Abstract
In this paper, we propose a centralized task allocation and an alignment technique based on constraint table and alignment rules. For task allocation, a scoring scheme has to be set. The existing time-discounted scoring scheme has two problems; if the score is calculated based on arrival time, the agent who arrives in a task point first may finish the task late, and if the score is calculated based on end-time of the task, agents who have the same score may appear because of temporal constraints. Therefore, a modified time-discounted reward scheme based on both arrival and end-time is proposed. Additionally, an accumulated distance cost scheme is proposed for minimum fuel consumption. The constraint table made by tasks that are already aligned is also considered in scoring. For centralized task alignment based on the constraint table and alignment rules, a technique based on sequential greedy algorithm is proposed. Resolving conflicts on alignment is described in detail using constraint table and alignment rules, which are composed of four basic principles. We demonstrate simulations about task allocation and alignment for multi-agent with coupled constraints. Simple and complicated cases are used to verify the scoring schemes and the proposed techniques. Additionally, a huge case is used to show computational efficiency. The results are feasibly good when the constraints are properly set.
1. Introduction
Automation techniques of systems are among some highly interesting research themes currently. According to this trend, concepts of swarming with a lot of the Unmanned Vehicles (UxVs) or teaming with manned and unmanned vehicles occur to overcome hard tasks with manned or single vehicle using the UxVs. To coordinate several tasks with the UxVs as described above, the sequence of tasks for each UxV has to be issued to them based on their situations and capabilities. In addition, the purpose of task allocation, for example minimizing total mission time, minimizing fuel consumption, etc., and spatial or temporal constraints have to be considered for successful task allocation and alignment. Hence, management techniques for multi-agent systems have been widely studied with various approaches and algorithms [1,2,3,4,5,6,7,8,9,10,11]. One of them is developed to recommend tasks to MOD drivers by analyzing and modeling the Mobility-on-Demand Vehicular Crowdsensing (MOD-CS) and MOD-Human-Crowdsensing (MOMAN-CS) market [10]. It is for manned vehicles, so they have freedom to refuse the recommendation. Another is developed for an urban delivery drone system considering energy consumption [11]. Previous research supposed that the energy consumption of robots, especially drones, is proportional to their moving distance but it did not match for delivery drone. Therefore, the weight of the drone including the consignment is also considered when calculating energy consumption.
One of the general task allocation algorithms is Consensus-Based Bundle Algorithm (CBBA), which is based on the auction process [12]. Several agents calculate the task rewards or costs which differ by the purpose, and the task is allocated to the agent that has the highest reward in CBBA. To calculate task rewards, the time-discounted reward scheme, one of the general scoring themes in score-based task allocation algorithm, is used in CBBA. This scheme calculates scores as decreasing time-invariant maximum rewards as time passes. This algorithm is fast to obtain the local optimum solution but CBBA cannot consider the constraints as depicted above. Therefore, Coupled-constraint CBBA (CCBBA), further improved CBBA, is developed [13,14]. In CCBBA, some spatial and temporal constraints can be considered in the task allocation and alignment. Each agent decides the bidding strategy for each task before bidding. According to the decided strategy, task rewards for each agent are calculated for task allocation. For task alignment, ‘number of iterations in constraint violation’, and some counts are considered. In the optimistic strategy, if the agent violates some constraints when performing a task, the number of iterations in constraint violation increases but the task can be aligned to the agent if it is lower than some thresholds. CCBBA has the ability to handle most multi-agent management problems, but there is a problem concerning the convergence of solution in certain scenarios. Additionally, there is a minor problem in setting temporal constraints; the user must set the maximum permitted time for each task unless they cannot predict it exactly.
CBBA and CCBBA are fast task allocation and alignment algorithms, but computational cost rapidly increases as the number of agents and tasks increases. The reason in CBBA is in the bundle construction phase. When creating a bundle for each agent, the score is calculated not only after the last task of the agent but also before and after all allocated tasks of the agent. For example, an agent has been allocated tasks 1 and 2, and there is an unallocated task 3. Then, scores about sequence of tasks (3-1-2), (1-3-2), and (1-2-3) are calculated to allocate the task 3. Note that task allocation and alignment with coupled constraints are NP-hard problems, and the solution of CBBA is just the local optimum solution. It is a time-consuming process to obtain this kind of solution. The reason in CCBBA is the process about whether an agent can bid to tasks or not. First, the groups of tasks are made based on coupled constraints, called activities. Dependency matrices and temporal constraint matrices are made for each activity to obtain a solution applying constraints. Then, each agent decides optimistic or pessimistic strategies for bidding on each task. For bidding, each agent counts violation iterations, number of bidding alone to task, and number of bidding of any task. This process is also time-consuming.
There is another way to allocate and align tasks from a different point of view, game theory [15]. In this method, the individual agent has freedom for its actions and the agent decides its action by sampling from its possible action set stochastically. When the agent violates the constraints for collective action, penalties that are larger than other rewards are given to it. These penalties are added to the score according to time-discounted reward scheme, so each agent is constrained to obey the constraints. This method solved a minor problem of CCBBA as setting the temporal constraints by just the relationship, such as ‘before’ or ‘after’ etc., so there is no need to set permitted time, such as ‘do in 30 min after task 1’. While CBBA and CCBBA did not permit the task to be allocated to multi-agents, task allocation based on game theory permits collective actions for one task. In this case, duration time of the task decreases because several agents work together. However, this method results in acceptable and stable solutions only when the probability distributions of actions in action set for each agent are set based on large experiments. It means that a lot of experiments for several cases are needed to obtain the suitable probability distributions. Additionally, computation time is reduced compared to CCBBA, but it is still slow so the update interval of task allocation and alignment results is long. According to the results in [15], 18.086 s (mean time) to obtain reasonable central task allocation solution with six agents and 27 tasks.
In this paper, we consider an algorithm for coupled-constraint task allocation and alignment problems using a constraint table and alignment rules. This is based on CBBA and CCBBA, but a new method is proposed alternating some time-consuming procedures, so local optimum solutions are obtained fast enough. For the task allocation, two scoring schemes are proposed; modified time-discounted scoring scheme and accumulated distance scoring scheme. Additionally, a spatial constraint in CCBBA is considered, called MUTually EXclusive (MUTEX). In addition, a new spatial constraint, called local MUTEX, is considered for essential cases; cooperative work, and etc. For classification, MUTEX in CCBBA is called global MUTEX. Unilateral dependency in CCBBA is considered by temporal constraints instead. For the task alignment, some temporal constraints in CCBBA are considered afterwards, called simultaneous. Temporal constraints ‘before’ and ‘between’ are replaced to ‘after’. Additionally, constraints ‘during’ is separated to two constraints; ‘start during’ and ‘end during’. Constraint ‘not during’ in CCBBA is not used. These temporal constraints are considered using the constraint table which is made when alignment of a task is completed. To apply these constraints and scoring schemes to the task allocation and alignment, the algorithm called centralized Task Allocation and alignment based on Constraint Table and Alignment Rules (TACTAR) is proposed.
