
Multivariate Fence: Using Parallel Coordinates to Locate and Compare Attributes of Adjacency Matrix Nodes in Immersive Environment


Abstract
1. Introduction
2. Related Work
2.1. Interactions in Adjacency Matrix
2.2. ROI Presentation Techniques of Adjacency Matrix
2.3. Immersive Analytics
2.4. Parallel Coordinate Plot
3. Design of the MVF
3.1. Design Goals
- G1:
- Improve node attribute location and comparison efficiency.
- G2:
- Minimize information occlusion.
- G3:
- Assist users to understand the adjacency matrix.
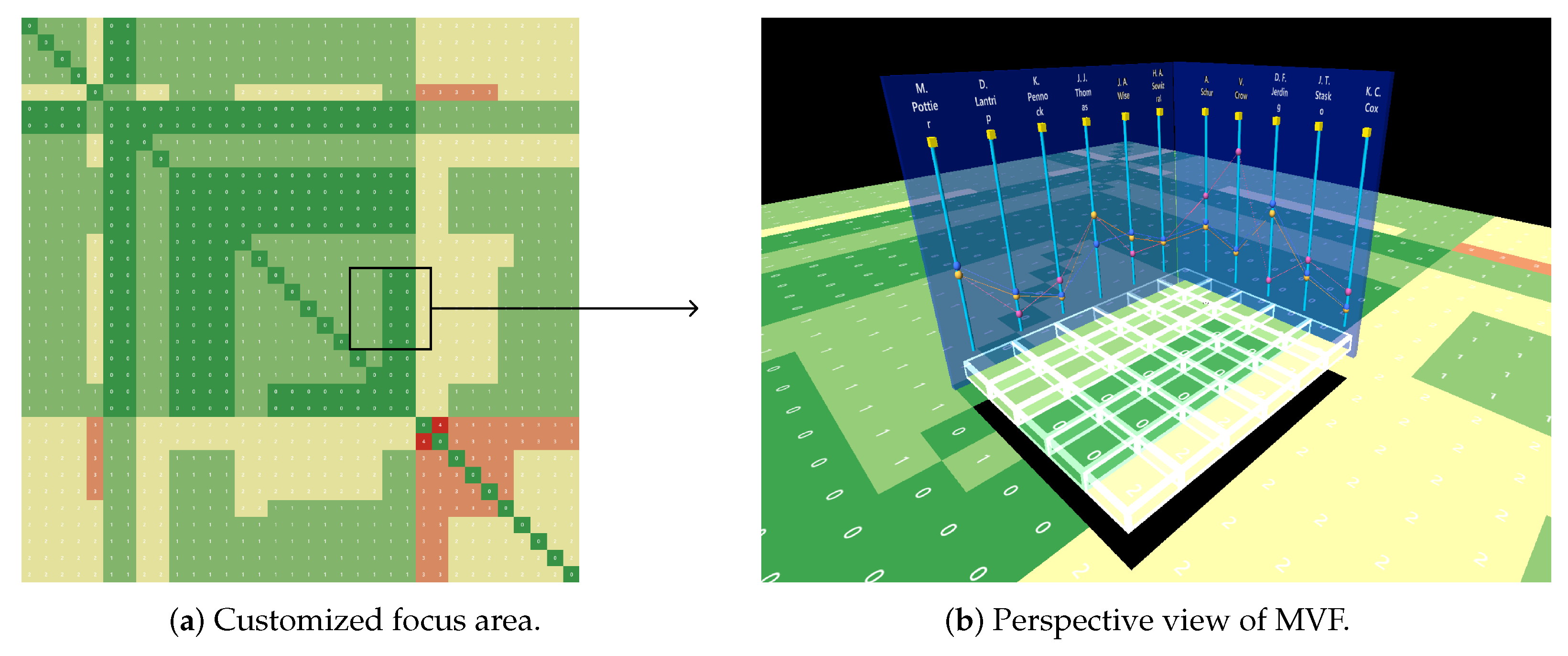
3.2. Overview of the MVF
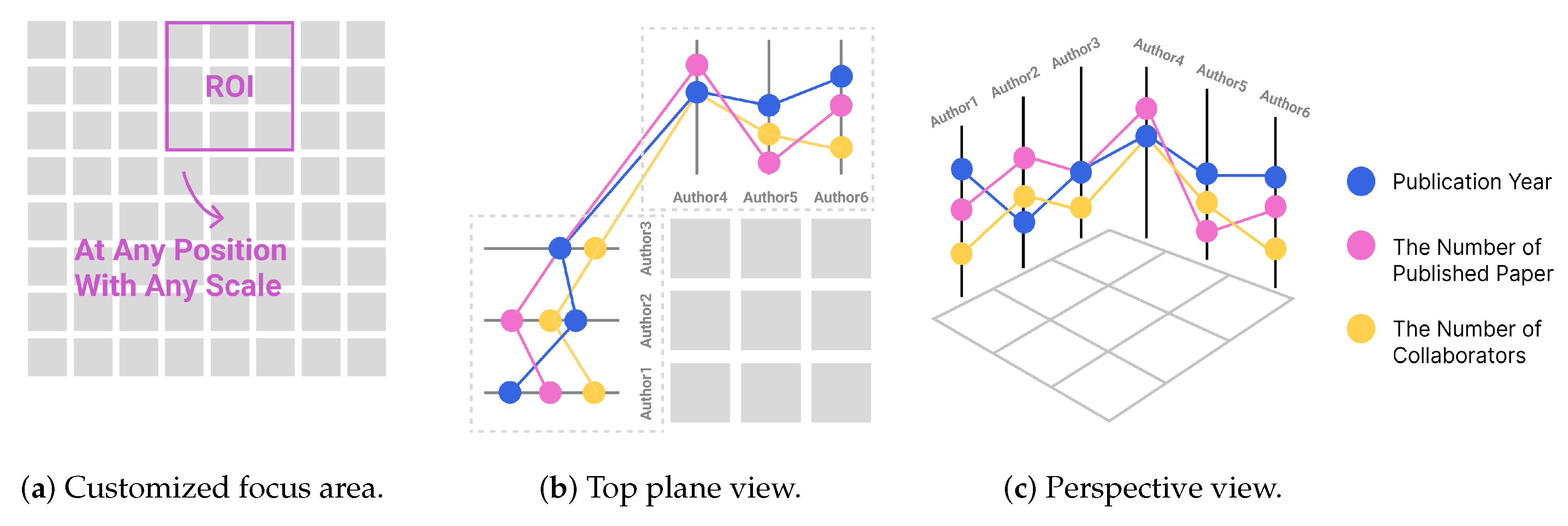
3.3. Construction of the MVF
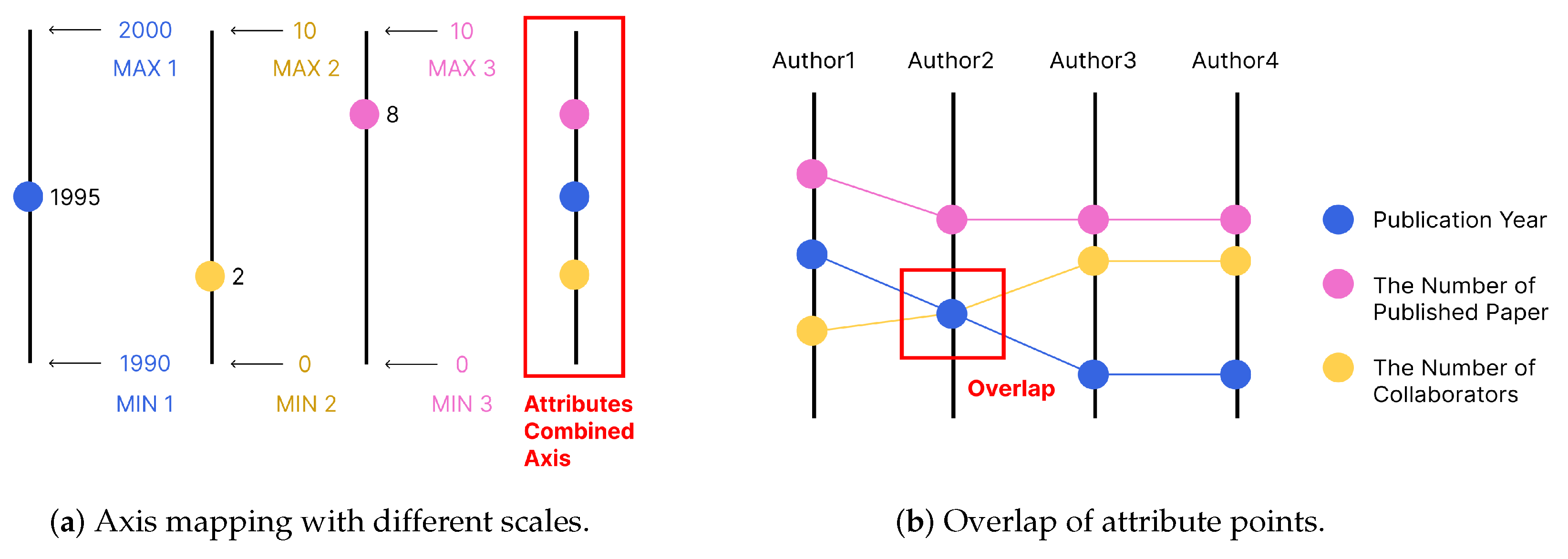
3.3.1. Axis and Point
3.3.2. Link
3.4. Parallel Coordinate
3.5. Interactions in Immersive Environment
4. Comparison with Embedded Model
