1. Introduction
Cognitive conversation systems are becoming ubiquitous. They are present at many user’s devices or employed for offering company’s services and customer care through conversational interfaces. This increase in popularity is mainly due to an efficient interface build upon the most natural way of communication: speech. Commonly, one of the cornerstones of such systems is the speech-to-text (S2T) technology, in charge of properly transcribing the user’s speech into text. The resulting transcription is then further processed across the pipeline of a natural language engine, for example, to extract user’s intent. The previous design makes it difficult to recover from word errors or inaccurate sentences coming from the S2T interface. Furthermore, S2T modules tend to be highly complex, computationally expensive, and, most of the time, prohibitive for low-resourced or embedded devices. They are required to operate under both highly variable and noisy scenarios and, consequently, they are often specifically fine-tuned to efficiently tackle the diversity of vocabulary size, prosody, or background noises, among others, within a specific language domain. With the aim of avoiding such an excessive usage of resources along the inference stage, it is common to require the pronunciation of a wake-up word (WUW), which triggers the S2T functionality and the rest of conversational mechanisms. The WUW module is only supposed to discern between the trigger word itself and any other kind of acoustic input, thus becoming a two-class hypothesis test, or verification step, that translates into a less computationally and resource demanding system than an always-awake S2T model.
Despite its simplicity with respect to a large vocabulary automatic speech recognizer, the WUW model still needs to be robust enough to handle acoustic distractions, such as TV, music, or overlapping speech. Noisy environments impact the WUW’s performance both by waking-up unexpectedly, that translates into false alarm errors, and by not properly catching the trigger word, also known as miss errors. Those errors, especially false alarms, dramatically impact the user experience and reduce the user’s expectations on the technology and his/her engagement with it. Therefore, there are common approaches employed for improving robustness in WUW detection. Some of them are based on a second-step verification, typically an automatic speech recognition (ASR) model or a WUW model [
2,
3,
4,
5]. Other works incorporate a Speech Enhancement (SE) module that employs a dedicated stage, at the audio input, aiming to reduce noise and to obtain an improved version of the acoustic signal. SE tackles the task of improving the perceptual intelligibility and quality of speech by usually removing background noises [
6,
7]. Although it is typically applied for a better perceptual experience in telecommunications [
8] and hearing aids [
9], SE has also reported improved results, e.g., as a pre-processing step into the context of ASR systems [
10,
11,
12].
With respect to the WUW detection and keyword spotting tasks themselves, recent approaches have reported on the benefits of using the most advanced deep learning architectures. For instance, more recent works have introduced systems based on convolutional [
13], recurrent, [
14,
15,
16] and self-attention networks [
17]. Dealing with robustness and generalization for previous architectures, we can find a widespread strategy based on synthesizing training data by noise augmentation. Noise data augmentation techniques exploit a deep neural network’s appetite for vast amounts of data. They artificially corrupt the original samples, which usually translates into better performance figures, making the models to be more robust with regard to a bigger variety of noises or unseen scenarios. Similar approaches can be seen across different speech tasks, such as in keyword spotting [
18], in ASR [
19,
20], or in WUW detection [
21]. Therefore, we adopt similar ideas for our training data employed by all the classifiers described in this work. We artificially mix training samples with additive noise or by creating different kind of artifacts on the original speech, translating into similar findings on performance for our WUW task than those reported in previous works and for other speech tasks.
Classical SE methods, such as Wiener filtering [
22], spectral subtraction [
9], or subspace algorithms [
23], specialize in characterizing noise, so it can be reduced from the speech signal. However, such methods do not provide a robust performance against certain contaminations, such as non-stationary noises or overlapped speech. This gap has been addressed in the last few years with deep learning approaches, with some of them acting at the spectral level [
12,
24] and others directly at the waveform input signal [
25,
26]. One widespread architecture is the encoder-decoder–autoencoder. It can be found in Reference [
27], which additionally proposes the generative adversarial network paradigm [
28] and makes use of skip connections in the style of U-Net [
29]. Another popular model is proposed in Reference [
30], which operates at the waveform level, using a similar architecture but including a LSTM [
31] between the encoder and the decoder for hidden state sequence-to-sequence modeling. Nevertheless, many current approaches are commonly optimized by minimizing a regression loss in time, or by a combination with a spectrogram domain loss [
24,
30].
Motivated by the performance of such models, we propose to study the application and the effects of SE modules and techniques upon the performance of a WUW detection task, extending our previous work in such matter [
1]. We hypothesize that cleaning noisy speech with a dedicated SE front-end should be beneficial for a WUW detector. Aiming to validate the previous assumption, we cover different experimental scenarios in this work:
- (a)
The isolated classifier: just a WUW classifier is available, which is our baseline with no SE.
- (b)
The independent SE and WUW models: both systems are trained separately, thus training the SE model exclusively on waveform and spectral regression losses.
- (c)
The Task-Aware SE (TASE) through frozen WUW model: WUW model is trained beforehand, so it is plugged after the SE model during SE training. This way, the WUW detection logits are available, so the classification loss can be back-propagated at the SE model and summed up to the regression losses. The WUW detector is frozen at SE training.
- (d)
The end-to-end TASE (TASE-E2E) and WUW model training: both systems are jointly trained at the same time from scratch, optimizing the SE model with joint regression and classification losses.
Wrapping up, one of the main novelties on the present paper is the study of SE applied to WUW detection, which has not been reported in previous works, to the best of our knowledge. Furthermore, we propose a new loss that makes the SE model task-aware, enhancing the speech in order to maximize the performance later on at the WUW detection stage. This is achieved not only by back-propagating the regression loss from the SE module but also by adding the loss of the classification task from the WUW classifier; see
Figure 1. Aiming to generalize the results to several noise conditions, we train and test with different signal-to-noise (SNR) ratios, showing that the SE module is specially beneficial as noise increases. Furthermore, we also report the SE benefit obtained in different acoustic scenarios, such as a TV, office, or living room scenario, for instance.
