
MAS-YOLO: A Lightweight Detection Algorithm for PCB Defect Detection Based on Improved YOLOv12


Abstract
1. Introduction
2. Methodology
2.1. Original YOLOv12 Algorithm
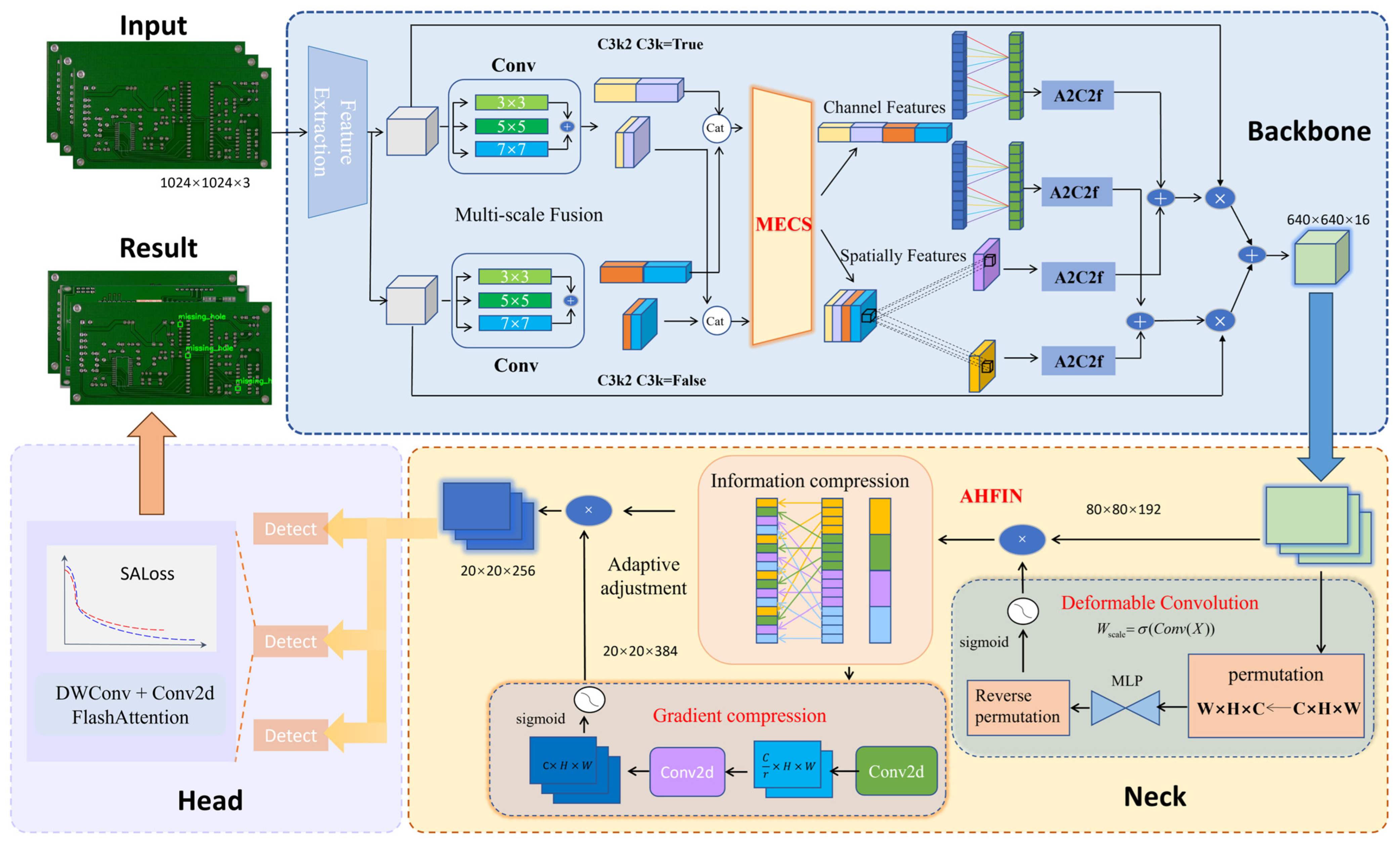
2.2. Improved YOLOv12 Algorithm
2.2.1. Median-Enhanced Channel and Spatial Attention Block (MECS)
2.2.2. Adaptive Hierarchical Feature Integration Network (AHFIN)
2.2.3. Slide Alignment Loss (SAL)
3. Experiment and Analysis
3.1. Datasets
3.1.1. Peking University PCB Defects Dataset
3.1.2. Kaggle PCBA Defects Dataset
3.2. Introduction to Experimental Environment and Indicators
3.3. Experimental Process
3.3.1. Comparison of Detection Performance Across Different Basic Models
3.3.2. Performance Evaluation and Comparative Experiments of MECS Module
3.3.3. Performance Evaluation and Comparative Experiments of AHFIN
3.3.4. The Comparison of the Impact of Loss Functions on the Training Process
3.3.5. Comprehensive Ablation Experiment
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, I.; Hwang, R. PCB defect detection based on Deep Learning algorithm. Processes 2023, 11, 775. [Google Scholar] [CrossRef]
- Fung, K.C.; Xue, K.-W.; Xue, K.; Lai, C.M.; Lin, K.H.; Lam, K.M. Improving PCB defect detection using selective feature attention and pixel shuffle pyramid. Results Eng. 2024, 21, 101992. [Google Scholar] [CrossRef]
- Liu, B.; Chen, D.; Qi, X. YOLO-pdd: A Novel Multi-scale PCB Defect Detection Method Using Deep Representations with Sequential Images. arXiv 2024, arXiv:2407.15427. [Google Scholar]
- Feliciano, F.; Leta, F.; Martins, F. Computer vision system for printed circuit board inspection. ABCM Symp. Ser. Mechatron. 2018, 3, 623–632. [Google Scholar]
- Harshitha, R.; Rao, M. Printed circuit board defect detection and sorting using image processing techniques. Int. J. Eng. Res. Electron. Commun. Eng. 2016, 3, 78–90. [Google Scholar]
- Zhou, Y.; Yuan, M.; Zhang, J.; Ding, G.; Qin, S. Review of vision-based defect detection research and its perspectives for printed circuit board. J. Manuf. Syst. 2023, 70, 557–578. [Google Scholar] [CrossRef]
- Trejo-Morales, A.; Bautista-Ortega, M.; Barriga-Rodríguez, L.; Cruz-González, C.E.; Franco-Urquiza, E.A. Development of an Image Processing Application for Element Detection in a Printed Circuit Board Manufacturing Cell. Appl. Sci. 2024, 14, 5679. [Google Scholar] [CrossRef]