4.1. Dataset
4.2. Scenarios for Comparison
- Scene 1:
- Adjacency Matrix with MVF
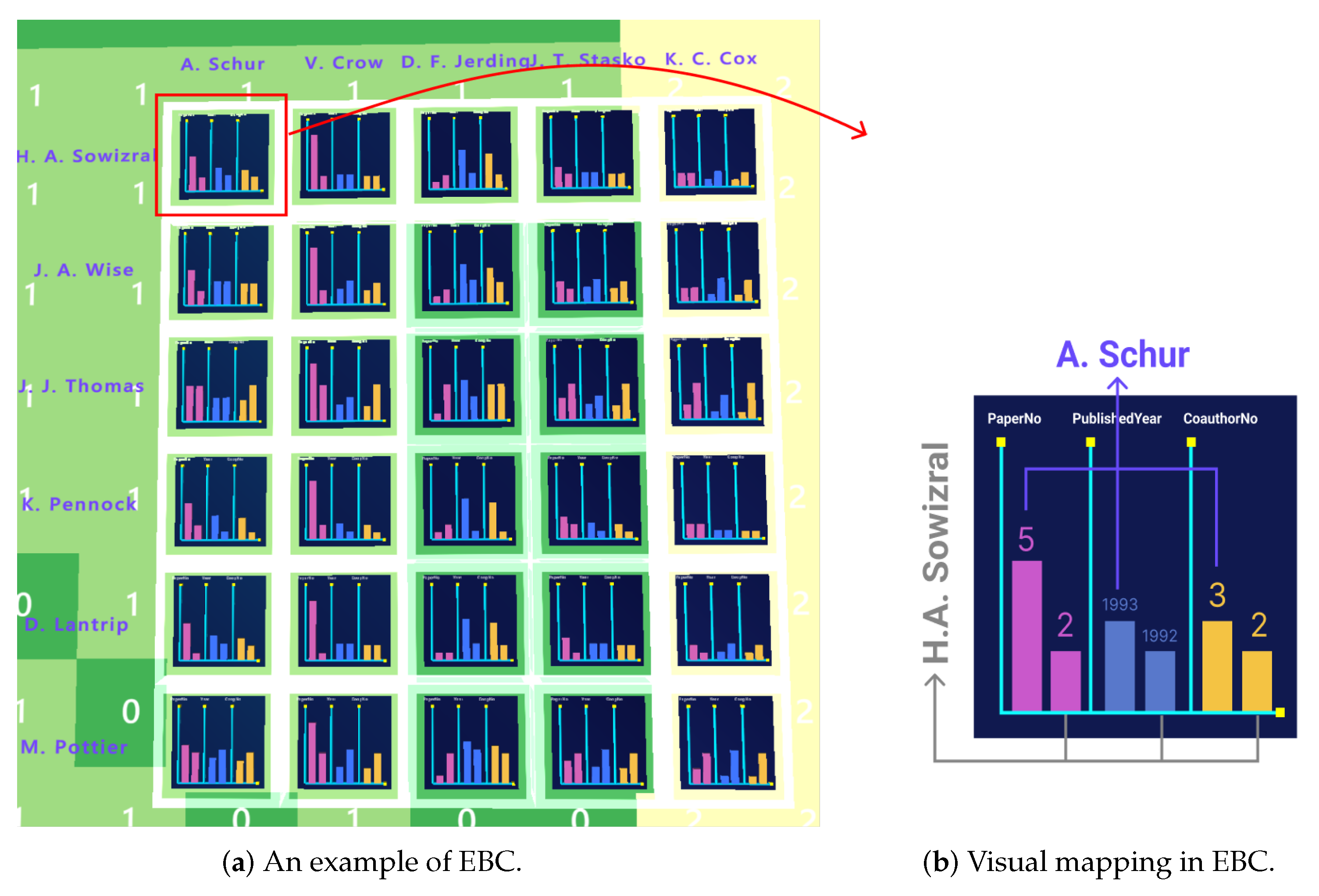
- Scene 2:
- Adjacency Matrix with Embedded Bar Chart (EBC)
5. User Study
5.1. Hypotheses
- H1: The MVF accomplishes tasks faster than the traditional focus view model EBC.
- H2: MVF is more accurate than EBC when locating and comparing.
- H3: MVF can locate more easily than EBC.
- H4: MVF can perform comparisons more easily than EBC.
- H5: MVF is easier to understand than EBC.
- H6: Users prefer MVF to the EBC model.
5.2. Task
- T1: The name of the author with two publications in the cluster.
- T2: The name of the author with one cooperator and the publication year of 1993 in the cluster.
- T3: The name of the author with the fewest publications.
- T4: The name of the author with the earliest publication year and the largest number of publications.
5.3. Apparatus
5.4. Procedure
- Q1: You think that the position mapping of the author and attributes is helpful for you to locate the attribute value.
- Q2: You think that the position mapping of the author and attributes is helpful for you to compare attribute values.
- Q3: You think that the position mapping of the author and attributes is helpful for you to understand the relationship between author and their attributes.
- Q4: You think that the attribute occurrence number is helpful for you to locate attribute values.
- Q5: You think that the attribute occurrence number is helpful for your to compare attribute values.
- Q6: You think that the attribute occurrence number is helpful for you to understand the relationship between the author and their attributes.
- Q7: Which model do you prefer?