2. Task-Aware Speech Enhancement
Speech enhancement of the voice assistant’s input is hypothesized to be beneficial for WUW detection. Firstly, removing background noise is supposed to lower the amount of false activations by reducing the variability in the input audio. Secondly, if enhancement is precisely done, speech is captured with higher intelligibility, thus making it easier to detect the trigger word. For the latter, the following sections report an exhaustive comparison of speech enhancement strategies. Furthermore, we introduce the TASE model, that optimizes the prediction loss of the subsequent WUW module, resulting in better figures than those from its task-agnostic counterpart. The resulting task-aware model not only enhances the speech signal but even removes the non-target speech or overlapped speech, that might be confusing for the trigger word detection. Finally, we make use of some of the most common noises found in domestic environments to simulate realistic acoustic conditions and train the different SE models at several SNR levels.
Model
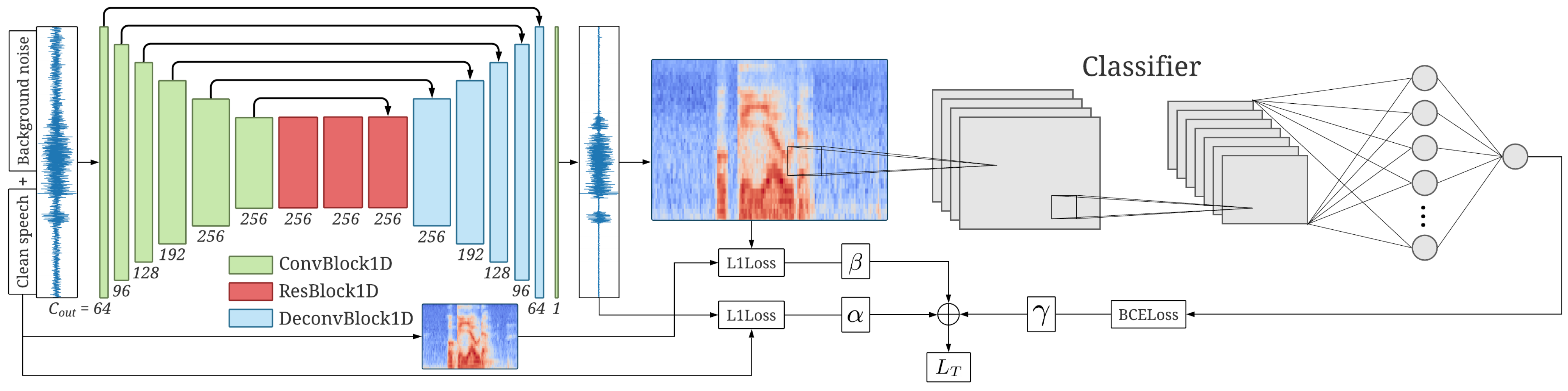
Our model is a fully-convolutional denoising autoencoder with skip connections (
Figure 1), in the style of previous effective SE models [
27,
30,
34]. In training, we input a noisy audio waveform
, comprised of clean speech signal
and background noise
so that
, where
is a parameter to control the SNR.
The encoder consists of six convolutional blocks (ConvBlock1D), each being a sequence of a convolutional layer, an instance normalization and a rectified linear unit (ReLU). Kernel size and stride are used, except in the first layer, where and . After the encoder, the compressed signal goes through three intermediate residual blocks (ResBlock1D) that preserve the shape, each formed by two ConvBlock1D with and . Skip connections are added from the input of each residual block to its output. The signal finally flows through the decoder, which follows the inverse structure of the encoder, where deconvolutional blocks (DeconvBlock1D) replace the convolutional layers of the ConvBlock1D with transposed convolutional layers. The output of the decoder is the enhanced signal with the shape of the input waveform, which is ready to be passed on to the WUW classifier. Both the encoder and decoder blocks are connected with skip connections to ensure that low-level details of the waveform are preserved.
The model is fully convolutional because this reduces the forward delay compared with the same architecture using a Recurrent Neural Network (RNN) to the latent representation of the audio.
Table 1 presents a comparison between state-of-the-art architectures and ours, in terms of number of parameters, operations, size, and forward delay. The measurements of the forward time have been done in the same conditions: same CPU and using the same input data, an audio of 1.5 s. We performed 100 forwards and then calculated the average forward time. For the architecture named “gruse”, we replaced the residual blocks that process the compressed signal of our architecture by a Gated Recurrent Unit (GRU) with a hidden size of 256. This produces a smaller model that carries out less operations, while considerably increasing the forward delay. Architectures demucs (H = 64 and H = 48) are from the work proposed in Reference [
30], and NSNet2 is the baseline network used for the Deep Noise Suppression Challenge [
35].
Optimization is guided with a regression loss function (L1 loss) at raw waveform level, together with another L1 loss over the log-mel spectrogram, as proposed in Reference [
36], to reconstruct the clean signal
at the output. Finally, we include the binary cross-entropy classification loss (BCE loss) of the WUW classifier in the TASE use-case. We either train the TASE model jointly with the WUW classifier from scratch, or we just concatenate a frozen pre-trained classifier at its output. In any case, the BCE loss is available to TASE to optimize itself toward WUW detection. Our final loss function is defined as a linear combination of the three losses:
where
,
, and
are hyperparameters weighting each loss term, and
denotes the log-mel spectrogram of the signal, which is computed using 512 FFT bins, a window of 20 ms with 10 ms of shift, and 40 filters in the mel scale.
