
Semantic Segmentation and Building Extraction from Airborne LiDAR Data with Multiple Return Using PointNet++


Abstract
:1. Introduction
2. Datasets and Method
2.1. Description of Datasets
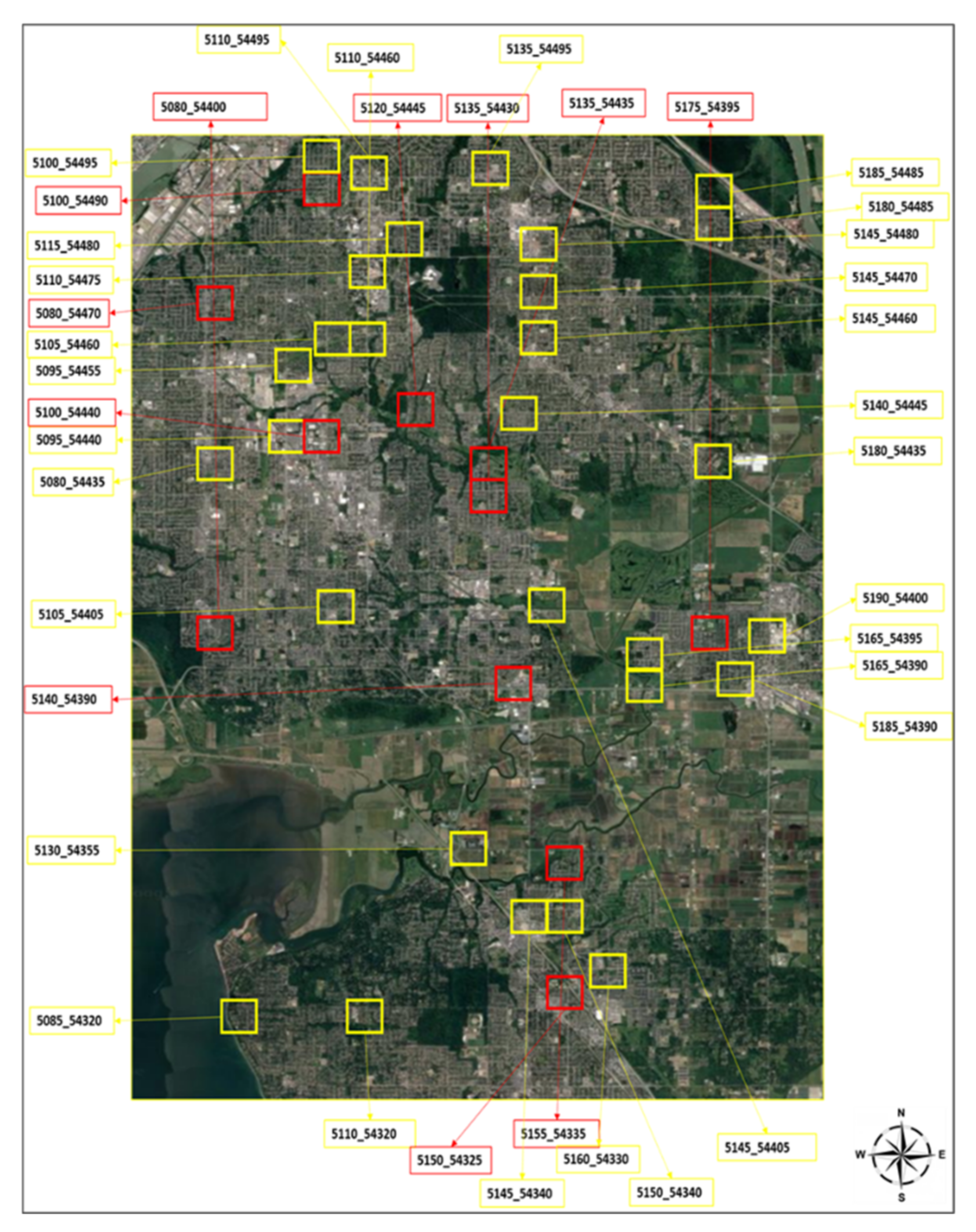
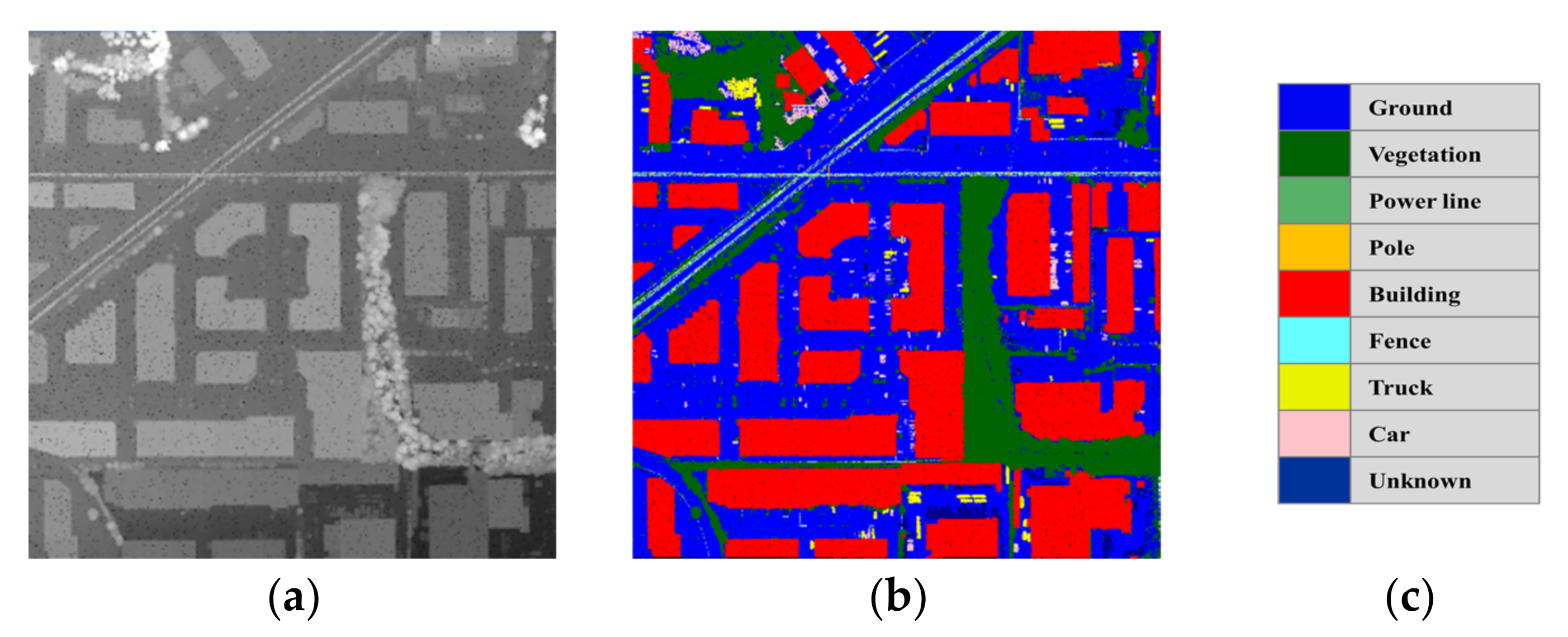
2.1.1. DALES Datasets
2.1.2. ISPRS Vaihingen Datasets
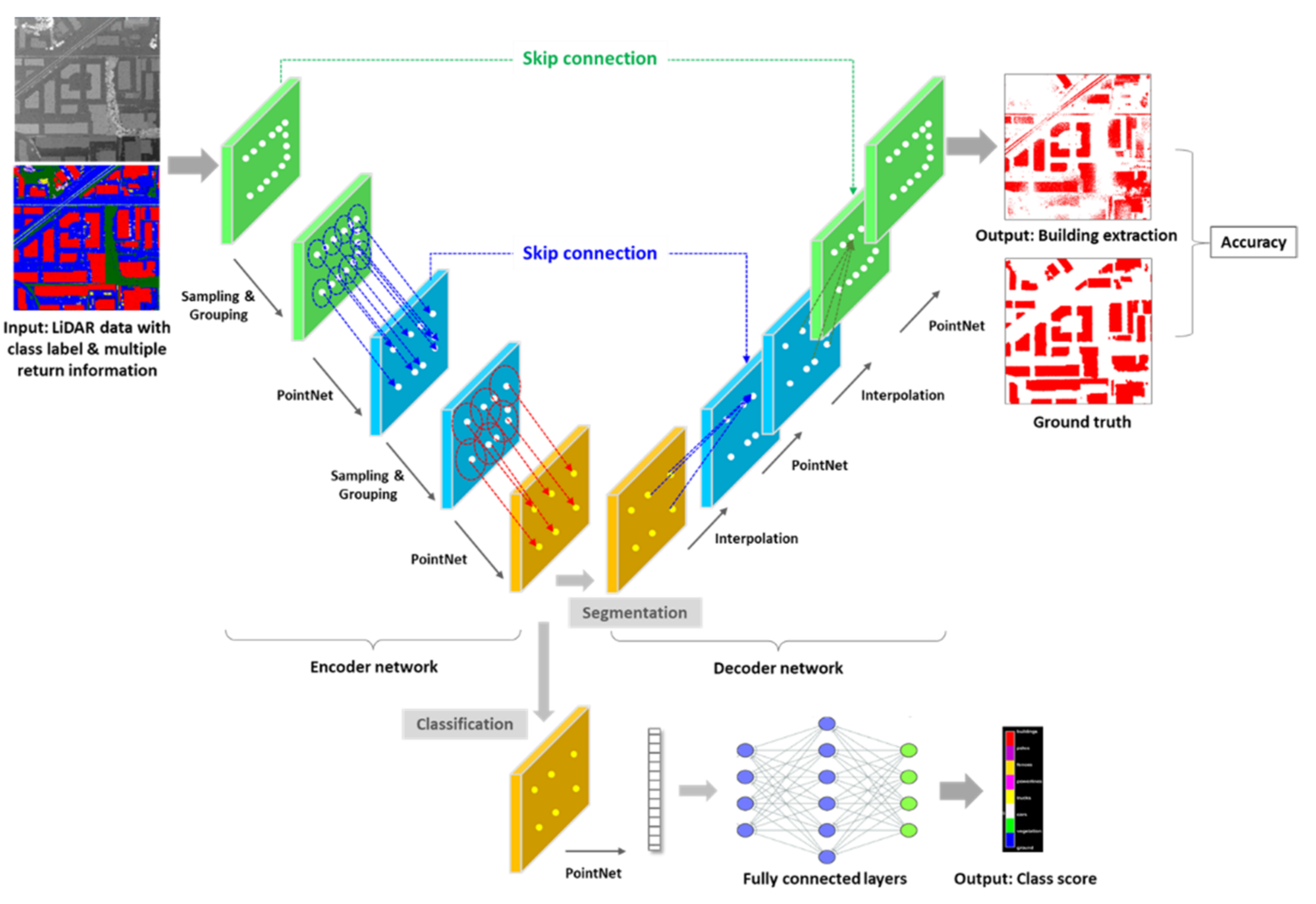
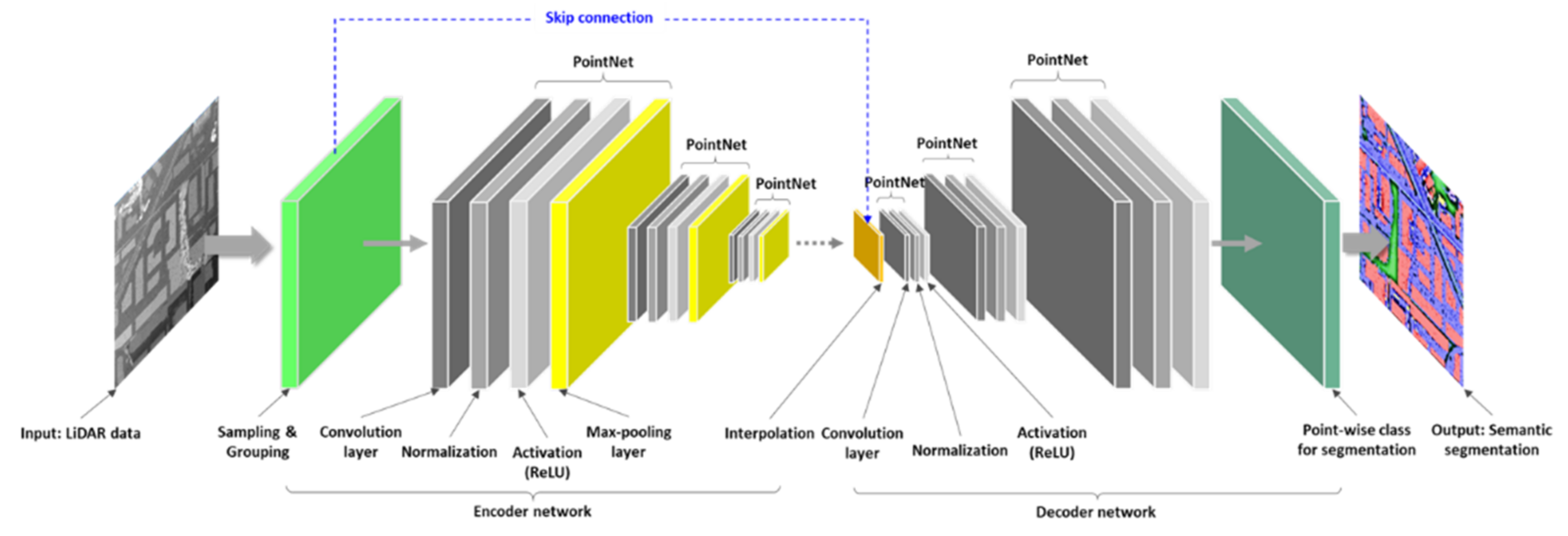
2.2. Overview of PointNet++ Model
2.3. Proposed Scheme and Experiments
2.4. Accuracy Assessment
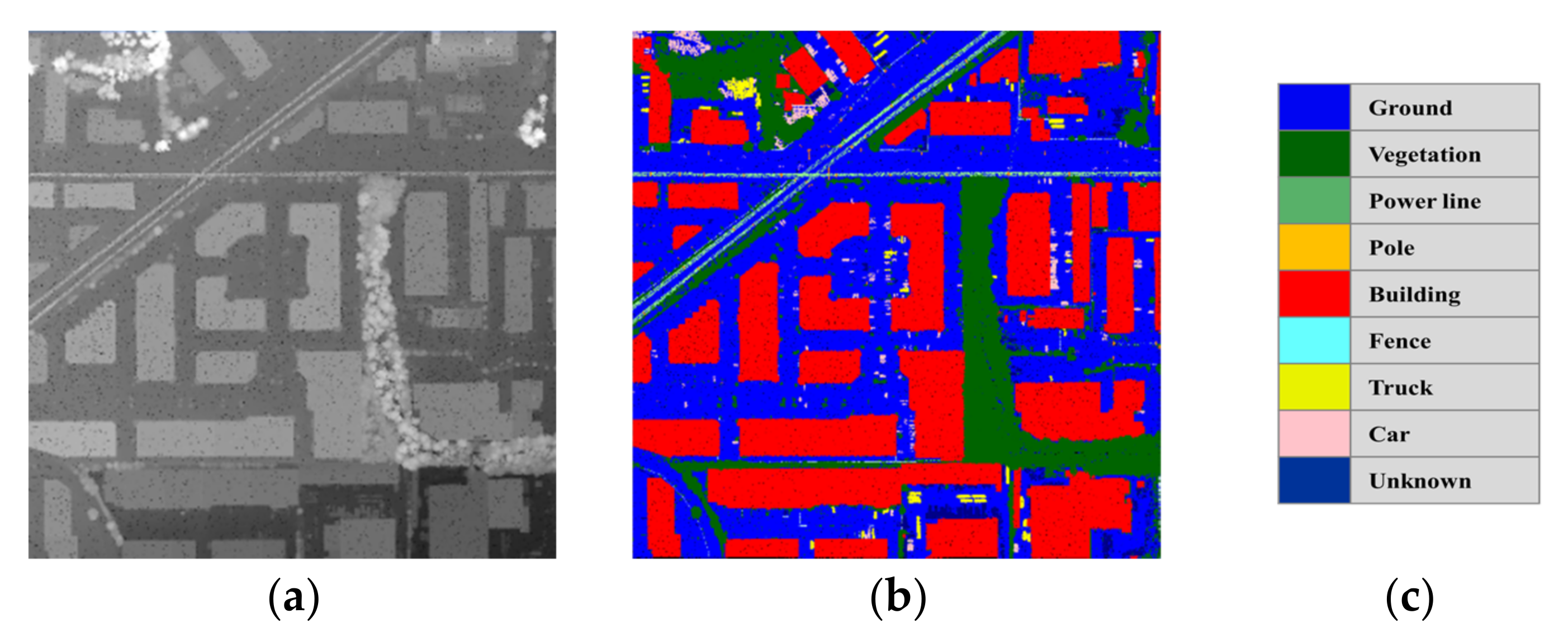
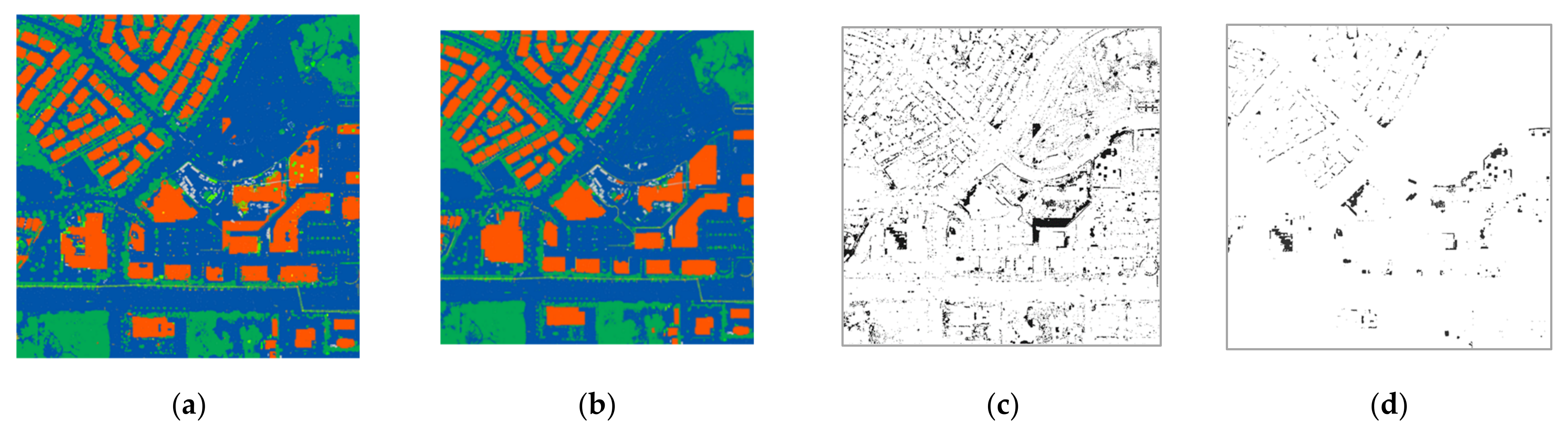
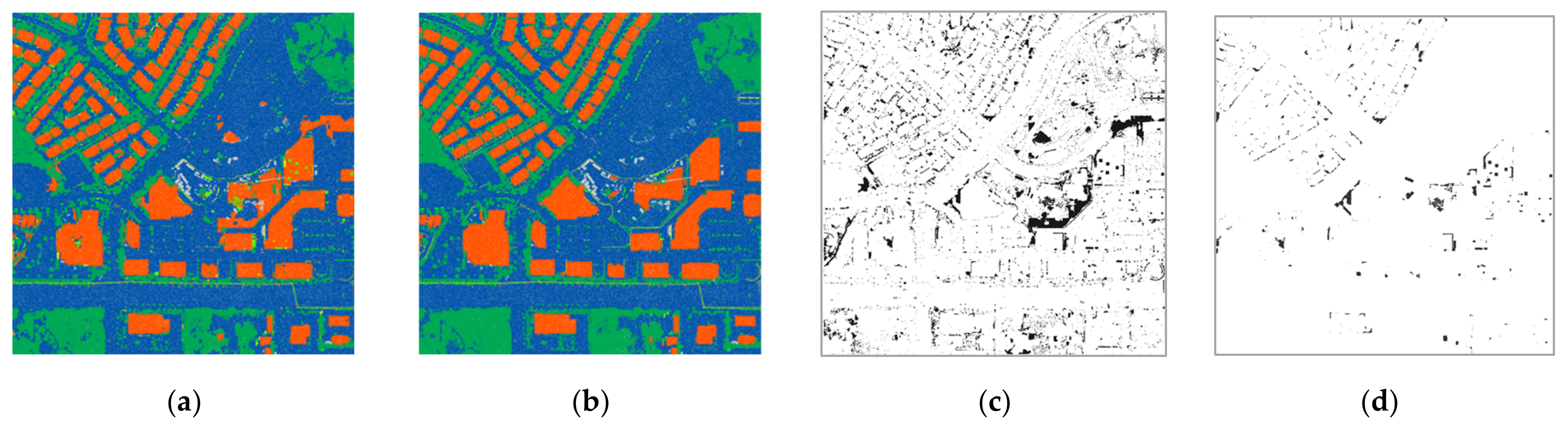
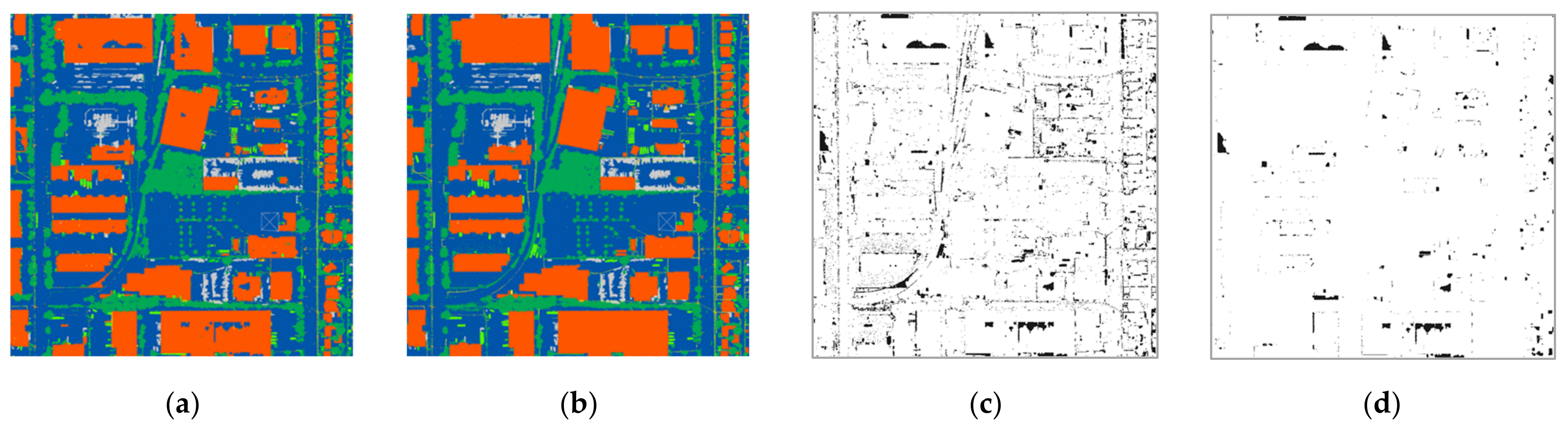
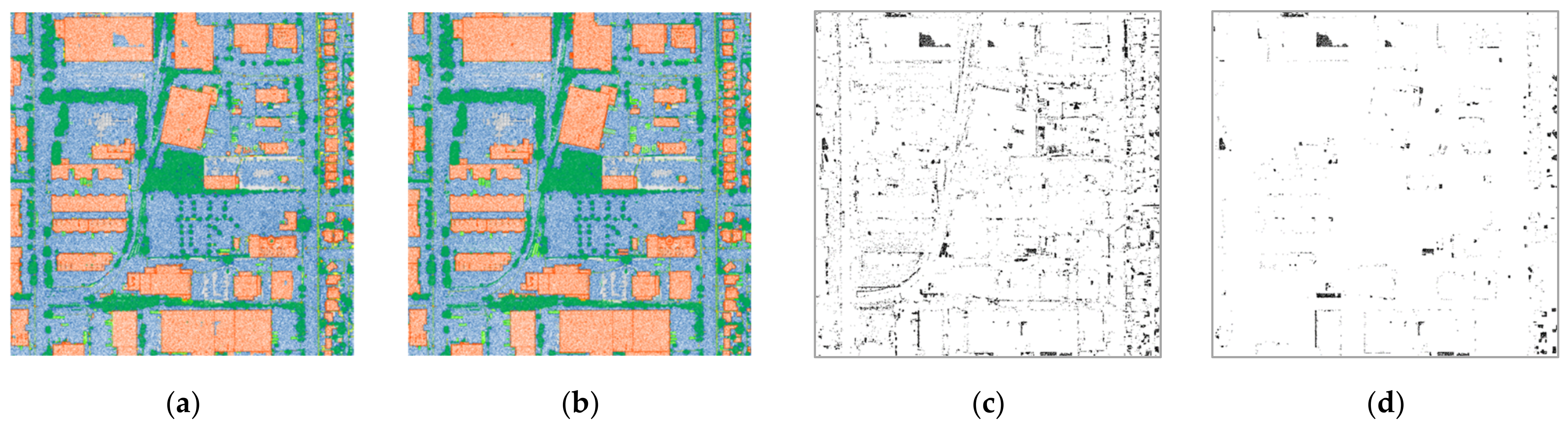
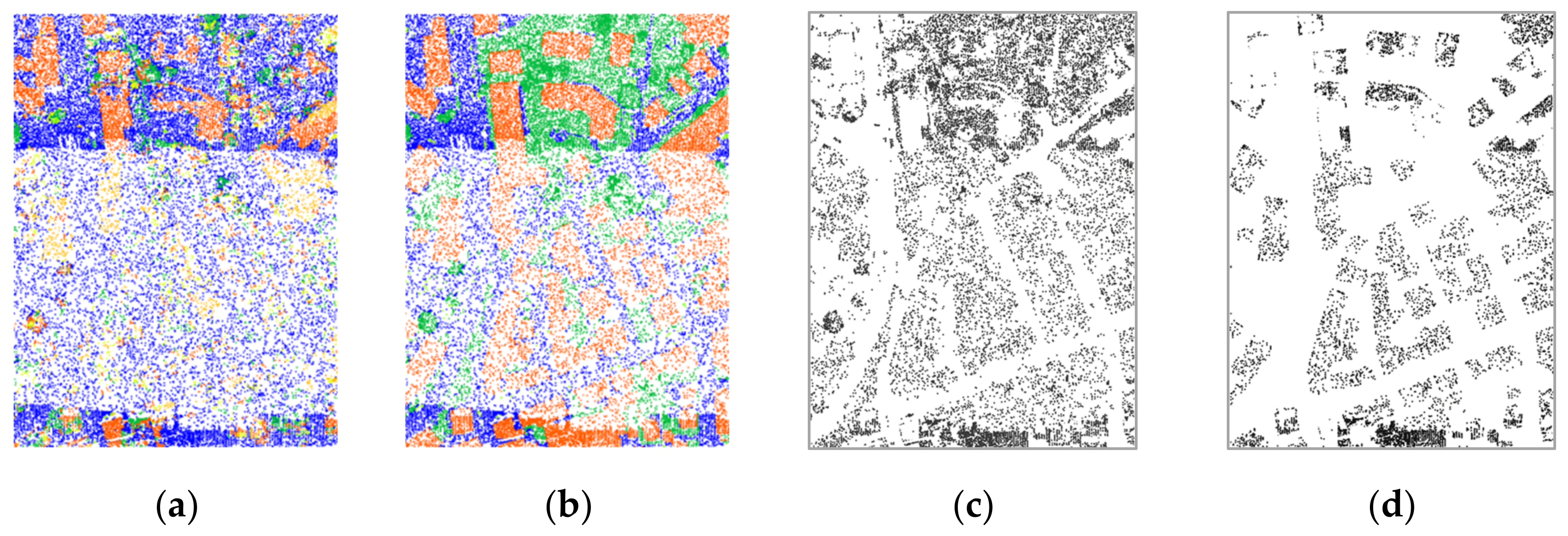
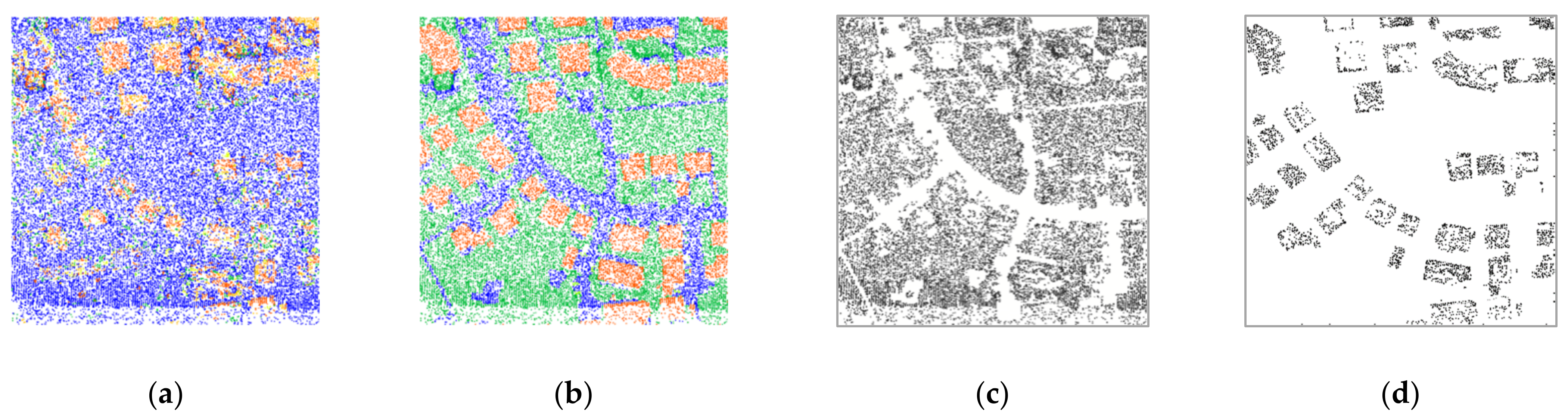
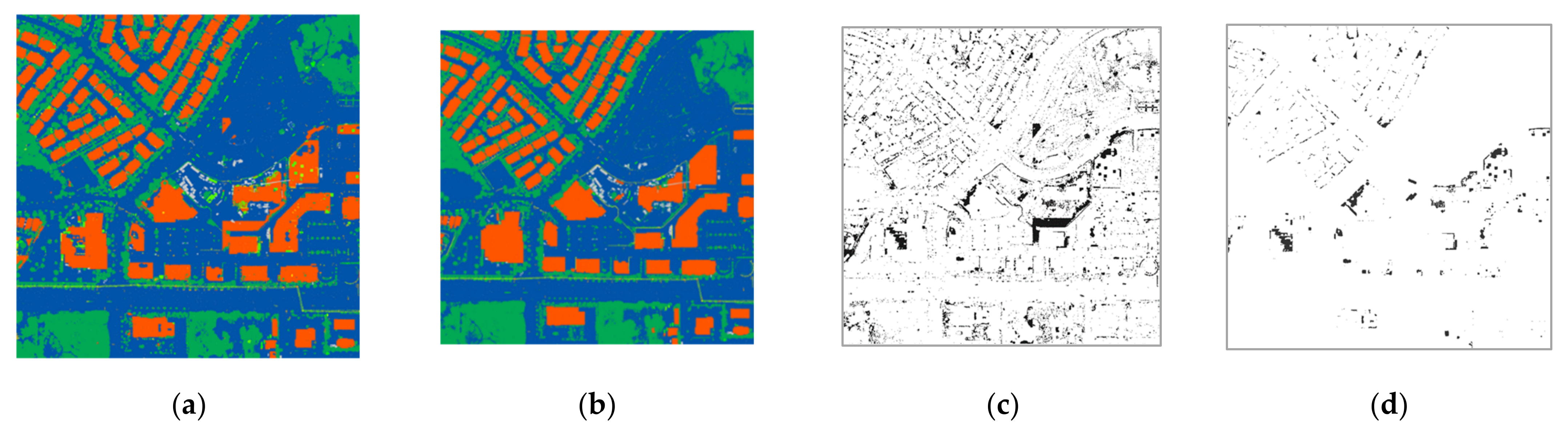
3. Experimental Results and Analysis
- Case 1: Original datasets (i.e., all number of returns)