2. Preliminaries
2.1. Task Allocation and Alignment Problems
The task allocation problem is to find matching of tasks to agents that maximizes global reward as below [12,16]:
subject to
where is number of agents, is number of tasks, and is maximum number of tasks each agent can be allocated. is the flag that is 1 if task j is allocated to agent i and is 0 otherwise, is the flag vector whose jth element is , and is the ordered sequence of tasks for agent . is the lowest number between and . is scoring function and means reward of task j if agent i completes tasks along based on . I and J are agent group and task group, respectively, so number of elements for I and J are and , respectively. As in Equation (2), one task is allocated to only one agent.
The task alignment problem is to calculate the arrival time, start-time, and end-time of each task satisfying temporal constraints and allocated sequence of tasks for each agent. If the temporal constraints have logical error, for example a task1 has to be started after finishing task2, and task2 has to be started after finishing task1, the task alignment result cannot be calculated. To prevent this, we assume that temporal constraints have no logical error so there must be at least one task alignment solution satisfying temporal constraints.
2.2. Consensus-Based Bundle Algorithm (CBBA)
CBBA is a multi-agent task allocation algorithm based on auction concept. CBBA is organized into two phases, bundle construction phase and consensus phase. In bundle construction phase, each agent makes its own ordered sequence of tasks and bundle by calculating the rewards of each task. The rewards are obtained by arriving or completing tasks so the sequence of tasks for each agent is changed according to reward function to obtain maximum global reward. Algorithm of the bundle construction phase is as below [12,17]:
In lines 1~4 of Algorithm 1, vectors about agent i for bundle construction are initialized to previous iteration results, where t is number of iteration, is winning bids list that the agent i knows, is winning agent list that the agent i knows, is bundle of the agent i, and is sequence of tasks for agent i. Then, the bundle and the sequence of tasks are constructed until the size of the bundle is same with in lines 5~14 of Algorithm 1. In line 6 of Algorithm 1, it founds agent i’s maximum reward when a task is added to a previous sequence of tasks of agent i, where is reward of agent i along and means that task j is added after nth component of . The rewards are then multiplied to the flag whether the reward is higher than winning bid or not. Finally, the task and the sequence that maximize the agent i’s reward are found in lines 8~9 of Algorithm 1 and the task is added to iteration results in lines 10~13 of Algorithm 1.
| Algorithm 1 CBBA Phase 1: Bundle construction |
| 1: 2: 3: 4: 5: while , do 6: 7: 8: 9: 10: 11: 12: 13: 14: end while |
In the consensus phase, agents confirm tasks to perform based on the bundles made in the bundle construction phase. In the decentralized system, the agents have to communicate data with each other for deciding the winning agent. However, in a centralized system, the agents send data only to the central computer. In the central computer, the data from the agents are collected and the consensus algorithm is processed with the data. The general centralized consensus algorithm is Sequential Greedy Algorithm (SGA) as shown in Algorithm 2 [12]. In lines 1~3 of Algorithm 2, variables for SGA are initialized, where I and J are groups of agents and tasks, respectively, is number of confirmed tasks for agent i, and is a reward that is obtained by finishing task j by agent i based on the bundle of agent i, . Superscript means the number of iterations. In lines 4~18 of Algorithm 2, agent and task , which are row and column of maximum value of , respectively, are found, and the agent is confirmed to do the task . For the next iteration, the task is excluded from the group of tasks J because of the assumption ‘one task is allocated to only one agent’ in Equation (2). If the number of confirmed tasks for the agent is equal to the limit number of task , the agent is also excluded from the group of agents I. This procedure is repeated for times to allocate all tasks to the agents.
| Algorithm 2 Sequential greedy algorithm |
| 1: 2: 3: 4: for to do 5: 6: 7: 8: 9: 10: if then 11: 12: 13: else 14: 15: end if 16: 17: 18: end for |
2.3. Coupled-Constraint Consensus-Based Bundle Algorithm (CCBBA)
CCBBA is an extension version of CBBA. CCBBA is designed to supplement the weakness of CBBA which is incapacity to resolve task allocation and alignment problems with coupled constraints. The coupled constraints which are considered in CCBBA are described in Table 1 and Table 2 [13,14,15].

Table 1.
Spatial coupled constraints in CCBBA.
Table 2.
Temporal coupled constraints in CCBBA.
For applying these coupled constraints to CCBBA, tasks are partitioned into subgroups called activity that share coupled constraints. The activity does not share constraints with other activities. For each activity, two matrices called dependency matrix and temporal constraint matrix, which are defined as shown in Table 3 and Table 4, are used [13,14,15]. Using these matrices, each agent decides bidding strategies, optimistic and pessimistic, for each task before bundle construction. The agent decides to bid or not according to these strategies in bundle construction and consensus phase. In this process, the concept of ‘number of iterations in constraint violation’ is applied. These are additional processes compared to CBBA. Although CCBBA can resolve most coupled constraint task allocation and alignment cases, there are some problems in CCBBA. First of all, it faces convergence problems in some cases due to latency. Additionally, the user must set maximum amount of time to the temporal constraint matrix. It means that the user should calculate the time for task alignment in a defined order. However, expected arrival time, start-time, and end-time of tasks are changed frequently based on multi-agent operation environment, so the user finds it hard to expect the maximum amount of time.
Table 3.
Entry codes for dependency matrix in CCBBA.
Table 4.
Entry for temporal constraint matrix in CCBBA.
3. Scoring Scheme
A method that is similar to the bundle construction phase of CBBA is used in centralized TACTAR for task allocation. As we can see in Algorithm 1, rewarding function has to decide on making . In this paper, two scoring schemes are used: modified time-discounted reward and accumulated distance cost.
3.1. Modified Time-Discounted Reward
The basic time-discounted reward function calculates the reward of agent i as the maximum reward of each task decreases over time as below [12,17]:
where is time-invariant maximum reward of task j, is decreasing ratio, and is arrival time of task j for agent i along the sequence of task . If the reward can be obtained when the agent finishes the task, can be substituted to the end-time of task j. This method can be used in various ways. For example, if the importance of each task is different, a reasonable sequence of tasks can be made by setting to the importance level of task j. Additionally, it can be used in food delivery problems if is the same for all tasks and is different for each task. In that case, delivering the food to appropriate places would be tasks, and differs by the kind of food. If the reward of task is considered as safety level, it can be used in finding the safest sequence of tasks for agent i.
