
A Seismic Phase Recognition Algorithm Based on Time Convolution Networks



Abstract
:1. Introduction
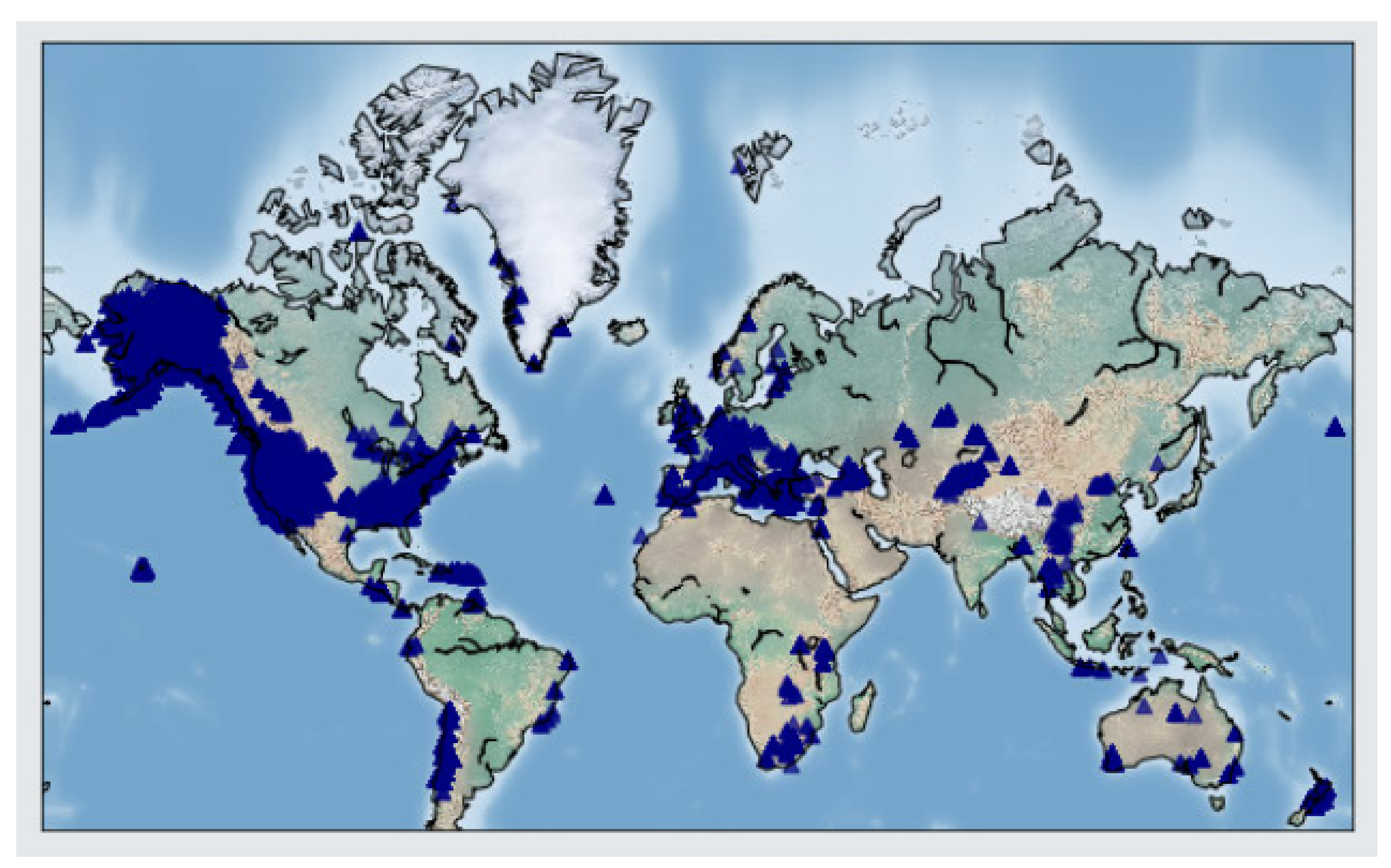
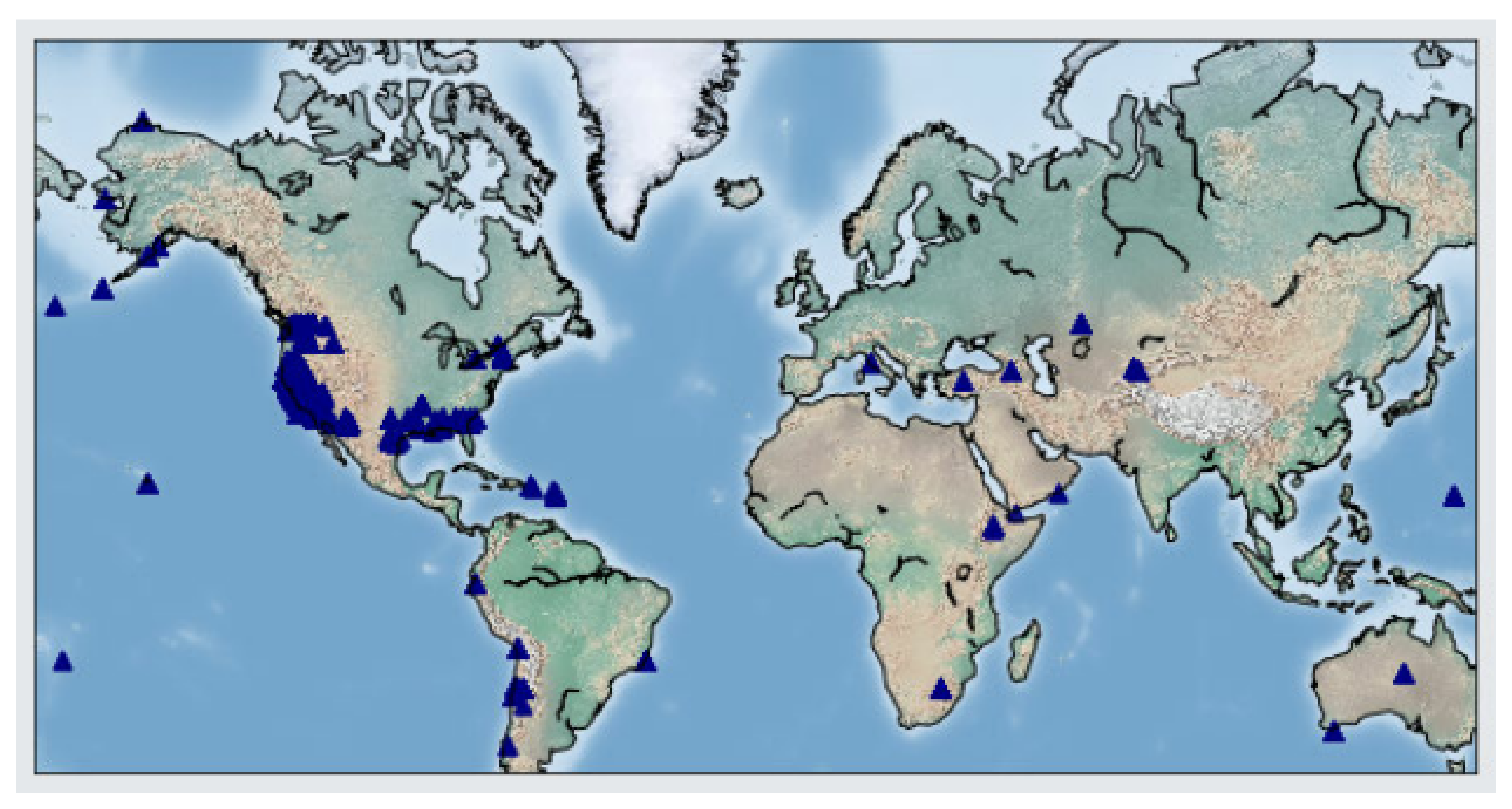
2. Data
2.1. Dataset
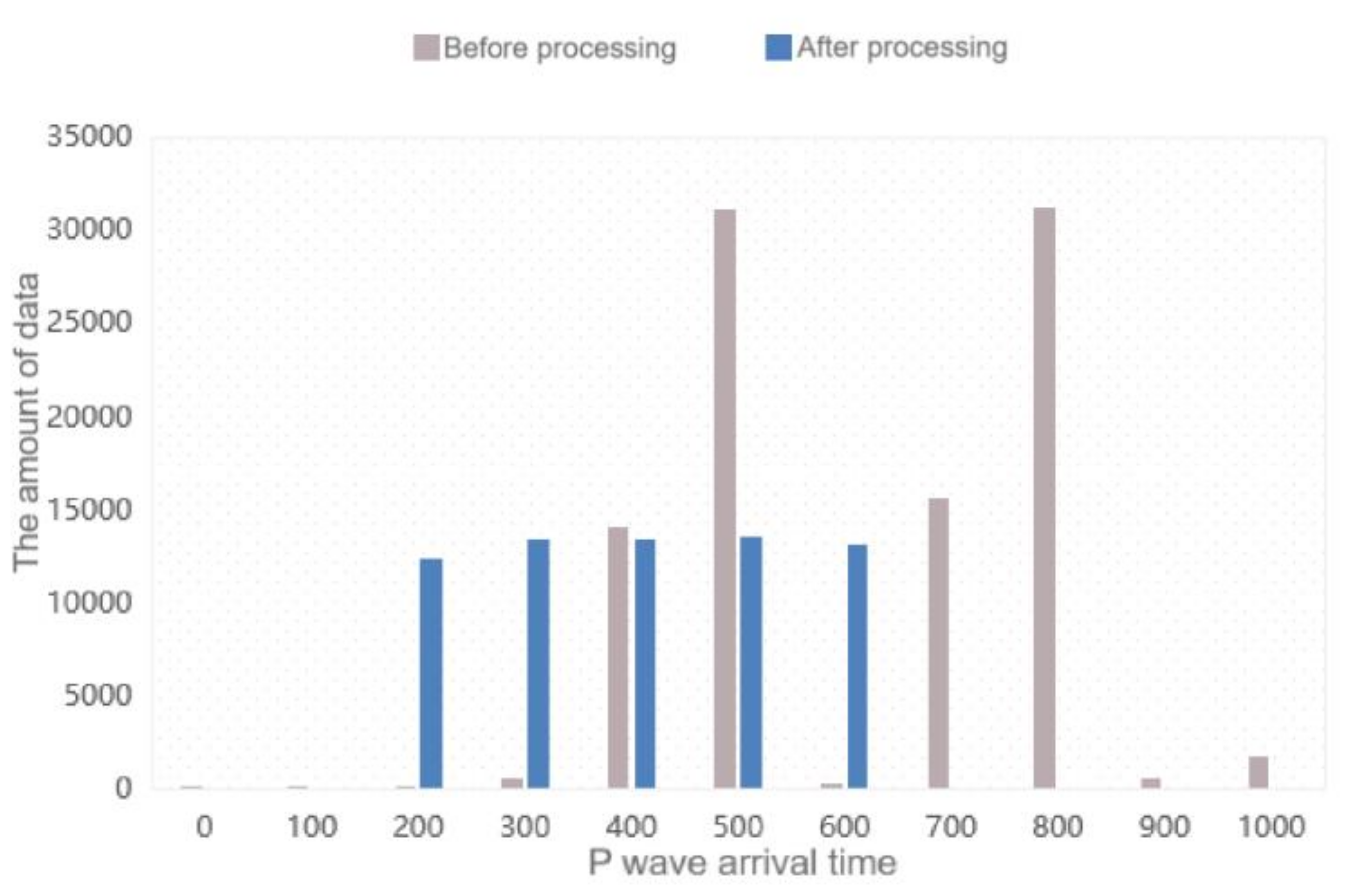
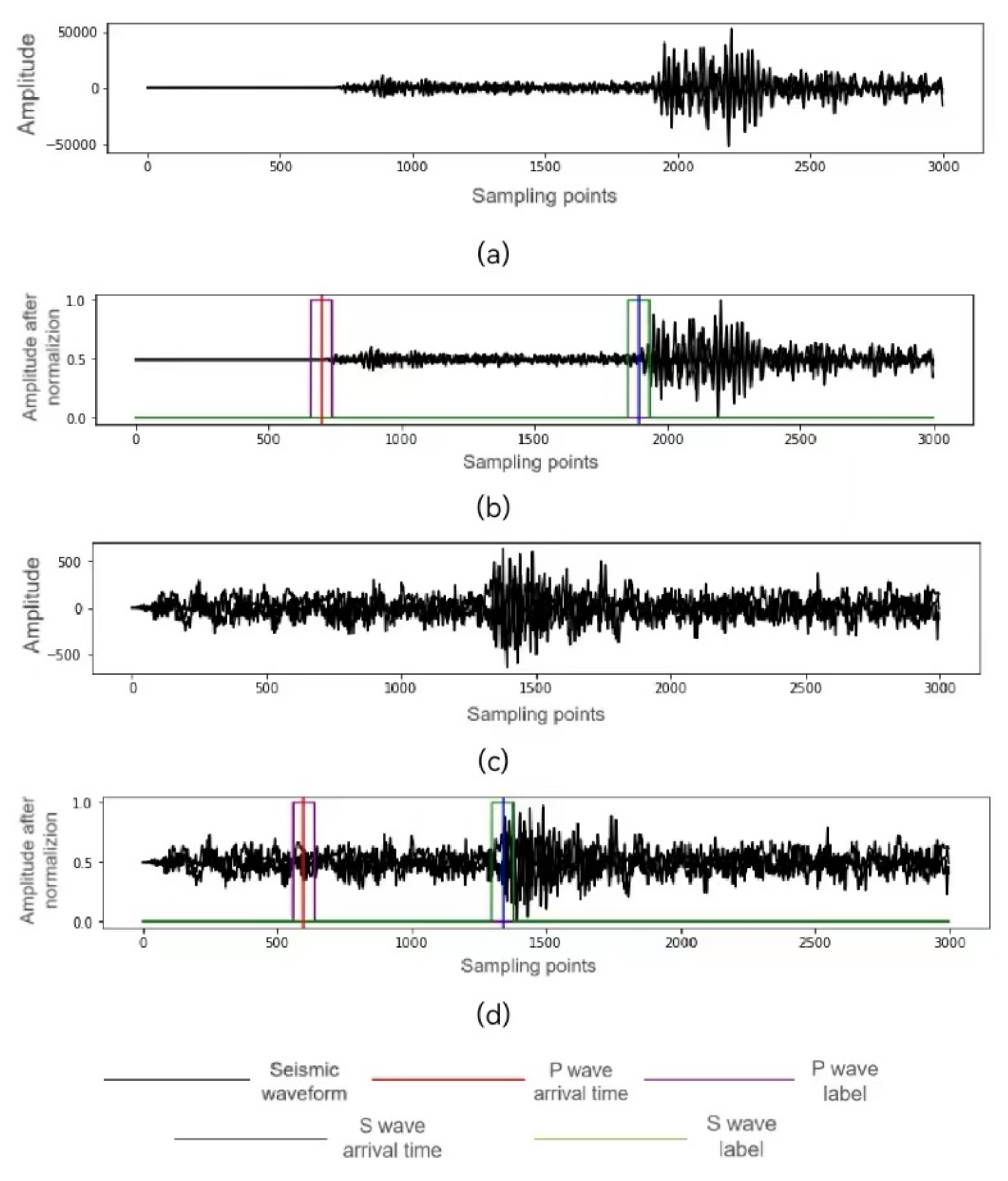
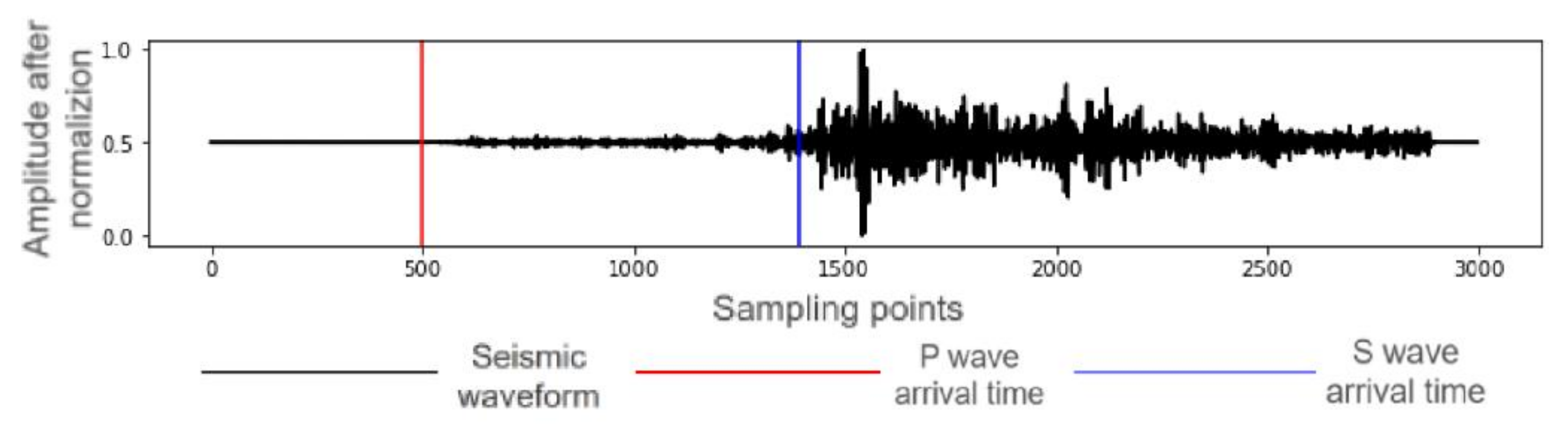
2.2. Data Preprocessing
3. Neural Network Structure
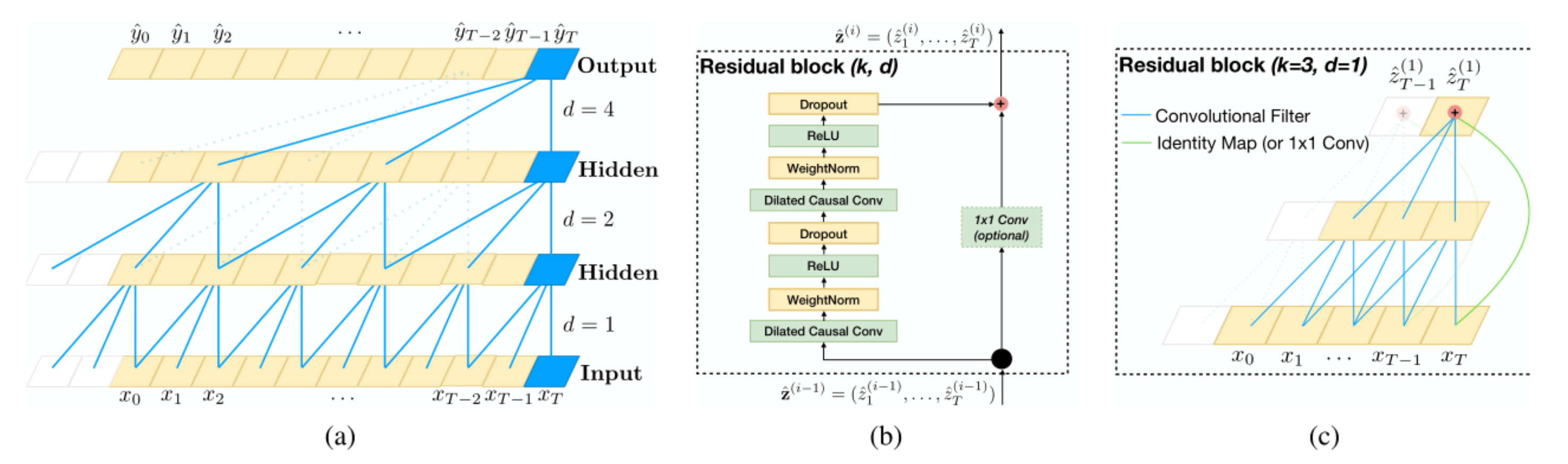
3.1. Temporal Convolutional Network
3.2. Improved S-TCN Structure Based on TCNs

4. Experiments
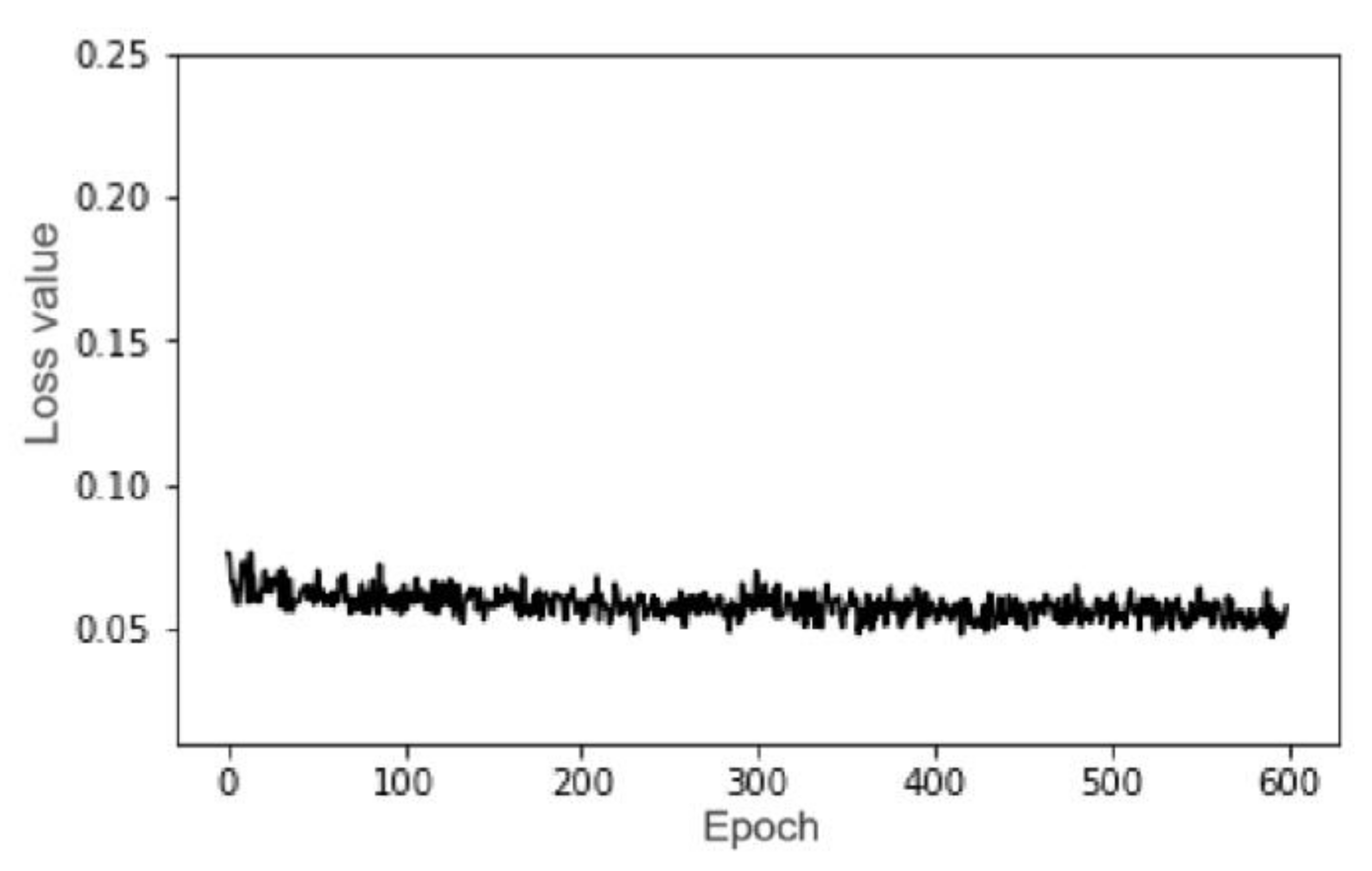
4.1. Training Process
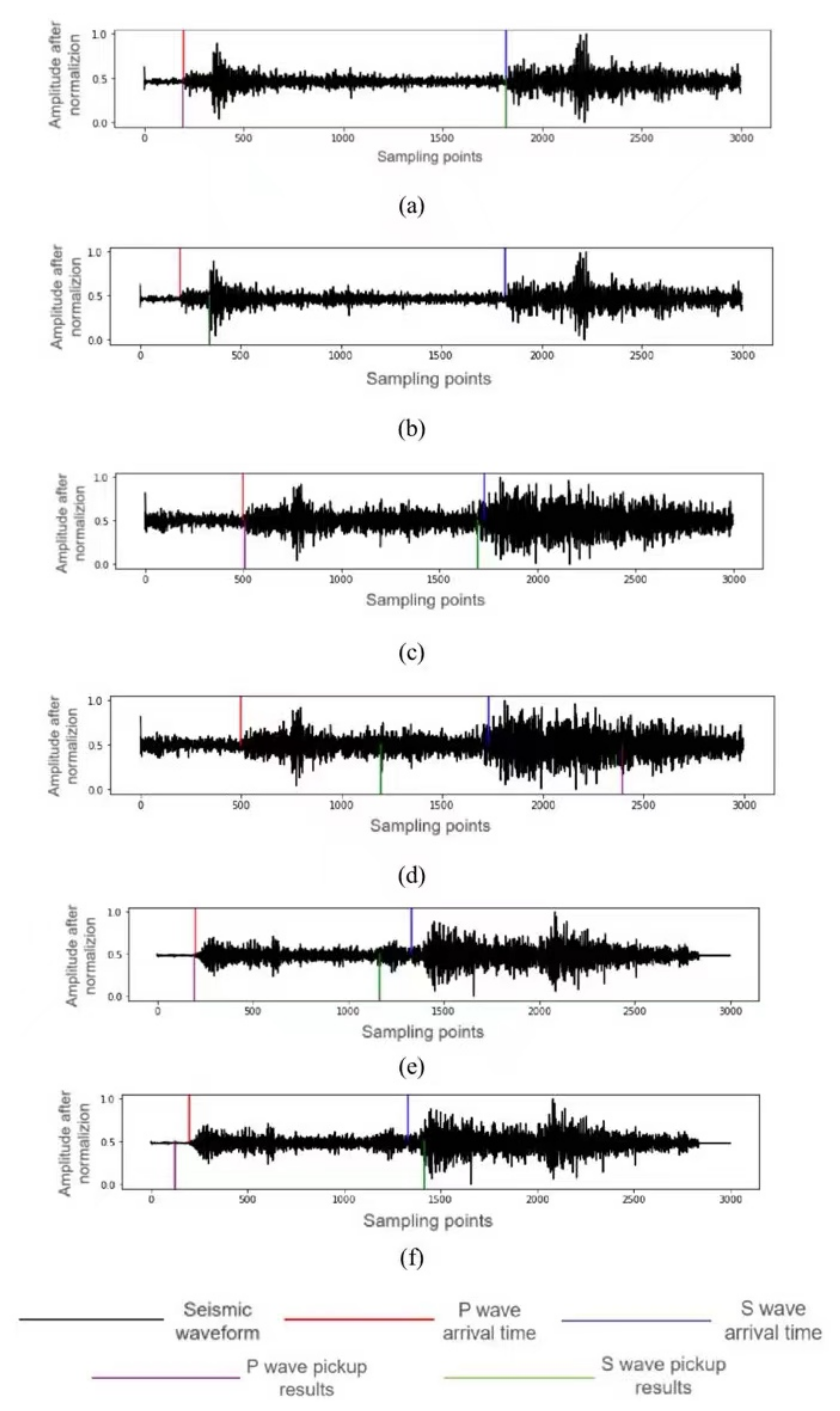
4.2. Evaluation Standards
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, Z.Y.; Chu, R.S.; Sheng, M.H. Pick onset time of P and S phase by deep neural network. Chin. J. Geophys. 2018, 61, 4873–4886. [Google Scholar]
