Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm and Blockchain in Internet of Vehicles


Abstract
1. Introduction
- A blockchain-based multi-vehicle multi-task computational offloading model for mobile scenarios is established that can accurately map the task computational demand, offloading the logic and blockchain consensus process generated by vehicles in the process of dynamic mobility;
- A new polar lights optimization algorithm is adopted to optimize the computational offloading strategy, which accelerates the convergence speed while reducing the risk of falling into the local optimal solution and is significantly better than the traditional optimization methods;
- An authorized Byzantine fault-tolerant consensus mechanism is adopted to dynamically select consensus nodes through stake vote election, which ensures transactions are tamperable;
- The impact of task load, number of vehicles, and data volume on system performance under different offloading strategies is demonstrated in simulation experiments, which verifies the stability of the proposed strategies in dynamic IoV environments and confirms the effectiveness of the strategies proposed in this paper.
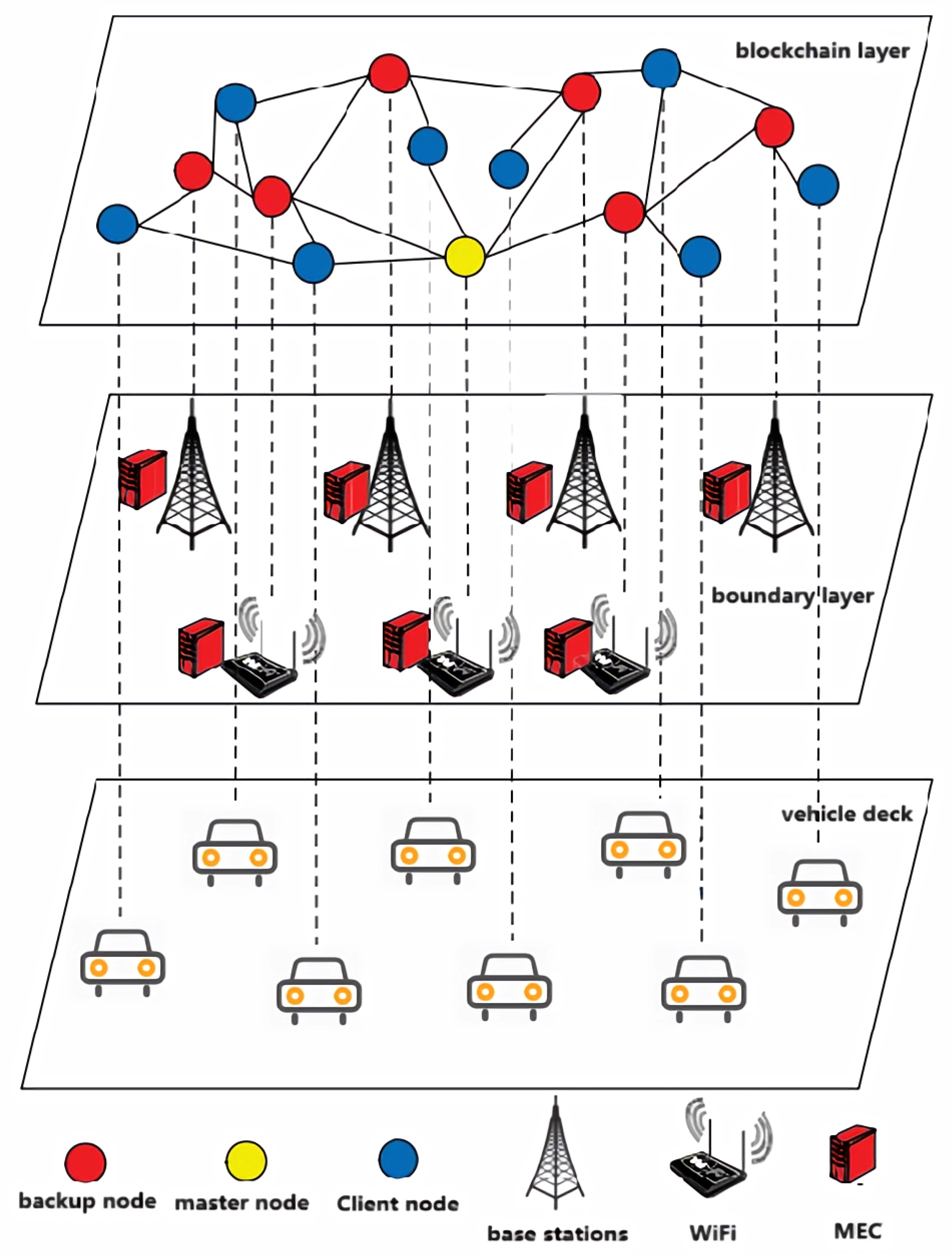
2. System Model
2.1. Network Model
2.2. Mission Model
2.3. Communications Model
2.4. Computational Model
- (1)
- Local Computing
- (2)
- Edge Server Computing
2.5. Vehicle Mobility Model
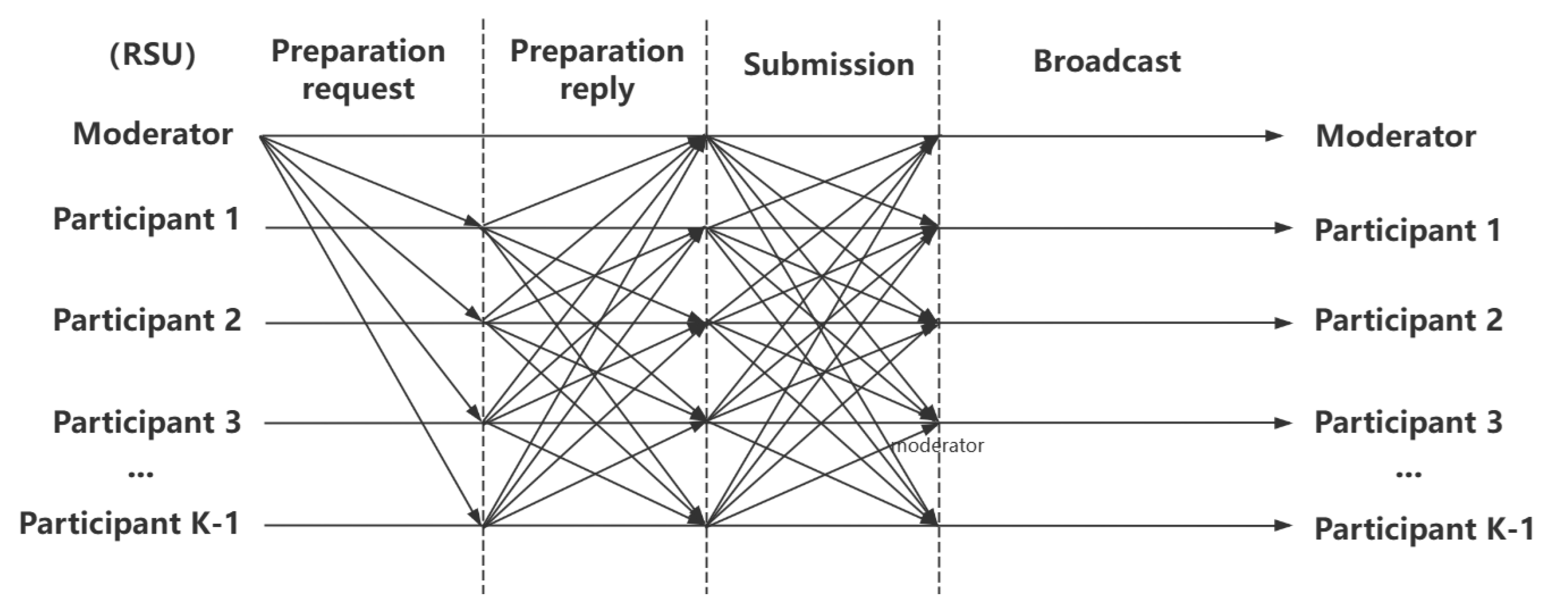
2.6. Blockchain Model
- (1)
- Preparation request:
- (2)
- Preparation reply:
- (3)
- Submission:
- (4)
- Broadcast:
2.7. Joint Optimization Problems
3. Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm
