This section presents the technology and measurement of a 5G base station, the proposed approach based on the random forest model, and the generation of datasets.
2.1. Fifth-Generation Base Station Measurement Campaign
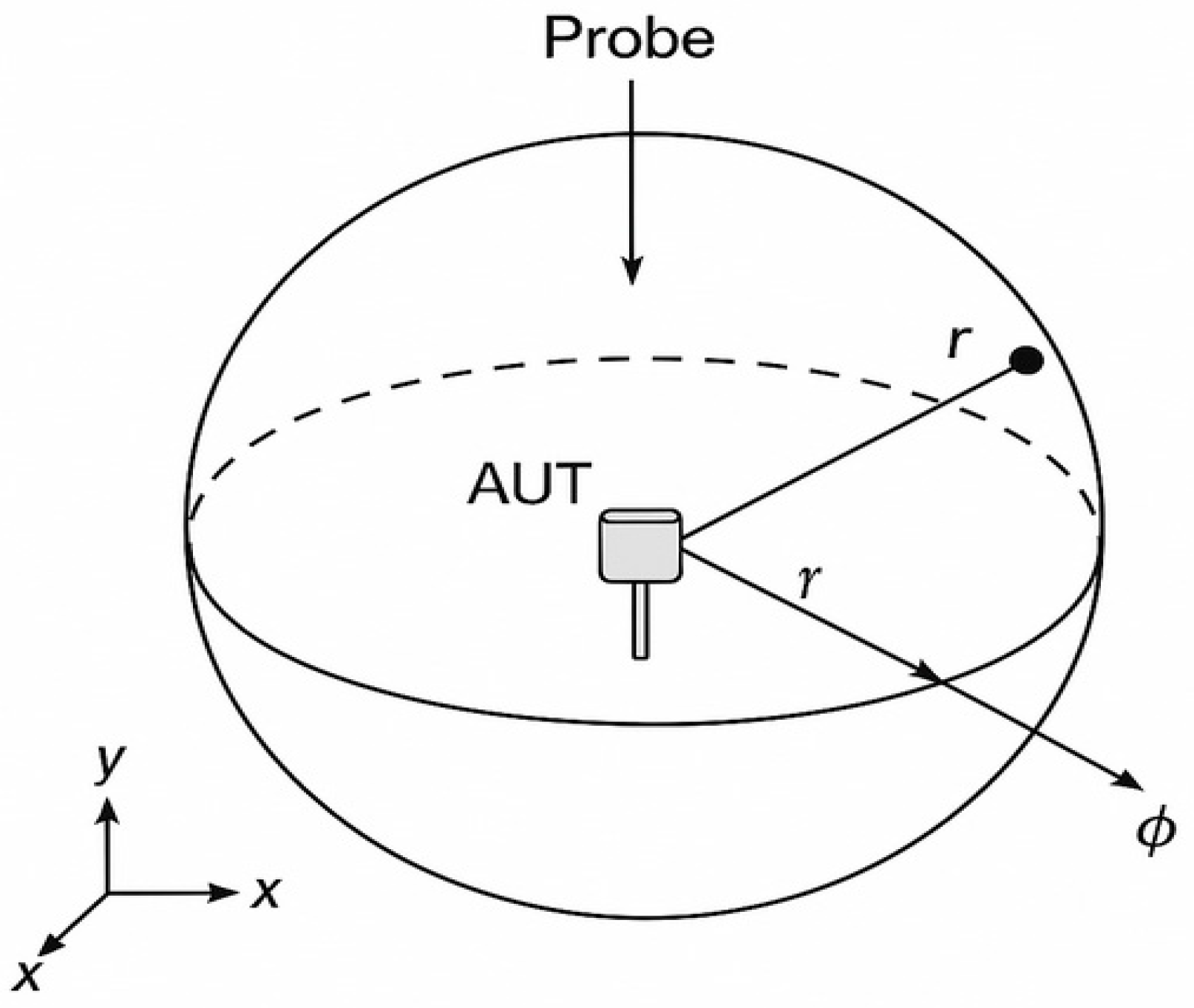
Figure 4 illustrates the setup for measuring near-field electromagnetic radiation emitted by a 5G base station using a spherical coordinate system. The 5G base station antenna, referred to as the Antenna Under Test (AUT), is positioned at the center of the spherical space and acts as the radiation source. A measurement probe is placed on the surface of this hypothetical sphere to detect the electric field strength at a radial distance
r. In this coordinate system,
r denotes the distance from the antenna to the probe, θ represents the elevation (or polar) angle measured from the vertical axis, and ϕ—although not shown—typically indicates the azimuthal angle around the
z-axis. The Cartesian axes (
x,
y, and
z) are included to correlate spherical coordinates with actual spatial directions. The radiation pattern is illustrated with arrows showing the general direction of wave propagation. This configuration is used to assess electromagnetic field levels in the near-field zone, allowing for the spatial mapping of electric field strength
E based on the angular position and distance, which aids in analyzing the antenna’s performance.
One of the main challenges to the rollout of 5G new radio (NR) is the extensive application of technological innovations like massive MIMO (multiple-input and multiple-output) and beamforming.
The electric field in the distant field near 5G base stations shown in
Figure 2 can be determined using the following [
27,
28,
29].
E is the electric field intensity (in volts per meter, V/m). PT is the transmitted power (in watts). is the gain of the transmitting antenna in the direction . R is the distance from the antenna to the observation point (in meters). The value of 377 is the intrinsic impedance of free space (η0 = 377 Ω), and 4πR2 represents spherical spreading in free space.
