
Active Pattern Classification for Automatic Visual Exploration of Multi-Dimensional Data


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
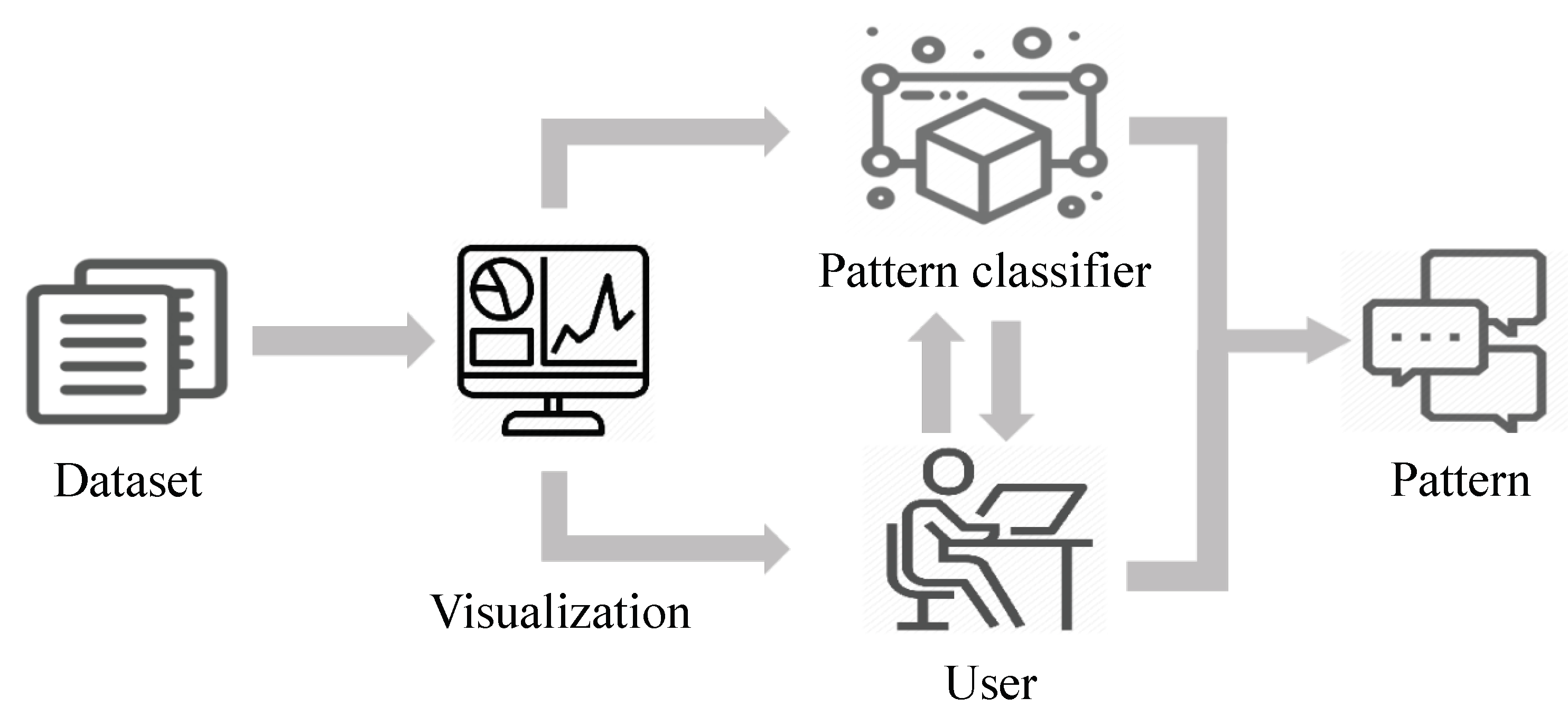
1. Introduction
- We propose an indicator for automatically identifying abnormal samples, enabling dynamic updating of the pattern classifier to cover all identified patterns during IDE;
- We design an IDE framework called random batch visualization exploration, enabling analysts to find representative patterns of the whole exploring space with few interactions.
2. Related Work
2.1. Active Sample Recommendation
2.2. Automatic Pattern Identification
3. Problem Statement
3.1. Application Scenarios
3.2. Challenges
- C1: Users may arbitrarily conduct data queries during IDE, inevitably generating visualizations with data patterns that have not been included in the PC. Thus, the first challenge to be resolved is how to automatically find these visualizations for updating PCs;
- C2: A PC changes the traditional IDE process taking the place of the human as the subject of pattern identification. How to construct a new visualization framework that adapts to this change and makes full use of a PC’s advantage in exploration efficiency is the second challenge.
