3.1. Test Scenarios
The implemented simulator has been tested with two realistic large-scale microsimulation scenarios: a smaller scenario for the metropolitan area of Bologna, Italy, and a larger scenario for the entire San Francisco Bay Area. The main characteristics of the scenarios are summarized in
Table 4.
The Bologna SUMO scenario contains a detailed street network of the city of Bologna, covering approximately 50 km
2. It includes bikeways and footpaths but excludes the rail network. A simplified road network of 3703 km
2 extends into the metropolitan hinterland of Bologna; the entire simulated area has a population of about one million. The road network has been imported from Openstreetmap [
31] and manually refined. The travel demand has been essentially generated from the OD matrices. For the core part of the city, the OD matrices have been disaggregated to create a synthetic population with daily travel plans, including car, bicycle, motorcycle, and bus modes. The hinterland demand matrices were used to create trips for external and through traffic [
32,
33]. Public transport services have been created from GTFS data, obtained from the local bus operator TPER.
For a fair comparison with the parallelized simulation, the following modifications have been made to the original SUMO scenario: (1) Within the city area, the original SUMO scenario simulates the door-to-door trip of each person of the synthetic population, e.g., a person walking from their house to the parking area, taking their car, etc; as pedestrians are currently not simulated in ParSim, all walks have been removed and only vehicle movements have been retained. (2) The original scenario uses the SUMO sublane lane-change model, where, for example, a car and a bike can stay side by side in the same lane. As such detail is not modeled with the parallelized version, the sublane model has been replaced by a simplified lane-change model (LANECHANGE2013), where only one vehicle can stay at one place on the same lane. (3) The routes have been pre-calculated for the comparison, such that SUMO and ParSim use the exact same routes; no re-routing during the simulation run is performed.
The second scenario is the mesoscopic BEAM CORE model of the entire San Francisco Bay Area. The original scenario consists of only 10% of the active population [
14]. The BEAM CORE network and the travel plans have been imported into hybridPY. Like the Bologna model, only vehicle trips have been extracted and pedestrians are not simulated. The demand has been upscaled by a factor of 10 by replicating existing routes and randomly varying their departure time by ±15 min.
Concerning the computer hardware used for the tests, all experiments were performed on a laptop with a GeForce RTX 4060 GPU from NVIDIA, purchased in Italy, that contains 3072 CUDA cores and 8 GB of RAM. The CUDA version used was 12.8. The CPU running the SUMO version 1.23.1 simulation was a 12th-Gen Intel(R) i7-12700. Speed measurements are performed in headless mode, allowing ParSim to run at full GPU speed without rendering overhead. In addition, the time for uploading the data arrays into the GPU memory is excluded from the simulation runtime measurements.
3.2. Assessment with the Bologna Scenario
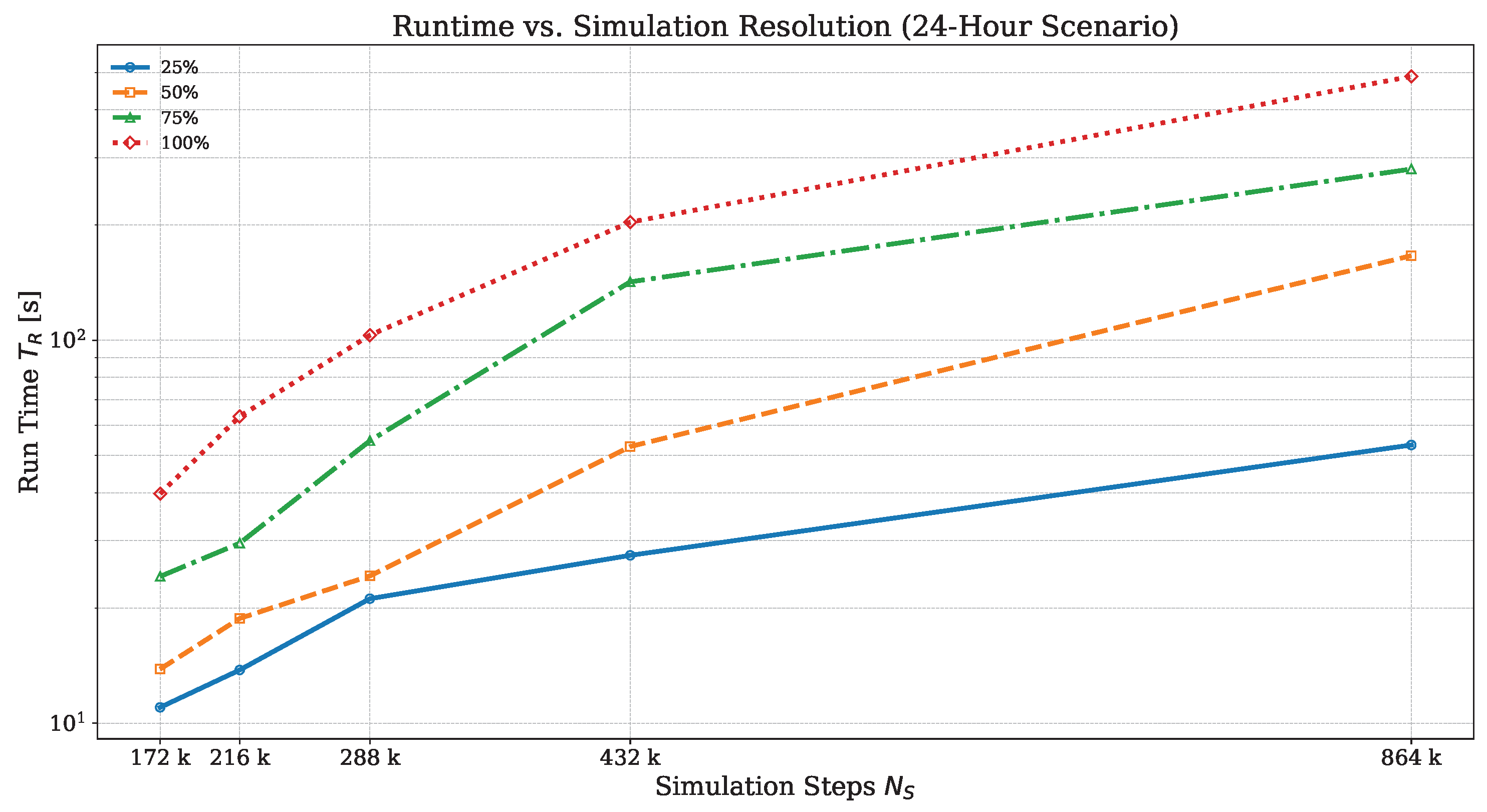