However, this rewarding scheme needs to be fixed because of two cases: one is that an agent is confirmed to perform a task because they arrive at the task point early, but finishes the task later than other agents; the other is that the agent cannot be confirmed to perform a task based on the rewards when several agents finish the task simultaneously. The second case occurs usually because of temporal constraints. Therefore, a modified time-discounted rewarding scheme has to be applied in TACTAR.
where and are weights for arrival and end rewards, respectively, and and are arrival time and end-time of task j for agent i based on sequence of tasks .
3.2. Accumulated Distance Cost
This cost function is used for finding the sequence of tasks for agents that minimizes total distance. To apply this cost function, bundle construction phase of CBBA should be changed as in Algorithm 3.
| Algorithm 3 CBBA Phase 1: Bundle construction for Accumulated Distance Cost |
| 1: 2: 3: 4: 5: while , do 6: 7: 8: 9: 10: 11: 12: 13: end while |
In line 6 of Algorithm 3, is total accumulated distance and is distance between agent i and point of task in . Note that the inequality sign and argument of the maxima in lines 7~8 of Algorithm 3 are changed for finding the sequence of tasks that minimizes total accumulated distance. To allocate tasks to agents, sequential greedy algorithm in Algorithm 2 also should be changed as described in Algorithm 4.
| Algorithm 4 Sequential greedy algorithm for Accumulated Distance Cost |
| 1: 2: 3: 4: for to do 5: 6: 7: 8: 9: 10: if then 11: 12: 13: else 14: 15: end if 16: 17: 18: end for |
In line 5 of Algorithm 4, argument of maxima is changed to argument of minimum as line 8 of Algorithm 3. Note that should be replaced to when calculating the next iteration costs, in line 17 of Algorithm 4. Additionally, note that accumulated distance cost can be only applied to centralized task allocation. This method can be used in the situation; a minimum number of agents are used for completing all tasks with minimum fuel consumption.
4. Scheduling Scheme
After task allocation, task alignment should be processed to meet temporal constraints. Assume that every agent has a speed limit and moves to target task points as soon as possible. Additionally, the duration time of each task is not changed by scheduling, such as shrinking or stretching; it is changed only by agents. Then, four basic rules can be made as in Table 5. If the task B is aligned, temporal constraints about the task B are generated. These constraints have to be considered for the next alignment of tasks, the task A in Table 5. If the task B is dropped by rules in Table 5, these constraints cannot be considered any more. Therefore, a constraint table is used in centralized TACTAR to manage generated constraints by aligned tasks. This table has number-of-constraints rows and six columns that contain that shown in Table 6.
Table 5.
Basic rules for scheduling.
Table 6.
Contents of constraint table.
For example, task 2 must start after task 1 ends and task 2 is aligned to agent 3. Then, a row of the constraint table is created. Column 1 of row 1 would be 1 which means task 1. Columns 2 and 3 would be 3 and 2 which mean agent 3 and task 2, respectively. Note that columns 2 and 3 are needed for deleting constraints when tasks are dropped. Column 4 would be 1 which means end-time of task 1. Columns 5 and 6 would be start-time of tasks 2 and 0, respectively. The zero in column 6 means that task 1 should end before the time in column 5. If temporal constraints on task 2 are more than one, other rows of the constraint table will be made.
Following the rules in Table 5, one of the temporal constraints ‘Not During’ in Table 2 cannot be applied because it cannot decide which rule should be applied when violating the constraint. For example, if task A must either end before task B starts or start after task B ends but task A starts after task B starts and task A ends before task B ends, it corresponds to rule 2 and 4. In this situation, task A cannot be aligned without changing the duration time of task A. Additionally, the temporal constraint ‘Between’ in Table 2 can be separated to ‘Before’ and ‘After’, so ‘Between’ is no longer needed in temporal constraints. The temporal constraint ‘Before’ can be replaced to ‘After’. For example, ‘Task A must end before task B starts’ can be ‘Task B must start after task A ends’.
The spatial constraint ‘Mutual exclusive’ in Table 1 means that only either task A or B can be allocated to all agents at each time. For example, if task A is allocated to agent 1, task B cannot be allocated to all agents. However, it needs to allocate task B to agents except agent 1. Hence, the spatial constraint ‘Mutual exclusive’ should be separated to two constraints: global and local. Additionally, ‘Unilateral dependency’ in Table 1 is useless because tasks which have unilateral dependency relationship have at least one temporal constraint so checking only temporal constraints violation is enough. Therefore, spatial and temporal constraints in centralized TACTAR are as in Table 7 and Table 8.
Table 7.
Spatial coupled constraints in centralized TACTAR.
Table 8.
Temporal coupled constraints in centralized TACTAR.
For applying these coupled constraints to centralized TACTAR, two matrices are defined as in Table 9 and Table 10. Note that the components of temporal constraint matrix are just codes in Table 9, not maximum amount of time in Table 4.
Table 9.
Entry codes for dependency matrix in centralized TACTAR.
Table 10.
Entry for temporal constraint matrix in centralized TACTAR.
5. Algorithm
The algorithm of centralized TACTAR including scoring and scheduling schemes as described in Section 3 and Section 4, respectively, can be summarized as in Algorithm 5. In line 1 of Algorithm 5, variables for centralized TACTAR are set where is positions of agents, is task points, and and are spatial and temporal constraint matrix, respectively.
In line 2 of Algorithm 5, constants for centralized TACTAR are set where is duration time of tasks, is maximum velocity of each agent, is bidding flags whether each agent can bid to tasks or not, and is minimum overlapping time between working time of tasks in ‘start during’ or ‘end during’ relationship. is time-invariant maximum reward for each task, is decreasing ratio of it for each task as described in Equation (7), and are weight of arrival and end-reward (cost) for Equation (7), respectively.
