
Maximizing the Productivity of Photolithography Equipment by Machine Learning Based on Time Analytics


Abstract
:1. Introduction
2. Related Works
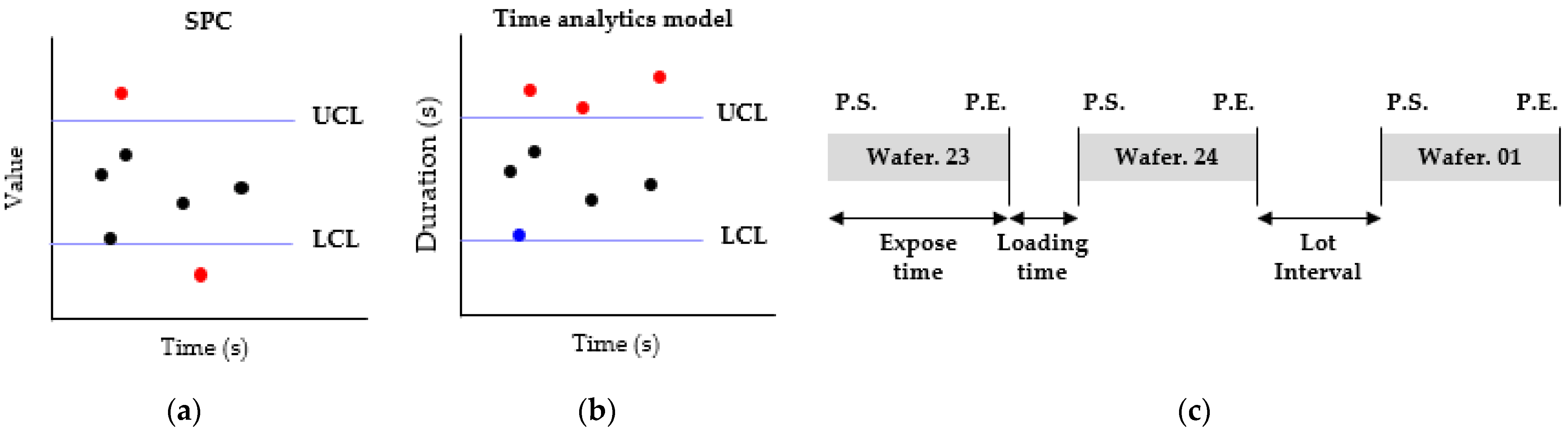
2.1. Statistical Process Control
2.2. Time Analysis of Two Equipment Makers
3. Time Analytics Model in Photolithography Equipment
3.1. Overview
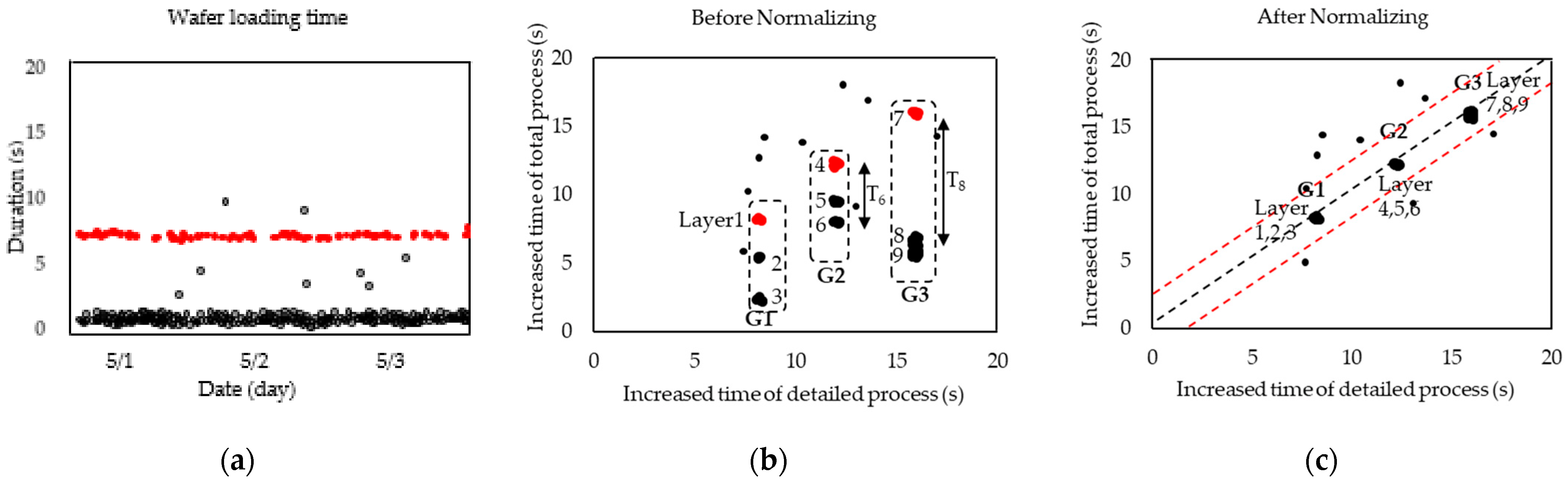
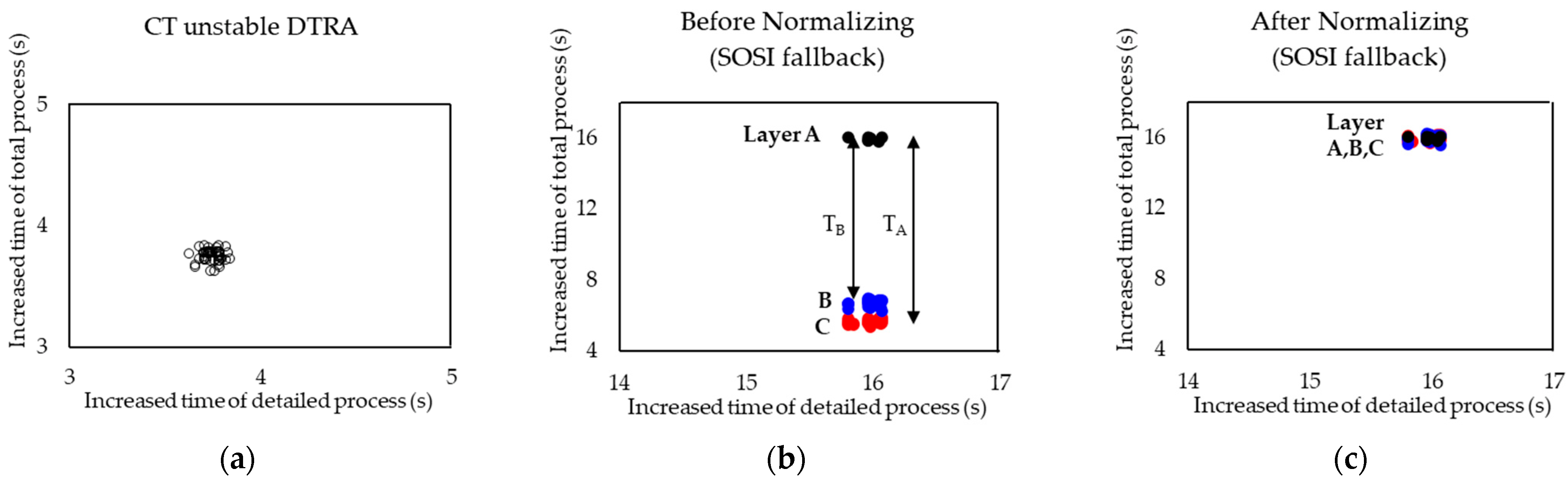
3.2. Typical and Atypical Time-Increased Wafers
3.3. Time Classification Based on Machine Learning
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nakajima, S. Introduction to TPM: Total Productive Maintenance (Translation); Productivity Press: Cambridge, UK, 1988; p. 129. [Google Scholar]
- Anvari, F.; Edwards, R. Performance measurement based on a total quality approach. Int. J. Product. Perform. Manag. 2011, 60, 512–528. [Google Scholar] [CrossRef]
- Braglia, M.; Castellano, D.; Frosolini, M.; Gallo, M. Overall material usage effectiveness (OME): A structured indicator to measure the effective material usage within manufacturing processes. Prod. Plan. Control 2018, 29, 143–157. [Google Scholar] [CrossRef]
- Jasiulewicz-Kaczmarek, M.; Piechowski, M. Practical aspects of OEE in automotive company—Case study. In Proceedings of the 2016 International Conference on Management Science and Management Innovation, Guilin, China, 13–14 August 2016; pp. 13–14. [Google Scholar]
- Muchiri, P.; Pintelon, L. Performance measurement using overall equipment effectiveness (OEE): Literature review and practical application discussion. Int. J. Prod. Res. 2008, 46, 3517–3535. [Google Scholar] [CrossRef] [Green Version]