3. Materials and Methods
3.1. Databases
The databases used for our experiments contain speech with either the WUW, “OK Aura”, or without it. On the one hand, WUW samples are drawn from two Telefónica’s in-house datasets, one of them being made publicly available for research purposes under End-User License Agreement (EULA). On the other hand, samples without the WUW are taken from the in-house public dataset itself and the Spanish Common Voice (CV) corpus [
37]. Background noise contamination is done to test the effectiveness of the speech enhancement models, and the acoustic events for doing so are sampled from further external datasets. More details about each dataset are given in the following subsections.
3.1.1. OK Aura Database
In-house data collection of WUW samples is done in two rounds. During the first round, ~4300 samples (2.8 h) from 360 speakers are collected, constituting the main bulk of positive WUW samples. Furthermore, office background ambient is recorded, as well, in order to obtain samples for posterior acoustic contamination.
The second round of data collection gathers 1247 utterances (1.4 h) from 80 speakers. It is designed with two purposes: (1) to address the main cases where Aura’s WUW classifiers typically under-perform and (2) to ask the participants to sign a consent form to make the data publicly available. Therefore, the dataset not only contains positive WUW samples but also other non-WUW samples that are phonetically similar to the WUW. Actually, sentences are scripted in different levels of similarity to the WUW:
The WUW itself: OK Aura.
The WUW within a context sentence: Perfecto, voy a mirar qué dan hoy. OK Aura.
Contains “Aura”: Hay un aura de paz y tranquilidad.
Contains “OK”: OK, a ver qué ponen en la tele.
Contains similar word units to “Aura”: Hola Laura.
Contains similar word units to “OK”: Prefiero el hockey al baloncesto.
Contains similar word units to “OK Aura”: Porque Laura, ¿qué te pareció la película?
Furthermore, knowing that WUW task performance depends on gender, age, and accent biases, plus other acoustic conditions, such as closeness to the microphone or room size, we also collect such metadata, as seen in
Table 2.
Data acquisition is done from a web-based form service called Jotform (
https://form.jotform.com/201694606537056, accessed on 1 February 2022). We actually encourage readers to contribute to the dataset while the form is still open. Meanwhile, the current dataset version has been published as the “OK Aura Wake-up Word Dataset” [
38], and it is publicly available (
https://zenodo.org/record/5734340, accessed on 1 February 2022) under request to any of the authors via EULA.
3.1.2. External Data
Most of the non-WUW samples are drawn from the validated set of the Spanish CV corpus [
37] (~300 h). However, we select a subset of 55 h for training, 7 h for development, and 7 h for testing. This way, we keep a ratio between negative and positive samples of 10:1, which showed good performance in Reference [
39]. Regarding background noises, we pick samples from a variety of public datasets, such as Free Music Archive (
https://freemusicarchive.org/, accessed on 1 February 2022), or Podcasts in Spanish (
https://www.podcastsinspanish.org/, accessed on 1 February 2022), in order to cover different acoustic scenarios (living room, TV, music, etc.), as shown in
Table 3.
3.1.3. Data Processing
The OK Aura Wake-up Word Dataset is comprised of monaural audio signals. They are stored in Waveform Audio File Format (WAV) by using a Pulse-Code Modulation (PCM) encoding with two bytes per sample at a rate of 16 kHz. All the external audio is also standardized to this format. The speech signal is processed with a Speech Activity Detection (SAD) module, producing timestamps where speech occurs and discarding fragments of inactivity. For this purpose, the tool from pyannote.audio [
42] is used, which has been trained with the AMI corpus [
43]. This is done to train only with valid speech segments from the collected audios.
The input to the speech enhancement module is the raw audio waveform. To train the model, the L1 regression loss is calculated at the log-mel spectrogram level and at the waveform level. In the case of concatenating the speech enhancement module with the WUW detector, it is the log-mel spectrogram obtained at the autoencoder output that is used as input for the WUW detector. The procedure for extracting the log-mel spectrogram (
) is detailed in
Section 2.
Training, validation, and test partitions are split, ensuring that neither speaker nor background noise is repeated between partitions, maintaining an 80-10-10 ratio, respectively. The total data, containing internal and external datasets, consists of 50,737 non-WUW samples and 4651 WUW samples.
3.2. Data Augmentation
For the purpose of training the system with representative noise samples of realistic scenarios of the device use case, several Room Impulse Responses (RIR) are created based on the Image Source Method [
44], for a room of dimensions
, where
m, with microphone and source randomly located at any
point within a height of
m. Every TV and music original recordings are convolved with different RIRs to simulate the noise signal picked up by the microphone of the device in a given room.
Although we have tested several data augmentation techniques, we have found that background noise addition is the most significant with respect to performance. Thus, we keep it as the main data augmentation technique in this work. Clean speech samples are combined with different noise recordings (TV, music, conversations, and office and living room noise) within a wide range of SNRs ( or dB SNR). This aims at improving the performance of the models against noisy environments. In each epoch, we create different noisy samples by randomly selecting a sample of background noise for each speech event and combining them with a randomly chosen SNR in a specified range. Other data augmentation techniques, such as time stretching, pitch shifting, cropping, clipping distortion, and fading with different probabilities, are discarded since no significant improvements are found in initial tests for very noisy scenarios.
3.3. Wake-Up Word Detection Models
With the purpose of measuring the quality of the task-aware SE models, we report the impact of the SE module on WUW detection performance using several trigger word detection models. Typically, the end device that runs the WUW detector model has constrained capabilities; thus, the forward delay is a relevant parameter to consider while selecting the architecture of the audio classifier. Bigger models tend to perform better but may lead to an undesired delay in the detection, propagating this delay to the whole conversational chain and, consequently, degrading the user experience.
As baseline classifier, a LeNet [
45] is used, a well-known convolutional neural network (CNN) composed of two convolution layers with ReLU activations and two pooling layers, followed by a final dense block consisting of two fully-connected layers.
