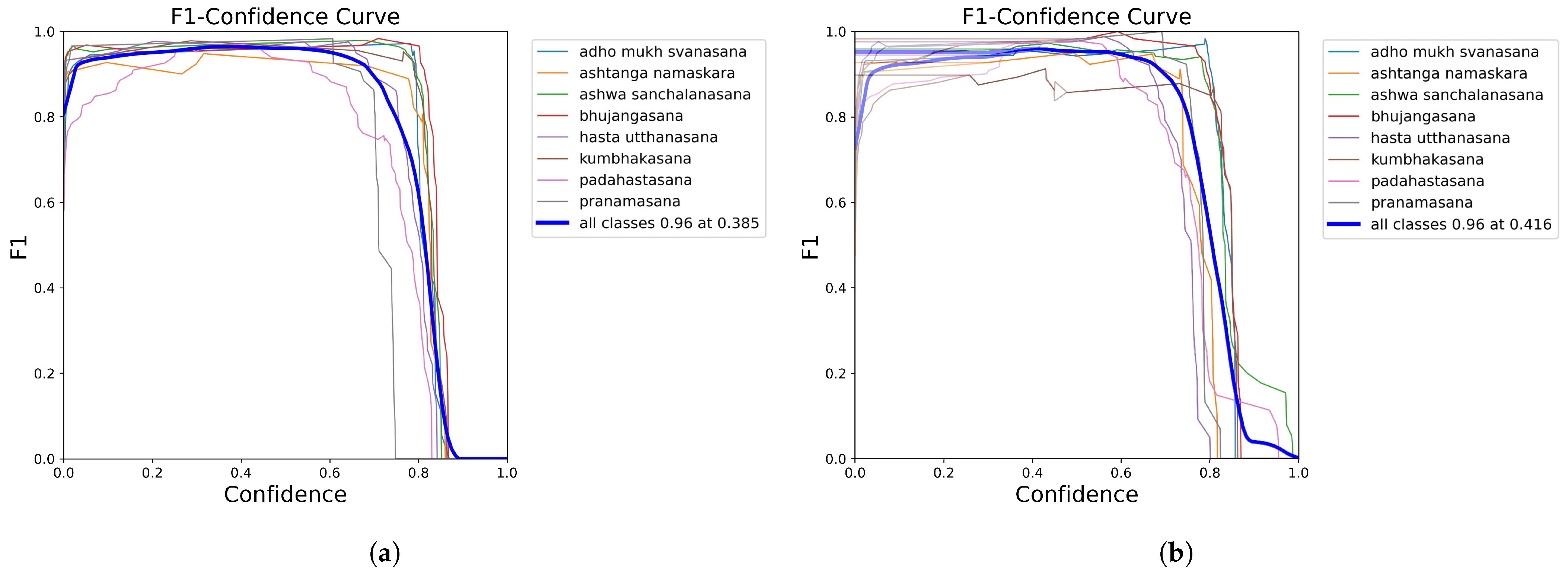
When comparing the F1 curves, both the original and improved models achieve a highest F1 score of 0.96, but the confidence threshold of the improved model is increased from 0.385 to 0.416, indicating that the model can maintain the same F1 score at a higher confidence level. The improved model is smoother in the high-confidence interval (confidence > 0.8) with less fluctuation in F1 scores, further demonstrating the ECA module’s effectiveness in optimizing the model for determining positive and negative samples.
Figure 5 shows the performance of the original model and the improved model on the F1 curve, with the improved model maintaining a higher F1 score across various confidence levels.
Finally, a comparison of the detection performance of the validation set shows that the overall performance of the improved model is significantly improved. The overall mAP@0.5 of the original model is 97.7%, and the improved model improves to 98.6%. In particular, for the categories ‘Pranamasana’ and ‘Adho Mukh Svanasana’, mAP@0.5 improves from 0.977 to 0.995 and from 0.964 to 0.993, respectively, with high levels of precision and recall. However, the performance of the ’hasta utthanasana’ and ’kumbhakasana’ categories slightly decreases from 0.987 to 0.983 and from 0.991 to 0.968, respectively.
Table 3 shows the comparison of the detection performance between the original model and the improved model on the validation set. From the table, it can be seen that the improved model achieves significant improvement in most of the categories, especially in the categories of ‘adho mukh svanasana’ and ‘pranamasana’ where mAP@0.5 improves from 0.964 and 0.977 to 0.993 and 0.995 respectively, indicating that the improved model significantly improves the detection ability in these categories. Meanwhile, the ‘ashwa sanchalanasana’ and ‘bhujangasana’ categories also show a more stable performance improvement, further validating the effectiveness of the ECA module.