- Cheah, C.K.; Prakash, J.; Ong, K.S. An integrated OEE framework for structured productivity improvement in a semiconductor manufacturing facility. Int. J. Product. Perform. Manag. 2020, 69, 1081–1105. [Google Scholar] [CrossRef]
- Prasetyo, Y.T.; Veroya, F.C. An Application of Overall Equipment Effectiveness (OEE) for Minimizing the Bottleneck Process in Semiconductor Industry. In Proceedings of the 2020 IEEE 7th International Conference on Industrial Engineering and Applications (ICIEA), Bangkok, Thailand, 16–21 April 2020; pp. 345–349. [Google Scholar]
- Dal, B.; Tugwell, P.; Greatbanks, R. Overall equipment effectiveness as a measure of operational improvement—A practical analysis. Int. J. Oper. Prod. Manag. 2000, 20, 1488–1502. [Google Scholar] [CrossRef]
- Nakazawa, T.; Kulkarni, D.V. Wafer map defect pattern classification and image retrieval using convolutional neural network. IEEE Trans. Semicond. Manuf. 2018, 31, 309–314. [Google Scholar] [CrossRef]
- Kim, D.; Kang, P.; Cho, S.; Lee, H.J.; Doh, S. Machine learning-based novelty detection for faulty wafer detection in semiconductor manufacturing. Expert Syst. Appl. 2012, 39, 4075–4083. [Google Scholar] [CrossRef]
- Byun, Y.; Baek, J.G. Pattern Classification for Small-Sized Defects Using Multi-Head CNN in Semiconductor Manufacturing. Int. J. Precis. Eng. Manuf. 2021, 22, 1681–1691. [Google Scholar] [CrossRef]
- Kang, P.S.; Kim, D.I.; Lee, S.K.; Doh, S.Y.; Cho, S.Z. Estimating the reliability of virtual metrology predictions in semiconductor manufacturing: A novelty detection-based approach. J. Korean Inst. Ind. Eng. 2012, 38, 46–56. [Google Scholar]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Wu, H. A clustering method based on K-means