1. Introduction
In recent years, computer security issues, such as cyberattacks, data intrusions, and other forms of malicious activities, have increased significantly. This trend is influenced by a number of factors, including a growing dependence on technology, an evolving threat landscape, human error, an absence of cybersecurity awareness, increased connectivity, etc. [
1]. Phishing is a type of cyber attack in which attackers attempt to trick users into disclosing sensitive information, such as usernames, passwords, and credit card details, by posing as a trustworthy entity [
2]. Numerous methods, including email, social media, instant messaging, and SMS, can be used to carry out phishing attacks. These attacks are designed to deceive users into revealing sensitive information, such as login credentials, credit card information, or other personal data, which can then be used for fraudulent purposes. A successful phishing attack can have severe consequences, including financial losses, identity theft, and reputation damage. In addition to all this, phishing attacks can be carried out to deliver malware or ransomware attacks.
The Anti-Phishing Working Group (APWG) conducted research for the 2nd Quarter 2023 Phishing Activity Trends Report, focusing on the increasing rate of phishing attacks [
3]. The findings indicate a notable increase over the past four years, with a growth rate exceeding 150% annually, as illustrated in
Figure 1. According to Proofpoint’s 2023 State of the Phish Report—Phishing Stats and Trends, 84% of the organizations experienced at least one successful phishing attack. These successful attacks mainly target the private information of companies, leading to increasing financial losses [
4].
As seen from this, phishing is still one of the most prevalent and difficult-to-prevent attack types, as attackers constantly change their methods and find ways to circumnavigate security measures. However, there are methods to reduce the risk of phishing attacks, such as educating users and implementing technical controls such as spam filters, URL-based phishing detection [
5], content-based phishing detection [
6], two-factor authentication [
7], etc. The URL-based phishing detection system, which analyzes features derived from URLs such as URL length, use of HTTPS, and domain age, are highly effective in identifying and preventing phishing attacks [
8]. This system quickly analyzes and recognizes patterns, making it a popular choice for detecting deceptive URLs that appear legitimate but direct users to fraudulent websites. In recent years, Machine Learning (ML)-based algorithms have gained popularity as a means of protecting computer systems against phishing attacks by automatically identifying malicious traffic. Phishing attacks are difficult to detect and prevent due to the use of sophisticated deception techniques by attackers and the variety of communication channels [
9].
Large datasets containing legitimate and phishing can be analyzed using ML algorithms to identify distinguishing patterns and characteristics. These algorithms can use related patterns to identify potential phishing attacks, even if they have never been seen before. Over time, ML can also improve the accuracy and efficiency of phishing detection systems. As new phishing attacks are identified, ML algorithms can update their models to detect future attacks of similar nature.
Big data lead to longer training times in ML algorithms due to the increased computational costs associated with processing larger datasets. Not only the number of samples in the dataset but also its dimensionality affects the time. The high dimensionality of the dataset extends the inference time of ML systems, particularly because of the increased cost of feature extraction. The inference time is vital in real-time phishing detection models because it directly influences users and impairs the run-time performance of the deployed ML models. To deal with this problem, feature reduction, also known as feature selection, is preferred to decrease the computational cost of the ML inference by utilizing a subset of all features. By employing the feature selection methods, it is expected to improve the model’s performance metrics, such as accuracy, while reducing the model’s complexity and computational cost. Therefore, feature selections are generally preferred to increase the efficiency of ML-based systems.
There are several commonly used feature selection algorithms in the literature, such as Recursive Feature Elimination (RFE) [
10], Principal Component Analysis (PCA) [
11], selectKBest [
12], lasso [
13], tree-based methods [
14], Evolutionary Algorithms (EAs), etc. EAs [
15] are a family of optimization techniques that draw inspiration from the principles of natural evolution. These algorithms use a population of possible solutions that change over time through a process of selection, mutation, and recombination to find an optimal or near-optimal solution to a problem. They are preferred in many optimization problems, just as they were in feature selection problems, because they are robust, flexible, can handle non-linear and non-differentiable problems, can work in parallel, or can optimize for more than one goal.
Genetic Algorithms (GAs) are evolutionary optimization techniques that try to find the best solution to a problem by imitating how natural selection works. GAs have been used to solve a wide range of optimization problems, such as feature selection, with great success. In this concept, our main challenge fits in a multi-objective optimization problem by increasing the detection accuracy and recall value of the trained system, while decreasing the processing time by minimizing the number of features to use.
The use of GAs for feature selection involves encoding the features into chromosomes and then applying genetic operators such as selection, crossover, and mutation to evolve a population of candidate solutions. Each solution is judged on how well it works with a given objective function, and the process is repeated until a good solution is found.
This paper aims to provide a comprehensive understanding of GA-based feature selection and its potential to improve the performance of ML models by selecting the optimal subset of features and reducing the dimensions of the data. By presenting the latest research in this area, we hope to inspire future work and encourage researchers to explore this promising approach in their applications.
In order to conduct a thorough and efficient systematic study, it is imperative to establish well-defined research questions. The research questions formulated for the present investigation are outlined below:
RQ 1: How can an evolutionary approach(genetic algorithm) be used during the feature selection of machine learning models in the URL-based phishing detection system?
RQ 2: What are the effects of a genetic-algorithm-based feature selection strategy on machine learning models?
