
Smart Grid Data Management in a Heterogeneous Environment with a Hybrid Load Forecasting Model

 , ,
, ,  ,
, 
Abstract
1. Introduction
- The Capability of Heterogeneous Data Acquisition and Data Federation
- A Hybrid Load Forecasting Model (Clustering, Historical Data, and External Factors)
2. Problem Statement: A Case Study for Energy Sector in Iraq
2.1. Direct Factors
2.2. Indirect Factors
3. Related Works
3.1. Existing and Potential Applications in Power Consumption for Data Management
3.2. Existing and Potential Applications in Power Consumption for Load Forecasting
3.3. Challenges of Applications in Power Consumption
3.3.1. Energy Efficiency Monitoring and Management
3.3.2. Power Consumption and Big Data Analytics Processing
4. The Proposed System
4.1. Data Tier Structure
- Step 1: Database Scheme creation: Structure definition, data format, and correlation among the tables
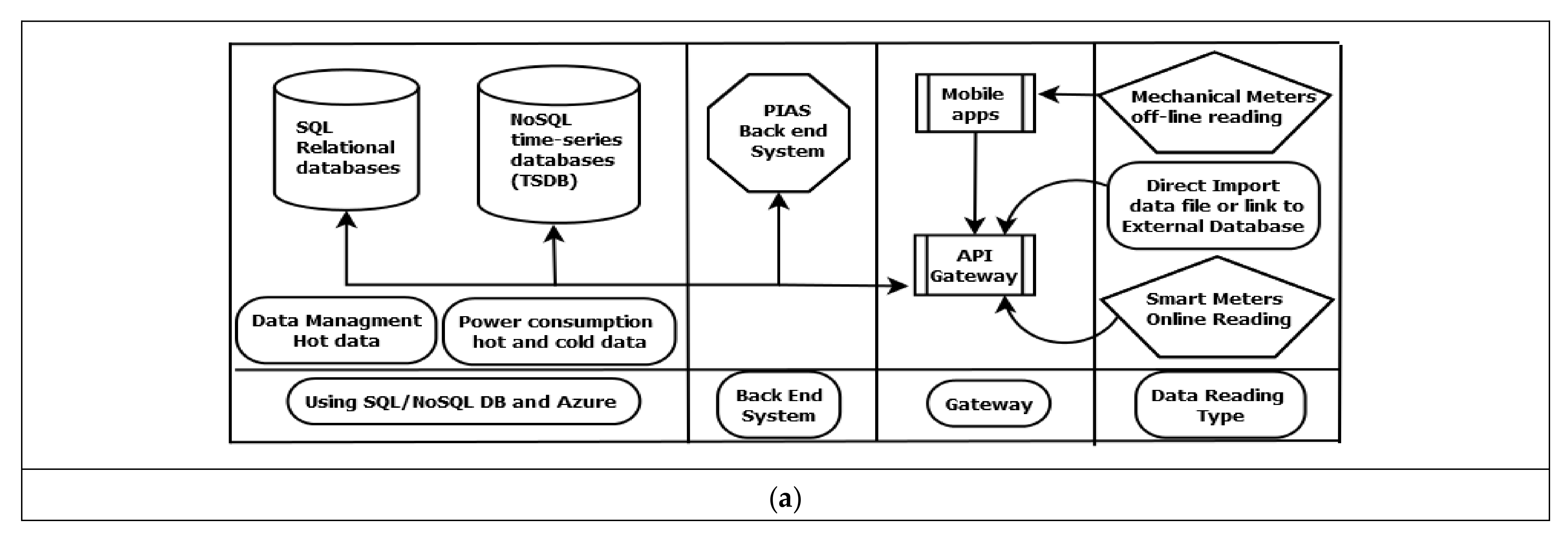
- Step 2: Data Acquisition: The collected data can be inserted into the database using many techniques, such as API Gateway, links to other databases as well as direct import to the data files, and direct reading from smart meters through PLC, the Data Concentrator Unit (DCU), and GPRS, in addition to reading offline data (mechanical meters) through the PIAS mobile application, as shown in Figure 2a,b. This mobile app is designed to work offline, connected to our system through API Gateway with the capability of reading the meter’s value from the image of mechanical meter measurement. The identified measurement value is transferred to a digital value and stored in the mobile devices which were used at the time of reading. Then, the stored data are sent along with the unique ID of each subscriber and meter ID to the PIAS through API Gateway when the mobile device is connected to any internet network. This will effectively reduce human errors in reading the values and reduce the costs required for this process.
- Step 3: Data manipulation: Create, read, update, and delete (CRUD) operations of any data from the database.
- Step 4: Querying: Retrieval of stored data to be used by the analytics and application tier.
- Step 5: Integration of security modules: Authorizing access to the data and ensuring which data to reveal.
4.2. Analytics Tier Structure
4.3. Application Tier Structure
4.4. Presentation Tier Structure
5. Results and Discussion (Case Study 1)
5.1. Case Study 1: Data Management
5.1.1. Data Quality and Design Structure
- Design an independent structured database to host mechanical meter data and an independent unstructured database (NoSQL) to host future smart meter data. The unstructured database will have a dynamic scheme with horizontal scalability, as it can be a document, key-value, images, or wide column store, which can be modified at any stage. This scheme will be fully dependent on the future controls that are set by the ministry of electricity requirements, where both databases are connected through the API gateway of our system. The system can access both databases with an integrated interface through the PIAS’s front-end. This proposed design gives the capability to host data from various sources such as mechanical and smart meters independently but integrated into the system’s back-end through API and the front end of the system using GUI.
