
Occlusion-Robust Multi-Target Tracking and Segmentation Framework with Mask Enhancement


Abstract
:1. Introduction
- We propose a mask-conditional feature fusion network that integrates a mask-guided attention mechanism and a spatial–temporal feature aggregation sub-network. The network improves tracking robustness under crowded scenes. The network leverages temporal information from short trajectories and learns to generate occlusion-robust spatial–temporal aggregation features under the guidance of masks.
- We present an occlusion-aware mask propagation network. The network prevents the contamination of online tracking templates from noise inputs by perceiving the occlusion states of targets. It completes the association of missing trajectory segments through a constructed mask propagation network.
- We propose a mask-enhanced multi-object tracking and segmentation framework. This framework combines mask-based methods with a mask-integrated multi-hypothesis tracking algorithm to achieve adaptability in occluded scenarios and enhance the robustness of the MOTS framework.
2. Related Works
2.1. Trajectory Association Algorithms
2.2. Instance Segmentation-Based Multi-Object Tracking
2.3. Multi-Object Tracking and Segmentation Frameworks
3. Methodology
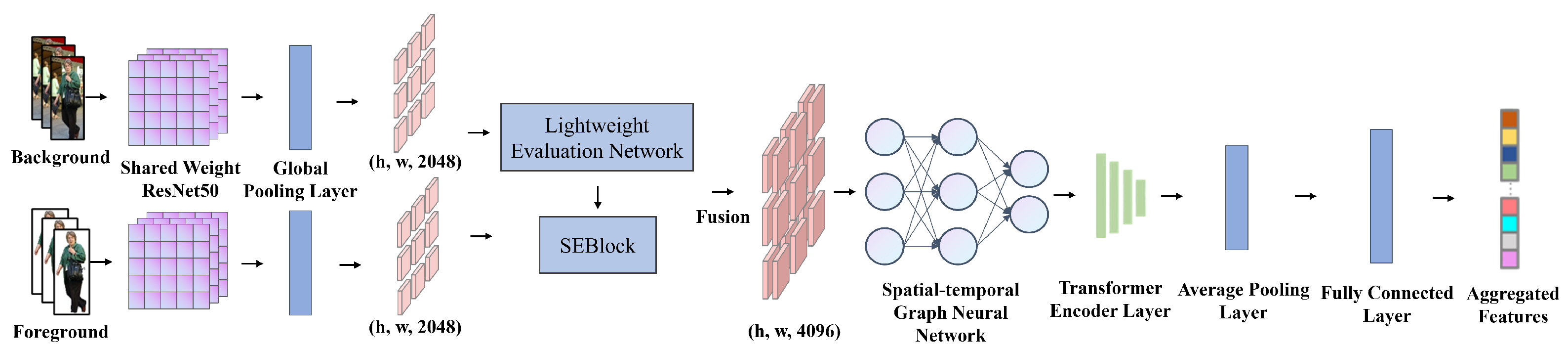
3.1. Mask-Conditioned Feature Fusion Network
3.1.1. Mask-Attentive Dual-Stream Encoder
3.1.2. Adaptive Feature Fusion Sub-Module
3.1.3. Spatial–Temporal Aggregation Sub-Network
3.2. Occlusion-Aware Mask Propagation Network
3.2.1. Occlusion State Perception with Mask IoU
- If there exists a target i such that , this indicates that target A overlaps with another target. To determine whether A is the occluder or the occluded, is used:
- –
- If A is smaller than , this indicates a rapid decrease in the mask area , which means that A is an occluder ( = 1);
- –
- If A is larger than , this indicates no decreasing trend in the mask area, which means that A is the occluder ( = 2).
- If there is no target i that satisfies , the occlusion state is also determined by :
- –
- If A is larger than , this indicates no occlusion ( = 0);
- –
- If A is smaller than , this indicates occlusion by non-target objects ( = 3).
