
Machine Learning Techniques for Soil Characterization Using Cone Penetration Test Data


Abstract
1. Introduction
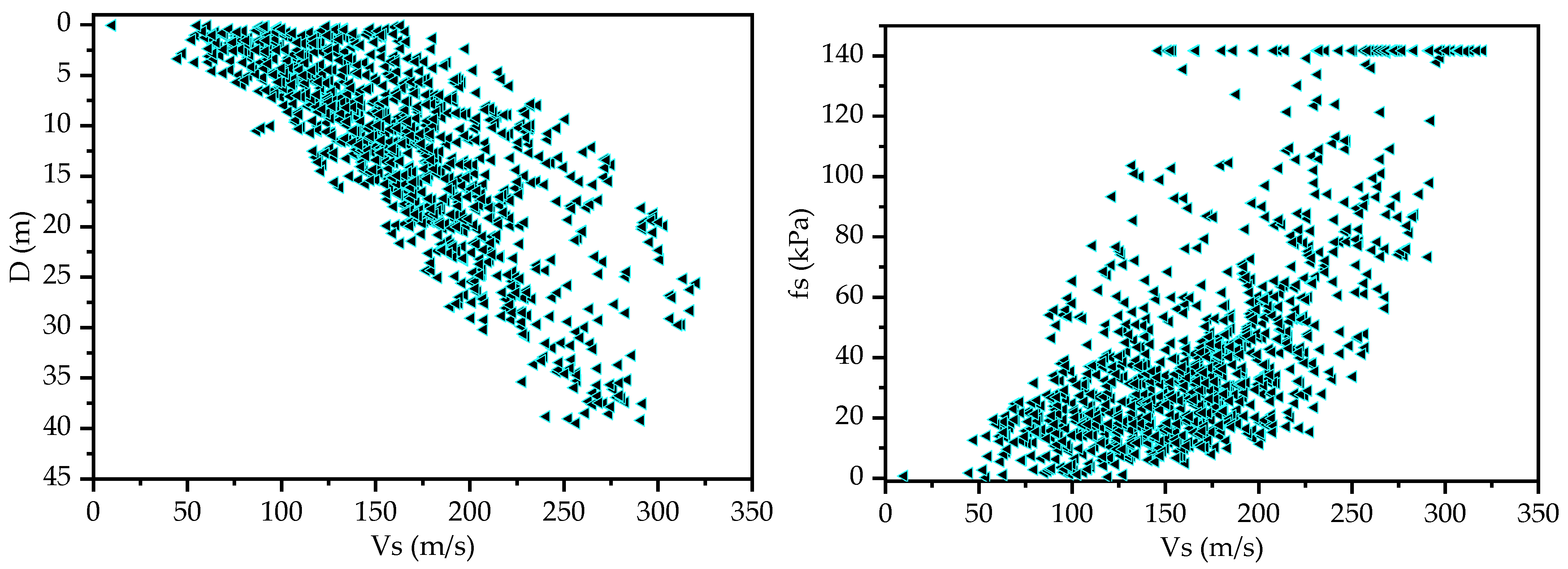
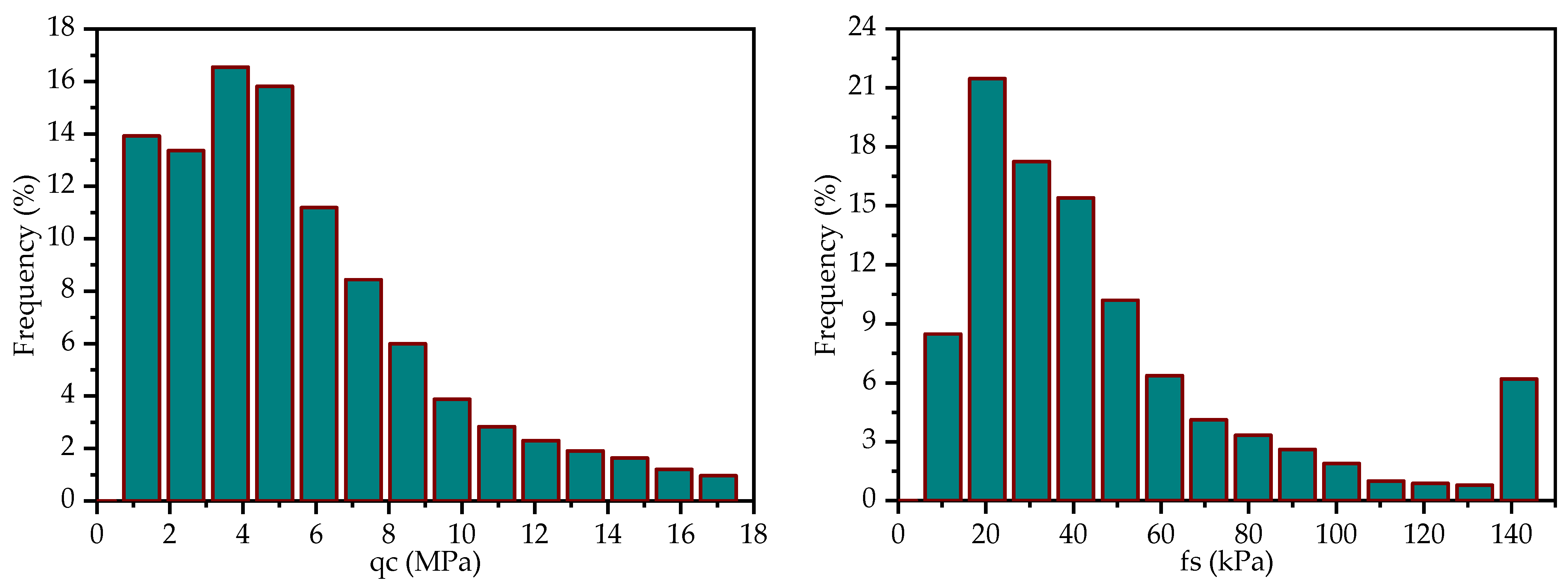
2. Datasets Preprocessing and Visualization
3. Methodology
4. Machine Learning Models
4.1. Random Forests
4.2. Support Vector Machine
4.3. Decision Trees
4.4. eXtreme Gradient Boosting
5. Results and Discussion
5.1. Hyperparameter Optimization Results
5.2. Performance of ML Models
5.3. Comparisons of ML Models
6. Conclusions
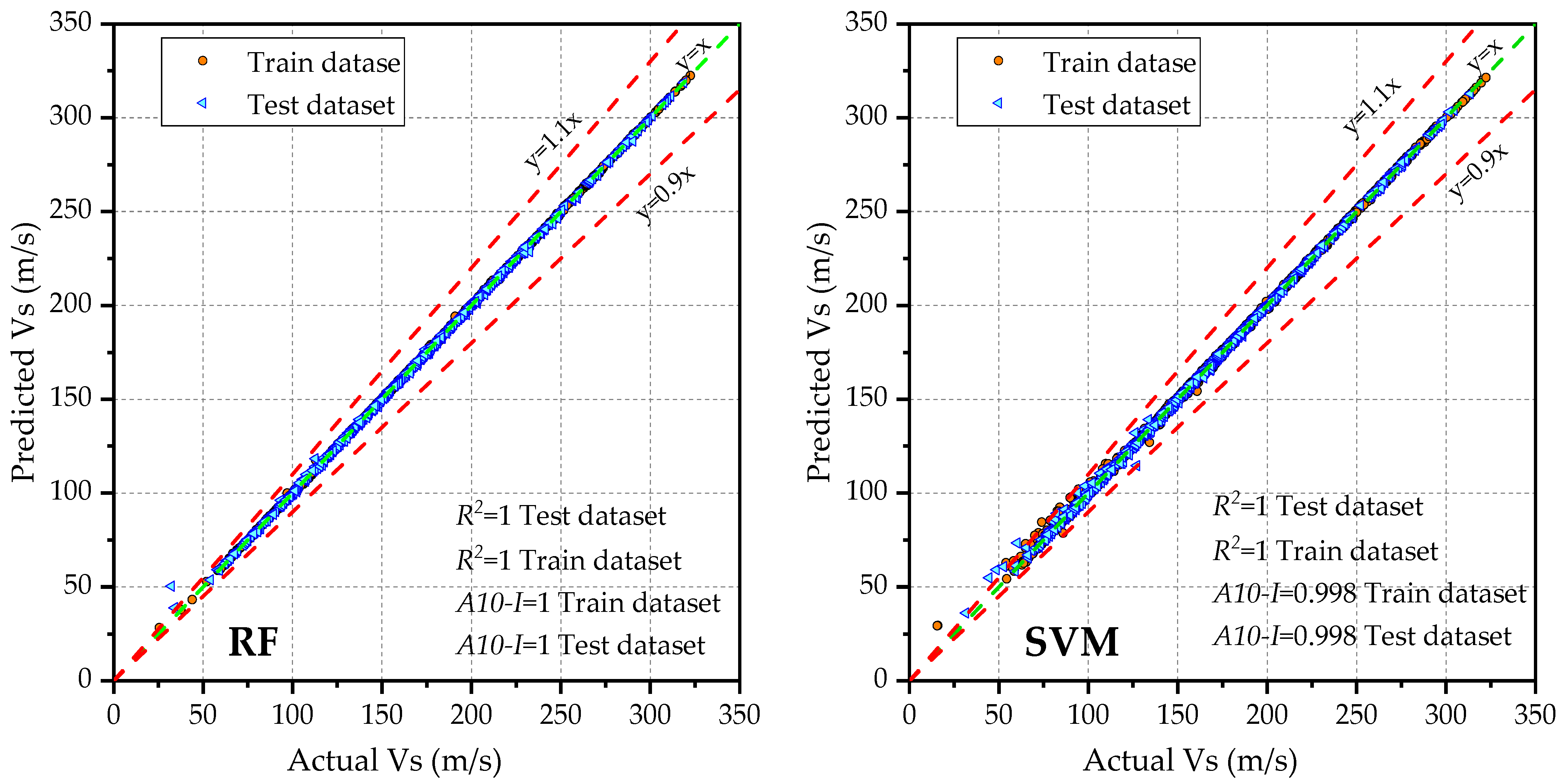
- The RF model outperformed the other ML models, achieving the lowest error metrics on both the training and testing datasets. Specifically, it achieved an of 0.46 and 0.96, an of 0.24 m/s and 0.5 m/s, and an of 0.17% and 0.36%, respectively. The model also demonstrated low scatter, with values of 0.003 and 0.006, and values of 0.002 and 0.004 on the training and testing datasets, respectively. Additionally, the RF model achieved and values of 1 on both datasets, indicating a perfect fit. Furthermore, the RF model recorded the lowest uncertainty, with a value of 1.24 on the training dataset.
