1. Introduction
As the core power generation unit of marine vessels, marine main diesel engines are prone to frequent failures due to prolonged high-load operations under harsh marine conditions. Performance evaluation of these engines enables early prediction of impending failures and proactive warnings, thereby allocating sufficient time for corrective maintenance or preventive interventions. However, the structural complexity and variable operational conditions of marine diesel main engines present significant challenges in achieving reliable performance assessments. Conventional onboard data acquisition systems typically record limited operational parameters that insufficiently reflect the engine’s actual performance state, while critical deep-seated condition parameters remain unmonitored. All measurable parameters exhibit operational condition dependency, with early-stage performance degradation often manifesting as subtle fluctuations in these parameters. Such incipient anomalies are frequently obscured by strong background noise interference, rendering traditional threshold-based warning methods inadequate due to insufficient sensitivity and high false-alarm rates.
With the advancement of big data and communication network technologies, new requirements have been proposed for the intelligent operation and maintenance of marine diesel engines. The concept of the “smart ship” was first introduced by Det Norske Veritas (DNV) in its
Future Shipping Industry report in 2014, which significantly promoted global research in this field [
1]. In 2015, the China Classification Society (CCS) released the world’s first smart ship code, marking a major step forward for China in the development of smart ship technologies [
2]. Subsequently, in 2017, Lloyd’s Register published the
Design Rules for Intelligent Ship Systems, further providing technical guidance for this domain [
3]. To accelerate the development of intelligent ships, Prognostics and Health Management (PHM) technologies have been gradually introduced into the maritime industry [
4]. Data-driven PHM techniques establish fault prediction models by analyzing large volumes of historical data and use real-time equipment data for health management. From early sensor and data logging systems to today’s cloud computing and artificial intelligence technologies, PHM has continuously improved the reliability and availability of equipment [
5] while becoming increasingly intelligent and autonomous. Li et al. investigated the application of PHM in marine diesel engines, described the characteristics of traditional fault diagnosis methods, proposed a system architecture for diesel engine PHM, summarized the key enabling technologies, and provided insights into data analysis, fault diagnosis, early warning, and health management [
6]. It is evident that health assessment and fault diagnosis of marine diesel engines based on monitoring data, intelligent algorithms, and condition monitoring have become an inevitable trend in the intelligent operation and maintenance of ship propulsion systems. The core objective of intelligent marine diesel engine management lies in the real-time monitoring, evaluation, and analysis of engine health and operational performance to enable timely fault prediction. This technological pathway primarily relies on big data and information technologies to uncover latent correlations among performance parameters through data mining, allowing for accurate identification of both visible and latent fault features. Such approaches significantly enhance the level of intelligent decision making for marine diesel engines [
7]. Based on this objective, this study conducts research utilizing monitoring data to analyze and assess the health condition of marine main diesel engines. It quantifies the overall engine performance to visually observe operational trend variations and proposes a fault early-warning technique according to the degradation trend of holistic engine performance. This technique can issue pre-failure alerts before abnormal performance parameters emerge, thereby preventing potential malfunctions. The implementation of this technology enhances navigation safety and reliability while providing theoretical foundations and technical tools for intelligent ship maintenance systems.
During ship navigation, the vessel is not always in a steady state. Monitored data from navigation states such as acceleration, deceleration, and shutdown cannot characterize the overall performance of marine diesel main engines but rather reduce the accuracy of performance evaluation. Therefore, stable running intervals must be identified prior to analysis, with only steady-state navigation data used for performance assessment. Current mainstream steady-state detection algorithms fall into quantitative and qualitative categories. Qualitative methods include the confidence interval method, R-test, combined statistical testing, and SSD algorithm, while quantitative approaches encompass physics-informed neural networks (PINN) and modified adaptive polynomial filtering algorithms. The combined statistical test and confidence interval method proposed by Narasimhan [
8] in the 1980s detects steady states by comparing dual means and variances. However, its assumption of zero-mean normal distribution makes it vulnerable to interference in practical applications with insufficient robustness. The R-test improves F-test through variance ratio analysis, yet its threshold is significantly affected by filtering parameters and shows sensitivity to random noise with poor stability. Physics-informed neural networks integrate physical equations (e.g., partial differential equations, conservation laws, etc.) into loss functions to jointly optimize data fitting and physical constraints but exhibit convergence instability for high-dimensional nonlinear problems [
9]. The robust adaptive polynomial filtering algorithm (ASF) based on M-estimation detects states through threshold parameter comparison, offering advantages of fewer parameters and strong noise resistance, yet requires manual parameter setting and shows poor adaptability to steady-state fluctuations [
10]. In contrast, Kelly et al. used the SSD algorithm, hich constructs threshold criteria using Student’s
t-test within window widths and requires only two parameters (window width and significance level), while demonstrating superior performance in multivariate collaborative detection [
11]. Given that marine diesel main engine stability identification involves coupled analysis of multiple thermodynamic parameters, this study adopted the SSD algorithm to identify stable operating intervals. Its concise parameter system and multivariate compatibility effectively support steady-state discrimination requirements under complex operating conditions.