3.2.2. Robust Mask Propagation Network
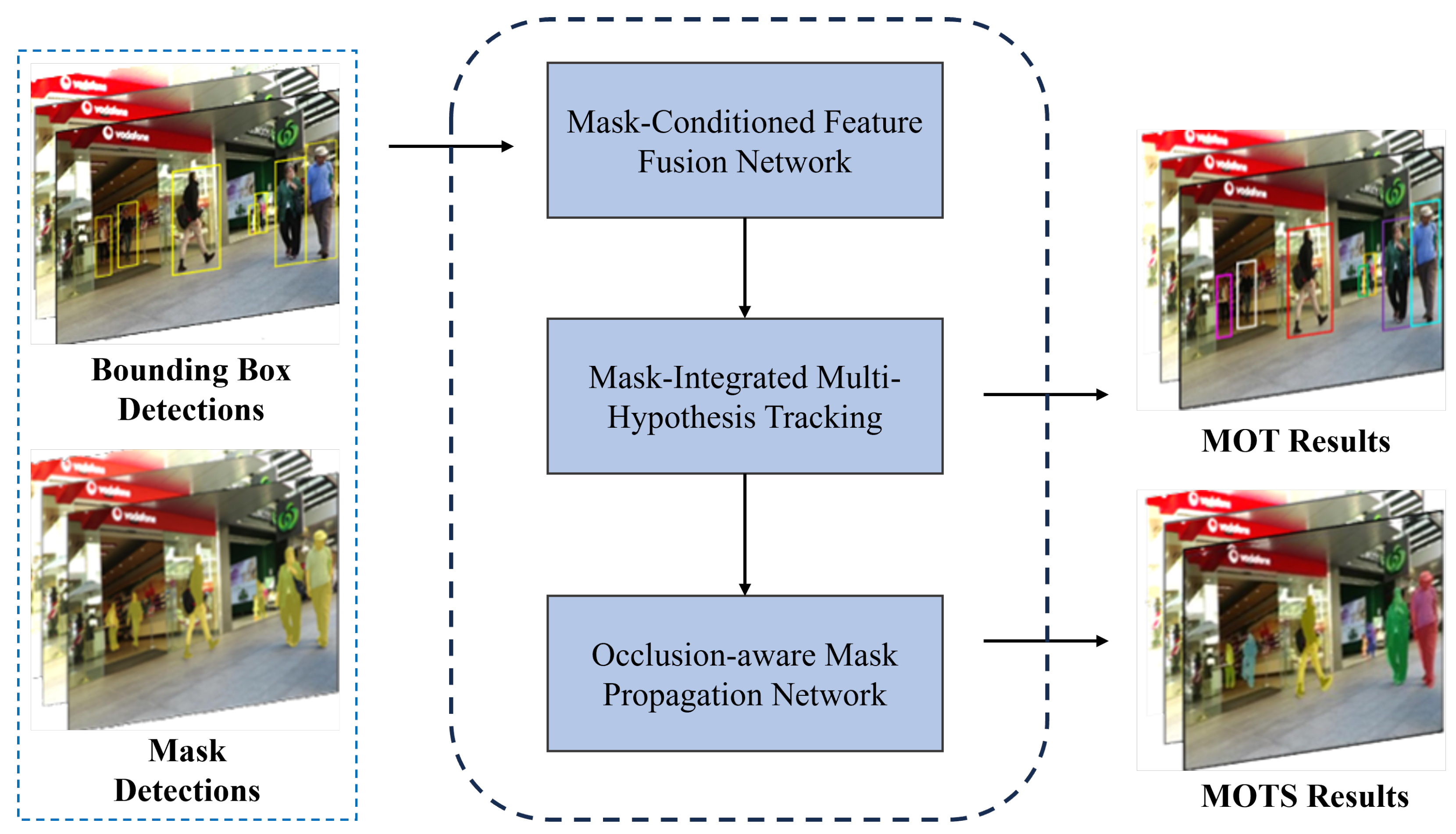
3.3. Mask-Enhanced Multi-Object Tracking and Segmentation Framework
3.3.1. Mask-Integrated Multi-Hypothesis Tracking
3.3.2. Mask-Enhanced Multi-Hypothesis Tracking Framework
- Short tracklet generation. Match background tracklets with foreground tracklets and generate short tracklet pairs. The tracklets to be matched come from detections generated by object detection and instance segmentation. These tracklet pairs have one-to-one correspondence with targets and are used for subsequent feature extraction and track association.