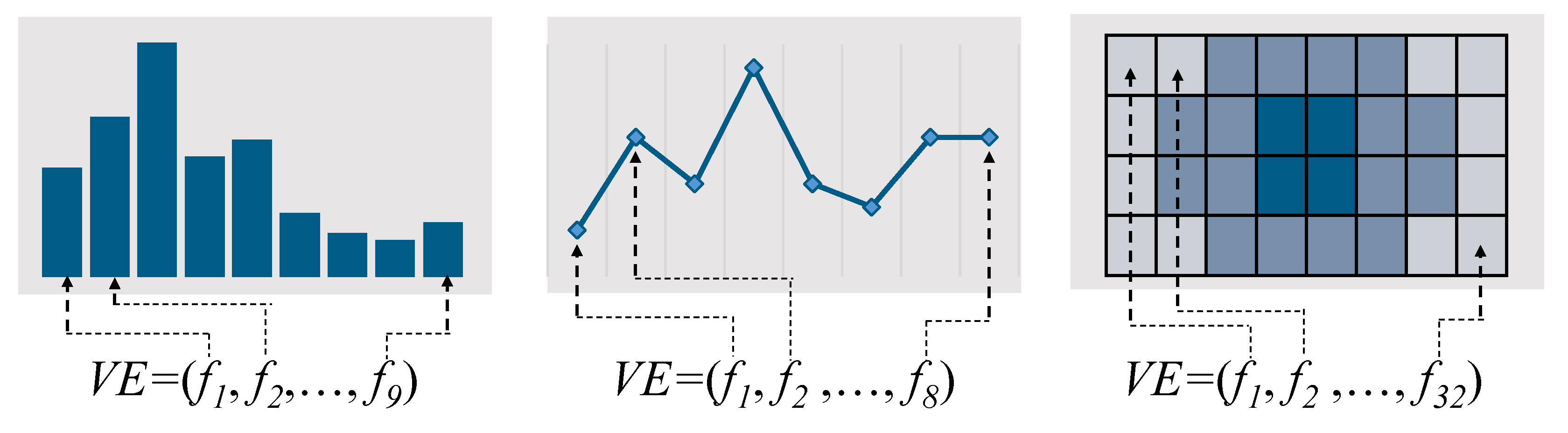
4. Input Normality Measurement
4.1. Sub-Model
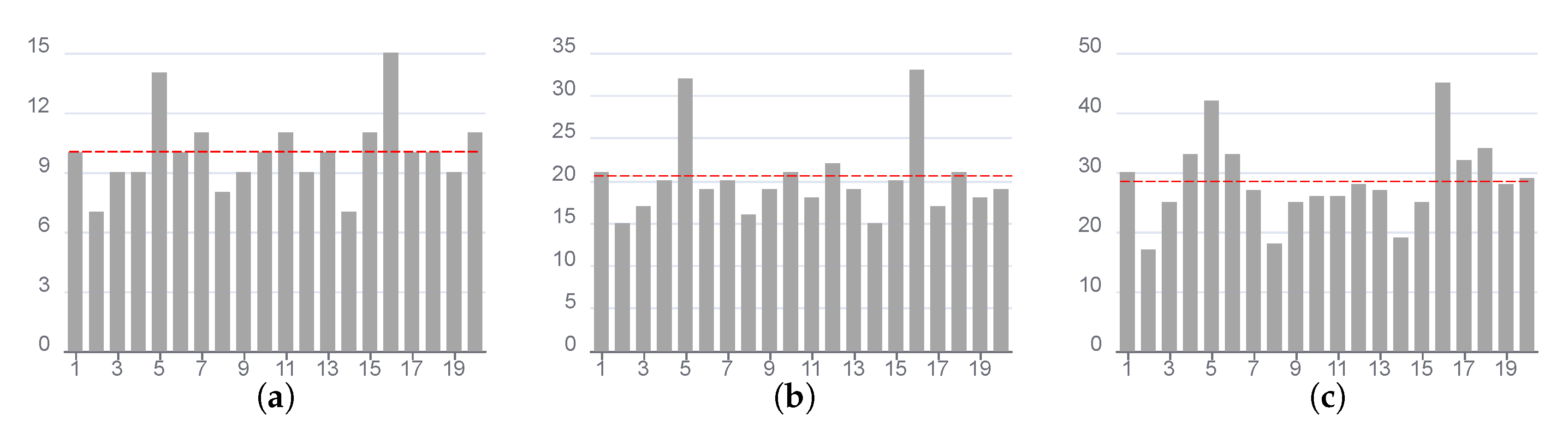
4.2. Preliminary Experiment
4.3. Indicator
5. Random Batch Visualization Exploration
5.1. Framework
5.2. PC Initialization
5.3. Proof-of-Concept Tool
6. Quantitative Experiments
7. User Study
7.1. Experiment Design
7.2. Representative Patterns
7.3. Objective Performance
7.4. Subjective Scores
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Battle, L.; Heer, J. Characterizing exploratory visual analysis: A literature review and evaluation of analytic provenance in tableau. Comput. Graph. Forum 2019, 38, 145–159. [Google Scholar] [CrossRef]
- Li, J.; Chen, S.; Zhang, K.; Andrienko, G.; Andrienko, N. COPE: Interactive exploration of co-occurrence patterns in spatial time series. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2554–2567. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Bakker, M.A.; Li, S.; Kraska, T.; Hidalgo, C. Vizml: A machine learning approach to visualization recommendation. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Dibia, V.; Demiralp, Ç. Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks. IEEE Comput. Graph. Appl. 2019, 39, 33–46. [Google Scholar] [CrossRef] [PubMed]
- Jäckle, D.; Hund, M.; Behrisch, M.; Keim, D.A.; Schreck, T. Pattern trails: Visual analysis of pattern transitions in subspaces. In Proceedings of the 2017 IEEE Conference on Visual Analytics Science and Technology (VAST), Phoenix, AZ, USA, 3–6 October 2017; pp. 1–12. [Google Scholar]
- Xie, P.; Tao, W.; Li, J.; Huang, W.; Chen, S. Exploring Multi-dimensional Data via Subset Embedding. Comput. Graph. Forum 2021, 40, 75–86. [Google Scholar] [CrossRef]
- Lehmann, D.J.; Theisel, H. Optimal sets of projections of high-dimensional data. IEEE Trans. Vis. Comput. Graph. 2015, 22, 609–618. [Google Scholar] [CrossRef]
- Krueger, R.; Beyer, J.; Jang, W.D.; Kim, N.W.; Sokolov, A.; Sorger, P.K.; Pfister, H. Facetto: Combining unsupervised and supervised learning for hierarchical phenotype analysis in multi-channel image data. IEEE Trans. Vis. Comput. Graph. 2019, 26, 227–237. [Google Scholar] [CrossRef]
- Pi, M.; Yeon, H.; Son, H.; Jang, Y. Visual cause analytics for traffic congestion. IEEE Trans. Vis. Comput. Graph. 2019, 27, 2186–2201. [Google Scholar] [CrossRef]
- Knaeble, M.; Nadj, M.; Maedche, A. Oracle or Teacher? A Systematic Overview of Research on Interactive Labeling for Machine Learning. In Proceedings of the 15th International Conference on Wirtschaftsinformatik (WI2020), Potsdam, Germany, 8–11 March 2020; pp. 2–16. [Google Scholar]
- Arendt, D.; Saldanha, E.; Wesslen, R.; Volkova, S.; Dou, W. Towards rapid interactive machine learning: Evaluating tradeoffs of classification without representation. In Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019; pp. 591–602. [Google Scholar]
- Beil, D.; Theissler, A. Cluster-Clean-Label: An interactive Machine Learning approach for labeling high-dimensional data. In Proceedings of the 13th International Symposium on Visual Information Communication and Interaction, Eindhoven, The Netherlands, 8–10 December 2020; pp. 1–8. [Google Scholar]