Current research on fault prediction can generally be categorized into two approaches: state prediction and state classification. State prediction, constrained by human factors and data quality, suffers from insufficient model accuracy due to challenges in realistically simulating diesel engine operating conditions and quantitative/qualitative modeling with scarce samples. For instance, Liu et al. developed a CNN-BiGRU-based exhaust temperature prediction model for marine diesel engines in which only exhaust temperature data were utilized for prediction. By artificially linearly adjusting the dataset to simulate abnormal exhaust temperature changes when potential faults occur in diesel engines, the model revealed prediction errors [
12]. Su et al. innovatively proposed a PCA-CNN-BiLSTM hybrid model, which employs only two parameters (after PCA dimensionality reduction) to represent overall engine performance and considers solely stable operating conditions of a specific diesel engine model with minimal load variations [
13]. Consequently, such prediction models struggle to establish corresponding fault prediction frameworks for complex, multivariate, and correlated fault systems [
14]. This study addresses this issue by adopting state classification with statistical data analysis methods to process multi-dimensional real-ship monitoring data, capturing temporal variations in statistical features while eliminating subjective influences, followed by autonomous operating condition partitioning. Current mainstream data analysis methods include principal component analysis (PCA), data mining clustering algorithms, and time series analysis. For example, Su et al. used PCA to extract two feature parameters that explained more than half of the characteristics in the sample data [
13], while Liu et al. derived performance parameters through coefficient and correlation efficiency definitions, established initial diesel engine performance maps via surface fitting, and tracked performance degradation trends by comparing real-time and initial performance maps [
15]. Fault warning methodologies are divided into physics-based models and data-driven approaches. Physics-based methods require precise mathematical or physical models to describe equipment operation [
14]. However, under dynamic load conditions, these models often produce larger errors, resulting in systemic biases in the data. In contrast, data-driven approaches construct analytical models based on historical operational data and utilize algorithms to mine potential fault features, effectively circumventing the complexities of physical modeling. With the advancement of intelligent algorithms, data-driven methods have become the dominant research direction in fault prediction for marine diesel engines.
The technical methods employed in this study include data mining clustering algorithms and time series analysis. Clustering algorithms are particularly suitable for solving complex operating condition partitioning in marine main diesel engines. For instance, Zheng et al. utilized the K-means clustering algorithm to partition engine operating intervals, followed by quadratic polynomial fitting to derive relationships between engine load and fuel consumption rates [
16]. Perera et al. applied the EM algorithm to identify the frequent operating ranges of marine diesel engines and analyzed engine performance using PCA [
17,
18]. Erik Vanem et al. explored methods including K-means clustering, Gaussian mixture models, density-based clustering, self-organizing maps, and support vector machines after data dimensionality reduction, concluding that dimensionality reduction may cause information loss. Although these methods are straightforward to implement, they require parameter tuning and validation prior to practical application [
19]. Time series analysis investigates statistical regularities in the temporal evolution of sequential data, enabling prediction and control of future events, such as preventing fault occurrences. Zhang et al. integrated time–domain analysis with deep learning algorithms, focusing on temporal characteristics of faults and resulting in higher diagnostic accuracy compared to traditional methods [
20]. Je-Gal H et al. proposed combining time–domain and frequency–domain analyses, achieving superior accuracy over frequency–domain methods alone [
21].