- Wan, Y.; Gao, L.; Li, X.; Gao, Y. Semi-supervised defect detection method with data-expanding strategy for PCB Quality Inspection. Sensors 2022, 22, 7971. [Google Scholar] [CrossRef]
- Virasova, A.; Klimov, D.; Khromov, O.; Gubaidullin, I.R.; Oreshko, V.V. Rich feature hierarchies for accurate object detection and semantic segmentation. Radio Eng. 2021, 85, 115–126. [Google Scholar] [CrossRef]
- Ni, Y.-S.; Chen, W.-L.; Liu, Y.; Wu, M.-H.; Guo, J.-I. Optimizing Automated Optical Inspection: An Adaptive Fusion and Semi-Supervised Self-Learning Approach for Elevated Accuracy and Efficiency in Scenarios with Scarce Labeled Data. Sensors 2024, 24, 5737. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, M.; Gamanayake, C.; Yuen, C.; Geng, Z.; Jayasekara, H.; Zhang, X.; Woo, C.; Low, J.; Liu, X. Deep learning based solder joint defect detection on industrial printed circuit board X-ray images. Complex Intell. Syst. 2022, 8, 1525–1537. [Google Scholar] [CrossRef]
- Jiang, S.; Lin, H.; Ren, H.; Hu, Z.; Weng, L.; Xia, M. Mdanet: A high-resolution city change detection network based on difference and attention mechanisms under multi-scale feature fusion. Remote Sens. 2024, 16, 1387. [Google Scholar] [CrossRef]
- Chung, S.-T.; Hwang, W.-J.; Tai, T.-M. Keypoint-Based Automated Component Placement Inspection for Printed Circuit Boards. Appl. Sci. 2023, 13, 9863. [Google Scholar] [CrossRef]
- Zhan, Z.; Ren, H.; Xia, M.; Lin, H.; Wang, X.; Li, X. Amfnet: Attention-guided multi-scale fusion network for bi-temporal change detection in remote sensing images. Remote Sens. 2024, 16, 1765. [Google Scholar] [CrossRef]
- Cheng, P.; Xia, M.; Wang, D.; Lin, H.; Zhao, Z. Transformer Self-Attention Change Detection Network with Frozen Parameters. Appl. Sci. 2025, 15, 3349. [Google Scholar] [CrossRef]
- Liu, G.; Li, J.; Yan, S.; Liu, R. A Novel Small Target Detection Strategy: Location Feature Extraction in the Case of Self-Knowledge Distillation. Appl. Sci. 2023, 13, 3683. [Google Scholar] [CrossRef]
- Ran, G.; Lei, X.; Li, D.; Guo, Z. Research on PCB Defect Detection Using Deep Convolutional Neural Network. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 22–25 December 2020; pp. 1310–1314. [Google Scholar]
- Anitha, D.; Rao, M. A survey on defect detection in bare pcb and assembled pcb using image processing techniques. In Proceedings of the International Conference on Wireless Communications, Signal Processing and NETWORKING, Chennai, India, 22–24 March 2018; pp. 39–43. [Google Scholar]