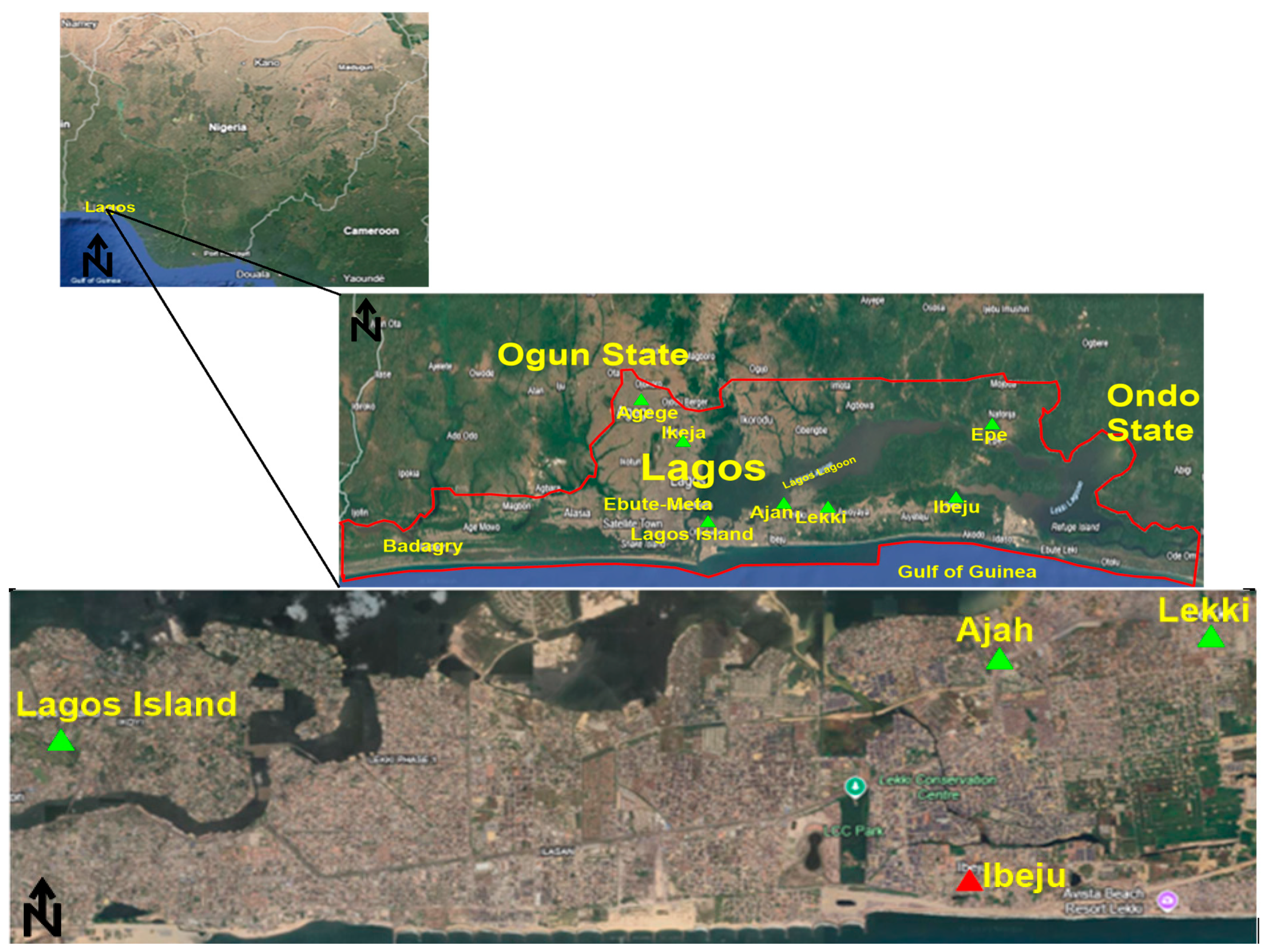
This section presents the method used for the environmental monitoring of electromagnetic radiation at 5G base stations. Measurements were conducted at multiple 5G base stations across six regions in Lagos, Nigeria: Ikeja, Lagos Island, Ikoyi, Lekki, and Ajah. Furthermore, three major operators—MTN, Global Communication, and Airtel—are active in these areas. The active bands of the 5G base stations are shown in
Table 1.
The 5G base station measurement data for the Lekki region is presented in
Figure 3. We used the PMM (Narda) EMR-300 (Narda, Pfullingen, Germany), a frequency-selective radiation meter, as our testing device. This equipment was chosen for its ability to monitor the frequency range within the probe’s response. This capability enables the device to accurately capture and display electromagnetic radiation from 5G base stations, showing the spectrum distribution of contributions across different frequencies. SRM-3006 (Narda, Pfullingen, Germany), offers a typical instrumental accuracy of ±1.5 dB across most of its operating range. For highest confidence, careful calibration, spatial resolution, and environmental control are essential to minimize total uncertainty and improve model-matching reliability. Furthermore, measurement accuracy depends significantly on the probe used: Isotropic E-field probes (e.g., EF 0691, EP-601(Narda, Pfullingen, Germany),) offer omnidirectional sensitivity, which is crucial for averaging over three spatial axes. Probe calibration contributes an uncertainty of around ±1.0 to ±1.5 dB, and the expanded uncertainty (combined, 95% confidence level) is ±2.5 to ±3.5 dB. This total uncertainty range is incorporated as an error band when interpreting how well measurements align with theoretical computation. Probe loading and size (relative to wavelength) affect the accuracy; this is minimized by using near-field-compatible small-aperture probes.