- The SVM and XGBoost models also exhibited strong performance, with slightly higher error metrics compared with the RF model. These two models ranked second and third, respectively, following the RF model, which achieved the highest performance. However, the DT model performed poorly, with higher error rates and uncertainty in predicting .
- The RF model demonstrated its overall superior performance and high accuracy in predicting soil , even when trained with minimal input features. Hence, owing to its excellent performance across multiple metrics, the RF model can be integrated into a software package for rapid and accurate prediction of soil .
- In summary, while this study relied solely on CPT data for training ML models, it is important to recognize the limitations of the CPT, particularly its primary suitability for fine-grained soils. To further enhance the application of ML models in soil characterization, future research should consider incorporating experimental results and data for coarse-grained soil types.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Engineering index with deviation | Coefficient of determination | ||
| Artificial neural network | Friction ratio | ||
| Cone penetration test | Random forest | ||
| Depth of soil (m) | Root mean squared error | ||
| Decision trees | Seismic cone penetration testing | ||
| Normalized friction ratio | SD | Standard deviation | |
| sleeve friction | Scatter index | ||
| Soil behavioral type index | Support vector machine | ||
| interquartile range | Uncertainty at 95% confidence interval | ||
| Mean absolute error | Shear wave velocity | ||
| Mean absolute percentage error | Total overburden stress | ||
| Multi-Channel Analysis of Surface Waves | Effective overburden stress | ||
| Machine learning | Atmospheric pressure | ||
| Total number of datasets | Third quartile | ||
| Atmospheric pressure | Mean | ||
| Performance index | Predicted value of ith observation | ||
| cone tip resistance | Actual value of ith observation | ||
| First quartile | Extreme gradient boosting |
References
- Kalinina, A.V.; Ammosov, S.M.; Bykova, V.V.; Tatevossian, R.E. Effect of the Upper Part of the Soil Profile on the Site Response. Seism. Instrum. 2018, 54, 499–513. [Google Scholar] [CrossRef]
- Kawase, H. Site Effects on Strong Ground Motions. In International Geophysics; Kyushu University: Fukuoka, Japan, 2003; Volume 81, pp. 1013–1030. [Google Scholar]
- Borcherdt, R.D.; Glassmoyer, G. On the Characteristics of Local Geology and Their Influence on Ground Motions Generated by the Loma Prieta Earthquake in the San Franciso Bay Region, California. Bull. Seismol. Soc. Am. 1992, 82, 603–641. [Google Scholar] [CrossRef]
- Hanks, T.C.; Krawinkler, H. The 1989 Loma Prieta Earthquake and Its Effects: Introduction to the Special Issue. Bull. Seismol. Soc. Am. 1991, 81, 1415–1423. [Google Scholar] [CrossRef]
- Aki, K. Local Site Effect on Ground Motion. Am. Soc. Civil Eng. 1988, 20, 103–155. [Google Scholar]
- Tokimatsu, K. Geotechnical Site Characterization Using Surface Waves. In Earthquake Geotechnical Engineering, Proceedings of the IS-Tokyo’95, the First International Conference on Earthquake Geotechnical Engineering, Tokyo, Japan, 14–16 November 1995; A.A. Balkema: Rotterdam, The Netherlands, 1995; pp. 1136–1333. [Google Scholar]
- Robertson, P.K.; Campanella, R.G. Interpretation of CPT-Sand&Clay. Can. Geotech. J. 1983, 20, 718–733. [Google Scholar]
- Park, C.B.; Miller, R.D.; Xia, J. Multichannel Analysis of Surface Waves. Geophysics 1999, 64, 800–808. [Google Scholar] [CrossRef]