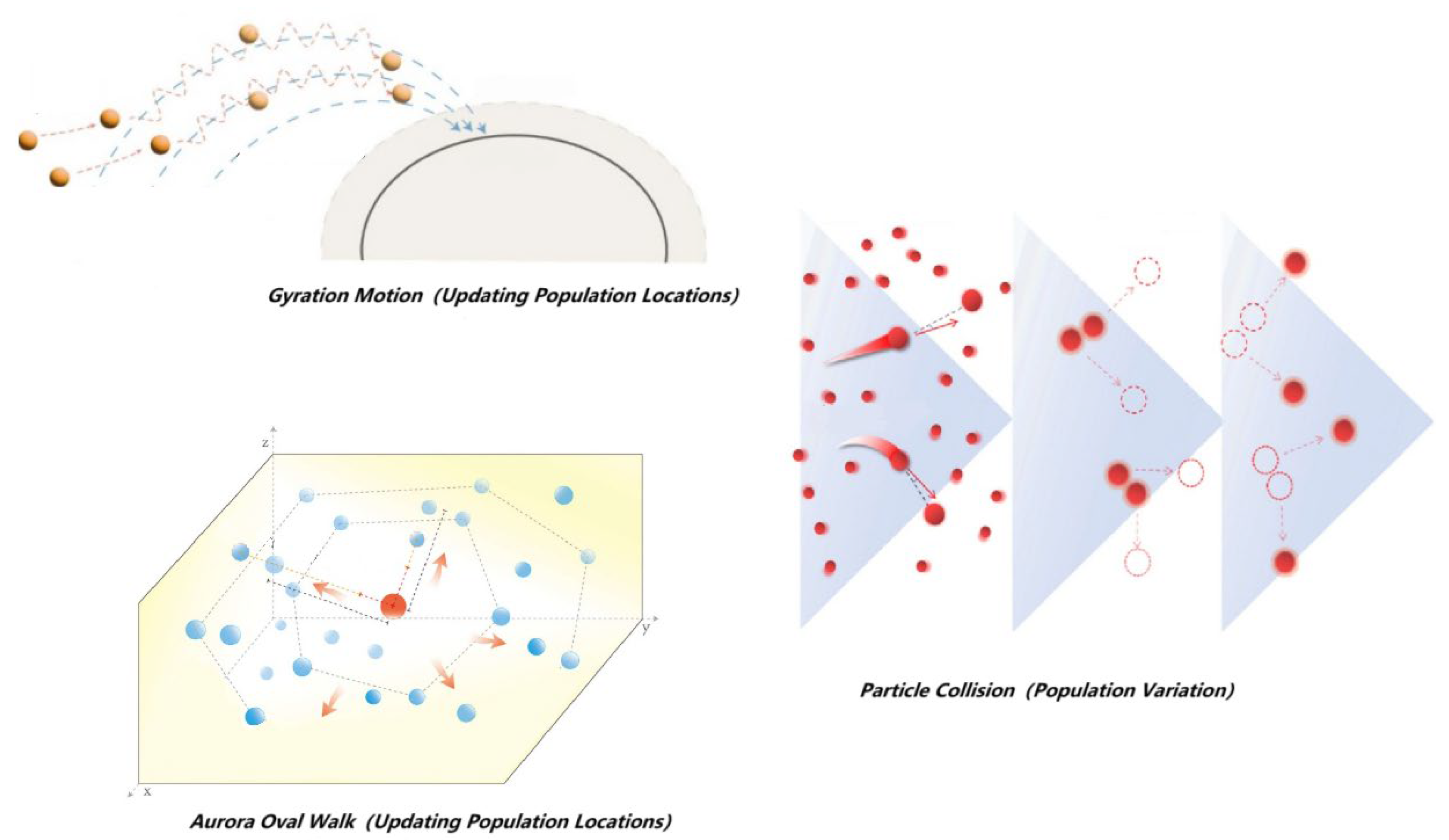
3.1. Improved Polar Lights Optimization
3.2. Algorithm Design
- (1)
- Initializing the Population
- (2)
- Updating Population Locations
- (3)
- Population Variation
- (4)
- Bounce Boundary Handling Mechanism
3.3. The Overall Flow of the Algorithm
| Algorithm 1. Computation offloading strategy based on IPLO algorithm | |
| 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. | Input: X Initialize high-energy particle populations X[i](i = 1, 2, 3, ...); Initialize the number of iterations FEs; Initialize the maximum number of iterations MaxFEs; Initialization N, X_new, BestS, BestP, BestTotal; Calculation of adaptation values ; While FEs <= MaxFEs do Use Equation (27) to calculate ; Use Equation (28) to calculate ; For i = 0 to N do Use Equation (29) to calculate ; Use Equation (30) to calculate ; Use Equation (31) to update ; If and then Use Equation (32) to update ; Use Equation (33) to update ; End if Calculate the fitness value ; FEs = FEs + 1; End for If then ; End if Use Equation (22), Equation (23) to calculate BestP; Calculate BestTotal from the sum of BestS and BestP; End While Output: BestTotal. |
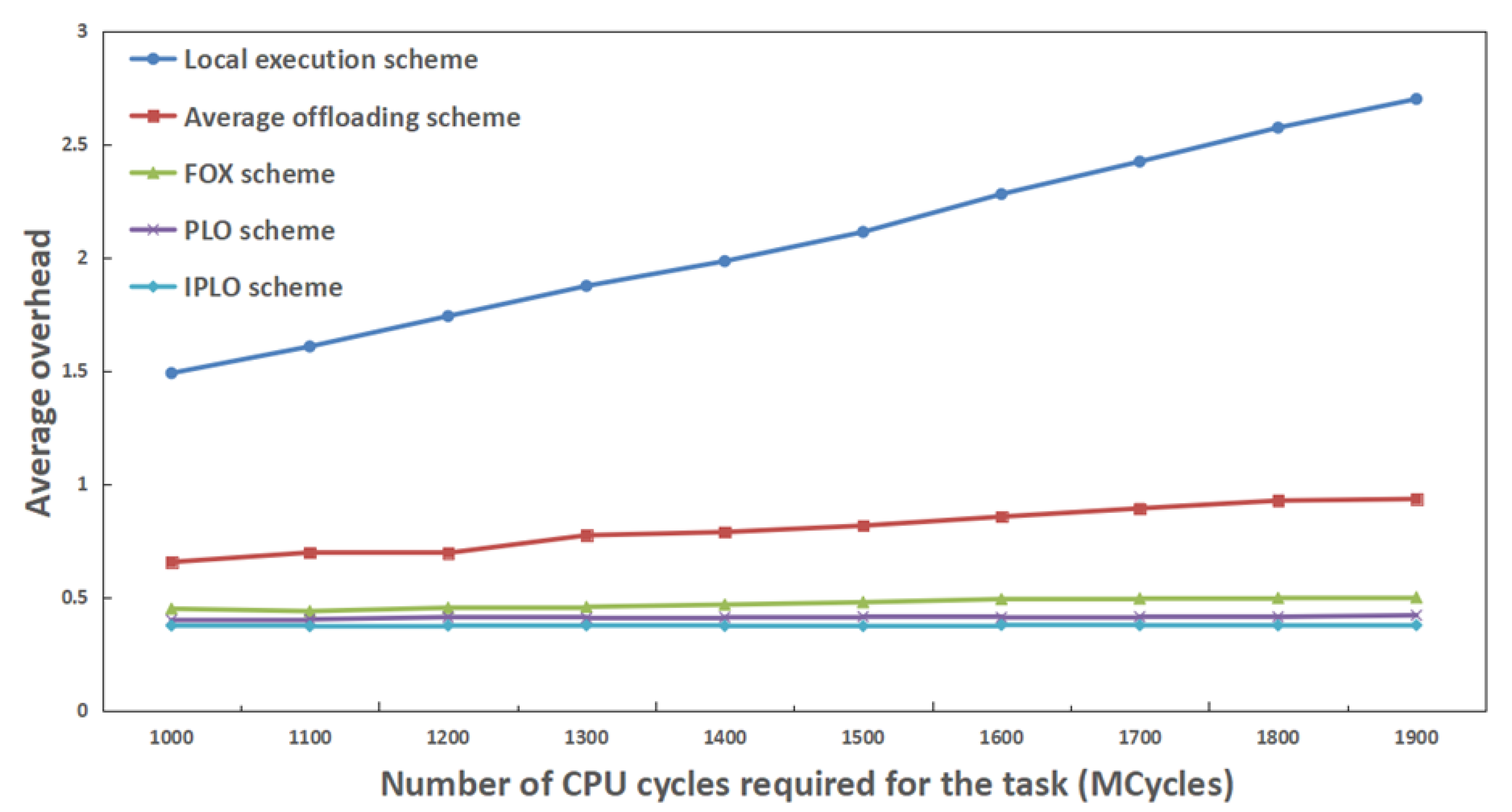
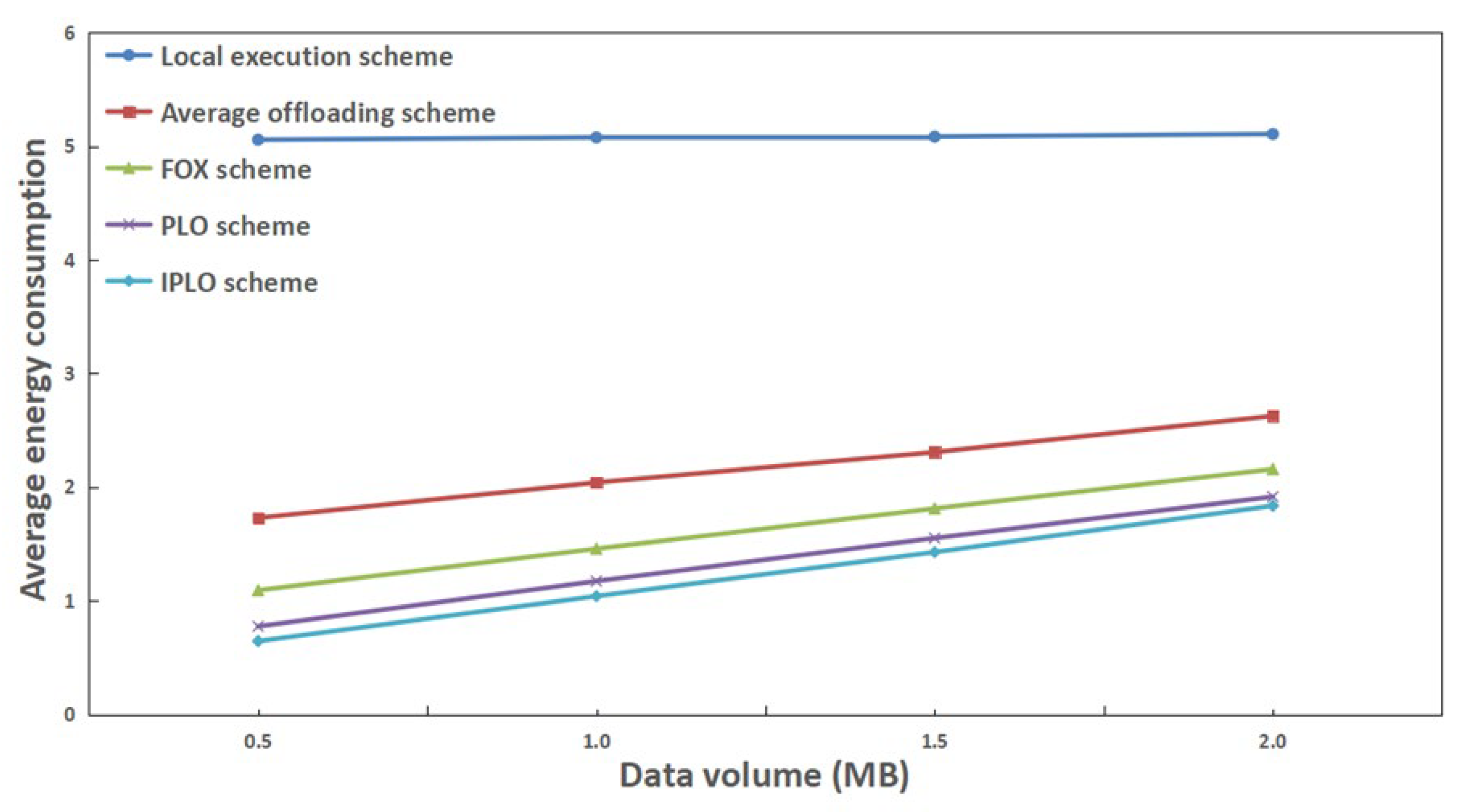
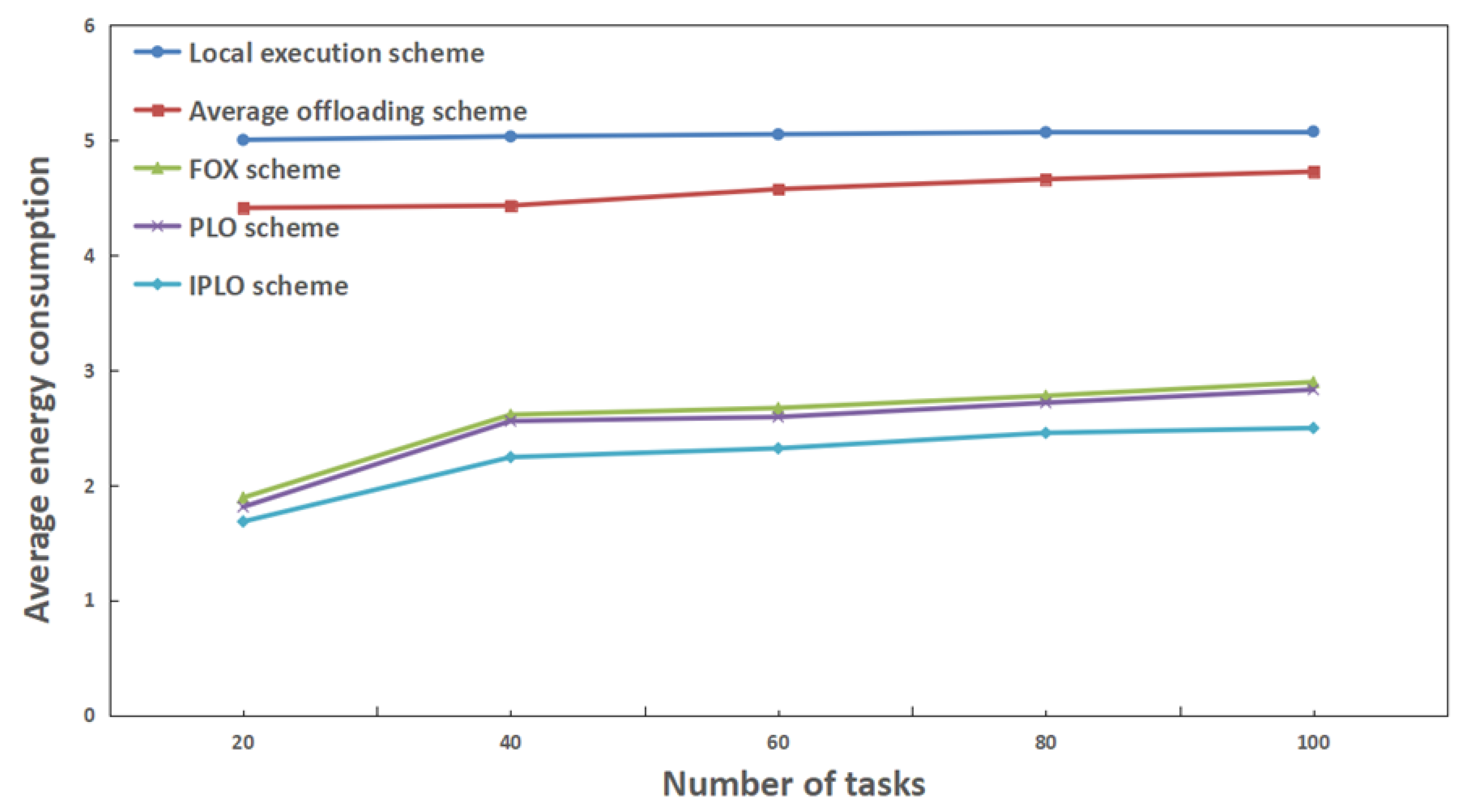
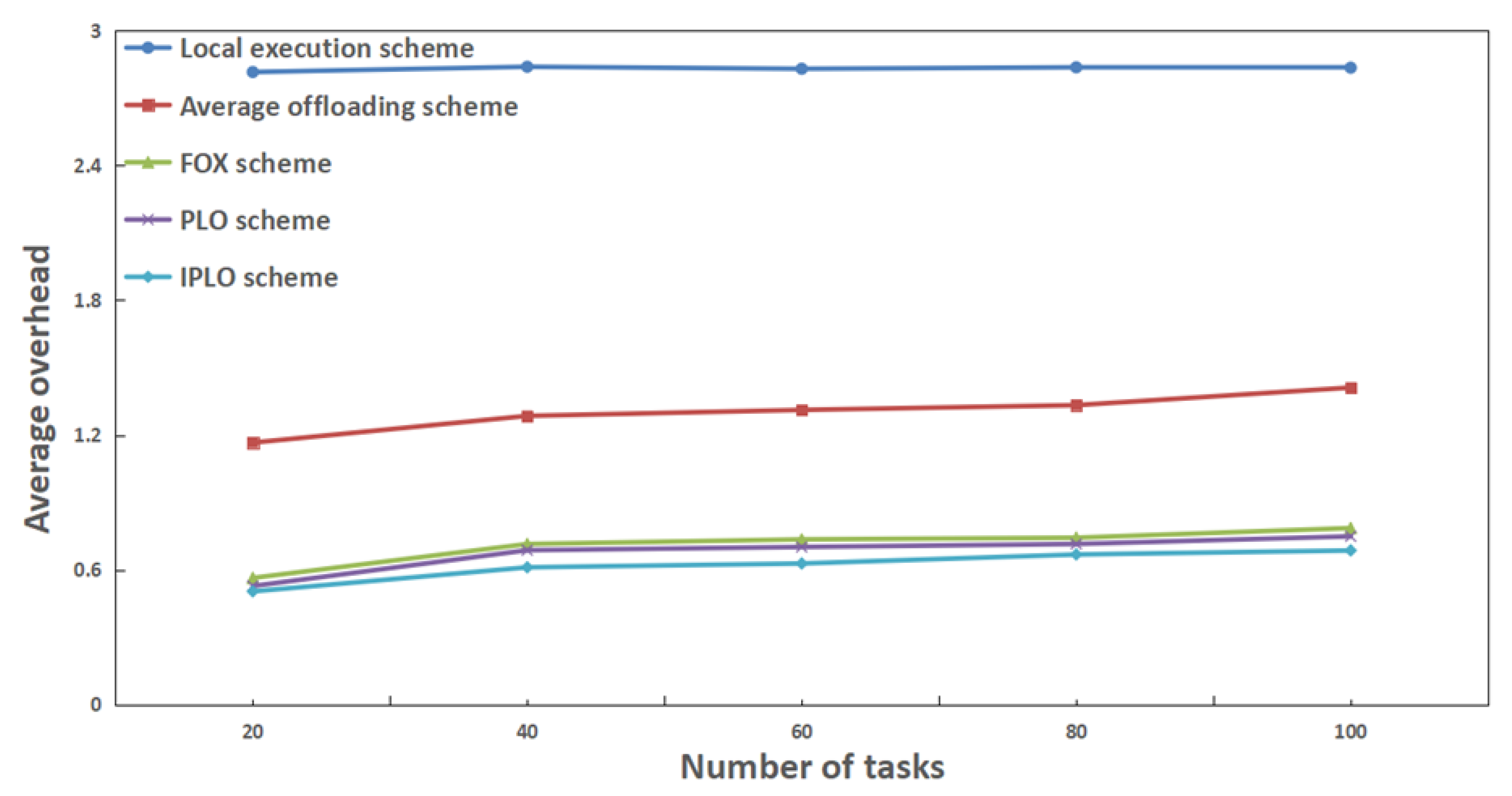
4. Simulation Experiments and Data Analysis
4.1. Simulation Parameters
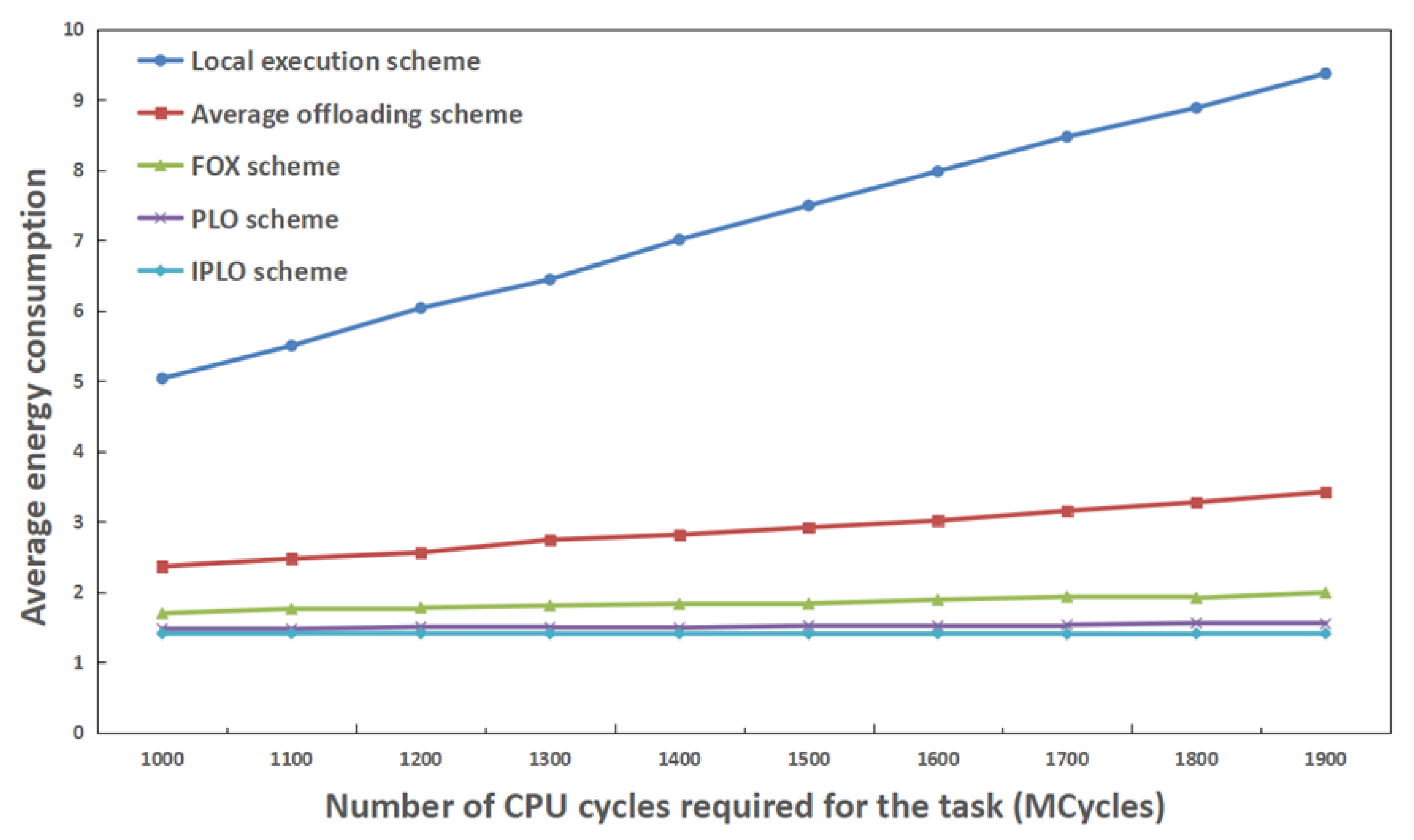
4.2. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maanak, G.; James, B.; Farhan, P.; Ravi, S. Secure V2V and V2I Communication in Intelligent Transportation Using Cloudlets. IEEE Trans. Serv. Comput. 2020, 15, 1912–1925. [Google Scholar]
