
Federated Reinforcement Learning in IoT: Applications, Opportunities and Open Challenges



Abstract
1. Introduction
- A comprehensive review of efforts regarding FRL-based solutions for IoT, and their main contributions, methods, resources, and future directions;
- An analysis of timely solutions divided into categories concerning problems faced, methods used, and immediate directions tailored to each domain;
- An extensive list of short- and long-term open challenges regarding the proposal of new IoT solutions supported by federated reinforcement learning (FRL).
2. Background
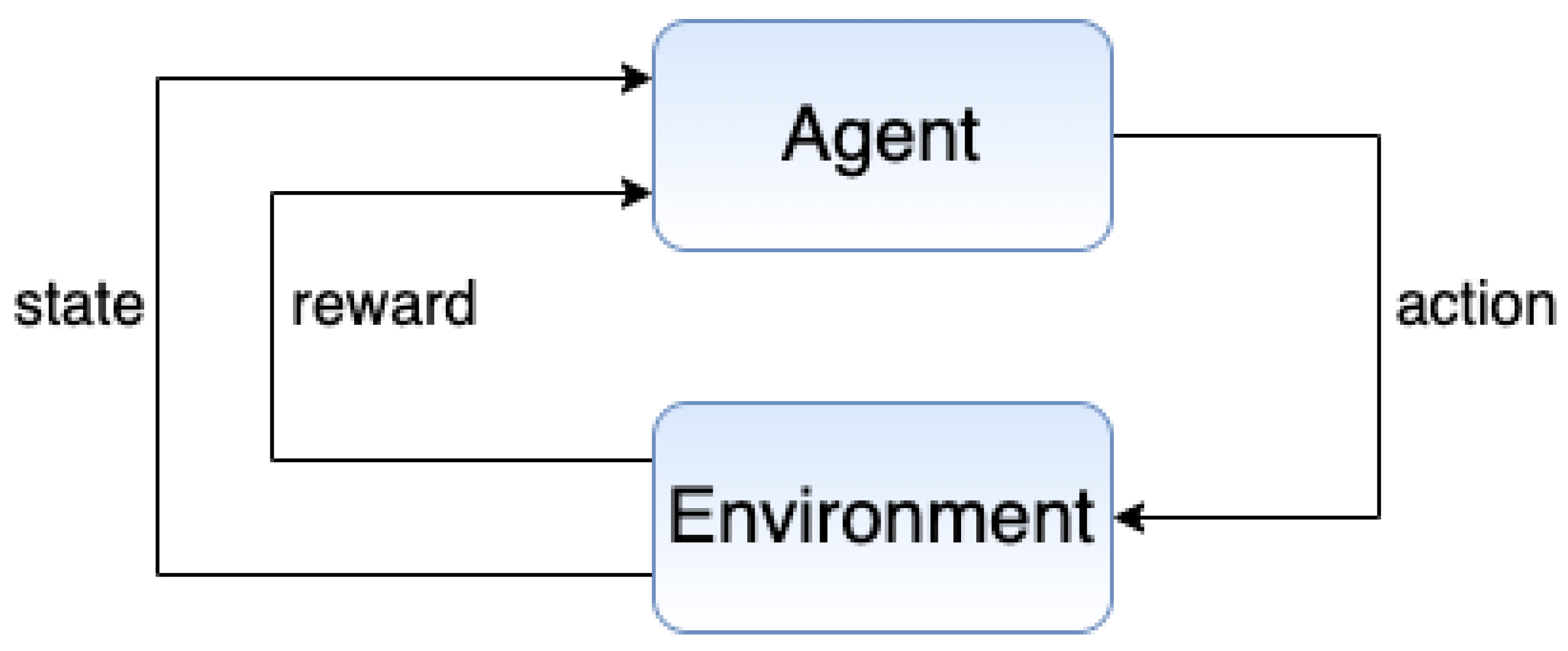
2.1. Reinforcement Learning (RL)
2.2. Federated Learning (FL)

- Cross-silo FL: This approach is based on the consideration of entities (e.g., companies or organizations) as training clients in different industrial sectors (e.g., transportation) [73]. Compared to cross-device FL, the number of clients tends to be smaller. Furthermore, each entity participates in the entire training process [74,75].
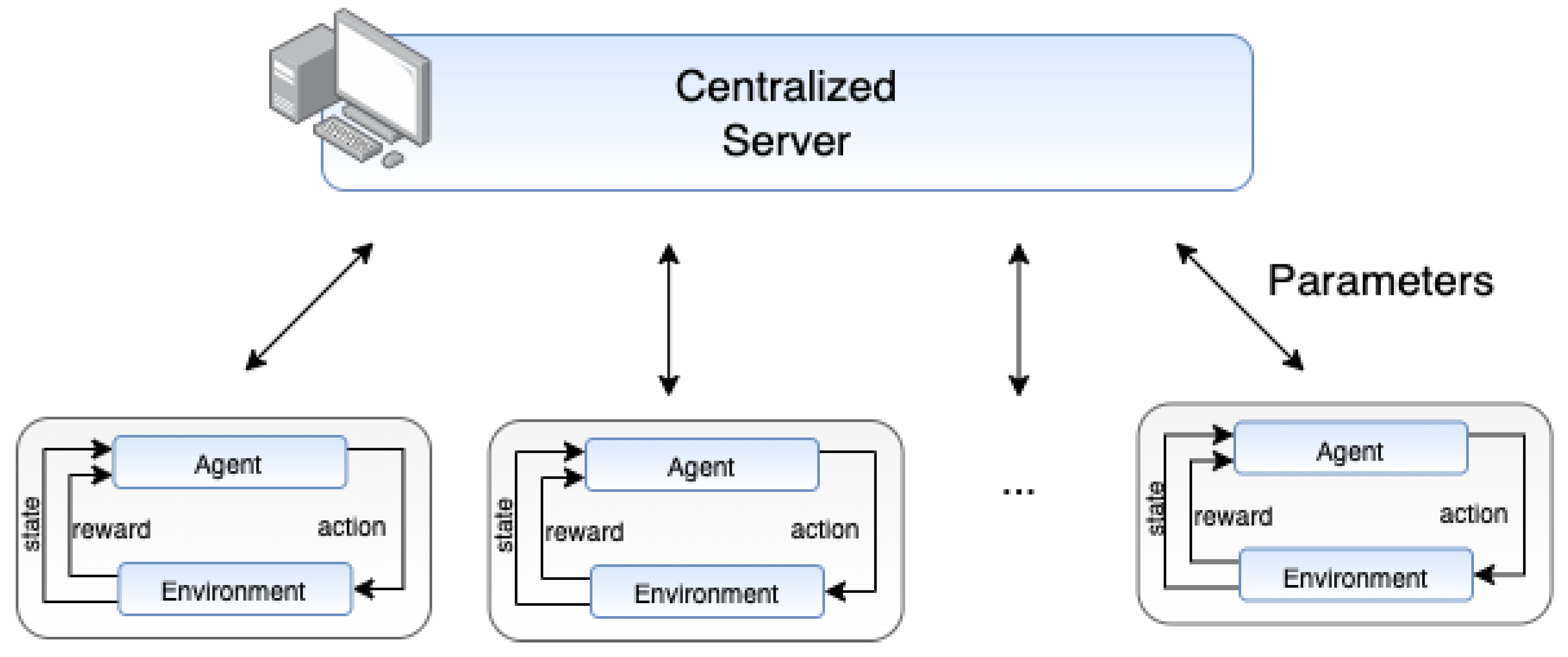
2.3. Federated Reinforcement Learning (FRL)
3. Methodology
3.1. FRL Applications in the IoT in Terms of Security
3.2. FRL Applications in the IoT in Terms of Sustainability and Efficiency
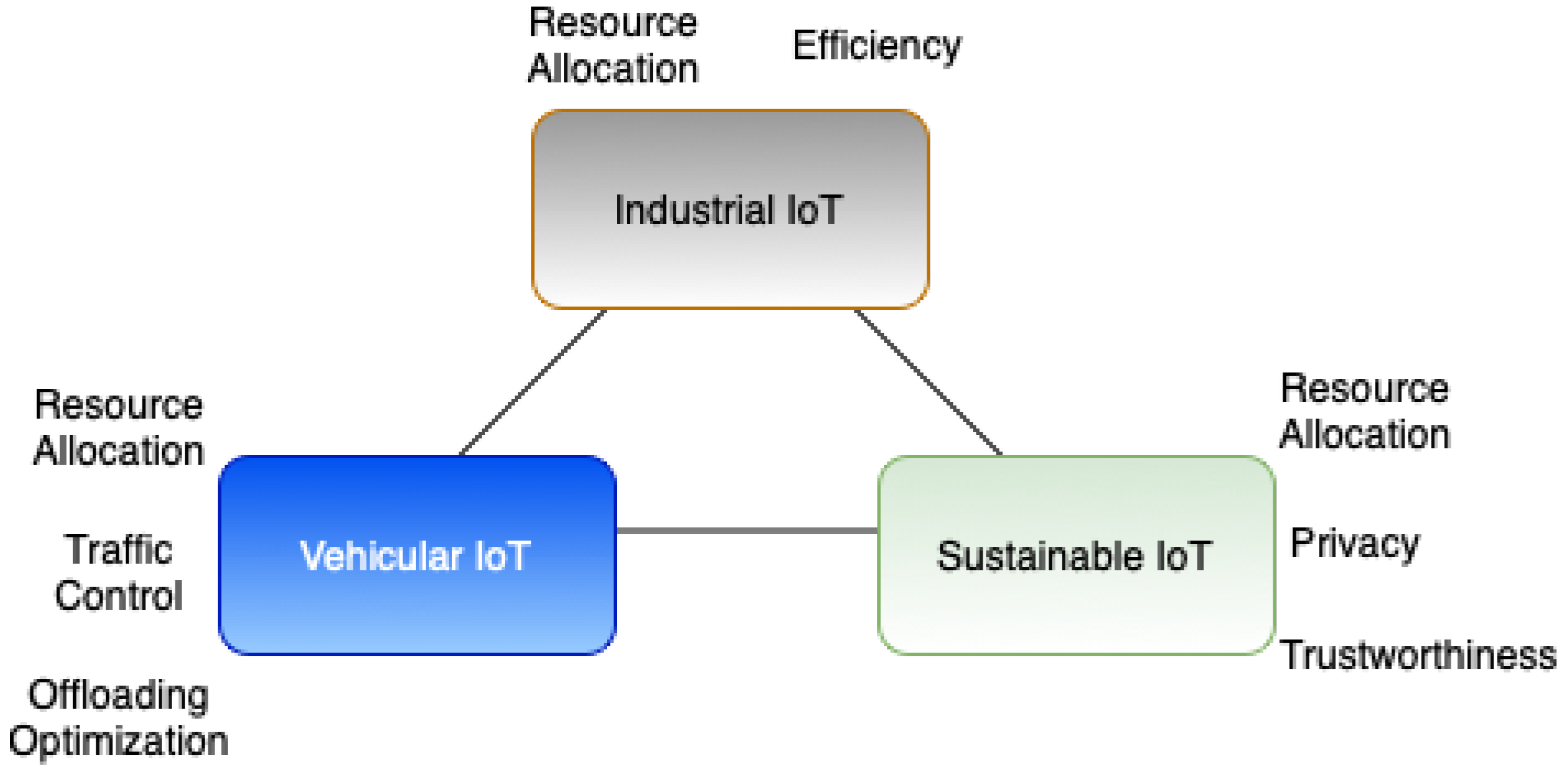
3.3. FRL Applications of IoT in the Vehicular Industry
3.4. FRL Applications in the Industrial Internet of Things
4. Open Challenges
- Integration of adaptable offloading methods, resource allocation, and energy management: Different solutions focus on individual challenges alongside specific constraints. Future efforts are expected to introduce an integrated approach to cover multiple tasks while offering flexibility regarding important systems’ constraints. In fact, the combination of energy management constraints with offloading and allocation solutions can further optimize existing solutions;
- Mitigation of security threats again distributed learning: In the past few years, there has been an increase in attacks again federated learning (FL) methods. These attacks threaten the integrity of the knowledge shared and can impact the performance of the overall system. Thereupon, new solutions are needed to mitigate attacks against FRL initiatives to ensure the learning process is not severally affected in different applications;
- Caching across multi-tenant applications: As presented in the reviewed papers, caching is a pivotal solution to improve the system performance in different IoT applications. In this sense, one future direction relies on caching solutions for multi-tenant and multi-service applications, in which separate logical infrastructures operated on the same physical topology with traffic isolation;
- Prioritized training: Due to the increasing number of IoT devices across different applications, it becomes challenging to identify trustworthy data feeds throughout the IoT network topology. In this context, another future direction focuses on proving a trust score for different training agents in order to define priorities in the FL aggregation procedure. This can mitigate attacks and ensure legitimate feeds are prioritized;
- Layered knowledge sharing based on service license agreements (SLA): Assuming that all knowledge can be shared across different agents, an application can diverge from real-world requirements, in which different organizations can establish special agreements regarding resource sharing. In this sense, the definition of logical channels for knowledge sharing in different FRL applications in IoT is an important direction for future works.