- Aka, M.; Agbasi, O. Delineation of Weathered Layer Using Uphole and Surface Seismic Refraction Methods in Parts of Niger Delta, Nigeria: Delineation of Weathered Layer. Sultan Qaboos Univ. J. Sci. SQUJS 2021, 26, 58–66. [Google Scholar] [CrossRef]
- Musgrave, A.W. Seismic Refraction Prospecting; Society of Exploration Geophysicists: Houston, TX, USA, 1967; ISBN 1560802677. [Google Scholar]
- Viggiani, G.; Atkinson, J.H. Interpretation of Bender Element Tests. Geotechnique 1995, 45, 149–154. [Google Scholar] [CrossRef]
- Nishio, S.; Tamaoki, K. Measurement of Shear Wave Velocities in Diluvial Gravel Samples Under Triaxial Conditions. Soils Found. 1988, 28, 35–48. [Google Scholar] [CrossRef]
- Drnevich, V. Resonant-Column Testing—Problems and Solutions; ASTM International: Singapore, 1978. [Google Scholar]
- Le, T.T.; Skentou, A.D.; Mamou, A.; Asteris, P.G. Correlating the Unconfined Compressive Strength of Rock with the Compressional Wave Velocity Effective Porosity and Schmidt Hammer Rebound Number Using Artificial Neural Networks; Springer: Vienna, Austria, 2022; Volume 55, ISBN 0123456789. [Google Scholar]
- Andrus, R.D.; Mohanan, N.P.; Piratheepan, P.; Ellis, B.S.; Holzer, T.L. Predicting Shear-Wave Velocity From Cone Penetration Resistance. In Proceedings of the 4th International Conference on Earthquake Geotechnical Engineering, Thessaloniki, Greece, 25–28 June 2007. [Google Scholar]
- Robertson, P.K. Interpretation of Cone Penetration Tests—A Unified Approach. Can. Geotech. J. 2009, 46, 1337–1355. [Google Scholar] [CrossRef]
- Wolf, Á.; Ray, R.P. Comparison and Improvement of the Existing Cone Penetration Test Results: Shear Wave Velocity Correlations for Hungarian Soils. Int. J. Environ. Chem. Ecol. Geol. Geophys. Eng. 2017, 11, 338–347. [Google Scholar]
- Mayne, P.W.; Rix, G.J. Correlations Between Shear Wave Velocity and Cone Tip Resistance in Natural Clays. Soils Found. 1995, 35, 107–110. [Google Scholar] [CrossRef] [PubMed]
- Tonni, L.; Simonini, P. Shear Wave Velocity as Function of Cone Penetration Test Measurements in Sand and Silt Mixtures. Eng. Geol. 2013, 163, 55–67. [Google Scholar] [CrossRef]
- Robertson, P.K. Cone Penetration Test (CPT)-Based Soil Behaviour Type (SBT) Classification System—An Update. Can. Geotech. J. 2016, 53, 1910–1927. [Google Scholar] [CrossRef]
- Robertson, P.K.; Campanella, R.G.; Gillespie, D.; Greig, J. Use of Piezometer Cone Data. In Use of In Situ Tests in Geotechnical Engineering; ASCE: Reston, VA, USA, 1986; pp. 1263–1280. [Google Scholar]
- Chen, J.; Vissinga, M.; Shen, Y.; Hu, S.; Beal, E.; Newlin, J. Machine Learning–Based Digital Integration of Geotechnical and Ultrahigh–Frequency Geophysical Data for Offshore Site Characterizations. J. Geotech. Geoenvironmental Eng. 2021, 147, 04021160. [Google Scholar] [CrossRef]
- Olayiwola, T.; Tariq, Z.; Abdulraheem, A.; Mahmoud, M. Evolving Strategies for Shear Wave Velocity Estimation: Smart and Ensemble Modeling Approach. Neural Comput. Appl. 2021, 33, 17147–17159. [Google Scholar] [CrossRef]
- Assaf, J.; Molnar, S.; El Naggar, M.H. CPT-Vs Correlations for Post-Glacial Sediments in Metropolitan Vancouver. Soil Dyn. Earthq. Eng. 2023, 165, 107693. [Google Scholar] [CrossRef]
- Tsiaousi, D.; Travasarou, T.; Drosos, V.; Ugalde, J.; Chacko, J. Machine Learning Applications for Site Characterization Based on CPT Data. In Proceedings of the Geotechnical Earthquake Engineering and Soil Dynamics V, Austin, TX, USA, 10–13 June 2018; American Society of Civil Engineers: Reston, VA, USA, 2018; pp. 461–472. [Google Scholar]