- Yueyue, D.; Du, X.; Sabita, M.; Yan, Z. Joint Load Balancing and Offloading in Vehicular Edge Computing and Networks. IEEE Internet Things J. 2019, 6, 4377–4387. [Google Scholar]
- Chen, C.; Yini, Z.; Huan, L.; Yangyang, L.; Shaohua, W. A Multihop Task Offloading Decision Model in MEC-Enabled Internet of Vehicles. IEEE Internet Things J. 2023, 10, 3215–3230. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.; Kumar, V. A Review on Genetic Algorithm: Past, Present, and Future. Multimed. Tools Appl. 2020, 80, 8091–8126. [Google Scholar] [CrossRef]
- Jonas, S.; Tatiana, K.; Ian, D.; Mani, J. Dynamic Impact for Ant Colony Optimization Algorithm. Swarm Evol. Comput. 2021, 69, 100993. [Google Scholar]
- Shugang, L.; Yanfang, W.; Xin, L.; He, Z.; Zhaoxu, Y. A New Fast Ant Colony Optimization Algorithm: The Saltatory Evolution Ant Colony Optimization Algorithm. Mathematics 2022, 10, 925. [Google Scholar]
- Xinyu, Z.; Jiaxin, L.; Junhong, H.; Maosheng, Z.; Mingwen, W. Enhancing Artificial Bee Colony Algorithm with Multi-Elite Guidance. Inf. Sci. 2021, 543, 242–258. [Google Scholar]
- Du, X.; Zhou, Y. A Novel Hybrid Differential Evolutionary Algorithm for Solving Multi-objective Distributed Permutation Flow-Shop Scheduling Problem. Int. J. Comput. Intell. Syst. 2025, 18, 67. [Google Scholar] [CrossRef]
- Penglin, D.; Kaiwen, H.; Xiao, W.; Huanlai, X.; Fei, T.; Zhaofei, Y. A Probabilistic Approach for Cooperative Computation Offloading in MEC-Assisted Vehicular Networks. IEEE Trans. Intell. Transp. Syst. 2020, 23, 899–911. [Google Scholar]