- Ling, Q.; Isa, N.A. Printed circuit board defect detection methods based on image processing, machine learning and Deep Learning: A survey. IEEE Access 2023, 11, 15921–15944. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, L.; Li, C. CS-ResNet: Cost-sensitive residual convolutional neural network for PCB cosmetic defect detection. Expert Syst. Appl. 2021, 185, 115673. [Google Scholar] [CrossRef]
- Şimşek, M.A.; Sertbaş, A.; Sasani, H.; Dinçel, Y.M. Automatic Meniscus Segmentation Using YOLO-Based Deep Learning Models with Ensemble Methods in Knee MRI Images. Appl. Sci. 2025, 15, 2752. [Google Scholar] [CrossRef]
- Yılmaz, A.; Yurtay, Y.; Yurtay, N. AYOLO: Development of a Real-Time Object Detection Model for the Detection of Secretly Cultivated Plants. Appl. Sci. 2025, 15, 2718. [Google Scholar] [CrossRef]
- Félix-Jiménez, A.F.; Sánchez-Lee, V.S.; Acuña-Cid, H.A.; Ibarra-Belmonte, I.; Arredondo-Morales, E.; Ahumada-Tello, E. Integration of YOLOv8 Small and MobileNet V3 Large for Efficient Bird Detection and Classification on Mobile Devices. AI 2025, 6, 57. [Google Scholar] [CrossRef]
- Wang, J.; Ma, L.; Li, Z.; Cao, Y.; Zhang, H. SSHP-YOLO: A High Precision Printed Circuit Board (PCB) Defect Detection Algorithm with a Small Sample. Electronics 2025, 14, 217. [Google Scholar] [CrossRef]
- Du, B.; Wan, F.; Lei, G.; Xu, L.; Xu, C.; Xiong, Y. YOLO-MBBi: PCB Surface Defect Detection Method Based on Enhanced YOLOv5. Electronics 2023, 12, 2821. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Adibhatla, V.A.; Chih, H.; Hsu, C.; Cheng, J.; Abbod, M.F.; Shieh, J.S. Applying deep learning to defect detection in printed circuit boards via a newest model of you-only-look-once. Math. Biosci. Eng. 2021, 18, 4411–4428. [Google Scholar] [CrossRef] [PubMed]
- Yuan, T.; Jiao, Z.; Diao, N. YOLO-SSW: An Improved Detection Method for Printed Circuit Board Surface Defects. Mathematics 2025, 13, 435. [Google Scholar] [CrossRef]
- Shi, P.; Zhang, Y.; Cao, Y.; Sun, J.; Chen, D.; Kuang, L. DVCW-YOLO for Printed Circuit Board Surface Defect Detection. Appl. Sci. 2024, 15, 327. [Google Scholar] [CrossRef]
- Chen, L.; Su, L.; Chen, W.; Chen, Y.; Chen, H.; Li, T. YOLO-DHGC: Small Object Detection Using Two-Stream Structure with Dense Connections. Sensors 2024, 24, 6902. [Google Scholar] [CrossRef]