- Application-specific solutions: The reviewed efforts adopt different RL methods to solve multiple problems. However, future efforts are expected to include problem-specific mechanisms in the agents’ internal training process. This also extends to the aggregation procedure, e.g., methods focused on offloading optimization can have tailored training mechanisms not necessarily present in caching solutions;
- Continuous adaptability: The training process of FRL applications in IoT considers several components and constraints. A future direction in this regard relies on adopting dynamic constraints in which initial assumptions evolve throughout the system’s operation. These changes can comprise states, prioritized, temporary goals, and special conditions;
- Large-scale solutions: Unfolding the solutions proposed by the reviewed works, it is possible to generalize different applications to operate on a global scale. However, scalability can bring multiple obstacles to efficient operations (e.g., global knowledge sharing, the balance of local and global influence, and multi-regional collaborations). In this sense, future endeavors can focus on the aspects of scaling FRL applications in different IoT domains;
- New FL aggregation methods: In recent years, there has been an increase in the number of FL aggregation algorithms. In fact, a future direction relies on designing and evaluating new aggregation methods that can consider specific aspects related to the IoT operation. These new methods can simplify global convergence as well as enable more secure training procedures;
- Deployment and evaluation in a real environment: Although the solutions reviewed present high-performance solutions for the cases investigated, there is a need for evaluating such strategies in realistic testbeds. Indeed, these efforts involve both the replication of realistic testbeds (e.g., topologies, devices, and connections) and the use of the proposed methods in real operations. Future endeavors can focus on establishing a safe and secure environment for testing such methods.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rose, K.; Eldridge, S.; Chapin, L. The internet of things: An overview. Internet Soc. ISOC 2015, 80, 1–50. [Google Scholar]
- Tan, L.; Wang, N. Future internet: The internet of things. In Proceedings of the 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE), Chengdu, China, 20–22 August 2010; Volume 5. [Google Scholar]
- Yang, F.; Wang, S.; Li, J.; Liu, Z.; Sun, Q. An overview of internet of vehicles. China Commun. 2014, 11, 1–15. [Google Scholar] [CrossRef]
- Ding, Y.; Jin, M.; Li, S.; Feng, D. Smart logistics based on the internet of things technology: An overview. Int. J. Logist. Res. Appl. 2021, 24, 323–345. [Google Scholar] [CrossRef]
- Ramlowat, D.D.; Pattanayak, B.K. Exploring the internet of things (IoT) in education: A review. In Proceedings of the Information Systems Design and Intelligent Applications: Proceedings of 5th International Conference INDIA 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 245–255. [Google Scholar]
- Verdouw, C.; Wolfert, S.; Tekinerdogan, B. Internet of things in agriculture. CABI Rev. 2016, 1–12. [Google Scholar] [CrossRef]
- Pan, J.; Yang, Z. Cybersecurity challenges and opportunities in the new “edge computing + IoT” world. In Proceedings of the ACM International Workshop on Security in Software Defined Networks & Network Function Virtualization, Tempe, AZ, USA, 19–21 March 2018; pp. 29–32. [Google Scholar]
- Kaur, B.; Dadkhah, S.; Shoeleh, F.; Neto, E.C.P.; Xiong, P.; Iqbal, S.; Lamontagne, P.; Ray, S.; Ghorbani, A.A. Internet of things (IoT) security dataset evolution: Challenges and future directions. Internet Things 2023, 22, 100780. [Google Scholar] [CrossRef]
- Danso, P.K.; Neto, E.C.P.; Dadkhah, S.; Zohourian, A.; Molyneaux, H.; Ghorbani, A.A. Ensemble-based Intrusion Detection for internet of things Devices. In Proceedings of the IEEE 19th International Conference on Smart Communities: Improving Quality of Life Using ICT, IoT and AI (HONET), Marietta, GE, USA, 10–12 October 2022; pp. 034–039. [Google Scholar]
- Leminen, S.; Rajahonka, M.; Wendelin, R.; Westerlund, M. Industrial internet of things business models in the machine-to-machine context. Ind. Mark. Manag. 2020, 84, 298–311. [Google Scholar] [CrossRef]
- Roy, S.; Rawat, U.; Karjee, J. A lightweight cellular automata based encryption technique for IoT applications. IEEE Access 2019, 7, 39782–39793. [Google Scholar] [CrossRef]
- Cecere, G.; Le Guel, F.; Soulié, N. Perceived Internet privacy concerns on social networks in Europe. Technol. Forecast. Soc. Chang. 2015, 96, 277–287. [Google Scholar] [CrossRef]
- Singh, R.; Dwivedi, A.D.; Srivastava, G.; Chatterjee, P.; Lin, J.C.W. A Privacy Preserving internet of things Smart Healthcare Financial System. IEEE Internet Things J. 2023. Early Access. [Google Scholar] [CrossRef]
- Sfar, A.R.; Challal, Y.; Moyal, P.; Natalizio, E. A game theoretic approach for privacy preserving model in IoT-based transportation. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4405–4414. [Google Scholar] [CrossRef]
- Sutton, R.S. Reinforcement learning: Past, present and future. In Proceedings of the Simulated Evolution and Learning: Second Asia-Pacific Conference on Simulated Evolution and Learning, SEAL’98, Canberra, Australia, 24–27 November 1998; Springer: Berlin/Heidelberg, Germany, 1999; pp. 195–197. [Google Scholar]
- Sutton, R.S. Open theoretical questions in reinforcement learning. In Proceedings of the Computational Learning Theory: 4th European Conference, EuroCOLT’99, Nordkirchen, Germany, 29–31 March 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 11–17. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Jin, H.; Peng, Y.; Yang, W.; Wang, S.; Zhang, Z. Federated reinforcement learning with environment heterogeneity. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual Conference, 28–30 March 2022; pp. 18–37. [Google Scholar]
- Fu, Y.; Li, C.; Yu, F.R.; Luan, T.H.; Zhang, Y. A Selective federated reinforcement learning Strategy for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1655–1668. [Google Scholar] [CrossRef]
- Xue, Z.; Zhou, P.; Xu, Z.; Wang, X.; Xie, Y.; Ding, X.; Wen, S. A resource-constrained and privacy-preserving edge-computing-enabled clinical decision system: A federated reinforcement learning approach. IEEE Internet Things J. 2021, 8, 9122–9138. [Google Scholar] [CrossRef]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing federated learning on non-iid data with reinforcement learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Online, 6–9 July 2020; pp. 1698–1707. [Google Scholar]
- Xu, M.; Peng, J.; Gupta, B.; Kang, J.; Xiong, Z.; Li, Z.; Abd El-Latif, A.A. Multiagent federated reinforcement learning for Secure Incentive Mechanism in Intelligent Cyber–Physical Systems. IEEE Internet Things J. 2021, 9, 22095–22108. [Google Scholar] [CrossRef]