- Yuwei, L.; Bo, Y.; Hao, W.; Qiaoni, H.; Cailian, C.; Xinping, G. Joint Offloading Decision and Resource Allocation for Vehicular Fog-Edge Computing Networks: A Contract-Stackelberg Approach. IEEE Internet Things J. 2022, 9, 15969–15982. [Google Scholar]
- Ramesh, R. Blockchain Technology: An Overview. IEEE Potentials 2022, 41, 6–12. [Google Scholar]
- Haibin, Z.; Jiajia, L.; Huanlei, Z.; Peng, W.; Nei, K. Blockchain-Based Trust Management for Internet of Vehicles. IEEE Trans. Emerg. Top. Comput. 2020, 9, 1397–1409. [Google Scholar]
- Zisang, X.; Wei, L.; Kuanching, L.; Jianbo, X.; Hai, J. A Blockchain-Based Roadside Unit-assisted Authentication and Key Agreement Protocol for Internet of Vehicles. J. Parallel Distrib. Comput. 2021, 149, 29–39. [Google Scholar]
- Sanjeev, K.D.; Ruhul, A.; Satyanarayana, V.; Rashmi, C. Blockchain-based Secured Event-Information Sharing Protocol in Internet of Vehicles for Smart Cities. Comput. Electr. Eng. 2020, 86, 106719. [Google Scholar]
- Cui, J.; Ouyang, F.; Ying, Z.; Wei, L.; Zhong, H. Secure and Efficient Data Sharing among Vehicles Based on Consortium Blockchain. IEEE Trans. Intell. Transp. Systems 2021, 23, 8857–8867. [Google Scholar]
- Qinglai, W.; Liyuan, H.; Tielin, Z. Spiking Adaptive Dynamic Programming Based on Poisson Process for Discrete-Time Nonlinear Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 1846–1856. [Google Scholar]
- Pengfei, H.; Wai, C. Software-Defined Edge Computing (SDEC): Principle, Open IoT System Architecture, Applications, and Challenges. UIC 2019, 7, 5934–5945. [Google Scholar]