- Xia, J.; Lin, W.; Jiang, G.; Wang, Y.; Chen, W.; Schreck, T. Visual Clustering Factors in Scatterplots. IEEE Comput. Graph. Appl. 2021, 41, 79–89. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report 1648; University of Wisconsin—Madison: Madison, WI, USA, 2009. [Google Scholar]
- Fu, Y.; Zhu, X.; Li, B. A survey on instance selection for active learning. Knowl. Inf. Syst. 2013, 35, 249–283. [Google Scholar] [CrossRef]
- Culotta, A.; McCallum, A. Reducing labeling effort for structured prediction tasks. AAAI 2005, 5, 746–751. [Google Scholar]
- Scheffer, T.; Decomain, C.; Wrobel, S. Active hidden markov models for information extraction. In Proceedings of the International Symposium on Intelligent Data Analysis, Cascais, Portugal, 13–15 September 2001; pp. 309–318. [Google Scholar]
- Settles, B.; Craven, M. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 1070–1079. [Google Scholar]
- Simpson, E.H. Measurement of diversity. Nature 1949, 163, 688. [Google Scholar] [CrossRef]
- Dagan, I.; Engelson, S.P. Committee-based sampling for training probabilistic classifiers. In Machine Learning Proceedings 1995; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 150–157. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Acm Sigmobile Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- McCallumzy, A.K.; Nigamy, K. Employing EM and pool-based active learning for text classification. ICML 1998, 98, 359–367. [Google Scholar]
- Bernard, J.; Zeppelzauer, M.; Sedlmair, M.; Aigner, W. VIAL: A unified process for visual interactive labeling. Vis. Comput. 2018, 34, 1189–1207. [Google Scholar] [CrossRef]
- Junaidi, A.; Fink, G.A. A semi-supervised ensemble learning approach for character labeling with minimal human effort. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 259–263. [Google Scholar]
- Moehrmann, J.; Bernstein, S.; Schlegel, T.; Werner, G.; Heidemann, G. Improving the usability of hierarchical representations for interactively labeling large image data sets. In International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 618–627. [Google Scholar]
- Khayat, M.; Karimzadeh, M.; Zhao, J.; Ebert, D.S. VASSL: A visual analytics toolkit for social spambot labeling. IEEE Trans. Vis. Comput. Graph. 2019, 26, 874–883. [Google Scholar] [CrossRef]
- Bernard, J.; Zeppelzauer, M.; Lehmann, M.; Müller, M.; Sedlmair, M. Towards User-Centered Active Learning Algorithms. Comput. Graph. Forum 2018, 37, 121–132. [Google Scholar] [CrossRef]
- Grimmeisen, B.; Theissler, A. The machine learning model as a guide: Pointing users to interesting instances for labeling through visual cues. In Proceedings of the International Symposium on Visual Information Communication and Interaction, Eindhoven, The Netherlands, 8–10 December 2020; pp. 1–8. [Google Scholar]
- Chegin, M.; Bernard, J.; Cui, J.; Chegini, F.; Sourin, A.; Keith, K.; Schreck, T. Interactive visual labelling versus active learning: An experimental comparison. Front. Inf. Technol. Electron. Eng. 2020, 21, 524–535. [Google Scholar] [CrossRef]