- Ross, Z.E.; Meier, M.A.; Hauksson, E.; Heaton, T.H. Generalized Seismic Phase Detection with Deep Learning. Bull. Seismol. Soc. Am. 2018, 108, 2894–2901. [Google Scholar] [CrossRef]
- Zhu, W.; Beroza, G.C. PhaseNet: A deep-neural-network-based seismic arrival-time picking method. Geophys. J. Int. 2019, 216, 261–273. [Google Scholar] [CrossRef]
- Zhao, M.; Chen, S.; Fang, L.; Yuen, D.A. Earthquake phase arrival auto-picking based on U-shaped convolutional neural network. Chin. J. Geophys. 2019, 62, 3034–3042. [Google Scholar]
- Zhou, Y.; Yue, H.; Kong, Q.; Zhou, S. Hybrid Event Detection and Phase cc icking Algorithm Using Convolutional and Recurrent Neural Networks. Seismol. Res. Lett. 2019, 90, 1079–1087. [Google Scholar] [CrossRef]
- Liu, F.; Jiang, Y.; Ning, J.; Zhang, J.; Zhao, Y. An array-assisted deep learning approach to seismic phase-picking. Chin. Sci. Bull. 2020, 65, 1016–1026. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Zhang, Y.; Wang, W.; Shang, J.; Gai, L. Research on the seismic phase picking method based on the deep convolution neural network. Geophys. J. 2020, 63, 1591–1606. [Google Scholar]
- Yu, Z.; Chu, R.; Wang, W.; Sheng, M. CRPN: A cascaded classification and regression DNN framework for seismic phase picking. Earthq. Sci. 2020, 33, 53–61. [Google Scholar] [CrossRef]
- Guo, H.; Chang, L.; Lu, L.; Wu, P.; Lu, M.; Ding, Z. High-resolution earthquake catalog for the focal area of the Qinghai Madoi MS7.4 earthquake based on deep-learning phase picker and dense array. Geophys. J. 2022, 65, 1628–1643. [Google Scholar]