| Algorithm 5 Centralized TACTAR: main |
| 1: set variables , , , 2: set constants , , , , , , , 3: While (at least one capable task is remained incompletion) 4: initialize uncompleted tasks 5: make sequence of tasks 6: end while |
In lines 3~7 of Algorithm 5, task allocation and alignment are performed until all tasks are completed. At the first iteration, variables for uncompleted tasks need to be initialized. The initialization for iterations is as below:
In Algorithm 6, lines 2~15 are performed for each agent. In lines 3~9 of Algorithm 6, initialization is performed based on condition of each task where is sequence of tasks for agent m. If the agent has not arrived at the task point, initialization in line 4 of Algorithm 6 is performed. In the case that the agent has arrived at the task point or started the task, initialization in line 7 of Algorithm 6 is performed. , , and are arrival time, start-time, and end-time of tasks, respectively, is the agent in charge of each task. If the user chooses accumulated distance cost scheme, lines 11~13 of Algorithm 6 are performed for recalculating accumulated distance, . After all, constraints made by deleted tasks in lines 4 or 7 of Algorithm 6 are deleted from the constraint table in line 14 of Algorithm 6. Note that if the agent in charge of the task differs from the agent in column 3 of the constraint table, these constraints also need to be deleted.
| Algorithm 6 Centralized TACTAR: line 4 of main | |
| 1: | form = 1: |
| 2: | for n = 1:size() |
| 3: | if agent m is not arrived (n) point |
| 4: | initialize , , , , for tasks (n) and after |
| 5: | Break |
| 6: | else if agent m is arrived (n) point or start (n) task last |
| 7: | initialize , , , , for after (n) |
| 8: | Break |
| 9: | end if |
| 10: | end for |
| 11: | if accumulated distance cost scheme |
| 12: | recalculate for |
| 13: | end if |
| 14: | delete constraints made by deleted tasks |
| 15: | end for |
After initialization is completed in line 4 of Algorithm 5, making a sequence of tasks, i.e., task allocation and alignment, is performed in line 5 of Algorithm 5 as follows:
In Algorithm 7, start-time, end-time, and reward(cost) of each task need to be calculated in line 1 before making the sequence of tasks if the task can be allocated. The conditions for the prohibition of task allocation are as in Table 11. Note that start-time and end-time of each task is calculated by assuming that agents move at maximum velocity. If at least one condition in Table 11 fails, the reward(cost), start-time, and end-time of the task are not calculated. In that case, the reward will be 0 if the user selects a time-discounted reward scheme and the cost will be infinity if the user selects an accumulated distance cost scheme.
| Algorithm 7 Centralized TACTAR: line 5 of main | |
| 1: | calculate , , and reward(cost) of each task |
| 2: | while (at least one task is not allocated) |
| 3: | if time-discounted reward scheme |
| 4: | find maximum reward |
| 5: | if maximum reward == 0 |
| 6: | Break |
| 7: | end if |
| 8: | else if accumulated distance cost scheme |
| 9: | find minimum cost |
| 10: | if minimum cost == infinity |
| 11: | break |
| 12: | end if |
| 13: | end if |
| 14: | find (agent, task) that have maximum reward(minimum cost) |
| 15: | align (agent, task) |
| 16: | renew , , , , for (agent, task) |
| 17: | add constraints to constraint table |
| 18: | if accumulated distance cost scheme |
| 19: | recalculate for |
| 20: | end if |
| 21: | calculate reward(cost) of each task |
| 22: | end while |
Table 11.
Conditions for prohibition of allocating task p to agent A in TACTAR.
If 11 conditions in Table 11 are all passed, start-time and end-time of each task are checked by the constraints table. If temporal violation can be solved by delaying these times, time correction proceeds. If not, these times are not corrected and reward(cost) calculation is processed. It is for time correction of already aligned tasks. Note that this procedure is not equal to bundle construction in Algorithm 1 or 3. In bundle construction, the sequence of whole tasks of each agent is made by calculating rewards(costs). However, in line 1 of Algorithm 7, reward(cost) of each task is calculated just for the next step. For example, there is an agent that is assigned task 1 and 2 and there are three remaining tasks. Then the rewards(costs), calculated in line 1 of Algorithm 7, are three rewards(costs) of remaining tasks for three sequences, (1-2-3), (1-2-4), and (1-2-5). The cost based on accumulated distance cost scheme is calculated as described in lines 6~7 of Algorithm 3.
The lines 2~22 in Algorithm 7 are repeated until all tasks are allocated. It will find (agent, task) set that has maximum reward(minimum cost) in line 14 of Algorithm 7. The alignment of this set is tried in line 15 of Algorithm 7 as described in Algorithm 8. In line 1 of Algorithm 8, constraints associated with the task in line 14 of Algorithm 7 are found in the constraint table. The lines 4~8 and lines 10~14 of Algorithm 8 are violation checked for start-time and end-time of the task, respectively. Note that only violations for ‘before’ and ‘simultaneous’ in Table 6 are checked because start-time and end-time are delayed based on the constraint table in line 1 of Algorithm 7 if they violate ‘after’ in Table 6. In lines 5 and 11 of Algorithm 8, aligned tasks correction proceeds. First, a task which made violated constraints afterwards are removed from tasks of the agent who made violated constraint. Then, constraints made by deleted tasks are removed from the constraint table. After that, constraints associated with the task in renewed constraint table are found in line 1 again. If the user choses accumulated distance cost scheme, is recalculated based on renewed in line 16 of Algorithm 7. Then, the calculation of rewards(costs) for remaining tasks proceeds for next iteration of lines 2~21 of Algorithm 7.
After the process in line 5 of Algorithm 5, task allocation and alignment for one iteration is performed. Lines 4 and 5 in Algorithm 5 are repeated every iteration until all capable tasks are completed, so real-time task allocation and alignment are performed by TACTAR.
| Algorithm 8 Centralized TACTAR: line 15 of Algorithm 7 |
| 1: find constraints associated the task in constraint table 2: for a = 1:number of constraints in line 1 3: if column 4 is 0 //start-time of task 4: if > column 5 and column 6 is 0 or 2 //violate before or simultaneous 5: delete the tasks constraint(a,3) and after all from constraint(a,2) 6: delete constraints made by deleted tasks in line 5 7: goto line 1 8: end if 9: else if column 4 is 1 //end-time of task 10: if > column 5 and column 6 is 0 or 2 //violate before or simultaneous 11: delete the tasks constraint(a,3) and after all from constraint(a,3) 12: delete constraints made by deleted tasks in line 5 13: goto line 1 14: end if 15: end if 16: end for |
6. Results and Discussion
In this section, simulation results are provided to assess TACTAR. First, two scoring schemes as described in Section 3 are applied to a simple case for verification of scoring schemes because it is hard to verify the schemes in complicated cases. This case is intuitive enough to prove the performance of scoring schemes. Then, these schemes are applied to complicated cases to check that TACTAR can derive a solution satisfying spatial and temporal constraints. Note that the complicated case must contain almost constraints in Table 7 and Table 8, and there are one or more solutions satisfying constraints for verification. Finally, a huge case which is composed of six agents, 30 tasks, and coupled constraints similar to the complicated case is used to emphasize the computational efficiency of TACTAR. These simulations are run by MATLAB 2018b, and specifications of the computer are in Table 12. Additionally, the settings for three cases are as shown in Table 13. To apply constraints in Table 13 to TACTAR, spatial and temporal matrices for the simple and complicated cases, respectively, should be made as described in Table 14.