- Bernard, J.; Hutter, M.; Zeppelzauer, M.; Fellner, D.; Sedlmair, M. Comparing visual-interactive labeling with active learning: An experimental study. IEEE Trans. Vis. Comput. Graph. 2017, 24, 298–308. [Google Scholar] [CrossRef]
- Höferlin, B.; Netzel, R.; Höferlin, M.; Weiskopf, D.; Heidemann, G. Interactive learning of ad-hoc classifiers for video visual analytics. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 23–32. [Google Scholar]
- Chegini, M.; Bernard, J.; Berger, P.; Sourin, A.; Andrews, K.; Schreck, T. Interactive labelling of a multivariate dataset for supervised machine learning using linked visualisations, clustering, and active learning. Vis. Inform. 2019, 3, 9–17. [Google Scholar] [CrossRef]
- Felix, C.; Dasgupta, A.; Bertini, E. The exploratory labeling assistant: Mixed-initiative label curation with large document collections. In Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology, Berlin, Germany, 14–17 October 2018; pp. 153–164. [Google Scholar]
- Tukey, J.W.; Tukey, P.A. Some graphics for studying four-dimensional data. In Computer Science and Statistics: Proceedings of the 14th Symposium on the Interface; Springer: Berlin/Heidelberg, Germany, 1982; pp. 60–66. [Google Scholar]
- Tukey, J.W.; Tukey, P.A. Computer graphics and exploratory data analysis: An introduction. In Proceedings of the Sixth Annual Conference and Exposition: Computer Graphics, Dallas, TX, USA, 14–18 April 1985; Volume 85, pp. 773–785. [Google Scholar]
- Sedlmair, M.; Tatu, A.; Munzner, T.; Tory, M. A taxonomy of visual cluster separation factors. Comput. Graph. Forum 2012, 31, 1335–1344. [Google Scholar] [CrossRef]
- Tatu, A.; Albuquerque, G.; Eisemann, M.; Schneidewind, J.; Theisel, H.; Magnork, M.; Keim, D. Combining automated analysis and visualization techniques for effective exploration of high-dimensional data. In Proceedings of the 2009 IEEE Symposium on Visual Analytics Science and Technology, Virtually, 25–30 October 2009; pp. 59–66. [Google Scholar]
- Abbas, M.M.; Aupetit, M.; Sedlmair, M.; Bensmail, H. Clustme: A visual quality measure for ranking monochrome scatterplots based on cluster patterns. Comput. Graph. Forum 2019, 38, 225–236. [Google Scholar] [CrossRef]
- Aupetit, M.; Sedlmair, M. Sepme: 2002 new visual separation measures. In Proceedings of the 2016 IEEE Pacific Visualization Symposium (PacificVis), Taipei, Taiwan, 19–22 April 2016; pp. 1–8. [Google Scholar]
- Matute, J.; Telea, A.C.; Linsen, L. Skeleton-based scagnostics. IEEE Trans. Vis. Comput. Graph. 2017, 24, 542–552. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, Z.; Liu, T.; Correll, M.; Cheng, Z.; Deussen, O.; Sedlmair, M. Improving the robustness of scagnostics. IEEE Trans. Vis. Comput. Graph. 2019, 26, 759–769. [Google Scholar] [CrossRef] [PubMed]
- Ryan, G.; Mosca, A.; Chang, R.; Wu, E. At a glance: Pixel approximate entropy as a measure of line chart complexity. IEEE Trans. Vis. Comput. Graph. 2018, 25, 872–881. [Google Scholar] [CrossRef] [PubMed]
- Dang, T.N.; Anand, A.; Wilkinson, L. Timeseer: Scagnostics for high-dimensional time series. IEEE Trans. Vis. Comput. Graph. 2012, 19, 470–483. [Google Scholar] [CrossRef] [PubMed]
