
Harnessing Generative Pre-Trained Transformers for Construction Accident Prediction with Saliency Visualization



Abstract
1. Introduction
2. Research Background
3. Materials and Methods
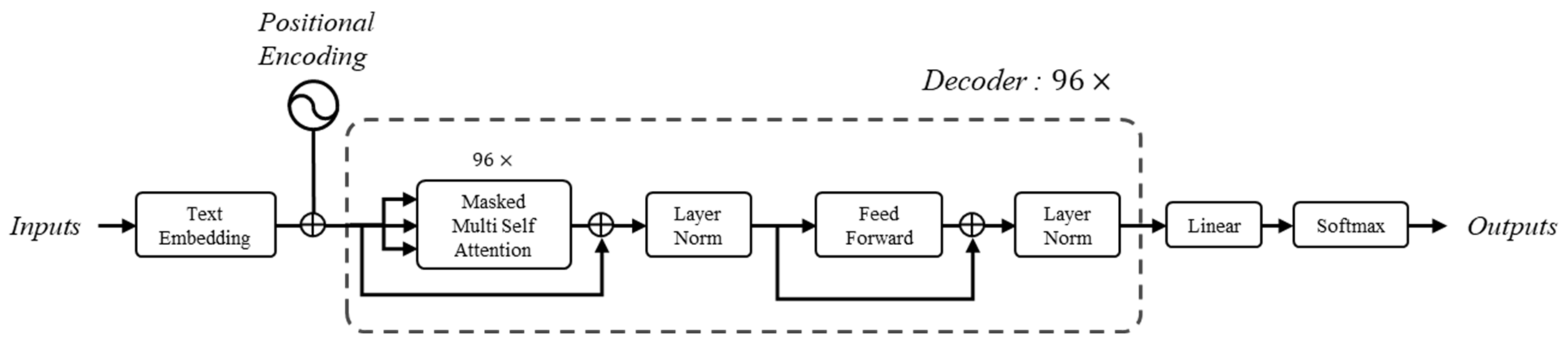
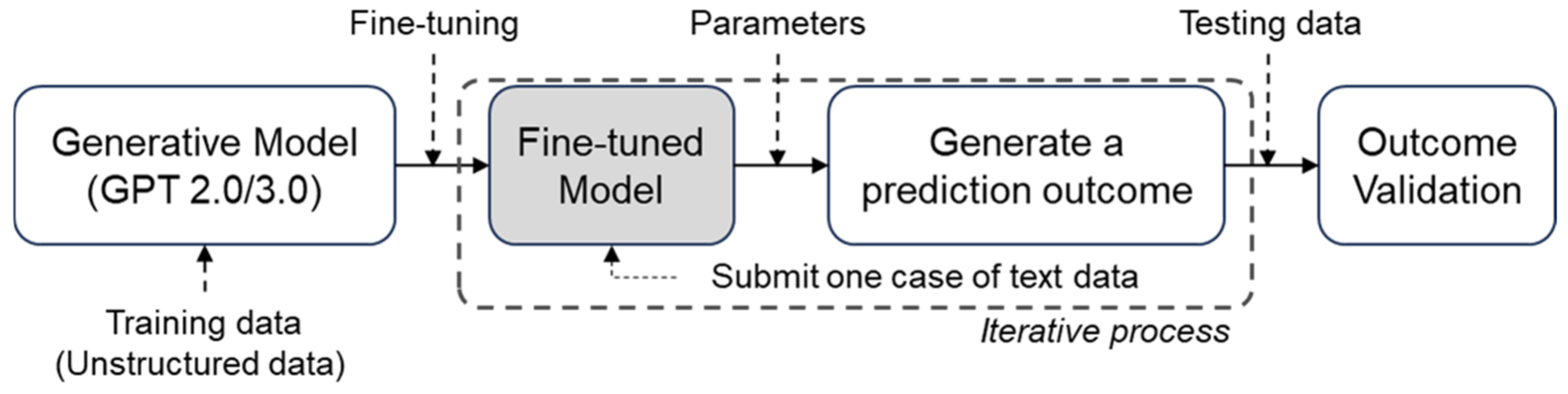
