

Data-Aware Path Planning for Autonomous Vehicles Using Reinforcement Learning †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- A novel reinforcement learning framework that jointly optimizes for travel time and data transfer efficiency in heterogeneous urban environments.
- Implementation of a realistic simulation environment using GraphML [7], incorporating real map data and vehicle mobility patterns for robust evaluations of path planning strategies.
- Experimental validation demonstrating the superiority of our approach over traditional baselines in heterogeneous traffic and bandwidth scenarios.
2. Related Work
2.1. Path Planning
2.2. Reinforcement Learning
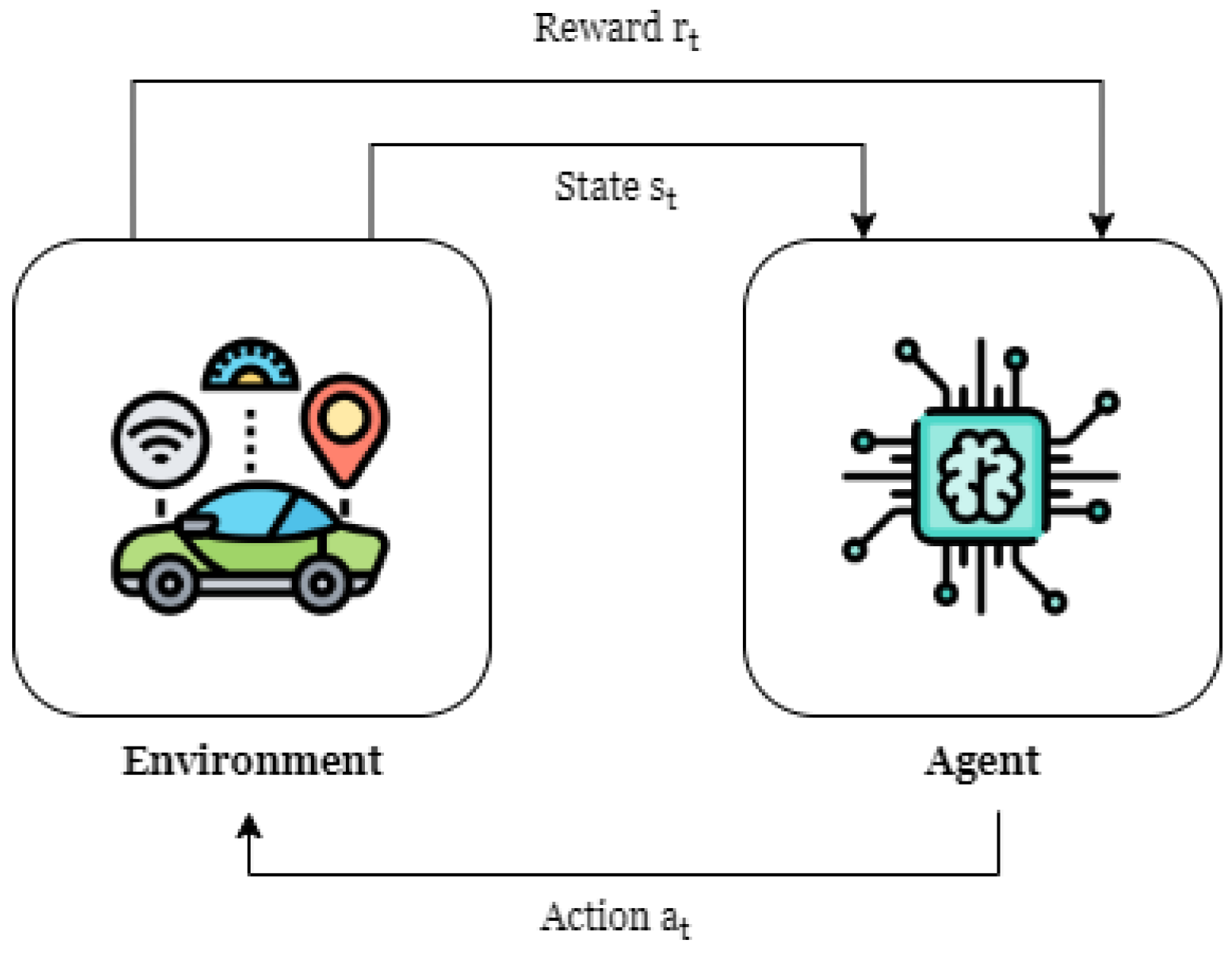
3. Problem Formulation
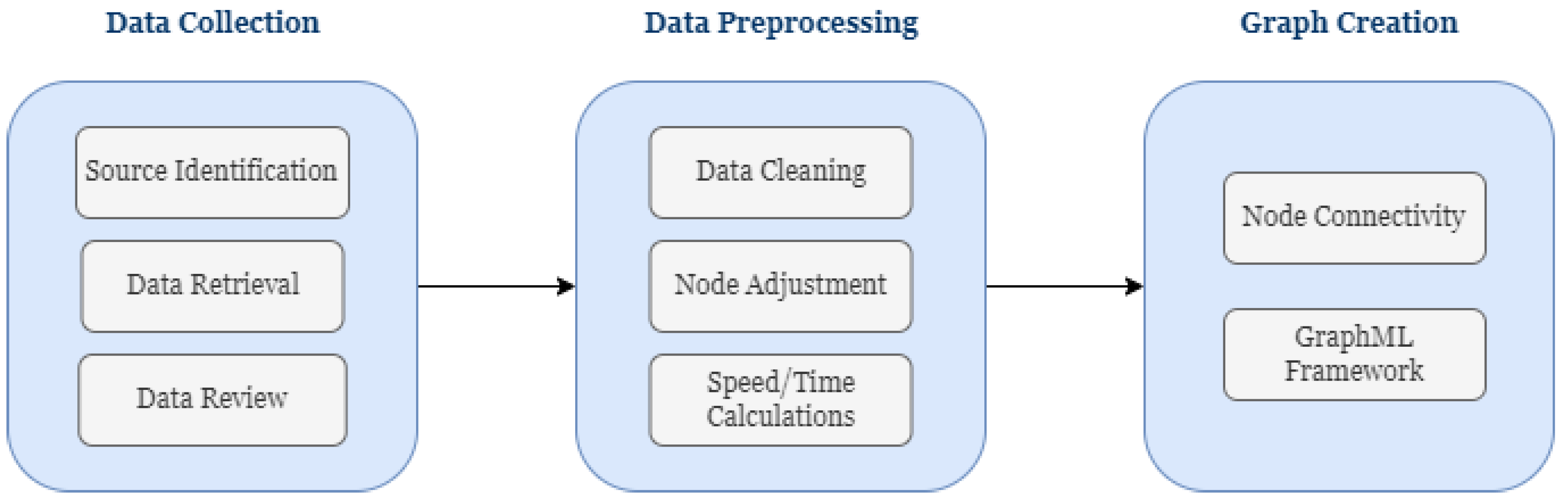
3.1. Constructing the Environment
3.2. Reinforcement Learning Formulation
3.2.1. Goal
3.2.2. State Space (S)
- x represents the current node position of the agent within the network.