- Zhang, K.; Mao, Y.; Leng, S.; Maharjan, S.; Zhang, Y. Optimal delay constrained offloading for vehicular edge computing networks. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Quyuan, L.; Changle, L.; Tom, H.L.; Weisong, S.; Weigang, W. Self-Learning Based Computation Offloading for Internet of Vehicles: Model and Algorithm. IEEE Trans. Wirel. Commun. 2021, 20, 5913–5925. [Google Scholar]
- Zhaolong, N.; Peiran, D.; Xiaojie, W.; Liang, G.; Joel, R.; Xiangjie, K.; Jun, H.; Ricky, Y.K.K. Deep Reinforcement Learning for Intelligent Internet of Vehicles: An Energy-Efficient Computational Offloading Scheme. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1060–1072. [Google Scholar]
- Zhen, D.; Fan, L.; Weijie, Y.; Christos, M.; Zenghui, Z.; Shuqiang, X.; Giuseppe, C. Integrated Sensing and Communications for V2I Networks: Dynamic Predictive Beamforming for Extended Vehicle Targets. IEEE Trans. Wirel. Commun. 2023, 22, 3612–3627. [Google Scholar]
- Tyler, C.; Vincent, G.; Mikel, L.; Michel, R. DBFT: Efficient Leaderless Byzantine Consensus and Its Application to Blockchains. In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018. [Google Scholar]
- Qin, W.; Jiangshan, Y.; Zhiniang, P.; Shiping, C.; Yong, D.; Yang, X. Formal Security Analysis on Dbft Protocol of NEO. Comput. Res. Repos. 2022, 2, 20–31. [Google Scholar]
- Dodo, K.; Low, T.J.; Manzoor, A.H. Systematic Literature Review of Challenges in Blockchain Scalability. Appl. Sci. 2021, 11, 9372. [Google Scholar]
- Wang, J.; Lv, T.; Huang, P. Mobility-aware partial computation offloading in vehicular networks: A deep reinforcement learning based scheme. China Commun. 2020, 17, 31–49. [Google Scholar] [CrossRef]