2.2. Random Forest Regression Method
Ensemble learning is a common technique that involves combining multiple learners to improve the performance of a machine learning model [
29,
30,
31,
32,
33,
34,
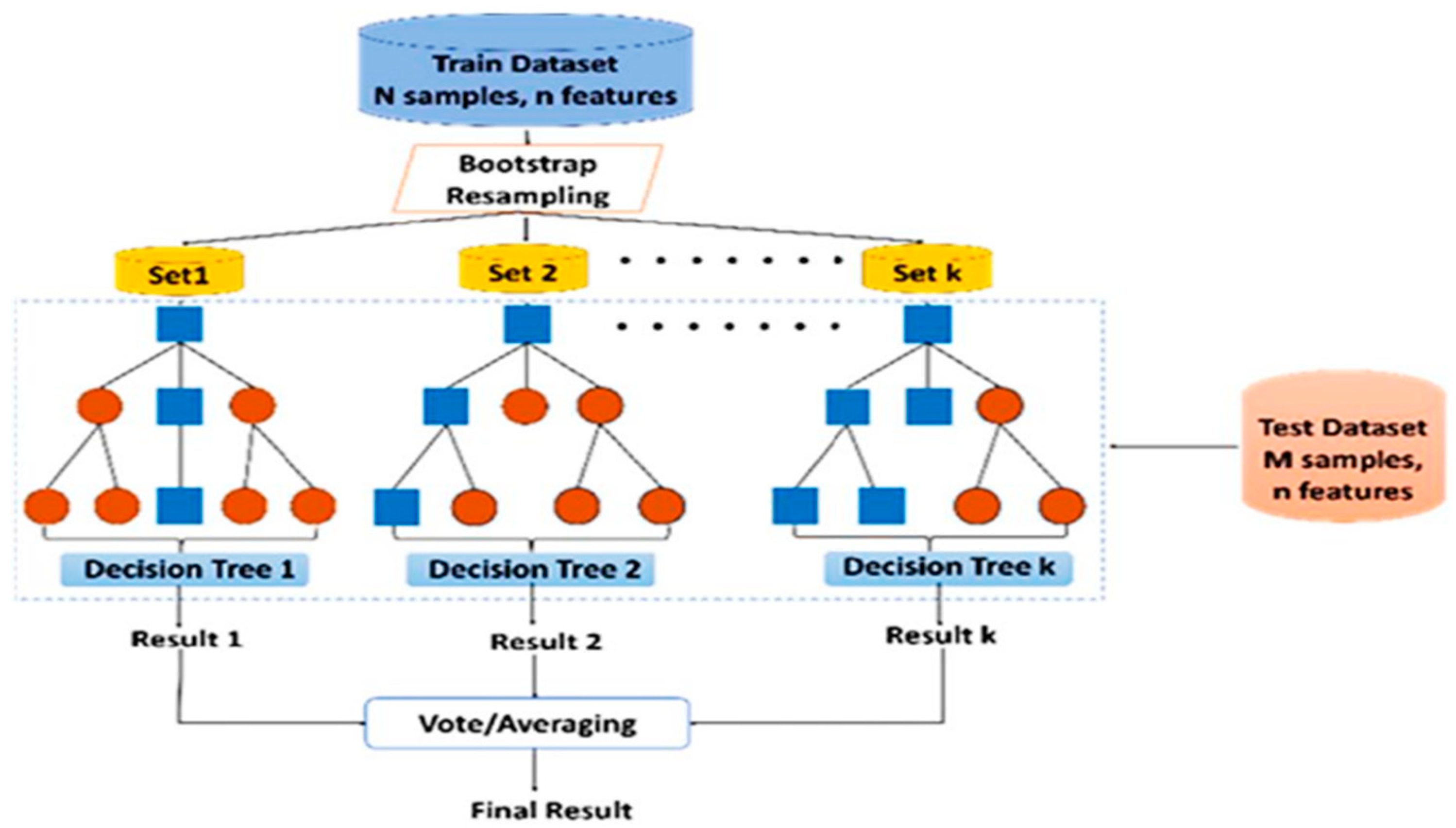
35]. This approach is often divided into two categories based on whether the base learners are generated simultaneously or sequentially. The random forest regression model, which is based on the Bagging (bootstrap sampling) algorithm, exhibits the characteristics of a traditional parallel ensemble learning model, such as randomness in both feature selection and training set composition.
Figure 5 illustrates the architecture. In random forest, bootstrapped datasets are created by randomly selecting samples from the training set with replacement, and these datasets are used to train multiple tree learners. The size of each bootstrapped dataset matches that of the original training set. Furthermore, instead of splitting nodes using all available attributes, decision trees in the random forest are constructed using random subsets of the features. A regression decision tree, which is built by partitioning the feature space into subgroups based on a set of splitting criteria, acts as the base learner for the random forest regression model. The training set
D is represented by the following equation.
Each data point in the training set is represented by xi, where xi is a feature vector (e.g., a set of measurements or attributes), and yi is the corresponding label or outcome associated with xi (e.g., the classification or predicted value). For example, in a dataset of weather data, xi could represent features like temperature and humidity, while yi could correspond to a label indicating whether it rained (yes or no) that day. i = 1, 2, …, N, where N is the total number of data points in the training set. where denotes the feature vector, and n represents the number of features.
To generate multiple training sample sets, data is randomly sampled from the original dataset D using the Bagging (bootstrap sampling) method. For each training sample set, a Classification and Regression Tree (CART) is constructed using the node random splitting technique, and the least mean square error principle is applied.
For any partition feature j corresponding to a partition node
s, the dataset is divided into two subsets,
and
. The partition feature
j is determined by minimizing the mean square errors of
and
, as well as the sum of these errors. The following are the resulting expressions:
and
are the split areas. Following the division of the feature space into
M areas (
,
,...,
), the process is repeated for each split area until the stop criterion is met.
and
represent the optimal output values of the two areas, respectively, and
and
are the number of samples in datasets
and
, respectively. Consequently, a regression tree is designed as
where the following equation provides the indicator function.
The estimated value can be determined by identifying the leaf node that corresponds to the input features of the instantaneous electric field intensity to be estimated when they are fed into the regression decision tree model.
As a result, the algorithm is robust and exhibits strong fault tolerance, making it well-suited for scenarios where electromagnetic radiation from 5G base stations fluctuates significantly based on operating conditions.
2.3. Dataset
We adopt a two-pronged approach to feature selection, considering both the actual measured values and the principles of electromagnetic radiation to avoid dimensionality issues and overfitting caused by irrelevant features. We carefully select the parameters to be used as inputs and outputs for the random forest regression model, as listed in
Table 2. The measurement campaign is conducted on both weekends and weekdays.