- Short tracklet representation. Based on the Mask-Conditioned Feature Fusion Network, extract the spatial–temporal features of target tracklet pairs to generate more robust features suitable for occluded scenarios. They are used for subsequent data association.
- Track association with multi-hypothesis tracking algorithm. For target A in frame t, if or , update the tracker’s internal template using the MHT algorithm. Compute similarity between adjacent nodes through mask association evaluation and perform track association.
- Occlusion state perception. Use the crowded perception model to detect target occlusion states. If or , perform data association as described in step (3). If or , suspend template updates in the multi-hypothesis tracker and proceed to step (5) for occluded track completion.
- Mask propagation. Generate target masks in occluded regions with the mask propagation network from Section 3.2 to complete missing track segments. When the target disappears or , return to step (3) for tracking with the MHT algorithm and complete the association of all track segments.
4. Experiments
4.1. MOTS Dataset
4.2. Implementation Details
- Short trajectory pair length: 3.
- Average confidence filtering threshold for short trajectory pairs: 0.7.
- Pruning backtracking layers: 5.
- Target disappearance window length: 20.
4.3. Performance Metrics
4.4. Ablation Experiment
4.5. Experiment Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | MOTSA↑ | IDF1↑ | sMOTSA↑ | MOTSP↑ | MT↑ | TP ↓ | FP ↓ | FN ↓ |
|---|---|---|---|---|---|---|---|---|
| TrackRCNN [1] | 55.2 | 42.4 | 40.6 | 76.1 | 127 | 19,628 | 1261 | 12,641 |
| MPNTrackSeg [47] | 73.7 | 68.8 | 58.6 | 80.6 | 207 | 25,036 | 1059 | 7233 |
| GMPHD_MAF [10] | 83.3 | 66.4 | 69.4 | 84.2 | 249 | 28,284 | 935 | 3985 |
| EMNT [46] | 83.7 | 77.0 | 70.0 | 84.1 | 234 | 27,943 | 666 | 4326 |
| ReMOTS_ [45] | 84.4 | 75.0 | 70.4 | 84.0 | 248 | 28,270 | 819 | 3999 |
| Our Method | 84.4 | 75.1 | 70.2 | 84.3 | 254 | 28,504 | 1043 | 3765 |
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Sekar, B.B.G.; Geiger, A.; Leibe, B. Mots: Multi-object tracking and segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7934–7943. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Chaabane, M.; Zhang, P.; Beveridge, J.R.; O’Hara, S. DEFT: Detection Embeddings for Tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10–25 June 2021. [Google Scholar]
- Liu, T.; Wang, G.; Yang, Q. Real-time part-based visual tracking via adaptive correlation filters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4902–4912. [Google Scholar]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 4696–4704. [Google Scholar]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Ke, W.; Xiong, Z. Multiplex Labeling Graph for Near-Online Tracking in Crowded Scenes. IEEE Internet Things J. 2020, 7, 7892–7902. [Google Scholar] [CrossRef]
- Wu, J.; Cao, J.; Song, L.; Wang, Y.; Yang, M.; Yuan, J. Track to detect and segment: An online multi-object tracker. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10–25 June 2021; pp. 12347–12356. [Google Scholar]
- Chu, P.; Ling, H. FAMNet: Joint Learning of Feature, Affinity and Multi-Dimensional Assignment for Online Multiple Object Tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6171–6180. [Google Scholar]
- Vermaa, J.; Doucet, A.; P’erez, P. Maintaining multi-modality through mixture tracking. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; Volume 2, pp. 1110–1116. [Google Scholar]