- Data Quality: Data cleaning and data pre-processing will be applied before any data import process. These processes will be only applied to mechanical meter data in the offline form (i.e., after manual reading and direct data feeding or digital transformation through the mobile application platform designed specifically for this purpose) or any other historical data form. This process can also be used to migrate the historical data, while the real-time data from smart meters will be a direct injection into our unstructured database through an enterprise API. Moreover, this process can remove irrelevant and obsolete data in historical data from the mechanical meters. These might include inactive accounts, missing information, closed accounts, or empty accounts from the dataset. A powerful cleaning procedure with Microsoft SQL was used to gain clean data. For the case study, a meter must fulfill the following four requirements to be considered. After the cleaning process was completed, 1,445,000 active and clean record entries of subscribers (mechanical meters) were retrieved. The following steps have been followed to ensure the data quality:
- Step 1: Check if the basic account information has been updated in the last 15 years.
- Step 2: Check if the account opens or active flags.
- Step 3: Check and remove special characters such as (\.|\,|\!|\@|\#|\‘|\~|\$|\%|\^|\+|\/|\-|\&|\*|
\( |\) |_|\+| |\=|\[|\]|\{|\}|\:|\”|\;|\’|\,|\.|\/|\<|\>|\?) - Step 4: Check and remove white spaces such as the word tab and new line spaces.
- Step 5: Check if some record fields contain letters and numbers together; this must be split and standardized.
- Step 6: Check if any record fields need type conversion.
- Step 7: Check if the account has any missing or empty information.
- Step 8: Recheck the database normalization and unify the lookup table value.
- Step 9: Check and remove any duplicates account records (merge, update and/or isolate the duplicate records).
- Additionally, the structured database can be joined to the climate condition data [60] where the subscribers’ information was linked to the climatic data that was retrieved from the Iraqi Weather Authority. In this work, the database source can either be by direct data injection or automated link via the API gateway of the proposed system. The climatic information is comprised of parameters such as maximum and minimum temperature, average temperature, amount of rainfall, humidity, and the length of daytime. The climatic data were collected simultaneously with power consumption data to determine an effective and accurate link between the two datasets. Figure 4 shows the step-by-step data cleaning and pre-processing process that was applied to the collected raw data. Moreover, additional fields were added to the database to create the final structure. These fields are comprised of information such as personal information, address, and the subscriber’s geographical location, which will be used for the proposed PIAS later.
- d.
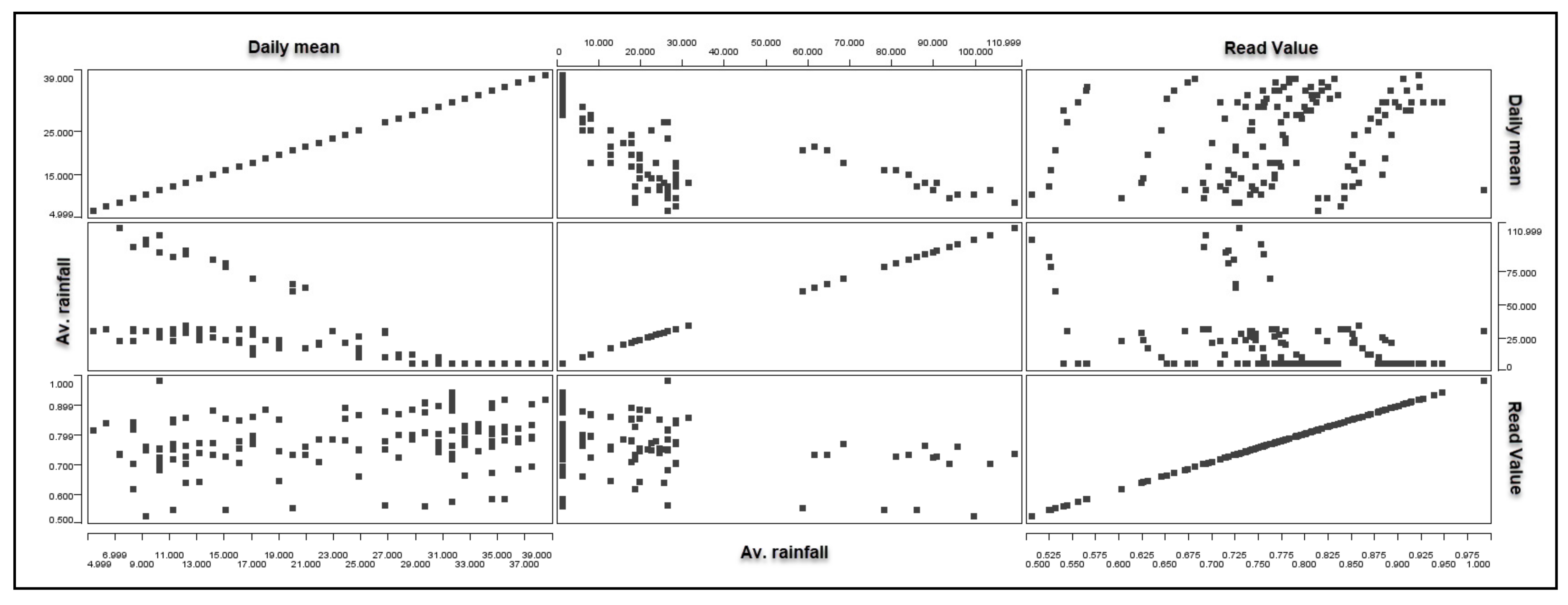
- Basic statistical analysis can be applied to the variables of the clean dataset. Table 5 shows the statistical analysis of the dataset variables after pre-processing and linking to climatic information, where the skewness was used to measure the symmetry of a dataset [61]. A higher value of these parameters means the data have high divergence. Similarly, skewness was used to describe our dataset; skewness of zero means that it is symmetrical, whereas a positive value means a shift towards the right side and a negative value towards the left [61]. Furthermore, kurtosis was used to measure the ‘tiredness’ of data or measure the data distribution peak [34]. A high kurtosis means that data are highly tailed and vice versa. The kurtosis is used to measure the degree of a distribution’s peaks. A kurtosis value close to (0) means that normal distribution is observed, a kurtosis value lower than (0) means the distribution has a light tail, and a kurtosis value larger than (0) represents a distribution with heavier tails. Moreover, a scatter matrix was used to determine the correlation between the variables and identify the correlation’s nature (if it exists) between the variables [62]. Figure 5 below shows the scatter matrix of the temperature variables used in this research. The range of reading values is from 0.5 to 1.0, against which other variables are plotted in the diagram. The daily mean temperature lies in the range of 4.999 to 39.000 and shows an increasing trend. The graph also shows positive correlations between several variables that can act as predictive indicators for the future.