Additionally, based on the work of Sainath and Parada [
13], which consists of the exploration of lightweight CNNs for keyword spotting, both limiting the number of operations and the number of parameters, and the Tang and Lin’s re-implementation in PyTorch [
46], we use the cnn-trad-pool2 architecture. This model consists of two convolutional layers, each one followed by pooling in time and frequency. Tang and Lin also worked with deep residual networks combined with dilated convolutions [
47], obtaining comparable results with other CNN-based architectures and giving the possibility to vary the depth and width to achieve small footprint architectures. From this work we use resnet15, resnet15-narrow, and resnet8, which have 15, 15, and 8 ResNet blocks and 45, 19, and 45 feature maps, respectively.
To continue with, we also use two RNN-based models based on the open source tool named Mycroft Precise [
48], which is a lightweight WUW detection tool implemented in TensorFlow. Named as SGRU and SGRU2, these are two bigger variations that we have implemented in PyTorch. The first one has a single GRU with a hidden size of 200, and the second one has two GRUs with a hidden size of 100.
Finally, we adapt an architecture from a kernel [
49] in Kaggle’s FAT 2019 competition [
50], named as CNN-FAT2019, which has shown good performance in tasks, such as audio tagging or detection of gender, identity, and speech events from pulse signal [
51]. This is the biggest architecture used, and it is conformed by eight convolutional layers with ReLU activations, with pooling layers every two convolutional layers.
In
Table 4, we present the number of parameters, operations (multiplications and additions), and the size of every keyword detection architecture used. RNN-based networks are the smallest, and ResNet-based architectures show the variability of operations and parameters, depending on the depth and width.
3.4. Training
Speech utterances are segmented with a fixed window length of
s, which is typically enough to cover the average duration of the WUW, which is
s, based on the SAD timestamps. Speech is combined randomly with background noises, following the procedure explained in
Section 3.2, with a given SNR range. The SE model is trained to cover a wide SNR range of
dBs, whereas WUW models are trained to cover two scenarios: a classifier trained with the same SNR range as the SE model, and a classifier less aware of noise with a narrower SNR range of
dBs. This way, it is possible to study the impact of the SE model regarding whether or not the classifier has been trained with more or less noise.
We address data imbalance by balancing the classes in each batch using a weighted sampler. Besides, batching is done to ensure that negative samples from the OK Aura dataset are always present at each batch. This way, we increase the representation of negative samples which are phonetically similar to the WUW during training.
The loss in Equation (
1) allows us to train the models in multiple ways, and we define different SE models and classifiers based on the loss function used:
- (a)
Isolated classifier: we remove the autoencoder from the architecture (
Figure 1) and train any of the classifiers using the noisy audio as input:
and
.
- (b)
Separate SE and classifier: we remove the classifier from the architecture and optimize the autoencoder based on the reconstruction losses only: and .
- (c)
Task-aware SE (TASE): operations of a frozen pretrained classifier are only backpropagated to the SE model, which is optimized with the reconstruction losses altogether: .
- (d)
End-to-end TASE (TASE-E2E): autoencoder and classifier are trained jointly using the three losses: .
All the models are trained with early stopping based on the validation loss with 60 epochs of patience, for a maximum number of 200 epochs. Additionally, the learning rate decreases in an order of magnitude if there is not improvement in 20 consecutive epochs. We use the Adam optimizer starting with a learning rate of in the E2E case and for the rest, always using a batch size of 50.
3.5. Testing
The following test results are reported, such as for a binary classification task or hypothesis test, that is, by evaluating whether the WUW is contained within a single time window or not. For synthesizing the testing data, both the negative and positive samples are combined with a background noise, by summing it up with a specific SNR level to the original waveform; see
Section 3.4 for further details.
Given the output probabilities from a model, the decision threshold is chosen as the one yielding the biggest difference between true and false positive rates, based on Youden’s J statistic [
52]. Once the threshold is decided, F1-score is computed to analyze and compare models. We compute such scores across all WUW classifiers described in
Section 3.3 and for every SNR range.
Additionally and for the sake of comparison, we also report the objective metrics PESQ [
53] and STOI [
54] on the Valentini et al. [
55] benchmark. This dataset is composed of both clean and noisy speech in English and uses a total of 15 different background noises (e.g., babble, metro, and restaurant). From the noisy test set, we randomly select two seconds of each audio clip that have been enhanced with SE models and then we measure PESQ and STOI.