- Song, Y.; Yoon, Y.; Yoon, K.; Jeon, M.; Park, D.; Paik, J. Online Multi-Object Tracking and Segmentation with GMPHD Filter and Mask-Based Affinity Fusion. arXiv 2020, arXiv:2009.00100. [Google Scholar]
- Chen, L.C.; Hermans, A.; Papandreou, G.; Schroff, F.; Wang, P.; Adam, H. MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4013–4022. [Google Scholar]
- Hafiz, A.M.; Bhat, G.M. A Survey on Instance Segmentation. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cox, I.J.; Hingorani, S.L. An efficient implementation of reid’s multiple hypothesis tracking algorithm and its evaluation for the purpose of visual tracking. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 148–150. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Rehg, J.M. Multi-Object Tracking with Neural Gating Using Bilinear LSTM. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 208–224. [Google Scholar]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Lyu, W.; Ke, W.; Xiong, Z. Long-Term Tracking with Deep Tracklet Association. IEEE Trans. Image Process. 2020, 29, 6694–6706. [Google Scholar] [CrossRef]
- Chu, Q.; Ouyang, W.; Li, H.; Wang, X.; Liu, B.; Yu, N. Online Multi-Object Tracking Using CNN-Based Single Object Tracker with Spatial-Temporal Attention Mechanism. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Saleh, F.; Aliakbarian, S.; Rezatofighi, H.; Salzmann, M.; Gould, S.; Petersson, L.; Garg, S. Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 14324–14334. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking. International Journal of Computer Vision 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Alexander, P. Cityscapes. Methodist Debakey Cardiovasc. J. 2022, 18, 114–116. [Google Scholar] [CrossRef] [PubMed]
- Neuhold, G.; Ollmann, T.; Bulo, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 159–183. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 847–856. [Google Scholar]
- Khoreva, A.; Benenson, R.; Ilg, E.; Brox, T.; Schiele, B. Lucid Data Dreaming for Video Object Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2019; pp. 1175–1197. [Google Scholar]
- Rothberg, M.B.; Vakharia, N. Object Segmentation with Joint Re-identification and Attention-Aware Mask Propagation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 1322–1324. [Google Scholar]
- Perazzi, F.; Khoreva, A.; Benenson, R.; Schiele, B.; Sorkine-Hornung, A. Learning video object segmentation from static images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3491–3500. [Google Scholar]
- Wang, W.; Shen, J.; Xie, J.; Cheng, M.-M.; Ling, H. Super-Trajectory for Video Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1680–1688. [Google Scholar]
- Bertasius, G.; Torresani, L. Classifying, Segmenting, and Tracking Object Instances in Video with Mask Propagation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9736–9745. [Google Scholar]
- Sun, C.; Wang, D.; Lu, H. Occlusion-Aware Fragment-Based Tracking with Spatial-Temporal Consistency. IEEE Trans. Image Process. 2016, 25, 3814–3825. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Shen, J.; Yu, D.; Wang, W.; Liu, J.; Huang, H. Occlusion-Aware Real-Time Object Tracking. IEEE Trans. Multimed. 2017, 19, 763–771. [Google Scholar] [CrossRef]
- Stadler, D.; Beyerer, J. Improving Multiple Pedestrian Tracking by Track Management and Occlusion Handling. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 10953–10962. [Google Scholar]
- Yang, L.; Fan, Y.; Xu, N. Video Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5187–5196. [Google Scholar]