5.1.2. PIAS Web Interface
5.1.3. Data Visualization
6. Results and Discussion (Case Study 2)
6.1. Case Study 2: Data Analytics (Load Forecasting)
6.1.1. The Proposed Model
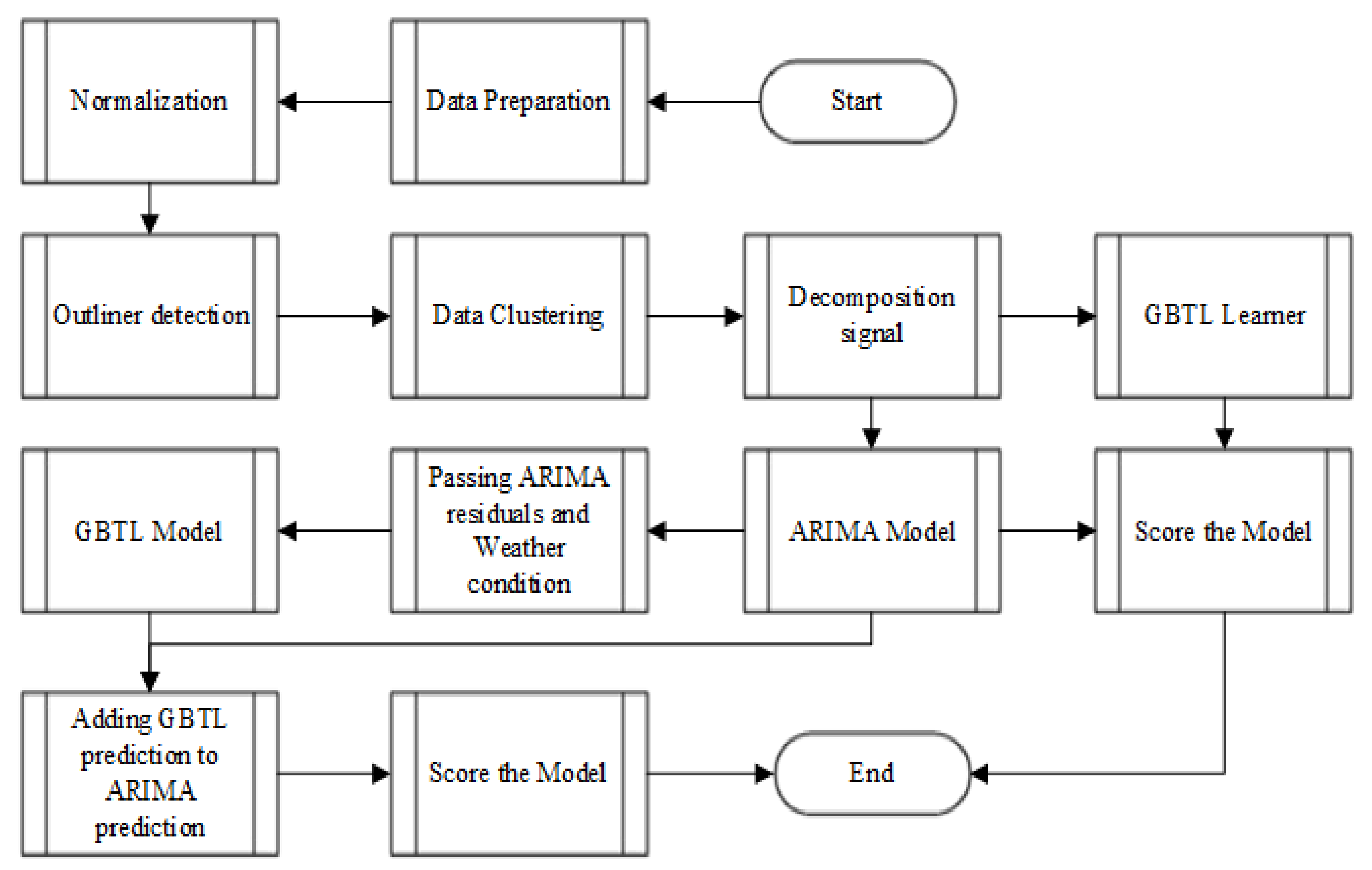
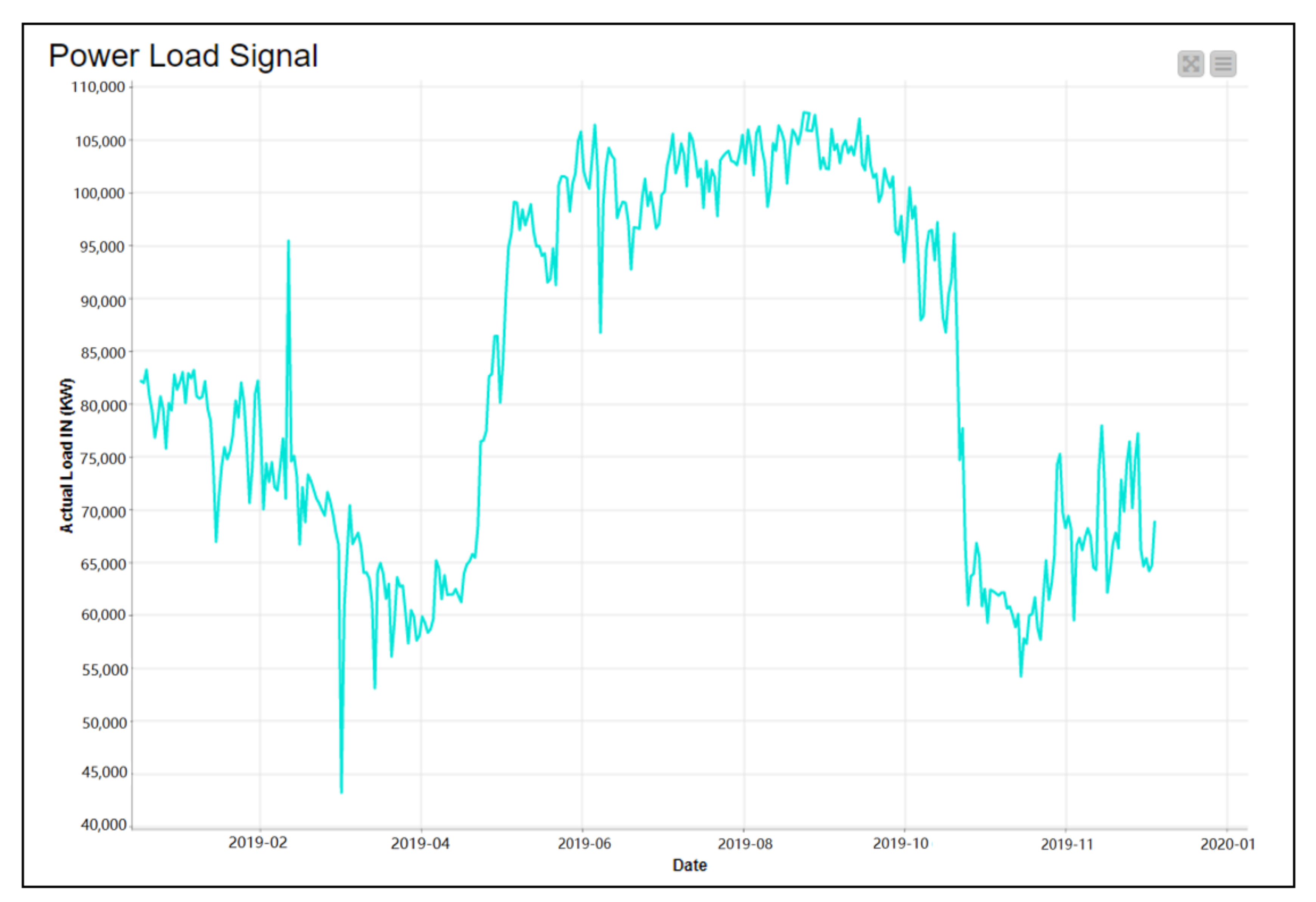
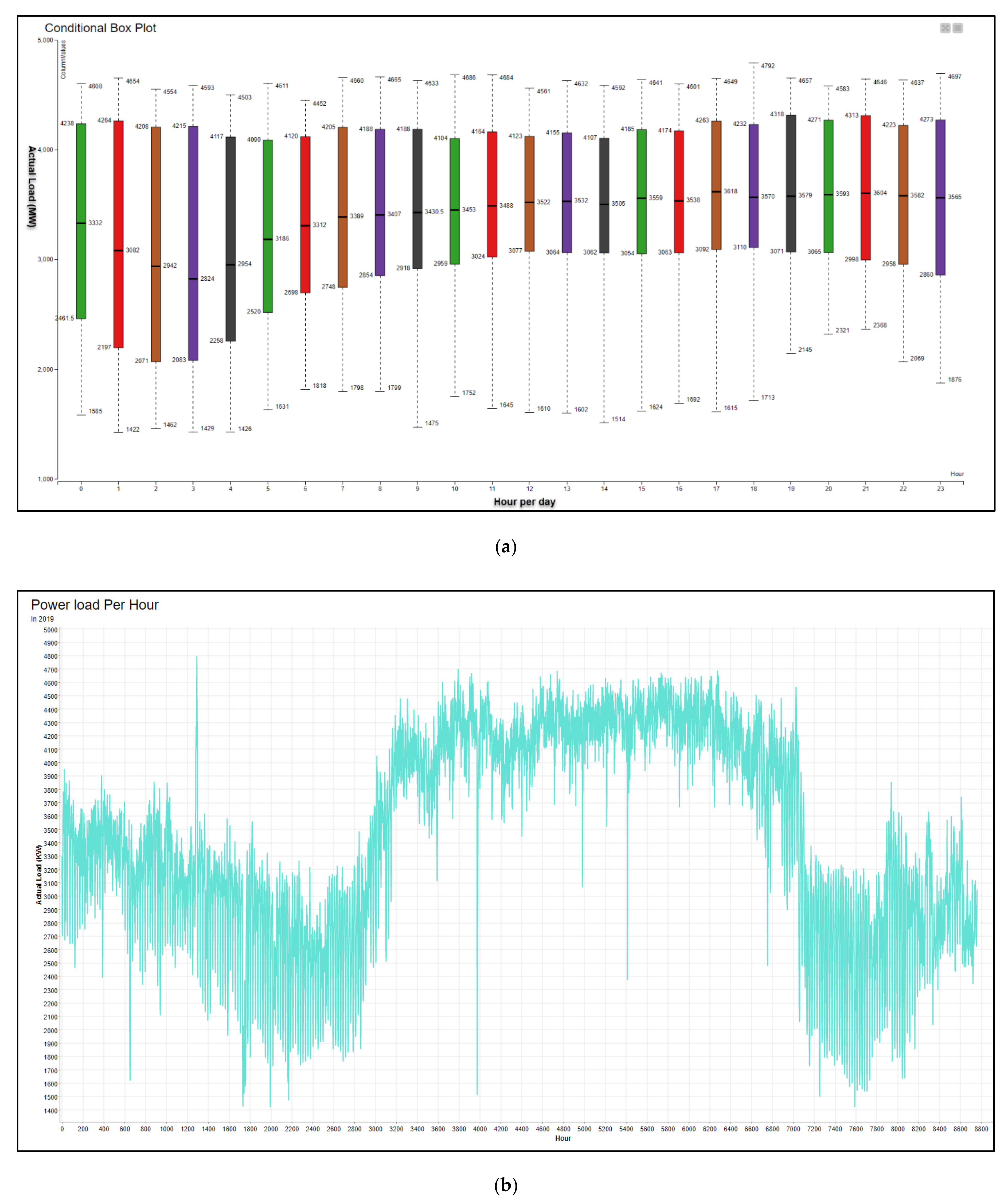
- First Stage (Data Reading and Preparation): data can be imported directly or linked to different databases through the internal API of our system and integrated and connected with the Knime platform. The next step is to un-pivot data from a 365/24 matrix to an hourly data form, 365*24. Figure 14 shows the daily Baghdad governorate load distribution (kW) for 2019, while Figure 15a,b