RQ 3: What are the strengths and weaknesses of the genetic-algorithm-based feature selection strategy compared to greedy-based feature selection algorithms?
The rest of the paper is organized as follows: In
Section 2, related works such as phishing detection, ML, and GA-based systems are detailed by showing the related works in the literature.
Section 3 explains the design details and algorithms of the proposed solution for a genetic-algorithm-based feature selection algorithm in a phishing detection system. The empirical results of the proposed system are analyzed by comparison with other feature selection models and are also illustrated in
Section 5 after explaining the experimental setup in
Section 4. Finally, after discussing the crucial aspects of the genetic-algorithm-based feature selection method in
Section 6, the paper is concluded in
Section 7 including future work that can be conducted in related areas.
3. Methodology
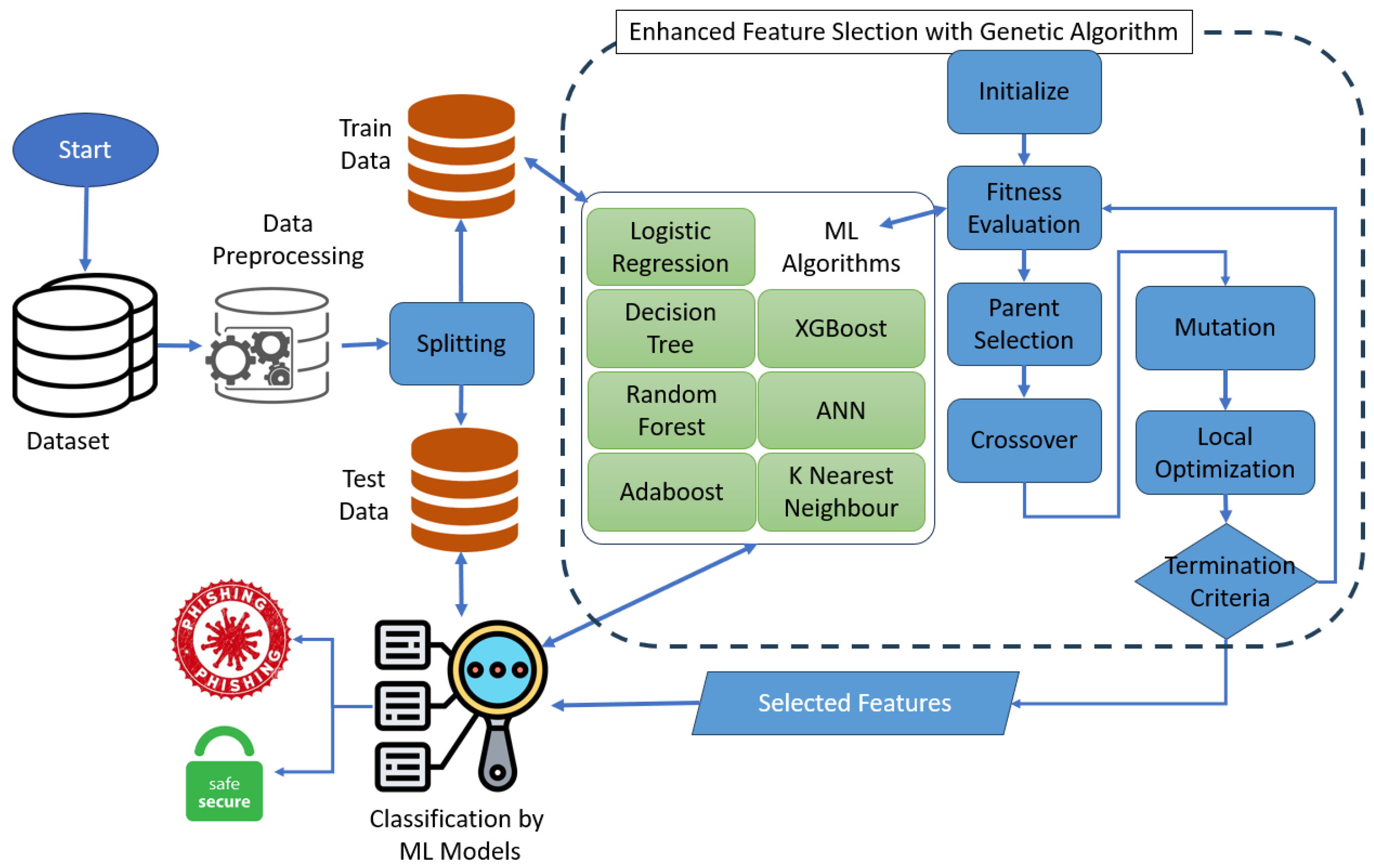
In this paper, we aim to develop a phishing detection system by selecting most significant URL-based features with the help of a genetic algorithm, as mentioned in the flow depicted in
Figure 2. Feature selection is a critical step in the ML pipeline for both the model’s accuracy and run-time measures such as inference time, i.e., prediction duration of the model. Useless features negatively affect the accuracy of the model and add unnecessary complexity into the model. Moreover, fewer features mean less total feature extraction time, which is critical during prediction in the production environment. Taking into account these aspects, we propose a GAFS strategy which aims to improve the performance scores of phishing detection while reducing the total number of selected features.