- Halim, Z.; Muhammad, T. Quantifying and optimizing visualization: An evolutionary computing-based approach. Inf. Sci. 2017, 385, 284–313. [Google Scholar] [CrossRef]
- Li, J.; Zhou, C.Q. Incorporation of Human Knowledge Into Data Embeddings to Improve Pattern Significance and Interpretability. IEEE Trans. Vis. Comput. Graph. 2022. early access. [Google Scholar] [CrossRef]
- Blumenschein, M.; Zhang, X.; Pomerenke, D.; Keim, D.A.; Fuchs, J. Evaluating reordering strategies for cluster identification in parallel coordinates. Comput. Graph. Forum 2020, 39, 537–549. [Google Scholar] [CrossRef]
- Pomerenke, D.; Dennig, F.L.; Keim, D.A.; Fuchs, J.; Blumenschein, M. Slope-Dependent Rendering of Parallel Coordinates to Reduce Density Distortion and Ghost Clusters. In Proceedings of the 2019 IEEE Visualization Conference (VIS), Vancouver, BC, Canada, 20–25 October 2019; pp. 86–90. [Google Scholar]
- Dasgupta, A.; Kosara, R. Pargnostics: Screen-space metrics for parallel coordinates. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1017–1026. [Google Scholar] [CrossRef]
- Xia, J.; Chen, T.; Zhang, L.; Chen, W.; Chen, Y.; Zhang, X.; Xie, C.; Schreck, T. SMAP: A Joint Dimensionality Reduction Scheme for Secure Multi-Party Visualization. In Proceedings of the 2020 IEEE Conference on Visual Analytics Science and Technology (VAST), Salt Lake City, UT, USA, 25–30 October 2020; pp. 107–118. [Google Scholar]
- Zhao, Y.; Shi, J.; Liu, J.; Zhao, J.; Zhou, F.; Zhang, W.; Chen, K.; Zhao, X.; Zhu, C.; Chen, W. Evaluating effects of background stories on graph perception. IEEE Trans. Vis. Comput. Graph. 2021, 28, 12. [Google Scholar] [CrossRef]
- Dennig, F.L.; Fischer, M.T.; Blumenschein, M.; Fuchs, J.; Keim, D.A.; Dimara, E. ParSetgnostics: Quality Metrics for Parallel Sets. Comput. Graph. Forum 2021, 40, 375–386. [Google Scholar] [CrossRef]
- Hu, R.; Chen, B.; Xu, J.; Van Kaick, O.; Deussen, O.; Huang, H. Shape-driven Coordinate Ordering for Star Glyph Sets via Reinforcement Learning. IEEE Trans. Vis. Comput. Graph. 2021, 27, 3034–3047. [Google Scholar] [CrossRef] [PubMed]
- Albuquerque, G.; Eisemann, M.; Lehmann, D.J.; Theisel, H.; Magnor, M. Improving the visual analysis of high-dimensional datasets using quality measures. In Proceedings of the 2010 IEEE Symposium on Visual Analytics Science and Technology, Salt Lake City, UT, USA, 25–26 October 2010; pp. 19–26. [Google Scholar]
- Seo, J.; Shneiderman, B. A rank-by-feature framework for unsupervised multidimensional data exploration using low dimensional projections. In Proceedings of the IEEE Symposium on Information Visualization, Austin, TX, USA, 10–12 October 2004; pp. 65–72. [Google Scholar]
- Piringer, H.; Berger, W.; Hauser, H. Quantifying and comparing features in high-dimensional datasets. In Proceedings of the International Conference Information Visualisation, London, UK, 9–11 July 2008; pp. 240–245. [Google Scholar]
- Li, J.; Chen, S.; Chen, W.; Andrienko, G.; Andrienko, N. Semantics-space-time cube: A conceptual framework for systematic analysis of texts in space and time. IEEE Trans. Vis. Comput. Graph. 2018, 26, 1789–1806. [Google Scholar] [CrossRef]