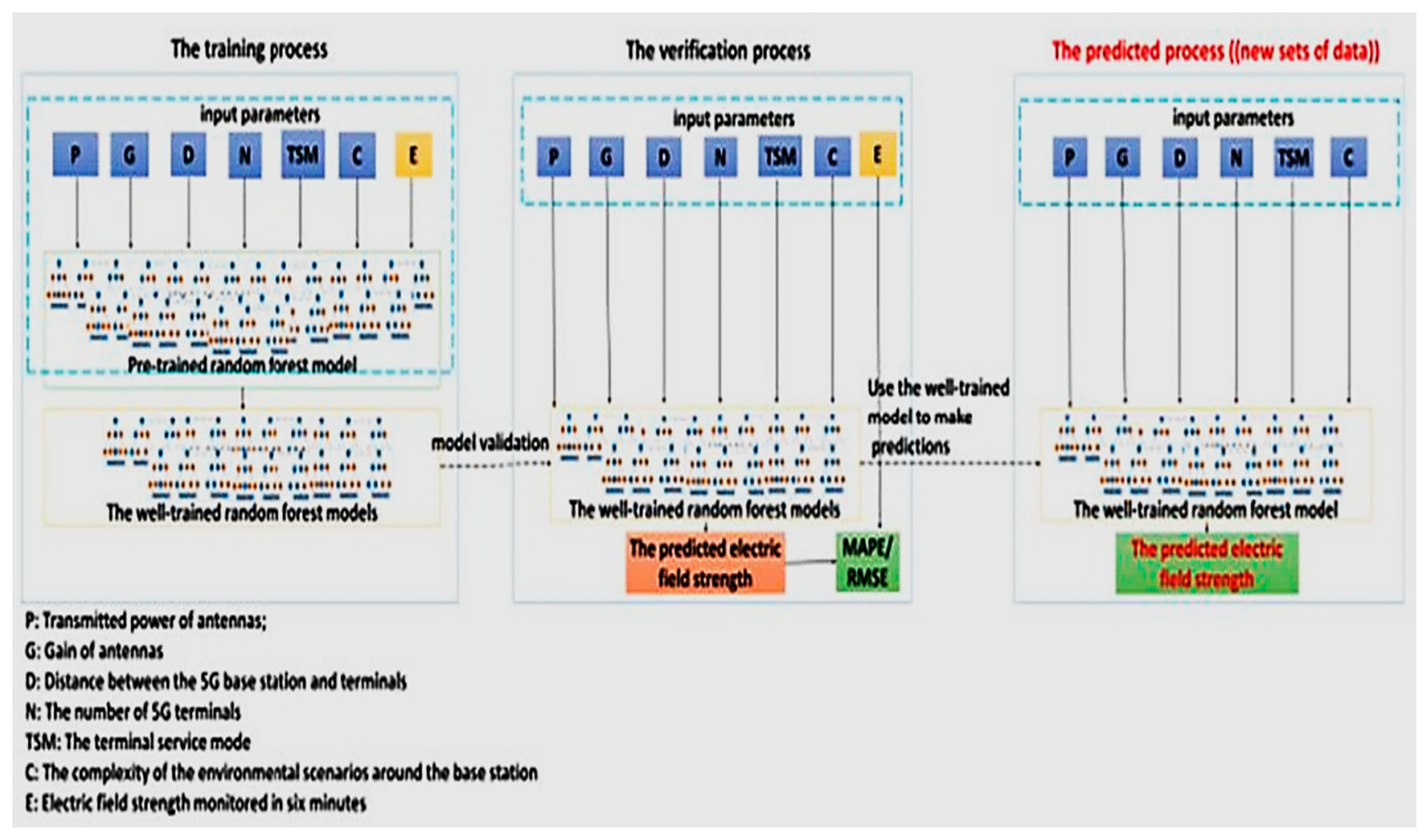
The training, validation, and prediction processes of the random forest model are illustrated in
Figure 6. The random forest algorithm was developed using Python 3.12.0, with implementation carried out through the scikit-learn library. During the training phase, the dataset includes inputs such as the antenna’s transmission power, antenna gain, terminal service modes, the number of 5G terminals, the distance between 5G terminals and the base station, the environmental complexity around the 5G base station, and the monitored electric field intensity. This dataset is used to train the pre-trained random forest model, resulting in a well-trained model. In the validation phase, the same set of inputs—antenna transmit power, antenna gain, terminal service modes, number of 5G terminals, distance from 5G terminals to the base station, environmental complexity, and monitored electric field intensity—are used. The output of the model is the predicted electric field intensity, and by comparing the predicted and monitored values, the error’s MAPE (Mean Absolute Percentage Error) and RMSE (Root Mean Squared Error) are calculated. In the prediction process, the dataset (new data) includes inputs such as the antenna’s transmit power, antenna gain, terminal service modes, the number of 5G terminals, the distance between the terminals and the base station, and the environmental complexity surrounding the 5G base station. The trained random forest model receives these input parameters and automatically predicts the electric field’s intensity.
Selecting the right features is the first step in accurately estimating electromagnetic radiation levels. As shown in Equation (1), factors such as antenna transmit power (P), antenna gain (G), and the distance (D) from the 5G base station significantly influence the electric field radiation level. In practice, three major Nigerian network operators—MTN, Globalcom, and Airtel—use a specific type of transmitting antenna to service the terminal.
Table 3 provides details on the nominal values of antenna transmit power for each operator. While there may be slight variations between these nominal values and the actual transmit power in certain monitoring conditions, this difference does not impact the accuracy of our predictions. The gain (absolute gain) is represented as a dimensionless ratio of the power output in a specific direction to the power radiated by the reference antenna. The model’s ability to predict the strength of the electromagnetic radiation field is not solely reliant on these variables; instead, it performs a comprehensive analysis using multi-dimensional data. As illustrated in
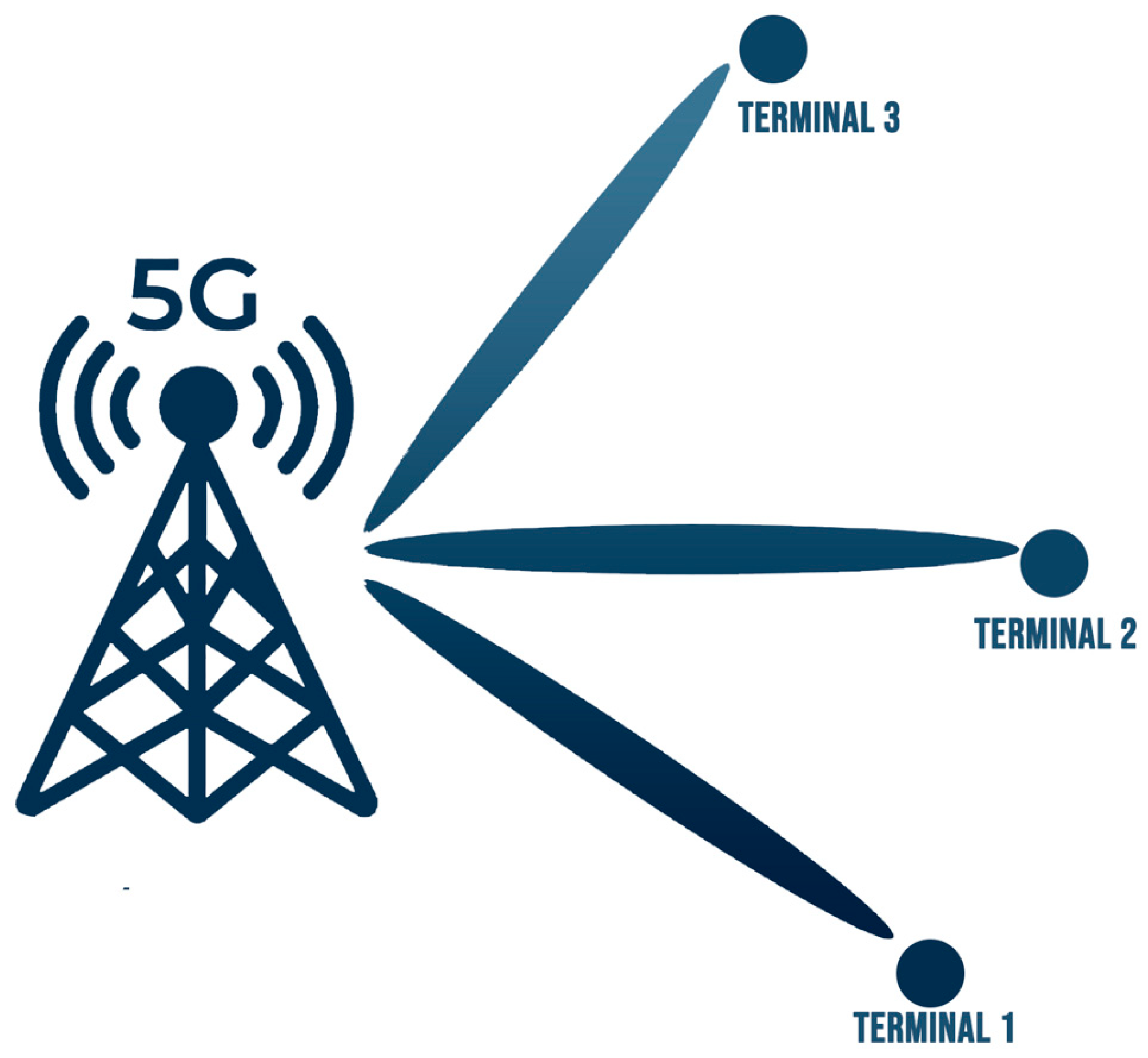
Figure 2, the monitoring point is equipped with a terminal, and the antenna beam is specifically designed to serve this terminal. Therefore, the gain referred to here is the nominal gain (P) of the antenna. Beamforming adjusts the radiation direction of antennas, concentrating wireless signals in a specific direction rather than radiating them uniformly, which results in a higher gain value for the antenna.
Just as the distance (D) between the 5G base station and the measurement site influences the measured electric field intensity, D is also selected as an input parameter.
A higher observed electric field intensity results from multiple beam overlaps caused by a concentration of 5G terminals. Therefore, we believe that the number of terminals has a significant impact on the detected radiation level from the 5G base station. In the measurement, we increase the number of 5G terminals from 1 to 4 to represent a more typical scenario. By analyzing monitoring data from selected areas in Lagos, Nigeria, we observe that as the number of terminals increases, the monitoring field strength also rises (
Table 4). Given its importance to the outcome, the number of terminals is one of the key features included in our model.
In practice, the antenna transmit power varies as the terminal service modes change. Therefore, it is important to consider both the impact of terminal service modes on transmit power and the effect of antenna transmit power on the level of electromagnetic radiation. An analysis of monitoring data from selected areas in Lagos reveals that the electric field intensity changes with different terminal service modes (
Table 5). The data transmission mode results in significantly higher electric field intensity compared to voice communication, with different service modes corresponding to varying data transmission rates (