3.1. Fine-Tuning in Generative Model Using Construction Report Data
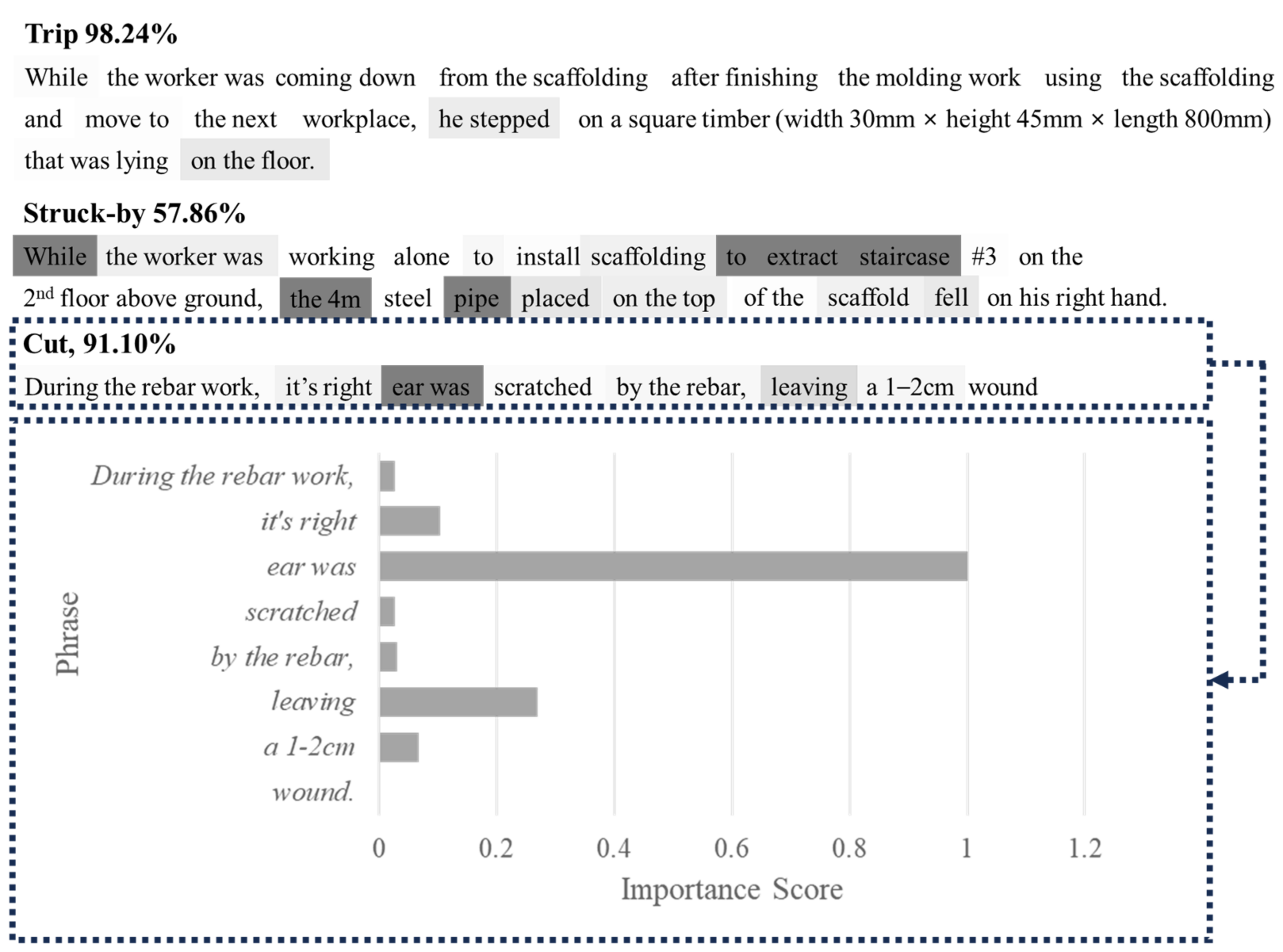
3.2. Saliency Visualization of Accident Attributes in Unstructured Free-Text Data
- represents the set of all word elements contained in the sentence.