Table 12.
Specifications of computer.
Table 13.
Settings for simulations.
Table 14.
Settings for simulations.
6.1. Time-Discounted Rewarding for Simple Case
Results for the simple case using the time-discounted scoring scheme are as in Figure 1, Figure 2 and Figure 3. In Figure 1, ‘A’ and ‘T’ mean agent and task, respectively, and numbers after these are the indices for agents or tasks. The red lines mean sequence of tasks for each agent. The number of tasks are larger than the number of agents so all agents are allocated (and aligned) tasks to get high total reward. Task 1 is allocated to agent 1 because agent 1 is the first to arrive at point of the task 1. Task 2 is allocated to agent 2 because the arrival time of task 2 for agent 2 is faster than agent 1. Figure 1 is the reasonable result from this point of view. Note that agent 2 is allocated to near tasks, task 2 and task 4, instead of far tasks, tasks 5~8, to obtain a high reward. It means that the modified time-discounted scoring scheme (and its original version as described in Equation (6)) is not used for minimizing total time for finishing all tasks. Figure 2 shows the computational time in this case. Most iterations are under 0.02 s so it is fast enough. Figure 3 describes the timetable of this case. Each row of Figure 2 shows the schedule of each agent. Blue bars mean working time of each task and the labels of y-axis mean agent in charge of tasks. ‘T’ and indices after that have same meaning as described in Figure 1. Note that the temporal constraints described in Table 13 are satisfied in the results.
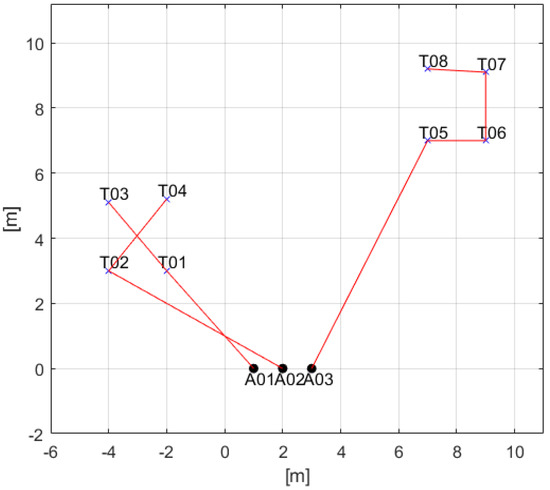
Figure 1.
2-D result of TACTAR for a simple case applying a modified time-discounted reward scheme.
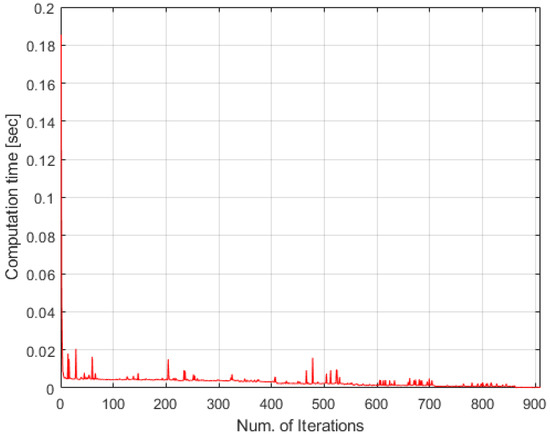
Figure 2.
Computational time of TACTAR for a simple case applying a modified time-discounted reward scheme.
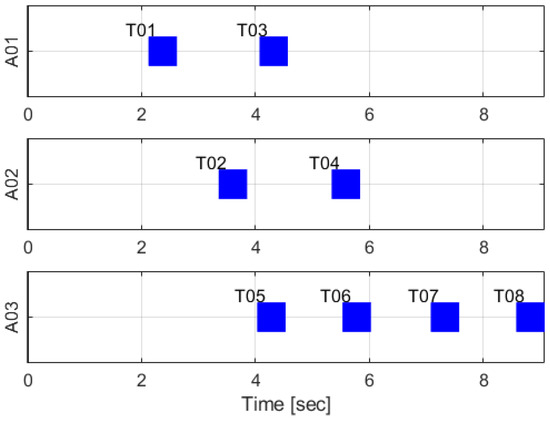
Figure 3.
Timetable result of TACTAR for a simple case applying a modified time-discounted reward scheme.
6.2. Accumulated Distance Cost for Simple Case
The results for the simple case using the accumulated distance scoring scheme are as in Figure 4, Figure 5 and Figure 6. Unlike the results in Section 6.1, only two agents, except agent two, are allocated tasks, although the number of tasks are larger than the number of agents. Task 1 is allocated to agent 1 first because distance between the point of the task 1 and the agent 1 is the shortest. Next, task 2 is allocated to agent 1 because increased total travel distance after finishing the task 1 is the smallest in this case. Figure 4 is an intuitive and reasonable result from this point of view. Figure 5 shows the computational time in this case. Most iterations are also under 0.02 s as seen in Figure 2 so it is fast enough. Figure 6 describes the timetable of this case. Agent 2 is not allocated to any task, so there is no timetable in row 2 of Figure 6. Note that the temporal constraints described in Table 13 are satisfied in the results.
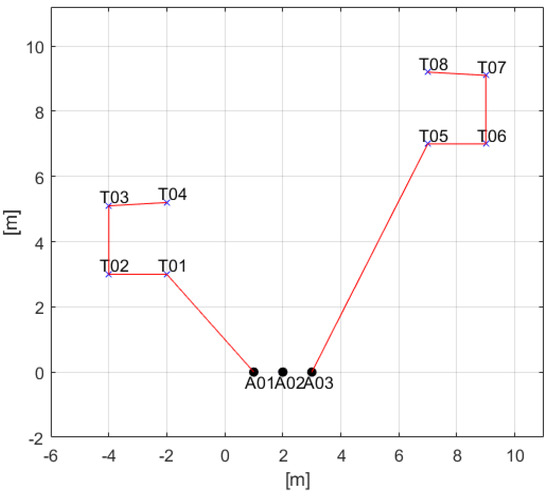
Figure 4.
2-D result of TACTAR for a simple case applying an accumulated distance cost scheme.