Table 6). As a result, we have included the 5G terminal service mode (TSM) as a feature in our model.
Data for our model was collected from 52 base stations across various regions of Lagos, Nigeria. These base stations are situated in diverse environments, ranging from busy streets to remote suburbs. To account for the potential reflections and diffractions caused by nearby buildings on test site results, we included environmental variables as inputs, considering both line-of-sight (LOS) and non-line-of-sight (NLOS) transmission scenarios. Consequently, the complex surrounding environment of each 5G base station (C) became a key characteristic. Lagos, Nigeria, experiences two primary seasons: the wet and dry seasons. Prior studies [
32,
33] have shown that atmospheric refractivity is higher during the wet season compared to the dry season, making the wet season the worse atmospheric period for analysis. Therefore, the RF measurement campaign was conducted in August 2024, at the height of the rainy season, to capture the effects of atmospheric attenuation. The height of the base station is 60 m according to the service providers, while the height of the receiving station is maintained at 1 m throughout. The measurements were taken at a distance ranging from 0.5 m to 3 m away from the base station.
The level CCC (climate change commission) in the document, as produced by the Lagos State Ministry of Environment [
34], represents the environmental complexity surrounding the base stations. It is categorized into three levels, 1, 2, and 3, which correspond to dense urban areas, urban regions, and suburban areas, respectively. The primary criterion for determining CCC is the building density, while the secondary criterion is the population density around the base stations. Building density is defined as the ratio of the building coverage area to the total area, represented by a circle centered at the base station, with the radius being the distance from the base station to the monitoring point. The population density map helps clarify the population distribution and allows for easy differentiation between densely urban, urban, and suburban areas.
We have established the calculation procedures for CCC based on the principles outlined in the “Lagos Master Plan” as follows:
Dense urban areas are defined as regions where building coverage exceeds 70% of the total area or where the population density is greater than 20,000 people per square kilometer. The entire area is defined by a circle with the base station at its center and the radius being the distance between the base station and the monitoring point.
Suburban areas are characterized by having less than 50% building coverage of the total area or a population density of 7000 or fewer people per square kilometer.
The remaining areas are classified as urban areas.
2.4. Estimation of Frequency-Selective Signal Field Strength
Lekki is a narrow stretch of land situated between two major bodies of water: the Atlantic Ocean to the south, known for its sandy beaches, and the Lekki and Lagos Lagoons to the north, which form its natural northern boundary. This positioning gives Lekki a long, strip-like shape, extending roughly from the east to the west. The urban development in Lekki follows a linear pattern centered around the Lekki-Epe Expressway, which acts as the main transportation route. The region is divided into phases (like Lekki Phase 1 and 2) and various residential estates, resulting in a grid-based street network radiating from the main road. The topography is mostly flat and low-lying and only a few meters above sea level, making it prone to flooding during heavy rainfall or tidal surges. The landscape includes mangroves, swamps, and reclaimed land, with areas like the Lekki Conservation Centre helping to protect the region’s biodiversity and wetlands.
Lagos Island is a compact, naturally formed island with an irregular coastline, and it is surrounded by Lagos Lagoon, Five Cowrie Creek, and other waterways. It has high-density urban structures, blending residential, commercial, and historical areas. The road layout combines planned grid patterns and organic street designs, especially in older neighborhoods. Like much of Lagos, the island is flat and close to sea level. It is well-connected to surrounding districts via key bridges such as the Carter Bridge, Eko Bridge, and Third Mainland Bridge, reflecting a mix of natural geography and intensive urban development.