- represents an individual word in the set , with the subscript indicating the positional information of that word.
| Algorithm 1 Computing Importance Scores for words in a sentence |
| Input: A sentence of text data ; Output: List ; 1 Split into a List of words ; 2 Declare variables on the disk; 3 for i from 1 to n do 4 5 6 7 end for 8 Assign |
4. Results
4.1. Data
4.2. Baseline Models
- TF-IDF, is a statistical measure that indicates how important a word is within a specific document in a collection of documents [48]. Typically used in information retrieval and text mining [49], TF-IDF provides weightings but does not involve learning on its own. However, it can be integrated with machine learning techniques and has surprisingly demonstrated strong performance in prior research, earning its selection as a benchmark model. Both the stochastic gradient descent (SGD) classifier and support vector machine (SVM) classifier were trained using the weights obtained from the TF-IDF vectorizer, and their accuracy was measured. In the training of the SGD classifier, the performance of four different kernels (radial basis function, linear, poly, sigmoid) was compared. Among these, the Linear Kernel yielded the highest accuracy. In the training of the SVM classifier, nine different loss parameters (logistic, hinge, modified huber, squared hinge, perceptron, squared error, huber, insensitive, squared epsilon insensitive) were utilized. Among these, the logistic loss parameter resulted in the highest accuracy.
- CNN specializes in deep learning models for image and grid data processing [50,51]. They use convolutional layers to detect features, pooling layers to downsample, and fully connected layers for classification. CNNs excel in tasks such as image recognition and have wide applications in computer vision and beyond. In the dataset, the following parameters yielded the most optimal results. The number of epochs was set to 8, following experimentation in the range of 6 to 100, while the batch size was configured to 64, tested across a range from 32 to 128. An embedding dimension of 300 was used, accompanied by 100 filters and filter sizes of 2, 3, and 4. A dropout rate of 0.5 was applied during training. The optimizer employed was Adam, and the criterion was defined as CrossEntropyLoss, since the task is multiclass classification. The text was tokenized using the spacy.load (“ko_core_news_sm”) tokenizer supported by spacy, which is the Python library. The pre-trained model used for the tokenizer is “ko_core_news_sm”. These parameters were crucial in achieving the desired outcomes, as highlighted in the provided data.
- BERT is indeed a type of LLM, similar to GPT, but it’s a smaller model with only 0.3 billion parameters compared to GPT-3.0’s 175 billion parameters [39,52]. The number of parameters in LLMs is proportional to the size of the training dataset. To investigate whether there is a performance difference in the dataset based on the number of parameters, experiments were conducted using BERT. The experiments were conducted using Python and the Keras TensorFlow package [52,53]. The training of the BERT model was based on the BERT-Base model available from Google on GitHub. The BERT-Base model supports 104 languages and consists of 12 layers, 768 hidden units per layer, 12 attention heads, and 110 million parameters. For optimization, the RAdam optimizer was chosen, incorporating a weight decay of 0.0025 [54,55]. Since the task involves multi-class classification, the sparse categorical cross-entropy loss function was employed. Furthermore, the following parameters that produced the best performance were used in this paper: sequence length (128), batch size (16), epochs (8), learning rate (0.00001), optimizer (Adam).
