

Comparative Evaluation of Sequential Neural Network (GRU, LSTM, Transformer) Within Siamese Networks for Enhanced Job–Candidate Matching in Applied Recruitment Systems

 , , ,
, , ,  ,
,  , , , , , and
, , , , , and 
Abstract
1. Introduction
- We introduce a modular Siamese framework that combines multilingual pretrained sentence embeddings with GRU, LSTM, and Transformer-based sequential heads for enhanced job–candidate matching.
- We conduct a systematic empirical comparison of these architectures using a real-world dataset derived from a commercial IT recruitment pipeline.
- We evaluate the models using both quantitative (ranking metrics) and qualitative (embedding space visualization) methods, demonstrating that the Transformer head yields the best overall performance.
- We analyze the practical implications of architectural choices in terms of matching precision, training dynamics, and computational tradeoffs.
1.1. Background and Motivation
1.2. Related Work
1.3. Problem Statement and Objectives
- To fill the gap left by past studies that fixed a single backbone.
- To train these models using a triplet loss function on a real-world dataset of job descriptions and candidate résumés from the IT sector.
- To evaluate and compare the performance of the GRU, LSTM, and Transformer head models using ranking metrics (Top-K Accuracy and MRR) and qualitative analysis (t-SNE visualization).
- To analyze the results highlighting the relative strengths and weaknesses of each sequential model for this specific task.
1.4. Contributions
- The first head-to-head evaluation of GRU, LSTM, and Transformer sequential heads inside an end-to-end Siamese network trained with triplet loss on 14.8 k real hiring events in English and Polish.
- A modular framework that combines multilingual pretrained sentence embeddings with sequential heads for job–candidate matching.
- An evaluation performed on a dataset reflecting real-world IT recruitment scenarios.
- Quantitative results obtained using ranking metrics (Top-K Accuracy and MRR) and analysis of training dynamics (loss and accuracy curves).
- A qualitative analysis of the learned embedding spaces using t-SNE visualizations for each model.
1.5. Paper Structure
2. Materials and Methods
2.1. Dataset Description
2.1.1. Data Source and Collection
- (a)
- A specific job posting (identified by job_id), along with its associated metadata such as job title and a detailed job description.
- (b)
- A candidate application (identified by candidate_id), which includes textual résumé data and recruitment progression details.
2.1.2. Data Statistics
2.1.3. Data Annotation (If Applicable)
- soft_positive: The candidate advanced through some recruitment stages but was not ultimately hired.
- positive: The candidate received and accepted a job offer.
- soft_negative: The candidate was rejected early in the process or chose to withdraw without advancing significantly.
2.2. Data Preprocessing
2.2.1. Text Cleaning
2.2.2. Anonymization
- Retrieving the candidate’s full name (e.g., from the candidate_name column).
- Splitting the full name into components. It is typically assumed that the first part is the first name and the last part is the surname.
- Using regular expressions to find and remove occurrences of the identified first name and surname within the corresponding candidate’s résumé text (stored in candidate_resume_no_html) [16]. This removal is case-insensitive.
- If the name cannot be reliably split into at least two parts, or if the anonymization function encounters an error, the original résumé text is retained.
2.2.3. Data Splitting
- The proportion allocated to the validation set is controlled by the VALID_SIZE parameter (0.1 for 10%).
- Stratification is optionally applied using specified columns to maintain the distribution of label column in both the training and validation sets.
- An additional filtering step can be applied before splitting. If set, job titles with fewer records than this threshold are temporarily removed. The split is performed on the filtered data, and the removed records are then added back to the training set to avoid data loss while ensuring robust stratification.
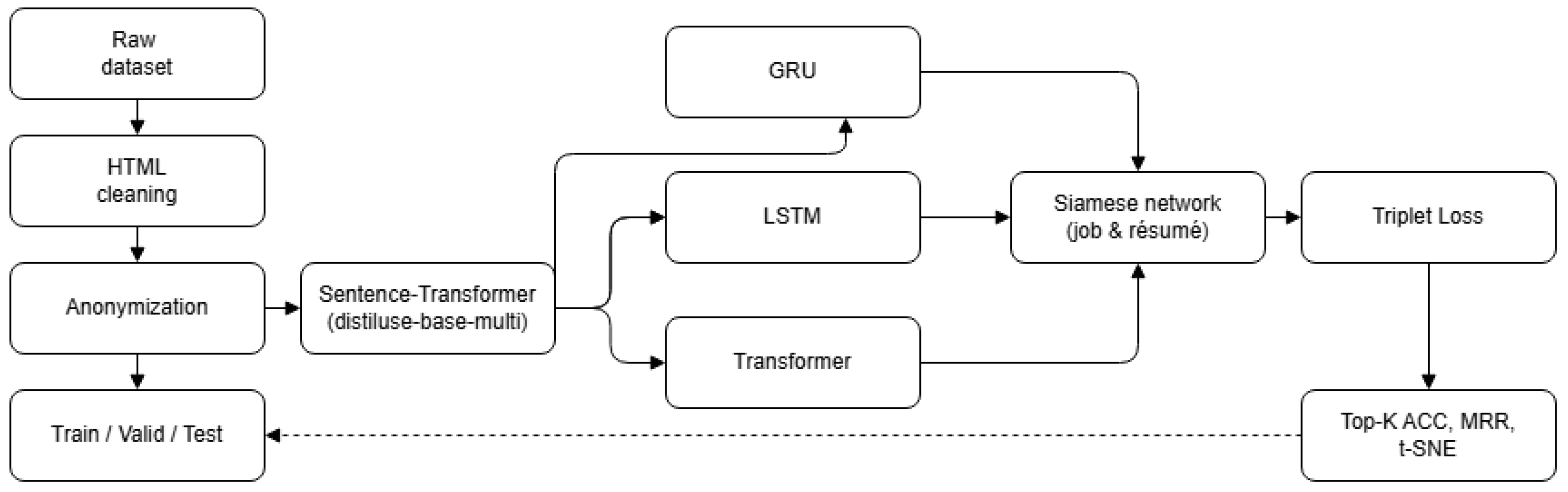
2.3. Proposed Model Architecture
2.3.1. Overall Siamese Framework
- Input Processing: Job descriptions and candidate resumes are independently fed into their respective towers.
- Base Embedding: A pretrained Sentence Transformer model generates initial contextual embeddings for segments of the input text.
- Sequential Head: A sequential model (GRU, LSTM, or Transformer) processes the sequence of segment embeddings generated by the base model to capture higher-level sequential or contextual information within the document.
- Final Embedding: Each tower outputs a final fixed-size vector representation (embedding) for the corresponding job description or résumé.
- Similarity Learning: The network is trained using a triplet loss function, which compares the embeddings of an anchor (job description), a positive sample (matching candidate résumé), and a negative sample (non-matching candidate résumé).
2.3.2. Base Sentence Embedding
- Segmenting the input text (job description or résumé) into chunks of a specified length (e.g., 1024 characters).
- Encoding each segment using the Sentence Transformer to obtain a sequence of initial embeddings, each with a dimension of 512.
- Optionally concatenating the embeddings generated from different chunk lengths if multiple lengths are specified.