Ajah is shaped by its coastal, linear layout, running along the Lekki-Epe Expressway, with growth patterns that reflect both planned estates and informal expansion. The area is flat and low-lying and bordered by creeks and lagoons, which contribute to its partially fragmented, organically growing form. Ajah’s development is influenced by nearby wetlands and water bodies, resulting in a mix of residential sprawl and natural features.
At the millimeter-wave range, propagation is highly sensitive to material properties around the base station, with strong attenuation through the walls, glass, and trees; it behaves almost like line-of-sight propagation. Common materials found around the study areas are dry concrete, brick, glass (window), dry and wet asphalt, vegetation, metallic poles ocean (salt water), and fresh water.
Based on the defined inputs and outputs, the dataset for training and evaluating the random forest regression model is derived from the measured results of 52 base stations. The dataset consists of 1344 measured data points, which are randomly split into two parts: 942 data points (70%) for the training set and 402 data points (30%) for the test set. The random forest regression model is trained using the training set, and the optimal parameters are selected. The performance of the model is assessed using the MAPE and RMSE on the test set as
where
is the measured electric field strength in the test set,
is the estimated electric field strength, and
n is the number of data points in the test set.
The maximum depth of decision trees (
D), the number of decision trees (
), and the maximum number of features that can be employed in the creation of decision trees (
) are the three key parameters of the random forest regression model. The maximum depth of decision trees is used to limit the depth of decision trees when the model with many features is trained with a small amount of data. This helps prevent the model from becoming overly complex and from underperforming in terms of generalization. The