3.1. Genetic-Algorithm-Based Flow
Finding the best URL-based feature subset among existing features in terms of ML performance measures and minimizing the model’s prediction time are objectives of an optimization problem, and searching for all possible solutions is an NP-hard problem. GA is one of the most successful ways of dealing with this type of problem. We decided to use it and adapt our problem into a GA skeleton. Furthermore, we improved it by adding a local optimization step to achieve optimal results in earlier stages of the evolutionary process carried out by the GA. The general flow of the proposed method and GA steps are given in Algorithm 1.
| Algorithm 1 Genetic-Algorithm-based Flow |
- 1:
c represents individual chromosome - 2:
fv represents fitness value - 3:
parameters: pop_size, generation, mutation_rate - 4:
Create initial population using pop_size (avoiding duplicates) - 5:
Calculate fv for each c and store them in local/global tables - 6:
Transfer best c to the next generation (elitism) - 7:
for to generation do - 8:
Select two parent c (tournament k = 4) - 9:
Crossover the parents and generate a child c (uniform crossover) - 10:
Mutate the child c based on the mutation_rate (bit flip) - 11:
Append the child c to the next generation - 12:
Apply local optimization to randomly selected newly generated c - 13:
Calculate fv and update the tables - 14:
end for - 15:
return the best c of the last generation
|
3.2. Chromosome
A chromosome serves as a representation of a solution in optimization problems, drawing inspiration from the sequence of genes. In this study, each gene corresponds to a URL-based feature, and its order remains fixed throughout the evolutionary process. The chromosome structure of the proposed model is represented as a binary array with a length of 73, corresponding to the number of URL-based features in our dataset. Each value in the chromosome can be either 1 or 0. A value of 1 indicates the inclusion of the corresponding feature in the training of machine learning models, while a value of 0 indicates its exclusion. For instance, if 10 genes are marked as 1, only these 10 features will be used to train ML-based phishing detection systems, the other features being reduced or extracted.
3.3. Initialization
Initialization in a GA is the process of creating an initial population of potential solutions (individuals or chromosomes) for the optimization problem at hand. The quality and diversity of the initial population can significantly affect the performance and convergence of GA. In some cases, more sophisticated initialization methods, such as using domain-specific knowledge or heuristics, may be employed to improve the performance of GA. In our algorithm, each chromosome is randomly generated while preventing duplicates. This randomness helps us to explore a diverse range of solutions from the beginning. A chromosome must contain at least one “1” to be a valid solution; i.e., it must have at least one feature to train the ML model.
3.4. Fitness Function
The fitness function is a crucial concept that plays a central role in the optimization process. A GA is an optimization algorithm inspired by the process of natural selection and is used to find solutions to complex problems. The fitness function is a key component that evaluates the quality of potential solutions, guiding the algorithm towards better solutions over successive generations.