show the hourly Baghdad governorate load distribution (kW) for 2019; in addition, we are checking missing values and normalization the load value between 0 and 0.5. Moreover, to handle rapid or irregular fluctuations and outliers (irregular patterns). Additionally, we applied outlier detection to smooth our data for the next stage process.
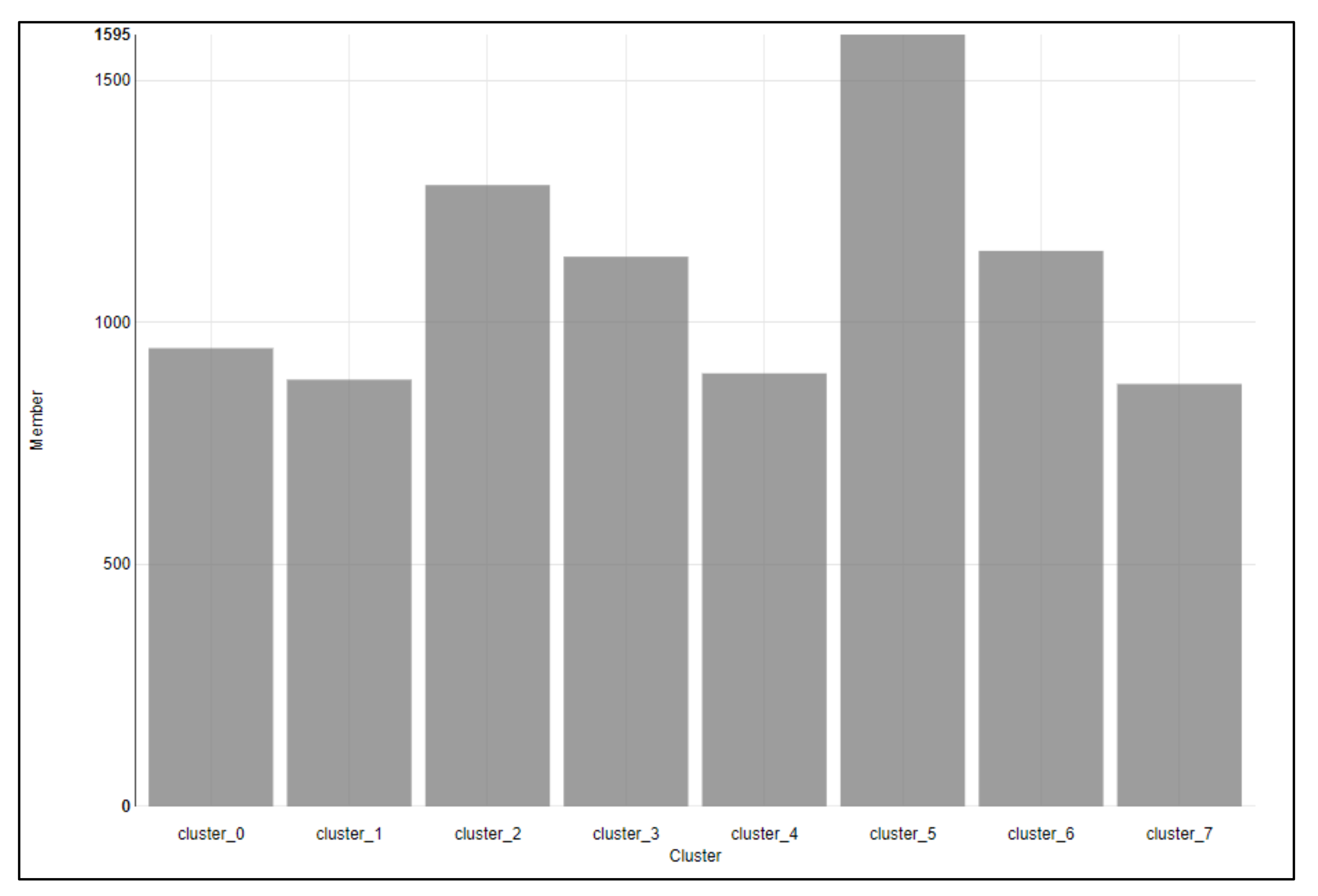
- Second Stage (Data Clustering with FCM): our novel approach includes clustering data of an entire period, i.e., for 365*24 (8760 H) of 2019. The clustering analysis is an unsupervised method that behaves as a keystone in data analysis developments, which is especially helpful in an irregular patterns