- Song, C.; Wang, Y.; Huang, Y.; Ouyang, W.; Wang, L. Mask-Guided Contrastive Attention Model for Person Re-Identification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Qi, M.; Wang, S.; Huang, G.; Lu, H.; Zhang, L. Mask-guided dual attention-aware network for visible-infrared person re-identification. Multimed. Tools Appl. 2021, 80, 17645–17666. [Google Scholar] [CrossRef]
- Cai, H.; Wang, Z.; Cheng, J. Multi-scale body-part mask guided attention for person re-identification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1555–1564. [Google Scholar]
- Tian, M.; Yi, S.; Li, H.; Shen, X.; Jin, X.; Wang, X. Eliminating Background-Bias for Robust Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5794–5803. [Google Scholar]
- Dendorfer, P.; Osep, A.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S.; Leal-Taixé, L. MOTChallenge: A Benchmark for Single-Camera Multiple Target Tracking. Int. J. Comput. Vis. 2021, 129, 845–881. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yang, F.; Chang, X.; Dang, C.; Ge, Z.; Zheng, N. ReMOTS: Self-Supervised Refining Multi-Object Tracking and Segmentation. arXiv 2020, arXiv:2007.03200. [Google Scholar]
- Wang, S.; Sheng, H.; Yang, D.; Zhang, Y.; Wu, Y.; Wang, S. Extendable Multiple Nodes Recurrent Tracking Framework With RTU++. IEEE Trans. Image Process. 2022, 31, 5257–5271. [Google Scholar] [CrossRef] [PubMed]
- Bras’o, G.; Cetintas, O.; Leal-Taix’e, L. Multi-Object Tracking and Segmentation Via Neural Message Passing. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]


| Method | Technical Features | Advantages |
|---|---|---|
| Online methods [2,3,4,5,6,7,8] | Sequential frame processing | Real-time performance |
| Filter-based [9,10] | Motion/appearance modeling | Fast computation |
| MHT [5,14] | Multi-Hypothesis Trees | Comprehensive association |
| Kim et al. [15] | CNN features with MHT | Improved appearance modeling |
| Zhang et al. [16] | LSTM-enhanced MHT | Long-term dependency capture |
| Chu et al. [17] | Spatial–temporal attention | Occlusion handling |
| Sadeghian et al. [18] | LSTM networks | Temporal dependency modeling |
| Peng et al. [8] | Deep residual networks | Frame-to-frame similarity |
| Yi et al. [19] | CenterNet | Background bias reduction |
| Mask IoU Threshold () | MOTSA ↑ | sMOTSA ↑ | (FP + FN) ↓ |
|---|---|---|---|
| 63.5 | 45.5 | 2509 | |
| 64.9 | 46.8 | 2410 | |
| 65.0 | 47.9 | 2392 | |
| 64.8 | 46.3 | 2452 |
| Method | MOTSA ↑ | MOTSP ↑ | MT ↑ |
|---|---|---|---|
| Baseline | 74.9 | 86.7 | 42 |
| +LI | 74.7 | 86.5 | 110 |
| +LI+OA | 75.3 | 86.6 | 105 |
| +OA+MP | 75.4 | 87.0 | 110 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, H.; Zhang, D.; Yang, D.; Yang, D.; Liu, X.; Ke, W. Occlusion-Robust Multi-Target Tracking and Segmentation Framework with Mask Enhancement. Appl. Sci. 2025, 15, 6969. https://doi.org/10.3390/app15136969
Sheng H, Zhang D, Yang D, Yang D, Liu X, Ke W. Occlusion-Robust Multi-Target Tracking and Segmentation Framework with Mask Enhancement. Applied Sciences. 2025; 15(13):6969. https://doi.org/10.3390/app15136969
Chicago/Turabian StyleSheng, Hao, Defa Zhang, Dazhi Yang, Da Yang, Xi Liu, and Wei Ke. 2025. "Occlusion-Robust Multi-Target Tracking and Segmentation Framework with Mask Enhancement" Applied Sciences 15, no. 13: 6969. https://doi.org/10.3390/app15136969
APA StyleSheng, H., Zhang, D., Yang, D., Yang, D., Liu, X., & Ke, W. (2025). Occlusion-Robust Multi-Target Tracking and Segmentation Framework with Mask Enhancement. Applied Sciences, 15(13), 6969. https://doi.org/10.3390/app15136969