- Qi, J.; Zhou, Q.; Lei, L.; Zheng, K. Federated reinforcement learning: Techniques, applications, and open challenges. arXiv 2021, arXiv:2108.11887. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement learning. J. Cogn. Neurosci. 1999, 11, 126–134. [Google Scholar]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1058–1063. [Google Scholar]
- Dayan, P.; Niv, Y. Reinforcement learning: The good, the bad and the ugly. Curr. Opin. Neurobiol. 2008, 18, 185–196. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Stone, P.; Sutton, R.S. Scaling reinforcement learning toward RoboCup soccer. ICML 2001, 1, 537–544. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Kurach, K.; Raichuk, A.; Stańczyk, P.; Zając, M.; Bachem, O.; Espeholt, L.; Riquelme, C.; Vincent, D.; Michalski, M.; Bousquet, O.; et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI Conference on artificial intelligence, Hilton, NY, USA, 7–12 February 2020; pp. 4501–4510. [Google Scholar]
- Zhang, H.; Feng, S.; Liu, C.; Ding, Y.; Zhu, Y.; Zhou, Z.; Zhang, W.; Yu, Y.; Jin, H.; Li, Z. Cityflow: A multi-agent reinforcement learning environment for large scale city traffic scenario. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3620–3624. [Google Scholar]
- Tizhoosh, H.R. Reinforcement learning based on actions and opposite actions. In Proceedings of the International Conference on Artificial Intelligence and Machine Learning, Hong Kong, China, 14–16 November 2005. [Google Scholar]
- Branavan, S.R.; Chen, H.; Zettlemoyer, L.; Barzilay, R. Reinforcement learning for mapping instructions to actions. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 82–90. [Google Scholar]
- Matignon, L.; Laurent, G.J.; Le Fort-Piat, N. Reward function and initial values: Better choices for accelerated goal-directed reinforcement learning. In Proceedings of the Artificial Neural Networks–ICANN 2006: 16th International Conference, Athens, Greece, 10–14 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 840–849. [Google Scholar]
- Singh, S.; Jaakkola, T.; Littman, M.L.; Szepesvári, C. Convergence results for single-step on-policy reinforcement-learning algorithms. Mach. Learn. 2000, 38, 287–308. [Google Scholar] [CrossRef]
- Barreto, A.; Hou, S.; Borsa, D.; Silver, D.; Precup, D. Fast reinforcement learning with generalized policy updates. Proc. Natl. Acad. Sci. USA 2020, 117, 30079–30087. [Google Scholar] [CrossRef]
- Galatzer-Levy, I.R.; Ruggles, K.V.; Chen, Z. Data science in the Research Domain Criteria era: Relevance of machine learning to the study of stress pathology, recovery, and resilience. Chronic Stress 2018, 2, 2470547017747553. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Su, Y.; Liao, Y. The path planning of mobile robot by neural networks and hierarchical reinforcement learning. Front. Neurorobot. 2020, 14, 63. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Bianchi, R.A.; Ros, R.; Lopez de Mantaras, R. Improving reinforcement learning by using case based heuristics. In Proceedings of the Case-Based Reasoning Research and Development: 8th International Conference on Case-Based Reasoning, ICCBR 2009, Seattle, WA, USA, 20–23 July 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 75–89. [Google Scholar]
- Rahmani, A.M.; Ali, S.; Malik, M.H.; Yousefpoor, E.; Yousefpoor, M.S.; Mousavi, A.; Khan, F.; Hosseinzadeh, M. An energy-aware and Q-learning-based area coverage for oil pipeline monitoring systems using sensors and internet of things. Sci. Rep. 2022, 12, 9638. [Google Scholar] [CrossRef]
- Aihara, N.; Adachi, K.; Takyu, O.; Ohta, M.; Fujii, T. Q-learning aided resource allocation and environment recognition in LoRaWAN with CSMA/CA. IEEE Access 2019, 7, 152126–152137. [Google Scholar] [CrossRef]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A theoretical analysis of deep Q-learning. In Proceedings of the Learning for Dynamics and Control PMLR, Palo Alto, CA, USA, 10–11 June 2020; pp. 486–489. [Google Scholar]
- Brim, A. Deep reinforcement learning pairs trading with a double deep Q-network. In Proceedings of the 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0222–0227. [Google Scholar]
- Zhu, J.; Song, Y.; Jiang, D.; Song, H. A new deep-Q-learning-based transmission scheduling mechanism for the cognitive internet of things. IEEE Internet Things J. 2017, 5, 2375–2385. [Google Scholar] [CrossRef]
- Salh, A.; Audah, L.; Alhartomi, M.A.; Kim, K.S.; Alsamhi, S.H.; Almalki, F.A.; Abdullah, Q.; Saif, A.; Algethami, H. Smart packet transmission scheduling in cognitive IoT systems: DDQN based approach. IEEE Access 2022, 10, 50023–50036. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Li, S.; Bing, S.; Yang, S. Distributional advantage actor–critic. arXiv 2018, arXiv:1806.06914. [Google Scholar]
- Peng, B.; Li, X.; Gao, J.; Liu, J.; Chen, Y.N.; Wong, K.F. Adversarial advantage actor–critic model for task-completion dialogue policy learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6149–6153. [Google Scholar]
- Chen, G.; Xu, X.; Zeng, Q.; Zhang, Y.D. A Vehicle-Assisted Computation Offloading Algorithm Based on Proximal Policy Optimization in Vehicle Edge Networks. Mob. Netw. Appl. 2022, 1–15. [Google Scholar] [CrossRef]
- Li, K.; Ni, W.; Yuan, X.; Noor, A.; Jamalipour, A. Deep-Graph-Based reinforcement learning for Joint Cruise Control and Task Offloading for Aerial Edge internet of things (EdgeIoT). IEEE Internet Things J. 2022, 9, 21676–21686. [Google Scholar] [CrossRef]
- Qiu, C.; Hu, Y.; Chen, Y.; Zeng, B. Deep deterministic policy gradient (DDPG)-based energy harvesting wireless communications. IEEE Internet Things J. 2019, 6, 8577–8588. [Google Scholar] [CrossRef]
- Nie, L.; Sun, W.; Wang, S.; Ning, Z.; Rodrigues, J.J.; Wu, Y.; Li, S. Intrusion detection in green internet of things: A deep deterministic policy gradient-based algorithm. IEEE Trans. Green Commun. Netw. 2021, 5, 778–788. [Google Scholar] [CrossRef]
- Babaeizadeh, M.; Frosio, I.; Tyree, S.; Clemons, J.; Kautz, J. Reinforcement learning through asynchronous advantage actor–critic on a gpu. arXiv 2016, arXiv:1611.06256. [Google Scholar]
- Zare, M.; Sola, Y.E.; Hasanpour, H. Towards distributed and autonomous IoT service placement in fog computing using asynchronous advantage actor–critic algorithm. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 368–381. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the artificial intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Zhang, X.; Lu, R.; Shao, J.; Wang, F.; Zhu, H.; Ghorbani, A.A. FedSky: An efficient and privacy-preserving scheme for federated mobile crowdsensing. IEEE Internet Things J. 2021, 9, 5344–5356. [Google Scholar] [CrossRef]
- Hao, M.; Li, H.; Luo, X.; Xu, G.; Yang, H.; Liu, S. Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Trans. Ind. Inf. 2019, 16, 6532–6542. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Federated learning for data privacy preservation in vehicular cyber-physical systems. IEEE Netw. 2020, 34, 50–56. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, G.P.; Tripathi, R. PEFL: Deep Privacy-Encoding based federated learning Framework for Smart Agriculture. IEEE Micro 2021, 42, 33–40. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Zhu, L.; Paik, H.Y.; Xu, X.; Wang, C. Architectural patterns for the design of federated learning systems. J. Syst. Softw. 2022, 191, 111357. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Zou, T.; Pu, Y.; He, Y.; Ye, X.; Ouyang, Y.; Zhang, Y.Q.; Yang, Q. Vertical federated learning. arXiv 2022, arXiv:2211.12814. [Google Scholar]