First, we examine with the Bologna scenario how the total runtime
increases with the number of simulated time steps
(e.g., the total simulated time divided by the simulation step time
) and the demand level (e.g., the total number of simulated trips).
Figure 7 shows that with a five-fold increase in the number of simulation steps
(from 172 k to 864 k) the runtime increases proportionally by a factor of
at the demand level of
.
The higher the demand level, the more disproportionately the runtime increases. At a demand level, the runtime increases 12 times when simulation steps are increased only five times. This effect could be explained by the higher number of vehicle transfers and interactions, which means more time is spent on atomic exchangers. However, more profiling is needed to identify the cause of the slowdown.
Next, the performance gains of ParSim, running on the GPU, versus the original SUMO simulation, running on a single core of the CPU, are investigated. Simulations of the 24 h Bologna scenario were repeated under four levels of traffic demand (
,
,
, and
). In each case, the exact same network, trips, and routes were used by the simulators and the simulation runtimes were recorded. From the runtimes in
Table 5 obtained from the Bologna scenario, it is again evident that the simulation times increase with increasing traffic. However, the SUMO simulation seems to be more affected than the ParSim simulation. This may be due to difficulties for SUMO in resolving congestion within the junction. Such artificial congestion can produce queues that can invade and gridlock the entire network. In fact, the average speed of the
SUMO simulation decreased to below 1 m/s toward the end of the simulation. SUMO has a teleport procedure (which triggers after a 90 s vehicle standstill) that can temporarily resolve mutual blocking by moving vehicles out of the junction to the next free edge. However, this is often not sufficient and the queues at affected junctions continue to grow. In any case, the performance gains of the GPU-based simulations transcend those of SUMO by factors between 1800 and 5000.
Concerning memory usage, the Bologna testbed exhibits a very compact memory footprint, increasing from only 132 MB at 25% demand to 258 MB at 50%, 404 MB at 75%, and just 503 MB at the full 100% scenario.
The accuracy and reliability of the GPU-based microsimulator have been evaluated by comparing two key indicators obtained from the ParSim and the SUMO simulation: (1) the average waiting time, which is the sum of all times during which the vehicle’s speed drops below 0.1 m/s—this is the way SUMO calculates the waiting time (for example in front of traffic lights)—and (2) the average speed of vehicles during their trips. The results of both indicators are summarized in
Table 6 for the two simulators. The waiting times for ParSim are generally lower and the average speeds higher, especially for higher demand levels. The average travel speeds can be used to quantify the error ParSim is showing with respect to SUMO due to the simplified dynamics at intersections. When comparing these speeds in the two simulators for demand levels where SUMO does not show deadlock phenomena (e.g., the 25% and 50% scenarios), the relative error of ParSim is between 11% and 15%, respectively.