- d is the remaining amount of data that needs to be transferred. This component reflects the agent’s communication objectives, crucial to ensuring that data transfer requirements are met before the journey ends.
- B denotes the set of bandwidths available on the links connected to the current node x. Each element in B represents the bandwidth on a specific link, which affects the rate at which data can be transferred as the agent considers its next move.
- T indicates the set of traffic densities on the links connected to the current node x. Each element in T reflects the traffic density on a specific link, which affects the agent’s travel time and decision-making for route optimization.
3.2.3. Action Space (A)
- x represents the current node position of the agent.
- denotes a potential next node to which the agent can move.
- L is the set of all the connections in the network, where each link is a tuple that indicates a direct connection from node x to node .
3.2.4. Reward Function (R)
- is a large positive reward given when the agent reaches the destination with no remaining data to transfer ().
- represents the fractional reward for traveling from node x to node , designed to encourage faster routes. The amount of this reward inversely correlates with the travel time or distance traveled.
- is the reward for data transferred during the transition from d to , structured to incentivize maximum data transfer throughout the journey.
- encompasses penalties for inefficiencies, such as remaining stationary ( and ), revisiting previously visited nodes, or selecting slower routes.
3.2.5. Transition Probability (P)
- denotes the current state at time t.
- represents the action taken at time t from state .
- is the state at time , resulting from taking action in state .
3.2.6. Policy ()