The fitness function essentially serves as a guide for the algorithm by quantifying how well each potential solution aligns with the desired outcome. The design of an effective fitness function is crucial for the success of a GA. It should accurately reflect the problem’s objectives and constraints, providing a clear measure of solution quality. Adjusting the fitness function allows the algorithm to adapt to different domains of problems and optimization goals. The choice of performance metrics depends on the nature of the problem and the goals of the model. While accuracy is a commonly used metric, there are situations where “recall” may be preferred, especially in scenarios where certain types of errors are more critical than others. Detection of positive classes, i.e., phishing attacks, is more critical than overall accuracy, and the accuracy even can be misleading in imbalanced datasets. In this direction, we ovtain the “Recall” performance metric as the fitness value of the model in the proposed algorithm. All related calculations were conducted accordingly.
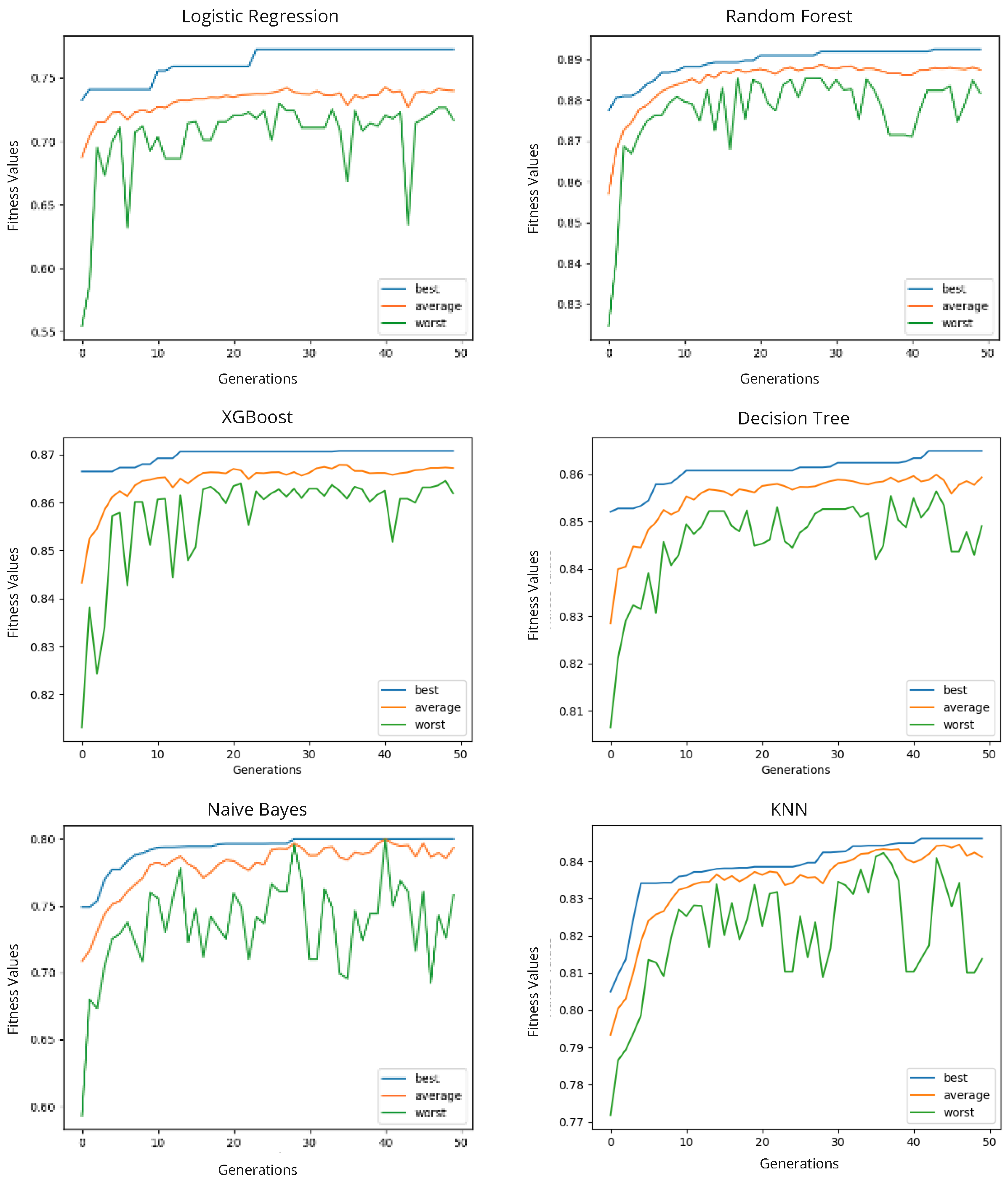
Chromosomes are evaluated according to their fitness values, which indicate how good they are for phishing detection. Fitness values correspond to recall scores that are calculated after training the ML models with selected features based on the chromosomes. In other words, an ML model needs to be trained and evaluated once for each chromosome to obtain the fitness value. The training processes differ due to the ML classifiers. For instance, while logistic regression’s training time is approximately 1 s with 87 thousand URLs, random forest’s training time is over 80 s in the same test machine based on our observations. The total run-time of the evolutionary progress can be too long since the fitness values of all chromosomes of the population need to be calculated for each generation. To reduce this time, we stored the fitness values of each chromosome in a hash table with their keys, which are produced using binary arrays. Then, before calculating the fitness value of a chromosome, we checked the key of the chromosome in the fitness values table so that we prevented repeated calculations of the fitness value.
3.5. Selection Operator
Selection is a crucial step in GA that determines the parent chromosomes, which will be used to produce the offspring chromosome. We prefer the tournament selection, which is a flexible and effective model for parent selection in GA and it includes a high level of randomness during selection.
Random chromosomes are selected according to the tournament size parameter (which is selected as 4) in the proposed model parameter, and after competing them, the best one with respect to their fitness values is selected as the parent chromosome. The same process is repeated for the second parent chromosome. For each offspring generation process, two different chromosomes are selected from the existing population.
3.6. Crossover Operator
The crossover operator generates an offspring solution based on the selected chromosomes from the previous generation. Different crossover techniques are available in the literature, such as “one-point crossover”, “two-point crossover”, and “uniform crossover”. We decided to use “uniform crossover” since each gene, i.e., each feature, is independent, and there are no sequential relationships between the genes. A mask with the same size of the parent chromosome is randomly generated for each crossover operation, and “1” means that the related gene of the first parent will be transferred to the offspring, while “0” points out the second parent, as shown in
Figure 3.