- Padding or truncating the sequence of segment embeddings to a fixed maximum length (MAX_SEGMENTS_LENGTH, e.g., 15) to create a consistent input shape for the subsequent sequential head model. Padding uses a dedicated embedding for the [PAD] token.
2.3.3. Sequential Head Models
GRU Head
LSTM Head
Transformer Head
2.3.4. Similarity Calculation and Loss Function
2.4. Training Details
2.4.1. Hyperparameters
2.4.2. Hardware and Software Setup
2.5. Evaluation Metrics
2.5.1. Ranking Metrics
- Top-K Accuracy: Measures the percentage of times a correct (positive or soft positive) candidate résumé appears within the top-K-ranked résumés for its corresponding job description. We calculated this for K values of 1, 3, 5, 10, 20, 30, 50, 75, and 100. The comparative results are presented in Table 6.
- Mean Reciprocal Rank (MRR): Calculates the average of the reciprocal ranks of the first correct candidate resume for each job description. A higher MRR indicates that the correct candidate is typically found closer to the top of the ranked list. The MRR values are included in Table 7.
2.5.2. Embedding Space Analysis
3. Results and Discussion
3.1. Computational Setup

3.2. Model Architecture and Embedding Configuration
3.3. Training Hyperparameters, Evaluation Settings, and Data Preprocessing
3.4. Quantitative Results
3.4.1. Performance Metrics Comparison
GRU Performance
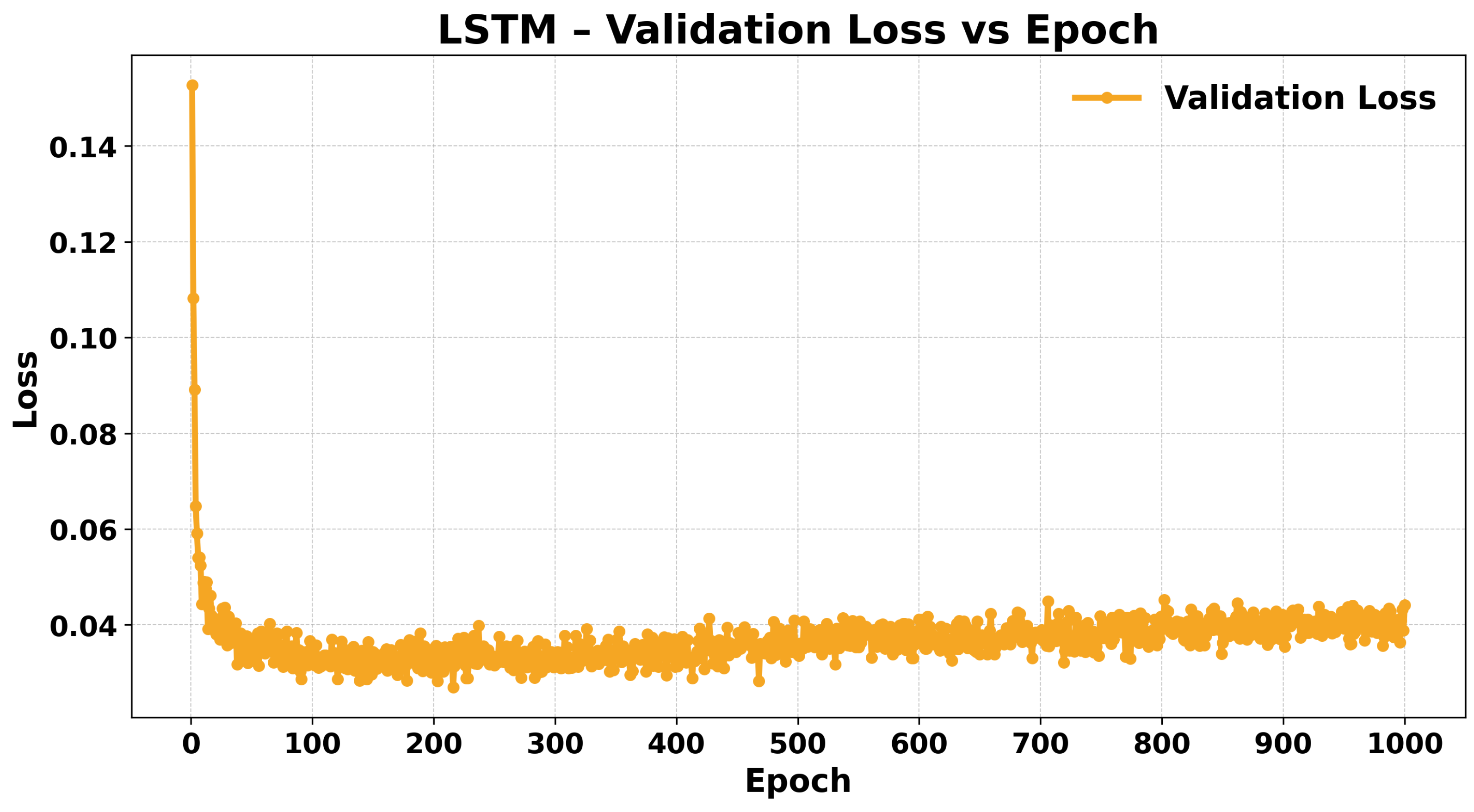
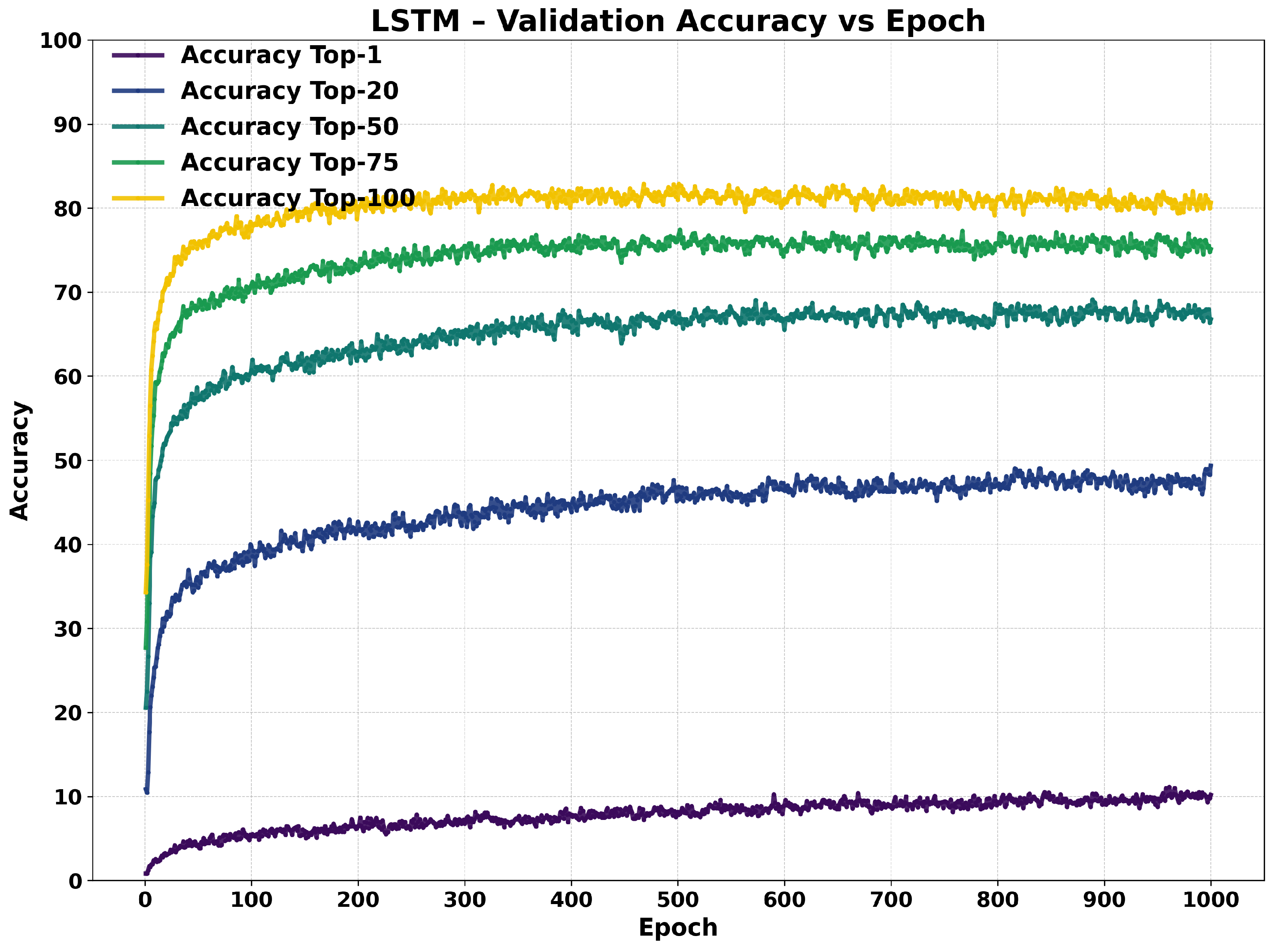
