Abstract
Oriented object detection in remote sensing images is a particularly challenging task, especially when it involves detecting tiny, densely arranged, or occluded objects. Moreover, such remote sensing images are often susceptible to noise, which significantly increases the difficulty of the task. To address these challenges, we introduce the Wavelet-Domain Adaptive Receptive Field Network (WDARFNet), a novel architecture that combines Convolutional Neural Networks (CNNs) with Discrete Wavelet Transform (DWT) to enhance feature extraction and noise robustness. WDARFNet employs DWT to decompose feature maps into four distinct frequency components. Through ablation experiments, we demonstrate that selectively combining specific high-frequency and low-frequency features enhances the network’s representational capacity. Discarding diagonal high-frequency features, which contain significant noise, further enhances the model’s noise robustness. In addition, to capture long-range contextual information and adapt to varying object sizes and occlusions, WDARFNet incorporates a selective kernel mechanism. This strategy dynamically adjusts the receptive field based on the varying shapes of objects, ensuring optimal feature extraction for diverse objects. The streamlined and efficient WDARFNet achieves state-of-the-art performance on three challenging remote sensing object detection benchmarks: DOTA-v1.0, DIOR-R, and HRSC2016.
1. Introduction
Lately, remote sensing rotated object detection has attracted significant research interest. This focuses on the identification and precise localization of specific objects within high-resolution satellite imagery, such as ships, aircraft, and buildings. In contrast to general object detection [1,2], objects in remote sensing images display arbitrary orientations. In this case, using horizontal bounding boxes as the object localization result is often limited when detecting densely arranged and occluded objects. The current mainstream solution involves using oriented bounding boxes that include angle information to replace horizontal bounding boxes. Oriented bounding boxes have fewer redundant regions, making them more suitable for dense scenes. Importantly, oriented object detection preserves the directional information of the target, providing crucial data for subsequent related tasks.
Recently, there has been significant progress in oriented object detection. Based on the Region Proposal, oriented detectors are categorized into two types: one-stage and two-stage oriented detectors. For instance, one-stage oriented detectors include R3Det [3], GWD [4], KLD [5], SASM [6], S2ANet [7], G-Rep [8], etc. Two-stage oriented detectors include RoI Trans [9], CSL [10], AOPG [11], ReDet [12], Oriented RCNN [13], Gliding Vertex [14], and LSKNet [15], etc. The success of these oriented detectors can be primarily attributed to the design of detection frameworks tailored for remote sensing objects. These oriented detectors have made improvements in various aspects, such as enhancing the representation of oriented bounding boxes, researching rotation-invariant feature extraction mechanisms, addressing the issue of feature misalignment, proposing loss functions better suited for oriented detectors, and proposing label assignment strategies better suited for remote sensing object detection.
Although numerous oriented object detectors for remote sensing imagery have made significant progress, the prevailing methods still rely on ResNet [16] as the backbone network. However, this design does not fully address the specific requirements of remote sensing images. First, the basic design of ResNet assumes that the boundaries between objects and backgrounds in images are relatively clear and that image features can typically be sufficiently expressed within a local context. However, remote sensing images are typically captured from a high-resolution bird’s-eye view, resulting in the presence of numerous small-sized or occluded objects, the detection of which often requires a broader contextual range and more detailed structural information. While ResNet is capable of feature extraction through deep networks, its convolution operations are confined to a local receptive field, making it difficult to capture long-range contextual information at early stages. While convolutional layers can capture some structural information, their response to small-scale and high-frequency structures is relatively weak. Due to the large stride in pooling operations and convolutional layers, detailed information (e.g., the texture and edges of tiny objects) may be lost or blurred. This makes it difficult for ResNet to capture more detailed structural information. Remote sensing images are often affected by various types of noise, making the consideration of noise robustness in detectors essential for practical applications. However, the ResNet design does not specifically account for noise interference. Particularly, when large amounts of noise are present in the image, the network may incorrectly recognize noisy regions as valid features, thereby affecting detection accuracy. Therefore, designing a backbone network specifically tailored for remote sensing image detection would contribute to improved detection accuracy.
Remote sensing images are typically high-resolution bird’s-eye views taken from satellites, and the image effects of such images are often affected by noise. Reference [17] indicates that noise may be amplified as the feature maps propagate to deeper layers of the network. This phenomenon highlights the relatively weak noise robustness of Convolutional Neural Networks (CNNs). The reason behind this is that pooling operations and strided convolution can cause the aliasing of different frequency components, resulting in the contamination of low-frequency components with high-frequency components (noise). This aliasing disrupts the integrity of low-frequency components (the basic structure of the image), thereby reducing the performance of CNNs. In digital signal processing, utilizing frequency domain analysis to enhance specific frequencies while suppressing others can effectively provide filter selectivity. Assuming that suppressing high-frequency components in the backbone network can enhance its noise robustness, it is essential to note that convolutional neural networks excel at extracting spatial features. Essentially, convolutional neural networks, as methods for analyzing signals in the spatial domain, cannot effectively suppress high-frequency components. Therefore, integrating frequency domain analysis methods with convolutional neural networks is a highly effective approach. FcaNet [18] demonstrated that Global Average Pooling (GAP) is a special case of the 2D Discrete Cosine Transform (DCT), equivalent to the lowest frequency component of the DCT. From the perspective of frequency analysis, using only GAP is equivalent to disregarding information about other valuable frequency components in the features. Selectively incorporating high-frequency components helps to address the issue of inadequate information utilized in the network. The 2D Discrete Wavelet Transform (DWT) can separate the basic structure and details of an image. After the transformation, the image is divided into four components. The low-frequency component preserves the fundamental structure of the image, while the high-frequency components retain detailed information but also introduce noise. Combining DWT and CNNs is a good attempt; selectively removing specific high-frequency components can effectively enhance the network’s noise robustness. Simultaneously, integrating partial high-frequency components effectively resolves the issue of inadequate information utilized in the network.
In remote sensing images, many objects exhibit significant variations in size, aspect ratio, dense distribution, and occlusion. Successful detection of such objects relies on extra contextual information; therefore, the effective receptive field size of the network is highly sensitive. The above viewpoint has been verified by Reference [15], and we further elaborate on this perspective.
- Enriched contextual information boosts the accuracy of the detector. As illustrated in Figure 1a, vehicles and boats typically exhibit similar shapes in remote sensing images due to their modest imaging sizes, leading to classification errors. The occurrence of these errors is because the detector only considers a small range of contextual information. Increasing the effective receptive field introduces more background information, facilitating effective and accurate classification based on whether the background is sea or road surface.
 Figure 1. Successfully detecting remote sensing objects requires appropriate contextual information. (a) cars vs. ships—small objects need local background; (b) occluded objects need long-range contextual information.