- Case 2: Datasets of two returns with randomly selected points of 10% from the original datasets
- Case 3: Datasets of two returns with randomly selected points of 50% from the original datasets


4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Maune, D. Digital Elevation Model Technologies and Applications: The DEM Users Manual, 2nd ed.; The American Society for Photogrammetry & Remote Sensing: Bethesa, MD, USA, 2007; pp. 199–424. [Google Scholar]
- Shan, J.; Toth, C. Topographic Laser Ranging and Scanning: Principles and Processing; CRC Press: Boca Raton, FL, USA, 2009; pp. 403–573. [Google Scholar]
- Beraldin, J.; Blais, F.; Lohr, U. Laser scanning technology. In Airborne and Terrestrial Laser Scanning; Vosselman, G., Maas, H., Eds.; CRC Press: Boca Raton, FL, USA, 2010; pp. 1–42. [Google Scholar]
- Li, Y.; Ma, L.F.; Zhong, Z.L.; Liu, F.; Chapman, M.A.; Cao, D.P.; Li, J.T. Deep learning for LiDAR point clouds in autonomous driving: A review. IEEE Trans. Neural. Netw. Learn. Syst. 2021, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Briechle, S.; Krzystek, P.; Vosselman, G. Semantic labeling of ALS point clouds for tree species mapping using the deep neural network PointNet++. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4213, 951–955. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.P.; Vosselman, G.; Cao, Y.P.; Yang, M.Y. Local and global encoder network for semantic segmentation of airborne laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 176, 151–168. [Google Scholar] [CrossRef]
- Meyer, G.P.; Laddha, A.; Kee, E.; Vallespi-Gonzalez, C.; Wellington, C.K. LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 5–20 June 2019. [Google Scholar]
- Hoang, L.; Lee, S.H.; Lee, E.J.; Kwon, K.R. GSV-NET: A multi-modal deep learning network for 3D point cloud classification. Appl. Sci. 2022, 12, 483. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 16–21 July 2017. [Google Scholar]