5.5. Result
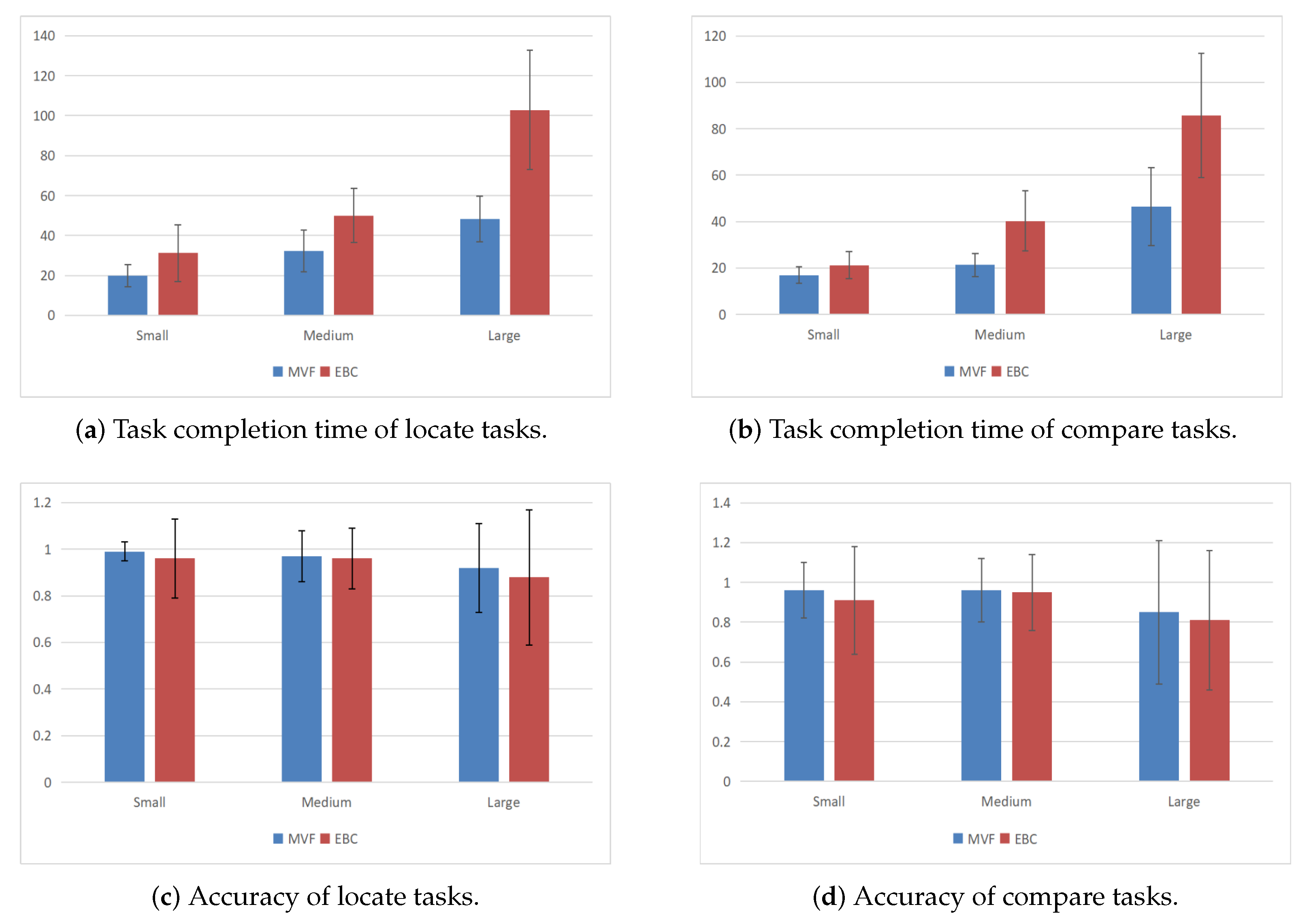
5.5.1. MVF Is Faster Than EBC
5.5.2. No Significant Difference in Accuracy between MVF and EBC
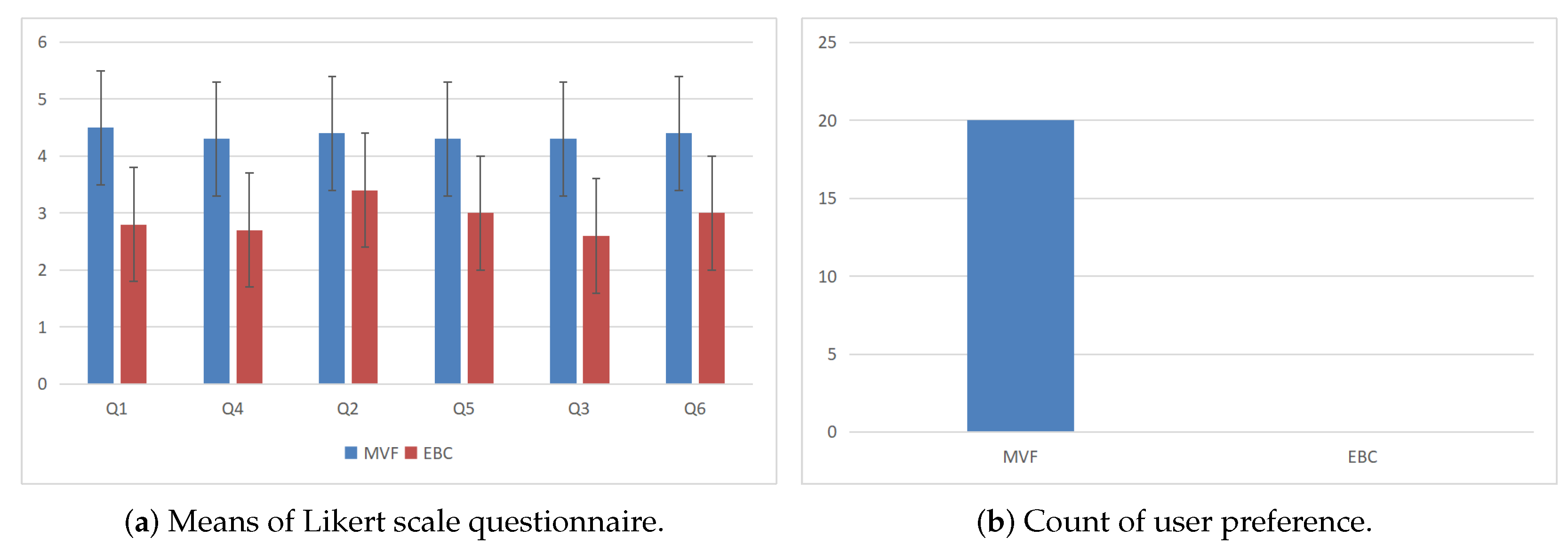
5.5.3. MVF Can Locate More Easily Than EBC
5.5.4. MVF Can Perform Comparisons More Easily Than EBC
5.5.5. MVF Is Easier to Understand Than EBC
5.5.6. Users Prefer MVF to EBC Model
6. Discussion
6.1. Efficiency
6.2. Accuracy
6.3. Localization Ability
6.4. Comparison Ability
6.5. Comprehensive Ability
6.6. User Preference
6.7. VR Immersive Environment Influence
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VR | Virtual Reality |
| IA | Immersive Analytics |
| ROI | Region of Interest |
| F+C | Focus + Context |
| HMD | Virtual Reality Head-Mounted Display |
| MVF | Multivariate Fence |
| EBC | Embedded Bar Chart |
| PCP | Parallel Coordinate Plot |
| PM | Position Mapping |
| NoO | Number of Occurrence |
References
- Chen, Y.; Guan, Z.; Zhang, R.; Du, X.; Wang, Y. A survey on visualization approaches for exploring association relationships in graph data. J. Vis. 2019, 22, 625–639. [Google Scholar] [CrossRef]
- Dinkla, K.; Westenberg, M.A.; Van Wijk, J.J. Compressed Adjacency Matrices: Untangling Gene Regulatory Networks. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2457–2466. [Google Scholar] [CrossRef] [PubMed]
- Kister, U.; Klamka, K.; Tominski, C.; Dachselt, R. G ra S p: Combining Spatially-aware Mobile Devices and a Display Wall for Graph Visualization and Interaction. Comput. Graph. Forum 2017, 36, 503–514. [Google Scholar] [CrossRef]
- Burch, M.; Brinke, K.B.T.; Castella, A.; Peters, G.K.S.; Shteriyanov, V.; Vlasvinkel, R. Dynamic graph exploration by interactively linked node-link diagrams and matrix visualizations. Vis. Comput. Ind. Biomed. Art 2021, 4, 23. [Google Scholar] [CrossRef] [PubMed]
- Elmqvist, N.; Do, T.-N.; Goodell, H.; Henry, N.; Fekete, J.-D. ZAME: Interactive Large-Scale Graph Visualization. In Proceedings of the 2008 IEEE Pacific Visualization Symposium, Kyoto, Japan, 5–7 March 2008; pp. 215–222. [Google Scholar] [CrossRef]
- Horak, T.; Berger, P.; Schumann, H.; Dachselt, R.; Tominski, C. Responsive Matrix Cells: A Focus+Context Approach for Exploring and Editing Multivariate Graphs. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1644–1654. [Google Scholar] [CrossRef] [PubMed]
- Henry, N.; Fekete, J.-D. MatrixExplorer: A Dual-Representation System to Explore Social Networks. IEEE Trans. Vis. Comput. Graph. 2006, 12, 677–684. [Google Scholar] [CrossRef]
- Dwyer, T.; Marriott, K.; Isenberg, T.; Klein, K.; Riche, N.; Schreiber, F.; Stuerzlinger, W.; Thomas, B.H. Immersive Analytics: An Introduction. In Immersive Analytics. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11190. [Google Scholar] [CrossRef]
- Fonnet, A.; Prié, Y. Survey of Immersive Analytics. IEEE Trans. Vis. Comput. Graph. 2021, 27, 2101–2122. [Google Scholar] [CrossRef]