complexity and ability of the model to capture relationships are primarily influenced by the number of decision trees. The differentiation between decision trees depends largely on the maximum number of features used during the development process. The optimal values for these parameters can be determined using ten-fold cross-validation [
25,
36,
37]. In this method, the dataset is randomly divided into ten subsets, with each subset used once as the validation set, and the validation process is repeated ten times, in line with the ten-fold cross-validation approach.
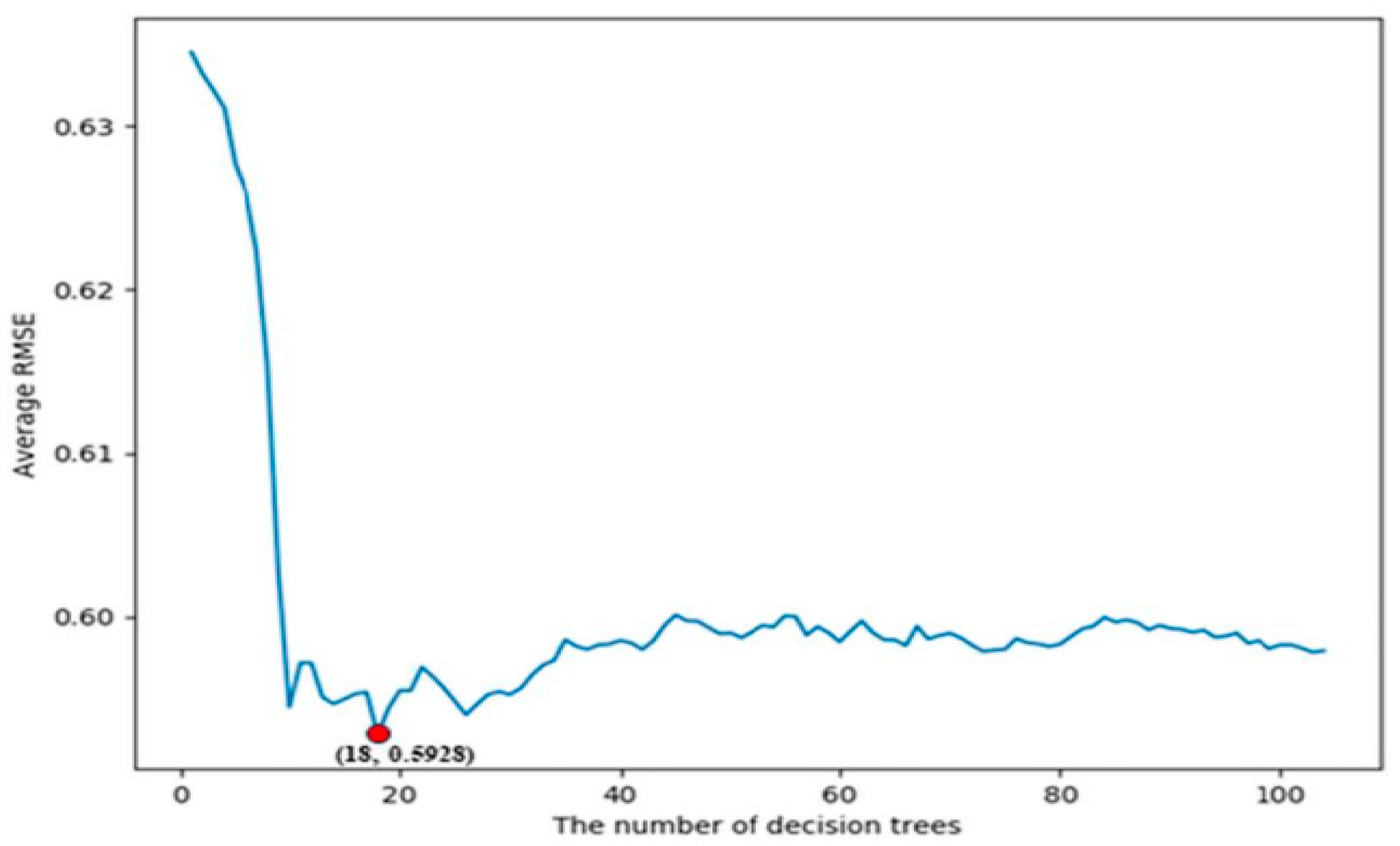
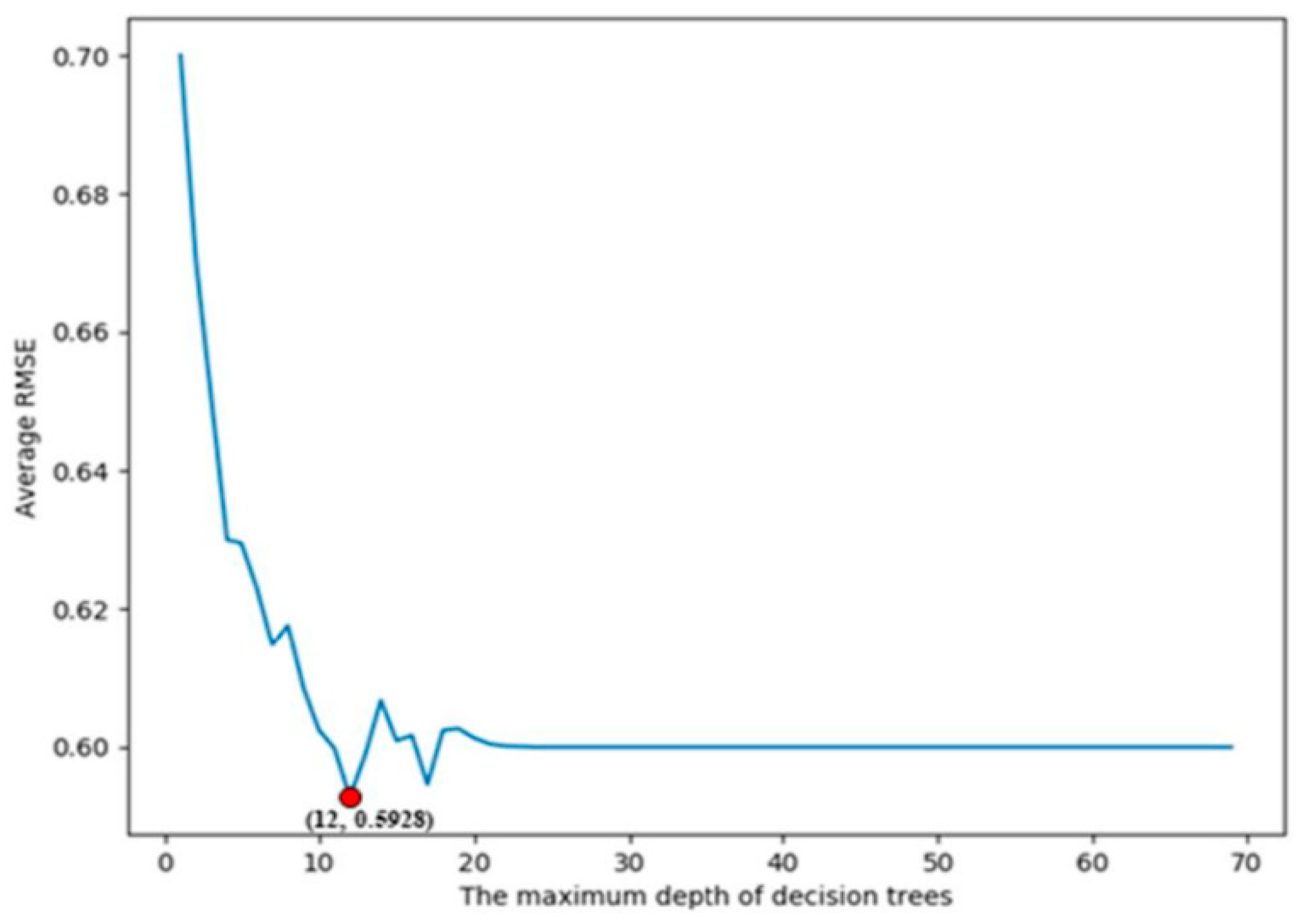
The entire model training process was conducted using an 8th Generation Intel Core i7 processor, 16 GB of RAM, a 64-bit operating system, and a 1 TB hard drive, with Python as the development software and Scikit-learn 0.24.1 as the framework. The model took approximately 3821.6 s, or 1.06 h, to complete training. To assess the real performance of the machine learning model with various parameters, we averaged the MAPE and RMSE across ten validation sets. Through this evaluation, we determined the values of
D,
, and
to be 12, 18, and 3, respectively. Specific parameters and settings for the random forest regression model are provided in
Table 7.
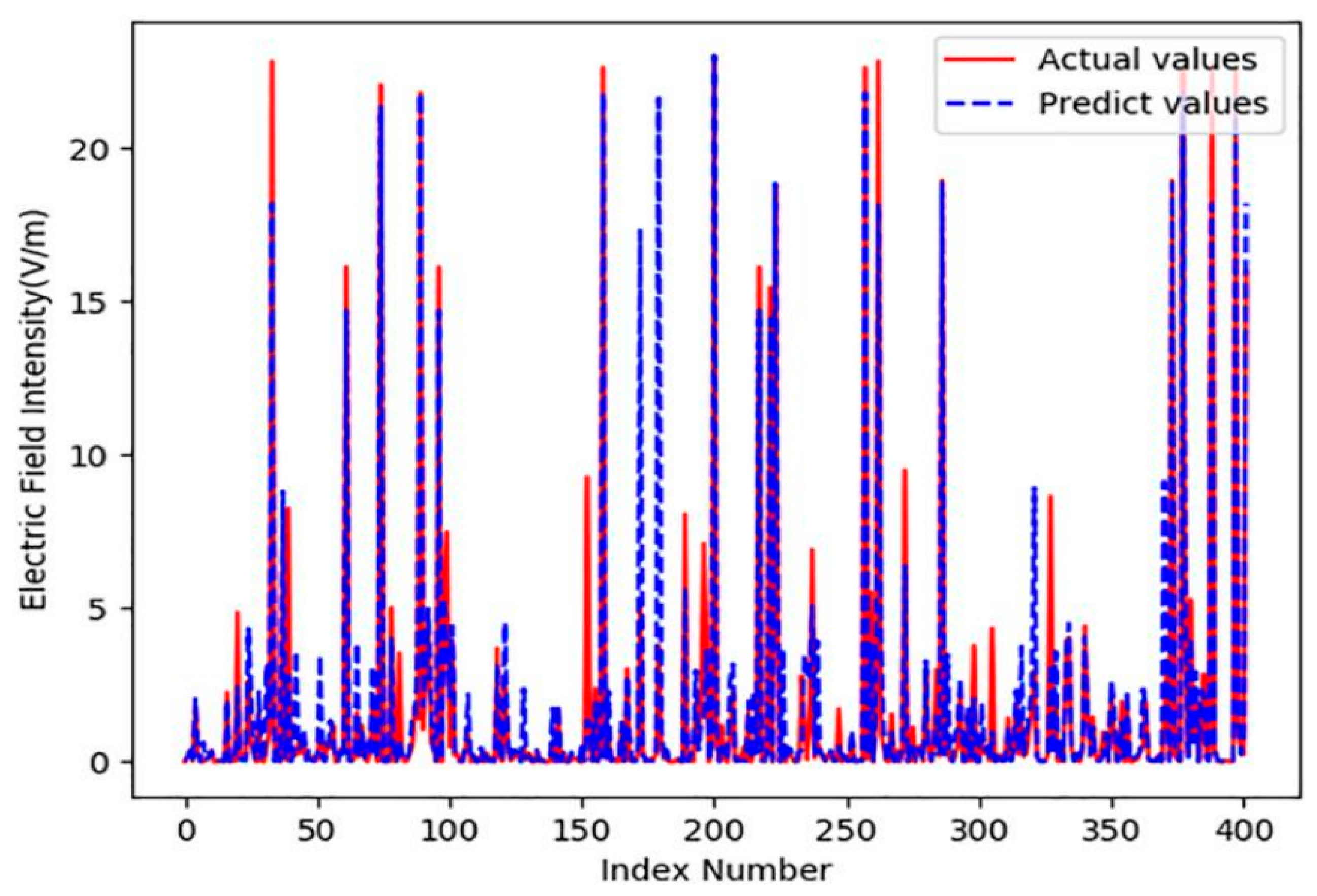
Using the random forest regression model with the optimal settings mentioned above,
Figure 7 presents a comparison between the estimated electric field strength and the measured values, with index numbers ranging from 1 to 404 in the test set. According to
Figure 8, the predicted values appear to be consistently lower than the measured ones in regions where the field strength is high. For instance,
Figure 7 shows that estimation errors can reach around 5 V/m. Such discrepancies could mean the difference between a measurement point complying with safety limits or not. This highlights the importance of conducting on-site measurements to ensure accurate compliance verification.
