


Transfer Learning in Multimodal Sunflower Drought Stress Detection

 , , ,
, , ,  and
and 
Abstract
1. Introduction
- Introducing a novel application of an image dataset for sunflower drought stress prediction, consisting of 584 images of sunflower roots and shoots;
- Using shoot, root parts, and rhizotron images to provide a comprehensive understanding of sunflower responses to drought;
- Applying targeted data augmentation to address the issues with limited and imbalanced datasets to improve model performance;
- Setting up a novel pipeline for sunflower drought stress detection based on a CNN and TL that combines multimodal images and customized augmentation strategies.
2. Materials and Methods
2.1. Experimental Framework
2.2. Planting Setup
2.3. Dataset
Data Augmentation Strategies
- Horizontal flipping;
- Rotation range: ±20 degrees;
- Width shift range: ±20%;
- Height shift range: ±20%;
- Zoom range: ±20%;
- Brightness range: 0.1–0.9.
2.4. Convolutional Neural Networks and Transfer Learning
2.5. Evaluation Metrics
- TPs (true positives) are the number of instances correctly predicted as positive;
- FPs (false positives) are the number of instances incorrectly predicted as positive when they are actually negative;
- TNs (true negatives) are the number of instances correctly predicted as negative;
- FNs (false negatives) are the number of instances incorrectly predicted as negative when they are actually positive.
3. Results and Discussion
3.1. Configuration of CNN Models
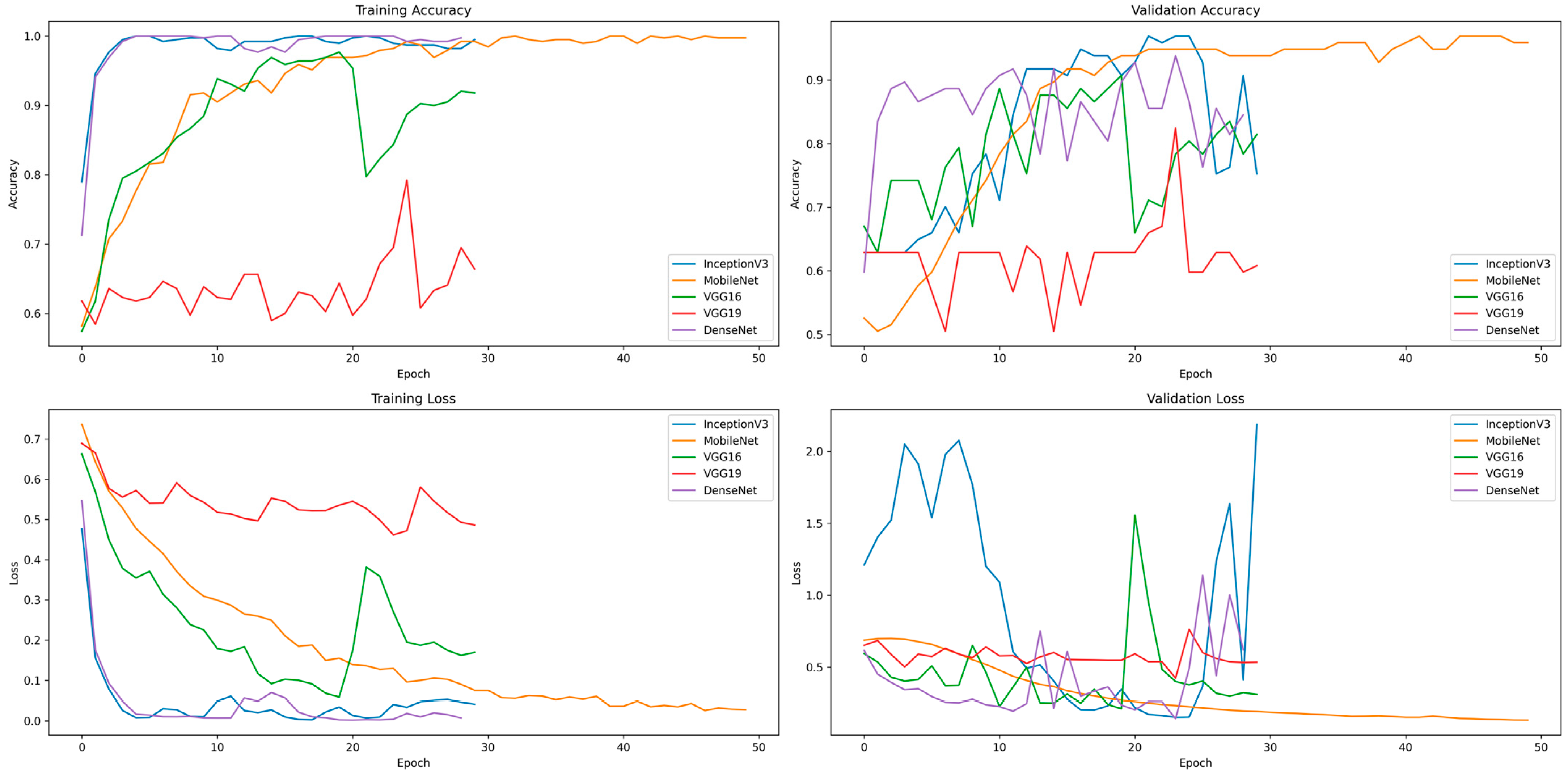
3.2. Initial Experiments Results
3.3. MobileNet Augmented Experiments Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agriculture|UN World Water Development Report. 2022. Available online: https://www.unesco.org/reports/wwdr/2022/en/agriculture (accessed on 17 April 2024).