LSTM Performance
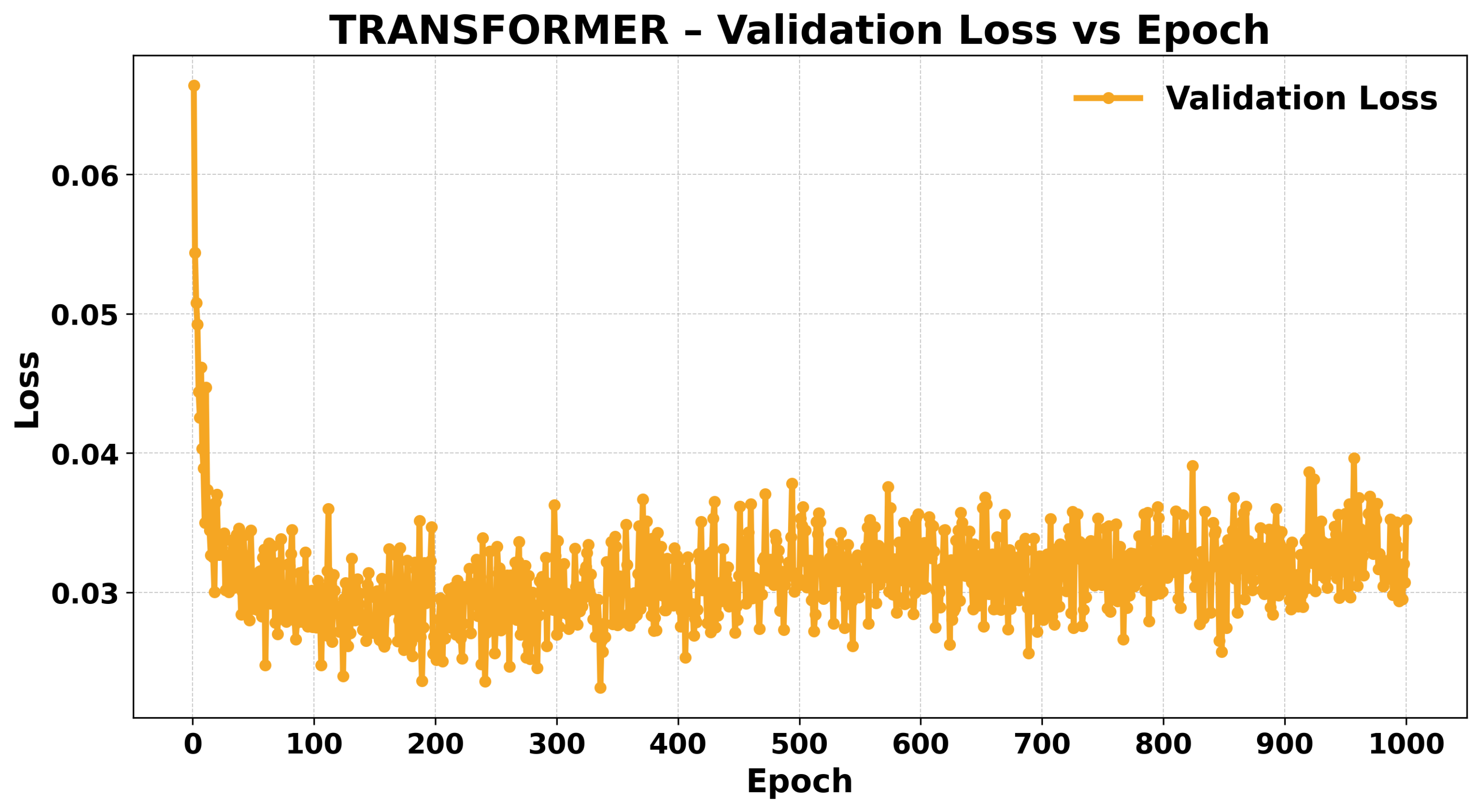
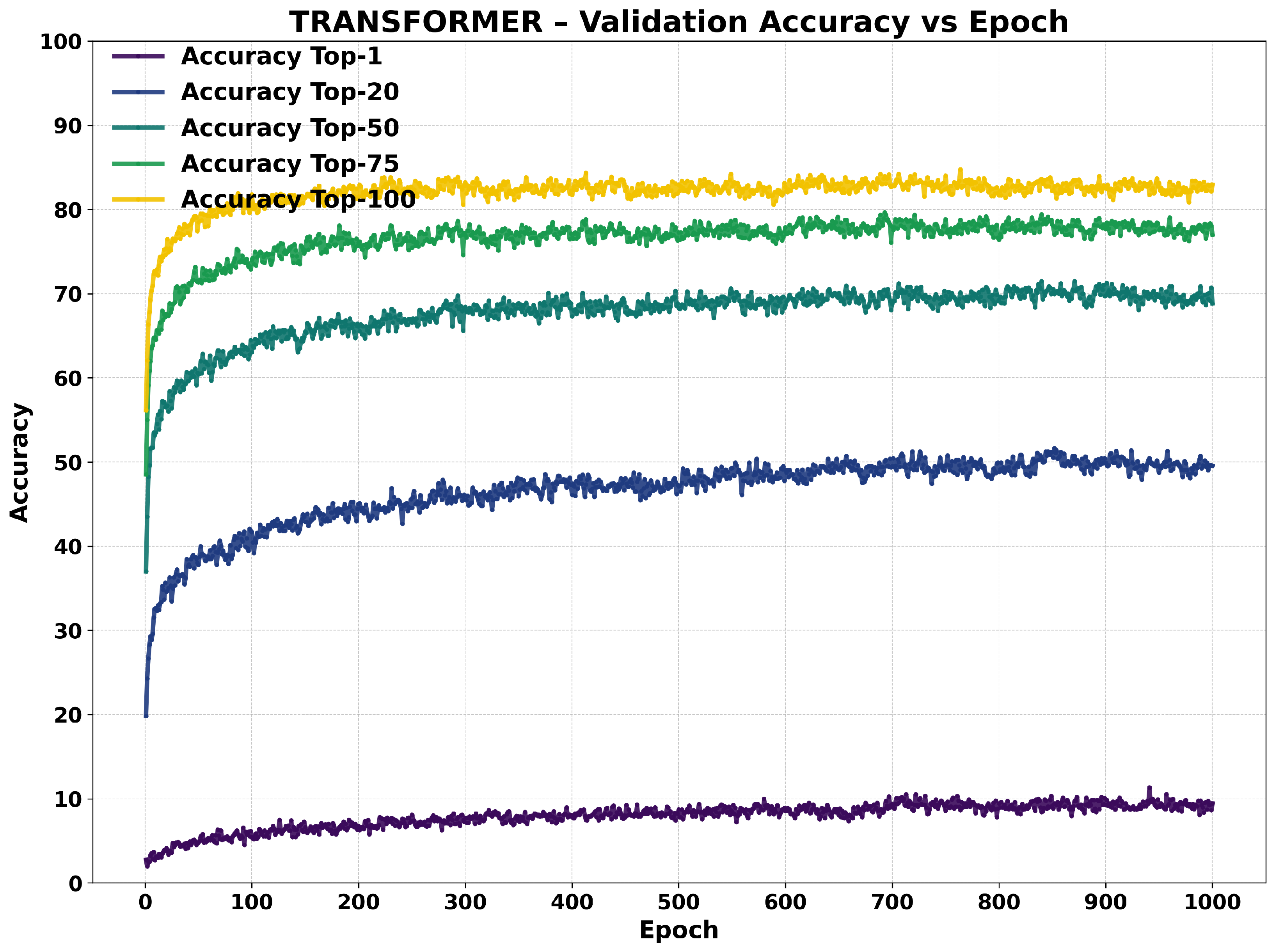
Transformer Performance
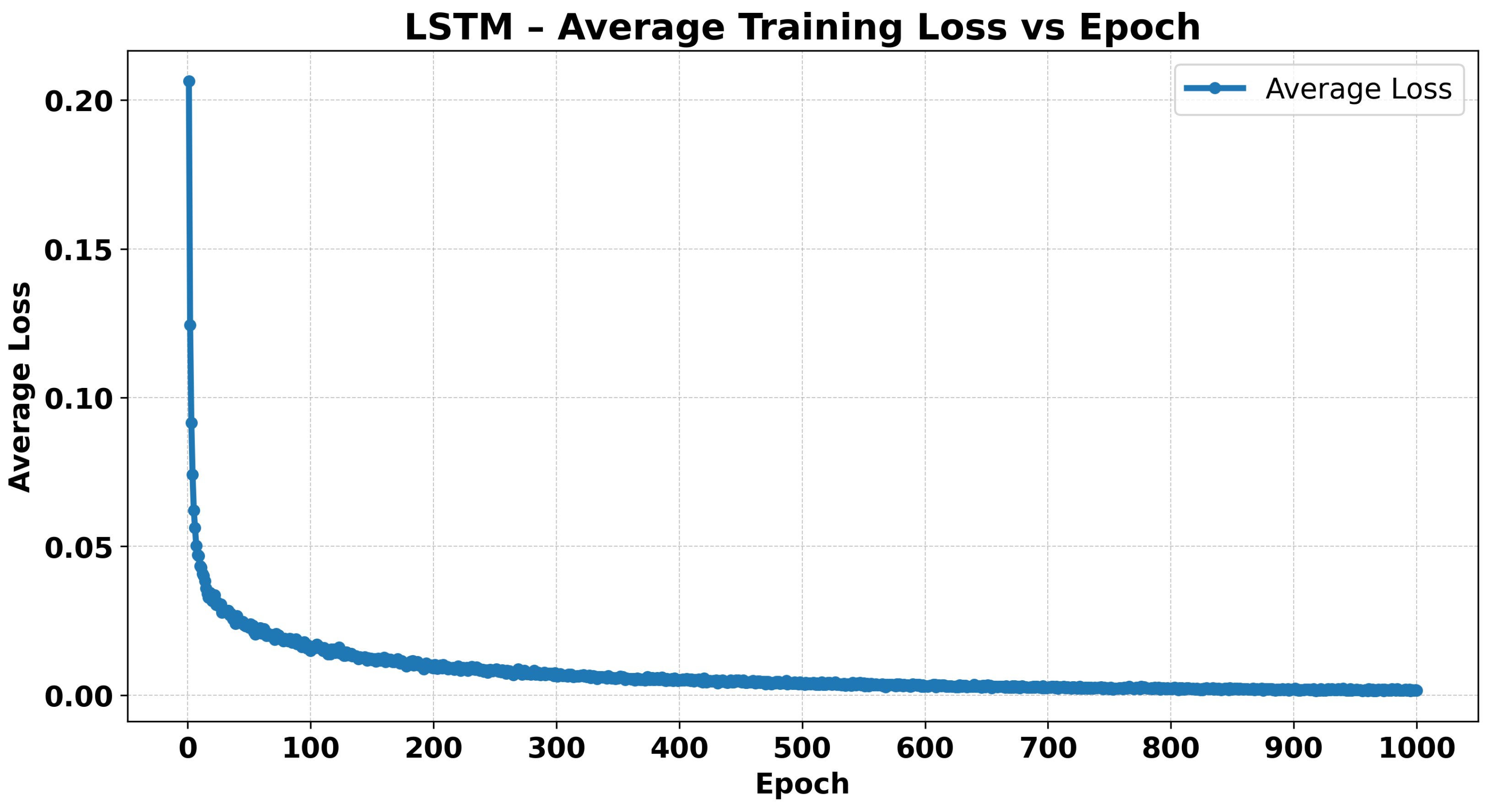
3.4.2. Training Dynamics
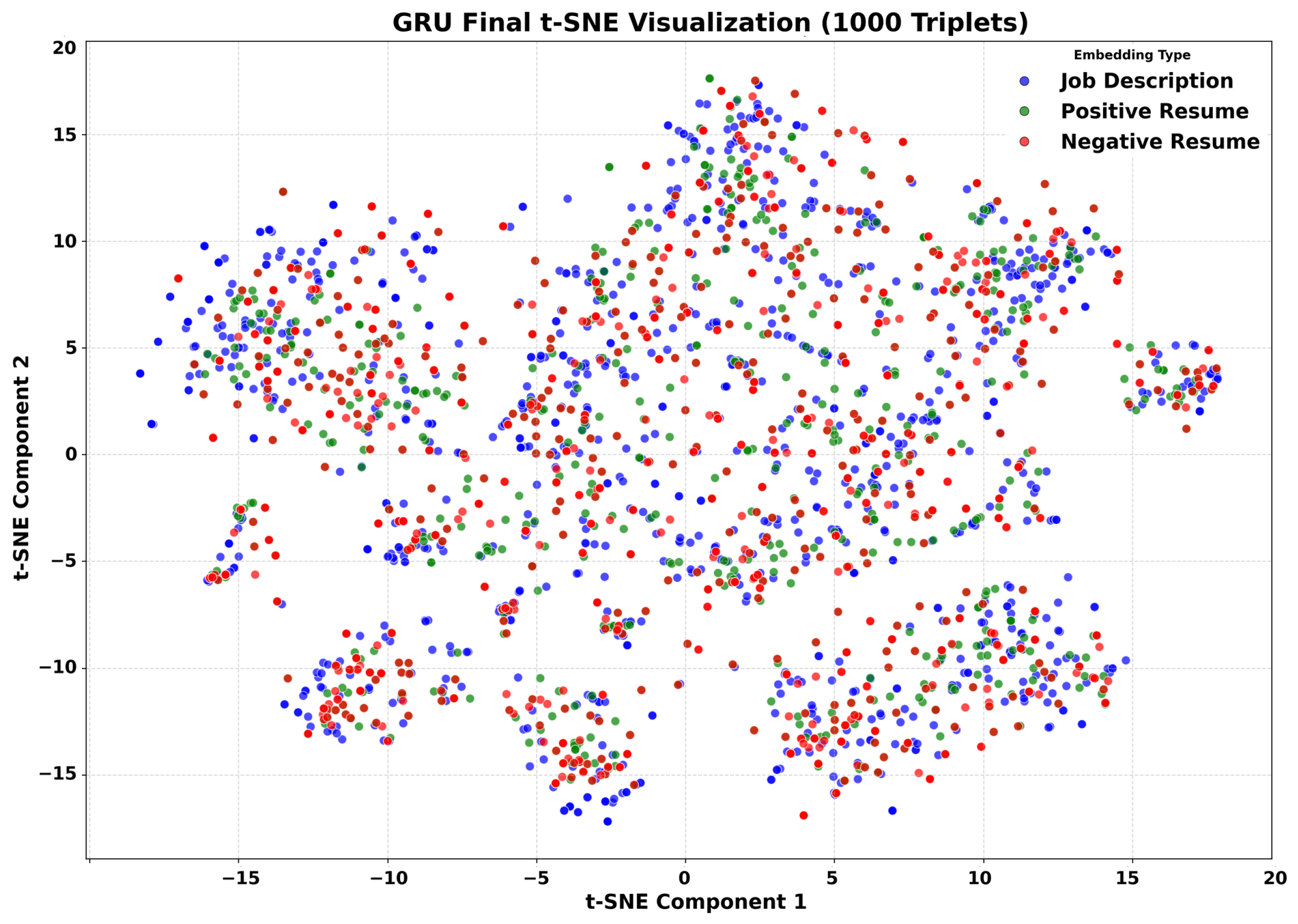
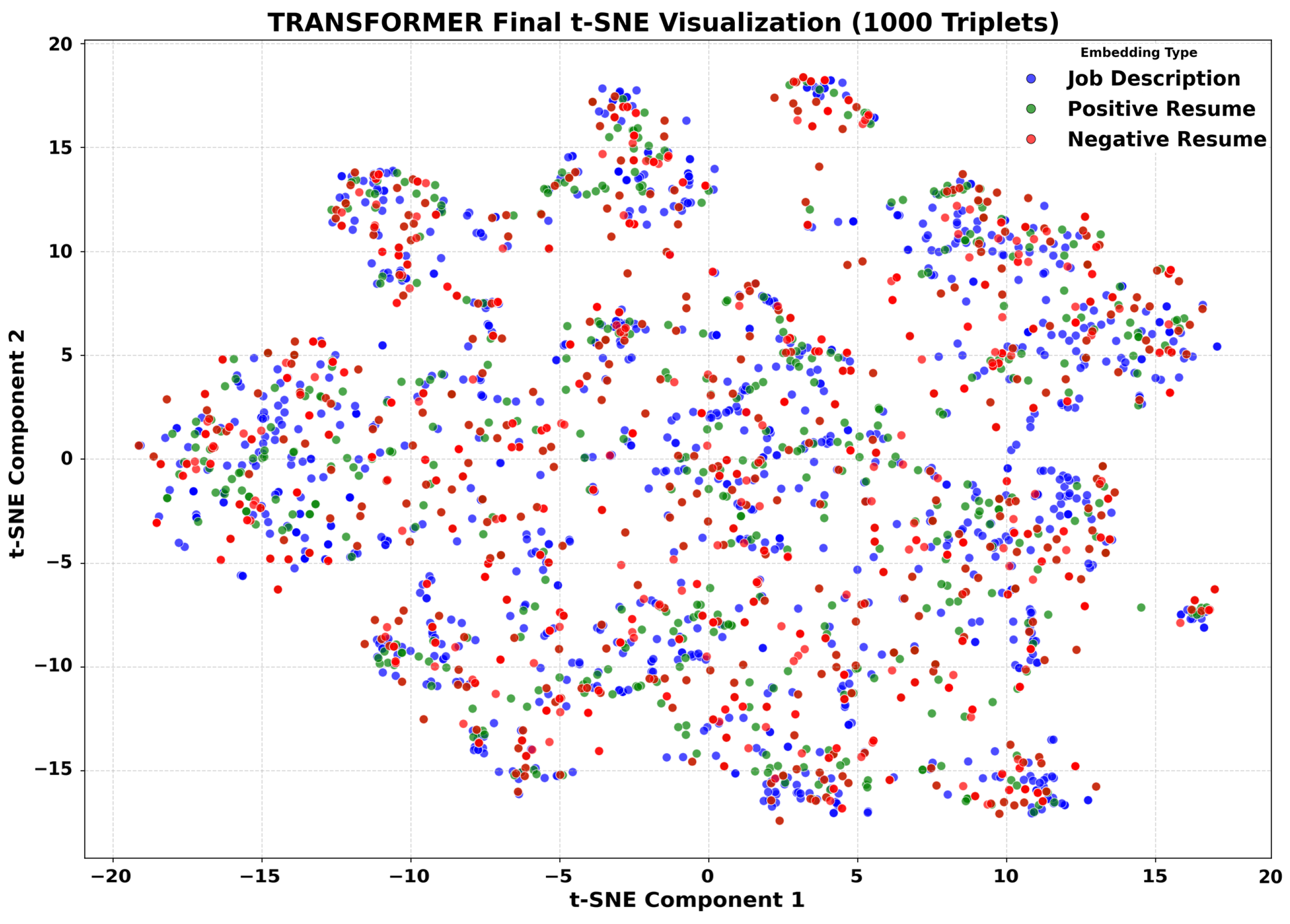
3.5. Qualitative Analysis
Embedding Space Visualization
3.6. Discussion
- Interpretation of Results.
- Comparison to Related Work.
- Strengths and Weaknesses of the Proposed Approach.
- Impact of Different Sequential Heads.