The demand level has not been evaluated, as the SUMO simulation showed excessive congestion due to artificial deadlocks at intersections. Also, the demand level resulted in heavy congestion and gridlock, which is why the SUMO waiting times are considerably higher than those of ParSim for this scenario. ParSim has no gridlock situation, but it can create artificial slow-downs in a situation where the vehicle speed is suddenly set to zero because the successive edge is momentarily occupied. This means that both simulators may show unrealistic behavior but that this behavior occurs in different situations. With SUMO, deadlocks happen at complex and congested intersections, while with ParSim, slow-down effects are more serious if vehicles run at higher speeds and occur more frequently at high vehicle densities.
In order to get a clearer picture of the simulated traffic volumes, we have recorded the number of vehicles entering each edge for ParSim and SUMO. We show only results for the 25% and 50% demand level, as the SUMO starts to show gridlock phenomena for the 75% demand level that is increased even further in the 100% scenario.
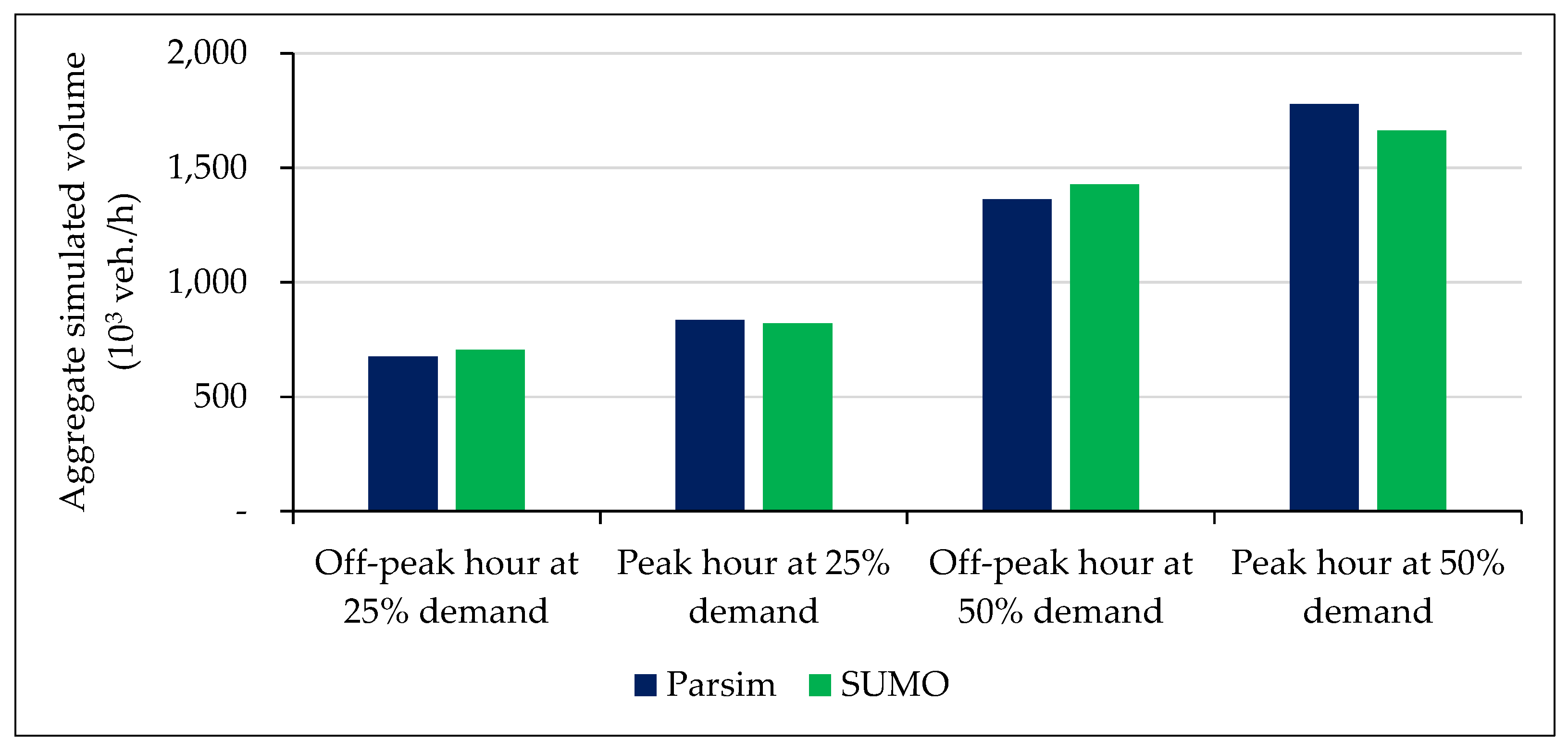
The total traffic volumes (the sum of vehicles entered in all edges) for off-peak and successive peak periods are shown in
Figure 8. ParSim and SUMO generated comparable aggregate traffic volumes across all scenarios. At both the 25% and 50% travel demand levels, ParSim estimated lower volumes during the off-peak hour (676.07 vs. 704.30 ×
veh/h at 25% demand and 1362.44 vs. 1427.02 ×
veh/h at 50% demand) and slightly higher volumes during the peak hour than SUMO (836.04 vs. 820.46 ×
veh/h at 25% demand and 1778.91 vs. 1662.64 ×
veh/h at 50% demand). Note that trips have exactly the same start time and the same routes for both simulators. The difference in flows during a certain time window is because the speed and number of crossed edges of an individual vehicle differs in the two simulators due to interactions with other vehicles and traffic lights.
