
A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization


Abstract
1. Introduction
- 1.
- We constructed the UAV reconnaissance image tank database UAVT-3 for detection, which includes 1263 images, 7 scenes, 3 types of tanks, and 2241 marked objects.
- 2.
- In order to improve the ability to detect small objects and blurred objects, we improved YOLOv5 by using data augmentation of blurred samples, adding a larger feature map in the neck, and optimizing the loss function and anchor priors.
- 3.
- In order to improve the explanation, we introduced the feature visualization technique of Class Action Mapping (CAM) to explore the mechanism of the proposed model.
2. UAV Reconnaissance Image Tank Database
2.1. Image Capturing and Annotation
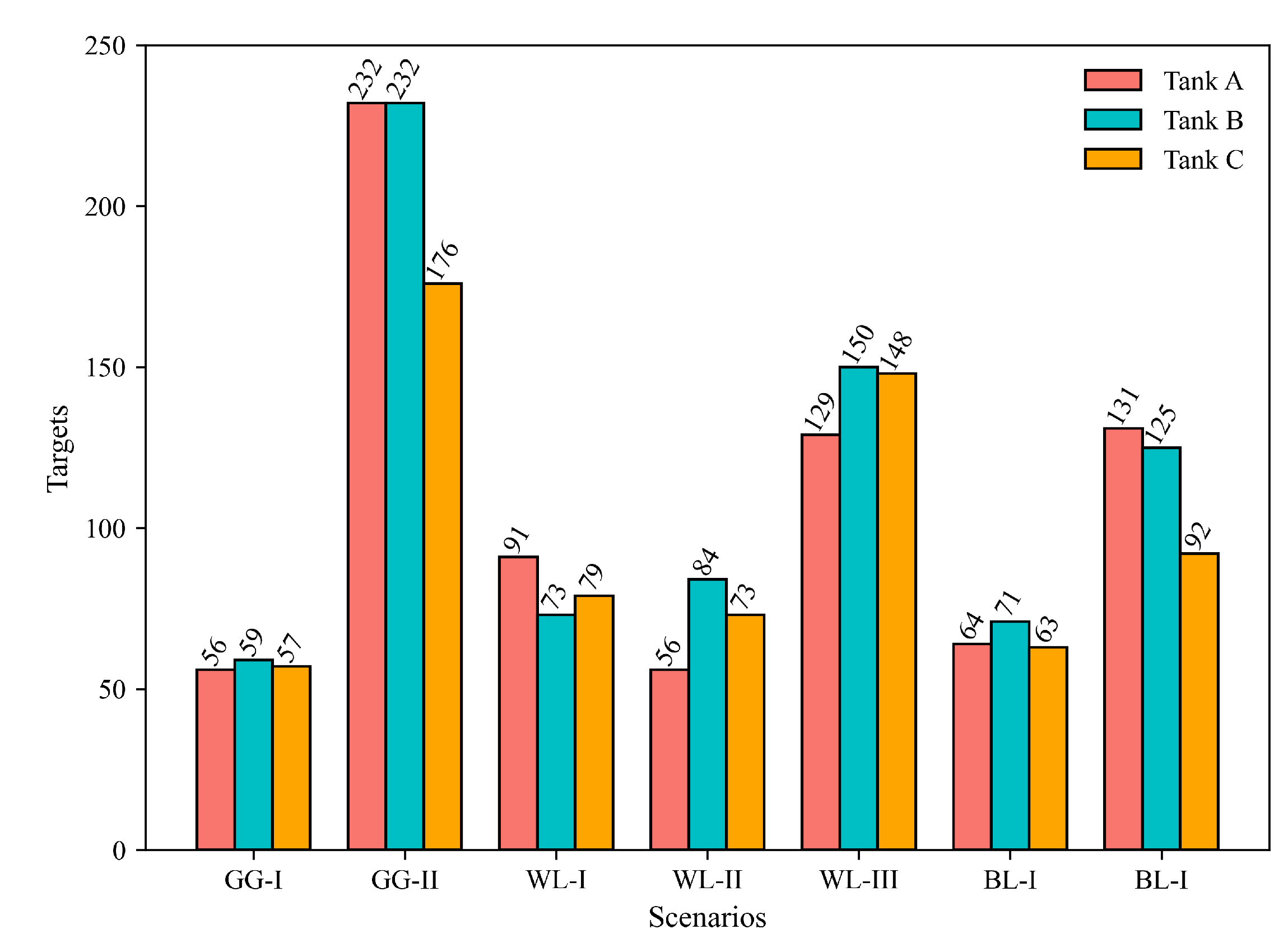
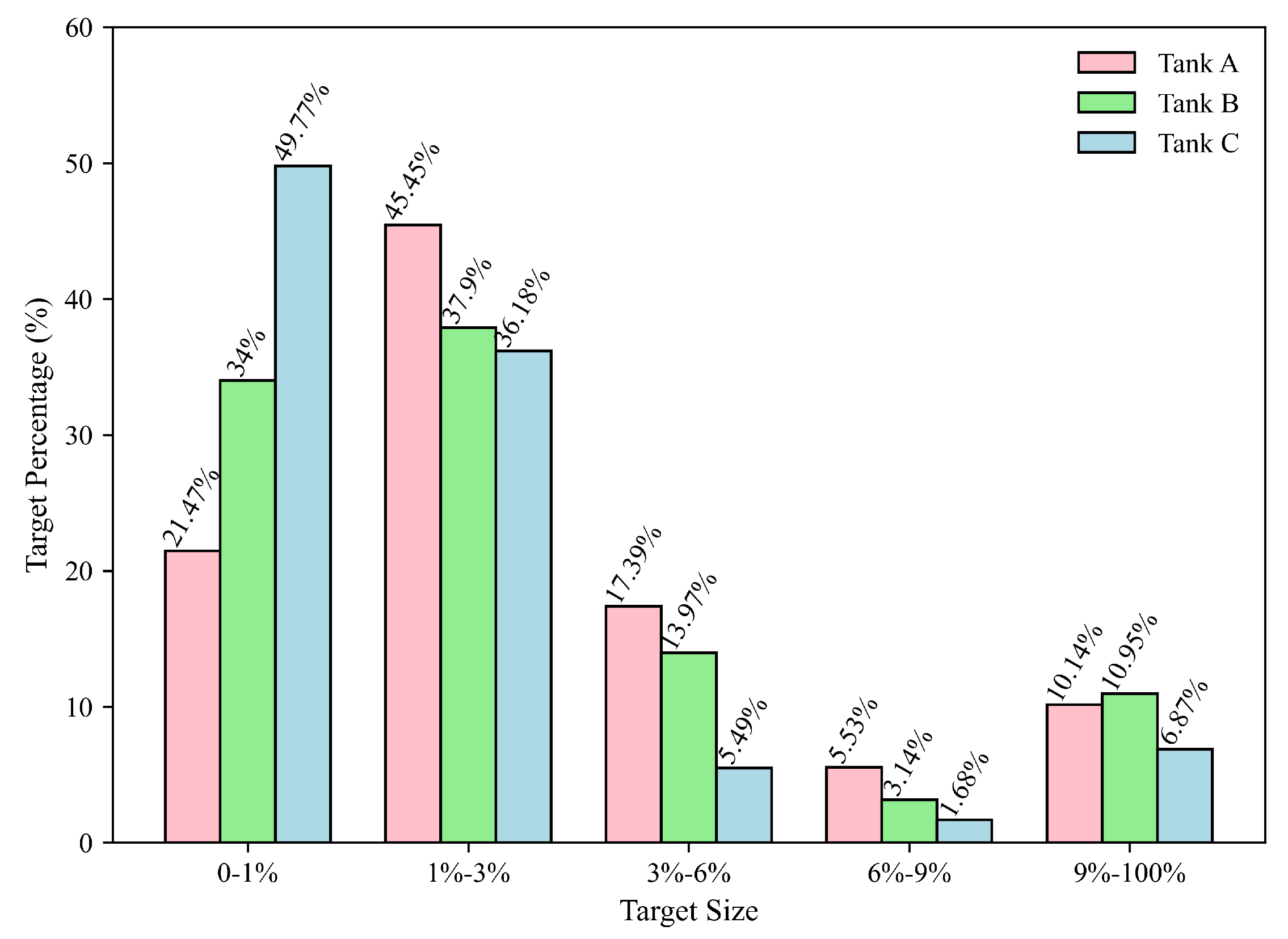
2.2. Dataset Statistics
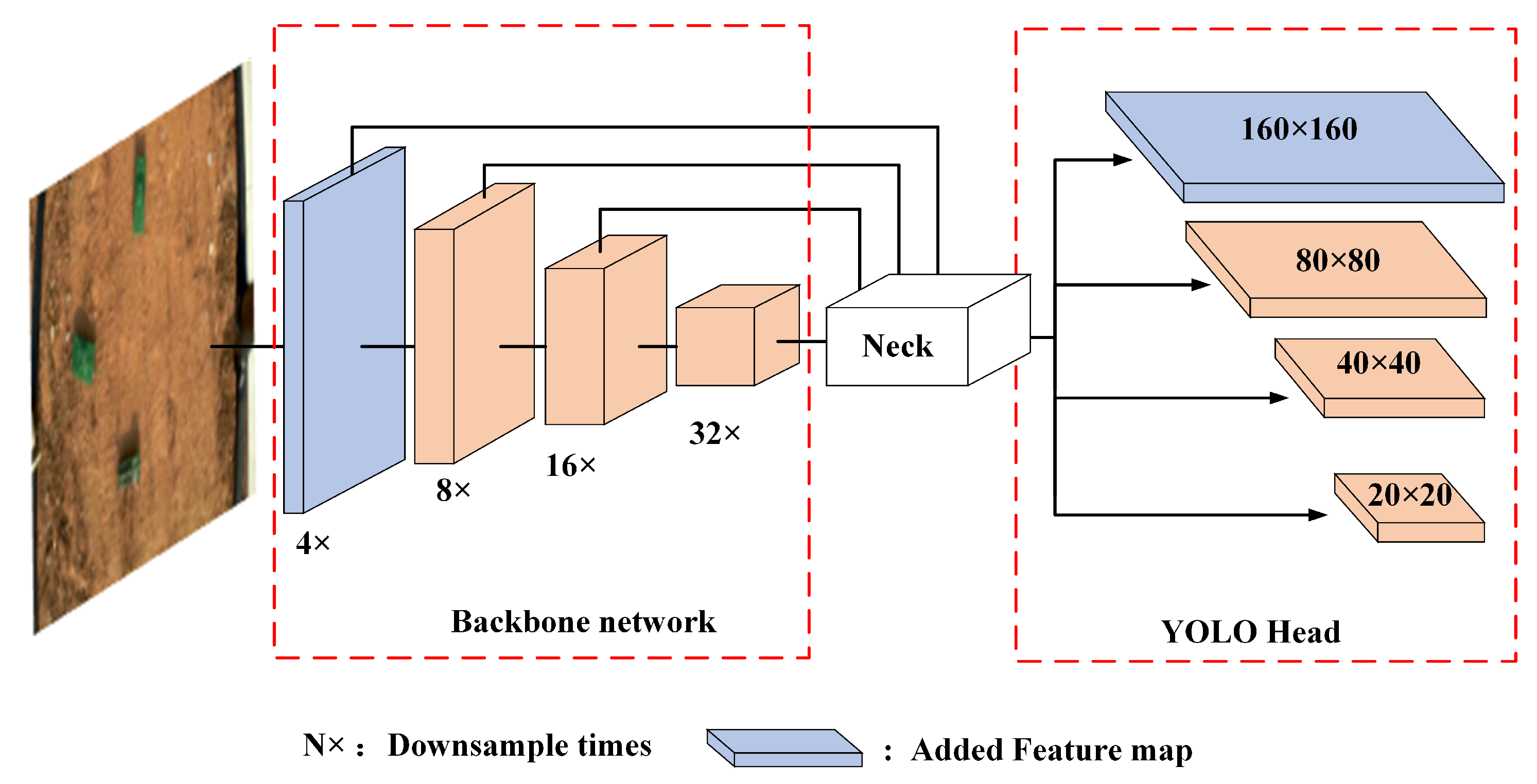
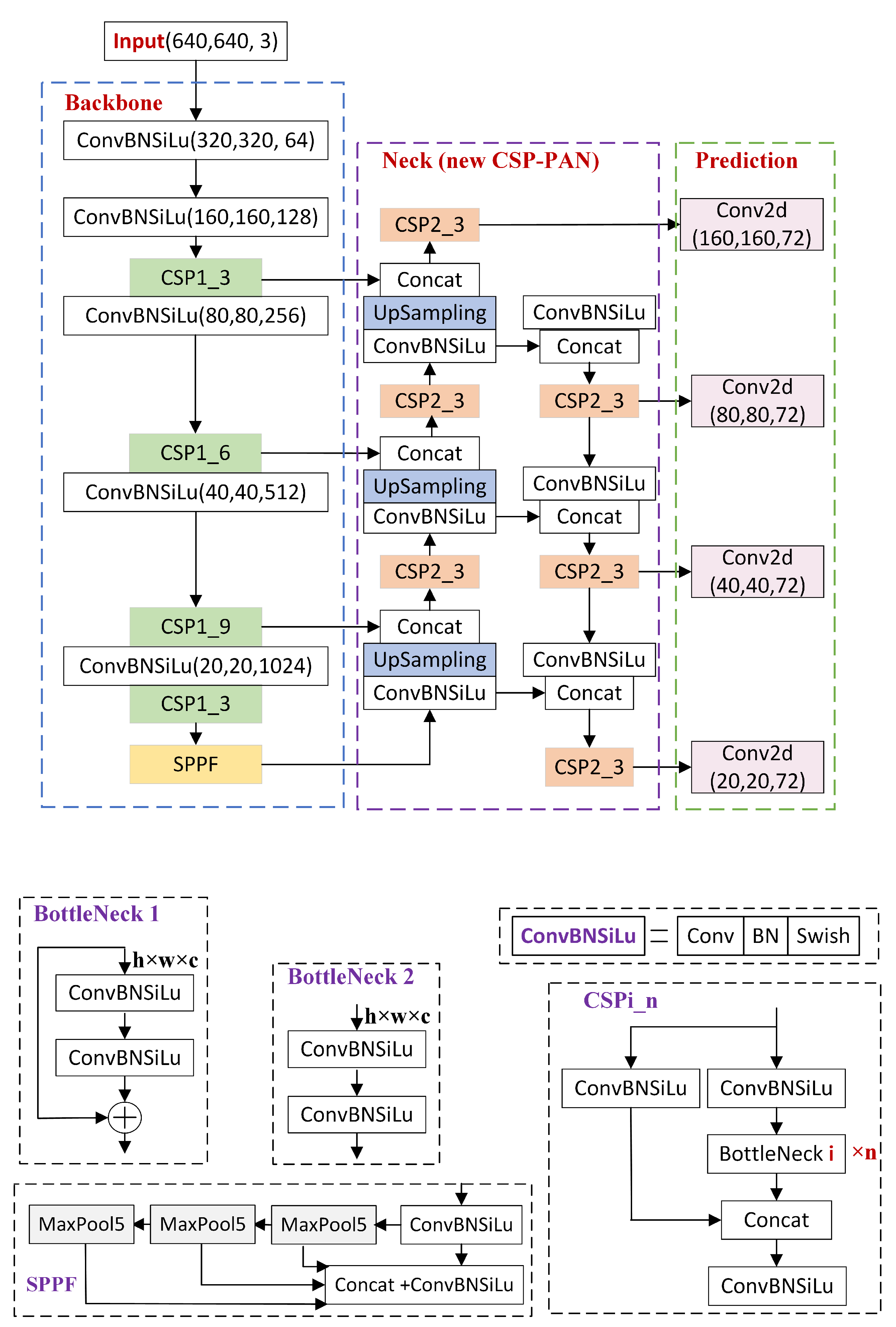
3. UAVT-YOLOv5 Model
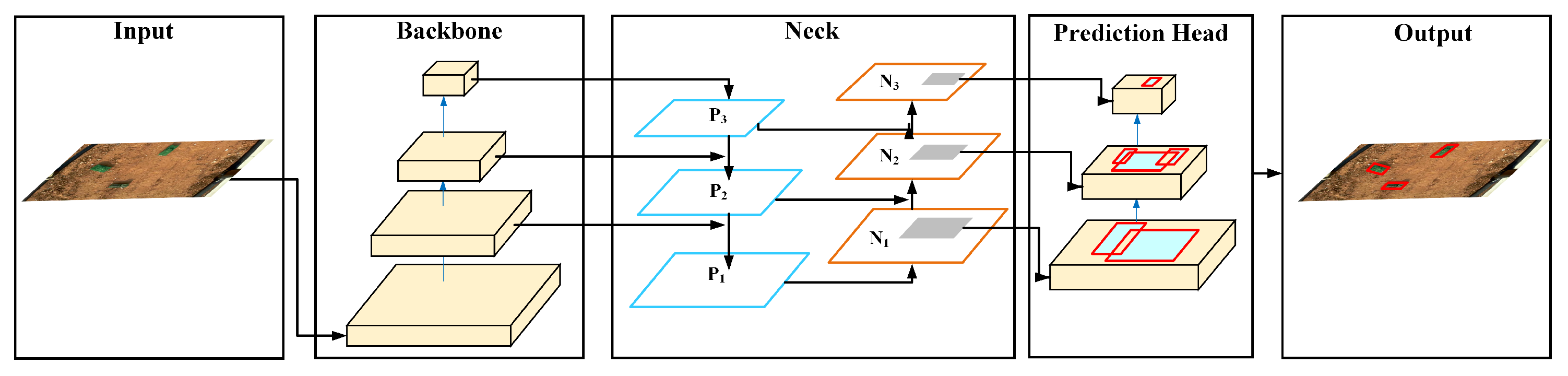
3.1. Structure of UAVT-YOLOv5
- 1.