- denotes the current state of the agent within the environment.
- represents the action chosen by the policy.
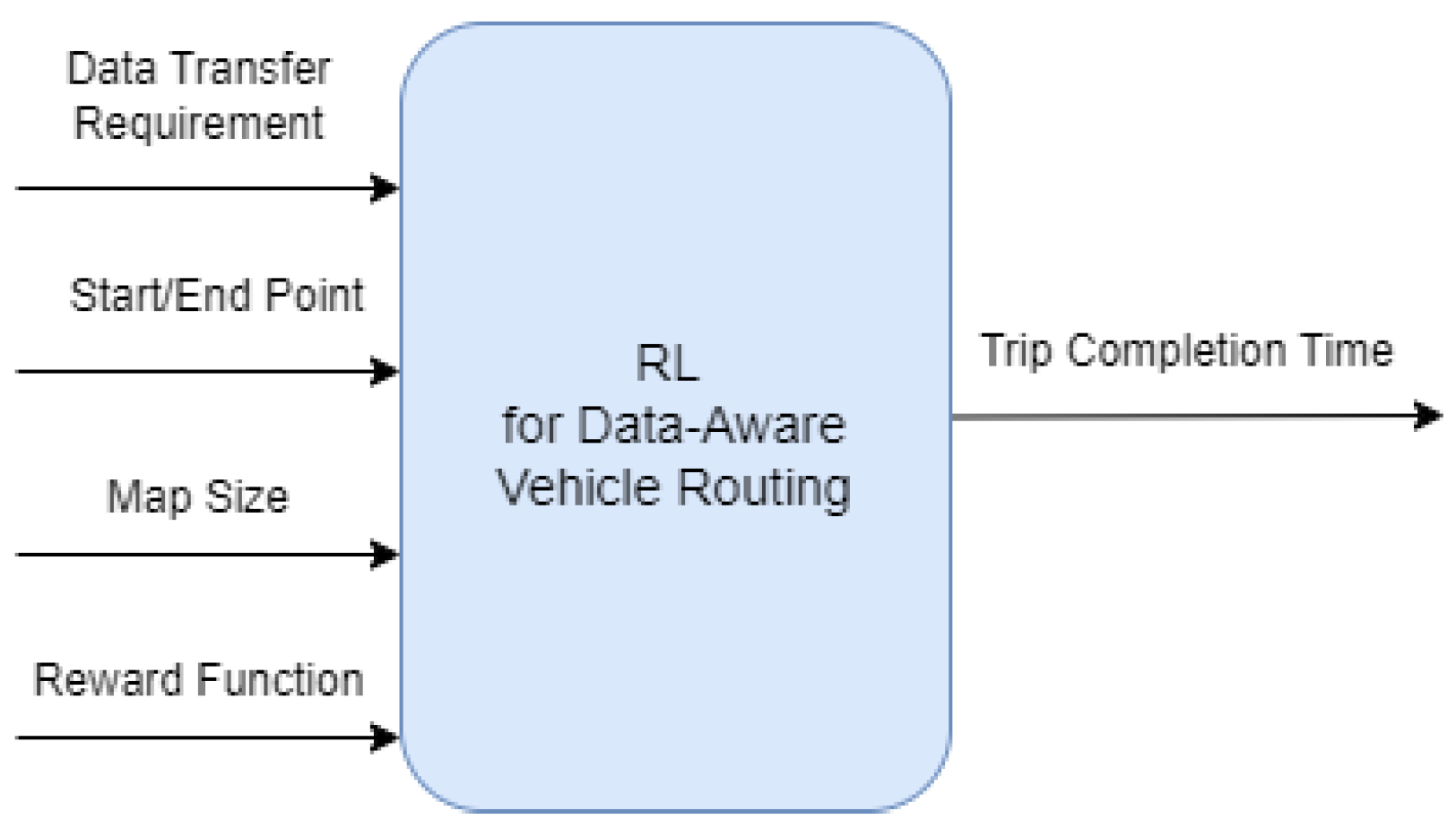
3.3. Experiment Setup
3.4. Simulation Setup
4. Experiments and Results
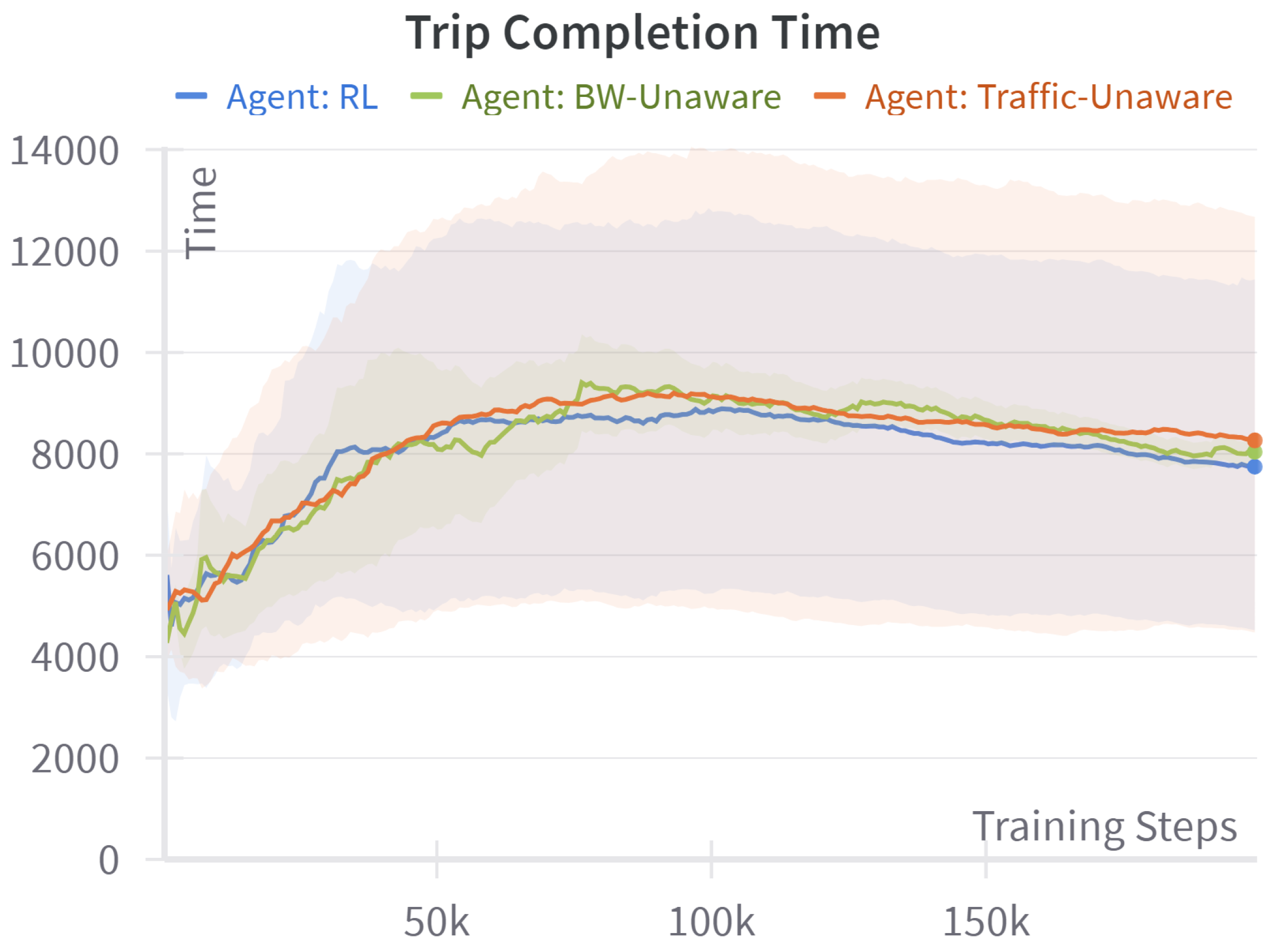
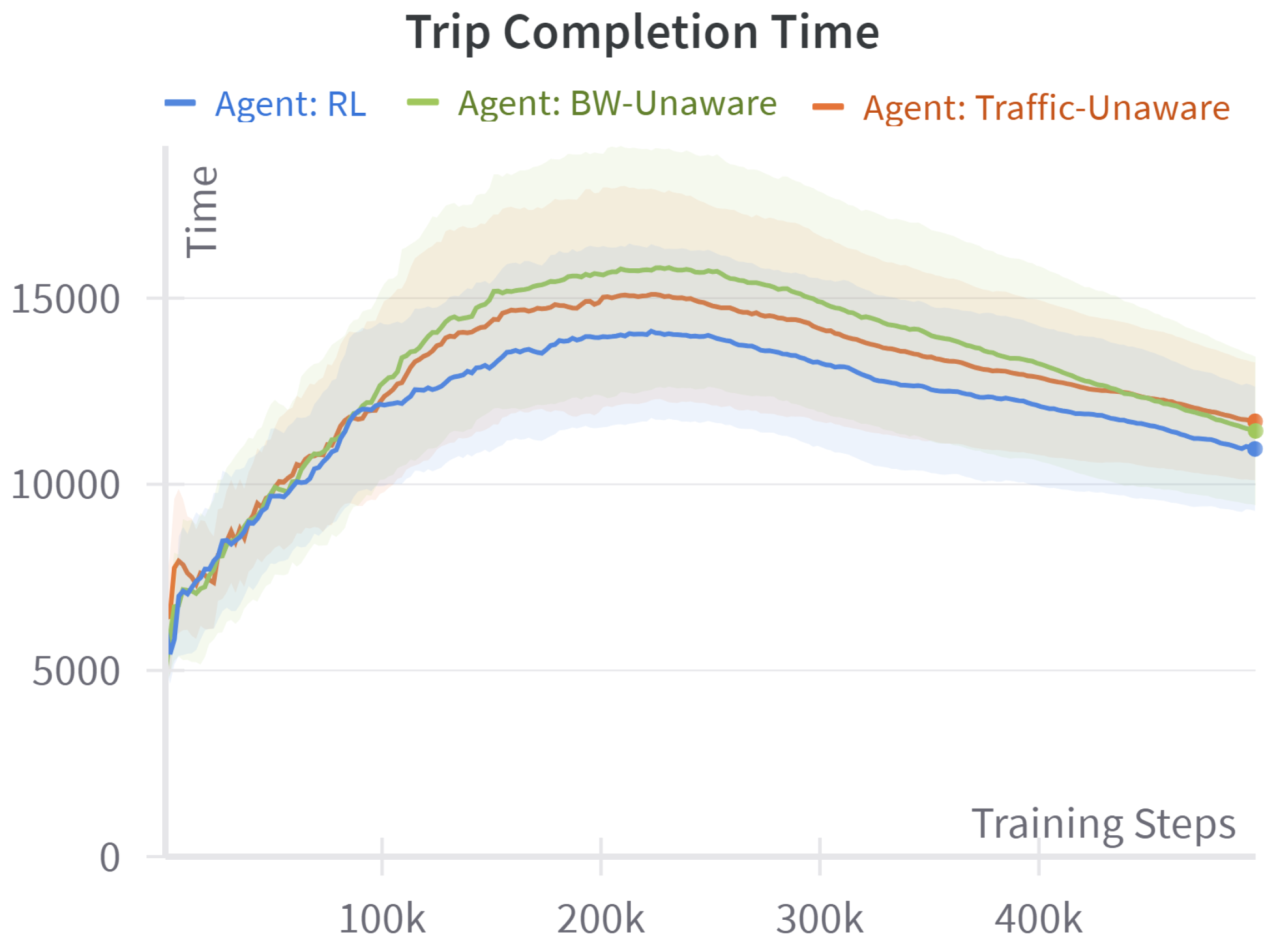
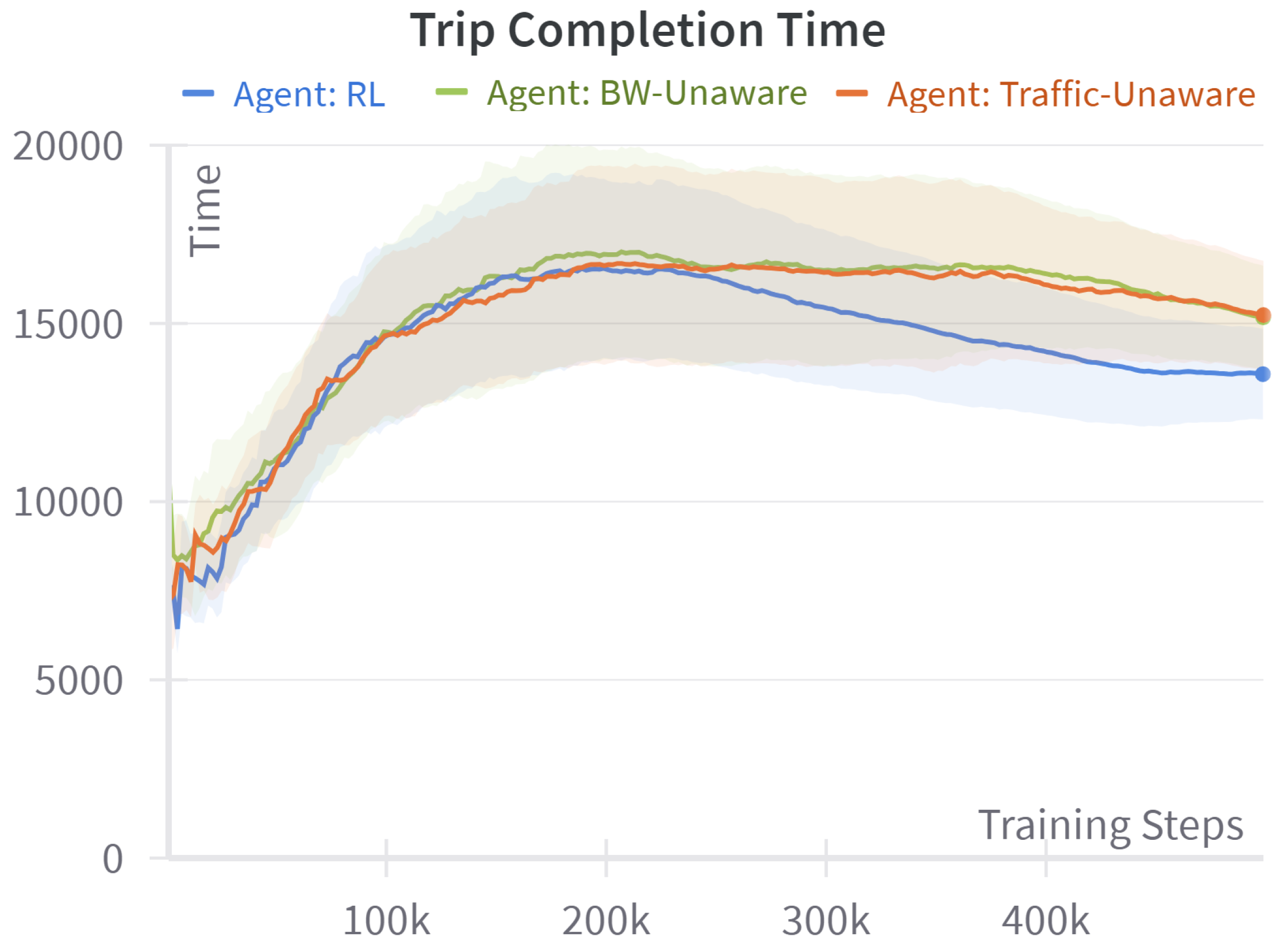
4.1. Baseline Comparison
- Traffic-unaware (shortest path): When the traffic-delay term is removed from the reward, every edge has a unit cost; the resulting policy is exactly the static shortest hop route returned by Dijkstra’s algorithm, a standard distance-optimal algorithm.
- Bandwidth-unaware (fastest path): When the data-throughput term is omitted, the reward reduces to negative travel time. The baseline therefore behaves like a time-dependent fastest path algorithm that minimizes congestion-aware travel time while ignoring any data-transfer objective.