- Chen, T.; Jin, X.; Sun, Y.; Yin, W. Vafl: A method of vertical asynchronous federated learning. arXiv 2020, arXiv:2007.06081. [Google Scholar]
- Liu, Y.; Zhang, X.; Wang, L. Asymmetrical vertical federated learning. arXiv 2020, arXiv:2004.07427. [Google Scholar]
- Gao, D.; Ju, C.; Wei, X.; Liu, Y.; Chen, T.; Yang, Q. Hhhfl: Hierarchical heterogeneous horizontal federated learning for electroencephalography. arXiv 2019, arXiv:1909.05784. [Google Scholar]
- Karimireddy, S.P.; Jaggi, M.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.U.; Suresh, A.T. Breaking the centralized barrier for cross-device federated learning. Adv. Neural Inf. Process. Syst. 2021, 34, 28663–28676. [Google Scholar]
- ur Rehman, M.H.; Dirir, A.M.; Salah, K.; Damiani, E.; Svetinovic, D. TrustFed: A framework for fair and trustworthy cross-device federated learning in IIoT. IEEE Trans. Ind. Inf. 2021, 17, 8485–8494. [Google Scholar] [CrossRef]
- Yang, W.; Wang, N.; Guan, Z.; Wu, L.; Du, X.; Guizani, M. A practical cross-device federated learning framework over 5g networks. IEEE Wirel. Commun. 2022, 29, 128–134. [Google Scholar] [CrossRef]
- Huang, C.; Huang, J.; Liu, X. Cross-Silo federated learning: Challenges and Opportunities. arXiv 2022, arXiv:2206.12949. [Google Scholar]
- Huang, Y.; Chu, L.; Zhou, Z.; Wang, L.; Liu, J.; Pei, J.; Zhang, Y. Personalized cross-silo federated learning on non-iid data. In Proceedings of the AAAI Conference on artificial intelligence, Online, 2–9 February 2021; pp. 7865–7873. [Google Scholar]
- Jiang, Z.; Wang, W.; Liu, Y. Flashe: Additively symmetric homomorphic encryption for cross-silo federated learning. arXiv 2021, arXiv:2109.00675. [Google Scholar]
- Zhang, Y.; Zeng, D.; Luo, J.; Xu, Z.; King, I. A Survey of Trustworthy federated learning with Perspectives on Security, Robustness, and Privacy. arXiv 2023, arXiv:2302.10637. [Google Scholar]
- Yang, Z.; Shi, Y.; Zhou, Y.; Wang, Z.; Yang, K. Trustworthy federated learning via blockchain. IEEE Internet Things J. 2022, 10, 92–109. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Marchal, S.; Miettinen, M.; Fereidooni, H.; Asokan, N.; Sadeghi, A.R. DÏoT: A federated self-learning anomaly detection system for IoT. In Proceedings of the IEEE 39th International conference on distributed computing systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; pp. 756–767. [Google Scholar]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated-learning-based anomaly detection for iot security attacks. IEEE Internet Things J. 2021, 9, 2545–2554. [Google Scholar] [CrossRef]
- Zhang, C.; Li, M.; Wu, D. Federated Multidomain Learning With Graph Ensemble Autoencoder GMM for Emotion Recognition. IEEE Trans. Intell. Transp. Syst. 2022. Early Access. [Google Scholar] [CrossRef]
- Hamid, O.H. Data-Centric and Model-Centric AI: Twin Drivers of Compact and Robust Industry 4.0 Solutions. Appl. Sci. 2023, 13, 2753. [Google Scholar] [CrossRef]
- Hamid, O.H.; Braun, J. Reinforcement learning and attractor neural network models of associative learning. In Proceedings of the Computational Intelligence: 9th International Joint Conference, IJCCI 2017, Funchal, Portugal, 1–3 November 2017; Springer: Berlin/Heidelberg, Germany, 2019; pp. 327–349. [Google Scholar]
- Espeholt, L.; Soyer, H.; Munos, R.; Simonyan, K.; Mnih, V.; Ward, T.; Doron, Y.; Firoiu, V.; Harley, T.; Dunning, I.; et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 25–31 July 2018; pp. 1407–1416. [Google Scholar]
- Hoffman, M.W.; Shahriari, B.; Aslanides, J.; Barth-Maron, G.; Momchev, N.; Sinopalnikov, D.; Stańczyk, P.; Ramos, S.; Raichuk, A.; Vincent, D.; et al. Acme: A research framework for distributed reinforcement learning. arXiv 2020, arXiv:2006.00979. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Proceedings of the Computer Security–ESORICS 2020: 25th European Symposium on Research in Computer Security, ESORICS 2020, Guildford, UK, 14–18 September 2020; Part I 25. Springer: Berlin/Heidelberg, Germany, 2020; pp. 480–501. [Google Scholar]
- Lim, H.K.; Kim, J.B.; Heo, J.S.; Han, Y.H. Federated reinforcement learning for training control policies on multiple IoT devices. Sensors 2020, 20, 1359. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Liu, Y.; Chen, T.; Liu, M.; Yang, Q. Federated transfer reinforcement learning for autonomous driving. In Federated and Transfer Learning; Springer: Berlin/Heidelberg, Germany, 2022; pp. 357–371. [Google Scholar]
- Ali, R.; Zikria, Y.B.; Garg, S.; Bashir, A.K.; Obaidat, M.S.; Kim, H.S. A federated reinforcement learning framework for incumbent technologies in beyond 5G networks. IEEE Netw. 2021, 35, 152–159. [Google Scholar] [CrossRef]
- Rjoub, G.; Bentahar, J.; Wahab, O.A. Explainable AI-based federated deep reinforcement learning for Trusted Autonomous Driving. In Proceedings of the 2022 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2022; pp. 318–323. [Google Scholar]
- Na, S.; Krajník, T.; Lennox, B.; Arvin, F. Federated reinforcement learning for Collective Navigation of Robotic Swarms. arXiv 2022, arXiv:2202.01141. [Google Scholar] [CrossRef]
- Otoum, S.; Guizani, N.; Mouftah, H. Federated reinforcement learning-supported IDS for IoT-steered healthcare systems. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Virtual, 4–23 June 2021; pp. 1–6. [Google Scholar]
- Zhu, R.; Li, M.; Liu, H.; Liu, L.; Ma, M. Federated deep reinforcement learning-Based Spectrum Access Algorithm With Warranty Contract in Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1178–1190. [Google Scholar] [CrossRef]
- Tiwari, P.; Lakhan, A.; Jhaveri, R.H.; Gronli, T.M. Consumer-Centric Internet of Medical Things for Cyborg Applications based on federated reinforcement learning. IEEE Trans. Consum. Electron. 2023. Early Access. [Google Scholar] [CrossRef]
- Li, F.; Shen, B.; Guo, J.; Lam, K.Y.; Wei, G.; Wang, L. Dynamic spectrum access for internet-of-things based on federated deep reinforcement learning. IEEE Trans. Veh. Technol. 2022, 71, 7952–7956. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for 5G beyond. IEEE Netw. 2020, 35, 219–225. [Google Scholar] [CrossRef]
- Tiwari, M.; Misra, S.; Bishoyi, P.K.; Yang, L.T. Devote: Criticality-aware federated service provisioning in fog-based iot environments. IEEE Internet Things J. 2021, 8, 10631–10638. [Google Scholar] [CrossRef]
- Xu, Y.; Bhuiyan, M.Z.A.; Wang, T.; Zhou, X.; Singh, A.K. C-fdrl: Context-aware privacy-preserving offloading through federated deep reinforcement learning in cloud-enabled IoT. IEEE Trans. Ind. Inf. 2022, 19, 1155–1164. [Google Scholar] [CrossRef]
- Miao, Q.; Lin, H.; Wang, X.; Hassan, M.M. Federated deep reinforcement learning based secure data sharing for internet of things. Comput. Netw. 2021, 197, 108327. [Google Scholar] [CrossRef]