- Chandler, T.; Cordeil, M.; Czauderna, T.; Dwyer, T.; Glowacki, J.; Goncu, C.; Klapperstueck, M.; Klein, K.; Marriott, K.; Schreiber, F.; et al. Immersive Analytics. In Proceedings of the 2015 Big Data Visual Analytics (BDVA), Hobart, Australia, 22–25 September 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Yang, Y.; Dwyer, T.; Marriott, K.; Jenny, B.; Goodwin, S. Tilt Map: Interactive Transitions between Choropleth Map, Prism Map and Bar Chart in Immersive Environments. IEEE Trans. Vis. Comput. Graph. 2020, 27, 4507–4519. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Xia, W.; Lekschas, F.; Nobre, C.; Krüger, R.; Pfister, H. The Pattern is in the Details: An Evaluation of Interaction Techniques for Locating, Searching, and Contextualizing Details in Multivariate Matrix Visualizations. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI’22), New Orleans, LA, USA, 29 April–5 May 2022; Article 84. Association for Computing Machinery: New York, NY, USA, 2022; pp. 1–15. [Google Scholar] [CrossRef]
- Spindler, M.; Stellmach, S.; Dachselt, R. PaperLens: Advanced magic lens interaction above the tabletop. In Proceedings of the ACM International Conference on Interactive Tabletops and Surfaces (ITS’09), Banff, AB, Canada, 23–25 November 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 69–76. [Google Scholar] [CrossRef]
- Kister, U.; Reipschläger, P.; Matulic, F.; Dachselt, R. BodyLenses: Embodied Magic Lenses and Personal Territories for Wall Displays. In Proceedings of the 2015 International Conference on Interactive Tabletops & Surfaces (ITS’15), Madeira, Portugal, 15–18 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 117–126. [Google Scholar] [CrossRef]
- Dostal, J.; Hinrichs, U.; Kristensson, P.O.; Quigley, A. SpiderEyes: Designing attention- and proximity-aware collaborative interfaces for wall-sized displays. In Proceedings of the 19th International Conference on Intelligent User Interfaces (IUI’14), Haifa, Israel, 24–27 February 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 143–152. [Google Scholar] [CrossRef]
- Elhart, I.; Scacchi, F.; Niforatos, E.; Langheinrich, M. ShadowTouch: A Multi-user Application Selection Interface for Interactive Public Displays. In Proceedings of the 4th International Symposium on Pervasive Displays (PerDis’15), Saarbruecken, Germany, 10–12 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 209–216. [Google Scholar] [CrossRef]
- Elmqvist, N.; Henry, N.; He, Y.R.; Fekete, J.-D. Melange: Space folding for multi-focus interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’08), Florence, Italy, 5–10 April 2008; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1333–1342. [Google Scholar] [CrossRef]
- Butscher, S.; Hornbæk, K.; Reiterer, H. SpaceFold and PhysicLenses: Simultaneous multifocus navigation on touch surfaces. In Proceedings of the 2014 International Working Conference on Advanced Visual Interfaces (AVI’14), Como, Italy, 27–29 May 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 209–216. [Google Scholar] [CrossRef]
- Butscher, S. Explicit & Implicit Interaction Design for Multi-Focus Visualizations. In Proceedings of the Ninth ACM International Conference on Interactive Tabletops and Surfaces (ITS’14), Dresden, Germany, 16–19 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 455–460. [Google Scholar] [CrossRef]
- Chiu, P.; Liao, C.; Chen, F. Multi-touch document folding: Gesture models, fold directions and symmetries. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’11), Vancouver, BC, Canada, 7–12 May 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1591–1600. [Google Scholar] [CrossRef]