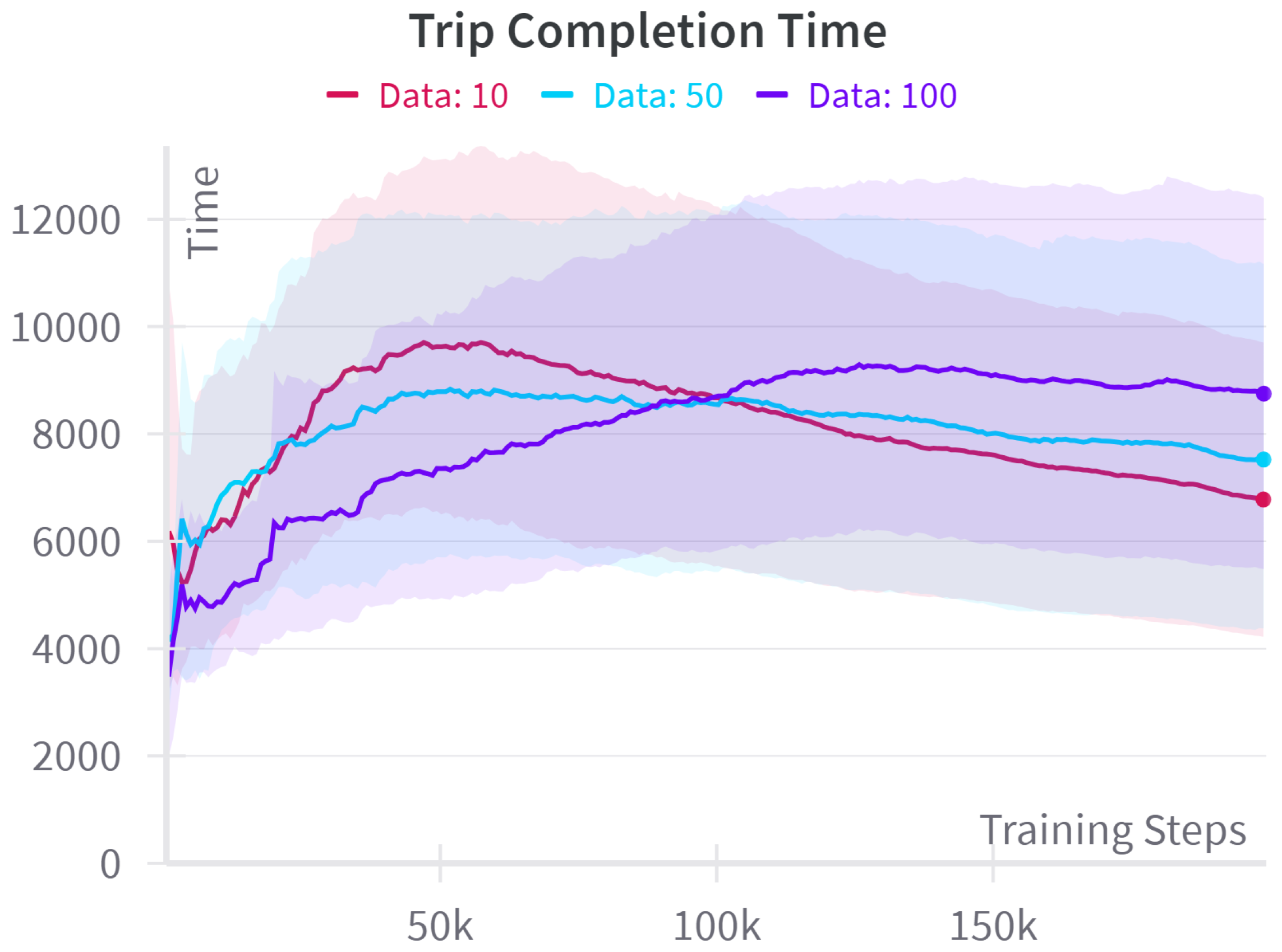
4.2. Data Requirement Comparison
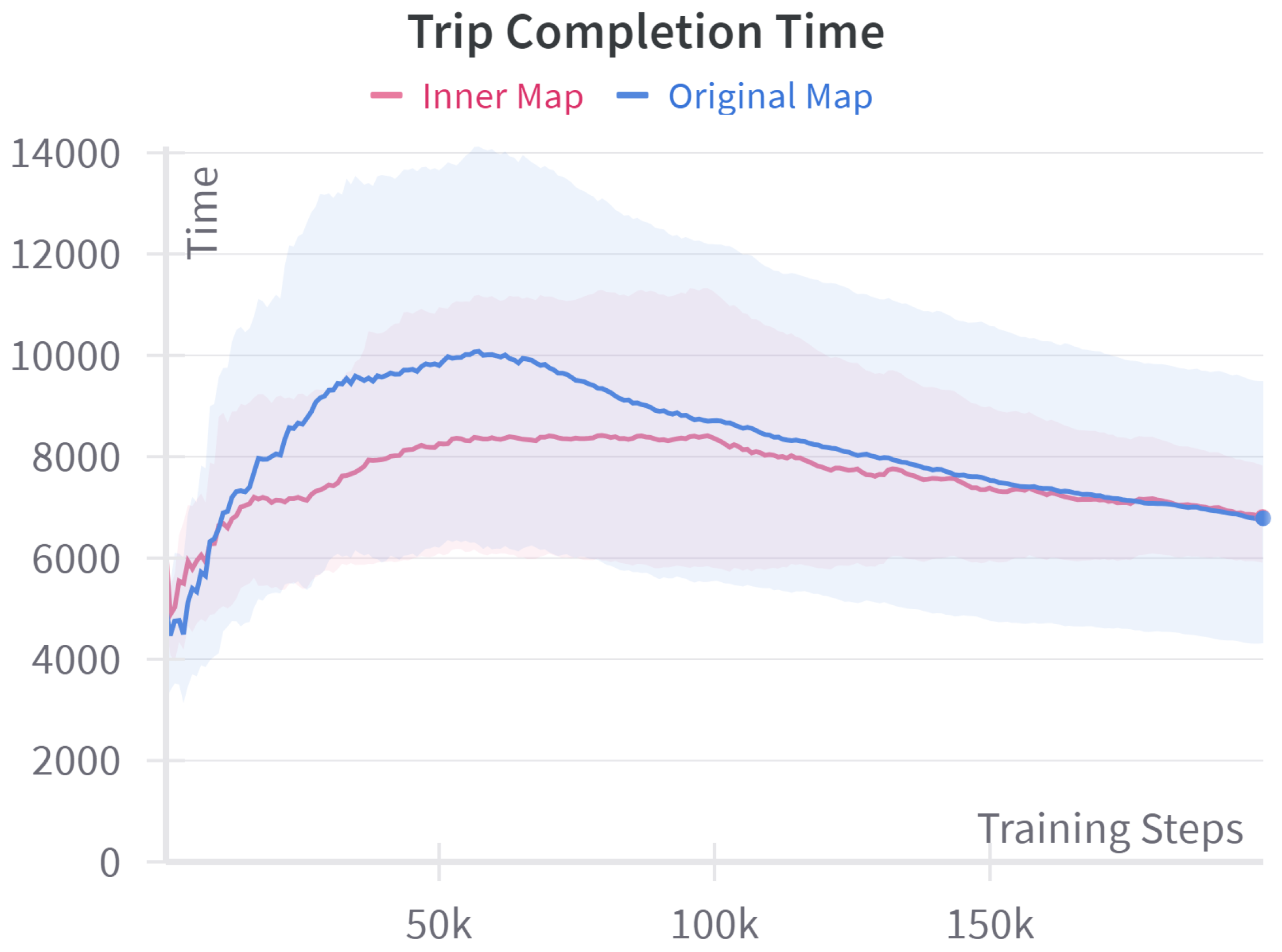
4.3. Map Size Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Intel Corporation. Data Is the New Oil in the Future of Automated Driving. 2016. Available online: https://www.intel.com/content/www/us/en/newsroom/news/self-driving-cars-data.html (accessed on 10 March 2024).
- You, C.; Lu, J.; Filev, D.; Tsiotras, P. Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning. Robot. Auton. Syst. 2019, 114, 1–18. [Google Scholar] [CrossRef]
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey; Technical Report; National Highway Traffic Safety Administration: Washington, DC, USA, 2015. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812506 (accessed on 10 March 2024).
- Ibáñez, J.A.G.; Zeadally, S.; Contreras-Castillo, J. Integration challenges of intelligent transportation systems with connected vehicle, cloud computing, and internet of things technologies. IEEE Wirel. Commun. 2015, 22, 122–128. [Google Scholar] [CrossRef]
- Taha, A.E.M.; Abuali, N.A. Route planning considerations for autonomous vehicles. IEEE Commun. Mag. 2018, 56, 78–84. [Google Scholar] [CrossRef]
- Ye, H.; Liang, L.; Li, G.Y.; Kim, J.; Lu, L.; Wu, M. Machine learning for vehicular networks: Recent advances and application examples. IEEE Veh. Technol. Mag. 2017, 13, 94–101. [Google Scholar] [CrossRef]
- Brandes, U.; Eiglsperger, M.; Lerner, J.; Pich, C. Graph markup language (GraphML). In Handbook of Graph Drawing and Visualization; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar] [CrossRef]
- Ming, Y.; Li, Y.; Zhang, Z.; Yan, W. A survey of path planning algorithms for autonomous vehicles. SAE Int. J. Commer. Veh. 2021, 14, 97–109. [Google Scholar] [CrossRef]
- Marin-Plaza, P.; Hussein, A.; Martin, D.; de la Escalera, A. Global and local path planning study in a ROS-based research platform for autonomous vehicles. J. Adv. Transp. 2018, 2018, 6392697. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connection with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Dechter, R.; Pearl, J. Generalized best-first search strategies and the optimality of A*. J. ACM 1985, 32, 505–536. [Google Scholar] [CrossRef]
- Paden, B.; Čáp, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Bast, H.; Delling, D.; Goldberg, A.V.; Müller-Hannemann, M.; Pajor, T.; Sanders, P.; Wagner, D.; Werneck, R.F. Route planning in transportation networks. In Algorithm Engineering; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Stentz, A. Optimal and efficient path planning for partially-known environments. In Proceedings of the 1994 IEEE International Conference on Robotics and Automation, San Diego, CA, USA, 8–13 May 1994; pp. 3310–3317. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Kim, D.H.; Kim, C.K.; Yim, H.; Jeong, S.K.; Kim, S.B. A simple path planning for automatic guided vehicle in unknown environment. In Proceedings of the 2017 14th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Jeju, Republic of Korea, 28 June–1 July 2017; pp. 337–341. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Autonomous Robot Vehicles; Springer: Berlin/Heidelberg, Germany, 1990; pp. 396–404. [Google Scholar] [CrossRef]
- Ganeshmurthy, M.S.; Suresh, G.R. Path planning algorithm for autonomous mobile robot in dynamic environment. In Proceedings of the 2015 3rd International Conference on Signal Processing, Communication and Networking, Chennai, India, 26–28 March 2015. [Google Scholar] [CrossRef]
- Wang, L.; Luo, C. A hybrid genetic tabu search algorithm for mobile robot to solve AS/RS path planning. Int. J. Robot. Autom. 2018, 33. [Google Scholar] [CrossRef]
- LaValle, S. Rapidly-exploring random trees: A new tool for path planning. Annu. Res. Rep. 1998. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2020, 23, 4909–4926. [Google Scholar] [CrossRef]
- Nešmark, J.I.; Fufaev, N.A. Dynamics of Nonholonomic Systems; American Mathematical Society: Providence, RI, USA, 2004. [Google Scholar] [CrossRef]