- In the input part, data augmentation of blurred images is adopted to improve the accuracy of fog blur and motion blur images, which will be detailed in Section 3.2.
- 2.
- In the neck part, to improve the recognition ability of small objects, a larger scale feature map is added to mine more features from the small target, and the multi-scale feedback mechanism is introduced to combine the global context information, which will be detailed in Section 3.3.
- 3.
- The box confidence loss function and anchor priors are optimized by increasing the penalty of small objects and by re-clustering the object boxes of UAVT-3 with a k-means algorithm, which will be Section 3.4 and Section 3.5, respectively.
3.2. Data Augmentation of Blur Image
3.3. Feature Extractor and Fusion
3.4. Loss Function
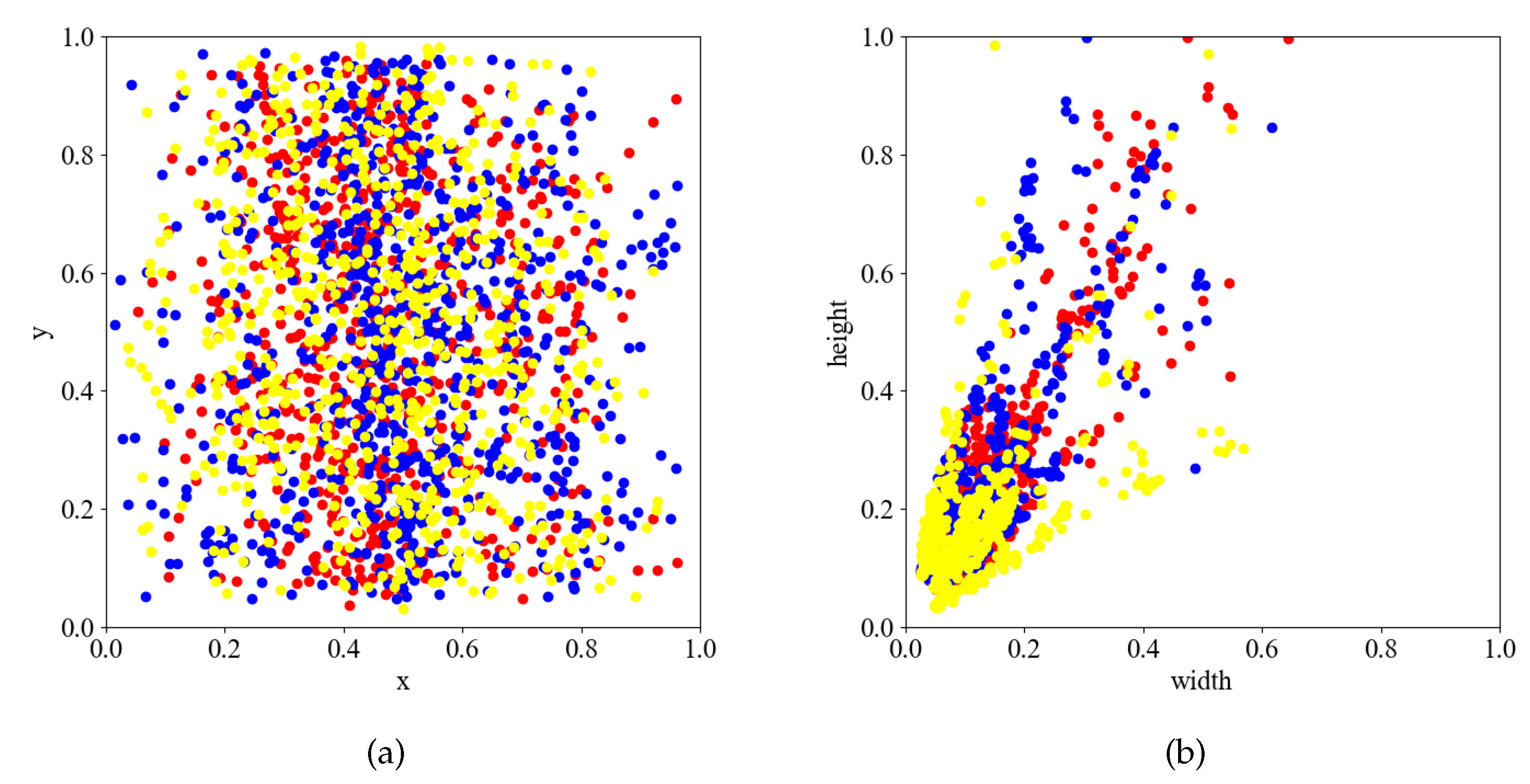
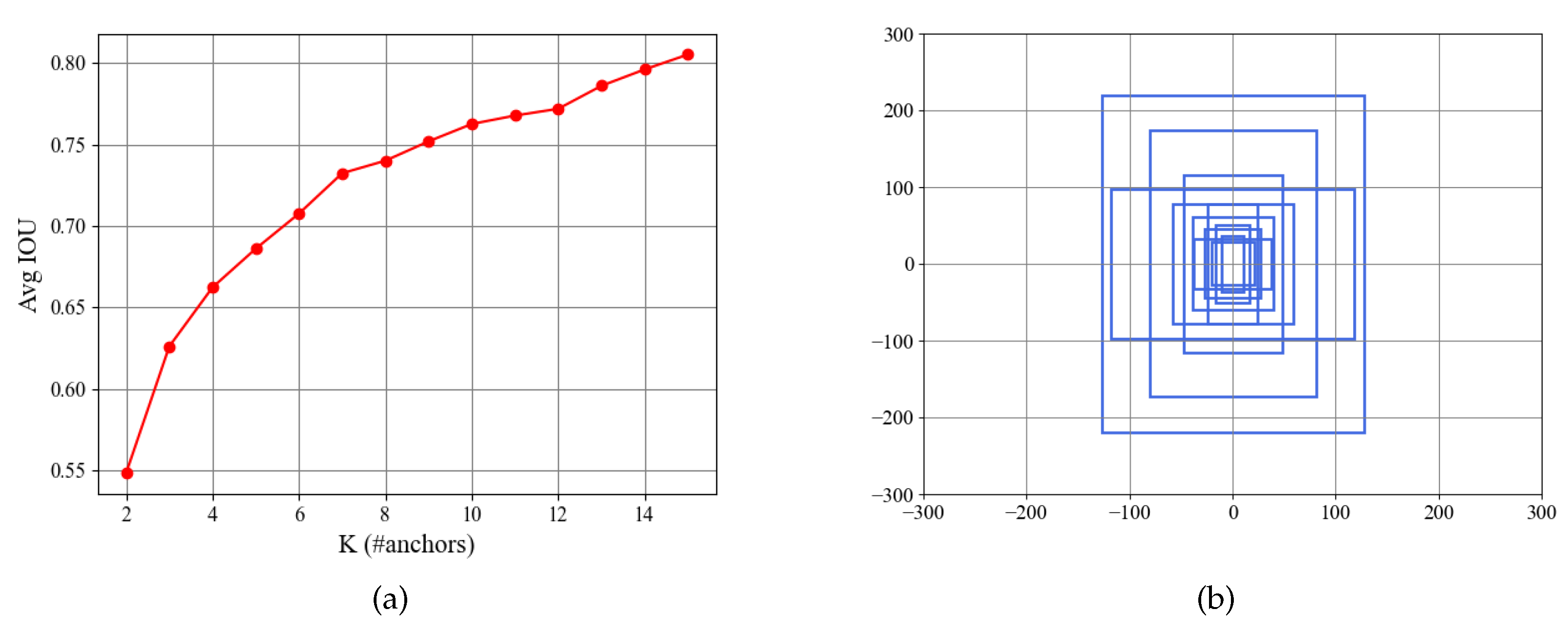
3.5. Anchor Box Setting
4. Experimental Results and Analysis
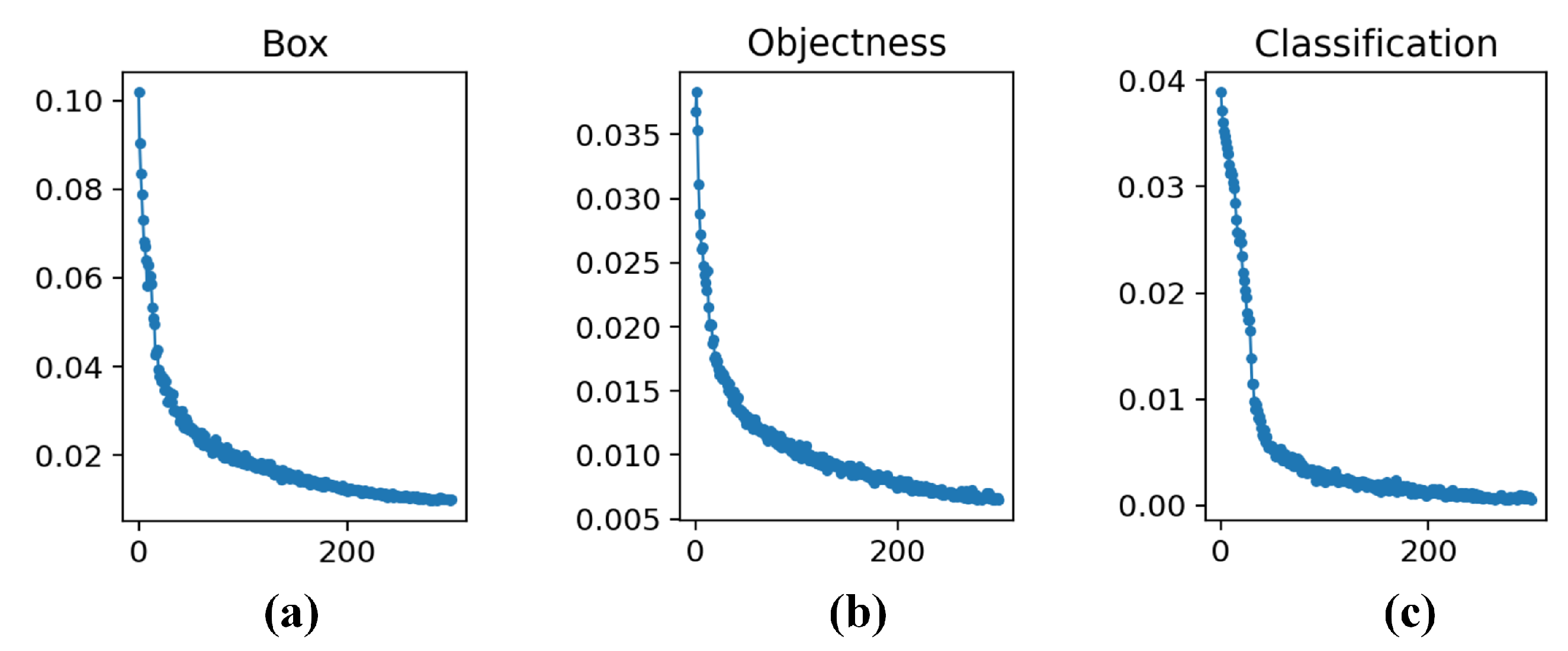
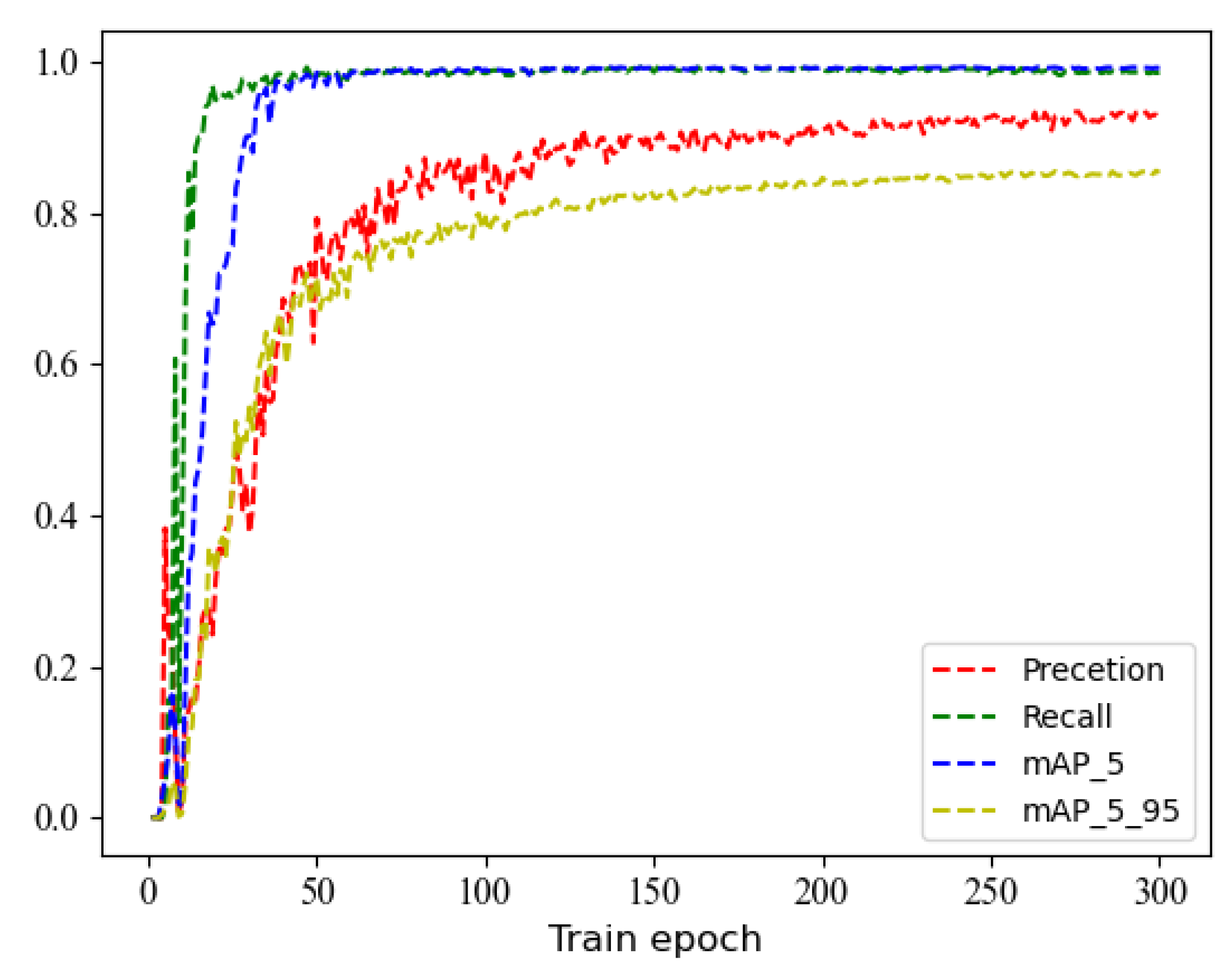