Figure 1. Successfully detecting remote sensing objects requires appropriate contextual information. (a) cars vs. ships—small objects need local background; (b) occluded objects need long-range contextual information. - Correctly detecting different objects requires varying effective receptive field sizes. Different objects have different sizes, degrees of occlusion, and backdrop complexity, leading to varying necessary receptive field sizes for successful detection. For instance, in unobstructed scenes such as aircraft, swimming pools, and tennis courts, relatively smaller receptive fields are required. However, at intersections, bridges, docks, etc., extremely large receptive fields are required because these types of objects often have large sizes and aspect ratios and are obscured by other objects, making accurate recognition challenging. As illustrated in Figure 1b, the tennis court in the upper image is clear and unobstructed, requiring only a smaller receptive field for accurate recognition. However, recognizing the tennis court in the lower image requires a broader receptive field, as the tennis court is largely obscured by tree shadows, making recognition based on appearance alone challenging.
To address these issues: (a) The noise in Remote Sensing images is amplified as the feature maps are passed to deeper layers of the network, thereby affecting the detector’s performance. (b) Successful detection of remote sensing objects necessitates appropriate sizes of contextual information. In this article, we propose a feature extraction backbone network suitable for remote sensing image object detection, termed the Wavelet-Domain Adaptive Receptive Field Network (WDARFNet). WDARFNet can extract frequency domain features, permitting the network to selectively eliminate certain high-frequency components to efficaciously enhance network noise robustness, with the objective of suppressing noise and precluding the loss of tiny object information during the down-sampling process. This provides more usable information for classification and regression and obtaining more accurate detection results. Furthermore, we propose a paradigm that integrates the selective kernel mechanism with the frequency domain analysis method, enabling the network to dynamically adjust the receptive field based on the object. The main contributions of this article are as follows.
- 3.
- To address the issue of insufficient information utilization in the network and mitigate the impact of noise on its performance, we integrate Convolutional Neural Networks (CNNs) with frequency domain analysis techniques. This integration results in a unified model, which leads to the proposal of the Wavelet Domain Channel Selection Module (WDCSM) and the Wavelet Domain Spatial Selection Module (WDSSM). Both WDCSM and WDSSM effectively combine low-frequency and high-frequency components, thereby capturing additional contours and detailed information, which enhance the network’s representational capacity. Moreover, by eliminating diagonal high-frequency components that contain substantial noise, the network’s noise robustness is improved. The WDCSM explicitly models the interdependencies between channels of feature maps and leverages global information to adaptively recalibrate the channel-wise feature responses, thereby further enhancing the network’s representational capacity. The WDSSM is capable of selecting the most suitable spatial feature information for detecting objects from various scales of large-kernel branches, thereby dynamically adjusting the receptive field size for each object in accordance with their spatial needs.
- 4.
- To adaptively adjust the receptive field of the backbone network, we integrate the selective kernel mechanism with the WDSSM. The selective kernel mechanism is implemented through a multi-branch large-kernel network, and the WDSSM effectively assigns weights to the features processed by large kernels in each branch and spatially integrates the features, thereby permitting the network to dynamically adjust the receptive field for each object in space according to specific requirements.
- 5.
- Extensive experiments have been conducted to validate the effectiveness of our proposed model on three widely used datasets: DOTA-v1.0, DIOR-R, and HRSC2016.
2. Related Work
2.1. Oriented Object Detection
Generic horizontal detection utilizes horizontal bounding boxes as the localization results. Nevertheless, objects in remote sensing images exhibit characteristics such as arbitrary orientation, dense arrangement, large aspect ratios, and substantial occlusion. Using horizontal bounding boxes for object localization would introduce a significant amount of complex background, limiting the performance of the detector. Researchers have extended the generic horizontal detection paradigm to oriented object detection by introducing oriented bounding boxes. Currently, the majority of oriented object detectors adopt the overall architecture of horizontal object detectors. This is accomplished by redefining the object representation. For example, angle information is incorporated into the regression results to facilitate oriented object detection.
The absence of feature rotation and scale invariance often limits oriented object detectors. Therefore, the design of oriented object detectors needs to consider these invariances. The two-stage detector RoI Transformer [9] proposes learning the transformation from Horizontal RoIs (HRoIs) to Rotational RoIs (RRoIs) in the first stage. In the second stage, rotation-invariant features are extracted from the rotated Region of Interest, which are subsequently used in subsequent classification and regression subtasks. ReDet [12] integrates rotation-equivariant networks into the backbone network to extract rotation-equivariant features, allowing accurate orientation prediction. In the second stage, a Rotation-invariant RoI Align operation is proposed, which adaptively extracts rotation-invariant features from equivariant features based on the orientation of the RoI.
Achieving high-precision detection of small targets in remote-sensing images is also a challenge in the field of remote-sensing object detection. References [19,20] designed a feature fusion module for the neck network, enhancing the detector’s capability to detect tiny objects. Some scholars have focused explicitly on redefining the object representation and have achieved notable results. Oriented RepPoints [21] utilizes an adaptive point representation to achieve oriented object detection. Introducing adaptive point sets as a fine-grained representation can capture the geometric structure of aerial objects with arbitrary orientations in cluttered environments. CFA [22] proposes a convex-hull feature adaptation (CFA) approach. The CFA method establishes a convex polygon to represent objects, and then dynamically selects a set of feature points on the feature map according to the geometric shape of the object, adapting to objects with irregular layouts and orientations. Gliding Vertex [14] proposes a novel bounding box localization method by sliding the vertices of a horizontal bounding box along the corresponding edges, accurately representing objects with different orientations. Meanwhile, research on loss functions specifically suited for oriented bounding boxes has yielded substantial results. GWD [4] and KLD [5] convert rotated bounding boxes into 2-D Gaussian distributions, then compute Gaussian Wasserstein distance and Kullback–Leibler Divergence as losses, respectively. Reference [23] proposes an Adaptive Rotated Convolution (ARC) module to address the challenge of difficult feature extraction in rotated object detection due to significant changes in varying orientations. The convolutional kernels in the ARC module can adaptively rotate to extract features from objects in varying orientations, accommodating significant orientation changes of the objects within the image. LSKNet [15] proposes a selectively large kernel network suitable for remote sensing object detection. It can adaptively select spatial receptive fields, enabling better contextual information extraction.
2.2. Frequency Domain in Deep Learning
Spatial and frequency domain analyses are two primary tools in signal processing. Consequently, spatial and frequency methods are essential in digital image processing downstream tasks. In recent years, Convolutional Neural Networks (CNNs) have demonstrated remarkable performance improvements in various tasks within digital image processing. However, CNNs excel at spatial feature extraction, which essentially uses spatial domain analysis methods for signal processing. In contrast, frequency domain feature extraction [24] can better capture texture information, providing significant assistance in tasks such as remote sensing image detection and segmentation. Frequency domain methods can enhance specific frequencies while suppressing others, enabling spatial filters to exhibit selectivity more easily. Combining frequency domain analysis methods with CNN convolutions is efficient because explicit selection of specific frequencies is challenging within CNNs. In recent years, scholars have explored integrating frequency domain analysis methods into the field of deep learning, achieving success in areas such as image fusion [25], image compression [26], model pruning [27], image super-resolution [28] and so on.