3.7. Mutation Operator
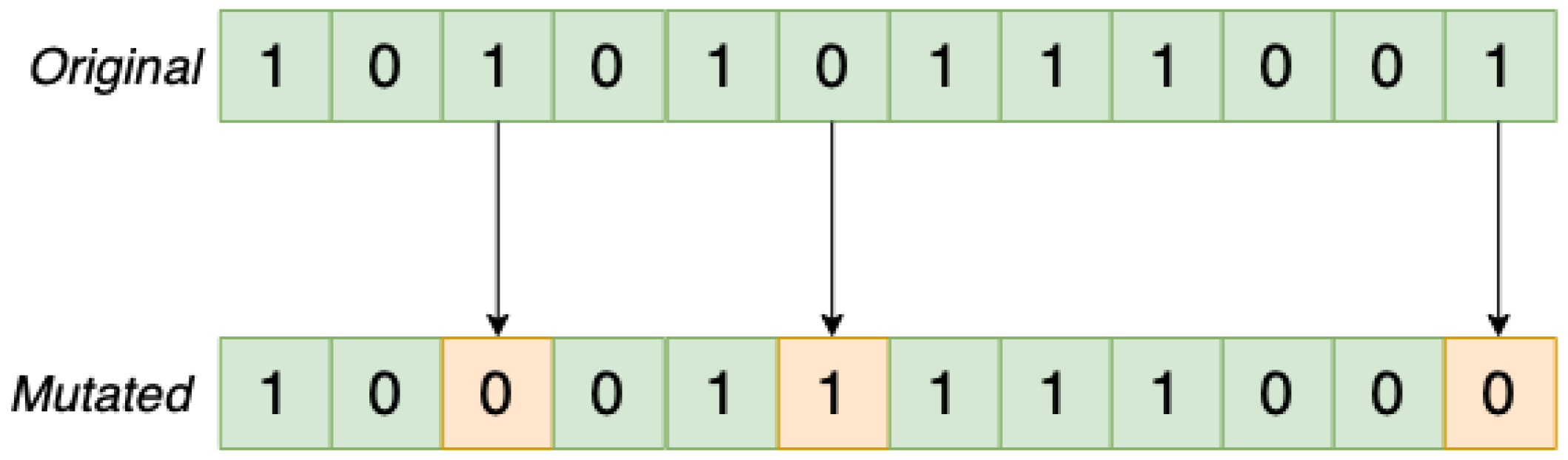
Mutation operators are inspired by the mutation of genes in nature during evolutionary progress, and they increase solution diversity by adding randomness, which helps to pass the local optima. We used “Bit flip mutation” to reach global optimal solutions in which the efficiency depends on the mutation rate.
For example, “0.1” means approximately 10% of each generation will be mutated. Another parameter is flip bit mutation rate, determining the number of genes that will be mutated. “0.1” means 10% of a chromosome, e.g., 8, since the total number of genes in our study is 73, will be flipped. An example is shown in
Figure 4.
3.8. Local Optimization
To quickly achieve better solutions and improve the quality of the solutions, local optimization can be embedded into a GA flow. It also enhances the exploration process by fine-tuning search space and improving individual solutions. We design a local optimization that checks the contributions of genes one by one and updates the existing chromosome in such a way as to increase the performance of ML models.
First, the selected chromosome’s fitness value is obtained. Second, random genes of the chromosome are selected according to a rate, i.e., a parameter. Then, each selected gene is flipped one by one. After each modification, a new fitness value of the modified chromosome is calculated. If the change positively affects performance, we save the modified chromosome. Otherwise, we roll back the modification and cancel the flip operation for that specific gene. Complete steps of the local optimization process for one chromosome are given in Algorithm 2. Since this process increases the cost of overall flow, we did not apply it to all chromosomes but to randomly selected chromosomes based on a parameter.
| Algorithm 2 Local Optimization |
- 1:
c represents a chromosome - 2:
represents the fitness value of the c - 3:
for gene in c do - 4:
Flip the gene - 5:
Calculate of the updated c - 6:
if gene == 0 then - 7:
if new old then - 8:
gene = 1 - 9:
end if - 10:
else ▹ gene == 1 - 11:
if new old then - 12:
gene = 0 - 13:
end if - 14:
end if - 15:
end for - 16:
return the updated c
|
3.9. Elitism
In the context of the GA, elitism refers to a strategy in which the best individuals of the current generation are directly passed on to the next generation without undergoing typical genetic operators, such as crossover and mutation. The goal of elitism is to preserve the most fit solutions in the population, ensuring that the best solutions found so far are not lost in the evolution process. Elitism helps maintain a certain level of diversity in the population while ensuring that the best solutions discovered so far continue to contribute to the evolving population. This can be particularly useful in preventing premature convergence to suboptimal solutions and speeding up the convergence towards a high-quality solution.
3.10. Termination Criteria
Termination refers to the conditions that determine when the algorithm should stop its search and return a solution. GA is a type of optimization algorithm inspired by the process of natural selection and genetics. They are used to find approximate solutions to optimization and search problems. Termination criteria are essential to prevent the algorithm from running indefinitely and to define when the algorithm has achieved a satisfactory solution. The choice of termination criteria depends on the specific problem to be solved and the available resources. Common termination criteria for GA are maximum number of generations, convergence, fitness threshold, sufficient solution, computational time limit, user-defined criteria, etc.
It is common to use a combination of these criteria to ensure the termination of the algorithm under various circumstances. Determining appropriate termination criteria is crucial to balance the trade-off between finding a sufficiently good solution and avoiding unnecessary computational costs. In the proposed model, we use maximum number of generations.
4. Experimental Setup
Phishing attacks are a major cybersecurity concern due to their widespread use (similar to the DoS, DDos and man-in-the-middle attacks) and high success rate in obtaining sensitive information through social engineering techniques. These attacks exploit human behavior, making them effective despite advanced security measures. Phishing often serves as an entry point for further malicious activities, such as data breaches and ransomware. The financial impact of phishing includes direct theft, fraudulent transactions, and significant mitigation costs. Organizations that fall victim to phishing can suffer severe reputational damage and face regulatory compliance issues, including legal penalties. In addition, attackers frequently exploit current events to make phishing attempts more convincing, increasing their likelihood of success. Therefore, to detect these attacks, we set a machine-learning-based detection system by using a pre-collected URL dataset, which is defined as high-risk URL dataset, and the performance metrics of the proposed models are detailed in this section.