According to the results in
Table 4, the performance of each detection model on the validation set varies. From the table, it can be seen that YOLOv11-ECA performs well in the precision and recall mAP@0.5 metrics, especially outperforming other models in recall and mAP@0.5, which shows its strong ability in the detection task. In contrast, the Transformer and YOLO series models also perform well, especially YOLOv6 and YOLOv10, which are close to 0.96 in precision and recall, but their overall performance is slightly inferior to that of YOLOv11-ECA.
It is important to note that the selection of baseline models in this study was primarily based on considerations of model lightweightness and practical application scenarios. Given that the task focuses on action posture classification based on camera input, which demands high detection speed and real-time performance, the YOLO series was selected as the main comparative framework. In addition, a Transformer-based model with relatively higher performance but greater computational complexity was introduced as a reference. Pixel-level segmentation models such as SAM2 were not included, as they are primarily designed for high-precision segmentation tasks, entail substantial computational costs, and are not well-suited for the requirements of this study. Considering detection efficiency, inference speed, and the alignment with the task objectives, the chosen comparative models are representative and appropriate, effectively validating the performance advantages of the proposed YOLOv11-ECA model.
In summary, by introducing the ECA module, the improved model achieves significant performance gains in several categories, especially in the three key metrics of precision, recall and mAP@0.5. Although there is a slight decrease in performance in some categories, the overall performance of the improved model shows higher accuracy and stability in most categories. This makes the improved model more suitable for real-world application scenarios, especially in dynamic environments where highly accurate recognition is required.
Figure 6 shows some of the recognition results of the YOLOv11-ECA model on the validation set. The model is able to accurately identify multiple targets and performs well in distinguishing between different action categories. At the same time, the model maintains high detection confidence in complex backgrounds. For example, most of the detection results shown in the figure have a confidence level higher than 0.8.
4.6. Masking Experiment
Table 5 shows the results of the ablation experiments to analyze the impact of the different improvements on the model performance. In experimental group 1, the original YOLOv11 (including the SE module) is used with a mAP of 0.977, an FPS of 85.99, a parameter count of 2.59 M and a FLOPs of 3.21 G, which shows high detection performance and inference speed, but the higher parameter count and computational volume reflect the redundancy of the SE module in feature extraction, and there is still room for further optimization. In experimental group 2, after replacing the SE module with the more efficient ECA module, the mAP is increased to 0.986, the parameter volume is reduced to 2.35 M, and the FLOPs are reduced to 3.11 G, while the FPS is only slightly reduced to 85.79, which shows that the ECA module is better than the SE module in feature channel enhancement and can significantly improve the detection accuracy while reducing the complexity of the model, showing that it is better than the SE module for yoga pose detection. This shows that the ECA module is better than the SE module in terms of feature channel enhancement and can significantly improve the detection accuracy while reducing the model complexity.
In experimental group 3, the removal of the Parallel Spatial Attention (PSA) module results in a mAP of 0.979, which is 0.002 higher than that of experimental group 1. Meanwhile, the FPS is increased to 89.88, the number of parameters is reduced to 2.34 M, and the FLOPs are the same as those of experimental group 2. The slight improvement in detection accuracy despite the removal of the PSA module suggests that the channel attention mechanism plays a central role in feature extraction after the introduction of the ECA module, while the spatial attention contribution of PSA is relatively limited. In addition, the significant improvement in FPS further confirms that the removal of the PSA module has significantly optimized the model inference efficiency. After the removal of all attention mechanisms in experimental group 4, the mAP recovers to 0.977, but the FPS decreases to 70.41, indicating that channel attention is a key factor in improving detection accuracy, while the removal of spatial attention plays a crucial role in optimizing inference efficiency.
The comprehensive analysis shows that the introduction of the ECA module is the key point to improve the performance of YOLOv11 in the yoga pose detection task. Compared to the SE module, the ECA module achieves higher feature enhancement through a lighter design, resulting in an increase in mAP to 0.986, while reducing the number of parameters and computation, demonstrating an excellent balance between efficiency and performance. In addition, the performance advantage of the ECA module can still be fully demonstrated after removing the PSA module, demonstrating the critical role of channel attention in feature extraction. The improved YOLOv11 achieves higher accuracy and inference efficiency in the yoga motion detection task, providing reliable technical support for subsequent research and application of related tasks.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}