- Alif, M.A.R.; Hussain, M. YOLOv12: A Breakdown of the Key Architectural Features. arXiv 2025, arXiv:2502.14740. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Vasu, S.; Ma, Y.; Singh, S.; Tuzel, O.; Ranjan, A. MobileOne: An Improved One Millisecond Mobile Backbone. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1238–1247. Available online: https://openaccess.thecvf.com/content/CVPR2023/papers/Vasu_MobileOne_An_Improved_One_Millisecond_Mobile_Backbone_CVPR_2023_paper.pdf (accessed on 1 January 2024).
- Xu, H.; Zhang, M.; Tong, P. MFDNN: Multi-Scale Feature-Weighted Dual-Neck Network for Underwater Object Detection. J. Electron. Imaging 2024, 33, 023056. [Google Scholar] [CrossRef]
- Wang, C.; Yi, H. DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery. Appl. Sci. 2025, 15, 2789. [Google Scholar] [CrossRef]
- Li, H.; Wang, Z.; Qiu, L.; Wei, X. Method for Detecting Tiny Defects on Machined Surfaces of Mechanical Parts Based on Object Recognition. Appl. Sci. 2025, 15, 2484. [Google Scholar] [CrossRef]
- Pan, C.; Zhang, Y.; Zhang, H.; Xu, J. Lateral Displacement and Distance of Vehicles in Freeway Overtaking Scenario Based on Naturalistic Driving Data. Appl. Sci. 2025, 15, 2370. [Google Scholar] [CrossRef]
- Zhu, T.; Zhao, Z.; Xia, M.; Huang, J.; Weng, L.; Hu, K.; Lin, H.; Zhao, W. FTA-Net: Frequency-Temporal-Aware Network for Remote Sensing Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 3448–3460. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Wang, Z.; Gu, G.; Xia, M.; Weng, L.; Hu, K. Bitemporal attention sharing network for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10368–10379. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP/% | Precision/% | Recall/% | Parameters/MB | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| SSD | 79.0 | 79.9 | 74.3 | 8.9 | 28.3 | 47.1 |
| CNN | 79.8 | 81.2 | 73.2 | 19.6 | 48.0 | 9.3 |
| Mask R-CNN | 84.2 | 83.4 | 82.6 | 14.8 | 34.2 | 10.9 |
| RetinaNet | 80.7 | 79.2 | 81.9 | 9.0 | 16.8 | 45.1 |
| EfficientDet | 83.1 | 83.8 | 79.9 | 11.1 | 19.1 | 38.3 |
| YOLOv8 | 83.2 | 83.5 | 80.3 | 12.6 | 20.0 | 46.7 |
| YOLOv12 | 85.3 | 82.7 | 85.6 | 12.8 | 22.4 | 47.2 |
| Model | mAP/% | Precision/% | Recall/% | Parameters/MB | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| SSD | 77.1 | 66.7 | 78.8 | 7.8 | 26.9 | 47.6 |
| CNN | 78.4 | 75.4 | 79.2 | 18.2 | 45.3 | 9.5 |
| Mask R-CNN | 84.1 | 79.8 | 84.6 | 13.6 | 33.3 | 11.2 |
| RetinaNet | 80.5 | 77.1 | 80.9 | 9.1 | 15.6 | 48.6 |