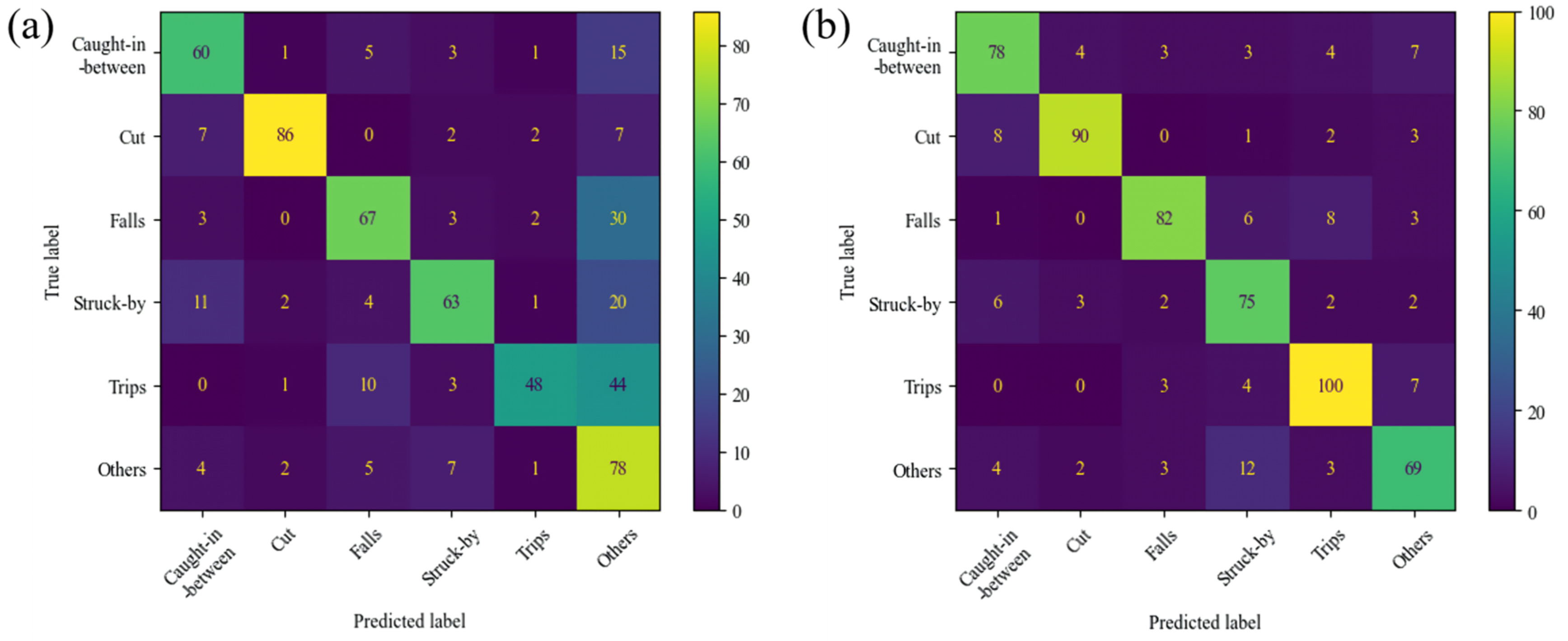
4.3. Experiment Results
4.4. Saliency Visualization Results for Accident Types
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rydning, D.R.-J.G.-J.; Reinsel, J.; Gantz, J. The digitization of the world from edge to core. Fram. Int. Data Corp. 2018, 16, 1–28. [Google Scholar]
- Data Growth Worldwide 2010–2025. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 23 October 2023).
- EDER Unstructured Data and the 80 Percent Rule. Breakthrough Analysis. 2008. Available online: https://breakthroughanalysis.com/2008/08/01/unstructured-data-and-the-80-percent-rule/ (accessed on 1 August 2008).