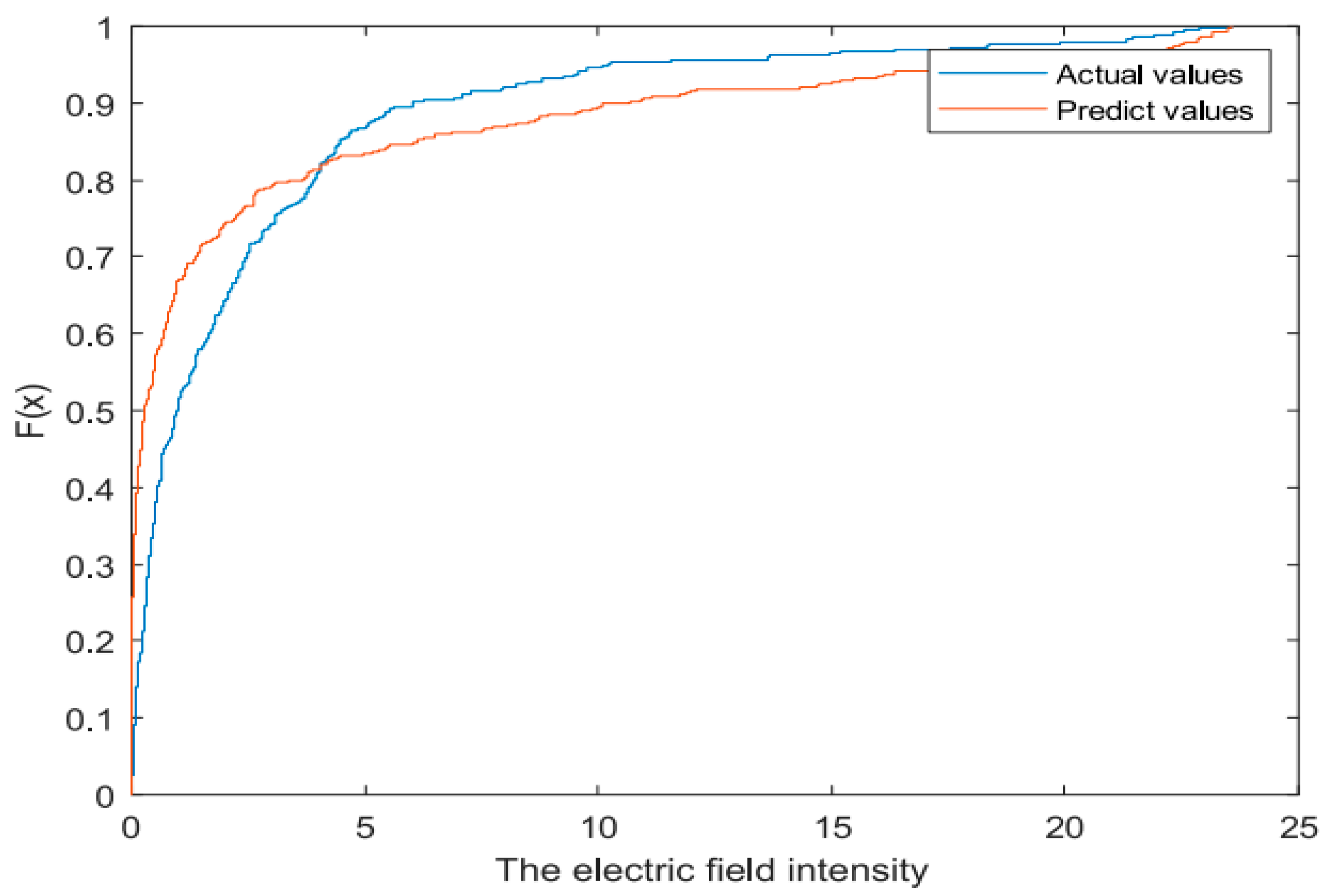
Figure 8 compares the measured values with the predicted values in the CDF plots of electromagnetic fields. The results indicate a strong agreement between the estimated and measured electric field intensities at different locations. Any observed discrepancies are likely due to occasional interference in the measurement environment, such as the presence of other 5G terminals or urban railroads, which were not considered in the estimation process. Additionally, we calculated the Root Mean Square Error (RMSE) and Mean Absolute Percentage Error (MAPE) to evaluate the performance of the estimation method. The results revealed an RMSE of 0.5928 and an MAPE of 5.985%. These findings further validate the effectiveness and reliability of the estimation technique. The proposed model is capable of accurately estimating the radiation field intensity of 5G base stations by considering a broad range of factors that influence electromagnetic radiation, thanks to its comprehensive analysis of multi-dimensional data.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}