4.1. Experimental Setting and Model Training
4.2. Performance of Different Detection Models
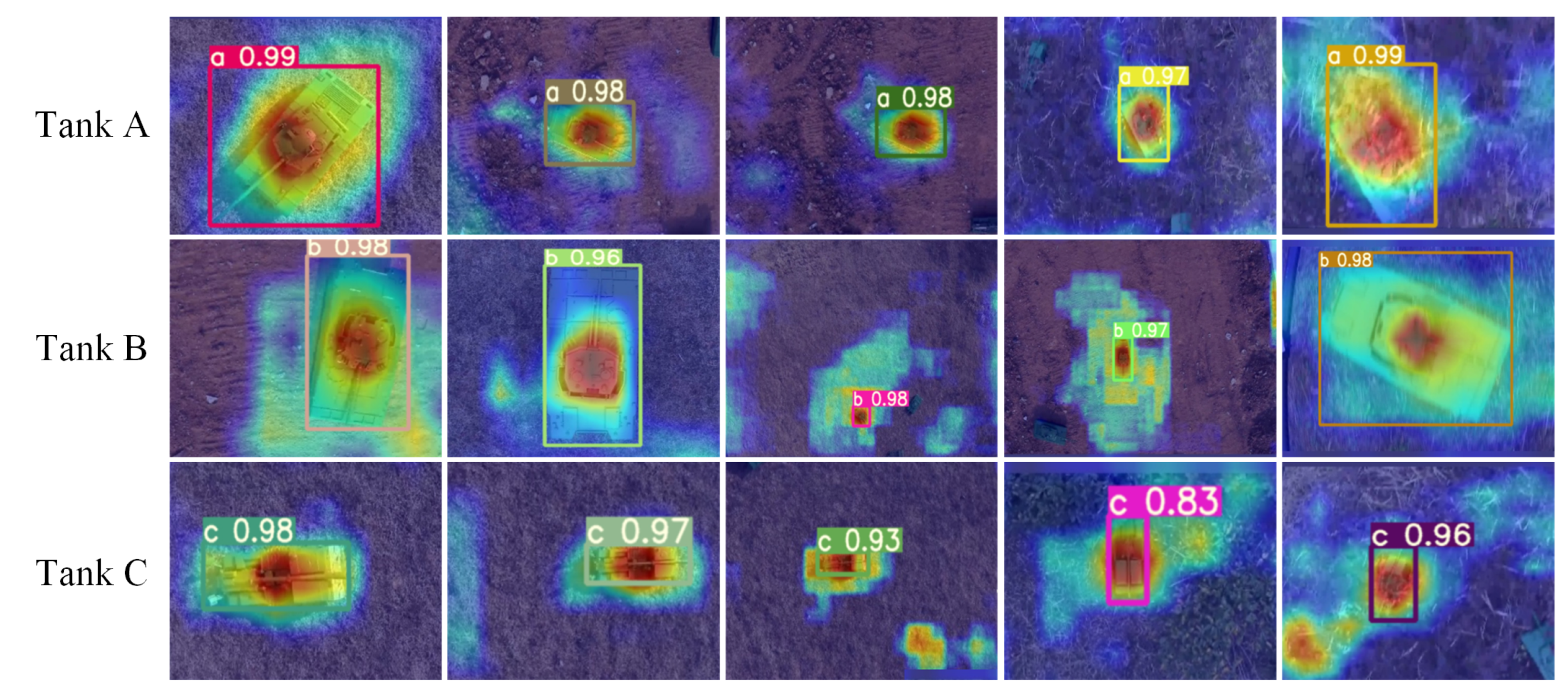
4.3. Analysis of Feature Visualization
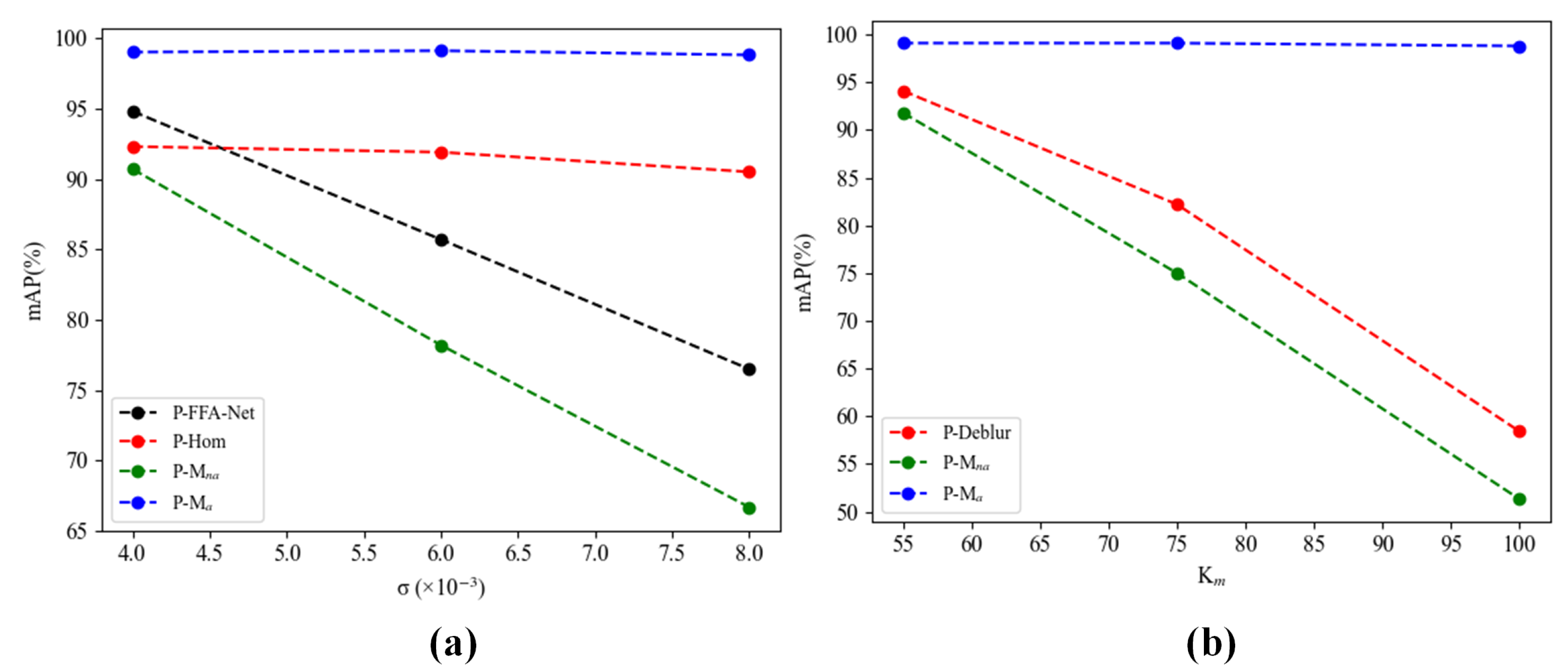
4.4. Effects of the Data Augmentation
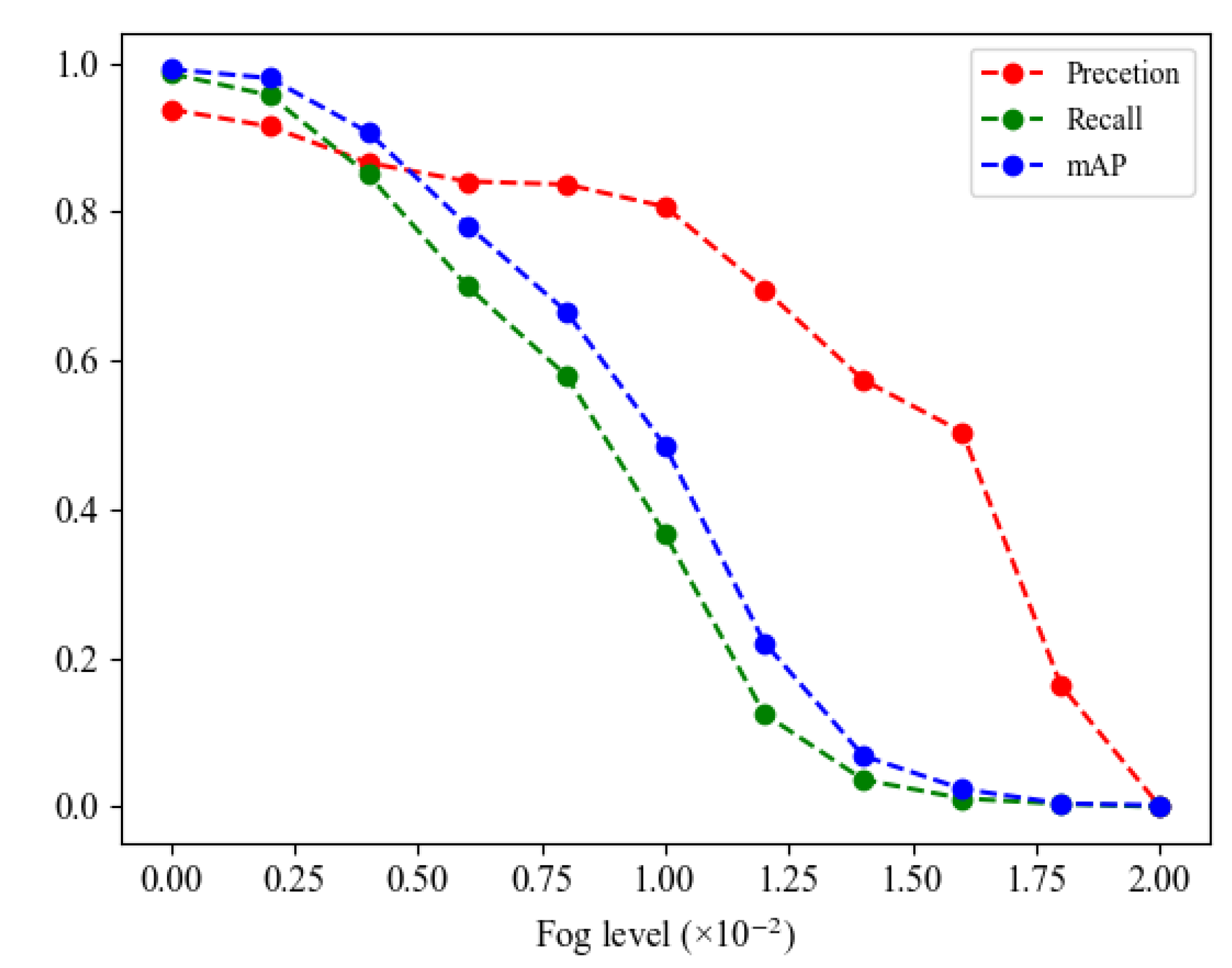
4.5. Further Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Volume 10, pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; Volume 10, pp. 1440–1448. [Google Scholar]
- Ren, S.; H, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE TPMI 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Darrell, T.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2021, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Yuan, H.; Liao, M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2021, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 10, pp. 2110–2118. [Google Scholar]