- Liao, S.; Zhang, H.; Fan, L.; Li, B.; Huang, L.; Fang, L.; Qin, M. Development of a real-time intelligent seismic processing system and its application in the 2021 Yunnan Yangbi MS6.4 earthquake. Geophys. J. 2021, 64, 3632–3645. [Google Scholar]
- Van Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Bai, S.; Kolter, J.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Dieleman, S.; Oord, A.V.; Simonyan, K. The challenge of realistic music generation: Modelling raw audio at scal. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 8000–8010. [Google Scholar]
- Yan, J.; Mu, L.; Wang, L.; Ranjan, R.; Zomaya, A.Y. Temporal convolutional networks for the Advance prediction of ENSO. Sci. Rep. 2020, 10, 1–15. [Google Scholar] [CrossRef]
- Guirguis, K.; Schorn, C.; Guntoro, A.; Abdulatif, S.; Yang, B. SELD-TCN: Sound Event Localization & Detection via Temporal Convolutional Networks. arXiv 2020, arXiv:2003.01609. [Google Scholar]
- Dario, R.; Pons, J.; Serra, X. A wavelet for speech denoising. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Mousavi, S.M.; Sheng, Y.; Zhu, W.; Beroza, G.C. Stanford EArthquake Dataset (STEAD): A Global Data Set of Seismic Signals for AI. IEEE Access 2019, 7, 179464–179476. [Google Scholar] [CrossRef]
- Lin, H.; Xing, L.; Liu, H.; Li, Q.; Zhang, H. Ground roll suppression with synchrosqueezing wavelet transform in time-spatial domain. Chin. J. Geophys. 2022, 65, 3569–3583. (In Chinese) [Google Scholar]
- Han, S.; Lv, M.; Cheng, Z. Dual-color blind image watermarking algorithm using the graph-based transform in the stationary wavelet transform domain. Optik 2022, 268, 169832. [Google Scholar] [CrossRef]
- Liang, P.; Wang, W.; Yuan, X.; Liu, S.; Zhang, L.; Cheng, Y. Intelligent fault diagnosis of rolling bearing based on wavelet transform and improved ResNet under noisy labels and environment. Eng. Appl. Artif. Intell. 