- Hussain, M.; Farooq, S.; Hasan, W.; Ul-Allah, S.; Tanveer, M.; Farooq, M.; Nawaz, A. Drought Stress in Sunflower: Physiological Effects and Its Management through Breeding and Agronomic Alternatives. Agric. Water Manag. 2018, 201, 152–166. [Google Scholar] [CrossRef]
- Safdar, M.; Shahid, M.A.; Sarwar, A.; Rasul, F.; Majeed, M.D.; Sabir, R.M. Crop Water Stress Detection Using Remote Sensing Techniques. Environ. Sci. Proc. 2023, 25, 20. [Google Scholar] [CrossRef]
- Kim, Y.; Evans, R.G.; Iversen, W.M. Remote Sensing and Control of an Irrigation System Using a Distributed Wireless Sensor Network. IEEE Trans. Instrum. Meas. 2008, 57, 1379–1387. [Google Scholar] [CrossRef]
- Talaviya, T.; Shah, D.; Patel, N.; Yagnik, H.; Shah, M. Implementation of Artificial Intelligence in Agriculture for Optimisation of Irrigation and Application of Pesticides and Herbicides. Artif. Intell. Agric. 2020, 4, 58–73. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop Yield Prediction Using Machine Learning: A Systematic Literature Review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Cvejić, S.; Hrnjaković, O.; Jocković, M.; Kupusinac, A.; Doroslovački, K.; Gvozdenac, S.; Jocić, S.; Miladinović, D. Oil Yield Prediction for Sunflower Hybrid Selection Using Different Machine Learning Algorithms. Sci. Rep. 2023, 13, 17611. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, L.; Wu, H.; Li, L. Advanced Agricultural Disease Image Recognition Technologies: A Review. Inf. Process. Agric. 2022, 9, 48–59. [Google Scholar] [CrossRef]
- Farooq, M.S.; Riaz, S.; Abid, A.; Umer, T.; Zikria, Y.B. Role of IoT Technology in Agriculture: A Systematic Literature Review. Electronics 2020, 9, 319. [Google Scholar] [CrossRef]
- Wolfert, S.; Ge, L.; Verdouw, C.; Bogaardt, M.-J. Big Data in Smart Farming—A Review. Agric. Syst. 2017, 153, 69–80. [Google Scholar] [CrossRef]
- Maffezzoli, F.; Ardolino, M.; Bacchetti, A.; Perona, M.; Renga, F. Agriculture 4.0: A Systematic Literature Review on the Paradigm, Technologies and Benefits. Futures 2022, 142, 102998. [Google Scholar] [CrossRef]
- Araújo, S.O.; Peres, R.S.; Barata, J.; Lidon, F.; Ramalho, J.C. Characterising the Agriculture 4.0 Landscape—Emerging Trends, Challenges and Opportunities. Agronomy 2021, 11, 667. [Google Scholar] [CrossRef]
- de Oliveira, R.C.; Silva, R.D.d.S.e. Artificial Intelligence in Agriculture: Benefits, Challenges, and Trends. Appl. Sci. 2023, 13, 7405. [Google Scholar] [CrossRef]
- Chandel, N.S.; Chakraborty, S.K.; Rajwade, Y.A.; Dubey, K.; Tiwari, M.K.; Jat, D. Identifying Crop Water Stress Using Deep Learning Models. Neural Comput. Appl. 2021, 33, 5353–5367. [Google Scholar] [CrossRef]
- Barradas, A.; Correia, P.M.P.; Silva, S.; Mariano, P.; Pires, M.C.; Matos, A.R.; Da Silva, A.B.; Marques Da Silva, J. Comparing Machine Learning Methods for Classifying Plant Drought Stress from Leaf Reflectance Spectra in Arabidopsis thaliana. Appl. Sci. 2021, 11, 6392. [Google Scholar] [CrossRef]