FcaNet [18] proposed a channel attention model in the frequency domain. By incorporating additional frequency components, this model effectively retains more high-frequency features, thereby addressing the deficiencies observed in channel attention mechanisms, which are characterized by inadequate feature representation. In comparison to DCT, Discrete Wavelet Transform (DWT) [29] has an advantage in capturing edges and other sharp features in images while also being able to represent images in a multi-resolution manner. This makes it more suitable for tasks in remote sensing image processing. Reference [30] combines the features extracted by DWT with those extracted by the backbone for image classification tasks. Reference [31] proposes a wavelet pooling algorithm to replace existing pooling operations. This method decomposes features into a second-level decomposition and retains only low-frequency sub-band information to reduce feature dimensions, thereby addressing overfitting issues associated with max pooling. WACNN [32] filters out irrelevant information in the low-frequency components by using DWT to decompose feature maps, preserving features containing low-frequency components. Simultaneously, discarding only a portion of high-frequency components allows the integration of detailed information from the high-frequency domain, achieving a Noise-Robust effect. WaveCNets [33] is designed for classification tasks. The down-sampling operation is replaced with the low-frequency components extracted by DWT. Furthermore, all high-frequency components are discarded, as random noise primarily occurs in those components. Dual Wavelet Attention [34] proposes the Wavelet Channel Attention (WCA) and Wavelet Spatial Attention (WSA). WCA treats low-frequency and high-frequency statistical features as channel scalars, effectively representing the importance of different channels. WSA incorporates high-frequency components to better capture critical structural features in the feature map. Compared to traditional spatial attention, Wavelet Spatial Attention demonstrates superior performance. MFFN [35] proposes a double-backbone network for SAR image object detection tasks, where one backbone extracts semantic information. Furthermore, the other backbone adds frequency features extracted by DWT to enrich texture information. Subsequently, the semantic and frequency features are fused to enhance the detector’s performance.
After decomposing noisy images using 2D-DWT, we found that a significant amount of noise was concentrated in the diagonal high-frequency component. In contrast, the horizontal and vertical high-frequency components primarily contained contour and detail information, with only minimal noise presence. Therefore, by discarding only the diagonal high-frequency component, we enable the network to capture more key structural characteristics in the feature maps, thereby enhancing the network’s representational capacity and effectively removing noise from the features, thus improving noise robustness.
2.3. Large Kernel Convolutional Neural Network
In recent years, vision transformer models [36,37,38,39] have undergone rapid development in the field of computer vision. The Transformer backbone with multi-head self-attention (MHSA) model possesses long-range dependencies (effective receptive fields) and adaptive spatial aggregation characteristics, which have enabled vision transformer models to achieve outstanding results in various domains. While scholars have widely recognized that models with larger effective receptive fields perform better in vision tasks, most current CNN models still rely on stacking 3 × 3 regular convolutions to enhance the network’s effective receptive field. However, even with considerable depth, networks based on stacked small-kernel convolutions still struggle to capture long-range dependencies as effectively as Transformer models, which limits their performance.
Some old-fashioned models, such as Inceptions [40] and VGG-Net [41], use large kernel convolutions to increase the effective receptive field of the network. Large kernel models gradually fell out of favor after VGG-Net. However, with the recent development of vision transformer models, scholars have also started to investigate large-kernel models for CNNs to bridge the gap between CNNs and transformers. Lsnet [42] points out that a smaller receptive field can only observe local features, leading the network to overlook relationships between features. Conversely, an excessively large receptive field can cause the network to capture too much irrelevant information, thereby reducing network performance. Therefore, selecting an appropriate effective receptive field is crucial for different vision tasks. SKNets [43] proposes a multi-branch structure with multiple large convolutional kernels. The features extracted from each branch are selectively combined in the channel dimension. SKNets endows the network with the ability to choose an appropriate receptive field adaptively. ConvNeXt [44] uses a 7 × 7 depth-wise convolution to increase the network’s effective receptive fields, significantly improving the performance of CNNs in vision tasks. RepLKNet [45] uses large kernels up to 31 × 31 to increase effective receptive fields, achieving compelling performance. SLaK [46] leverages dynamic sparsity to scale neural architectures with a 51 × 51 kernel, demonstrating that using large kernel convolutions to enhance effective receptive fields allows the network to capture richer contextual information, significantly impacting network improvement. LSKNet [15] proposes a selectively large kernel network suitable for remote sensing object detection. It can adaptively select spatial receptive fields, enabling better contextual information extraction.
3. Method
3.1. Two-Dimensional Discrete Wavelet Transform
Typically, for an image , the definition of 2D Discrete Cosine Transform (DCT) can be expressed as:
where is the 2D Frequency domain, is the input image, are the length and width of the image, respectively. FcaNet [18] demonstrates that global average pooling (GAP) is a special case of Discrete Cosine Transform (DCT). Assuming , Equation (1) is:
where is the lowest-frequency component in the 2D DCT, and it is proportional to global average pooling.
In contrast to 2D DCT, 2D DWT possesses the capability of multi-resolution analysis, which involves decomposing the image into low-frequency and high-frequency components at various scales. This allows DWT to capture both the global and local features of the image simultaneously. Additionally, the DWT decomposition process divides the image into sub-bands with varying frequencies, allowing for image denoising by selectively retaining or discarding high-frequency components.
For an image , the 2-D wavelet decomposition into four sub-bands is represented as:
where is the input image, are the length and width of the image, respectively. represents A sub-band, which is the low-frequency component and has been proven to approximate global average pooling (GAP). , where is horizontal high-frequency components, is vertical high-frequency component, is diagonal high-frequency components. and are the corresponding scaling functions of the sub-bands. The scale function output corresponds to the low-frequency component of the original signal, and the wavelet function output corresponds to the high-frequency component of the original signal. The scale function of the orthogonal wavelet basis is separable, allowing specific one-dimensional filters to be applied separately to the rows and columns of the image to obtain the desired overall 2-D response. Therefore, the 2D DWT consists of the horizontal () and vertical outputs of the 1D DWT, including a scale function and three wavelet functions .
where are the row and column of the 2D signal, respectively. and is low-pass filter and high-pass filter, respectively. Figure 2 illustrates the decomposition process of the 2D Discrete Wavelet Transform for an image. First, apply one-dimensional row filtering along each column of the image to obtain the low-frequency and high-frequency components in the horizontal direction. Then, apply one-dimensional column filtering along each row of the transformed data to obtain four different frequency sub-bands .
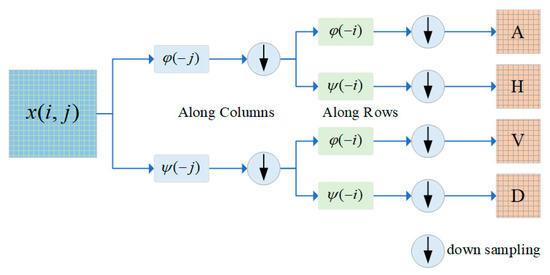
Figure 2.
Flowchart of the 2D Discrete Wavelet Transform.