- Woods, D.D.; Patterson, E.S.; Roth, E.M. Can We Ever Escape from Data Overload? A Cognitive Systems Diagnosis. Cogn. Tech. Work 2002, 4, 22–36. [Google Scholar] [CrossRef]
- Henke, N.; Jacques Bughin, L. The Age of Analytics: Competing in a Data-Driven World; McKinsey Global Institute Research: New York, NY, USA, 2016. [Google Scholar]
- Baker, H.; Hallowell, M.R.; Tixier, A.J.-P. Automatically learning construction injury precursors from text. Autom. Constr. 2020, 118, 103145. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Tang, S.; Zhang, J.; Wan, J. Integrating information entropy and latent Dirichlet allocation models for analysis of safety accidents in the construction industry. Buildings 2023, 13, 1831. [Google Scholar] [CrossRef]
- Lukic, D.; Littlejohn, A.; Margaryan, A. A framework for learning from incidents in the workplace. Saf. Sci. 2012, 50, 950–957. [Google Scholar] [CrossRef]
- Sanne, J.M. Incident reporting or storytelling? Competing schemes in a safety-critical and hazardous work setting. Saf. Sci. 2008, 46, 1205–1222. [Google Scholar] [CrossRef]
- Ganguli, R.; Miller, P.; Pothina, R. Effectiveness of natural language processing based machine learning in analyzing incident narratives at a mine. Minerals 2021, 11, 776. [Google Scholar] [CrossRef]
- Fang, W.; Luo, H.; Xu, S.; Love, P.E.; Lu, Z.; Ye, C. Automated text classification of near-misses from safety reports: An improved deep learning approach. Adv. Eng. Inform. 2020, 44, 101060. [Google Scholar] [CrossRef]
- Wu, H.; Zhong, B.; Medjdoub, B.; Xing, X.; Jiao, L. An ontological metro accident case retrieval using CBR and NLP. Appl. Sci. 2020, 10, 5298. [Google Scholar] [CrossRef]
- Li, J.; Wu, C. Deep Learning and Text Mining: Classifying and Extracting Key Information from Construction Accident Narratives. Appl. Sci. 2023, 13, 10599. [Google Scholar] [CrossRef]
- Zhang, J.; Zi, L.; Hou, Y.; Deng, D.; Jiang, W.; Wang, M. A C-BiLSTM approach to classify construction accident reports. Appl. Sci. 2020, 10, 5754. [Google Scholar] [CrossRef]
- Tixier, A.J.-P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Application of machine learning to construction injury prediction. Autom. Constr. 2016, 69, 102–114. [Google Scholar] [CrossRef]
- Zhang, F.; Fleyeh, H.; Wang, X.; Lu, M. Construction site accident analysis using text mining and natural language processing techniques. Autom. Constr. 2019, 99, 238–248. [Google Scholar] [CrossRef]
- Baker, H.; Hallowell, M.R.; Tixier, A.J.-P. AI-based prediction of independent construction safety outcomes from universal attributes. Autom. Constr. 2020, 118, 103146. [Google Scholar] [CrossRef]
- Locatelli, M.; Seghezzi, E.; Pellegrini, L.; Tagliabue, L.C.; Di Giuda, G.M. Exploring natural language processing in construction and integration with building information modeling: A scientometric analysis. Buildings 2021, 11, 583. [Google Scholar] [CrossRef]
- Lee, J.-K.; Cho, K.; Choi, H.; Choi, S.; Kim, S.; Cha, S.H. High-level implementable methods for automated building code compliance checking. Dev. Built Environ. 2023, 15, 100174. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning; Technical Report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); NIPS: New Orleans, LA, USA, 2017; Volume 30. [Google Scholar]
- Pal, A.; Lin, J.J.; Hsieh, S.-H.; Golparvar-Fard, M. Automated vision-based construction progress monitoring in built environment through digital twin. Dev. Built Environ. 2023, 16, 100247. [Google Scholar] [CrossRef]