- Virnodkar, S.S.; Pachghare, V.K.; Patil, V.C.; Jha, S.K. Remote Sensing and Machine Learning for Crop Water Stress Determination in Various Crops: A Critical Review. Precis. Agric. 2020, 21, 1121–1155. [Google Scholar] [CrossRef]
- An, J.; Li, W.; Li, M.; Cui, S.; Yue, H. Identification and Classification of Maize Drought Stress Using Deep Convolutional Neural Network. Symmetry 2019, 11, 256. [Google Scholar] [CrossRef]
- Al Sahili, Z.; Awad, M. The Power of Transfer Learning in Agricultural Applications: AgriNet. Front. Plant Sci. 2022, 13, 992700. [Google Scholar] [CrossRef]
- Halevy, A.; Norvig, P.; Pereira, F. The Unreasonable Effectiveness of Data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Madsen, S.L.; Mathiassen, S.K.; Dyrmann, M.; Laursen, M.S.; Paz, L.-C.; Jørgensen, R.N. Open Plant Phenotype Database of Common Weeds in Denmark. Remote Sens. 2020, 12, 1246. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A New Lightweight Deep Neural Network for Surface Scratch Detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef]
- Thapa, R.; Zhang, K.; Snavely, N.; Belongie, S.; Khan, A. The Plant Pathology Challenge 2020 Data Set to Classify Foliar Disease of Apples. Appl. Plant Sci. 2020, 8, e11390. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Zheng, L.; Chen, X.; Zabawa, L.; Zhang, M.; Wang, M. Transfer Learning from Synthetic In-Vitro Soybean Pods Dataset for In-Situ Segmentation of On-Branch Soybean Pods. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1666–1675. [Google Scholar]
- Kamarudin, M.H.; Ismail, Z.H.; Saidi, N.B. Deep Learning Sensor Fusion in Plant Water Stress Assessment: A Comprehensive Review. Appl. Sci. 2021, 11, 1403. [Google Scholar] [CrossRef]
- Škorić, D. Sunflower Breeding for Resistance to Abiotic and Biotic Stresses. In Abiotic and Biotic Stress in Plants—Recent Advances and Future Perspectives; InTech: Vienna, Austria, 2016; ISBN 978-953-51-2250-0. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 27 April 2024).
- A Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations. 2017. Available online: https://browse.arxiv.org/pdf/1712.02779v2 (accessed on 22 April 2024).
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Han, J.; Fang, P.; Li, W.; Hong, J.; Armin, M.A.; Reid, I.; Petersson, L.; Li, H. You Only Cut Once: Boosting Data Augmentation with a Single Cut. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 15 June 2022; pp. 8196–8212. [Google Scholar]
- Ben Tamou, A.; Benzinou, A.; Nasreddine, K. Targeted Data Augmentation and Hierarchical Classification with Deep Learning for Fish Species Identification in Underwater Images. J. Imaging 2022, 8, 214. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A Review of the Use of Convolutional Neural Networks in Agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Alfarhood, S.; Alrayeh, A.; Safran, M.; Alfarhood, M.; Che, D. Image-Based Arabian Camel Breed Classification Using Transfer Learning on CNNs. Appl. Sci. 2023, 13, 8192. [Google Scholar] [CrossRef]
- TensorFlow Hub. Available online: https://www.tensorflow.org/hub (accessed on 26 April 2024).