4. Results
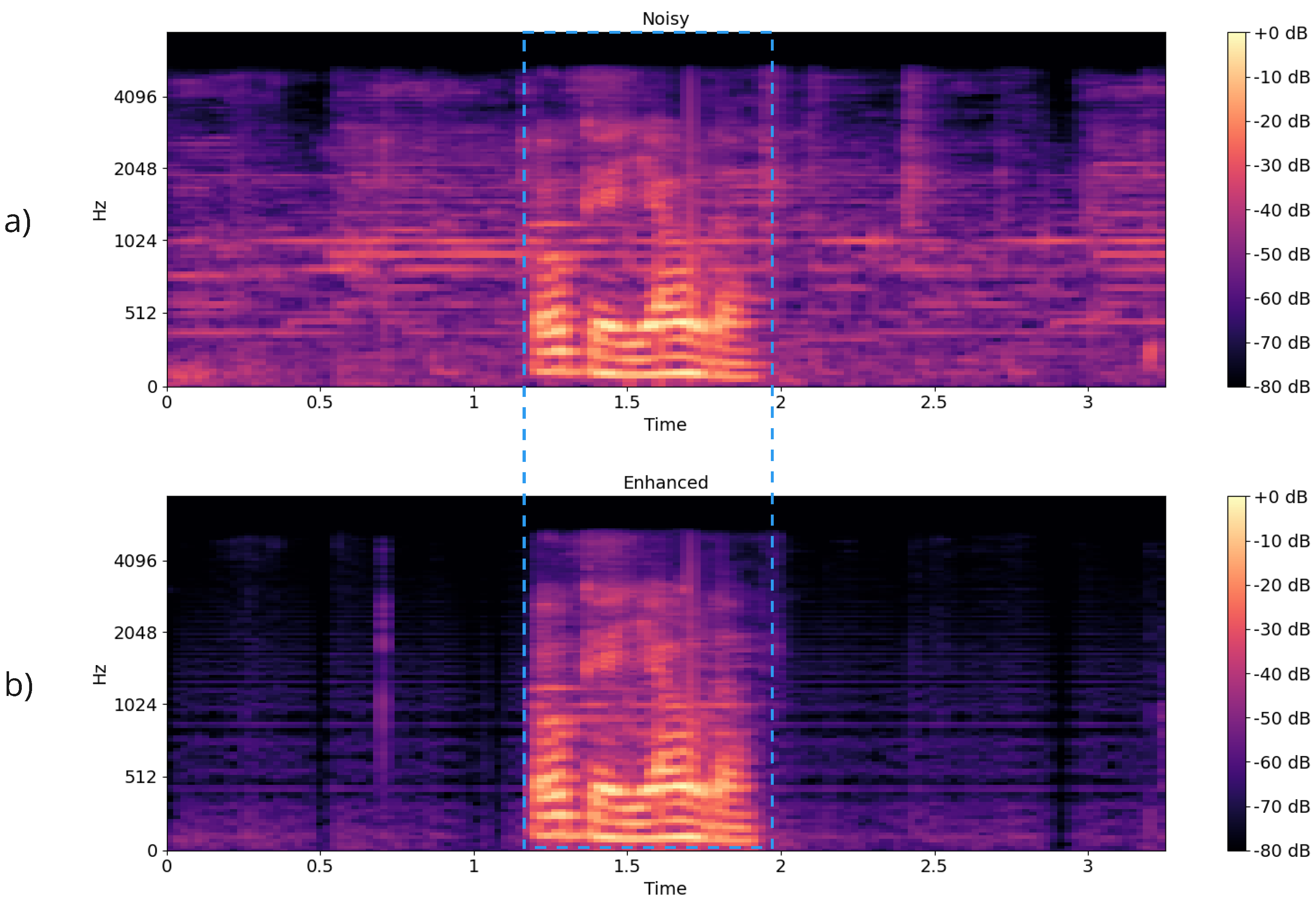
Figure 2 shows an example of speech enhanced spectrogram using the TASE architecture. The audio combines background music with the keyword between 1.15 and 1.95 s, and the enhanced audio completely preserves the speech relevant information for the posterior classification.
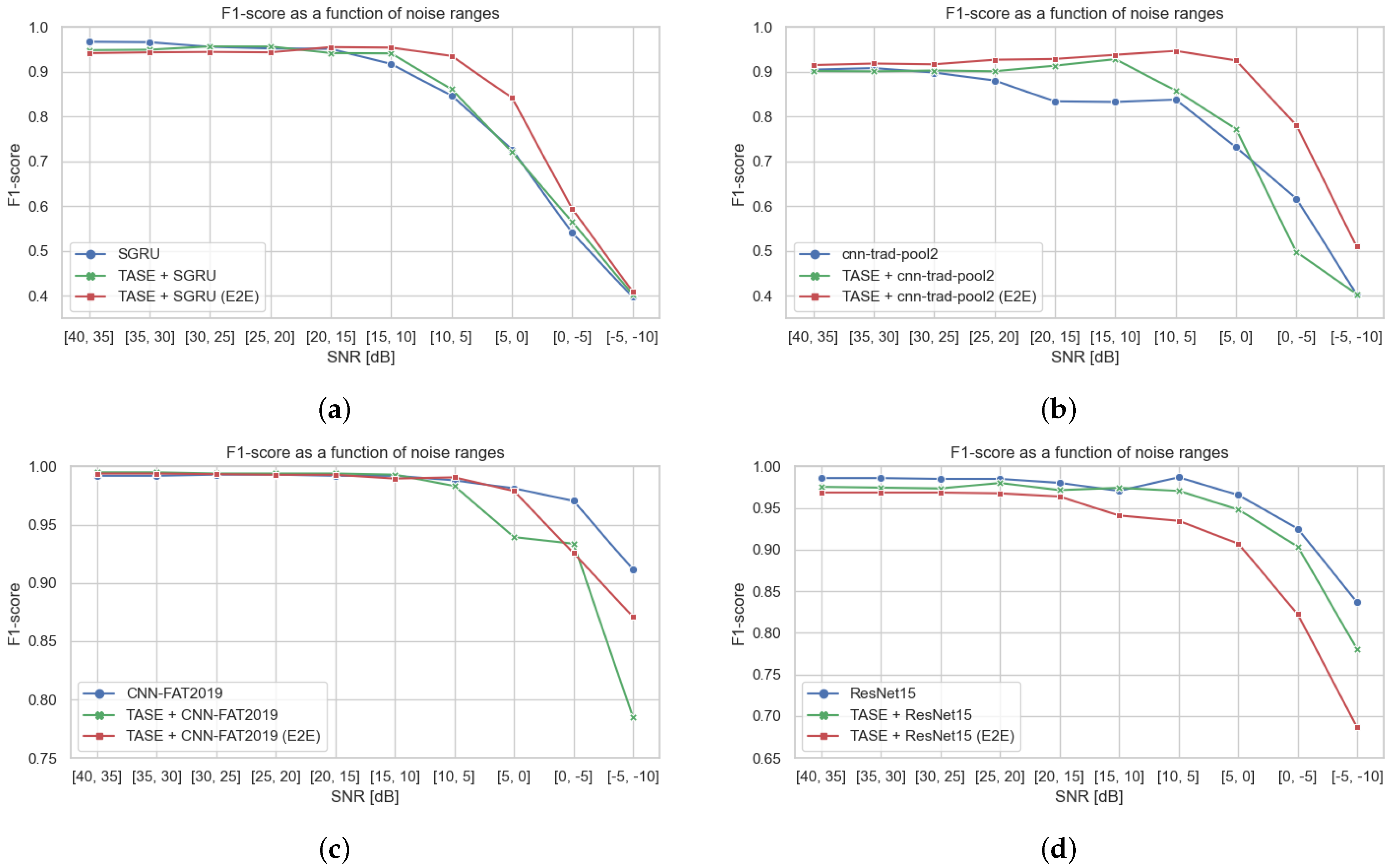
Figure 3a–d show the behavior of TASE when plugged to some of the different WUW classifiers described in
Section 3.3. We find that TASE is notably beneficial to models, such as SGRU or cnn-trad-pool2, which present lowest robustness to noise, as compared to ResNet15 or CNN-FAT2019, where TASE yields equal or worse performance at some noise ranges. We hypothesize that ResNet15 and CNN-FAT2019 do not benefit of the speech enhancement as much, since they are bigger and more complex architectures that already handle the nuances of noise with more precision. However, an exhaustive fine-tuning of hyperparameters has not been done for every architecture, as we have prioritized covering more models, instead of deeply fine-tuning a few ones, due to computational restrictions. Therefore, we do not discard that our default hyperparameter choice might be biased toward certain architectures, yielding worse performances for cases, such as the TASE-E2E in ResNet15. Detailed metrics for SGRU and cnn-trad-pool2 can be found in
Table A1 and
Table A2.