dataset. For that, FCM clustering was used to discover a set of homogeneous patterns in a heterogeneous load dataset [30]. The number of eight cluster groups that share the same characteristics in load was appropriate for the entire period, where each data input (value) is assigned, a likelihood score appropriate to that cluster. The formula of FCM is given in Equation (1) [30]. Figure 16 shows the cluster group membership.
- Xi = {X1, X2, , Xn}: the input value
- is the membership value of the element Xi in a cluster with center Vk, 1 ≤ i ≤ N; 1 ≤ k ≤ C
- The bigger is, the higher the degree of confidence that the element Xi belongs to the cluster k.
- m is the fuzzification coefficient of the algorithm.
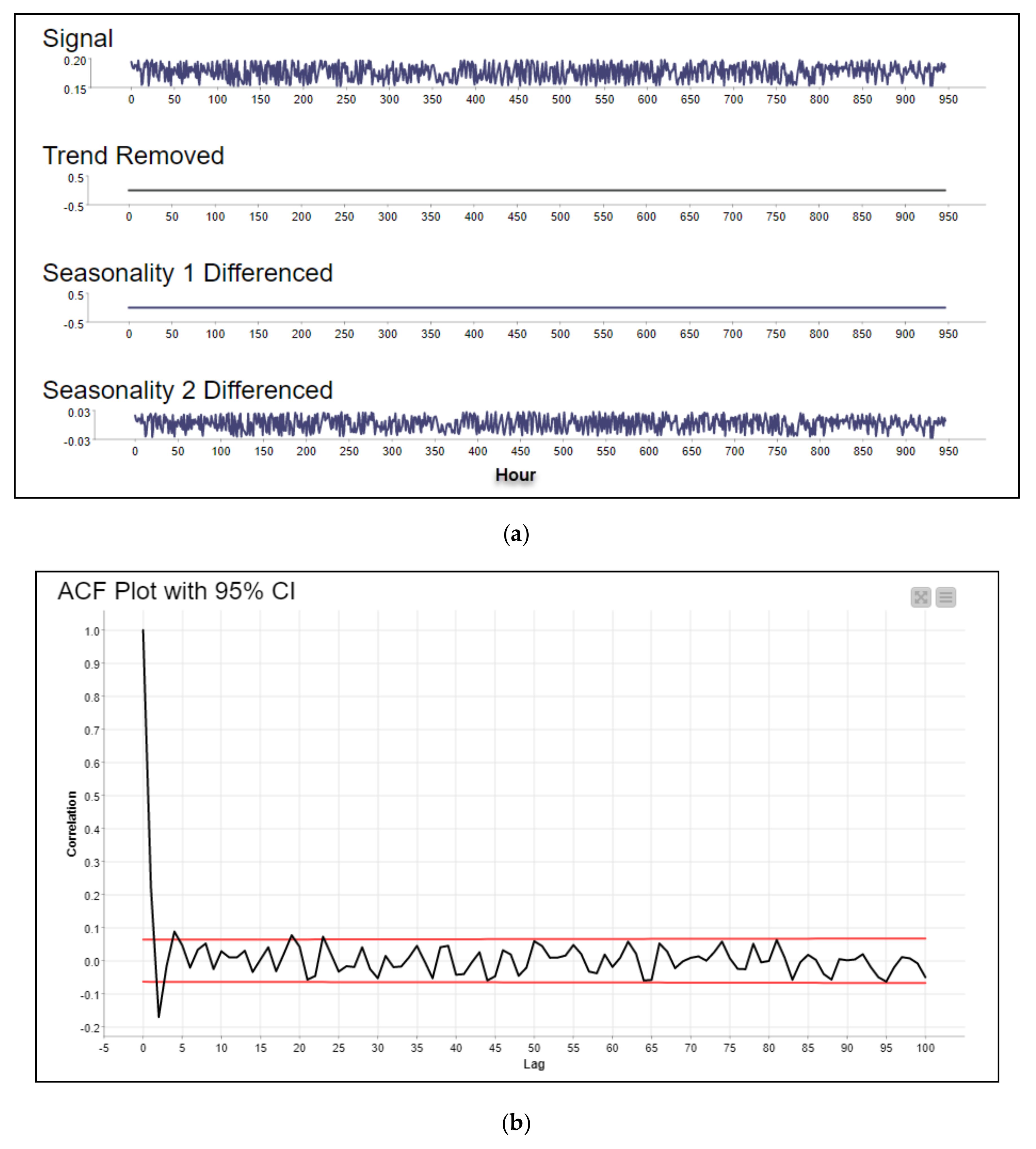
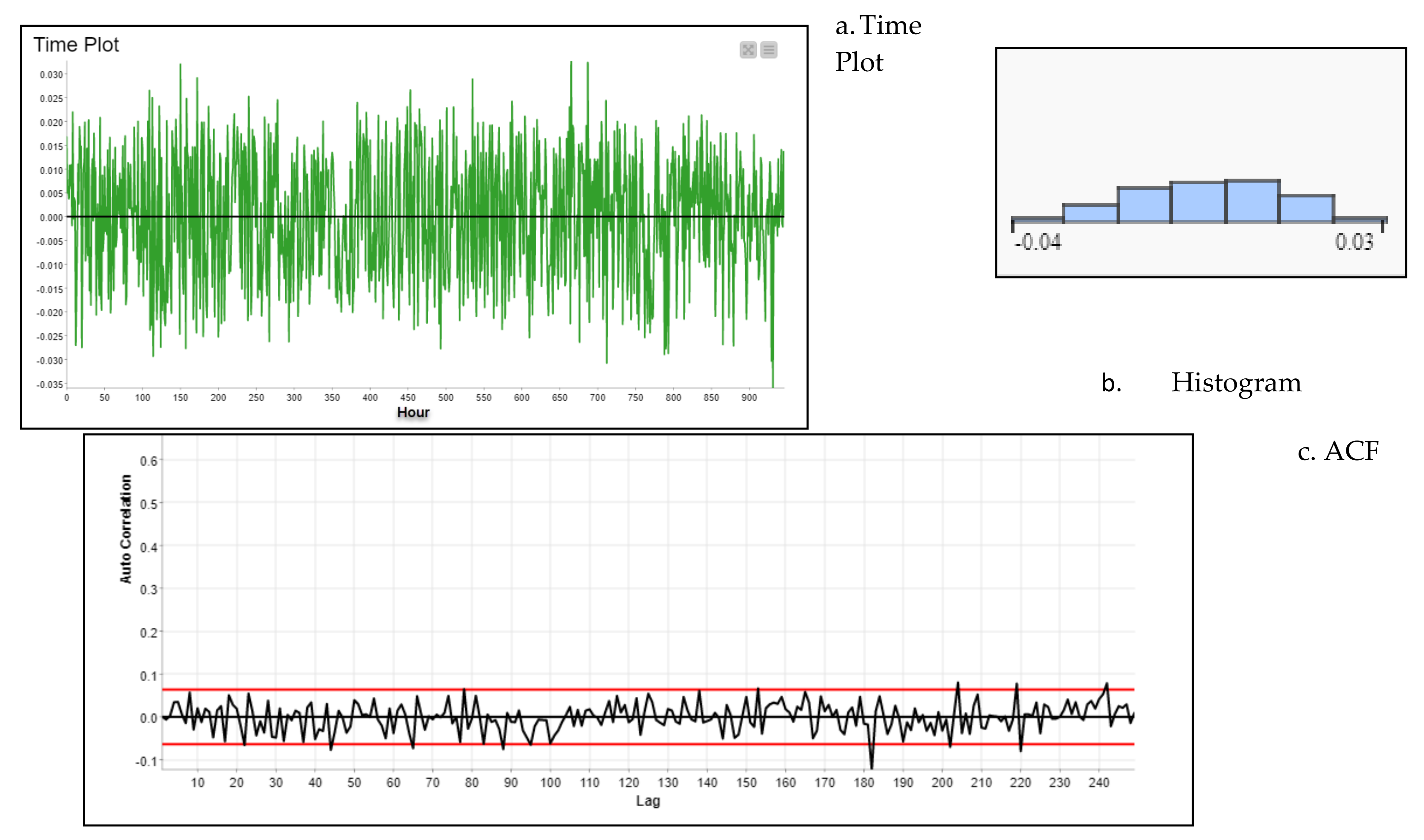
- Third Stage (Signal Decomposition): to provide a good benchmark for our forecasting, the seasonality inspection and a decomposition signal model have been applied to each cluster. A decomposition signal is a process of extracting the information from the reading value data over time (), into a much smaller component, such as (i) seasonality (), which represents the major spike in the autocorrelation of the data over time, (ii) trend (), from fitting a regression model of data over time, and (iii) residual (), the component for further analysis, which represents the remaining data over time (Equation (2)). The knime auto decomposition signal (loess regression) was applied with max observation lags of 100, lag step of 1, and correlation cut-off value of 0.5. This will automatically check the tested signal for trend, seasonality, and the residual. We can inspect seasonality in a time series in an Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF). The regular and unregular peaks in the plot can give information about seasonality, which can be eliminated by differencing the data at the lag with the highest correlation. An example from Cluster 0 can be seen in Figure 17a–c to show the decomposition signal, ACF and PACF, respectively.