- Langner, R.; Satkowski, M.; Büschel, W.; Dachselt, R. MARVIS: Combining Mobile Devices and Augmented Reality for Visual Data Analysis. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI’21), Yokohama, Japan, 8–13 May 2021; Article 468. Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–17. [Google Scholar] [CrossRef]
- Bach, B.; Pietriga, E.; Fekete, J.-D. Visualizing dynamic networks with matrix cubes. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’14), Toronto, ON, Canada, 26 April–1 May 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 877–886. [Google Scholar] [CrossRef]
- Alper, B.; Bach, B.; Riche, N.H.; Isenberg, T.; Fekete, J.-D. Weighted graph comparison techniques for brain connectivity analysis. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’13), Paris, France, 27 April–2 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 483–492. [Google Scholar] [CrossRef]
- Yi, J.S.; Elmqvist, N.; Lee, S. TimeMatrix: Analyzing Temporal Social Networks Using Interactive Matrix-Based Visualizations. Int. J. Human-Computer Interact. 2010, 26, 1031–1051. [Google Scholar] [CrossRef]
- Nobre, C.; Meyer, M.; Streit, M.; Lex, A. The State of the Art in Visualizing Multivariate Networks. Comput. Graph. Forum 2019, 38, 807–832. [Google Scholar] [CrossRef]
- Abello, J.; van Ham, F. Matrix Zoom: A Visual Interface to Semi-External Graphs. In Proceedings of the IEEE Symposium on Information Visualization, Austin, TX, USA, 10–12 October 2004; pp. 183–190. [Google Scholar] [CrossRef]
- Viau, C.; McGuffin, M.J.; Chiricota, Y.; Jurisica, I. The FlowVizMenu and Parallel Scatterplot Matrix: Hybrid Multidimensional Visualizations for Network Exploration. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1100–1108. [Google Scholar] [CrossRef]
- Ko, S.; Afzal, S.; Walton, S.; Yang, Y.; Chae, J.; Malik, A.; Jang, Y.; Chen, M.; Ebert, D. Analyzing high-dimensional multivaríate network links with integrated anomaly detection, highlighting and exploration. In Proceedings of the 2014 IEEE Conference on Visual Analytics Science and Technology (VAST), Paris, France, 25–31 October 2014; pp. 83–92. [Google Scholar] [CrossRef]
- Bezerianos, A.; Chevalier, F.; Dragičević, P.; Elmqvist, N.; Fekete, J. GraphDice: A System for Exploring Multivariate Social Networks. Comput. Graph. Forum 2010, 29, 863–872. [Google Scholar] [CrossRef]
- Bach, B.; Dachselt, R.; Carpendale, S.; Dwyer, T.; Collins, C.; Lee, B. Immersive Analytics: Exploring Future Interaction and Visualization Technologies for Data Analytics. In Proceedings of the 2016 ACM International Conference on Interactive Surfaces and Spaces (ISS’16), Niagara Falls, ON, Canada, 6–9 November 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 529–533. [Google Scholar] [CrossRef]
- Cordeil, M.; Cunningham, A.; Dwyer, T.; Thomas, B.H.; Marriott, K. ImAxes: Immersive Axes as Embodied Affordances for Interactive Multivariate Data Visualisation. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology (UIST’17), Quebec City, QC, Canada, 22–25 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 71–83. [Google Scholar] [CrossRef]
- Sicat, R.; Li, J.; Choi, J.; Cordeil, M.; Jeong, W.-K.; Bach, B.; Pfister, H. DXR: A Toolkit for Building Immersive Data Visualizations. IEEE Trans. Vis. Comput. Graph. 2018, 25, 715–725. [Google Scholar] [CrossRef] [PubMed]