- Zheng, J.; Li, K.; Mhaisen, N.; Ni, W.; Tovar, E.; Guizani, M. Exploring Deep-Reinforcement-Learning-Assisted federated learning for Online Resource Allocation in Privacy-Preserving EdgeIoT. IEEE Internet Things J. 2022, 9, 21099–21110. [Google Scholar] [CrossRef]
- Anwar, A.; Raychowdhury, A. Multi-task federated reinforcement learning with adversaries. arXiv 2021, arXiv:2103.06473. [Google Scholar]
- Nguyen, T.G.; Phan, T.V.; Hoang, D.T.; Nguyen, T.N.; So-In, C. Federated deep reinforcement learning for traffic monitoring in SDN-based IoT networks. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 1048–1065. [Google Scholar] [CrossRef]
- Wang, X.; Hu, J.; Lin, H.; Garg, S.; Kaddoum, G.; Piran, M.J.; Hossain, M.S. QoS and privacy-aware routing for 5G-enabled industrial internet of things: A federated reinforcement learning approach. IEEE Trans. Ind. Inf. 2021, 18, 4189–4197. [Google Scholar] [CrossRef]
- Huang, H.; Zeng, C.; Zhao, Y.; Min, G.; Zhu, Y.; Miao, W.; Hu, J. Scalable orchestration of service function chains in NFV-enabled networks: A federated reinforcement learning approach. IEEE J. Sel. Areas Commun. 2021, 39, 2558–2571. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X.; Zhou, Z.; Gong, X.; Wu, D. When deep reinforcement learning meets federated learning: Intelligent multitimescale resource management for multiaccess edge computing in 5G ultradense network. IEEE Internet Things J. 2020, 8, 2238–2251. [Google Scholar] [CrossRef]
- Xiaofeng Fan, F.; Ma, Y.; Dai, Z.; Jing, W.; Tan, C.; Low, B.K.H. Fault-Tolerant federated reinforcement learning with Theoretical Guarantee. arXiv 2021, arXiv:2110.14074v2. [Google Scholar]
- Rjoub, G.; Wahab, O.A.; Bentahar, J.; Cohen, R.; Bataineh, A.S. Trust-augmented deep reinforcement learning for federated learning client selection. Inf. Syst. Front. 2022, 1–18. [Google Scholar] [CrossRef]
- Raghu, A.; Komorowski, M.; Ahmed, I.; Celi, L.; Szolovits, P.; Ghassemi, M. Deep reinforcement learning for sepsis treatment. arXiv 2017, arXiv:1711.09602. [Google Scholar]
- Tahir, A.M.; Chowdhury, M.E.; Khandakar, A.; Rahman, T.; Qiblawey, Y.; Khurshid, U.; Kiranyaz, S.; Ibtehaz, N.; Rahman, M.S.; Al-Maadeed, S.; et al. COVID-19 infection localization and severity grading from chest X-ray images. Comput. Biol. Med. 2021, 139, 105002. [Google Scholar] [CrossRef] [PubMed]
- Qiu, D.; Xue, J.; Zhang, T.; Wang, J.; Sun, M. Federated reinforcement learning for smart building joint peer-to-peer energy and carbon allowance trading. Appl. Energy 2023, 333, 120526. [Google Scholar] [CrossRef]
- Jarwan, A.; Ibnkahla, M. Edge-Based federated deep reinforcement learning for IoT Traffic Management. IEEE Internet Things J. 2022, 10, 3799–3813. [Google Scholar] [CrossRef]
- Wu, D.; Ullah, R.; Harvey, P.; Kilpatrick, P.; Spence, I.; Varghese, B. Fedadapt: Adaptive offloading for iot devices in federated learning. IEEE Internet Things J. 2022, 9, 20889–20901. [Google Scholar] [CrossRef]
- Zang, L.; Zhang, X.; Guo, B. Federated deep reinforcement learning for online task offloading and resource allocation in WPC-MEC networks. IEEE Access 2022, 10, 9856–9867. [Google Scholar] [CrossRef]
- Ren, J.; Wang, H.; Hou, T.; Zheng, S.; Tang, C. Federated learning-Based Computation Offloading Optimization in Edge Computing-Supported internet of things. IEEE Access 2019, 7, 69194–69201. [Google Scholar] [CrossRef]
- Chen, X.; Liu, G. Federated deep reinforcement learning-based task offloading and resource allocation for smart cities in a mobile edge network. Sensors 2022, 22, 4738. [Google Scholar] [CrossRef]
- Zarandi, S.; Tabassum, H. Federated double deep Q-learning for joint delay and energy minimization in IoT networks. In Proceedings of the IEEE International Conference on Communications Workshops (ICC Workshops), Virtual, 14–15 June 2021; pp. 1–6. [Google Scholar]
- Guo, Q.; Tang, F.; Kato, N. Federated reinforcement learning-Based Resource Allocation in D2D-Enabled 6G. IEEE Netw. 2022. Early Access. [Google Scholar] [CrossRef]
- Tianqing, Z.; Zhou, W.; Ye, D.; Cheng, Z.; Li, J. Resource allocation in IoT edge computing via concurrent federated reinforcement learning. IEEE Internet Things J. 2021, 9, 1414–1426. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Luong, N.C.; Zhao, J.; Yuen, C.; Niyato, D. Resource allocation in mobility-aware federated learning networks: A deep reinforcement learning approach. In Proceedings of the IEEE 6th World Forum on internet of things (WF-IoT), New Orleans, LO, USA, 2–16 June 2020; pp. 1–6. [Google Scholar]
- Cui, Y.; Cao, K.; Wei, T. Reinforcement learning-Based Device Scheduling for Renewable Energy-Powered federated learning. IEEE Trans. Ind. Inf. 2022, 19, 6264–6274. [Google Scholar] [CrossRef]
- Gao, J.; Wang, W.; Campbell, B. Residential Energy Management System Using Personalized Federated deep reinforcement learning. In Proceedings of the 2022 21st ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Milano, Italy, 4–6 May 2022; pp. 541–542. [Google Scholar]
- Wang, X.; Wang, C.; Li, X.; Leung, V.C.; Taleb, T. Federated deep reinforcement learning for internet of things with decentralized cooperative edge caching. IEEE Internet Things J. 2020, 7, 9441–9455. [Google Scholar] [CrossRef]
- Majidi, F.; Khayyambashi, M.R.; Barekatain, B. Hfdrl: An intelligent dynamic cooperate cashing method based on hierarchical federated deep reinforcement learning in edge-enabled iot. IEEE Internet Things J. 2021, 9, 1402–1413. [Google Scholar] [CrossRef]
- Baghban, H.; Rezapour, A.; Hsu, C.H.; Nuannimnoi, S.; Huang, C.Y. Edge-AI: IoT Request Service Provisioning in Federated Edge Computing Using actor–critic reinforcement learning. IEEE Trans. Eng. Manag. 2022. Early Access. [Google Scholar] [CrossRef]
- Sethi, V.; Pal, S. FedDOVe: A Federated Deep Q-learning-based Offloading for Vehicular fog computing. Future Gener. Comput. Syst. 2023, 141, 96–105. [Google Scholar] [CrossRef]
- Hao, M.; Ye, D.; Wang, S.; Tan, B.; Yu, R. URLLC resource slicing and scheduling for trustworthy 6G vehicular services: A federated reinforcement learning approach. Phys. Commun. 2021, 49, 101470. [Google Scholar] [CrossRef]
- Shabir, B.; Rahman, A.U.; Malik, A.W.; Buyya, R.; Khan, M.A. A federated multi-agent deep reinforcement learning for vehicular fog computing. J. Supercomput. 2022, 79, 6141–6167. [Google Scholar] [CrossRef]
- Lee, W. Federated reinforcement learning-Based UAV Swarm System for Aerial Remote Sensing. Wirel. Commun. Mob. Comput. 2022, 2022, 4327380. [Google Scholar] [CrossRef]
- Salameh, H.B.; Alhafnawi, M.; Masadeh, A.; Jararweh, Y. Federated reinforcement learning approach for detecting uncertain deceptive target using autonomous dual UAV system. Inf. Process. Manag. 2023, 60, 103149. [Google Scholar] [CrossRef]
- Zhang, Q.; Wen, H.; Liu, Y.; Chang, S.; Han, Z. Federated-Reinforcement-Learning-Enabled Joint Communication, Sensing, and Computing Resources Allocation in Connected Automated Vehicles Networks. IEEE Internet Things J. 2022, 9, 23224–23240. [Google Scholar] [CrossRef]