- Esmaeili, B.; Hallowell, M. Attribute-Based Risk Model for Measuring Safety Risk of Struck-By Accidents. In Proceedings of the Construction Research Congress 2012; American Society of Civil Engineers: West Lafayette, IN, USA, 2012; pp. 289–298. [Google Scholar]
- Jeong, J.; Jeong, J. Quantitative Risk Evaluation of Fatal Incidents in Construction Based on Frequency and Probability Analysis. J. Manag. Eng. 2022, 38, 04021089. [Google Scholar] [CrossRef]
- Kang, Y.; Cai, Z.; Tan, C.-W.; Huang, Q.; Liu, H. Natural language processing (NLP) in management research: A literature review. J. Manag. Anal. 2020, 7, 139–172. [Google Scholar] [CrossRef]
- Hallowell, M.R. Safety-Knowledge Management in American Construction Organizations. J. Manag. Eng. 2012, 28, 203–211. [Google Scholar] [CrossRef]
- Huang, X.; Hinze, J. Owner’s Role in Construction Safety. J. Constr. Eng. Manag. 2006, 132, 164–173. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, J.; Luo, X. Applications of natural language processing in construction. Autom. Constr. 2022, 136, 104169. [Google Scholar] [CrossRef]
- Chokor, A.; Naganathan, H.; Chong, W.K.; El Asmar, M. Analyzing Arizona OSHA injury reports using unsupervised machine learning. Procedia Eng. 2016, 145, 1588–1593. [Google Scholar] [CrossRef]
- Tixier, A.J.-P.; Hallowell, M.R.; Rajagopalan, B. Construction Safety Risk Modeling and Simulation. Risk Anal. 2017, 37, 1917–1935. [Google Scholar] [CrossRef]
- Hsieh, H.-F.; Shannon, S.E. Three Approaches to Qualitative Content Analysis. Qual. Health Res. 2005, 15, 1277–1288. [Google Scholar] [CrossRef] [PubMed]
- Tixier, A.J.-P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Automated content analysis for construction safety: A natural language processing system to extract precursors and outcomes from unstructured injury reports. Autom. Constr. 2016, 62, 45–56. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Kusoemo, D.; Gosno, R.A. Text mining-based construction site accident classification using hybrid supervised machine learning. Autom. Constr. 2020, 118, 103265. [Google Scholar] [CrossRef]
- Kim, T.; Chi, S. Accident Case Retrieval and Analyses: Using Natural Language Processing in the Construction Industry. J. Constr. Eng. Manag. 2019, 145, 04019004. [Google Scholar] [CrossRef]
- Kim, H.; Jang, Y.; Kang, H.; Yi, J.-S. A Study on Classifying Construction Disaster Cases in Report with CNN for Effective Management. In Proceedings of the Construction Research Congress 2022; American Society of Civil Engineers: Arlington, VA, USA, 2022; pp. 483–491. [Google Scholar]
- Goh, Y.M.; Ubeynarayana, C.U. Construction accident narrative classification: An evaluation of text mining techniques. Accid. Anal. Prev. 2017, 108, 122–130. [Google Scholar] [CrossRef]
- Liu, P.; Shi, Y.; Xiong, R.; Tang, P. Quantifying the reliability of defects located by bridge inspectors through human observation behavioral analysis. Dev. Built Environ. 2023, 14, 100167. [Google Scholar] [CrossRef]
- Zhang, M.; Li, J. A commentary of GPT-3 in MIT Technology Review 2021. Fundam. Res. 2021, 1, 831–833. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Balkus, S.V.; Yan, D. Improving short text classification with augmented data using GPT-3. In Natural Language Engineering; Cambridge University Press: Cambridge, UK, 2022; pp. 1–30. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Alkaissy, M.; Arashpour, M.; Golafshani, E.M.; Hosseini, M.R.; Khanmohammadi, S.; Bai, Y.; Feng, H. Enhancing construction safety: Machine learning-based classification of injury types. Saf. Sci. 2023, 162, 106102. [Google Scholar] [CrossRef]