algorithm. Phys. Procedia 2012, 25, 1104–1109. [Google Scholar] [CrossRef] [Green Version]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Ran, X.; Zhou, X.; Lei, M.; Tepsan, W.; Deng, W. A novel k-means clustering algorithm with a noise algorithm for capturing urban hotspots. Appl. Sci. 2021, 11, 11202. [Google Scholar] [CrossRef]
- Oakland, J.S. Statistical Process Control; Routledge: London, UK, 2007. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar]
- Fatourechi, M.; Ward, R.K.; Mason, S.G.; Huggins, J.; Schlögl, A.; Birch, G.E. Comparison of evaluation metrics in classification applications with imbalanced datasets. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 777–782. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual | |||
|---|---|---|---|
| True | False | ||
| Predict | True | TP | FP |
| False | FN | TN | |
| Wafers | TP | FP | FN | TN | Precision (%) | Recall (%) | Accuracy (%) | |
|---|---|---|---|---|---|---|---|---|
| Fold 1 | 5120 | 452 | 22 | 11 | 4635 | 95.36 | 97.62 | 99.36 |
| Fold 2 | 5034 | 320 | 18 | 9 | 4687 | 94.67 | 97.26 | 99.46 |
| Fold 3 | 4825 | 351 | 12 | 8 | 4454 | 96.69 | 97.77 | 99.59 |
| Fold 4 | 5244 | 414 | 42 | 10 | 4778 | 90.79 | 97.64 | 99.01 |
| Fold 5 | 4151 | 337 | 16 | 13 | 3785 | 95.47 | 96.29 | 99.30 |
| Equipment. 1 | Equipment. 2 | Equipment. 3 | Equipment. 4 | Equipment. 5 | Equipment. 6 | |
|---|---|---|---|---|---|---|
| Time-increased wafer (%) | 23.50 | 9.94 | 8.30 | 17.45 | 7.85 | 7.39 |
| Cause classification ratio (%) | 98.65 | 97.89 | 98.16 | 98.72 | 99.32 | 99.07 |
| Time classification ratio (%) | 1.35 | 2.11 | 1.84 | 1.28 | 0.68 | 0.93 |