- LaValle, S.M.; Kuffner, J.J. Randomized kinodynamic planning. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), Detroit, MI, USA, 10–15 May 1999; Volume 1, pp. 473–479. [Google Scholar] [CrossRef]
- Loaiza Quintana, C.; Climent, L.; Arbelaez, A. Iterated Local Search for the eBuses Charging Location Problem. In Proceedings of the Parallel Problem Solving from Nature—PPSN XVII: 17th International Conference, Dortmund, Germany, 10–14 September 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Nasrabadi, N.M. Pattern recognition and machine learning. J. Electron. Imaging 2007, 16, 049901. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Deep learning and its applications to signal and information processing. IEEE Signal Process. Mag. 2011, 28, 145–154. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. arXiv 2013, arXiv:1303.5778. [Google Scholar] [CrossRef]
- Kumar, A.; Irsoy, O.; Ondruska, P.; Iyyer, M.; Bradbury, J.; Gulrajani, I.; Zhong, V.; Paulus, R.; Socher, R. Ask me anything: Dynamic memory networks for natural language processing. arXiv 2015, arXiv:1506.07285. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar] [CrossRef]
- Kononenko, I. Machine learning for medical diagnosis: History, state of the art and perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef]
- Shvets, A.A.; Rakhlin, A.; Kalinin, A.A.; Iglovikov, V.I. Automatic instrument segmentation in robot-assisted surgery using deep learning. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018; pp. 624–628. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement learning: An introduction. IEEE Trans. Neural Netw. 1988, 9, 1054. [Google Scholar] [CrossRef]
- Bae, H.; Kim, G.D.; Kim, J.; Qian, D.; Lee, S.G. Multi-robot path planning method using reinforcement learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef]
- Ge, S.S.; Cui, Y.J. New potential functions for mobile robot path planning. IEEE Trans. Robot. Autom. 2000, 16, 615–620. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.; Zhang, J. Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 2013, 103, 172–185. [Google Scholar] [CrossRef]
- Tharwat, A.; Elhoseny, M.; Hassanien, A.E.; Gabel, T.; Kumar, A. Intelligent Bézier curve-based path planning model using chaotic particle swarm optimization algorithm. Clust. Comput. 2019, 22, 4745–4766. [Google Scholar] [CrossRef]
- Elhoseny, M.; Tharwat, A.; Hassanien, A.E. Bezier curve based path planning in a dynamic field using modified genetic algorithm. J. Comput. Sci. 2018, 25, 339–350. [Google Scholar] [CrossRef]
- Alomari, A.; Comeau, F.; Phillips, W.; Aslam, N. New path planning model for mobile anchor-assisted localization in wireless sensor networks. Wirel. Netw. 2018, 24, 2589–2607. [Google Scholar] [CrossRef]
- Peters, J.; Schaal, S. Natural actor-critic. Neurocomputing 2008, 71, 1180–1190. [Google Scholar] [CrossRef]
- Bhasin, S.; Kamalapurkar, R.; Johnson, M.; Vamvoudakis, K.G.; Lewis, F.L.; Dixon, W.E. A novel actor–critic–identifier architecture for approximate optimal control of uncertain nonlinear systems. Automatica 2013, 49, 82–92. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L. Online actor–critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica 2010, 46, 878–888. [Google Scholar] [CrossRef]
- Florensa, C.; Degrave, J.; Heess, N.; Springenberg, J.T.; Riedmiller, M. Self-supervised learning of image embedding for continuous control. arXiv 2019, arXiv:1901.00943. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar] [CrossRef]
- Kofinas, P.; Dounis, A.I.; Vouros, G.A. Fuzzy Q-learning for multi-agent decentralized energy management in microgrids. Appl. Energy 2018, 219, 53–67. [Google Scholar] [CrossRef]
- Dowling, J.; Curran, E.; Cunningham, R.; Cahill, V. Using feedback in collaborative reinforcement learning to adaptively optimize MANET routing. IEEE Trans. Syst. Man Cybern.—Part A Syst. Hum. 2005, 35, 360–372. [Google Scholar] [CrossRef]