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001; ISBN 978-1-4899-0519-2. [Google Scholar]
- Stone, M. Cross-Validatory Choice and Assessment of Statistical Predictions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Ryan, K.N.; Bahhur, B.N.; Jeiran, M.; Vogel, B.I. Evaluation of augmented training datasets. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXXII; SPIE: Bellingham, WA, USA, 2021; Volume 11740, pp. 118–125. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Crnic, J. Introduction to Modern Information Retrieval. Libr. Manag. 2011, 32, 373–374. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Zhang, Y.; Wallace, B. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd: Birmingham, UK, 2017. [Google Scholar]
- Sokolov, A.; Mostovoy, J.; Ding, J.; Seco, L. Building Machine Learning Systems to Automate ESG Index Construction; Luis Seco Publications: Toronto, ON, Canada, 2020. [Google Scholar]
- Won, K.; Jang, Y.; Choi, H.; Shin, S. Design and implementation of information extraction system for scientific literature using fine-tuned deep learning models. SIGAPP Appl. Comput. Rev. 2022, 22, 31–38. [Google Scholar] [CrossRef]
- Li, J.; Zhao, X.; Zhou, G.; Zhang, M. Standardized use inspection of workers’ personal protective equipment based on deep learning. Saf. Sci. 2022, 150, 105689. [Google Scholar] [CrossRef]
- Tang, S.; Golparvar-Fard, M. Machine Learning-Based Risk Analysis for Construction Worker Safety from Ubiquitous Site Photos and Videos. J. Comput. Civ. Eng. 2021, 35, 04021020. [Google Scholar] [CrossRef]
- Sasaki, Y. The truth of the F-measure. Teach Tutor Mater. 2007, 1, 1–5. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors (Year) | Task | Source Data | Text Fields | Outperformed Method | Accuracy |
|---|---|---|---|---|---|
| Tixierc, A.J.P., et al. (2020) [6] | Prediction of 6 incident type, 4 injury type, 6 body part, 2 severity from injury reports | A dataset of 90,000 incident reports from global oil refineries | Title, accident details, detail, root cause | TF-IDF + SVM | 71.55% |
| Kim, H., Jang, Y., Kang, H. & Yi, J.S. (2022) [35] | Classification of 5 accident case from accident reports | Korea Occupational Safety and Health Agency | Accident case | CNN | 52% |
| Zhang, Jinyue, et al. (2020) [14] | Classification of 11 accident categories from accident reports | Occupational Safety and Health Administration | Accident narratives | BERT | 80% |
| Goh, Y.M. & Ubeynarayana, C.U. (2017) [36] | Classification of 11 labels of accident causes or types from accident reports | Occupational Safety and Health Administration | Accident narratives | SVM | 62% |
| Zhang, Fan, et al. (2019) [16] | Classification of 11 causes of accidents from accident reports | Occupational Safety and Health Administration | Fatality and catastrophe investigation summary reports | Ensemble | 68% |
| Cheng, M.Y., Kusoemo, D. & Gosno, R.A. (2020) [33] | Classification of 11 labels of accident causes or types from accident reports | Occupational Safety and Health Administration | Accident narratives | Hybrid model | 69% |
| Variable | Type | Feature | |
|---|---|---|---|
| Output | Event type | Categorical (6 events) | Caught-in-between, Cut, Falls, Struck-by, Trips, Others. |
| Input (Unstructured) | Narrative details of accidents | Text (Accident details) | Unstructured text data |
| Input (Structured) | Date | Categorical (4 seasons) | Spring, Summer, Fall, Winter |