Figure 3 illustrates the sub-bands resulting from the 2-D Discrete Wavelet Transform. primarily preserves the core structural information of the image, excluding random noise and redundant information. correspondingly contain detailed details in the horizontal and vertical directions. comprises diagonal detail characteristics, with low information content and is mainly composed of noise signals. Reference [47] proposes that incorporating particular wavelet bands in complex scene recognition tasks can capture minor variations in the image, which is useful for detecting tiny objects. Therefore, we choose to discard the and use the as additional effective features. This strategy not only enhances the noise robustness of the detector but also improves its feature extraction capability.

Figure 3.
Illustration of image using Haar wavelet transformation. The image on the left is the original image with added Gaussian noise. The image on the right displays the four sub-bands that are produced as the result of the 2D Discrete Wavelet Transform. is the low-frequency component, is the horizontal high-frequency component, is the vertical high-frequency component, and is the diagonal high-frequency component.
3.2. Wavelet Domain Selective Kernel Network
This section provides an overview of our method, as shown in Figure 4. The overall architecture is built upon recent popular structures [15,18,34,43]. The Wavelet-Domain Adaptive Receptive Field Network (WDARFNet) architecture consists of four stages, and the number of WDARFNet blocks in each stage is . Correspondingly, the feature channel numbers in each stage are . Each WDARF block (Figure 4) consists of a Wavelet Domain Selective Kernel (WDSK) sub-block and a Feed-forward Network sub-block. The core WDARF module (Figure 5) is embedded in the WDARF block, consisting of three modules: Selective Kernel Convolutions Module, Wavelet Domain Channel Selection Module (WDCSM), and Wavelet Domain Spatial Selection Module (WDSSM). The Selective Kernel Convolutions Module consists of two branches with large convolution kernels, explicitly constructing a series of feature maps with different receptive field ranges. Subsequently, the WDCSM and WDSSM select appropriate features in the channel and spatial dimensions, respectively. This allows the model to adjust the receptive field size for each object as needed, which will be detailed later. The Feed-forward Network sub-block is used for channel mixing and feature refinement.
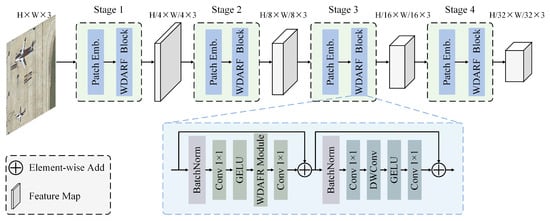
Figure 4.
Illustration of a block of Wavelet-Domain Adaptive Receptive Field Network.
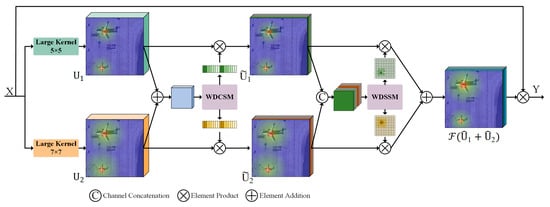
Figure 5.
Illustration of Wavelet Domain Adaptive Receptive Field Module.
3.3. Selective Kernel Convolutions
In the introduction, we mentioned that correctly detecting different objects requires varying effective receptive field sizes. In order to guarantee the network’s adaptive adjustment of effective receptive field sizes, we utilize a multi-branch structure to model a series of long-range contexts for adaptive selection. We propose to combine larger kernel convolutions and depth-wise convolutions to construct larger effective receptive field sizes. Increasing kernel size is more effective than stacking more layers in expanding the Effective Receptive Field (ERF) [44]. Therefore, a small number of large kernel layers can be utilized to build a sufficient ERF, thus saving computational budget. The saved computational budget can be used to add other effective structures, effectively enhancing the abstraction level of spatial patterns or network depth. Therefore, we introduce Wavelet Domain Channel Selection Module (WDCSM) and the Wavelet Domain Spatial Selection Module (WDSSM) to increase the network depth and enhance representational capacity.
As illustrated in Figure 5, it represents an WDARF module with dual-branch case, yet this module can be easily extended to multiple-branch case. For any given feature map , we first use depth-wise convolutions with kernels of different sizes to obtain a series of features:
where and are depth-wise convolutions with kernel sizes of and , respectively. The purpose is to explicitly generate a series of features with different receptive field sizes, facilitating subsequent kernel selection operations.
Subsequently, use convolution to reduce dimensionality for each branch:
where and are 1 × 1 convolutions, the purpose is to reduce the dimensionality of feature maps for each branch and allow mixing of features from different channels. Due to the multi-branch structure generating a series of feature maps, causing a significant increase in computational resource requirements, we reduce the channel dimension of each group of feature maps by half to mitigate computational complexity. In the following section, we propose the WDSSM and WDCSM. This mechanism dynamically selects suitable receptive fields for various objects while also enhancing the noise robustness of the network.
3.4. Wavelet Domain Channel Selection Module
In Section 3.1, we analyzed the advantages of DWT. Inspired by this, we propose the Wavelet Domain Channel Selection Module (WDCSM). FcaNet [17] proposed that GAP represents the lowest frequency component of 2D DCT. Therefore, relying solely on GAP may lead to insufficient information utilization in channel attention. FcaNet incorporates additional frequency components of 2D DCT to address this issue. Furthermore, by analyzing the sub-bands generated by 2D DWT, it is observed that the diagonal high-frequency component () includes diagonal detail features with low information content and is mainly composed of noise signals. Therefore, in the WDCSM, the diagonal high-frequency component () is discarded, and horizontal detail () and vertical detail () are used as additional effective features to generate channel descriptor, as shown in Figure 6.
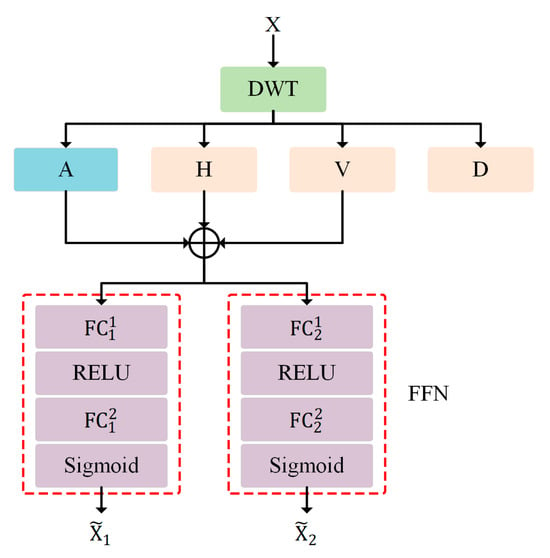
Figure 6.
Illustration of Wavelet Domain Channel Selection Module.
Specifically, the proposed WDCSM can be expressed as follows. Firstly, 2D DWT can decompose the original input into four sub-bands, as shown in Equation (5). Then, aggregate the sub-band into a channel descriptor. It can be formulated as:
Subsequently, the channel descriptor is fed into a lightweight feed-forward network to fully capture inter-channel dependencies. The WDCSM attention map can be formulated as:
where refers to fully connected layers, refers to the RELU function, and refers to the sigmoid function. The final output of the WDCSM is:
where refers to the index of the WDCSM branch, the purpose is to multiply the features extracted from the two large-kernel branches by their respective channel selection masks. As shown in Figure 5, we design the Wavelet Domain Selective Kernel module with a dual-branch structure. The Wavelet Domain Channel Selection Module explicitly models the interdependencies between channels of feature maps. Furthermore, it leverages global information to adaptively recalibrate the channel-wise feature responses, enhancing the representation capability of the network.