In current research on marine diesel engine fault prediction, the use of single or limited data sources to evaluate overall engine performance often results in incomplete assessments and introduces systematic bias into model predictions. Moreover, existing studies that focus solely on predicting stable operating conditions for a specific diesel engine model fail to adequately support the evolving dynamic requirements of intelligent ship engine operation and maintenance. To address these limitations, this study selected 22 performance parameters of a marine diesel engine over an extended time span. By incorporating the SSD steady-state detection algorithm, a data-driven approach using the CLIQUE clustering algorithm is herein proposed for autonomous classification of multi-parameter operating conditions. This approach overcomes the constraints of traditional single-variable or dimensionality-reduced methods, enabling objective and precise condition partitioning. The Mahalanobis distance was computed across different time points to construct a time series that provides a more comprehensive and accurate foundation for evaluating engine performance. Finally, a time–domain analysis method was employed for mutation detection in the performance degradation curve, thereby improving the accuracy of fault warning timing. The effectiveness of the proposed methodology was validated through experimental data.
2. Introduction to Performance Assessment and Fault Warning Methods
2.1. Steady-State Interval Identification Algorithm
Ships operate under various navigation states, such as acceleration, deceleration, and stoppage, resulting in the collection of substantial non-steady-state data by sensors. These transient datasets introduce significant interference in the performance evaluation of marine diesel main engines. The SSD (slope sign detection) steady-state detection algorithm, which requires minimal manual parameter configuration and demonstrates strong capability in multi-variable steady-state detection, is particularly suitable for identifying the stable operating ranges of marine diesel main engines [
11]. The fundamental principle of the SSD algorithm is as follows:
The SSD algorithm is based on the assumption that the system exhibits dynamic drift. The univariate process signal
y(
t) of the system is constructed by multiplying the relative time by a non-zero slope, with the mathematical expression formulated as follows:
In the equation, represents the dynamic drift component; denotes the cycle index; is the mean under the assumed steady-state condition, whose value equals the arithmetic mean or sample mean of the window when the slope is zero; corresponds to a white noise or random error sequence following a normal distribution (0,).
The difference between the signal
at the previous time step and the signal
at the current time step is
The steady-state judgment criterion is constructed using Student’s
t-test, with the mathematical expression formulated as follows:
In the equation,
is the critical value of Student’s
t-test, determined from statistical tables based on the significance level
and degrees of freedom v; when the significance level is set to 0.05, it implies a 5% Type I error rate (i.e., 5 non-steady-state data points out of 100 tested);
represents the standard deviation of the window sample, calculated as follows:
2.2. Operational Condition Classification Algorithm
Clustering algorithms demonstrate advantages in analyzing unlabeled marine diesel engine monitoring data through their capacity to automatically determine optimal cluster numbers via performance metrics, eliminating the need for manual intervention. The grid-based CLIQUE (Clustering In QUEst) algorithm, also recognized as a high-dimensional clustering approach, exhibits particular suitability for this study due to its inherent strengths in autonomous processing of high-dimensional datasets and independence from operator-specific domain expertise.
The fundamental principle of CLIQUE involves partitioning the multidimensional data space into non-overlapping rectangular cells of equal size. Cluster formation operates through density-based evaluation, where a cell exceeding a predefined density threshold qualifies as a dense unit. Cell density is defined by the number of data points contained within it. The final clusters emerge as maximally connected regions composed of adjacent dense cells [
22,
23].
A Priori Properties of the CLIQUE Clustering Algorithm:
Theorem 1. Anti-Monotonicity: If a k-dimensional spatial unit is dense, its projection onto any (k − 1)-dimensional subspace is also dense.
Theorem 2. If any projection of a k-dimensional spatial unit onto a (k − 1)-dimensional subspace contains one or more sparse units, the k-dimensional unit is necessarily non-dense.
Three-Step Procedure for CLIQUE Clustering in Multidimensional Space:
Step 1: Identification of All Dense Subspaces Containing Clusters
The multidimensional space is partitioned into disjoint rectangular units. Dense units are identified using the a priori properties via a bottom-up approach:
The multidimensional space is first partitioned into disjoint rectangular units, and the a priori properties are then utilized to determine whether these units are dense. The identification of dense units employs a “bottom-up” approach, which incrementally processes data from lower to higher dimensions. For instance, once the set of dense units Dk − 1 in the (k − 1)-dimensional space is identified, the candidate dense unit set for the k-dimensional space can be derived using the a priori properties. If is empty, the highest-dimensional subspace containing clusters is obtained. If is non-empty, the k-dimensional data are traversed again to eliminate non-dense units in using the a priori properties, yielding the dense unit set for the k-dimensional space. Subsequently, the candidate dense unit set for the (k + 1)-dimensional space is generated. This process iterates until the candidate dense unit set for a certain dimension becomes empty.
Step 2: Cluster Identification
Input: A set D of dense units in a k-dimensional subspace.