3.7. Limitations
- Dataset Size and Representation Bias: Although our dataset is drawn from real-world IT recruitment processes, it may not cover all role types or industry segments comprehensively. Additionally, the proportion of résumés in English vs. Polish could bias the model’s multilingual performance. Models trained under these conditions might not generalize well to other languages or drastically different domains without further fine-tuning.
- Domain Specificity: We focused on IT-related positions, where job descriptions often include specific technical terms and résumés list programming languages or frameworks. Hence, models trained on this domain may need additional data and adaptation for non-technical roles (e.g., marketing or finance) or for specialized subfields in IT (e.g., data science vs. cybersecurity).
- Model Complexity: Transformer-based heads, in particular, can have high memory and computational demands during training and inference. Organizations with limited GPU or CPU resources might find GRU or LSTM architectures more practical, albeit with slightly reduced performance. Hyperparameter tuning can further inflate the total cost of model deployment.
- No Explicit Handling of Structured Fields: Our current approach encodes job descriptions and résumés as free-text strings, largely ignoring tabular or structured information such as discrete skill lists, candidate location, or salary ranges. While the neural representations implicitly capture some structure, explicit incorporation of tabular or metadata features could further improve matching accuracy.
- Evaluation Based on Historical Outcomes: Our ground truth labels reflect the final result of each recruitment process, which may include factors beyond direct skill or qualification matches (e.g., salary negotiation, candidate relocation constraints, etc.). Relying on these labels assumes that historical decisions perfectly correlate with “best match” outcomes, which might not always hold. Future studies could refine labeling schemes to isolate skill-based matching from external hiring factors.
4. Conclusions
Future Work
- Integration of Structured Data: While our approach focused on unstructured text (job and résumé content), incorporating tabular metadata (e.g., candidate location, years of experience, and skill taxonomies) might further refine matching outcomes.
- Domain Expansion: Although our dataset was derived from IT-specific recruitment pipelines, extending experiments to other industry sectors or roles with distinct terminologies (e.g., finance, marketing, healthcare, etc.) would test model generalization capabilities and highlight potential domain adaptation strategies.
- Explainability and Interpretability: Providing interpretability (e.g., attention heatmaps or saliency scores) would offer transparency to recruiters, helping them understand why certain candidates rank higher than others and thus increasing the trust in the system’s recommendations.
- Real-Time Inference Optimization: Transformer heads can be computationally demanding in real-time ranking scenarios. Investigating model distillation, quantization, or efficient Transformers could make the approach more practical for large-scale deployments.
- Active Learning and Online Updates: In real recruitment environments, data distribution shifts occur frequently (e.g., new technologies, changing skill demands, etc.). Implementing active learning, continuous fine-tuning, or online learning methods can help the models to remain current and effective.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Economic Forum. The Future of Jobs Report 2023. White Paper. 2023. Available online: https://www.weforum.org/publications/the-future-of-jobs-report-2023/ (accessed on 17 May 2025).
- Upadhyay, A.K.; Khandelwal, K. Applying artificial intelligence: Implications for recruitment. Strateg. HR Rev. 2018, 17, 255–258. [Google Scholar] [CrossRef]
- LinkedIn Talent Insights Team. Global Talent Trends 2023. Industry Report. 2023. Available online: https://www.accaglobal.com/gb/en/professional-insights/pro-accountants-the-future/global-talent-trends-2023.html (accessed on 17 May 2025).
- Saxena, P.; Agrawal, V.; Pradhan, I.P. AI-Powered Talent Acquisition and Recruitment. In Human Resource Management and Artificial Intelligence; Routledge: London, UK, 2025; pp. 25–43. [Google Scholar] [CrossRef]
- Gethe, R.K. Extrapolation of talent acquisition in AI aided professional environment. Int. J. Bus. Innov. Res. 2022, 27, 462–479. [Google Scholar] [CrossRef]
- Gupta, S.; Shukla, B.; Sharma, U.; Hinneh, P.J.; Eswaran, B.; Sinha, B.C.; Kumari, A.; Sharma, N.; Laddhu, S. Impact of artificial intelligence and machine learning on recruitment process in MNCs of India. In Sustainable Management Practices for Employee Retention and Recruitment; IGI Global: Hershey, PA, USA, 2025; pp. 177–198. [Google Scholar] [CrossRef]
- Bouhoun, Z.; Guerrois, T.; Li, X.; Baker, M.; Elhadji Ille Gado, N.; Roumili, E.; Vitillo, F.; Benmiloud Bechet, L.; Plana, R. Information Retrieval Using Domain Adapted Language Models: Application to Resume Documents for HR Recruitment Assistance. In Computational Science and Its Applications—ICCSA 2023 Workshops; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2023; pp. 440–457. [Google Scholar] [CrossRef]
- Jiang, J.; Ye, S.; Wang, W.; Xu, J.; Luo, X. Learning Effective Representations for Person-Job Fit by Feature Fusion. In Proceedings of the CIKM’20: 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020; pp. 2549–2556. [Google Scholar] [CrossRef]
- Menacer, M.A.; Hamda, F.B.; Mighri, G.; Hamidene, S.B.; Cariou, M. An Interpretable Person-Job Fitting Approach Based on Classification and Ranking. 2021, pp. 130–138. Available online: https://aclanthology.org/2021.icnlsp-1.15.pdf (accessed on 17 May 2025).
- Yazici, M.B.; Sabaz, D.; Elmasry, W. AI-based Multimodal Resume Ranking Web Application for Large Scale Job Recruitment. In Proceedings of the 2024 8th International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Türkiye, 21–22 September 2024. [Google Scholar] [CrossRef]
- Rezaeipourfarsangi, S.; Milios, E.E. AI-powered Resume-Job matching: A document ranking approach using deep neural networks. In Proceedings of the DocEng’23: ACM Symposium on Document Engineering, Limerick, Ireland, 22–25 August 2023. [Google Scholar] [CrossRef]
- Gu, F.; Lu, J.; Cai, C. RPformer: A Robust Parallel Transformer for Visual Tracking in Complex Scenes. IEEE Trans. Instrum. Meas. 2022, 71, 5011214. [Google Scholar] [CrossRef]
- Kurek, J.; Latkowski, T.; Bukowski, M.; Świderski, B.; Łępicki, M.; Baranik, G.; Nowak, B.; Zakowicz, R.; Dabrowski, L. Zero-Shot Recommendation AI Models for Efficient Job–Candidate Matching in Recruitment Process. Appl. Sci. 2024, 14, 2601. [Google Scholar] [CrossRef]
- Nikolaou, I. What Is Artificial Intelligence in Recruitment and Selection? A Research Agenda for Future Adoption. Eur. J. Work Organ. Psychol. 2021, 30, 505–513. [Google Scholar] [CrossRef]
- Bevara, R.V.K.; Mannuru, N.R.; Karedla, S.P.; Lund, B.; Xiao, T.; Pasem, H.; Dronavalli, S.C.; Rupeshkumar, S. Resume2Vec: Transforming Applicant Tracking Systems with Intelligent Resume Embeddings for Precise Candidate Matching. Electronics 2025, 14, 794. [Google Scholar] [CrossRef]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; Lecun, Y.; Moore, C.; SÄckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the 32nd International Conference on Machine Learning (ICML) Deep Learning Workshop, Lille, France, 6–11 July 2015; Available online: https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf (accessed on 17 May 2025).