Furthermore,
Figure 4 shows the improvement of the WUW detection in noisy scenarios by concatenating our TASE model with the remaining classifiers described in
Section 3.3 that are neither large nor robust to noise (SGRU2, ResNet8, ResNet15-narrow), plus LeNet, which architecture has not been fine-tuned for audio tasks. Classifiers are trained with low noise (
dB SNR), to simulate a voice assistant system that has not been exposed to overwhelming amounts of noise at training. Applying SE in quiet scenarios maintains fairly good results and, especially, improves the models in lower SNR ranges.
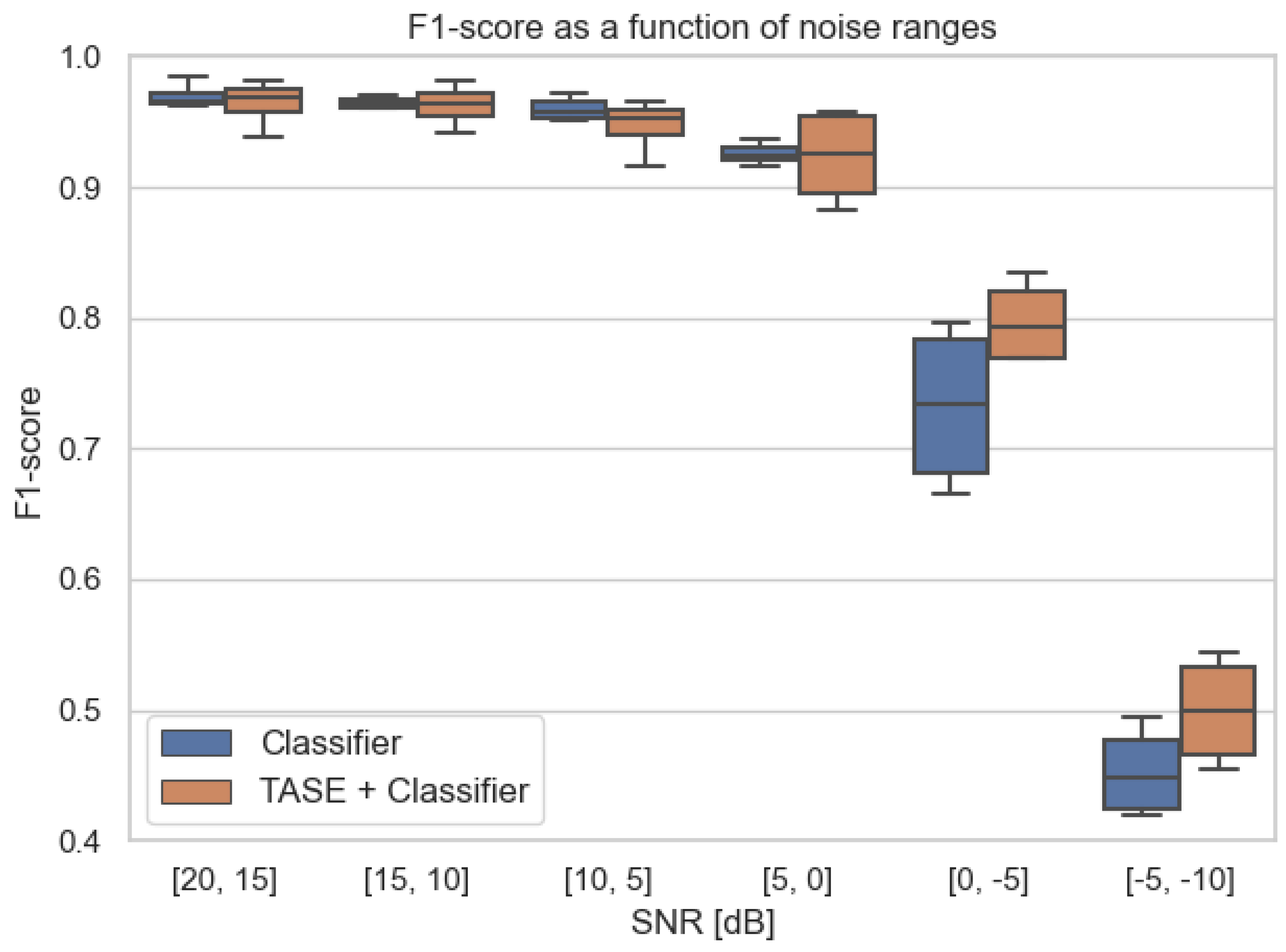
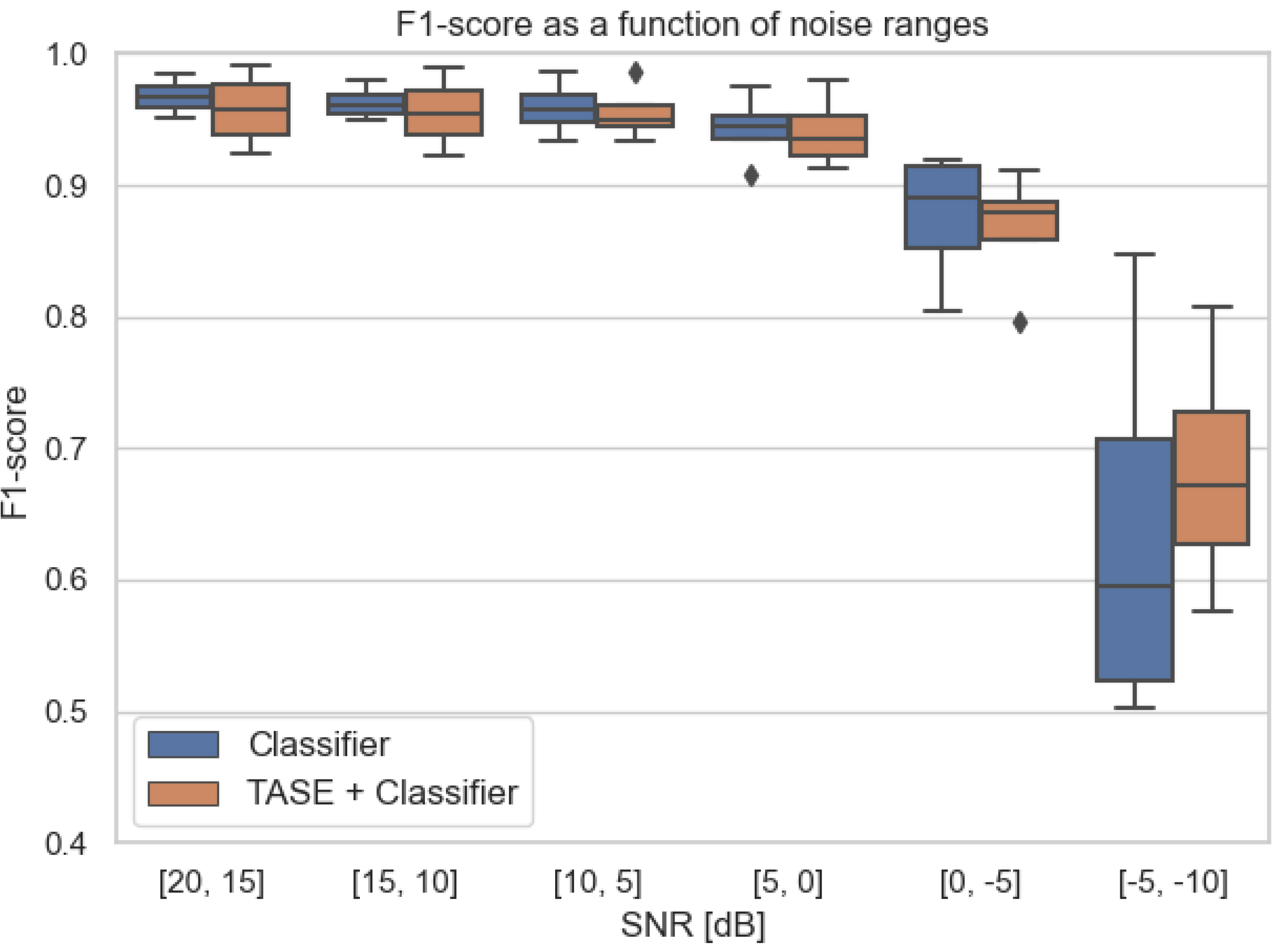
Nonetheless, in the case when the classifiers are trained with a wider SNR range (
dB SNR) by data augmentation, the performance gap between using TASE or not using is significantly reduced. F1-scores between both choices are on par for most of the SNR ranges. The noisiest range of
dB SNR shows a small advantage for the model with respect to TASE, but it is not as large as the averaged improvement reported in
Figure 4; see
Figure 5.