3.5. Wavelet Domain Spatial Selection Module
To enhance the network’s adaptive capability to select appropriate receptive field sizes for different objects, we propose the Wavelet Domain Spatial Selection Module (WDSSM). The WDSSM has the capability to select appropriate large kernels for various objects, allowing it to dynamically adjust receptive field sizes for each object based on their individual spatial requirements. Primarily, by weighting features generated by a series of large kernels in the spatial dimension, and recalibrating spatial-wise feature responses to achieve the aforementioned functionality.
Firstly, we concatenate the features generated by each branch:
Due to the need for weighting the feature maps in the spatial dimension, element-wise summation of features from different branches is not applicable. Subsequently, input the into the WDSSM, as detailed in Figure 7.
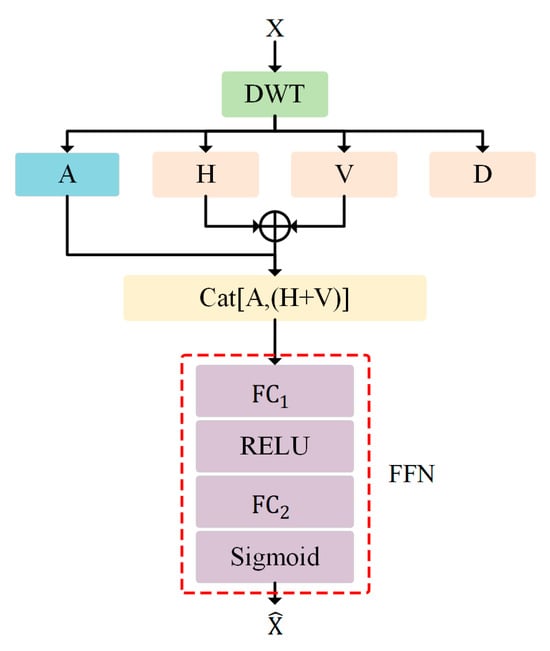
Figure 7.
Illustration of Wavelet Domain Spatial Selection Module.
WDSSM predominantly uses sub-bands derived from 2D DWT to capture a wide range of contextual information, because these sub-bands contain extensive features of key points and structures. Similar to WDCSM, WDSSM also discards the diagonal high-frequency component and aggregates components into two distinct spatial context descriptors, effectively extracting spatial relationships. The aggregation features can be formulated as:
where refers to the concatenation operation; and the attention map of Wavelet Domain Spatial Selection Module can be expressed as:
where refers to fully connected layers, refers to the RELU function, and refers to the sigmoid function. The output is a spatial selection mask composed of the spatial selection masks of two separate branches. Next, the features extracted from the two large-kernel branches are weighted by their respective spatial selection masks, and feature fusion is conducted using the convolutional layer to generate the final attention map .
The final output of the Wavelet Domain Selective Kernel Module is the element-wise product between the inputs X and the attention map. Figure 5 shows the detailed structure diagram of the Wavelet Domain Selective Kernel Module.
4. Experiments
4.1. Datasets
DOTA-v1.0 [48] is a large-scale benchmark dataset specifically designed for aerial image object detection. The images in the DOTA-v1.0 dataset were collected from various sensors and platforms. The DOTA-v1.0 dataset comprises 15 common categories, 2806 pictures, and 188,282 occurrences. The images vary in size, ranging from to pixels, and contain objects of diverse scales, orientations, and shapes.
DIOR-R [11] is a large-scale benchmark dataset for optical remote sensing image object detection. DIOR-R comprises 20 common categories, encompassing 23,463 remote sensing photos and 190,288 target instances. The images in the dataset have a size of pixels, with spatial resolutions ranging from 0.5 m to 30 m. The dataset is divided into a training-validation set, consisting of 11,725 images, and a separate test set, consisting of 11,738 images.
HRSC2016 [49] is a high-resolution remote sensing image dataset utilized for ship detection. It comprises 1061 images, encompassing information on 2976 ship instances across 4 major categories and 19 subcategories. The dimensions of ship images range from 300 to 1500 pixels, with the majority being larger than pixels.
4.2. Implementation Details
In our experiments, we report the results of detection models on DOTA-v1.0, DIOR-R, HRSC2016 datasets. WDARFNet is developed based on the MMRotate [50] platform and built within the framework of Oriented RCNN [13]. To ensure a fair comparison with other methods, we follow the same data augmentation strategy as other mainstream approaches [7,13]. In ablation studies, we adopt a scheme of training from scratch to improve experimental efficiency. To achieve higher accuracy on the aforementioned datasets, we pretrain the backbone network on the ImageNet-1K [51] dataset for 120 epochs and then fine-tune it on remote sensing datasets. We use the AdamW [52] optimizer to train the model for 36 epochs on the HRSC2016 dataset and 24 epochs on the DOTA-v1.0 and DIOR-R datasets. The initial learning rate is set to 0.0001, and the weight decay is 0.05. Model training is conducted using 2 RTX3090 GPUs (batch size of 2), and testing is performed using a single RTX3090 GPU.
4.3. Ablation Studies
In this section, we conduct a series of ablation studies to analyze how different design choices influence the performance of WDARFNet. We use Oriented RCNN [13] as the detector to conduct a series of ablation studies on the DIOR-R dataset to investigate the effectiveness of WDARFNet. We initially demonstrate that the WDSSM and WDCSM modules, which integrate convolutional neural networks with Discrete Wavelet Transforms, significantly outperform pure convolutional methods. We further show that the WDSSM and WDCSM modules enhance the network’s noise robustness. Finally, we examine the enhancement of the network through the Selective Kernel mechanism.
Kernel size (). Kernel size () and dilation () are critical factors that control the size of the receptive field (RF). To investigate their effects, we employed a dual-branch structure based on the settings of SKNet, and we present the results of the ablation study in Table 1. Table 1 demonstrates that the mAP (mean average precision) rises as the RF increases, and it indicates that increasing dilation () proves more effective at enhancing RF under similar overall complexity constraints, furthermore. This enhancement in network performance is more pronounced under conditions of relatively low overall complexity. Ablation study results indicate that the optimal parameter settings are (kernel size = 5, dilation = 1) and (kernel size = 7, dilation = 3), indicating that using a large-size kernel and higher dilation () offers slight advantages in both performance and complexity, and that an excessively small receptive field will hinder the performance of WDARFNet.

Table 1.
An ablation study of WDARFNet was conducted, exploring various combinations of kernel sizes (K) and dilation rates (D). The dataset DIOR-R was used in the experiment.