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing: Association for Computational Linguistics, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Lu, X.; Sheng, W.; Li, X. TSN-GReID: Transformer-based Siamese Network for Group Re-Identification. In Proceedings of the 2022 17th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 11–13 December 2022; pp. 422–427. [Google Scholar] [CrossRef]
- Maheshwary, S.; Misra, H. Matching Resumes to Jobs via Deep Siamese Network. In Proceedings of the WWW ’18: Companion the Web Conference 2018, Lyon France, 23–27 April 2018; pp. 87–88. [Google Scholar] [CrossRef]
- Wu, R.; Wen, X.; Yuan, L.; Xu, H.; Liu, Y. Visual Tracking based on deformable Transformer and spatiotemporal information. Eng. Appl. Artif. Intell. 2024, 127, 107269. [Google Scholar] [CrossRef]
- Che, C.; Fu, Y.; Shi, W.; Zhu, Z.; Wang, D. Dual Feature Fusion Tracking with Combined Cross-Correlation and Transformer. IEEE Access 2023, 11, 144966–144977. [Google Scholar] [CrossRef]
- Yu, X.; Xu, R.; Xue, C.; Zhang, J.; Yu, Z. ConFit v2: Improving Resume–Job Matching Using Hypothetical Resume Embedding and Runner-Up Hard-Negative Mining. arXiv 2025, arXiv:2502.12361. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar] [CrossRef]
- Mhatre, S.; Dakhare, B.; Ankolekar, V.; Chogale, N.; Navghane, R.; Gotarne, P. Resume Screening and Ranking using Convolutional Neural Network. In Proceedings of the 2023 International Conference on Sustainable Computing and Smart Systems (ICSCSS), Coimbatore, India, 14–16 June 2023; pp. 412–419. [Google Scholar] [CrossRef]
- Omara, E.; Mosa, M.; Ismail, N. Applying Recurrent Networks For Arabic Sentiment Analysis. Menoufia J. Electron. Eng. Res. 2022, 31, 21–28. [Google Scholar] [CrossRef]
- Yang, X.; Song, Y.; Zhao, Y.; Zhang, Z.; Zhao, C. Unveil the potential of siamese framework for visual tracking. Neurocomputing 2022, 513, 204–214. [Google Scholar] [CrossRef]
- Otman, M.; Rachid, E.A.; Mohamed, B. Amazigh Part of Speech Tagging using Gated recurrent units (GRU). In Proceedings of the 2021 7th International Conference on Optimization and Applications (ICOA), Wolfenbüttel, Germany, 19–20 May 2021. [Google Scholar] [CrossRef]
- Chen, H.; Meng, L.; Xi, Y.; Xin, M.; Yu, S.; Chen, G.; Chen, Y. GRU Based Time Series Forecast of Oil Temperature in Power Transformer. Distrib. Gener. Altern. Energy J. 2023, 38, 393–412. [Google Scholar] [CrossRef]
- Yu, S.; Liu, D.; Zhu, W.; Zhang, Y.; Zhao, S. Attention-based LSTM, GRU and CNN for short text classification. J. Intell. Fuzzy Syst. 2020, 39, 333–340. [Google Scholar] [CrossRef]
- Wang, S.; Ge, H.; Li, W.; Liu, L.; Zhou, T.; Yang, S. Bidirectional Joint Attention Mechanism for Target Tracking Algorithm. In Proceedings of the 2022 4th International Conference on Natural Language Processing (ICNLP), Xi’an, China, 25–27 March 2022; pp. 256–265. [Google Scholar] [CrossRef]
- Goel, A.; Katiyar, A.; Goel, A.K.; Kumar, A. LSTM Neural Networks for Brain Signals and Neuromorphic Chip. In Proceedings of the 2024 2nd International Conference on Advances in Computation, Communication and Information Technology (ICAICCIT), Faridabad, India, 28–29 November 2024; pp. 1033–1039. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, Y.; Han, G. Cooperative Use of Recurrent Neural Network and Siamese Region Proposal Network for Robust Visual Tracking. IEEE Access 2021, 9, 57704–57715. [Google Scholar] [CrossRef]
- Yang, L.; Wang, Y.; Fu, S.; Liu, L.; Luo, Y. EVS2vec: A Low-dimensional Embedding Method for Encrypted Video Stream Analysis. In Proceedings of the 2023 20th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Madrid, Spain, 11–14 September 2023; Volume 2023, pp. 537–545. [Google Scholar] [CrossRef]
- Wei, Y.; Wu, D.; Terpenny, J. Bearing remaining useful life prediction using self-adaptive graph convolutional networks with self-attention mechanism. Mech. Syst. Signal Process. 2023, 188, 110010. [Google Scholar] [CrossRef]
- Tallec, C.; Ollivier, Y. Can recurrent neural networks warp time? arXiv 2018, arXiv:1804.11188. [Google Scholar]
- Tang, Z.; Shi, Y.; Wang, D.; Feng, Y.; Zhang, S. Memory visualization for gated recurrent neural networks in speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2736–2740. [Google Scholar] [CrossRef]
- Fide, M.; Anarım, E. User Authentication with GRU based Siamese Networks using Keyboard Usage Behaviour. In Proceedings of the 2024 32nd Signal Processing and Communications Applications Conference (SIU), Mersin, Türkiye, 15–18 May 2024. [Google Scholar] [CrossRef]
- Wang, H.; Guo, F. Online object tracking based interactive attention. Comput. Vis. Image Underst. 2023, 236, 103809. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Column Name | Data Type | Column Description |
|---|---|---|
| index | int64 | Sequential number identifying the record in the dataset. |
| job_submission_id | int64 | Unique identifier of a candidate’s submission for a given job posting. |
| job_id | int64 | Unique identifier of the job posting. |
| job_title | string | The descriptive title or name of the job position (e.g., “Senior Java Developer”). |
| job_description | string | Full description of the job, covering responsibilities, requirements, and other details. |
| candidate_id | int64 | Unique identifier of the candidate (applicant). |
| candidate_resume | string | Textual content of the candidate’s résumé/CV (potentially multilingual). |
| recruitment_path | string | A text-based representation of the candidate’s progress through different recruiting stages. |
| recruitment_path_len | int64 | Number of completed stages in the candidate’s recruitment path. |