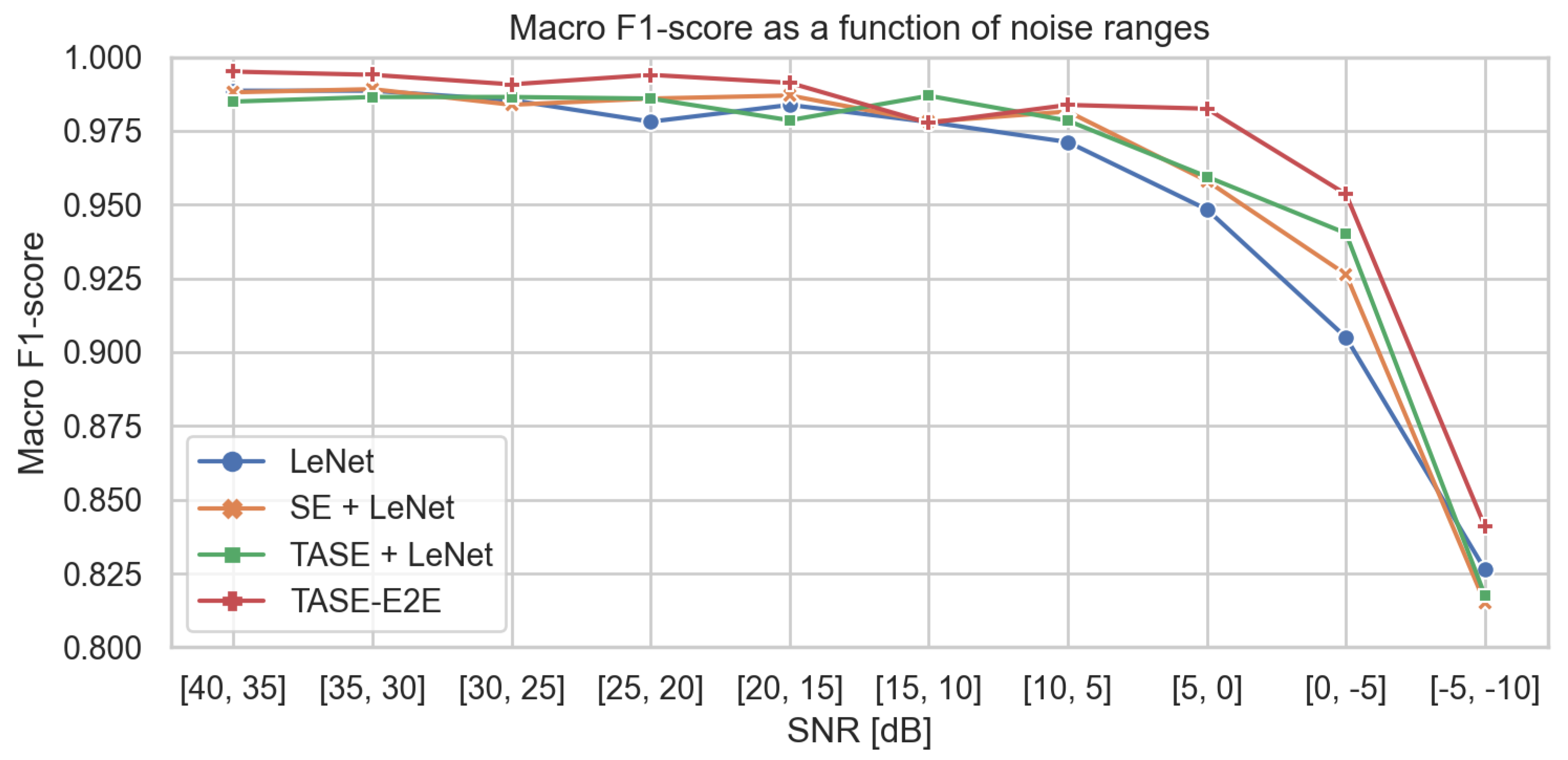
In
Section 3.4, we have defined the parameters of the loss function (
1) to train a classifier (see case (a) in
Section 1 list), and three different approaches to train the SE model: standalone (b) or coupled with the classifier (c, d). In
Figure 6, we analyze all the cases using a LeNet as WUW detector. We see how TASE-E2E performs better than all the other cases in almost every SNR range. From 40 dB to 10 dB of SNR, the results are very similar for the 4 models. In contrast, in the noisiest ranges the classifiers without SE model are the worst performers, followed by the separate SE case where only the waveform and spectral reconstruction losses are used. We find that the TASE case, which includes the classification loss in the training stage, improves the results for the WUW detection task. However, the best results are obtained with the TASE-E2E case, where the SE models and the classifiers are trained jointly using all three losses.
We compare the WUW detection results of TASE-E2E with other state-of-the-art SE models (SEGAN [
27] and Denoiser [
30]), followed by a classifier (data augmented LeNet) in different noise scenarios. In
Table 5, it can be observed that, when training the models together with the task loss, the results in our setup are better than with other, more powerful, but more general, SE models. We hypothesize that this is due to the natural adaptation of the SE to the classifier during the end-to-end training, as well as having been trained with a focus on common home noises. TASE-E2E improves the detection over the no SE model case, especially in scenarios with background conversations, loud office noise, or loud TV; see
Table 6.
Table 7 shows that our SE system does not improve speech quality with respect to the case where we do not use any model to enhance speech. This was expected because our models have not been trained to remove generic background noises that the Valentini dataset contains. Instead, we train an SE system to learn to remove background conversations and TV noise that could trigger the device, which can lead to speech deterioration for the Valentini data. Nevertheless, we observe that PESQ improves in the case of TASE coupled with a LeNet classifier compared with SE, and the best results are obtained in the end-to-end case, where the PESQ and STOI results obtained without an SE module are preserved. This demonstrates that the consideration of the classification task in the loss improves the capacity of the SE model to clean speech.
5. Conclusions
To the best of our knowledge, we have reported the first exploration of neural-based speech enhancement applied to wake-up word detection, and we validated its benefits with respect to classification performance. Furthermore, we proposed a way of making the SE module task-aware, by back-propagating the classification loss of the WUW model along the training. We call this task-aware speech enhancement (TASE), and it yields even further improvements than training SE and WUW modules separately. We show that TASE can be done by freezing the WUW module during SE training, or jointly training both from scratch, which we call end-to-end task-aware speech enhancement (TASE-E2E). The latter reports the best classification performance results of all the setups studied herein. Across all the experiments, we find that gains from SE are especially significant at noisier SNR ranges, between 10 and −10 dBs. We have also evaluated the effectiveness of such SE techniques when compared to a standalone WUW classifier that has been trained on a wide SNR range between 50 and −10 dBs. In that case, the results between applying TASE or not using it are on par, with TASE having a slight advantage in the most severely noisy setups, that is, between −5 and −10 dBs SNR. Thus, we have reported the potential of TASE at improving the performance of standard neural net classifiers that are not specifically trained to be resilient to noise, and we encourage further experiments in the comparison between speech enhancement and noise data augmentation techniques. Finally, as we have corroborated our hypotheses with a manually segmented corpus, we motivate further work for the online streaming case, with the aim to explore the particularities and challenges that may arise in such a setup.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}