- Doddalinganavar, S.S.; Tergundi, P.V.; Patil, R.S. Survey on deep reinforcement learning protocol in VANET. In Proceedings of the 1st International Conference on Advances in Information Technology, Chikmagalur, India, 25–27 July 2019; pp. 81–86. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Q.; He, C.; Jaffrès-Runser, K.; Xu, Y.; Li, Z.; Xu, Y. QMR: Q-learning based multi-objective optimization routing protocol for flying ad hoc networks. Comput. Commun. 2020, 150, 304–316. [Google Scholar] [CrossRef]
- Coutinho, W.P.; Battarra, M.; Fliege, J. The unmanned aerial vehicle routing and trajectory optimisation problem, a taxonomic review. Comput. Ind. Eng. 2018, 120, 116–128. [Google Scholar] [CrossRef]
- Nazib, R.A.; Moh, S. Reinforcement learning-based routing protocols for vehicular ad hoc networks: A comparative survey. IEEE Access 2021, 9, 27552–27587. [Google Scholar] [CrossRef]
- Li, F.; Song, X.; Chen, H.; Li, X.; Wang, W. Hierarchical routing for vehicular ad hoc networks via reinforcement learning. IEEE Trans. Veh. Technol. 2019, 68, 1852–1865. [Google Scholar] [CrossRef]
- Misra, S.; Woungang, I.; Misra, S.C. Guide to Wireless Ad Hoc Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Hartenstein, H.; Laberteaux, K. VANET: Vehicular Applications and Inter-Networking Technologies; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar] [CrossRef]
- Vigo, D.; Toth, P. (Eds.) Vehicle Routing; MOS-SIAM Series on Optimization; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2014. [Google Scholar] [CrossRef]
- Rasheed, A.; Gillani, S.; Ajmal, S.; Qayyum, A. Vehicular ad hoc network (VANET): A survey, challenges, and applications. In Proceedings of the Vehicular Ad-Hoc Networks for Smart Cities; Advances in Intelligent Systems and Computing. Springer: Berlin/Heidelberg, Germany, 2017; pp. 39–51. [Google Scholar] [CrossRef]
- Li, F.; Wang, Y. Routing in vehicular ad hoc networks: A survey. IEEE Veh. Technol. Mag. 2007, 2, 12–22. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Chettibi, S.; Chikhi, S. A survey of reinforcement learning based routing protocols for mobile ad-hoc networks. In Proceedings of the Recent Trends in Wireless and Mobile Networks, Ankara, Turkey, 26–28 June 2011; Communications in Computer and Information Science. Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–13. [Google Scholar] [CrossRef]
- McCall, J.C.; Trivedi, M.M. Video-based lane estimation and tracking for driver assistance: Survey, system, and evaluation. IEEE Trans. Intell. Transp. Syst. 2006, 7, 20–37. [Google Scholar] [CrossRef]
- Keen, S.D.; Cole, D.J. Application of time-variant predictive control to modelling driver steering skill. Veh. Syst. Dyn. 2011, 49, 527–559. [Google Scholar] [CrossRef]
- You, C.; Tsiotras, P. Optimal two-point visual driver model and controller development for driver-assist systems for semi-autonomous vehicles. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 5976–5981. [Google Scholar] [CrossRef]
- Zafeiropoulos, S.; Tsiotras, P. Design of a lane-tracking driver steering assist system and its interaction with a two-point visual driver model. In Proceedings of the 2014 American Control Conference, Portland, OR, USA, 4–6 June 2014; pp. 3911–3917. [Google Scholar] [CrossRef]
- Lange, S.; Riedmiller, M.; Voigtländer, A. Autonomous reinforcement learning on raw visual input data in a real world application. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Wang, Y. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef]
- Sallab, A.; Abdou, M.; Perot, E.; Yogamani, S. End-to-End Deep Reinforcement Learning for Lane Keeping Assist. arXiv 2016, arXiv:1612.04340. [Google Scholar] [CrossRef]
- Min, K.; Kim, H.; Huh, K. Deep distributional reinforcement learning based high-level driving policy determination. IEEE Trans. Intell. Veh. 2019, 4, 416–424. [Google Scholar] [CrossRef]