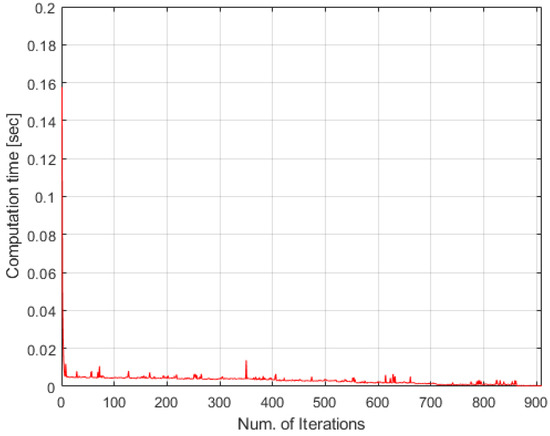
Figure 5.
Computational time of TACTAR for a simple case applying an accumulated distance cost scheme.
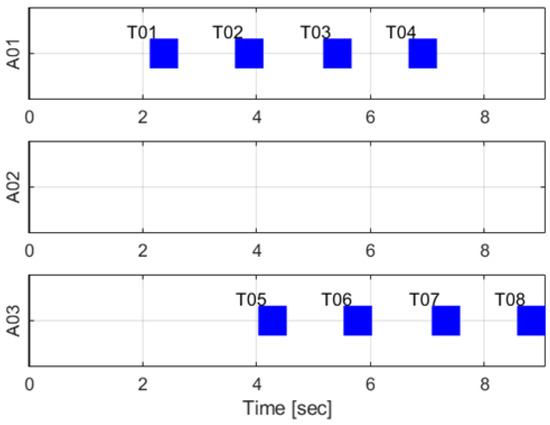
Figure 6.
Timetable result of TACTAR for a simple case applying an accumulated distance cost scheme.
6.3. Time-Discounted Rewarding for Complicated Case
The time-discounted scoring scheme is verified in simple cases as in Section 6.1. Therefore, this scheme is applied to the complicated case and the results are as in Figure 7, Figure 8 and Figure 9. These results are different from the results in Section 6.1 because the spatial and temporal constraints are changed. In Figure 7, agent 1 is not allocated task 3 because task 1 is in local MUTEX relationship with the task 3. Additionally, the start-time of task 8 is faster than task 4 which is in global MUTEX relationship with task 8 so task 4 is not allocated to all agents. Therefore, all spatial constraints in Table 13 are satisfied in the results. Figure 8 shows the computational time in this case. Most iterations are under 0.05 s so it is fast enough. In Figure 9, agent 1 arrives at the point of task 1 early but task 1 starts late because task 1 must start with task 5 simultaneously. The red bar means hold time at point of each task. Note that the hold time is from arrival time to start time of task. Task 2 must start after task 1 ends so agent 2 waits until the task 1 ends. The third temporal constraint is that task 6 must start during work at task 7. To satisfy this constraint, agent 3 waits until 0.2 s before the start-time of the task 6 because is set to 0.3 s and is set to 0.5 s. Note that TACTAR is iterated frequently so if the start-time of task 6 is delayed, the start-time of task 7 will be also delayed reflecting the situation of task 6. All temporal constraints in Table 13 are also satisfied in the results.
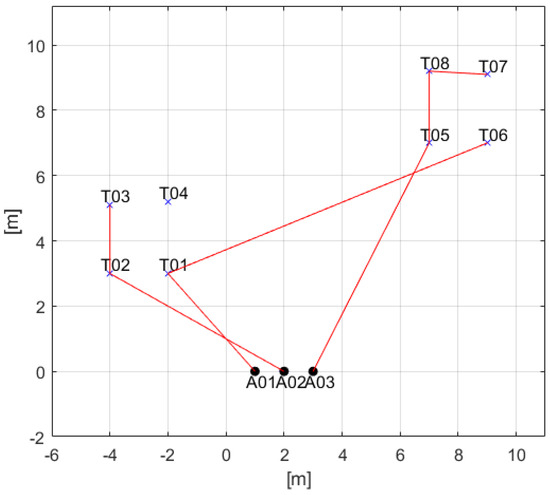
Figure 7.
2-D result of TACTAR for a complicated case applying a modified time-discounted reward scheme.
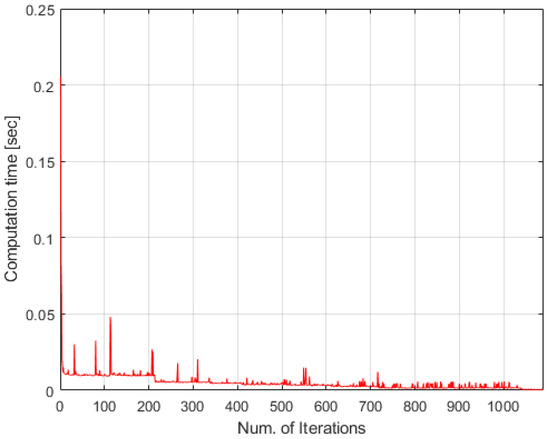
Figure 8.
Computational time of TACTAR for a complicated case applying a modified time-discounted reward scheme.
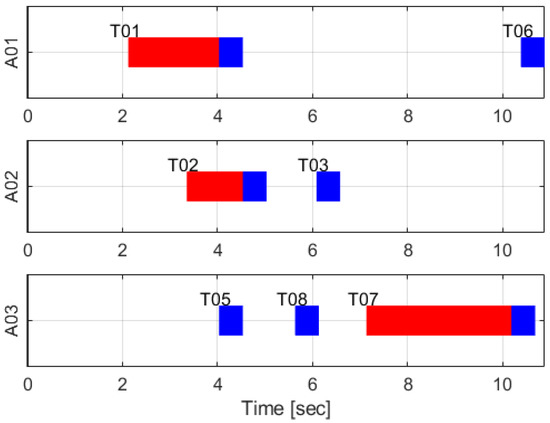
Figure 9.
Timetable result of TACTAR for a complicated case applying a modified time-discounted reward scheme.
6.4. Accumulated Distance Cost for Complicated Case
The accumulated distance scoring scheme is also verified in the simple case as in Section 6.2, so this scheme is applied to the complicated case. The results are as in Figure 10, Figure 11 and Figure 12. These results are also different to the results in Section 6.2 because of constraints. In Figure 10, agent 1 is not allocated task 3 because task 1 is in local MUTEX relationship with the task 3. Additionally, start-time of task 4 is faster than task 8 which is in global MUTEX relationship with the task 4, so the task 8 is not allocated to all agents. Therefore, all spatial constraints in Table 13 are satisfied in the results. Figure 11 shows the computational time in this case. Most iterations are also under 0.05 s as seen in Figure 8 so it is fast enough. In Figure 12, agent 1 arrives at the point of task 1 early but task 1 starts late because the task 1 must start with task 5 simultaneously. Task 3 also starts late because task 3 must start after the end of task 2. Task 7 is paused to start so long because of the third temporal constraint in Table 13. When the current time is 0.2 s before the start-time of task 6, the task is started by agent 3. Therefore, all temporal constraints in Table 13 are also satisfied in the results.