- Chong, Y.; Dong, Z.; Ali, A.H.; Lei, L.; Yi, C.; Huiling, C. Polar Lights Optimizer: Algorithm and Applications in Image Segmentation and Feature Selection. Neurocomputing 2024, 607, 128427. [Google Scholar]
- Shi, T.; Qing, H.; Baiman, C.; Xiaoping, Y.; Simin, H. One-point Second-Order Curved Boundary Condition for Lattice Boltzmann Simulation of Suspended Particles. Comput. Math. Appl. 2018, 76, 1593–1607. [Google Scholar]
- Orlando, E.; Contreras, P.; Cyrlene, C.; Rohit, N. Knowledge sharing among engineers: An empirical examination. In Proceedings of the 2017 IEEE Technology & Engineering Management Conference (TEMSCON), Santa Clara, CA, USA, 8–10 June 2017; pp. 260–266. [Google Scholar]
- Yi, L.; Chao, Y.; Li, J.; Shengli, X.; Yan, Z. Intelligent Edge Computing for IoT-Based Energy Management in Smart Cities. IEEE Netw. 2019, 33, 111–117. [Google Scholar]
- Ali Bulut, U.; Ali Ozgur, Y. Oversampling in One-Bit Quantized Massive MIMO Systems and Performance Analysis. IEEE Trans. Wirel. Commun. 2018, 17, 7952–7964. [Google Scholar]
- Ranjeet Singh, T.; Shekhar, V. RSU-supported MAC Protocol for Vehicular Ad Hoc Networks. Int. J. Veh. Saf. 2012, 6, 162. [Google Scholar]
- Ray, K. Adaptive Bernstein–von Mises Theorems in Gaussian White Noise. Ann. Stat. 2017, 45, 2511–2536. [Google Scholar] [CrossRef]
- Choi, J. NOMA Based Random Access with Multichannel ALOHA. IEEE J. Sel. Areas Commun. 2017, 35, 2736–2743. [Google Scholar] [CrossRef]
- Fengxian, G.; Richard, F.Y.; Heli, Z.; Hong, J.; Mengting, L. Adaptive Resource Allocation in Future Wireless Networks with Blockchain and Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2020, 19, 1689–1703. [Google Scholar]