- Bouton, M.; Nakhaei, A.; Fujimura, K.; Kochenderfer, M.J. Cooperation-aware reinforcement learning for merging in dense traffic. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Auckland, New Zealand, 27–30 October 2019; pp. 3441–3447. [Google Scholar] [CrossRef]
- Chen, D.; Hajidavalloo, M.R.; Li, Z.; Chen, K.; Wang, Y.; Jiang, L.; Wang, Y. Deep multi-agent reinforcement learning for highway on-ramp merging in mixed traffic. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11623–11638. [Google Scholar] [CrossRef]
- Fu, Y.; Li, C.; Yu, F.R.; Luan, T.H.; Zhang, Y. A decision-making strategy for vehicle autonomous braking in emergency via deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 5876–5888. [Google Scholar] [CrossRef]
- Xie, J.; Xu, X.; Wang, F.; Liu, Z.; Chen, L. Coordination control strategy for human-machine cooperative steering of intelligent vehicles: A reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21163–21177. [Google Scholar] [CrossRef]
- Haydari, A.; Yılmaz, Y. Deep reinforcement learning for intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2020, 23, 11–32. [Google Scholar] [CrossRef]
- Fei, Y.; Xing, L.; Yao, L.; Yang, Z.; Zhang, Y. Deep reinforcement learning for decision making of autonomous vehicles in non-lane-based traffic environments. PLoS ONE 2025, 20, e0320578. [Google Scholar] [CrossRef] [PubMed]
- Hussain, Q.; Noor, A.; Qureshi, M.; Li, J.; Rahman, A.; Bakry, A.; Mahmood, T.; Rehman, A. Reinforcement learning based route optimization model to enhance energy efficiency in internet of vehicles. Sci. Rep. 2025, 15, 3113. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; He, J.; Wan, J.; Guan, Y.; Liu, D.; Su, X.; Li, L. Deep reinforcement learning based low energy consumption scheduling approach design for urban electric logistics vehicle networks. Sci. Rep. 2025, 15, 9003. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Qian, B.; Zhuo, J.; Liu, W. An Autonomous Vehicle Behavior Decision Method Based on Deep Reinforcement Learning with Hybrid State Space and Driving Risk. Sensors 2025, 25, 774. [Google Scholar] [CrossRef]
- Audinys, R.; Slikas, Z.; Radkevicius, J.; Sutas, M.; Ostreika, A. Deep Reinforcement Learning for a Self-Driving Vehicle Operating Solely on Visual Information. Electronics 2025, 14, 825. [Google Scholar] [CrossRef]
- Lu, Y.; Ma, H.; Smart, E.; Yu, H. Enhancing Autonomous Driving Decision: A Hybrid Deep Reinforcement Learning-Kinematic-Based Autopilot Framework for Complex Motorway Scenes. IEEE Trans. Intell. Transp. Syst. 2025, 26, 3198–3209. [Google Scholar] [CrossRef]
- AlSaqabi, Y.; Chattopadhyay, S. Driving with Guidance: Exploring the Trade-Off Between GPS Utility and Privacy Concerns Among Drivers. arXiv 2023, arXiv:2309.12601. [Google Scholar] [CrossRef]
- AlSaqabi, Y.; Krishnamachari, B. Trip planning for autonomous vehicles with wireless data transfer needs using reinforcement learning. In Proceedings of the IEEE International Conference on Mobile Ad-hoc and Sensor Systems, Denver, CO, USA, 19–23 October 2022. [Google Scholar] [CrossRef]
- Ng, A.; Harada, D.; Russell, S.J. Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping. In Proceedings of the International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlSaqabi, Y.; Krishnamachari, B. Data-Aware Path Planning for Autonomous Vehicles Using Reinforcement Learning. Appl. Sci. 2025, 15, 6099. https://doi.org/10.3390/app15116099
AlSaqabi Y, Krishnamachari B. Data-Aware Path Planning for Autonomous Vehicles Using Reinforcement Learning. Applied Sciences. 2025; 15(11):6099. https://doi.org/10.3390/app15116099
Chicago/Turabian StyleAlSaqabi, Yousef, and Bhaskar Krishnamachari. 2025. "Data-Aware Path Planning for Autonomous Vehicles Using Reinforcement Learning" Applied Sciences 15, no. 11: 6099. https://doi.org/10.3390/app15116099
APA StyleAlSaqabi, Y., & Krishnamachari, B. (2025). Data-Aware Path Planning for Autonomous Vehicles Using Reinforcement Learning. Applied Sciences, 15(11), 6099. https://doi.org/10.3390/app15116099