- Zaheer, M.; Kottur, S.; Ravanbhakhsh, S.; Póczos, B.; Salakhutdinov, R.; Smola1, A. Deep sets. NIPS 2017, 30. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in A Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Audebert, N.; le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Maltezos, E.; Doulamis, A.; Doulamis, N.; Ioannidis, C. Building extraction from LiDAR data applying deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 155–159. [Google Scholar] [CrossRef]
- Lee, D.G.; Shin, Y.H.; Lee, D.C. Land cover classification using SegNet with slope, aspect, and multidirectional shaded relief images derived from digital surface model. J. Sens. 2020, 2020, 8825509. [Google Scholar] [CrossRef]
- Varney, N.; Asari, V.K.; Graehling, Q. DALES: A Large-scale Aerial LiDAR Data Set for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14 April 2020. [Google Scholar]
- Singer, N.M.; Asari, V.K. DALES Objects: A large scale benchmark dataset for instance segmentation in aerial Lidar. IEEE Access 2021, 9, 97495–97504. [Google Scholar] [CrossRef]
- Dayton Annotated Laser Earth Scan (DALES). Available online: https://udayton.edu/engineering/research/centers/vision_lab/research/was_data_analysis_and_processing/dale.php (accessed on 22 August 2021).
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkop, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1–3, 293–298. [Google Scholar] [CrossRef] [Green Version]
- Cramer, M. The DGPF test on digital aerial camera evaluation—Overview and test design. PFG 2010, 2, 73–82. [Google Scholar] [CrossRef] [PubMed]
- 2D Semantic Labeling—Vaihingen Data. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/ (accessed on 6 September 2020).
- NGP Standards and Specifications Update LAS Reference to R15. Available online: https://www.usgs.gov/ngp-standards-and-specifications/update-las-reference-r15 (accessed on 17 July 2021).