| EfficientDet | 82.0 | 81.8 | 79.7 | 10.3 | 18.4 | 39.4 |
| YOLOv8 | 83.3 | 82.1 | 80.2 | 12.2 | 22.1 | 46.9 |
| YOLOv12 | 84.2 | 85.7 | 82.4 | 12.4 | 23.2 | 48.0 |
| Model | mAP/% | FPS |
|---|---|---|
| YOLOv12 | 85.3 | 47.2 |
| YOLOv12 + CBAM YOLOv12 + MECS | 87.2 92.0 | 46.8 47.1 |
| Model | mAP/% | FPS |
|---|---|---|
| YOLOv12 | 84.2 | 48.0 |
| YOLOv12 + CBAM YOLOv12 + MECS | 88.1 91.7 | 47.2 47.4 |
| Model | mAP/% | FPS |
|---|---|---|
| YOLOv12 YOLOv12 + FPN | 85.3 87.2 | 47.2 49.1 |
| YOLOv12 + AHFIN | 89.4 | 49.6 |
| Model | mAP/% | FPS |
|---|---|---|
| YOLOv12 YOLOv12 + FPN | 84.2 88.1 | 48.0 48.4 |
| YOLOv12 + AHFIN | 89.0 | 49.2 |
| Loss Function | 250 epochs | 275 epochs | 300 epochs | 325 epochs | 350 epochs | 375 epochs | 400 epochs |
|---|---|---|---|---|---|---|---|
| CIoU | 0.0284 | 0.0279 | 0.0278 | 0.0277 | 0.0278 | 0.0278 | 0.0278 |
| DIoU | 0.0278 | 0.0275 | 0.0274 | 0.0274 | 0.0274 | 0.0274 | 0.0274 |
| GIoU | 0.0278 | 0.0269 | 0.0266 | 0.0266 | 0.0265 | 0.0266 | 0.0266 |
| SAL | 0.0221 | 0.0219 | 0.0218 | 0.0218 | 0.0218 | 0.0218 | 0.0218 |
| Loss Function | mAP/% | Precision/% | Recall/% |
|---|---|---|---|
| CIoU DIoU | 85.4 79.3 | 85.6 80.8 | 78.5 75.4 |
| GIoU SAL | 85.9 88.4 | 86.2 89.8 | 78.6 82.1 |
| Model | mAP/% | Precision/% | Recall/% | FPS |
|---|---|---|---|---|
| YOLOv12 | 85.4 | 85.6 | 78.5 | 47.0 |
| +MECS | 92.1 | 92.3 | 85.1 | 47.1 |
| +AHFIN | 89.6 | 90.2 | 86.3 | 47.8 |
| +MECS + AHFIN | 92.9 | 93.0 | 87.2 | 49.4 |
| +MECS + AHFIN + SAL (MAS-YOLO) | 93.2 | 93.6 | 88.2 | 49.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, X.; Zhao, Z.; Weng, L. MAS-YOLO: A Lightweight Detection Algorithm for PCB Defect Detection Based on Improved YOLOv12. Appl. Sci. 2025, 15, 6238. https://doi.org/10.3390/app15116238
Yin X, Zhao Z, Weng L. MAS-YOLO: A Lightweight Detection Algorithm for PCB Defect Detection Based on Improved YOLOv12. Applied Sciences. 2025; 15(11):6238. https://doi.org/10.3390/app15116238
Chicago/Turabian StyleYin, Xupeng, Zikai Zhao, and Liguo Weng. 2025. "MAS-YOLO: A Lightweight Detection Algorithm for PCB Defect Detection Based on Improved YOLOv12" Applied Sciences 15, no. 11: 6238. https://doi.org/10.3390/app15116238
APA StyleYin, X., Zhao, Z., & Weng, L. (2025). MAS-YOLO: A Lightweight Detection Algorithm for PCB Defect Detection Based on Improved YOLOv12. Applied Sciences, 15(11), 6238. https://doi.org/10.3390/app15116238