2022, 115, 105269. [Google Scholar] [CrossRef]
- Wei, A.; Chen, Y.; Li, D.; Zhang, X.; Wu, T.; Li, H. Prediction of groundwater level using the hybrid model combining wavelet transform and machine learning algorithms. Earth Sci. Inform. 2022, 15, 1951–1962. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P Wave Detection | S Wave Detection | ||||
|---|---|---|---|---|---|---|
| Average Error | Error within 0.2 s | Error within 0.5 s | Average Error | Error within 0.2 s | Error within 0.5 s | |
| TCN | 1.25 s | 75% | 81.90% | 4.01 s | 17.30% | 29.80% |
| SELD-TCN-1 | 0.29 s | 57.50% | 96.20% | 0.84 s | 46.10% | 79.20% |
| SELD-TCN-2 | 0.34 s | 74.40% | 94.60% | 0.91 s | 50.30% | 76.9% |
| Model | Dataset | P Wave Detection | S Wave Detection | ||||
|---|---|---|---|---|---|---|---|
| Average Error | Error within 0.2 s | Error within 0.5 s | Average Error | Error within 0.2 s | Error within 0.5 s | ||
| TCN | Training | 2.257 s | 56.94% | 64.95% | 6.029 s | 6.75% | 13.26% |
| Testing | 1.844 s | 63.13% | 72.07% | 5.699 s | 5.03% | 12.85% | |
| S-TCN | Training | 0.266 s | 70.01% | 86.01% | 1.089 s | 49.08% | 76.25% |
| Testing | 0.204s | 69.27% | 97.76% | 1.866 s | 50.84% | 74.86% | |
| AR-AIC | Testing | 1.269 s | 60.39% | 73.82% | 1.498 s | 56.61% | 68.49% |
| Error within 0.1 s | Error within 0.2 s | Error within 0.3 s | Error within 0.4 s | Error within 0.5 s | Average Error | |
|---|---|---|---|---|---|---|
| P Wave Detection | 5847 | 5900 | 5928 | 5946 | 5956 | 0.08824 |
| S Wave Detection | 5611 | 5731 | 5818 | 5868 | 5910 | 0.09821 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Z.; Li, Y.; Guo, K.; Li, G.; Zheng, W.; Liu, H. A Seismic Phase Recognition Algorithm Based on Time Convolution Networks. Appl. Sci. 2022, 12, 9547. https://doi.org/10.3390/app12199547
Han Z, Li Y, Guo K, Li G, Zheng W, Liu H. A Seismic Phase Recognition Algorithm Based on Time Convolution Networks. Applied Sciences. 2022; 12(19):9547. https://doi.org/10.3390/app12199547
Chicago/Turabian StyleHan, Zhenhua, Yu Li, Kai Guo, Gang Li, Wen Zheng, and Hongfu Liu. 2022. "A Seismic Phase Recognition Algorithm Based on Time Convolution Networks" Applied Sciences 12, no. 19: 9547. https://doi.org/10.3390/app12199547
APA StyleHan, Z., Li, Y., Guo, K., Li, G., Zheng, W., & Liu, H. (2022). A Seismic Phase Recognition Algorithm Based on Time Convolution Networks. Applied Sciences, 12(19), 9547. https://doi.org/10.3390/app12199547