- Wang, C.; Liao, H.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the CVPR Workshop, Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Lin, T.; Dollar, P.; Girshich, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 2, pp. 740–755. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1063–6919. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-cam: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the CVPR Workshop, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Desai, S.; Ramaswamy, H.G. Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Aggarwal, A.K. Fusion and enhancement techniques for processing of multispectral images. In Unmanned Aerial Vehicle: Applications in Agriculture and Environment; Springer: Cham, Switzerland, 2020; pp. 159–179. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map | Size of Anchor Box | ||
|---|---|---|---|
| 160 × 160 | (22, 74) | (32, 102) | (41, 55) |
| 80 × 80 | (48, 156) | (54, 89) | (76, 64) |
| 40 × 40 | (79, 121) | (95, 230) | (117, 156) |
| 20 × 20 | (161, 347) | (236, 195) | (255, 440) |
| Models | AP (%) | mAP (%) | F1-Score (%) | Times (s) | FPS | ||
|---|---|---|---|---|---|---|---|
| Tank A | Tank B | Tank C | |||||
| Faster-RCNN [4] | 84.05 | 72.22 | 64.85 | 73.70 | 74.40 | 0.319 | 3.14 |
| SSD [6] | 96.01 | 97.14 | 95.33 | 96.16 | 91.98 | 0.0245 | 40.8 |
| YOLOv1 [5] | 71.21 | 57.60 | 60.23 | 63.02 | 61.20 | 0.069 | 14.4 |
| YOLOv2 [7] | 80.40 | 72.50 | 79.64 | 77.52 | 76.35 | 0.050 | 20.1 |
| YOLOv3 [8] | 98.00 | 91.67 | 98.00 | 95.22 | 82.22 | 0.041 | 24.76 |
| YOLOv4 [9] | 96.75 | 95.20 | 97.33 | 96.42 | 95.05 | 0.046 | 21.3 |
| YOLOv5 | 97.10 | 97.28 | 97.40 | 97.16 | 96.16 | 0.020 | 50 |
| Proposed | 99.20 | 99.00 | 99.40 | 99.20 | 98.31 | 0.025 | 40 |
| Blur Type | Blur Degree | Models | P (%) | R (%) | mAP (%) |
|---|---|---|---|---|---|
| Fog | = 0.004 | 86.6 | 85.0 | 90.7 | |
| 92.8 | 98.6 | 99.0 | |||
| = 0.006 | 84.1 | 70.0 | 78.2 | ||
| 93.8 | 98.6 | 99.1 | |||
| = 0.008 | 83.7 | 58.0 | 66.7 | ||
| 98.2 | 99.2 | 98.8 | |||
| Motion | = 55 | 91.5 | 87.4 | 91.8 | |
| 91.6 | 98.9 | 99.1 | |||
| = 75 | 80.0 | 69.5 | 75.0 | ||
| 90.8 | 99.1 | 99.1 | |||
| = 100 | 69.5 | 42.9 | 51.3 | ||
| 93.9 | 98.2 | 98.8 |
| Schemes | AP (%) | mAP (%) | ||
|---|---|---|---|---|
| Tank A | Tank B | Tank C | ||
| SS1 | 14.60 | 19.40 | 45.20 | 26.40 |
| SS2 | 49.80 | 59.00 | 86.20 | 65.00 |
| RS | 57.20 | 85.70 | 93.00 | 78.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Yu, Y.; Liu, S.; Wang, W. A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization. Appl. Sci. 2022, 12, 12236. https://doi.org/10.3390/app122312236
Liu H, Yu Y, Liu S, Wang W. A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization. Applied Sciences. 2022; 12(23):12236. https://doi.org/10.3390/app122312236
Chicago/Turabian StyleLiu, Huanhua, Yonghao Yu, Shengzong Liu, and Wei Wang. 2022. "A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization" Applied Sciences 12, no. 23: 12236. https://doi.org/10.3390/app122312236
APA StyleLiu, H., Yu, Y., Liu, S., & Wang, W. (2022). A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization. Applied Sciences, 12(23), 12236. https://doi.org/10.3390/app122312236