- Bello, S.A.; Yu, S.; Wang, C. Review: Deep learning on 3D point clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar]
- Chen, Y.; Liu, G.; Xu, Y.; Pan, P.; Xing, Y. PointNet++ network architecture with individual point level and global features on centroid for ALS point cloud classification. Remote Sens. 2021, 13, 472. [Google Scholar] [CrossRef]
- 3D Point Clouds Bounding Box Detection and Tracking (PointNet, PointNet++, LaserNet, Point Pillars and Complex Yolo)—Series 5 (Part 1). Available online: https://medium.com/@a_tyagi/pointnet-3d-point-clouds-bounding-box-detection-and-tracking-pointnet-pointnet-lasernet-33c1c0ed196d (accessed on 15 May 2021).
- Getting Started with PointNet++. Available online: https://kr.mathworks.com/help/lidar/ug/get-started-pointnetplus.html (accessed on 23 November 2021).
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data. 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Zhou, Z.; Huang, H.; Fang, B. Application of weighted cross-entropy loss function in intrusion detection. J. Comput. Commun. 2021, 9, 1–21. [Google Scholar] [CrossRef]
- Sander, R. Sparse Data Fusion and Class Imbalance Correction Techniques for Efficient Multi-Class Point Cloud Semantic Segmentation. 2020. Available online: https://www.researchgate.net/publication/339323048_Sparse_Data_Fusion_and_Class_Imbalance_Correction_Techniques_for_Efficient_Multi-Class_Point_Cloud_Semantic_Segmentation (accessed on 25 January 2022). [CrossRef]
- Zhao, W.; Zhang, H.; Yan, Y.; Fu, Y.; Wang, H. A semantic segmentation algorithm using FCN with combination of BSLIC. Appl. Sci. 2018, 8, 500. [Google Scholar] [CrossRef] [Green Version]
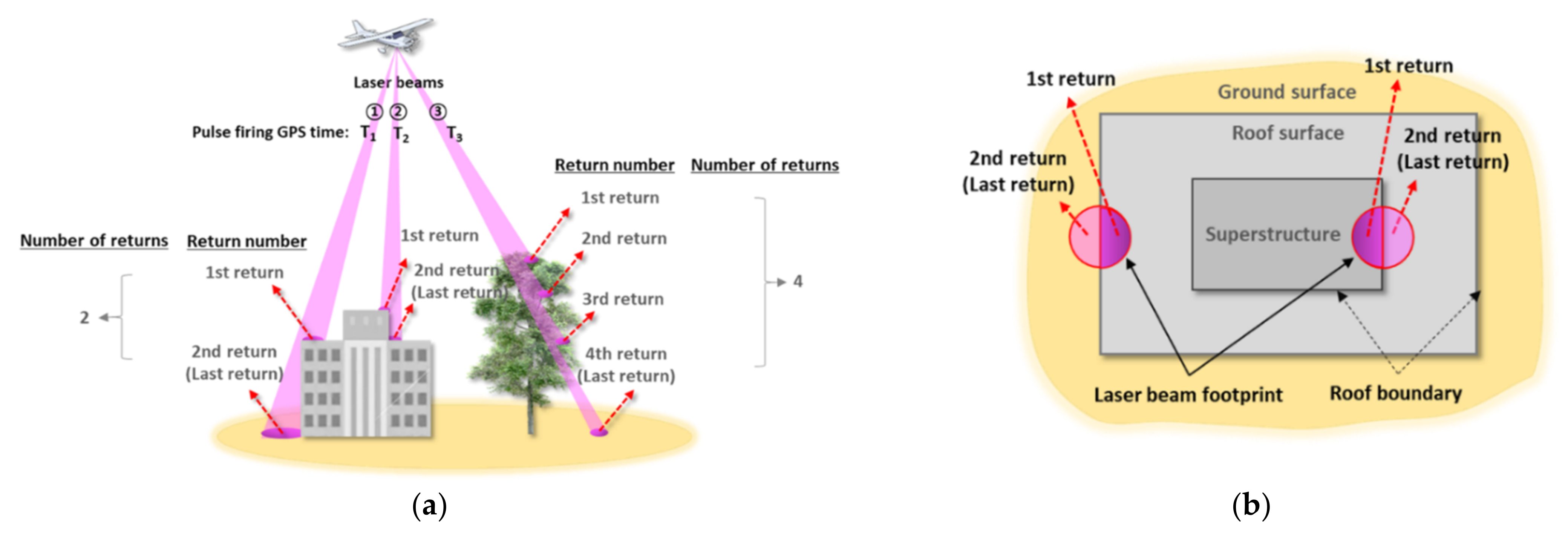
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
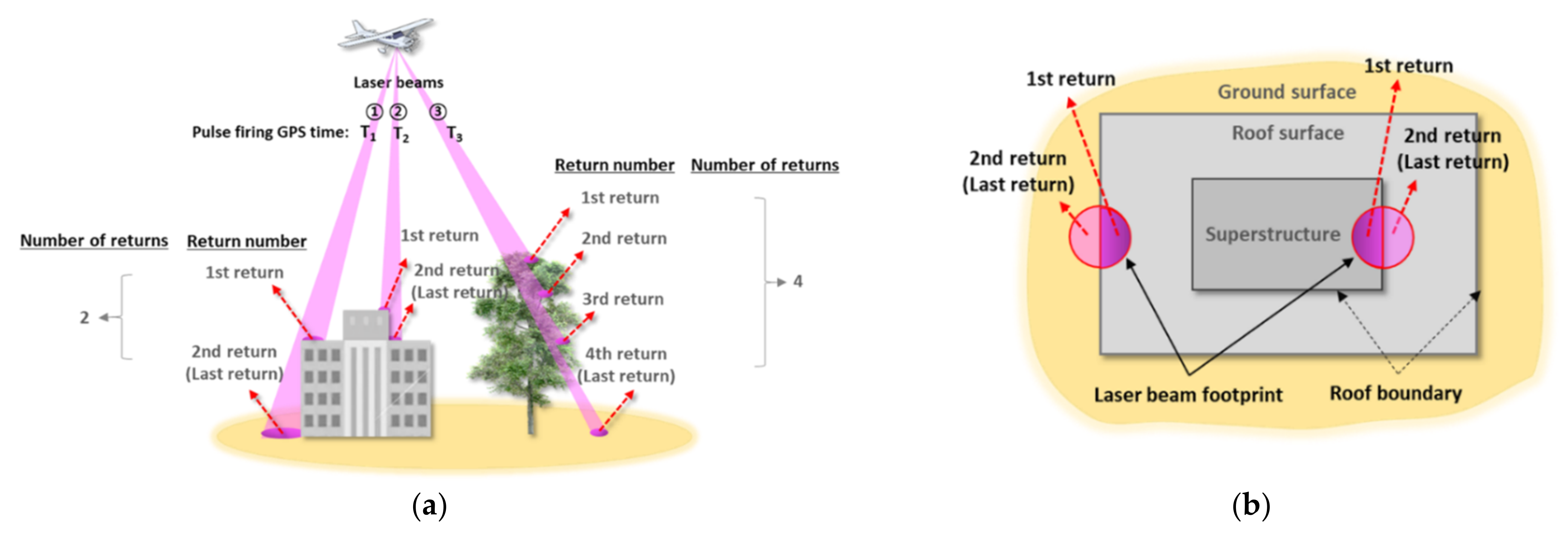
| Laser Beam | X | Y | Z | Return Number | Number of Returns |
|---|---|---|---|---|---|
| ① | 514,519.07 | 5,447,023.33 | 95.39 | 1 | 2 |
| 514,520.24 | 5,447,031.85 | 91.71 | 2 | 2 | |
| ② | 514,519.10 | 5,447,023.81 | 96.14 | 1 | 2 |
| 514,520.23 | 5,447,023.02 | 95.26 | 2 | 2 | |