- Ye, Y.; Zhao, W.; Wei, T.; Hu, S.; Chen, M. Fedlight: Federated reinforcement learning for autonomous multi-intersection traffic signal control. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 847–852. [Google Scholar]
- Kwon, D.; Jeon, J.; Park, S.; Kim, J.; Cho, S. Multiagent DDPG-based deep learning for smart ocean federated learning IoT networks. IEEE Internet Things J. 2020, 7, 9895–9903. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, Z.; He, K.; Lai, S.; Xia, J.; Fan, L. Efficient and flexible management for industrial internet of things: A federated learning approach. Comput. Netw. 2021, 192, 108122. [Google Scholar] [CrossRef]
- Lim, H.K.; Kim, J.B.; Ullah, I.; Heo, J.S.; Han, Y.H. Federated reinforcement learning acceleration method for precise control of multiple devices. IEEE Access 2021, 9, 76296–76306. [Google Scholar] [CrossRef]
- Ho, T.M.; Nguyen, K.K.; Cheriet, M. Federated deep reinforcement learning for task scheduling in heterogeneous autonomous robotic system. IEEE Trans. Autom. Sci. Eng. 2022. Early Access. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wu, W.; Peng, H.; Zhang, N.; Zhang, H.; Shen, X. Optimizing federated learning in distributed industrial IoT: A multi-agent approach. IEEE J. Sel. Areas Commun. 2021, 39, 3688–3703. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wu, W.; Peng, H.; Zhang, H.; Shen, X.S. Spectrum and computing resource management for federated learning in distributed industrial IoT. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Yang, W.; Xiang, W.; Yang, Y.; Cheng, P. Optimizing federated learning with deep reinforcement learning for digital twin empowered industrial IoT. IEEE Trans. Ind. Inf. 2022, 19, 1884–1893. [Google Scholar] [CrossRef]
- Sun, W.; Lei, S.; Wang, L.; Liu, Z.; Zhang, Y. Adaptive federated learning and digital twin for industrial internet of things. IEEE Trans. Ind. Inf. 2020, 17, 5605–5614. [Google Scholar] [CrossRef]
- Messaoud, S.; Bradai, A.; Ahmed, O.B.; Quang, P.T.A.; Atri, M.; Hossain, M.S. Deep federated Q-learning-based network slicing for industrial IoT. IEEE Trans. Ind. Inf. 2020, 17, 5572–5582. [Google Scholar] [CrossRef]
- Zeng, M.; Wang, X.; Pan, W.; Zhou, P. Heterogeneous Training Intensity for federated learning: A Deep reinforcement learning Approach. IEEE Trans. Netw. Sci. Eng. 2022, 10, 990–1002. [Google Scholar] [CrossRef]
- Pang, J.; Huang, Y.; Xie, Z.; Han, Q.; Cai, Z. Realizing the heterogeneity: A self-organized federated learning framework for IoT. IEEE Internet Things J. 2020, 8, 3088–3098. [Google Scholar] [CrossRef]
- Wang, X.; Garg, S.; Lin, H.; Hu, J.; Kaddoum, G.; Piran, M.J.; Hossain, M.S. Toward accurate anomaly detection in Industrial internet of things using hierarchical federated learning. IEEE Internet Things J. 2021, 9, 7110–7119. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, C.; Jiang, C.; Han, Z. Deep reinforcement learning assisted federated learning algorithm for data management of IIoT. IEEE Trans. Ind. Inf. 2021, 17, 8475–8484. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, Z.; Zhou, Z.; Wang, Y.; Zhang, H.; Zhang, G.; Ding, H.; Mumtaz, S.; Guizani, M. Blockchain and federated deep reinforcement learning Based Secure Cloud-Edge-End Collaboration in Power IoT. IEEE Wirel. Commun. 2022, 29, 84–91. [Google Scholar] [CrossRef]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 691–706. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep models under the GAN: Information leakage from collaborative deep learning. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 603–618. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Work | Domain | Technology | Research Purpose | Research Problem | Dataset | Year |
|---|---|---|---|---|---|---|---|
| 1 | Li et al. [94] | Wireless communication networks, dynamic spectrum access | FDRL | Optimizing spectrum allocation efficiency | Spectrum sharing optimization problem | Simulated data | 2022 |
| 2 | Lu et al. [95] | 5G networks | FL, blockchain, and 5G | Improving 5G networks, integration of blockchain and FL | Security, privacy, and scalability challenges of 5G networks | Simulated data | 2020 |
| 3 | Ali et al. [88] | Dynamic spectrum | FRL | Improved performance | Incumbent interference | Simulated environment | 2021 |
| 4 | Tiwari [96] | Fog computing and IoT | Federated computing | Service provisioning | Criticality management | Simulated data | 2021 |
| 5 | Xu et al. [97] | Cloud-enabled IoT | FDRL | Privacy-preserving offloading | Privacy preservation | Own dataset | 2022 |
| 6 | Miao et al. [98] | IoT and data sharing | FDRL | Secure data sharing | Secure and efficient data sharing | Simulated data | 2021 |
| 7 | Zheng et al. [99] | Edge computing and IoT | DRL, FL, and edge computing | Resource optimization | Privacy-preserving | Real-world dataset | 2022 |
| 8 | Anwar et al. [100] | Federated learning | FL, RL, and federated RL framework | Multi-task RL efficiency | Privacy-preserving federated learning | N/A | 2021 |
| 9 | Xue et al. [20] | Healthcare decision system | FL, edge computing, and RL | Privacy-preserving, clinical decision | Resource constraints, privacy, and clinical decision-making | MIMIC III dataset [107] | 2021 |
| 10 | Nguyen et al. [101] | Networking and IoT | FL, DRL, and SDN | Traffic monitoring optimization | Traffic monitoring scalability, and privacy | N/A | 2021 |
| 11 | Lim et al. [86] | SDN-based IoT networks | FRL, IoT, and SDN | IoT network optimization, automation | IoT control complexity, IoT network performance, and network management efficiency | Simulated environment | 2020 |
| 12 | Wang et al. [102] | Wireless IoT networks | FRL, IIoT, and 5G | Improve IIoT routing, improve IIoT communication | Routing, privacy, and QoS | Simulated data | 2021 |
| 13 | Xu et al. [22] | AI, multi-agent systems | MARL, FL, and cybersecurity | Secure multi-agent cyber-physical systems | Secure multi-agent collaboration and privacy-preserving incentives | FMNIST dataset | 2021 |
| 14 | Huang et al. [103] | Network function virtualization (NFV) and service function chain (SFC) | NFV, SFC, and FRL | NFV service orchestration and SFC orchestration enhancement | SFC inflexibility and scalability problem | Simulated data | 2021 |
| 15 | Yu et al. [104] | Networking and resource management | FL, DL, and multi-access edge computing | Optimizing network resources and edge computing, | Resource allocation optimization | Simulated environment | 2020 |
| 16 | Xiaofeng et al. [105] | Distributed systems and fault-tolerance | FRL, FL, and multi-agent systems | Secure FRL convergence, develop fault-tolerant FRL | Faulty agent resilience and faulty multi-agent learning | N/A | 2021 |
| 17 | Lim et al. [86] | Privacy preservation and IoT | FL, RL | Federated IoT control | Federated IoT control | Simulated environments | 2020 |
| 18 | rjoub et al. [106] | Federated ML trust | FL, IoT | Federated client selection, enhancing FL security | Client trustworthiness evaluation | COVID-19 radiography database [108] | 2022 |