- Chen, S.; Li, J.; Andrienko, G.; Andrienko, N.; Wang, Y.; Nguyen, P.H.; Turkay, C. Supporting story synthesis: Bridging the gap between visual analytics and storytelling. IEEE Trans. Vis. Comput. Graph. 2018, 26, 2499–2516. [Google Scholar] [CrossRef] [PubMed]
- Vartak, M.; Madden, S.; Parameswaran, A.; Polyzotis, N. SeeDB: Supporting visual analytics with data-driven recommendations. Proc. Vldb Endow. 2015, 8, 2015. [Google Scholar] [CrossRef]
- Wills, G.; Wilkinson, L. Autovis: Automatic visualization. Inf. Vis. 2010, 9, 47–69. [Google Scholar] [CrossRef]
- Lee, D.J.L.; Dev, H.; Hu, H.; Elmeleegy, H.; Parameswaran, A. Avoiding drill-down fallacies with vispilot: Assisted exploration of data subsets. In Proceedings of the International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019; pp. 186–196. [Google Scholar]
- Demiralp, C.; Haas, P.J.; Parthasarathy, S.; Pedapati, T. Foresight: Recommending Visual Insights. arXiv 2017, arXiv:1707.03877. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Z.; Zhang, H.; Cui, W.; Xu, K.; Ma, X.; Zhang, D. Datashot: Automatic generation of fact sheets from tabular data. IEEE Trans. Vis. Comput. Graph. 2019, 26, 895–905. [Google Scholar] [CrossRef]
- Siddiqui, T.; Kim, A.; Lee, J.; Karahalios, K.; Parameswaran, A. Effortless Data Exploration with zenvisage: An Expressive and Interactive Visual Analytics System. arXiv 2016, arXiv:1604.03583. [Google Scholar] [CrossRef]
- Bertini, E.; Tatu, A.; Keim, D. Quality metrics in high-dimensional data visualization: An overview and systematization. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2203–2212. [Google Scholar] [CrossRef]
- Behrisch, M.; Blumenschein, M.; Kim, N.W.; Shao, L.; El-Assady, M.; Fuchs, J.; Seebacher, D.; Diehl, A.; Brandes, U.; Pfister, H.; et al. Quality metrics for information visualization. Comput. Graph. Forum 2018, 37, 625–662. [Google Scholar] [CrossRef]
- Law, P.M.; Endert, A.; Stasko, J. Characterizing automated data insights. In Proceedings of the 2020 IEEE Visualization Conference (VIS), Salt Lake City, UT, USA, 25–30 October 2020; pp. 171–175. [Google Scholar]
- Zhao, Y.; Ge, L.; Xie, H.; Bai, G.; Zhang, Z.; Wei, Q.; Lin, Y.; Liu, Y.; Zhou, F. ASTF: Visual abstractions of time-varying patterns in radio signals. IEEE Trans. Vis. Comput. Graph. 2022. early access. [Google Scholar] [CrossRef] [PubMed]
- Satyanarayan, A.; Moritz, D.; Wongsuphasawat, K.; Heer, J. Vega-lite: A grammar of interactive graphics. IEEE Trans. Vis. Comput. Graph. 2016, 23, 341–350. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Qin, X.; Tang, N.; Li, G. Deepeye: Towards automatic data visualization. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 101–112. [Google Scholar]
- Moritz, D.; Wang, C.; Nelson, G.L.; Lin, H.; Smith, A.M.; Howe, B.; Heer, J. Formalizing visualization design knowledge as constraints: Actionable and extensible models in draco. IEEE Trans. Vis. Comput. Graph. 2018, 25, 438–448. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Ghosh, S.; Li, D.; Tasci, S.; Heck, L.; Zhang, H.; Kuo, C.C.J. Class-incremental learning via deep model consolidation. In Proceedings of the Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1131–1140. [Google Scholar]