| ③ | 514,519.13 | 5,447,023.63 | 100.20 | 1 | 4 |
| 514,519.33 | 5,447,024.32 | 97.76 | 2 | 4 | |
| 514,519.41 | 5,447,024.63 | 96.76 | 3 | 4 | |
| 514,519.65 | 5,447,025.46 | 92.81 | 4 | 4 |
| Evaluation Metrics | Case 1 | Case 2 | Case 3 |
|---|---|---|---|
| Accuracy (%) | 97.08 | 95.55 | 96.45 |
| Loss | 0.20 | 0.23 | 0.20 |
| Dataset | Evaluation Metrics | Case 1 | Case 2 | Case 3 |
|---|---|---|---|---|
| Test 1 | Global accuracy | 0.9253 | 0.8869 | 0.9126 |
| Mean accuracy | 0.6254 | 0.6304 | 0.6323 | |
| Mean IoU | 0.4287 | 0.4640 | 0.4474 | |
| Weighted IoU | 0.8669 | 0.8017 | 0.8454 | |
| Test 2 | Global accuracy | 0.9399 | 0.9059 | 0.9281 |
| Mean accuracy | 0.6411 | 0.6640 | 0.6537 | |
| Mean IoU | 0.4979 | 0.5284 | 0.5031 | |
| Weighted IoU | 0.8937 | 0.8372 | 0.8738 | |
| New 1 | Global accuracy | 0.6557 | 0.4754 | 0.6349 |
| Mean accuracy | 0.5216 | 0.3952 | 0.4961 | |
| Mean IoU | 0.1916 | 0.1261 | 0.1860 | |
| Weighted IoU | 0.4958 | 0.3115 | 0.4781 | |
| New 2 | Global accuracy | 0.5064 | 0.3104 | 0.4656 |
| Mean accuracy | 0.4976 | 0.3344 | 0.4630 | |
| Mean IoU | 0.1591 | 0.0768 | 0.1405 | |
| Weighted IoU | 0.3475 | 0.1540 | 0.3011 |
| Dataset | Class | Accuracy | IoU | ||||
|---|---|---|---|---|---|---|---|
| Case 1 | Case 2 | Case 3 | Case 1 | Case 2 | Case 3 | ||
| Test 1 | Ground | 0.9740 | 0.9607 | 0.9659 | 0.9140 | 0.8462 | 0.8955 |
| Vegetation | 0.8663 | 0.8528 | 0.8610 | 0.8035 | 0.7909 | 0.7986 | |
| Car | 0.4005 | 0.3804 | 0.3980 | 0.2615 | 0.2837 | 0.2822 | |
| Truck | 0.3731 | 0.1300 | 0.2562 | 0.0236 | 0.0198 | 0.0207 | |
| Powerline | 0.8661 | 0.8703 | 0.8731 | 0.3932 | 0.5568 | 0.4650 | |
| Fence | 0.0498 | 0.2979 | 0.1993 | 0.0391 | 0.1872 | 0.1136 | |
| Pole | 0.5767 | 0.7089 | 0.6230 | 0.1413 | 0.2527 | 0.1825 | |
| Building | 0.8966 | 0.8420 | 0.8820 | 0.8537 | 0.7747 | 0.8208 | |
| Test 2 | Ground | 0.9924 | 0.9898 | 0.9874 | 0.9302 | 0.8964 | 0.9166 |
| Vegetation | 0.8826 | 0.8651 | 0.8773 | 0.8445 | 0.8147 | 0.8355 | |
| Car | 0.6838 | 0.3482 | 0.5332 | 0.2060 | 0.1711 | 0.2196 | |
| Truck | 0.4217 | 0.4077 | 0.3738 | 0.2750 | 0.3033 | 0.2431 | |