- Taheri, A.; Makarian, E.; Manaman, N.S.; Ju, H.; Kim, T.H.; Geem, Z.W.; Rahimizadeh, K. A Fully-Self-Adaptive Harmony Search GMDH-Type Neural Network Algorithm to Estimate Shear-Wave Velocity in Porous Media. Appl. Sci. 2022, 12, 6339. [Google Scholar] [CrossRef]
- Kang, T.H.; Choi, S.W.; Lee, C.; Chang, S.H. Soil Classification by Machine Learning Using a Tunnel Boring Machine’s Operating Parameters. Appl. Sci. 2022, 12, 11480. [Google Scholar] [CrossRef]
- Carvalho, L.O.; Ribeiro, D.B. Soil Classification System from Cone Penetration Test Data Applying Distance-Based Machine Learning Algorithms. Soils Rocks 2019, 42, 167–178. [Google Scholar] [CrossRef]
- Eyo, E.; Abbey, S. Multiclass Stand-Alone and Ensemble Machine Learning Algorithms Utilised to Classify Soils Based on Their Physico-Chemical Characteristics. J. Rock Mech. Geotech. Eng. 2022, 14, 603–615. [Google Scholar] [CrossRef]
- Hikouei, I.S.; Kim, S.S.; Mishra, D.R. Machine-Learning Classification of Soil Bulk Density in Salt Marsh Environments. Sensors 2021, 21, 4408. [Google Scholar] [CrossRef]
- Aydın, Y.; Işıkdağ, Ü.; Bekdaş, G.; Nigdeli, S.M.; Geem, Z.W. Use of Machine Learning Techniques in Soil Classification. Sustainability 2023, 15, 2374. [Google Scholar] [CrossRef]
- Carvalho, L.O.; Ribeiro, D.B. A Multiple Model Machine Learning Approach for Soil Classification from Cone Penetration Test Data. Soils Rocks 2021, 44, 1–14. [Google Scholar] [CrossRef]
- Chala, A.T.; Ray, R. Assessing the Performance of Machine Learning Algorithms for Soil Classification Using Cone Penetration Test Data. Appl. Sci. 2023, 13, 5758. [Google Scholar] [CrossRef]
- Akhundi, H.; Ghafoori, M.; Lashkaripour, G. Prediction of Shear Wave Velocity Using Artificial Neural Network Technique, Multiple Regression and Petrophysical Data: A Case Study in Asmari Reservoir (SW Iran). Open J. Geol. 2014, 4, 303–313. [Google Scholar] [CrossRef]
- Demir, S.; Sahin, E.K. An Investigation of Feature Selection Methods for Soil Liquefaction Prediction Based on Tree-Based Ensemble Algorithms Using AdaBoost, Gradient Boosting, and XGBoost. Neural Comput. Appl. 2023, 35, 3173–3190. [Google Scholar] [CrossRef]
- Demir, S.; Şahin, E.K. Liquefaction Prediction with Robust Machine Learning Algorithms (SVM, RF, and XGBoost) Supported by Genetic Algorithm-Based Feature Selection and Parameter Optimization from the Perspective of Data Processing. Environ. Earth Sci. 2022, 81, 459. [Google Scholar] [CrossRef]
- Samui, P.; Sitharam, T.G. Machine Learning Modelling for Predicting Soil Liquefaction Susceptibility. Nat. Hazards Earth Syst. Sci. 2011, 11, 1–9. [Google Scholar] [CrossRef]
- Ozsagir, M.; Erden, C.; Bol, E.; Sert, S.; Özocak, A. Machine Learning Approaches for Prediction of Fine-Grained Soils Liquefaction. Comput. Geotech. 2022, 152, 105014. [Google Scholar] [CrossRef]
- Alobaidi, M.H.; Meguid, M.A.; Chebana, F. Predicting Seismic-Induced Liquefaction through Ensemble Learning Frameworks. Sci. Rep. 2019, 9, 11786. [Google Scholar] [CrossRef] [PubMed]
- Jas, K.; Dodagoudar, G.R. Explainable Machine Learning Model for Liquefaction Potential Assessment of Soils Using XGBoost-SHAP. Soil Dyn. Earthq. Eng. 2023, 165, 107662. [Google Scholar] [CrossRef]
- Wang, L.; Wu, C.; Tang, L.; Zhang, W.; Lacasse, S.; Liu, H.; Gao, L. Efficient Reliability Analysis of Earth Dam Slope Stability Using Extreme Gradient Boosting Method. Acta Geotech. 2020, 15, 3135–3150. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, R.; Wu, C.; Goh, A.T.C.; Wang, L. Assessment of Basal Heave Stability for Braced Excavations in Anisotropic Clay Using Extreme Gradient Boosting and Random Forest Regression. Undergr. Space 2022, 7, 233–241. [Google Scholar] [CrossRef]