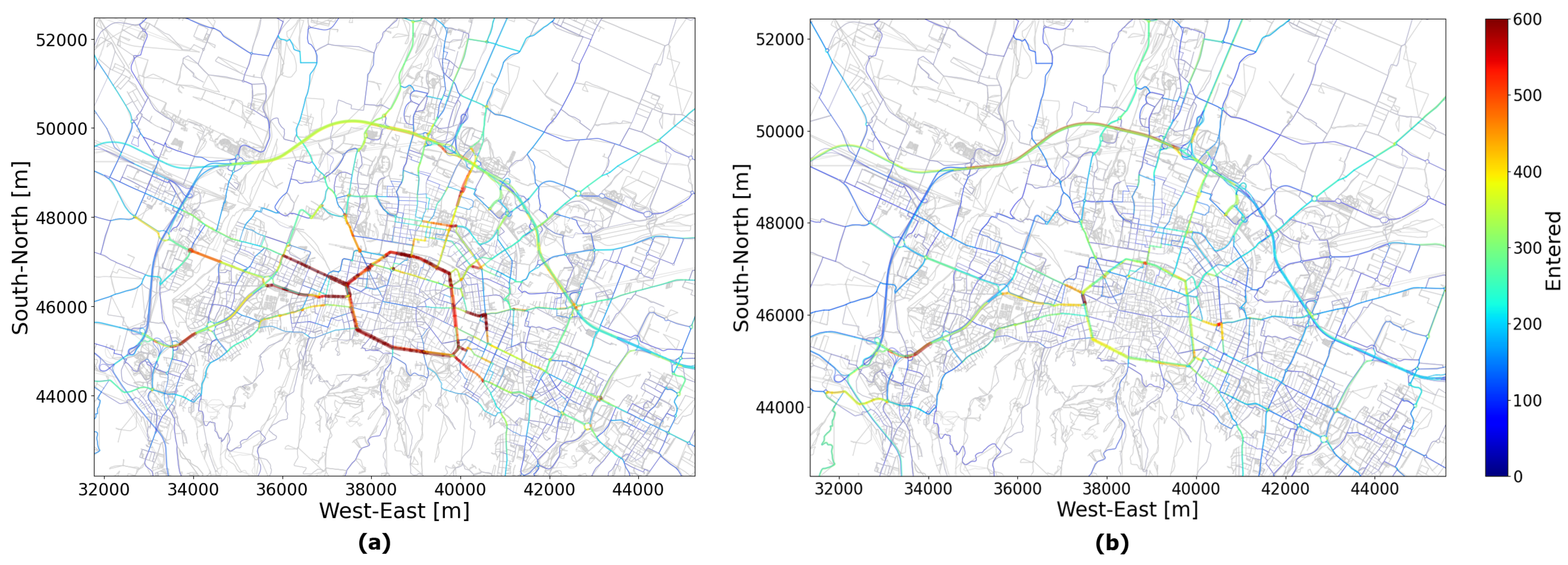
To better visualize the spatial distribution, the simulated edge flows are shown for the peak-hour scenario with
travel demand. It can be observed in
Figure 9 that edges with high vehicle flows are fairly similar in both ParSim and SUMO: higher traffic volumes are predominantly located along the inner ring road, the radial roads to/from the city center, and the outer ring road. In more detail, the volumes simulated by ParSim are slightly higher than those in SUMO for this scenario (
Figure 8), as indicated by the greater presence of red areas with flows reaching up to 500–600 vehicles per hour.