Seven ML algorithms were selected and experiments were carried out within the scope of the study. Among the most traditional ML algorithms, Logistic Regression (LR), K-Nearest Neighborhood (KNN), Naive Bayes (NB), and Decision Tree (DT) were selected for the experiments. In addition, XGBoost (XGB) and Random Forest (RF) algorithms, which perform ensemble learning, and Artificial Neural Network (ANN) algorithm as a neural network were also used in the experiments.
4.1. Dataset
As of December 2023, there are 1.11 billion websites worldwide, of which 201 million are active [
42]. New ones are added to this number every day, some of which are used for phishing attacks. The process of labeling these phishing websites requires a lot of work. There are specific organizations that work on this process, such as
https://phishtank.com/ accessed on 20 May 2024.
The PhishTank.com website, which works to detect and list phishing attacks, works on the basis of tagging URLs by users. Internet users access the PhishTank.com website to query suspicious websites, which members then analyze and tag as “Phishing” or “Legitimate”. The final result of the classification is based on the number of tags. Those websites labeled as “Phishing” or “Legitimate” are added to the list under the respective label. In this way, the black and white lists continue to grow with each passing day of labeling.
This PhishTank.com blacklist is one of the most widely used sources for this and other datasets in the literature, which is classified as phishing on Phishtank.com, can also be found in the datasets in the literature. However, unlike the datasets in the literature, the legitimate websites in this dataset are not obtained from reliable whitelists on the Internet. These websites are also taken from Phishtank.com. For example, in the legitimate class of the dataset, instead of a trusted website such as “
www.youtube.com” accessed on 20 May 2024 , there are websites with more complex URLs.
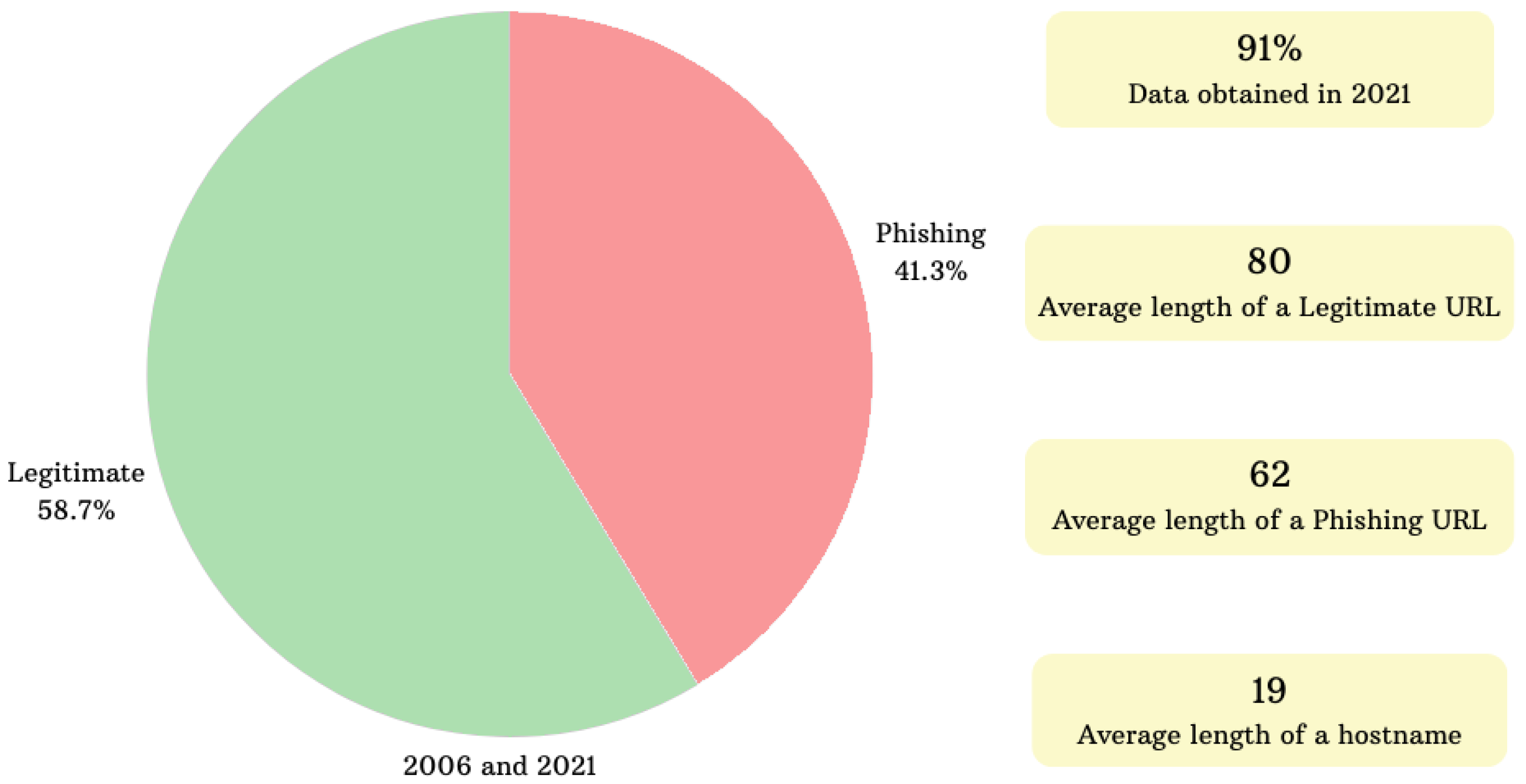
The dataset used in the hybrid phishing detection model, proposed by Korkmaz et al. [
43], consists of 51,316 legitimate websites and 36,173 phishing websites listed between 2006 and 2021. The highlights of this dataset are shown in
Figure 5. This dataset has two main characteristics. First, the data belonging to the legitimate class are websites that members think they are phishing but are legitimate. Therefore, websites belonging to the legitimate class are labeled as risky by us. We have utilized this “High-Risk URL and Content Dataset” in our system because it does not include exact phishing or clean URLs, nor can the URLs be found in white lists such as “
www.oracle.com” or “
www.nytimes.com” accessed on 20 May 2024. All web pages have a suspicious (unknown) status on the PhishTank website. Although relatively lower scores are expected, the performance metrics are considered more realistic in real-world scenarios.