- Bharti, J.P.; Mishra, P.; Moorthy, U.; Sathishkumar, V.E.; Cho, Y.; Samui, P. Slope Stability Analysis Using Rf, Gbm, Cart, Bt and Xgboost. Geotech. Geol. Eng. 2021, 39, 3741–3752. [Google Scholar] [CrossRef]
- Samui, P. Slope Stability Analysis: A Support Vector Machine Approach. Environ. Geol. 2008, 56, 255–267. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Y.; Peng, G. Landslide Susceptibility Assessment Using Integrated Deep Learning Algorithm along the China-Nepal Highway. Sensors 2018, 18, 4436. [Google Scholar] [CrossRef] [PubMed]
- Nejad, F.P.; Jaksa, M.B. Load-Settlement Behavior Modeling of Single Piles Using Artificial Neural Networks and CPT Data. Comput. Geotech. 2017, 89, 9–21. [Google Scholar] [CrossRef]
- Nejad, F.P.; Jaksa, M.B.; Kakhi, M.; McCabe, B.A. Prediction of Pile Settlement Using Artificial Neural Networks Based on Standard Penetration Test Data. Comput. Geotech. 2009, 36, 1125–1133. [Google Scholar] [CrossRef]
- Chen, R.; Zhang, P.; Wu, H.; Wang, Z.; Zhong, Z. Prediction of Shield Tunneling-Induced Ground Settlement Using Machine Learning Techniques. Front. Struct. Civ. Eng. 2019, 13, 1363–1378. [Google Scholar] [CrossRef]
- Riyadi, Z.A.; Husen, M.H.; Lubis, L.A.; Ridwan, T.K. The Implementation of TPE-Bayesian Hyperparameter Optimization to Predict Shear Wave Velocity Using Machine Learning: Case Study From X Field in Malay Basin. Pet. Coal 2022, 64, 467–488. [Google Scholar]
- Shooshpasha, I.; Kordnaeij, A.; Dikmen, U.; Molaabasi, H.; Amir, I. Shear Wave Velocity by Support Vector Machine Based on Geotechnical Soil Properties. Nat. Hazards Earth Syst. Sci. 2014, 2, 2443–2461. [Google Scholar] [CrossRef]
- Bagheripour, P.; Gholami, A.; Asoodeh, M.; Vaezzadeh-Asadi, M. Support Vector Regression Based Determination of Shear Wave Velocity. J. Pet. Sci. Eng. 2015, 125, 95–99. [Google Scholar] [CrossRef]
- Oberhollenzer, S.; Premstaller, M.; Marte, R.; Tschuchnigg, F.; Erharter, G.H.; Marcher, T. Cone Penetration Test Dataset Premstaller Geotechnik. Data Brief 2021, 34, 106618. [Google Scholar] [CrossRef] [PubMed]
- Esmaeili-Falak, M.; Benemaran, R.S. Ensemble Deep Learning-Based Models to Predict the Resilient Modulus of Modified Base Materials Subjected to Wet-Dry Cycles. Geomech. Eng. 2023, 32, 583–600. [Google Scholar]
- Harandizadeh, H.; Armaghani, D.J.; Asteris, P.G.; Gandomi, A.H. TBM Performance Prediction Developing a Hybrid ANFIS-PNN Predictive Model Optimized by Imperialism Competitive Algorithm; Springer: London, UK, 2021; Volume 33, ISBN 0052102106. [Google Scholar]
- Hajihassani, M.; Abdullah, S.S.; Asteris, P.G.; Armaghani, D.J. A Gene Expression Programming Model for Predicting Tunnel Convergence. Appl. Sci. 2019, 9, 4650. [Google Scholar] [CrossRef]
- Li, Z.; Bejarbaneh, B.Y.; Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. A Hybrid GEP and WOA Approach to Estimate the Optimal Penetration Rate of TBM in Granitic Rock Mass. Soft Comput. 2021, 25, 11877–11895. [Google Scholar] [CrossRef]
- Abushanab, A.; Wakjira, T.G.; Alnahhal, W. Machine Learning-Based Flexural Capacity Prediction of Corroded RC Beams with an Efficient and User-Friendly Tool. Sustainability 2023, 15, 4824. [Google Scholar] [CrossRef]
- Wakjira, T.G.; Ebead, U.; Alam, M.S. Machine Learning-Based Shear Capacity Prediction and Reliability Analysis of Shear-Critical RC Beams Strengthened with Inorganic Composites. Case Stud. Constr. Mater. 2022, 16, e01008. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Mohammed, A.S.; Faraj, R.H.; Abdalla, A.A.; Qaidi, S.M.A.; Sor, N.H.; Mohammed, A.A. Innovative Modeling Techniques Including MEP, ANN and FQ to Forecast the Compressive Strength of Geopolymer Concrete Modified with Nanoparticles. Neural Comput. Appl. 2023, 35, 12453–12479. [Google Scholar] [CrossRef]