The Effects of Wavelet Domain Channel Selection Module and Wavelet Domain Spatial Selection Module. We conducted experiments to assess the effectiveness of WDCSM and WDSSM in the Wavelet Domain Selective Kernel module, with the corresponding ablation study results depicted in Table 2. We validated the effectiveness of WDCSM and WDSSM by replacing the backbone networks; Experiment 1, as depicted in Table 2, utilizes ResNet50 as its backbone, whereas Experiments 2 and 3 employ solely WDCSM or WDSSM, respectively, and Experiment 4 implements the complete WDARFNet as its backbone. The results of the ablation experiments reveal that both WDCSM and WDSSM improve network performance compared to the baseline ResNet50. Compared with the proposed WDCSM, the performance of the proposed WDSSM is more improved. This is attributed to WDSSM’s effective assignment of weights to the features processed by large kernels in each branch and its spatial integration of these features, thereby allowing the network to dynamically adjust the receptive field for each object in space according to specific requirements. Furthermore, the combined use of WDCSM and WDSSM yields a marginal improvement in network performance over employing WDSSM alone.
Table 2.
An ablation study was conducted to evaluate the effectiveness of the proposed WDCSM and WDSSM modules. The DIOR-R dataset was utilized in this experiment.
Noise-robustness. Convolutional neural networks are generally susceptible to noise interference. As feature maps propagate through deeper layers of the network, the noise is amplified successively, resulting in incorrect final predictions. To address the aforementioned issue, we propose a Wavelet Domain denoising strategy to enhance the network’s noise robustness. Subsequently, ablation experiments were conducted to verify the effectiveness of WDARFNet. In the training stage, ResNet50 and WDARFNet were used as backbone networks to train models on the clean DIOR-R training set for 12 epochs, respectively. In the testing stage, the clean DIOR-R testing set, and the Gaussian-noise-added DIOR-R testing set were selected as test datasets to evaluate ResNet-50 and WDARFNet, respectively. The corresponding ablation study results are presented in Table 3. The ablation study results show that after adding Gaussian noise with a mean () of 0 and a standard deviation () of 10 to the testing set, the mAP using ResNet50 as the backbone network drastically fell to 46.52%, which is a significant decrease of 13.80% compared to the results on the clean test set. When using the WDARFNet backbone network, the mAP fell to 56.61%, which is only a decrease of 8.72% compared to that on the clean test set. After adding Gaussian noise with and to the test set, the mAP using ResNet50 as the backbone network drastically fell to 31.18%, whereas the mAP using WDARFNet as the backbone network is 48.19%. This indicates that WDARFNet can effectively maintain object structure and suppress noise during network inference. Figure 8 presents two examples of the heatmaps for the well-trained ResNet50 and WDARFNet models, using noisy images as input. The first row displays the clean image and the heatmaps of ResNet50 and WDARFNet. The second and third rows show the images with added Gaussian noise (μ = 0, σ = 10) and (μ = 0, σ = 25), respectively, along with the heatmaps generated by the two networks. These two examples demonstrate that the original CNN has difficulty suppressing noise, whereas WDARFNet can effectively suppress noise and concentrates its attention primarily on or around the object during the inference process. Consequently, WDARFNet achieves superior detection accuracy in various challenging situations.
Table 3.
Ablation study on the noise robustness of WDARFNet. The DIOR-R dataset was utilized in this experiment.
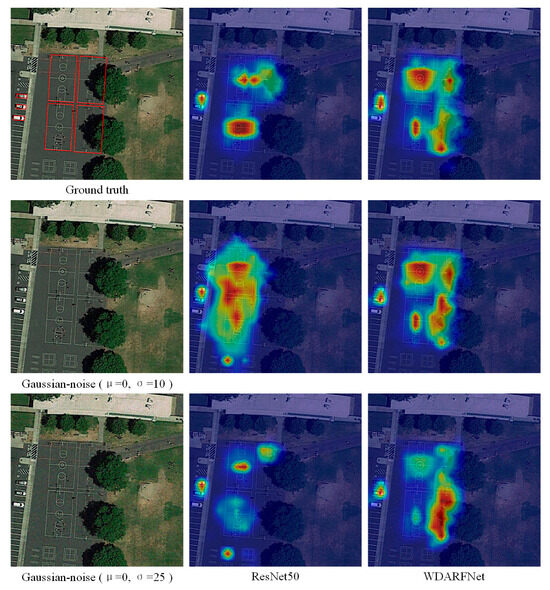
Figure 8.
Visualization analysis of heatmaps illustrating feature activation for ResNet50 and WDARFNet, derived from clean (top) and noisy (bottom) images. This comparison highlights the improved noise suppression and object focus of WDARFNet.
Selection of Wavelet Domain sub-bands after 2D Discrete Wavelet Transform. Figure 3 illustrates the sub-bands resulting from the 2-D Discrete Wavelet Transform. The four components decomposed after the wavelet transform are the low-frequency component , the horizontal high-frequency component , the vertical high-frequency component , and the diagonal high-frequency component . It is readily apparent that the low-frequency component primarily preserves the core structural information of the image, filtering out random noise and redundant information. The high-frequency components harbor more detailed information and noise, where the diagonal high-frequency component exhibits lower information content and is predominantly composed of noise signals. Thus, selecting appropriate sub-bands significantly influences network performance. We conducted experiments to determine the optimal selection of frequency domain sub-bands, and the corresponding ablation study results are presented in Table 4. The results of the ablation studies indicate that the combination pattern of and both improve network performance; however, the combination pattern reduces network performance, as is primarily composed of noise signals, and noise has a marked effect on network performance. When the combination pattern of (A+H+V) is selected, the test results reach the optimum.
Table 4.
Ablation study on the effectiveness of different high-frequency component combinations in WDARFNet. The DIOR-R dataset was utilized in this experiment.
4.4. Comparison with State-of-the-Art Methods
Results on DOTA-v1.0. We report the results of 21 state-of-the-art oriented object detectors in Table 5. To ensure fairness, we adopted the same data augmentation methods and training strategies as other mainstream approaches, and we report detailed experimental results, including the average precision (AP) for each category and the mean Average Precision (mAP) on the DOTA dataset, to facilitate fair comparisons with previous methods. Without bells and whistles, under a single-scale training and testing strategy, WDARFNet improved the mAP of Oriented R-CNN (ResNet50) by 2.03%, outperforming all other single-scale models and most multi-scale models. Under a multi-scale training and testing strategy, WDARFNet achieves 81.06% mAP.
Table 5.
Comparisons with state-of-the-art methods on the DOTA-v1.0 OBB-task. * indicates multi-scale training and testing. The WDARFNet backbones are pretrained on ImageNet for 120 epochs. The results with red color indicate the best result of each category, and the results with blue color indicate the second-best result of each category.
Results on DIOR-R. We report the results of 14 state-of-the-art oriented object detectors in Table 6. To ensure fairness, we adopted the same data augmentation methods and training strategies as other mainstream approaches, and we report detailed experimental results, including the average precision (AP) for each category and the mean Average Precision (mAP) on the DIOR-R dataset, to facilitate fair comparisons with previous methods. The results reveal that our WDARFNet performs exceptionally well, achieving state-of-the-art mAP scores of 67.48%.