4.2. Genetic Algorithm Setting
The impact of predetermined parameters on the performance of the genetic algorithm is of paramount importance as these parameters significantly influence both the resultant outcome and the corresponding computational time required for its attainment. As a result of our preliminary experiments, we decided to use the setting specified in
Table 1.
4.3. Performance Assessment Methods and Testing Parameters
ML models necessitate evaluation through a range of criteria as reliance on a singular metric is inadequate to ensure reliable outcomes. Conventional metrics encompass accuracy, recall, precision, and F-1 score, while in scenarios featuring an imbalanced dataset, the average precision score assumes significance as an indicator of model performance concerning minority dataset. Therefore, we include these metrics in our testing parameters.
The present study aims to identify the optimal set of features through the utilization of a GA-driven optimization technique complemented by local optimization. This selection process not only enhances performance metrics, including accuracy and recall, but also mitigates inference time by significantly reducing the number of features employed. Since each feature extraction operation incurs a computational cost, a reduction in feature usage entails a corresponding reduction in cost. The experimental phase incorporates a carefully monitor of cost fluctuations in relation to the chosen feature list, thereby integrating these changes into the evaluation of performance results.
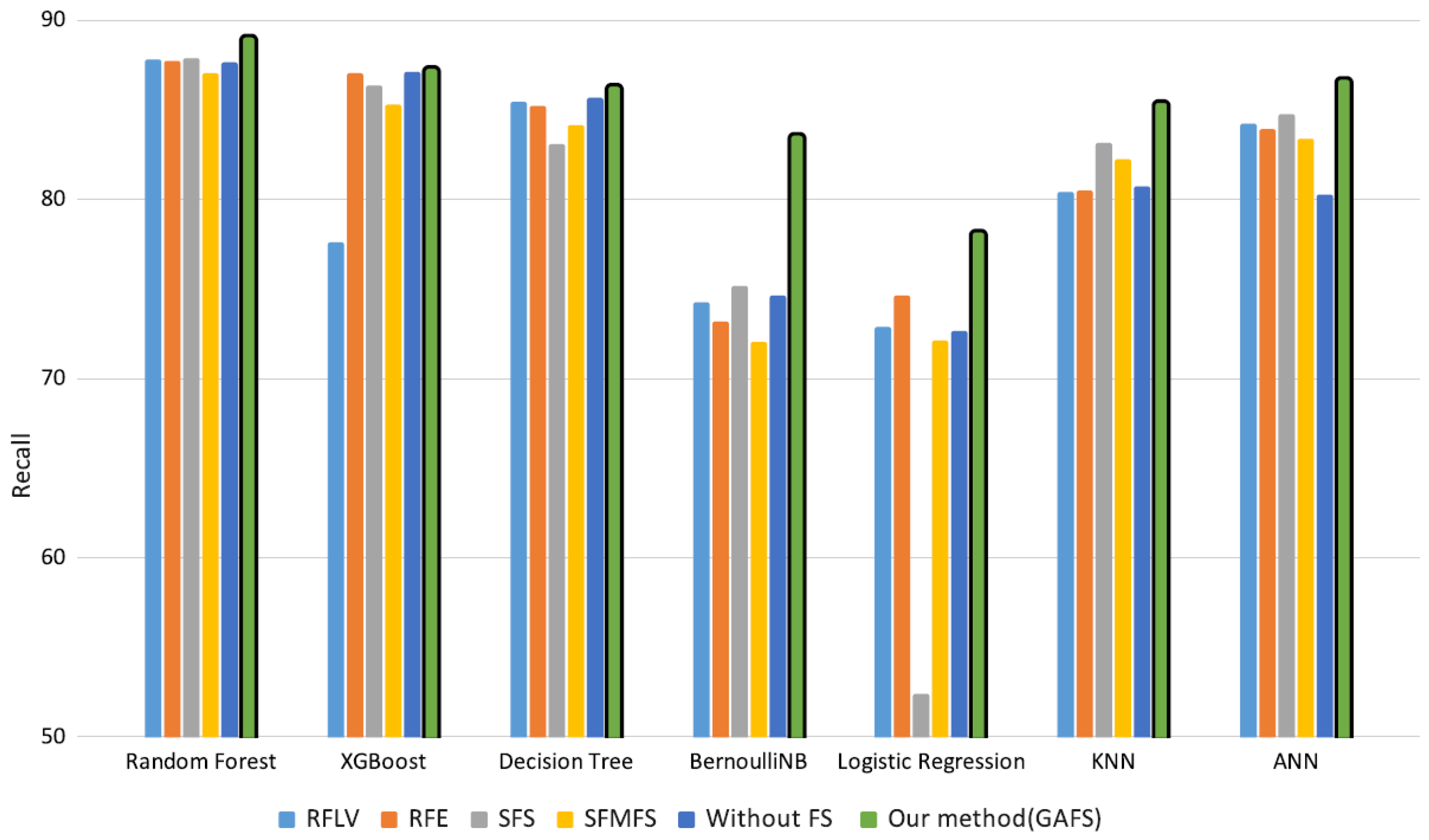
4.4. Greedy Search Feature Selection Methods
Choosing the right features is essential in ML for constructing effective predictive models. Several greedy search approaches exist, in which features are selected iteratively based on individual performance, without considering the global optimal subset. There are feature selection approaches, such as filter methods, that rely solely on statistical information of features. Examples of such approaches include RFE [
44], Sequential Feature Selection (SFS) [
45], Select From Model Feature Selection (SFMFS), which is a technique that selects features according to their importance from a meta-transformer model’s perspective [
46], and Removing Features with Low Variance (RFLV) with the common filtering method [
47], among others.