| Number | Work | Domain | Technology | Goal | Year |
|---|---|---|---|---|---|
| 1 | Qiu et al. [109] | Multi-energy systems (MES) | Deep deterministic policy gradient and abstract critic network | Method to address the joint P2P energy and carbon trading (JPC) problem in a local community | 2023 |
| 2 | Jarwan et al. [110] | IoT traffic management | Advantage-actor–critic | Propose an edge-based backhaul selection to improve traffic delivery based on multi-objective feedback | 2022 |
| 3 | Wu et al. [111] | Offloading optimization | Proximal policy optimization (PPO) | Adaptive offloading FL framework to tackle efficiency challenges | 2022 |
| 4 | Zang et al. [112] | Offloading optimization | Federated DRL-based online task offloading and resource allocation (FDOR) | Online task offloading and resource allocation in WPC-MEC Networks | 2022 |
| 5 | Ren et al. [113] | Offloading optimization | Double deep Q-learning (DDQN) | FL and DRL to optmize IoT computation offloading | 2019 |
| 6 | Chen et al. [114] | Offloading optimization | Deep deterministic policy gradient (DDPG) | Task offloading and resource allocation | 2022 |
| 7 | Guo et al. [116] | Resource allocation | Deep Q-network (DQN) | FRL-based resource allocation in D2D-enabled 6G | 2022 |
| 8 | Tianqing et al. [117] | Resource allocation | Deep Q-network (DQN) | Resource allocation in IoT edge computing | 2022 |
| 9 | Nguyen et al. [118] | Resource allocation | Deep Q-network (DQN), Deep Q-learning (DQL), and double deep Q-network (DDQN) | Resource allocation in mobility-aware networks | 2020 |
| 10 | Zarandi et al. [115] | Offloading optimization | Double deep Q-network (DDQN) | Delay and energy minimization in IoT networks | 2021 |
| 11 | Cui et al. [119] | Energy management | Adapter multi-armed bandit (MAB) algorithm | Device scheduling for renewable energy-powered federated learning | 2022 |
| 12 | Gao et al. [120] | Energy management | Personalized deep federated reinforcement (PDRL) | Residential energy management system to tackle the standby energy reduction in residential buildings | 2022 |
| 13 | Wang et al. [121] | Caching | Double deep Q-network (DDQN) | Federated DRL-based cooperative edge caching (FADE) framework to enable collaborative learning of shared predictive models | 2020 |
| 14 | Majidi et al. [122] | Caching | Hierarchical federated deep reinforcement learning (HFDRL) | Prediction of user’s future requests to determine appropriate content replacement strategies | 2021 |
| 15 | Baghban et al. [123] | Service provision | Actor–critic (AC) reinforcement learning (RL) | Propose an RL-based request service provisioning system | 2022 |
| Number | Work | Domain | Technology | Goal | Year |
|---|---|---|---|---|---|
| 1 | Sethi et al. [124] | Offloading Optimization | Deep Q-learning | Optimize energy consumption across Roadside Units (RSUs) and load balancing across fog servers | 2022 |
| 2 | Hao et al. [125] | Offloading Optimization | Asynchronous Advantage actor–critic (A3C) | Resource slicing and scheduling for trustworthy 6G vehicular services | 2021 |
| 3 | Salameh et al. [128] | Search Cooperation | SARSA and Q-learning | Uncertain Deceptive Target Detection | 2023 |
| 4 | Lee et al. [127] | Aerial Remote Sensing | Proximal Policy Optimization (PPO) | Propose a UAV Swarm System for Aerial Remote Sensing | 2022 |
| 5 | Zhang et al. [129] | Offloading Optimization | Deep Reinforcement Learning (DRL) | Optimization of Resources Allocation in Connected Automated Vehicles Networks | 2022 |
| 6 | Ye et al. [130] | Traffic Control | Advantage actor–critic (A2C) | Autonomous Multi-Intersection Traffic Signal Control | 2021 |
| 7 | Shabir et al. [126] | Offloading Optimization | Asynchronous Advantage actor–critic (A3C) | Optimization of task-offloading decisions at multiple tiers in vehicular fog computing | 2022 |
| 8 | Kwon et al. [131] | Resource Allocation | Multiagent Deep Deterministic Policy Gradient (MADDPG) | Propose a method for joint cell association and resource allocation | 2020 |
| Number | Work | Domain | Technology | Research Purpose | Research Problem | Dataset | Year |
|---|---|---|---|---|---|---|---|
| 1 | Wang et al. [142] | IIoT | DRL, FL | Privacy preservation | Anomaly detection | Simulated data | 2022 |
| 2 | Yang et al. [137] | IIoT, digital twin, and industrial 4.0 | DRL, FL | Mitigation for data transmission Burden | Real-time device evaluation | MNIST data | 2022 |
| 3 | Zeng [140] | IoT | DRL, FL | Efficient improvement | Task assignment in FL | Simulated Data, MNIST, and CIFAR-10 | 2022 |
| 4 | Ho et al. [134] | Autonomous robotic system | DRL, proximal policy optimization | Efficient queue control | Task scheduling | Simulated data | 2022 |
| 5 | Zhang et al. [144] | Power internet of things (PioT) | DRL, FL, and blockchain | Data security, intelligent computation | Cloud-edge collaboration | Simulated data | 2022 |
| 6 | Guo et al. [132] | IIoT, mobile-edge computing | DRL, FL | Efficient resource allocation | Management optimization | Simulated data | 2021 |
| 7 | Sun et al. [138] | IIoT, digital twin | DRL, FL | Performance enhancement with resource constraints | Deviation reduction | MNIST data | 2021 |
| 8 | Messaoud et al. [139] | IIoT | DRL, deep federated Q-learning | Resource allocation, data sharing | Quality-of-service | Simulated data | 2021 |
| 9 | Zhang et al. [143] | IIoT, industrial 4.0 | DRL, FL | Efficient and secure data training | Training data management | MNIST, Fashion MNIST, and CIFAR-10 | 2021 |
| 10 | Lim et al. [133] | Robotics, autonomous driving | DRL | Control policy optimization | Multi-agent control and management | Simulated data and QUBE-servo system | 2021 |
| 11 | Zhang et al. [135] | IIoT | DRL, FL | Device assignment and resource allocation | On-device resource-consumption management | Simulated data | 2021 |
| 12 | Zhang et al. [136] | IIoT | DRL, FL | Efficient resource allocation | Management optimization | Simulated data | 2021 |
| 13 | Pang et al. [141] | IoT | DRL, FL | Efficient improvement | Task assignment in FL | MNIST, Fashion MNIST, and CIFAR-10 | 2020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinto Neto, E.C.; Sadeghi, S.; Zhang, X.; Dadkhah, S. Federated Reinforcement Learning in IoT: Applications, Opportunities and Open Challenges. Appl. Sci. 2023, 13, 6497. https://doi.org/10.3390/app13116497
Pinto Neto EC, Sadeghi S, Zhang X, Dadkhah S. Federated Reinforcement Learning in IoT: Applications, Opportunities and Open Challenges. Applied Sciences. 2023; 13(11):6497. https://doi.org/10.3390/app13116497
Chicago/Turabian StylePinto Neto, Euclides Carlos, Somayeh Sadeghi, Xichen Zhang, and Sajjad Dadkhah. 2023. "Federated Reinforcement Learning in IoT: Applications, Opportunities and Open Challenges" Applied Sciences 13, no. 11: 6497. https://doi.org/10.3390/app13116497
APA StylePinto Neto, E. C., Sadeghi, S., Zhang, X., & Dadkhah, S. (2023). Federated Reinforcement Learning in IoT: Applications, Opportunities and Open Challenges. Applied Sciences, 13(11), 6497. https://doi.org/10.3390/app13116497