Output: A partition of D into connected components, where no two distinct components are interconnected.
This step is analogous to searching for connected components in a graph, where the units in the multidimensional space are treated as vertices, and an edge exists between two units if they are connected.
Step 3: Cluster Description Generation
Input: A dense unit set in a k-dimensional subspace, forming a cluster C.
Output: A collection R within the same subspace, where R ∈ C, and every unit in C belongs to at least one member of R. For each cluster, generate concise descriptions using the minimal covering hyper-rectangles of R.
From the analysis of the above clustering process, the CLIQUE algorithm implementation for marine diesel engine operational mode classification proceeds through the following systematized workflow:
- (1)
Dimensionality Specification: Determine the dimensionality of the multidimensional space according to the number of performance parameters required for operational mode differentiation;
- (2)
Grid Partitioning: Define parameter λ to partition each dimension into λ equal-length intervals, establishing the fundamental grid structure;
- (3)
Initial Candidate Generation: At k = 1 (where k denotes subspace dimensionality), designate all rectangular units as candidate dense units;
- (4)
Density Computation: Systematically examine each k-dimensional subspace to calculate unit densities, quantified as the number of data points contained within individual units;
- (5)
Dense Unit Identification: Apply density threshold τ to classify units exceeding this value as k-dimensional dense units;
- (6)
Subspace Pruning: Eliminate subspaces failing to meet minimum density criteria through iterative validation;
- (7)
Dimensionality Expansion: Generate (k + 1)-dimensional candidate dense units from the intersection of k-dimensional dense unit sets;
- (8)
Cluster Extraction: Identify final clusters as maximally connected regions within k-dimensional dense unit assemblies;
- (9)
Data Archiving: Store derived cluster characteristics and metadata in designated databases for subsequent operational mode analysis.
2.3. Performance Evaluation Metrics—Mahalanobis Distance
Marine diesel main engine performance parameters exhibit strong interdependencies with heterogeneous dimensionality and variation ranges. To address this multivariate challenge, the Mahalanobis distance (MD)—a covariance-based metric proposed by P.C. Mahalanobis—was adopted for its efficacy in quantifying similarity between multidimensional datasets. Consider a sample
x. The Mahalanobis distance from X to another sample set can be mathematically expressed as
In the equation,
denotes the sample mean of the dataset, and
represents the covariance matrix. When
reduces to an identity matrix, the Mahalanobis distance becomes equivalent to the Euclidean distance. Two critical properties emerge from this formulation: First, the Mahalanobis distance calculation is scale-invariant [
24], meaning it remains unaffected by measurement unit variations across parameters in different datasets. Second, through explicit incorporation of the covariance matrix, this metric inherently eliminates parameter correlations and incorporates the overall distribution characteristics of the dataset.
2.4. Fault Early Warning Method
The cumulative anomaly curve method and Yamamoto detection method were employed for abrupt change identification in the Mahalanobis distance time series.
2.4.1. Cumulative Anomaly Curve Method
The cumulative anomaly method calculates cumulative anomaly values for each temporal node, generating a time-indexed curve that visually represents trend variations. The curve’s inflection points, determined by slope direction reversals (ascending-to-descending or vice versa), approximate the timing of abrupt changes in the target time series [
25]. For a given time series
X, the cumulative anomaly at time
t is defined as
In the equation, denotes the mean value of series x.
2.4.2. Yamamoto Detection Method
The Yamamoto detection method identifies abrupt changes by assessing the statistical significance of mean differences between pre- and post-test point subsequences [
26]. This methodology conceptualizes abrupt change detection as a hypothesis-testing problem concerning population mean equivalence. For a given series
x, let
and
represent the sample sizes of the pre- and post-test subsequences, respectively. The signal-to-noise ratio (SNR) is defined as
In the equation, and represent the mean values of the pre- and post subsequences, respectively, with s1 and s2 denoting their standard deviations.
If the signal-to-noise ratio (SNR) is greater than 1.0, it is considered that an abrupt change occurs at that moment. If the SNR exceeds 2.0, the abrupt change is classified as a strong mutation. If the value of the SNR is set to 10, it corresponds to a confidence level of 95%, while a value of 14 corresponds to a confidence level of over 99.5%.