| recruitment_path_status | string | The candidate’s final or current stage status (e.g., passed technical interview, awaiting HR interview, etc.). |
| label | string | The final recruitment outcome category for the candidate (e.g., soft_positive, soft_negative, or positive). |
| Property | Train + Valid (Count) | Train + Valid (%) | Test (Count) | Test (%) |
|---|---|---|---|---|
| Number of Rows | 14,827 | – | 1000 | – |
| Number of Columns | 23 | – | 23 | – |
| Label: soft_positive | 6630 | 44.72% | 432 | 43.20% |
| Label: soft_negative | 5556 | 37.47% | 381 | 38.10% |
| Label: positive | 2641 | 17.81% | 187 | 18.70% |
| Total | 14,827 | 100.00% | 1000 | 100.00% |
| Train + Valid | Test | |||
|---|---|---|---|---|
| Language | Record Count | Percent | Record Count | Percent |
| en | 13,019 | 87.81% | 870 | 87.00% |
| pl | 1808 | 12.19% | 130 | 13.00% |
| Total | 14,827 | 100.00% | 1000 | 100.00% |
| Parameter Category | Value |
|---|---|
| Training Hyperparameters | |
| Batch Size | 1024 |
| Number of Epochs | 1000 |
| Learning Rate | 0.001 |
| Triplet Loss Margin () | 0.4 |
| Gradual Triplet Scaler | 4.0 |
| Evaluation and Logging | |
| Top-K Accuracy Metrics (K values) | 1, 3, 5, 10, 20, 30, 50, 75, 100 |
| t-SNE Visualization Sample Size | 1000 |
| Log Frequency (steps) | Dynamic (e.g., every 1/10 epoch) |
| K Values for Plotting Accuracy | 1, 20, 50, 75, 100 |
| Main Model Save File Name | head_model.pt |
| Best Model Save File Name | best_model.pt |
| Data Handling and Preprocessing | |
| Validation Set Ratio | 0.1 |
| Embedding Chunk Lengths | 1024 |
| Max Segments per Document | 15 |
| Parameter | GRU | LSTM | Transformer |
|---|---|---|---|
| Total Run Duration (seconds) | 3048.03 | 2903.50 | 3017.77 |
| Avg. Epoch Duration (seconds) | 1.90 | 1.73 | 1.83 |
| Device Used | cuda | cuda | cuda |
| Num GPU Used | 2 | 2 | 2 |
| GPU Name | NVIDIA GH200 144G HBM3e | NVIDIA GH200 144G HBM3e | NVIDIA GH200 144G HBM3e |
| GPU CUDA Version | 12.6 | 12.6 | 12.6 |
| Num Dataloader Workers (CPU) | 144 | 144 | 144 |
| Metric | GRU | LSTM | Transformer |
|---|---|---|---|
| Train Top-1 | 1.45 | 0.94 | 1.15 |
| Train Top-3 | 3.98 | 2.86 | 3.31 |
| Train Top-5 | 6.09 | 4.35 | 5.19 |
| Train Top-10 | 9.98 | 7.49 | 8.52 |
| Train Top-20 | 15.93 | 12.19 | 13.67 |
| Train Top-30 | 20.72 | 15.83 | 17.85 |
| Train Top-50 | 28.04 | 22.51 | 24.47 |
| Train Top-75 | 35.03 | 28.78 | 31.07 |
| Train Top-100 | 40.52 | 34.43 | 36.11 |
| Valid Top-1 | 5.46 | 4.72 | 4.79 |
| Valid Top-3 | 12.34 | 11.13 | 11.53 |
| Valid Top-5 | 17.94 | 15.85 | 17.19 |
| Valid Top-10 | 29.53 | 24.68 | 26.10 |
| Valid Top-20 | 42.35 | 37.90 | 38.17 |
| Valid Top-30 | 49.36 | 48.01 | 47.47 |
| Valid Top-50 | 61.83 | 59.81 | 60.28 |
| Valid Top-75 | 72.69 | 69.93 | 70.67 |
| Valid Top-100 | 79.30 | 78.08 | 77.68 |
| Test Top-1 | 5.00 | 5.40 | 4.50 |
| Test Top-3 | 12.80 | 13.20 | 11.60 |
| Test Top-5 | 18.10 | 19.30 | 18.00 |
| Test Top-10 | 30.90 | 29.50 | 29.90 |
| Test Top-20 | 44.70 | 43.50 | 43.40 |
| Test Top-30 | 55.20 | 52.50 | 54.60 |
| Test Top-50 | 69.20 | 66.40 | 69.20 |
| Test Top-75 | 80.00 | 78.00 | 80.50 |
| Test Top-100 | 86.70 | 84.80 | 87.20 |
| Metric | GRU | LSTM | Transformer |
|---|---|---|---|
| Train Loss | 0.01433 | 0.01610 | 0.01423 |
| Train MRR | 0.9918 | 0.9905 | 0.99115 |
| Train Avg. Pos. Sim. | 0.68324 | 0.69887 | 0.75792 |
| Train Avg. Neg. Sim. | 0.02040 | 0.03455 | 0.01873 |
| Validation Loss | 0.03157 | 0.03679 | 0.03253 |
| Validation MRR | 0.98314 | 0.97741 | 0.97876 |
| Valid Avg. Pos. Sim. | 0.61753 | 0.65069 | 0.69815 |
| Valid Avg. Neg. Sim. | 0.00836 | 0.03975 | 0.02107 |
| Test Loss | 0.03586 | 0.03703 | 0.03140 |
| Test MRR | 0.97800 | 0.97750 | 0.97900 |
| Test Avg. Pos. Sim. | 0.60579 | 0.63980 | 0.69249 |
| Test Avg. Neg. Sim. | 0.00540 | 0.04778 | 0.02460 |
| Parameter Category | Value |
|---|---|
| Sentence Transformer | |
| Base Model | distiluse-base-multilingual-cased-v2 |
| Input Embedding Size | 512 |
| Head Model (GRU/LSTM/Transformer) | |
| Hidden Size | 256 |
| Number of Layers | 1 |
| Output Embedding Size | 256 |
| Output Aggregation | attention |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Łępicki, M.; Latkowski, T.; Antoniuk, I.; Bukowski, M.; Świderski, B.; Baranik, G.; Nowak, B.; Zakowicz, R.; Dobrakowski, Ł.; Act, B.; et al. Comparative Evaluation of Sequential Neural Network (GRU, LSTM, Transformer) Within Siamese Networks for Enhanced Job–Candidate Matching in Applied Recruitment Systems. Appl. Sci. 2025, 15, 5988. https://doi.org/10.3390/app15115988
Łępicki M, Latkowski T, Antoniuk I, Bukowski M, Świderski B, Baranik G, Nowak B, Zakowicz R, Dobrakowski Ł, Act B, et al. Comparative Evaluation of Sequential Neural Network (GRU, LSTM, Transformer) Within Siamese Networks for Enhanced Job–Candidate Matching in Applied Recruitment Systems. Applied Sciences. 2025; 15(11):5988. https://doi.org/10.3390/app15115988
Chicago/Turabian StyleŁępicki, Mateusz, Tomasz Latkowski, Izabella Antoniuk, Michał Bukowski, Bartosz Świderski, Grzegorz Baranik, Bogusz Nowak, Robert Zakowicz, Łukasz Dobrakowski, Bogdan Act, and et al. 2025. "Comparative Evaluation of Sequential Neural Network (GRU, LSTM, Transformer) Within Siamese Networks for Enhanced Job–Candidate Matching in Applied Recruitment Systems" Applied Sciences 15, no. 11: 5988. https://doi.org/10.3390/app15115988
APA StyleŁępicki, M., Latkowski, T., Antoniuk, I., Bukowski, M., Świderski, B., Baranik, G., Nowak, B., Zakowicz, R., Dobrakowski, Ł., Act, B., & Kurek, J. (2025). Comparative Evaluation of Sequential Neural Network (GRU, LSTM, Transformer) Within Siamese Networks for Enhanced Job–Candidate Matching in Applied Recruitment Systems. Applied Sciences, 15(11), 5988. https://doi.org/10.3390/app15115988