- Cordeil, M.; Cunningham, A.; Bach, B.; Hurter, C.; Thomas, B.H.; Marriott, K.; Dwyer, T. IATK: An Immersive Analytics Toolkit. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; pp. 200–209. [Google Scholar] [CrossRef]
- Liu, J.; Prouzeau, A.; Ens, B.; Dwyer, T. Design and Evaluation of Interactive Small Multiples Data Visualisation in Immersive Spaces. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Atlanta, GA, USA, 22–26 March 2020; pp. 588–597. [Google Scholar] [CrossRef]
- Hayatpur, D.; Xia, H.; Wigdor, D. DataHop: Spatial Data Exploration in Virtual Reality. In Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology (UIST’20), Virtual Event, 20–23 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 818–828. [Google Scholar] [CrossRef]
- Satriadi, K.A.; Ens, B.; Cordeil, M.; Czauderna, T.; Jenny, B. Maps Around Me. Proc. ACM Hum.-Comput. Interact. 2020, 4, 201. [Google Scholar] [CrossRef]
- Zhao, Y.; Shi, J.; Liu, J.; Zhao, J.; Zhou, F.; Zhang, W.; Chen, K.; Zhao, X.; Zhu, C.; Chen, W. Evaluating Effects of Background Stories on Graph Perception. IEEE Trans. Vis. Comput. Graph. 2021, 28, 4839–4854. [Google Scholar] [CrossRef]
- Whitlock, M.; Smart, S.; Szafir, D.A. Graphical Perception for Immersive Analytics. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Atlanta, GA, USA, 22–26 March 2020; pp. 616–625. [Google Scholar] [CrossRef]
- Inselberg, A.; Dimsdale, B. Parallel coordinates: A tool for visualizing multi-dimensional geometry. In Proceedings of the First IEEE Conference on Visualization: Visualization’90, San Francisco, CA, USA, 23–26 October 1990; pp. 361–378. [Google Scholar] [CrossRef]
- Kobayashi, H.; Furukawa, T.; Misue, K. Parallel Box: Visually Comparable Representation for Multivariate Data Analysis. In Proceedings of the 2014 18th International Conference on Information Visualisation, Paris, France, 16–18 July 2014; pp. 183–188. [Google Scholar] [CrossRef]
- Johansson, J.; Cooper, M.; Jern, M. 3-dimensional display for clustered multi-relational parallel coordinates. In Proceedings of the Ninth International Conference on Information Visualisation (IV’05), London, UK, 6–8 July 2005; pp. 188–193. [Google Scholar] [CrossRef]
- Artero, A.O.; de Oliveira, M.C.F.; Levkowitz, H. Uncovering clusters in crowded parallel coordinates visualizations. In Proceedings of the IEEE Symposium on Information Visualization, Austin, TX, USA, 10–12 October 2004; pp. 81–88. [Google Scholar]
- Bok, J.; Kim, B.; Seo, J. Augmenting Parallel Coordinates Plots With Color-Coded Stacked Histograms. IEEE Trans. Vis. Comput. Graph. 2020, 28, 2563–2576. [Google Scholar] [CrossRef] [PubMed]
- Valiati, E.R.A.; Pimenta, M.S.; Freitas, C.M.D.S. A taxonomy of tasks for guiding the evaluation of multidimensional visualizations. In Proceedings of the 2006 AVI Workshop on BEyond Time and Errors: Novel Evaluation Methods for Information Visualization (BELIV’06), Venice Italy, 23 May 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 1–6. [Google Scholar] [CrossRef]