| Equipment. 1 | Equipment. 2 | Equipment. 3 | Equipment. 4 | Equipment. 5 | Equipment. 6 | |
|---|---|---|---|---|---|---|
| Cause 1 | 3738 | 445 | 0 | 0 | 1 | 68 |
| Cause 2 | 42 | 21 | 307 | 67 | 95 | 113 |
| Cause 3 | 2029 | 1475 | 652 | 435 | 1113 | 824 |
| Cause 4 | 53 | 20 | 87 | 477 | 18 | 20 |
| Cause 5 | 771 | 1354 | 817 | 2744 | 785 | 756 |
| Cause 6 | 7853 | 1697 | 150 | 3433 | 2 | 0 |
| Cause 7 | 4989 | 6925 | 6507 | 6238 | 7856 | 7891 |
| Cause 8 | 94 | 384 | 9 | 13 | 2546 | 2 |
| Cause 9 | 116 | 117 | 123 | 633 | 77 | 35 |
| Cause 10 | 245 | 79 | 2297 | 3878 | 43 | 231 |
| Cause 11 | 184 | 743 | 24 | 3902 | 6 | 2175 |
| Cause 12 | 0 | 13 | 1 | 0 | 0 | 1 |
| Unclassified | 276 | 286 | 206 | 282 | 86 | 114 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, J.; Hong, J.-H.; Suk, J.; Park, H.; Choi, B. Maximizing the Productivity of Photolithography Equipment by Machine Learning Based on Time Analytics. Appl. Sci. 2022, 12, 8003. https://doi.org/10.3390/app12168003
Jung J, Hong J-H, Suk J, Park H, Choi B. Maximizing the Productivity of Photolithography Equipment by Machine Learning Based on Time Analytics. Applied Sciences. 2022; 12(16):8003. https://doi.org/10.3390/app12168003
Chicago/Turabian StyleJung, Juyoung, Jin-Hwan Hong, Jeewoong Suk, Hyunsoon Park, and Byoungdeog Choi. 2022. "Maximizing the Productivity of Photolithography Equipment by Machine Learning Based on Time Analytics" Applied Sciences 12, no. 16: 8003. https://doi.org/10.3390/app12168003
APA StyleJung, J., Hong, J.-H., Suk, J., Park, H., & Choi, B. (2022). Maximizing the Productivity of Photolithography Equipment by Machine Learning Based on Time Analytics. Applied Sciences, 12(16), 8003. https://doi.org/10.3390/app12168003