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Miao, J.; Zhu, W. Precision–Recall Curve (PRC) Classification Trees. Evol. Intell. 2022, 15, 1545–1569. [Google Scholar] [CrossRef]
- Riyanto, S.; Sitanggang, I.S.; Djatna, T.; Atikah, T.D. Comparative Analysis Using Various Performance Metrics in Imbalanced Data for Multi-Class Text Classification. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 1082–1090. [Google Scholar] [CrossRef]
- Gao, Z.; Luo, Z.; Zhang, W.; Lv, Z.; Xu, Y. Deep Learning Application in Plant Stress Imaging: A Review. AgriEngineering 2020, 2, 430–446. [Google Scholar] [CrossRef]
- Zubler, A.V.; Yoon, J.-Y. Proximal Methods for Plant Stress Detection Using Optical Sensors and Machine Learning. Biosensors 2020, 10, 193. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Model | Number of Epochs | Learning Rate |
|---|---|---|
| VGG16 | 50 | 0.00001 |
| VGG19 | 30 | 0.0001 |
| DenseNet | 30 | 0.0001 |
| Inception V3 | 30 | 0.0001 |
| MobileNet | 30 | 0.0001 |
| CNN Model | Color | Accuracy | Precision | Recall | F1 Score | Test Loss | Average Epoch Time (s) |
|---|---|---|---|---|---|---|---|
| VGG16 | Original | 0.82 | 0.81 | 0.86 | 0.84 | 0.82 | 250.81 |
| Grayscale | 0.65 | 0.62 | 0.84 | 0.72 | 0.65 | 233.69 | |
| VGG19 | Original | 0.66 | 0.91 | 0.39 | 0.55 | 0.66 | 306.31 |
| Grayscale | 0.67 | 0.81 | 0.49 | 0.61 | 0.67 | 282.62 | |
| DenseNet | Original | 0.85 | 0.78 | 1.00 | 0.87 | 0.85 | 103.00 |
| Grayscale | 0.93 | 0.98 | 0.88 | 0.93 | 0.93 | 90.91 | |
| Inception V3 | Original | 0.85 | 0.78 | 1.00 | 0.87 | 1.61 | 69.16 |
| Grayscale | 0.93 | 0.94 | 0.92 | 0.93 | 0.13 | 51.28 | |
| MobileNet | Original | 0.91 | 0.92 | 0.90 | 0.91 | 0.19 | 56.60 |
| Grayscale | 0.89 | 0.88 | 0.90 | 0.89 | 0.22 | 33.29 |
| Color | Data Augmentation | Accuracy | Precision | Recall | F1 Score | Test Loss |
|---|---|---|---|---|---|---|
| Original | Without augmentation | 0.91 | 0.92 | 0.90 | 0.91 | 0.19 |
| Standard augmentation | 0.73 | 0.88 | 0.57 | 0.69 | 0.58 | |
| Targeted augmentation | 0.92 | 0.98 | 0.86 | 0.92 | 0.21 | |
| Grayscale | Without augmentation | 0.89 | 0.88 | 0.90 | 0.89 | 0.22 |
| Standard augmentation | 0.74 | 0.86 | 0.61 | 0.71 | 0.47 | |
| Targeted augmentation | 0.95 | 1.00 | 0.90 | 0.95 | 0.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lazić, O.; Cvejić, S.; Dedić, B.; Kupusinac, A.; Jocić, S.; Miladinović, D. Transfer Learning in Multimodal Sunflower Drought Stress Detection. Appl. Sci. 2024, 14, 6034. https://doi.org/10.3390/app14146034
Lazić O, Cvejić S, Dedić B, Kupusinac A, Jocić S, Miladinović D. Transfer Learning in Multimodal Sunflower Drought Stress Detection. Applied Sciences. 2024; 14(14):6034. https://doi.org/10.3390/app14146034
Chicago/Turabian StyleLazić, Olivera, Sandra Cvejić, Boško Dedić, Aleksandar Kupusinac, Siniša Jocić, and Dragana Miladinović. 2024. "Transfer Learning in Multimodal Sunflower Drought Stress Detection" Applied Sciences 14, no. 14: 6034. https://doi.org/10.3390/app14146034
APA StyleLazić, O., Cvejić, S., Dedić, B., Kupusinac, A., Jocić, S., & Miladinović, D. (2024). Transfer Learning in Multimodal Sunflower Drought Stress Detection. Applied Sciences, 14(14), 6034. https://doi.org/10.3390/app14146034