| Powerline | 0.6757 | 0.7863 | 0.7677 | 0.5517 | 0.6407 | 0.5376 | |
| Fence | 0.1207 | 0.5763 | 0.3530 | 0.0907 | 0.2999 | 0.1816 | |
| Pole | 0.4210 | 0.4619 | 0.4332 | 0.1788 | 0.2546 | 0.2108 | |
| Building | 0.9208 | 0.8764 | 0.9044 | 0.9067 | 0.8464 | 0.8797 | |
| New 1 | Ground | 0.8814 | 0.9046 | 0.8534 | 0.5666 | 0.4129 | 0.5556 |
| Vegetation | 0.3350 | 0.2296 | 0.2831 | 0.2838 | 0.2098 | 0.2515 | |
| Car | 0.1852 | 0.0756 | 0.1270 | 0.0920 | 0.0517 | 0.0953 | |
| Building | 0.7523 | 0.3712 | 0.7208 | 0.6573 | 0.3342 | 0.5858 | |
| New 2 | Ground | 0.9445 | 0.9570 | 0.9429 | 0.3292 | 0.2742 | 0.3299 |
| Vegetation | 0.1712 | 0.0583 | 0.1332 | 0.1680 | 0.0564 | 0.1298 | |
| Car | 0.0237 | 0.0139 | 0 | 0.0588 | 0.0085 | 0 | |
| Building | 0.8512 | 0.3086 | 0.7760 | 0.7699 | 0.3797 | 0.6644 | |
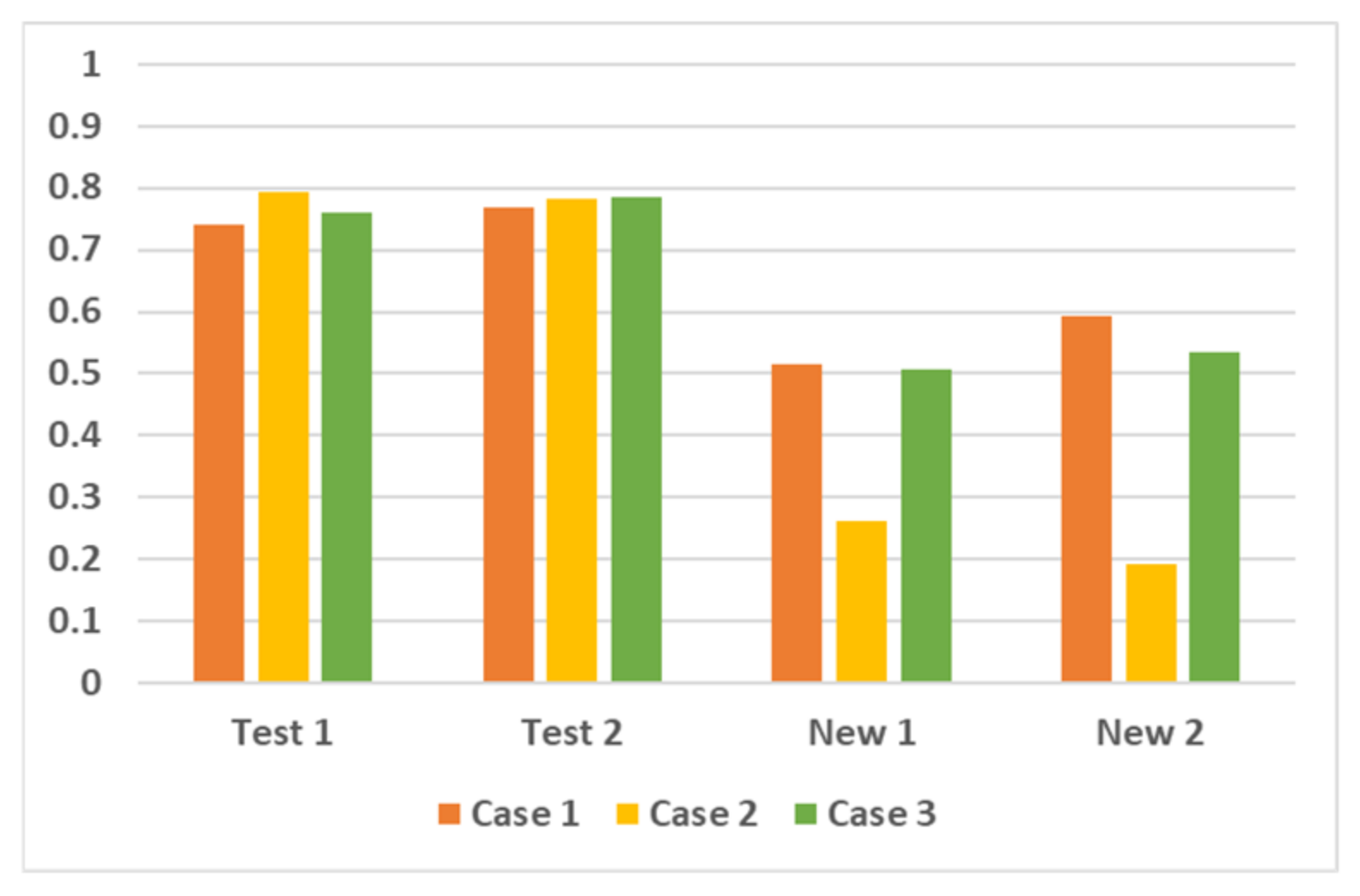
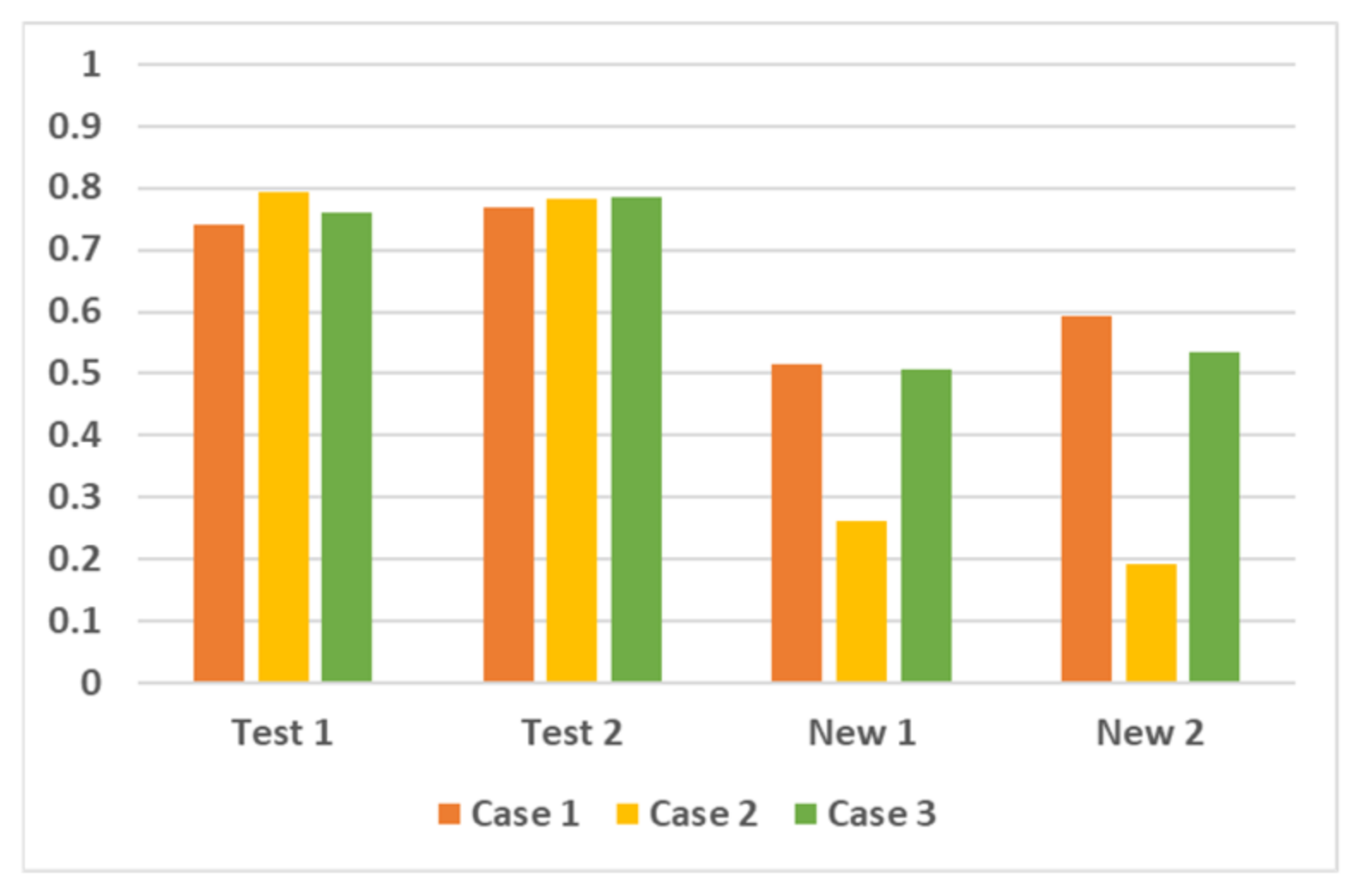
| Dataset | Case 1 | Case 2 | Case 3 |
|---|---|---|---|
| Test 1 | 0.7417 | 0.7948 | 0.7598 |
| Test 2 | 0.7691 | 0.7826 | 0.7851 |
| New 1 | 0.5158 | 0.2611 | 0.5063 |
| New 2 | 0.5938 | 0.1930 | 0.5344 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, Y.-H.; Son, K.-W.; Lee, D.-C. Semantic Segmentation and Building Extraction from Airborne LiDAR Data with Multiple Return Using PointNet++. Appl. Sci. 2022, 12, 1975. https://doi.org/10.3390/app12041975
Shin Y-H, Son K-W, Lee D-C. Semantic Segmentation and Building Extraction from Airborne LiDAR Data with Multiple Return Using PointNet++. Applied Sciences. 2022; 12(4):1975. https://doi.org/10.3390/app12041975
Chicago/Turabian StyleShin, Young-Ha, Kyung-Wahn Son, and Dong-Cheon Lee. 2022. "Semantic Segmentation and Building Extraction from Airborne LiDAR Data with Multiple Return Using PointNet++" Applied Sciences 12, no. 4: 1975. https://doi.org/10.3390/app12041975
APA StyleShin, Y.-H., Son, K.-W., & Lee, D.-C. (2022). Semantic Segmentation and Building Extraction from Airborne LiDAR Data with Multiple Return Using PointNet++. Applied Sciences, 12(4), 1975. https://doi.org/10.3390/app12041975