| Time | Categorical (5 windows) | Dawn, Morning, Daytime, Afternoon, Night | |
| Weather | Categorical | Sunny, Snowy, Rainy, Windy, Foggy, Cloudy | |
| Temperature | Numerical (Integer) | …, −3 °C, −2 °C, −1 °C, 0 °C, 1 °C, 2 °C, 3 °C, … | |
| Humidity | Numerical (Percentage in natural number) | 0%, 1%, 2%, 3%, … | |
| Type of construction | Categorical | File drive, Building blocks, Formwork installation, … | |
| Method of construction | Categorical | Firewall installation, Doka form installation, Gang form dismantling, … | |
| Nationality | Categorical | Republic of Korea, Malaysia, USA, Vietnam, … | |
| Age | Numerical (Natural number) | 20, 21, 22, …, 79 | |
| Work progress | Categorical (Ranges of percentage) | 0~9%, 10~19%, 20~29%, …, 90~100% | |
| Classifier (Data Type) | Performance Metrics | Caught-in- between | Cut | Falls | Struck-by | Trips | Others | Total | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|
| TF-IDF + SGD (Unstructured data only) | Precision | 0.52 | 0.80 | 0.56 | 0.36 | 0.59 | 0.35 | 0.53 | 51.34 |
| Recall | 0.59 | 0.49 | 0.60 | 0.48 | 0.58 | 0.32 | 0.51 | ||
| F1 | 0.55 | 0.61 | 0.58 | 0.41 | 0.59 | 0.33 | 0.51 | ||
| TF-IDF + SVM (Unstructured data only) | Precision | 0.54 | 0.74 | 0.55 | 0.38 | 0.59 | 0.43 | 0.54 | 53.34 |
| Recall | 0.62 | 0.55 | 0.66 | 0.49 | 0.54 | 0.32 | 0.53 | ||
| F1 | 0.58 | 0.63 | 0.60 | 0.43 | 0.57 | 0.36 | 0.53 | ||
| CNN (Unstructured data only) | Precision | 0.51 | 0.74 | 0.56 | 0.40 | 0.47 | 0.43 | 0.52 | 52.10 |
| Recall | 0.58 | 0.67 | 0.57 | 0.42 | 0.54 | 0.33 | 0.52 | ||
| F1 | 0.54 | 0.71 | 0.57 | 0.41 | 0.51 | 0.38 | 0.52 | ||
| BERT (Unstructured data only) | Precision | 0.51 | 0.78 | 0.67 | 0.42 | 0.63 | 0.32 | 0.56 | 54.33 |
| Recall | 0.61 | 0.60 | 0.56 | 0.59 | 0.59 | 0.30 | 0.54 | ||
| F1 | 0.56 | 0.67 | 0.61 | 0.49 | 0.61 | 0.31 | 0.54 | ||
| GPT-2.0 (Unstructured data only) | Precision | 0.53 | 0.72 | 0.62 | 0.22 | 0.60 | 0.52 | 0.54 | 56.40 |
| Recall | 0.48 | 0.63 | 0.57 | 0.10 | 0.71 | 0.58 | 0.51 | ||
| F1 | 0.50 | 0.67 | 0.59 | 0.14 | 0.65 | 0.55 | 0.52 | ||
| GPT-3.0 (Unstructured + structured data) | Precision | 0.71 | 0.93 | 0.74 | 0.78 | 0.87 | 0.40 | 0.74 | 67.22 |
| Recall | 0.71 | 0.83 | 0.64 | 0.62 | 0.45 | 0.80 | 0.68 | ||
| F1 | 0.71 | 0.88 | 0.68 | 0.69 | 0.60 | 0.54 | 0.68 | ||
| GPT-3.0 (Unstructured data only) | Precision | 0.80 | 0.91 | 0.88 | 0.74 | 0.84 | 0.76 | 0.82 | 82.33 |
| Recall | 0.79 | 0.87 | 0.82 | 0.83 | 0.88 | 0.64 | 0.81 | ||
| F1 | 0.80 | 0.89 | 0.85 | 0.79 | 0.86 | 0.75 | 0.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, B.; Kim, J.; Park, S.; Ahn, C.R.; Oh, T. Harnessing Generative Pre-Trained Transformers for Construction Accident Prediction with Saliency Visualization. Appl. Sci. 2024, 14, 664. https://doi.org/10.3390/app14020664
Yoo B, Kim J, Park S, Ahn CR, Oh T. Harnessing Generative Pre-Trained Transformers for Construction Accident Prediction with Saliency Visualization. Applied Sciences. 2024; 14(2):664. https://doi.org/10.3390/app14020664
Chicago/Turabian StyleYoo, Byunghee, Jinwoo Kim, Seongeun Park, Changbum R. Ahn, and Taekeun Oh. 2024. "Harnessing Generative Pre-Trained Transformers for Construction Accident Prediction with Saliency Visualization" Applied Sciences 14, no. 2: 664. https://doi.org/10.3390/app14020664
APA StyleYoo, B., Kim, J., Park, S., Ahn, C. R., & Oh, T. (2024). Harnessing Generative Pre-Trained Transformers for Construction Accident Prediction with Saliency Visualization. Applied Sciences, 14(2), 664. https://doi.org/10.3390/app14020664