- Archambault, D.; Abello, J.; Borner, K.; Diehl, S.; Dwyer, T.; Elmqvist, N.; Fekete, J.D.; Gou, L.; Hagen, H.; Holten, D.; et al. Multivariate Network Visualization. In Proceedings of the Dagstuhl Seminar 13201, Dagstuhl Castle, Germany, 12–17 May 2013; Springer: Cham, Switzerland, 2013; Volume 8380. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| One Attribute | Multi-Attribute | |
|---|---|---|
| Locate | T1 | T2 |
| Compare | T3 | T4 |
| Size | Type | M | SD | t | p | Line No. | |
|---|---|---|---|---|---|---|---|
| Locate Tasks | Small (S) | MVF | 19.85 | 10.98 | −3.15 | 0.003 ** | ➀ |
| EBC | 31.2 | 28.51 | ➁ | ||||
| Medium (M) | MVF | 32.24 | 20.73 | −4.285 | 0.000 ** | ➂ | |
| EBC | 49.94 | 27.07 | ➃ | ||||
| Large (L) | MVF | 48.4 | 22.88 | −6.404 | 0.000 ** | ➄ | |
| EBC | 102.9 | 59.75 | ➅ | ||||
| Compare Tasks | Small (S) | MVF | 16.93 | 7.28 | −2.492 | 0.016 * | ➆ |
| EBC | 21.16 | 11.66 | ➇ | ||||
| Medium (M) | MVF | 21.27 | 10.04 | −6.457 | 0.000 ** | ➈ | |
| EBC | 40.25 | 25.96 | ➉ | ||||
| Large (L) | MVF | 46.41 | 33.63 | −5.138 | 0.000 ** | ⑪ | |
| EBC | 85.79 | 53.43 | ⑫ |
| Size | Type | M | SD | t | p | Line No. | |
|---|---|---|---|---|---|---|---|
| Locate Tasks | Small (S) | MVF | 0.99 | 0.04 | 1.609 | 0.113 | ➀ |
| EBC | 0.96 | 0.17 | ➁ | ||||
| Medium (M) | MVF | 0.97 | 0.11 | 0.661 | 0.511 | ➂ | |
| EBC | 0.96 | 0.13 | ➃ | ||||
| Large (L) | MVF | 0.92 | 0.19 | 0.857 | 0.395 | ➄ | |
| EBC | 0.88 | 0.29 | ➅ | ||||
| Compare Tasks | Small (S) | MVF | 0.96 | 0.14 | 1.286 | 0.203 | ➆ |
| EBC | 0.91 | 0.27 | ➇ | ||||
| Medium (M) | MVF | 0.96 | 0.16 | 0.266 | 0.791 | ➈ | |
| EBC | 0.95 | 0.19 | ➉ | ||||
| Large (L) | MVF | 0.85 | 0.36 | 0.597 | 0.553 | ⑪ | |
| EBC | 0.81 | 0.35 | ⑫ |
| Size | Type | M | SD | t | p | Line No. | |
|---|---|---|---|---|---|---|---|
| Easy to Locate | Q1 (NoO) | MVF | 4.5 | 0.53 | 4.019 | 0.003 ** | ➀ |
| EBC | 2.8 | 1.4 | ➁ | ||||
| Q4 (PM) | MVF | 4.3 | 0.67 | 5.237 | 0.001 ** | ➂ | |
| EBC | 2.7 | 0.82 | ➃ | ||||
| Easy to Compare | Q2 (NoO) | MVF | 4.4 | 0.52 | 3 | 0.015 ** | ➄ |
| EBC | 3.4 | 1.07 | ➅ | ||||
| Q5 (PM) | MVF | 4.3 | 0.67 | 3.881 | 0.004 ** | ➆ | |
| EBC | 3 | 0.82 | ➇ | ||||
| Easy to Understand | Q3 (NoO) | MVF | 4.3 | 0.82 | 5.075 | 0.001 ** | ➈ |
| EBC | 2.6 | 0.84 | ➉ | ||||
| Q6 (PM) | MVF | 4.4 | 0.7 | 3.096 | 0.013 * | ⑪ | |
| EBC | 3 | 1.05 | ⑫ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Jin, Y.; Wu, S.; Liu, S. Multivariate Fence: Using Parallel Coordinates to Locate and Compare Attributes of Adjacency Matrix Nodes in Immersive Environment. Appl. Sci. 2022, 12, 12182. https://doi.org/10.3390/app122312182
Li T, Jin Y, Wu S, Liu S. Multivariate Fence: Using Parallel Coordinates to Locate and Compare Attributes of Adjacency Matrix Nodes in Immersive Environment. Applied Sciences. 2022; 12(23):12182. https://doi.org/10.3390/app122312182
Chicago/Turabian StyleLi, Tiemeng, Yanning Jin, Songqian Wu, and Shiran Liu. 2022. "Multivariate Fence: Using Parallel Coordinates to Locate and Compare Attributes of Adjacency Matrix Nodes in Immersive Environment" Applied Sciences 12, no. 23: 12182. https://doi.org/10.3390/app122312182
APA StyleLi, T., Jin, Y., Wu, S., & Liu, S. (2022). Multivariate Fence: Using Parallel Coordinates to Locate and Compare Attributes of Adjacency Matrix Nodes in Immersive Environment. Applied Sciences, 12(23), 12182. https://doi.org/10.3390/app122312182