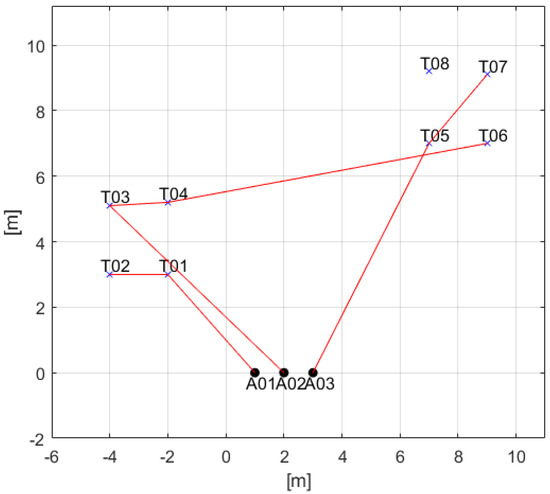
Figure 10.
2-D result of TACTAR for a complicated case applying an accumulated distance cost scheme.
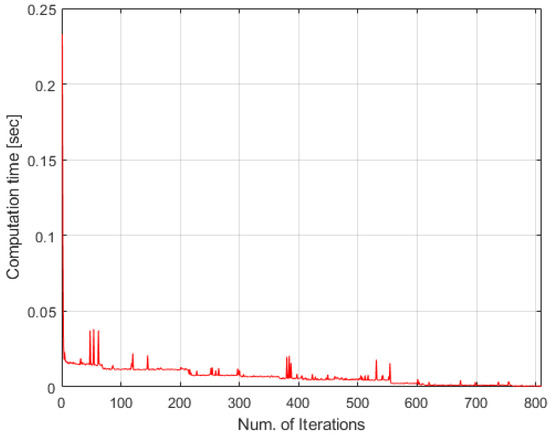
Figure 11.
Computational time of TACTAR for a complicated case applying an accumulated distance cost scheme.
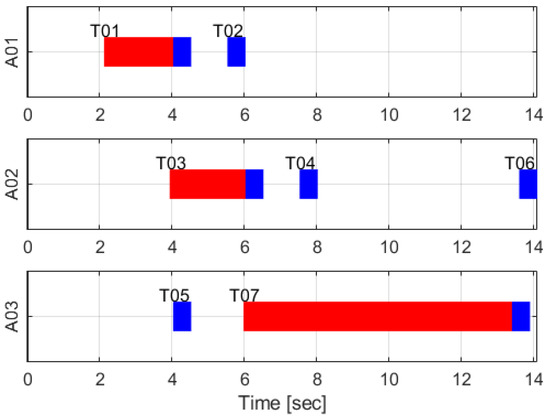
Figure 12.
Timetable result of TACTAR for a complicated case applying an accumulated distance cost scheme.
6.5. Time-Discounted Rewarding for Huge Case
The time-discounted scoring scheme is verified in simple and complicated cases as in Section 6.1 and Section 6.3, so this scheme is applied to the huge case for showing computational efficiency. The results are as in Figure 13, Figure 14 and Figure 15. As we can see, all spatial and temporal constraints in Table 13 are satisfied in Figure 13 and Figure 15. Figure 14 describes computational time of huge cases. The computational time is under 0.15 s for all iterations except the first one. Additionally, it decreases as the number of iterations increases because tasks are finished by agents. Note that these are the results using MATLAB which uses only a single CPU core. If the simulations are run by another compiler such as Visual Studio etc., the computational time will be much lower.
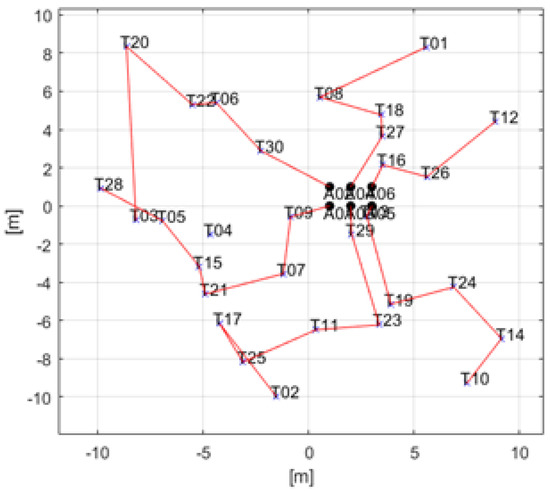
Figure 13.
2-D result of TACTAR for a huge case applying a modified time-discounted reward scheme.
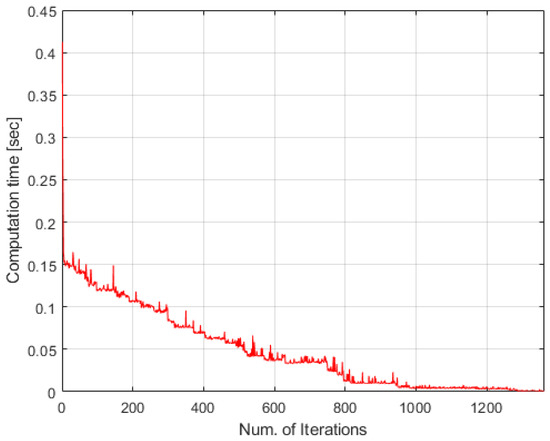
Figure 14.
Computational time of TACTAR for a huge case applying a modified time-discounted reward scheme.
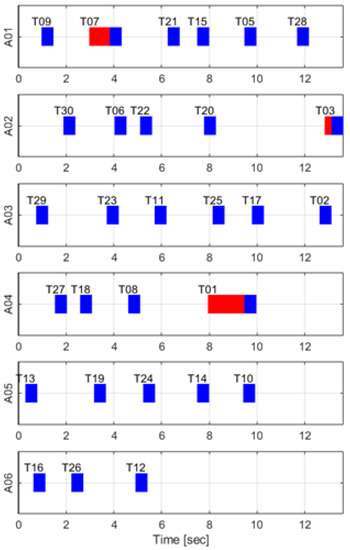
Figure 15.
Timetable result of TACTAR for a huge case applying a modified time-discounted reward scheme.