Pearson correlation coefficients (r) and mean absolute errors (MAEs) of edge-level traffic volumes simulated by ParSim and SUMO are compared during peak and off-peak hours under the
and
demand scenarios, as shown in
Table 7. The results demonstrate positive (
) and strong correlations (
) [
34] between the two simulation outputs.
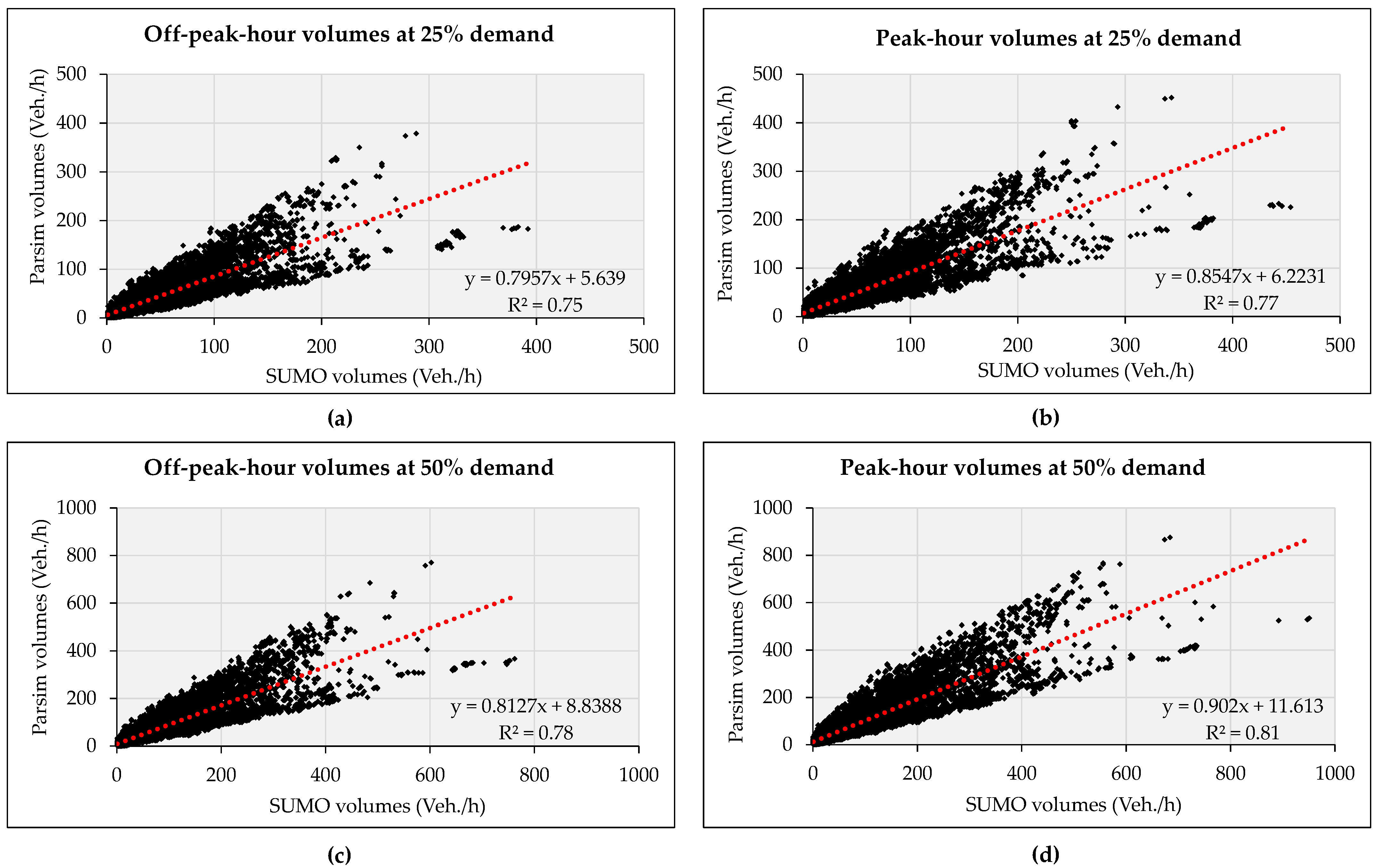
In addition, we also performed a regression analysis between the flows generated by ParSim and SUMO.
Figure 10 shows the flows from both simulators for each edge as a dot; slopes and
values are also reported. The ParSim simulation results closely matched those of SUMO, especially during peak hours at the 50% travel demand, with a slope of
and
of
, which are within acceptable thresholds according to [
35].


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}