4. Conclusions
This study proposes a data-driven methodology for marine diesel engine performance assessment, effectively revealing performance degradation trends and enabling proactive fault warning through degradation pattern analysis. The results demonstrate the capability to detect and issue warnings for impending faults 20–30 days prior to measurable parameter anomalies. Key findings are summarized as follows:
(1) Utilizing 43,186 operational data points collected over one year, 37,026 stable samples were obtained through preprocessing and steady-state detection. The CLIQUE clustering algorithm automatically partitioned these samples into 33 operational conditions, with Condition 1 (containing 23,720 samples) identified as the dominant operational range. These results quantitatively validate the algorithm’s efficacy in automatic operational condition classification;
(2) Analysis of the Mahalanobis distances within the dominant operational range yielded a fitted performance degradation curve. While the initial phase followed empirical degradation patterns, subsequent abrupt changes and fluctuations indicated systemic anomalies. Sequential parameter elimination localized the anomaly near the No. 2 cylinder jacket cooling water outlet, with temporal analysis confirming abnormal parameter deviations.
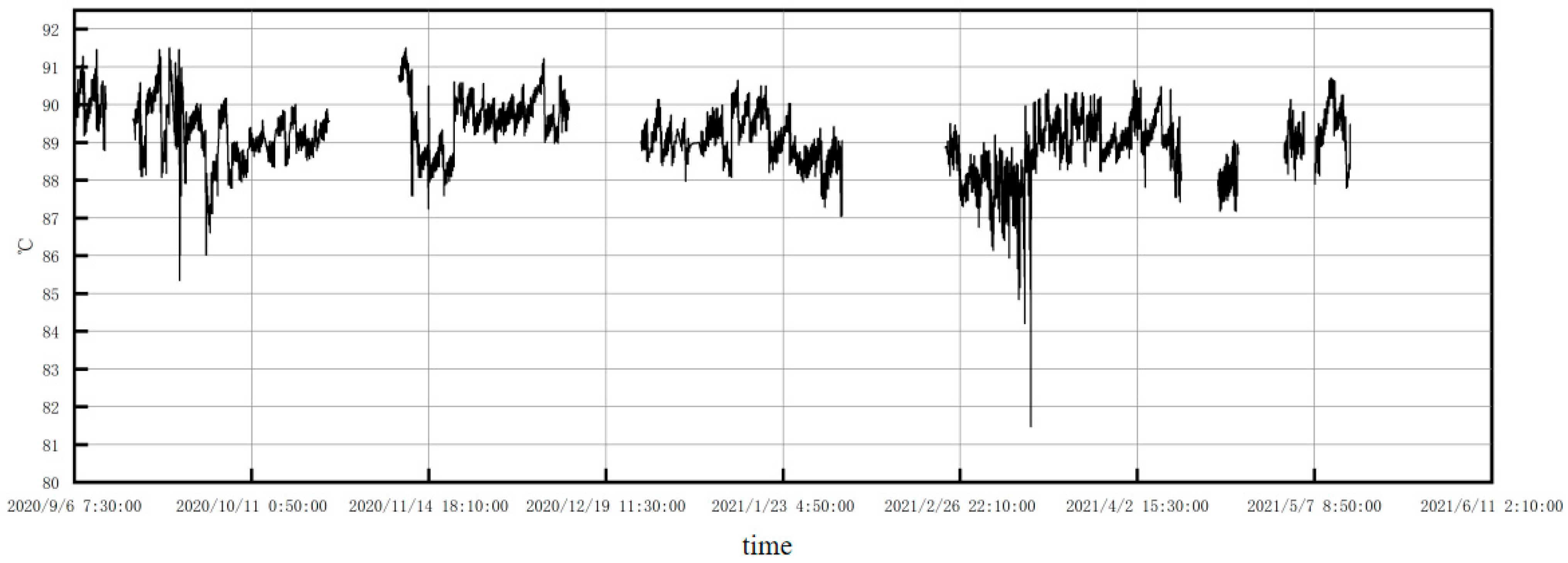
(3) Comparative analysis revealed that degradation curve destabilization preceded measurable temperature fluctuations at the No. 2 cylinder outlet by approximately 20 days, establishing a critical early-warning window. The time–domain analysis-based warning system demonstrated operational validity, with precise warning triggering at 18:10 on 25 January 2021.
The proposed methodology provides novel insights for marine diesel engine health management while offering methodological references for intelligent marine equipment condition classification and abrupt change detection. Future research will incorporate additional conventional thermodynamic parameters to enhance holistic engine performance characterization. Concurrently, algorithmic refinements to the SSD framework will implement adaptive window width configuration, establishing a data-driven foundation for integrated ship–shore performance diagnostics.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}