- Belouadah, E.; Popescu, A. Il2m: Class incremental learning with dual memory. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 583–592. [Google Scholar]
- Hu, X.; Tang, K.; Miao, C.; Hua, X.S.; Zhang, H. Distilling causal effect of data in class-incremental learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3957–3966. [Google Scholar]
- Bosch, H.; Thom, D.; Heimerl, F.; Püttmann, E.; Koch, S.; Krüger, R.; Wörner, M.; Ertl, T. Scatterblogs2: Real-time monitoring of microblog messages through user-guided filtering. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2022–2031. [Google Scholar] [CrossRef]
- Snyder, L.S.; Lin, Y.S.; Karimzadeh, M.; Goldwasser, D.; Ebert, D.S. Interactive learning for identifying relevant tweets to support real-time situational awareness. IEEE Trans. Vis. Comput. Graph. 2019, 26, 558–568. [Google Scholar] [CrossRef]
- Heimerl, F.; Koch, S.; Bosch, H.; Ertl, T. Visual classifier training for text document retrieval. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2839–2848. [Google Scholar] [CrossRef]
- Gramazio, C.C.; Huang, J.; Laidlaw, D.H. An Analysis of Automated Visual Analysis Classification: Interactive Visualization Task Inference of Cancer Genomics Domain Experts. IEEE Trans. Vis. Comput. Graph. 2017, 24, 2270–2283. [Google Scholar] [CrossRef]
- Law, P.M.; Basole, R.C.; Wu, Y. Duet: Helping data analysis novices conduct pairwise comparisons by minimal specification. IEEE Trans. Vis. Comput. Graph. 2018, 25, 427–437. [Google Scholar] [CrossRef]
- Dennig, F.L.; Polk, T.; Lin, Z.; Schreck, T.; Pfister, H.; Behrisch, M. FDive: Learning relevance models using pattern-based similarity measures. In Proceedings of the 019 IEEE conference on visual analytics science and technology (VAST), Vancouver, BC, Canada, 20–25 October 2019; pp. 69–80. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 1 March 2022).
- LeCun, Y. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 1 March 2022).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Xia, J.; Zhang, Y.; Song, J.; Chen, Y.; Wang, Y.; Liu, S. Revisiting Dimensionality Reduction Techniques for Visual Cluster Analysis: An Empirical Study. IEEE Trans. Vis. Comput. Graph. 2022, 28, 529–539. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Tan, H.; Huang, W. Active Pattern Classification for Automatic Visual Exploration of Multi-Dimensional Data. Appl. Sci. 2022, 12, 11386. https://doi.org/10.3390/app122211386
Li J, Tan H, Huang W. Active Pattern Classification for Automatic Visual Exploration of Multi-Dimensional Data. Applied Sciences. 2022; 12(22):11386. https://doi.org/10.3390/app122211386
Chicago/Turabian StyleLi, Jie, Huailian Tan, and Wentao Huang. 2022. "Active Pattern Classification for Automatic Visual Exploration of Multi-Dimensional Data" Applied Sciences 12, no. 22: 11386. https://doi.org/10.3390/app122211386
APA StyleLi, J., Tan, H., & Huang, W. (2022). Active Pattern Classification for Automatic Visual Exploration of Multi-Dimensional Data. Applied Sciences, 12(22), 11386. https://doi.org/10.3390/app122211386