Table 6.
Comparisons with state-of-the-art methods on the DIOR-R OBB-task. The WDARFNet backbones are pretrained on ImageNet for 120 epochs. The results with red color indicate the best result of each category, and the results with blue color indicate the second-best result of each category.
Results on HRSC2016. We report the results of 10 state-of-the-art oriented object detectors in Table 7. The results show that our WDARFNet surpasses other methods, attaining mAP scores of 90.61% and 98.27% on the PASCAL VOC 2007 and VOC 2012, respectively.
Table 7.
Comparisons with state-of-the-art methods on the HRSC2016 OBB-task. The WDARFNet backbones are pretrained on ImageNet for 120 epochs.
4.5. Visualization
To better understand the superiority of our method, we visualize the predicted oriented bounding boxes, corresponding scores, and heatmaps. We compare the results of our WDARFNet with the baseline on the DOTA V1.0 and DIOR-R test datasets. The experiment uses Oriented R-CNN [13] as the detector and compares the performance of WDARFNet and ResNet50 as backbone networks.
Figure 9 and Figure 10, respectively, display the visual comparisons of our method and the baseline on the DOTA V1.0 and DIOR-R test datasets. From the visual results, it is evident that WDARFNet outperforms ResNet50 in several object detection tasks. Specifically, in the roundabout detection task, WDARFNet is able to more accurately draw the rotated bounding boxes of target objects, with superior boundary precision and coverage compared to ResNet50. In the basketball and tennis court detection tasks, the detection results of WDARFNet comprehensively and clearly cover the target areas, avoiding false negatives and duplicate bounding boxes. For complex scenes involving objects such as airplanes and ships, WDARFNet achieves clearer boundary delineation, avoiding overlap and false positives between targets, particularly in scenarios with tightly arranged multiple targets or when detecting targets obscured by shadows. Furthermore, in large-object detection tasks, such as in harbors, WDARFNet’s bounding box coverage is more comprehensive, demonstrating robustness to complex shapes and backgrounds.

Figure 9.
Visualization analysis of the predicted results on DOTA V1.0. The upper row displays the results of ResNet50, which serves as the baseline, while the bottom row displays the results of WDARFNet.

Figure 10.
Visualization analysis of the predicted results on DIOR-R. The upper row displays the results of ResNet50, which serves as the baseline, while the bottom row displays the results of WDARFNet.
Figure 11 displays the heatmaps of our method and the baseline for detecting objects obscured by shadows, with the first and third columns illustrating the test results of ResNet50 and WDARFNet, respectively. The second and fourth columns depict the heatmaps of partially obscured objects. In the baseball court detection task, the heatmap generated by WDARFNet focuses more precisely on the target area, with more accurate bounding box coverage. In the basketball court detection task, the heatmap generated by WDARFNet demonstrates greater attention to densely arranged objects obscured by shadows and effectively separates tightly distributed objects, avoiding overlapping, and false negatives in the bounding boxes. In the airplane detection task, WDARFNet not only accurately locates individual aircraft targets but also effectively reduces interference from shadows and backgrounds, with the generated heatmap focusing on the core regions of the objects, further improving detection accuracy.
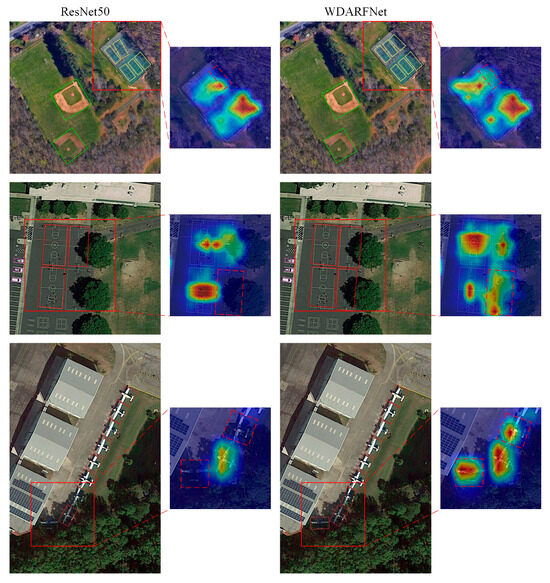
Figure 11.
Visualization analysis of heatmaps illustrating feature activation for ResNet50 and WDARFNet.
5. Discussion
This work proposes a backbone network termed WDARFNet, which fuses frequency domain analysis with adaptive receptive-field modeling to enhance oriented object detection in remote-sensing imagery. Extensive experiments on three widely used benchmarks were conducted to substantiate the effectiveness of the proposed model. For instance, when embedded into Oriented R-CNN under a single-scale training protocol, WDARFNet achieves an mAP of 81.06 % on DOTA-v1.0. On DIOR-R, WDARFNet elevated the baseline mAP by 7.16%, achieving 67.48 %. Collectively, the findings indicate that synergistically coupling the discrete wavelet transform with Selective Kernel module delivers markedly superior performance relative to either component in isolation.
The ablation study further quantifies the individual contribution of each module. Introducing WDCSM or the WDSSM in isolation increased mAP by 1.47 and 2.06 percentage points, respectively. When combined, the two modules yielded a 3.24-point overall gain over the ResNet-50 baseline, confirming their complementary effects across the channel and spatial domains. WDARFNet also exhibits outstanding robustness to noise. When Gaussian noise with a standard deviation of 25 is injected during the inference stage, the mAP of ResNet-50 decreases by 29.14 percentage points, whereas that of WDARFNet decreases by only 17.14 percentage points. Heat-map visualizations corroborate these quantitative results, revealing that, even under severe noise perturbations, the network activations remain concentrated on the target rather than on the noisy background, thereby highlighting the superior noise robustness of WDARFNet.
Despite the above advances, several limitations remain. First, the multi-branch large-kernel design introduces additional parameters relative to standard ResNet, which may hinder deployment on edge devices. Second, the current framework targets single-image tasks; incorporating temporal cues into video or sequential remote-sensing scenarios could further exploit the adaptive receptive-field mechanism.
In future research work, we will focus on reducing model complexity while maintaining accuracy. Specifically, we plan to explore quantization and pruning strategies and to devise lighter-weight architectures through channel trimming and knowledge distillation. In addition, we will broaden the data spectrum by validating the model on larger-scale datasets—for example, by systematically assessing its performance in SAR-image object detection—to obtain a more comprehensive evaluation.
6. Conclusions
In this paper, we propose the Wavelet-Domain Adaptive Receptive Field Network for the task of rotated object detection in remote sensing images. The WDARFNet effectively addresses inherent challenges in remote sensing images, such as noise interference, variation in object scales, densely distributed objects, occlusion issues, and complex backgrounds. We integrate Convolutional Neural Networks with Discrete Wavelet Transform and propose WDSSM and WDCSM modules. These modules can effectively utilize the high- and low- frequency information in the sub-bands to retain more image details, while selectively discarding the high-frequency components that contain significant noise, thus enhancing the representational capability and noise robustness of the network. The WDARFNet contains the Selective Kernel module, which is composed of a multi-branch large-kernel network, and leverages the WDSSM module to amalgamate features in the spatial domain, thereby achieving a dynamic adjustment of the receptive field for each object. Comprehensive experimental results demonstrate that our proposed WDARFNet outperforms other methods on competitive remote sensing benchmarks. This validates its effectiveness and robustness in detecting rotating objects in remote sensing images.