We applied these feature selection methods and compared their results with our proposed approach. Each method was run on seven selected ML algorithms, and the best results were compared with the results obtained with our proposed feature selection approach. The results are given in
Section 5.
6. Discussion
Feature engineering techniques are crucial in the ML pipeline due to their impact on model’s performance, and one of the most common techniques is feature selection that aims to find an optimal subset from the original feature set. Although model-agnostic techniques such as the “Low Variance” method are less expensive in terms of computational cost than modeling-dependent methods, our experiments indicated that the proposed GAFS produced better results.
In the context of the ML pipeline, training the model is the most time-consuming phase after data acquisition and structuring. Specifically, in a GA-based feature selection model, this phase is a dominant part of the training process. The use of GA on the Nvidia-CUDA platform is particularly suitable for master–slave parallelism. This approach involves a master process that manages the population and several slave processes that handle the evaluation of individuals. The master process distributes individuals to the slaves, collects the results, and performs genetic operations. The proposed method is well-suited for parallel computing, unlike other methods such as sequential feature selection. In our approach, each solution within a population and its associated model training can be generated concurrently, presenting a significant advantage of the GA. In an environment with parallel computing infrastructure, the classification performance scores achieved by our method can be enhanced by expanding the search space, such as by increasing parameters like population size and the number of generations while reducing the total processing time.
Other feature selection methods typically consider the correlation of the features with the target variable. In contrast, the proposed model has adaptability and flexibility to shape the fitness function to meet new requirements or constraints that may emerge such as multi-objective optimization based on fitness values. For example, since the focus of this problem is on phishing detection, the recall value for the positive class is of the utmost importance. However, in the post-deployment phase, if a need arises to limit the total feature extraction time for an input to reduce the application decision time, the same method can be used simply by adjusting the structure of the fitness function. Although other methods may have functions such as specifying a minimum number of features, they do not account for the execution or processing time of the features as a flexible customization capability.
As mentioned previously, the timing of feature calculation is not currently considered in this work. However, the structure of GA is suitable for making selections and taking timing into account. For this calculation, two main metrics are considered: recall value and the calculation time of the feature subset. In our current work, we focus on the recall value as our main fitness value, as depicted in Equation (
1). To incorporate feature calculation time, we can modify this fitness function as shown in Equation (
2), where a and b are constants that represent the weights of these metrics in the fitness value calculation.
This study shows that a powerful optimization algorithm such as a GA has potential in many respects, such as improving ML applications and increasing cost efficiency. Especially with multicore GPUs, the parallel-computing-friendly structure of the GA can be useful not only for feature selection but also for many other problems, such as hyperparameter optimization in the ML and DL models.
7. Conclusions and Future Work
This research introduced a feature selection approach founded upon GA principles, augmented by localized optimization techniques, with the specific objective of classifying phishing websites instead of exhaustively using the entire set of 73 URL-based features. The application of our proposed methodology led to significant improvements in classical performance indicators for ML models, encompassing accuracy, recall, and precision. Furthermore, it is noteworthy that our approach consistently yielded feature subsets comprising fewer than 45 elements across all models, resulting in a substantial reduction in inference-related computational costs.
Although the current study utilized URL-based features, our future work aims to enhance the feature set’s versatility by incorporating content-based features such as HTML and CSS attributes. This expansion is intended to improve the effectiveness of phishing attack detection. Additionally, we plan to transform our research into a multi-objective optimization problem, taking into account the phishing detection scores of the model (e.g., accuracy and recall) alongside feature extraction time, which directly impacts costs, especially considering that content-based features are more computationally intensive than URL-based features. As part of our forthcoming efforts, we intend to develop a multi-objective feature selection methodology that adequately addresses these time-related complexities. Additionally, an extension of this research could involve applying the same algorithm to other related optimization problems, such as hyperparameter tuning for ML/DL models using GA. The process of finding the best hyperparameter combinations presents computational challenges similar to the feature selection task, making the proposed algorithm potentially valuable in this context as well.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}