- Mengting, L.; Richard, F.Y.; Yinglei, T.; Victor, C.M. Leung.; Mei, Song. Performance Optimization for Blockchain-Enabled Industrial Internet of Things (iiot) Systems: A Deep Reinforcement Learning Approach. IEEE Trans. Ind. Inform. 2019, 15, 3559–3570. [Google Scholar]
- Leliang, R.; Weilin, G.; Yong, X.; Zhenyu, L.; Daqiao, Z.; Shaopeng, L. Deep Reinforcement Learning Based Integrated Evasion and Impact Hierarchical Intelligent Policy of Exo-Atmospheric Vehicles. Chin. J. Aeronaut. 2025, 38, 103193. [Google Scholar]
- Chunmei, M.; Jinqi, Z.; Ming, L.; Hui, Z.; Nianbo, L.; Xinyu, Z. Parking Edge Computing: Parked-Vehicle-Assisted Task Of-floading for Urban VANETs. IEEE Internet Things J. 2021, 8, 9344–9358. [Google Scholar]
- Dawid, P.; Marcin, W. Red Fox Optimization Algorithm. Expert Syst. Appl. 2020, 166, 114107. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Numerical |
|---|---|
|
Data size of the task CPU cycles required for the task Transmitting power of the vehicle [28] Computing power of the vehicles [29] Computing power of the MEC server [30] Radius of communication coverage of RSUs [31] Gaussian channel white noise [32] Subchannel bandwidth [33] Weighting of latency Weighting of energy CPU cycles required for signature [34] CPU cycles required for MAC [34] Average deal size [35] Average computing power of RSUs [36] Average transmission power of RSUs [37] Number of blockchain nodes Number of blockchain consensus nodes Constant speed | [0.5–1.5] MB [1000–2000] Megacycles 46 dBm 2.0 GHz 8.0 GHz 500 m −147 dBm 2 MHz 0.8 0.2 1 Megacycles 10 Megacycles 200 B 3 GHz 1000 mW 6 4 40 Km/s |