7. Conclusions
In this paper, we introduced an algorithm for coupled-constraint task allocation and alignment problems using a constraint table and alignment rules called TACTAR. The two scoring schemes are used for task allocation. One is time-discounted reward scheme which is used in CBBA. For preventing the situation that two or more rewards of tasks are the same and calculating rewards based on both arrival time and end-time of tasks, a modified version of the reward scheme is used in TACTAR. To obtain reasonable allocation results, we need to set weights of arrival and end-rewards appropriately. The other is accumulated distance cost scheme which is proposed first in this paper. This scoring scheme is used for allocation with minimum fuel consumption.
The constraint table is used for task allocation and alignment. The constraint table has six columns which contain constrained task, who and which task makes constraints, and the contents of constraints. It is used in task allocation when arrival, start, and end-time of each task are used for calculating reward(cost). Additionally, it is used in task alignment, which is based on alignment rules. The alignment rules are about methods between candidate task of alignment and tasks already aligned. Finally, pseudo-codes of TACTAR and simulations for simple and complicated cases are described. The constraints used in TACTAR are different from those in CCBBA because some constraints are added for needs. Additionally, some constraints are deleted because it can be replaced with another one. However, the temporal constraint ‘Not During’ in CCBBA cannot be handled in this paper, which is a minor limitation of TACTAR. Some limitations including this have to be solved in future works.
Author Contributions
Conceptualization, N.E.H.; methodology, N.E.H.; software, N.E.H.; validation, N.E.H.; formal analysis, N.E.H.; investigation, N.E.H.; resources, N.E.H.; data curation, N.E.H.; writing—original draft preparation, N.E.H.; writing—review and editing, N.E.H.; visualization, N.E.H.; supervision, H.J.K. and J.G.K.; project administration, H.J.K. and J.G.K.; funding acquisition, H.J.K. and J.G.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Korea Research Institute for defense Technology planning and advancement (KRIT) grant funded by the Korea government (DAPA (Defense Acquisition Program Administration)) (No. KRIT-CT-21-009, Development of Realtime Automatic Mission Execution and Correction Technology based on Battlefield Information, 2022).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study might be available on reasonable request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jeong, B.M.; Ha, J.S.; Choi, H.L. MDP-Based Mission Planning for Multi-UAV Persistent Surveillance. In Proceedings of the 2014 14th International Conference on Control, Automation and Systems, Gyeonggi-do, Korea, 22–25 October 2014. [Google Scholar]
- Billionnet, A.; Costa, M.C.; Sutter, A. An Efficient Algorithm for a Task Allocation Problem. J. ACM 1992, 39, 502–518. [Google Scholar] [CrossRef]
- Bellingham, J.; Tillerson, M.; Richards, A.; How, J.P. Multi-Task Allocation and Path Planning for Cooperating UAVs. In Cooperative Control: Models, Applications and Algorithms, 1st ed.; Butenko, S., Murphey, R., Pardalos, P.M., Eds.; Springer: Boston, MA, USA, 2003; Volume 1, pp. 23–41. [Google Scholar]
- Liu, C.; Kroll, A. A Centralized Multi-Robot Task Allocation for Industrial Plant Inspection by Using A* and Genetic Algorithms. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 29 April–3 May 2012. [Google Scholar]
- Jin, Y.; Minai, A.A.; Polycarpou, M.M. Cooperative Real-Time Search and Task Allocation in UAV Teams. In Proceedings of the 42nd IEEE International Conference on Decision and Control, Hawaii, HI, USA, 9–12 December 2003. [Google Scholar]
- Lagoudakis, M.G.; Berhault, M.; Koenig, S.; Keskinocak, P.; Kleywegt, A.J. Simple Auctions with Performance Guarantees for Multi-Robot Task Allocation. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, 28 September–2 October 2004. [Google Scholar]
- Marcarthur, K.S.; Stranders, R.; Ramchurn, S.D.; Jennings, N.R. A Distributed Anytime Algorithm for Dynamic Task Allocation in Multi-Agent Systems. In Proceedings of the 25th AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011. [Google Scholar]
- Oh, K.T.; Kim, W.D. Task Assignment Algorithm for Rendezvous of Multiple UAVs. In Proceedings of the 2012 Korean Society for Aeronautical and Space Sciences Fall Conference, Jeju, Korea, 7–11 November 2012. [Google Scholar]
- Wei, H.; Lv, Q.; Duo, N.; Wang, G.S.; Liang, B. Consensus Algorithms Based Multi-Robot Formation Control under Noise and Time Delay Conditions. Appl. Sci. 2019, 9, 229–244. [Google Scholar] [CrossRef] [Green Version]
- Xiang, C.; Li, Y.; Zhou, Y.; He, S.; Qu, Y.; Li, Z.; Gong, L.; Chen, C. A Comparative Approach to Resurrecting the Market of MOD Vehicular Crowdsensing. In Proceedings of the IEEE International Conference on Computer Communications, Virtual Conference, 2–5 May 2022. [Google Scholar]
- Xiang, C.; Zhou, Y.; Dai, H.; Qu, Y.; He, S.; Chen, C.; Yang, P. Reusing Delivery Drones for Urban Crowdsensing. IEEE Trans. Mob. Compt. 2021; preprint. [Google Scholar] [CrossRef]
- Choi, H.L.; Brunet, L.; How, J.P. Consensus-Based Decentralized Auctions for Robust Task Allocation. IEEE Trans. Robot. 2009, 25, 912–926. [Google Scholar] [CrossRef] [Green Version]
- Whitten, A.K.; Choi, H.L.; Johnson, L.B.; How, J.P. Decentralized Task Allocation with Coupled Constraints in Complex Missions. In Proceedings of the 2011 American Control Conference, San Francisco, CA, USA, 29 June–1 July 2011. [Google Scholar]
- Whitten, A. Decentralized Planning for Autonomous Agents Cooperating in Complex Missions. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2010. [Google Scholar]
- Lim, M.C.; Choi, H.L. Improving Computational Efficiency in Crowded Task Allocation Games with Coupled Constraints. Appl. Sci. 2019, 9, 29–52. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.H.; Moon, G.H.; Yoo, D.W.; Tahk, M.J.; Lee, I.S. Distributed Task Assignment Algorithm for SEAD Mission of Heterogeneous UAVs Based on CBBA Algorithm. J. Korean Soc. Aeronaut. Space Sci. 2012, 40, 988–996. [Google Scholar]
- Moon, S.; Kim, H.J. Cooperation with Ground and Arieal Vehicles for Multiple Tasks: Decentralized Task Assignment and Graph Connectivity Control. J. Inst. Contr. Robot Syst. 2012, 18, 218–223. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).