- Skentou, A.D.; Bardhan, A.; Mamou, A.; Lemonis, M.E.; Kumar, G.; Samui, P.; Armaghani, D.J.; Asteris, P.G. Closed-Form Equation for Estimating Unconfined Compressive Strength of Granite from Three Non-Destructive Tests Using Soft Computing Models. Rock Mech. Rock Eng. 2023, 56, 487–514. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, J.; Asteris, P.G.; Armaghani, D.J.; Tahir, M.M. Supervised Machine Learning Techniques to the Prediction of Tunnel Boring Machine Penetration Rate. Appl. Sci. 2019, 9, 3715. [Google Scholar] [CrossRef]
- Mahmood, W.; Mohammed, A. Performance of ANN and M5P-Tree to Forecast the Compressive Strength of Hand-Mix Cement-Grouted Sands Modified with Polymer Using ASTM and BS Standards and Evaluate the Outcomes Using SI with OBJ Assessments. Neural Comput. Appl. 2022, 34, 15031–15051. [Google Scholar] [CrossRef]
- Abdalla, A.; Salih, A. Implementation of Multi-Expression Programming (MEP), Artificial Neural Network (ANN), and M5P-Tree to Forecast the Compression Strength Cement-Based Mortar Modified by Calcium Hydroxide at Different Mix Proportions and Curing Ages. Innov. Infrastruct. Solut. 2022, 7, 1–15. [Google Scholar] [CrossRef]
- Shi, X.; Yu, X.; Esmaeili-Falak, M. Improved Arithmetic Optimization Algorithm and Its Application to Carbon Fiber Reinforced Polymer-Steel Bond Strength Estimation. Compos. Struct. 2023, 306, 116599. [Google Scholar] [CrossRef]
- Behar, O.; Khellaf, A.; Mohammedi, K. Comparison of Solar Radiation Models and Their Validation under Algerian Climate—The Case of Direct Irradiance. Energy Convers. Manag. 2015, 98, 236–251. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random Forests for Classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. arXiv 2015, arXiv:1508.04409. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. E1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien; R Package Version 1.7-13; R Core Team: Vienna, Austria, 2023. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees; Springer: Berlin/Heidelberg, Germany, 1986; Volume 1. [Google Scholar]
- Therneau, T.; Atkinson, B.; Ripley, B.; Ripley, M.B. Rpart: Recursive Partitioning and Regression Trees, R Package version 4.1-10; R Core Team: Vienna, Austria, 2015; pp. 1–9. [Google Scholar]
- Song, Y.Y.; Lu, Y. Decision Tree Methods: Applications for Classification and Prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharya, B.; Solomatine, D.P. Machine Learning in Soil Classification. Neural Networks 2006, 19, 186–195. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Fei, Z.; Liang, S.; Cai, Y.; Shen, Y. Ensemble Machine-Learning-Based Prediction Models for the Compressive Strength of Recycled Powder Mortar. Materials 2023, 16, 583. [Google Scholar] [CrossRef]
- Ray, R.P.; Wolf, A.; Kegyes-Brassai, O. Harmonizing Dynamic Property Measurements of Hungarian Soils. In Proceedings of the 6th International Conference on Geotechnical and Geophysical Site Characterization (ISC2020), Budapest, Hungary, 7–11 September 2020. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Unit | Class | Training Dataset | Testing Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Min | Max | Count | Mean | SD | Min | Max | Count | |||
| m | Input | 12.42 | 8.88 | 0.01 | 40 | 79,579 | 12.38 | 8.78 | 0.01 | 40 | 34,104 | |
| MPa | Input | 4.89 | 3.60 | 0.01 | 17 | 79,579 | 4.87 | 3.59 | 0.01 | 17 | 34,104 | |
| kPa | Input | 42.91 | 35.35 | 0.07 | 142 | 79,579 | 42.88 | 35.39 | 0.10 | 142 | 34,104 | |
| % | Input | 1.56 | 6.11 | 0.00 | 1121 | 79,579 | 1.57 | 6.28 | 0.00 | 1083 | 34,104 | |