| Arithmetic | Fixed Data Volume and Number of Tasks | Fixed CPU Cycles and Number of Tasks | Fixed CPU Cycles and Data Volume |
|---|---|---|---|
| FOX | 0.022325712 | 0.121529847 | 0.084908155 |
| PLO | 0.006160379 | 0.120456452 | 0.086015252 |
| IPLO | 0.001792003 | 0.115658619 | 0.071276243 |
| Collision Probability | Fixed Data Volume and Number of Tasks | Fixed CPU Cycles and Number of Tasks | Fixed CPU Cycles and Data Volume |
|---|---|---|---|
| 0.01 | 0.450215907 | 0.40370882 | 0.615417646 |
| 0.03 | 0.451200618 | 0.397350783 | 0.619286688 |
| 0.05 | 0.451540167 | 0.400150143 | 0.616115548 |
| 0.07 | 0.450900238 | 0.399467543 | 0.618433646 |
| 0.1 | 0.45002346 | 0.403075415 | 0.616594892 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Yan, B.; Wang, B.; Sun, Q.; Dai, Y. Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm and Blockchain in Internet of Vehicles. Appl. Sci. 2025, 15, 7341. https://doi.org/10.3390/app15137341
Liu Y, Yan B, Wang B, Sun Q, Dai Y. Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm and Blockchain in Internet of Vehicles. Applied Sciences. 2025; 15(13):7341. https://doi.org/10.3390/app15137341
Chicago/Turabian StyleLiu, Yubao, Bocheng Yan, Benrui Wang, Quanchao Sun, and Yinfei Dai. 2025. "Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm and Blockchain in Internet of Vehicles" Applied Sciences 15, no. 13: 7341. https://doi.org/10.3390/app15137341
APA StyleLiu, Y., Yan, B., Wang, B., Sun, Q., & Dai, Y. (2025). Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm and Blockchain in Internet of Vehicles. Applied Sciences, 15(13), 7341. https://doi.org/10.3390/app15137341