Author Contributions
Conceptualisation, J.Y. and L.Z.; methodology, J.Y. and L.Z.; software, J.Y.; validation, J.Y.; formal analysis, J.Y. and L.Z.; investigation, J.Y. and L.Z.; resources, L.Z. and Y.J.; data curation, J.Y.; writing—original draft preparation, J.Y.; writing—review and editing, L.Z. and Y.J.; visualisation, J.Y.; supervision, L.Z. and Y.J.; project administration, L.Z. and Y.J.; funding acquisition, L.Z. and Y.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This research used three publicly available datasets, including DOTA-v1.0, DIOR-R, and HRSC2016. The DOTA-v1.0 datasets can be found at https://captain-whu.github.io/DOTA (accessed on 1 December 2019); The DIOR-R datasets can be found at https://ieee-dataport.org/documents/dior#files (accessed on 12 April 2025); the HRSC2016 dataset can be found at https://aistudio.baidu.com/aistudio/datasetdetail/31232 (accessed on 15 December 2020).
Acknowledgments
The editors and anonymous reviewers are appreciated by the authors for their insightful feedback, which significantly enhanced the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Newry, Northern Ireland, 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3163–3171. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking Rotated Object Detection with Gaussian Wasserstein Distance Loss. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-Adaptive Selection and Measurement for Oriented Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; AAAI Press: Palo Alto, CA, USA, 2022; Volume 36, pp. 923–932. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Yang, X.; Li, Y.; Xue, J. G-Rep: Gaussian Representation for Arbitrary-Oriented Object Detection. Remote Sens. 2023, 15, 757. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2844–2853. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-Oriented Object Detection with Circular Smooth Label. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 677–694. [Google Scholar]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-Free Oriented Proposal Generator for Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625411. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A Rotation-Equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 16794–16805. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, C.; Wu, Y.; Maaten, L.V.D.; Yuille, A.L.; He, K. Feature Denoising for Improving Adversarial Robustness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 501–509. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency Channel Attention Networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 763–772. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting Small, Cluttered and Rotated Objects via Instance-Level Feature Denoising and Rotation Loss Smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2384–2399. [Google Scholar] [CrossRef]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented Reppoints for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond Bounding-Box: Convex-Hull Feature Adaptation for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8792–8801. [Google Scholar]
- Pu, Y.; Wang, Y.; Xia, Z.; Han, Y.; Wang, Y.; Gan, W.; Wang, Z.; Song, S.; Huang, G. Adaptive Rotated Convolution for Rotated Object Detection. arXiv 2023, arXiv:2303.07820. [Google Scholar]
- Unser, M. Texture Classification and Segmentation Using Wavelet Frames. IEEE Trans. Image Process. 1995, 4, 1549–1560. [Google Scholar] [CrossRef]
- Li, J.; Yuan, G.; Fan, H. Multifocus Image Fusion Using Wavelet-Domain-Based Deep CNN. Comput. Intell. Neurosci. 2019, 2019, 4179397. [Google Scholar] [CrossRef]
- Ehrlich, M.; Davis, L. Deep Residual Learning in the JPEG Transform Domain. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3483–3492. [Google Scholar]
- Wang, Y.; Xu, C.; You, S.; Tao, D.; Xu, C. CNNpack: Packing Convolutional Neural Networks in the Frequency Domain. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Newry, Northern Ireland, 2016; Volume 29. [Google Scholar]
- Xin, J.; Li, J.; Jiang, X.; Wang, N.; Huang, H.; Gao, X. Wavelet-Based Dual Recursive Network for Image Super-Resolution. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 707–720. [Google Scholar] [CrossRef] [PubMed]
- Mallat, S.G. A Theory for Multiresolution Signal Decomposition: The Wavelet Representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Fujieda, S.; Takayama, K.; Hachisuka, T. Wavelet Convolutional Neural Networks. arXiv 2018, arXiv:1805.08620. [Google Scholar]
- Williams, T.; Li, R. Wavelet Pooling for Convolutional Neural Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhao, X.; Huang, P.; Shu, X. Wavelet-Attention CNN for Image Classification. Multimed. Syst. 2022, 28, 915–924. [Google Scholar] [CrossRef]
- Li, Q.; Shen, L.; Guo, S.; Lai, Z. Wavelet Integrated CNNs for Noise-Robust Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7245–7254. [Google Scholar]
- Yang, Y.; Jiao, L.; Liu, X.; Liu, F.; Yang, S.; Li, L.; Chen, P.; Li, X.; Huang, Z. Dual Wavelet Attention Networks for Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1899–1910. [Google Scholar] [CrossRef]
- Wang, S.; Cai, Z.; Yuan, J. Automatic SAR Ship Detection Based on Multifeature Fusion Network in Spatial and Frequency Domains. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4102111. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers & Distillation through Attention. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning; AAAI: Washington, DC, USA, 2017; Volume 31. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sheng, P.; Shi, Y.; Liu, X.; Jin, H. Lsnet: Real-Time Attention Semantic Segmentation Network with Linear Complexity. Neurocomputing 2022, 509, 94–101. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A Convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up Your Kernels to 31x31: Revisiting Large Kernel Design in Cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Liu, S.; Chen, T.; Chen, X.; Chen, X.; Xiao, Q.; Wu, B.; Kärkkäinen, T.; Pechenizkiy, M.; Mocanu, D.; Wang, Z. More Convnets in the 2020s: Scaling up Kernels beyond 51x51 Using Sparsity. arXiv 2022, arXiv:2207.03620. [Google Scholar]
- Li, S.; Florencio, D.; Li, W.; Zhao, Y.; Cook, C. A Fusion Framework for Camouflaged Moving Foreground Detection in the Wavelet Domain. IEEE Trans. Image Process. 2018, 27, 3918–3930. [Google Scholar] [CrossRef] [PubMed]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction from High-Resolution Optical Satellite Images with Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C. Mmrotate: A Rotated Object Detection Benchmark Using Pytorch. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 7331–7334. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Long, Y.; Xia, G.-S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On Creating Benchmark Dataset for Aerial Image Interpretation: Reviews, Guidances, and Million-Aid. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Li, H.-C.; Zhang, H.; Xia, G.-S. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic Anchor Learning for Arbitrary-Oriented Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 2355–2363. [Google Scholar]
- Lang, S.; Ventola, F.; Kersting, K. Dafnet: A One-Stage Anchor-Free Deep Model for Oriented Object Detection. arXiv 2021, arXiv:2109.06148. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU Loss for Rotated Object Detection. arXiv 2022, arXiv:2201.12558. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-Free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).