| m/s | Target | 166.76 | 55.89 | 10.06 | 322 | 79,579 | 166.55 | 55.57 | 9.93 | 322 | 34,104 | |
| Metrics | Best Performance | Equations | Equation No. |
|---|---|---|---|
| Root mean squared error | Lower value | (4) | |
| Mean absolute error | Lower value | (5) | |
| Mean absolute percentage error | Lower value | (6) | |
| Coefficient of determination | unity | (7) | |
| unity | (8) | ||
| Scatter index | Lower value | (9) | |
| Performance index | Lower value | (10) | |
| Uncertainty at 95% confidence level | Lower value | (11) | |
| [64,65] | SI < 0.05: excellent precision (EP), 0.05 < SI < 0.1: good precision (GP), 0.1 < SI < 0.15: fair precision (FP), SI > 0.15: poor precision (PP) | ||
| ML Models | Tuned Hyperparameters | ||
|---|---|---|---|
| Names | Ranges | Optimized Values | |
| RF | Number of variables, mtry | 1–4 | 3 |
| Minimum node of tree | 1–30 | 2 | |
| Maximum depth of tree | 2–100 | 64 | |
| Number of trees in the forest | 1–30 | 12 | |
| SVM | Penalty parameter, Cost | 0.1–100 | 58.75 |
| Kernel coefficient, gamma | 0.01–10 | 9.44 | |
| Margin of tolerance, Epsilon | 0.01–1 | 0.026 | |
| Kernel type | radial | radial | |
| DT | Complexity parameter, cp | 0.001–1 | 0.001 |
| Maximum depth of trees | 1–30 | 20 | |
| Minimum number of splits | 2–20 | 5 | |
| Minimum number of observations at terminal node, minbucket | 2–20 | 6 | |
| Maximum number of splits at node, maxcompete | 1–20 | 9 | |
| XGBoost | Learning rate, eta | 0.01–1 | 0.26 |
| Loss reduction term, gamma | 0.01–10 | 3.79 | |
| L2 regularization term, lambda | 0.01–1 | 0.38 | |
| L1 regularization term, alpha | 0.01–1 | 0.83 | |
| Number of boosting rounds, nrounds | 1–100 | 84 | |
| Maximum depth of trees | 2–10 | 9 | |
| Fraction of samples for each tree, subsample | 0.1–1 | 0.79 | |
| Models | Train dataset | Rank | |||||||
| A10 − I | RMSE | PI | SI | MAE | MAPE | U95 | |||
| RF | 1 (1) | 0.46 (1) | 1 (1) | 0.002 (1) | 0.003 (1) | 0.24 (1) | 0.17 (1) | 1.24 (1) | 1 |
| SVM | 0.998 (2) | 1.11 (2) | 1 (1) | 0.005 (2) | 0.007 (2) | 0.37 (2) | 0.28 (2) | 3.07 (2) | 2 |
| DT | 0.78 (3) | 13.1 (4) | 0.95 (2) | 0.06 (4) | 0.08 (4) | 10.27 (4) | 7.23 (4) | 36.20 (4) | 4 |
| XGBoost | 1 (1) | 1.68 (3) | 1 (1) | 0.007 (3) | 0.01 (3) | 1.29 (3) | 0.87 (3) | 4.65 (3) | 3 |
| Models | Test dataset | Rank | |||||||
| A10 − I | RMSE | PI | SI | MAE | MAPE | U95 | |||
| RF | 1 (1) | 0.96 (1) | 1 (1) | 0.004 (1) | 0.006 (1) | 0.50 (2) | 0.36 (2) | 2.66 (2) | 1 |
| SVM | 0.998 (2) | 1.36 (2) | 1 (1) | 0.006 (2) | 0.008 (2) | 0.38 (1) | 0.31 (1) | 2.3 (1) | 2 |
| DT | 0.77 (3) | 13.2 (4) | 0.94 (2) | 0.06 (4) | 0.08 (4) | 10.34 (4) | 7.31 (4) | 36.48 (4) | 4 |
| XGBoost | 1 (1) | 1.86 (3) | 1 (1) | 0.008 (3) | 0.01 (3) | 1.40 (3) | 0.94 (3) | 5.16 (3) | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chala, A.T.; Ray, R.P. Machine Learning Techniques for Soil Characterization Using Cone Penetration Test Data. Appl. Sci. 2023, 13, 8286. https://doi.org/10.3390/app13148286
Chala AT, Ray RP. Machine Learning Techniques for Soil Characterization Using Cone Penetration Test Data. Applied Sciences. 2023; 13(14):8286. https://doi.org/10.3390/app13148286
Chicago/Turabian StyleChala, Ayele Tesema, and Richard P. Ray. 2023. "Machine Learning Techniques for Soil Characterization Using Cone Penetration Test Data" Applied Sciences 13, no. 14: 8286. https://doi.org/10.3390/app13148286
APA StyleChala, A. T., & Ray, R. P. (2023). Machine Learning Techniques for Soil Characterization Using Cone Penetration Test Data. Applied Sciences, 13(14), 8286. https://doi.org/10.3390/app13148286