- Fourth Stage (ARIMA Model): After observation and removing the trend () and seasonality () from our main signal, the residual () will pass to the next node which is used as the training data for the forecasting model. The ARIMA models have been used to forecast a given time series dataset based on its historical values. As we have one year period in an hourly based time stamp, our proposed model can predict the load of one value which represents one hour ahead, or one day ahead, 24 h value, or one week ahead, 168 h value, etc. The time, date, or period that needs to be forecast can be controlled before the ARIMA model is applied. Cases such as a certain day or a certain period must be considered along with selecting the right cluster that they belong to. An ARIMA consists of two parts: an autoregressive (AR) model where the variable depends only on its lags, and a moving (MA) model [34] that combines the dependence between observation and residual of the forecast errors. ARIMA is written with the notation ARIMA (p,d,q), where ‘p’ represents the number of lag observations, ‘d’ represent the number of differences necessary to make the dataset stationary, and ‘q’ represents the size of the moving average window. The formula of ARIMA is given in Equation (3).
- p = is the order of the autoregressive part.
- q = is the order of the moving average part.
- c = constant.
- et = residuals (error in time t).
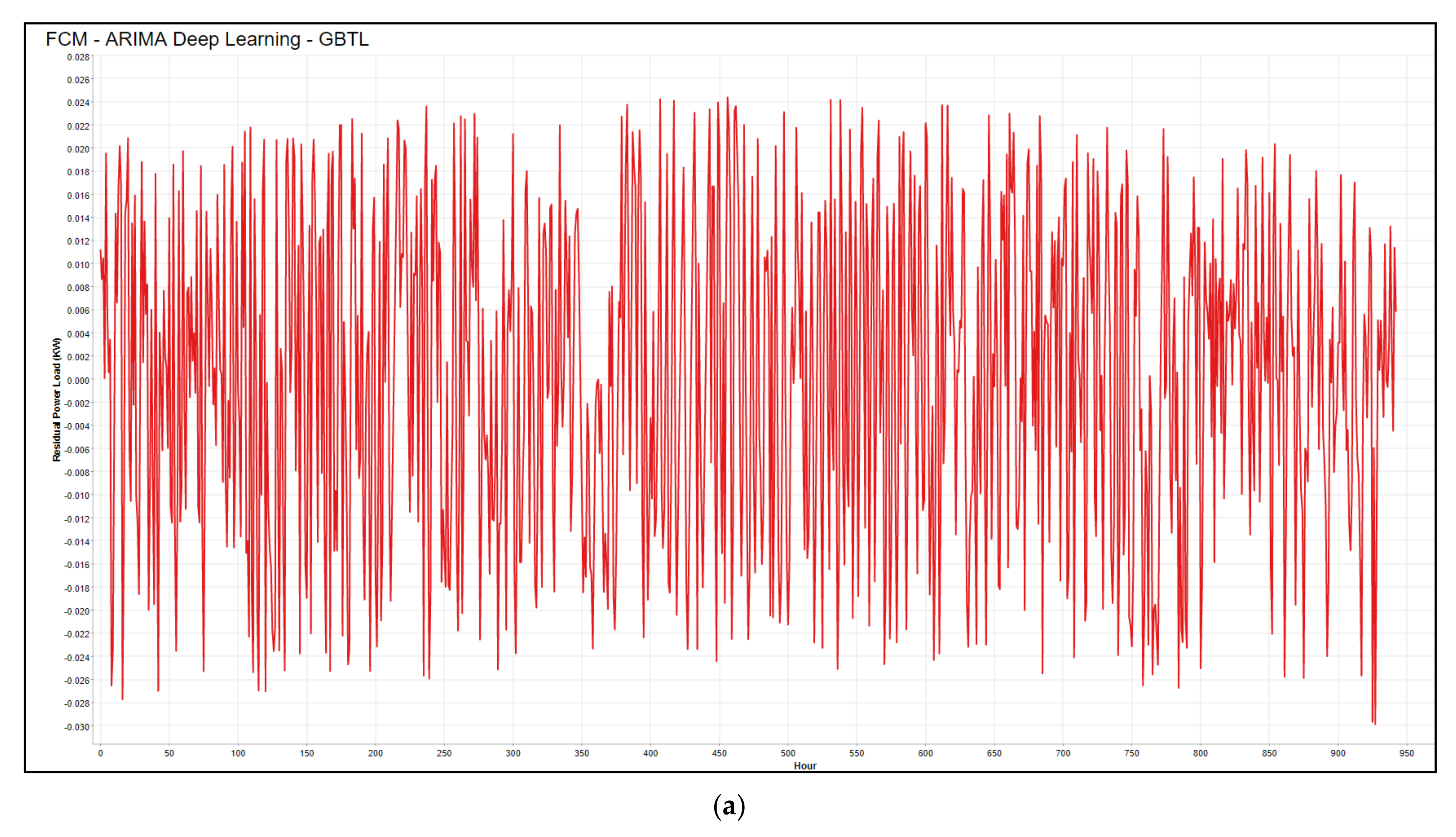
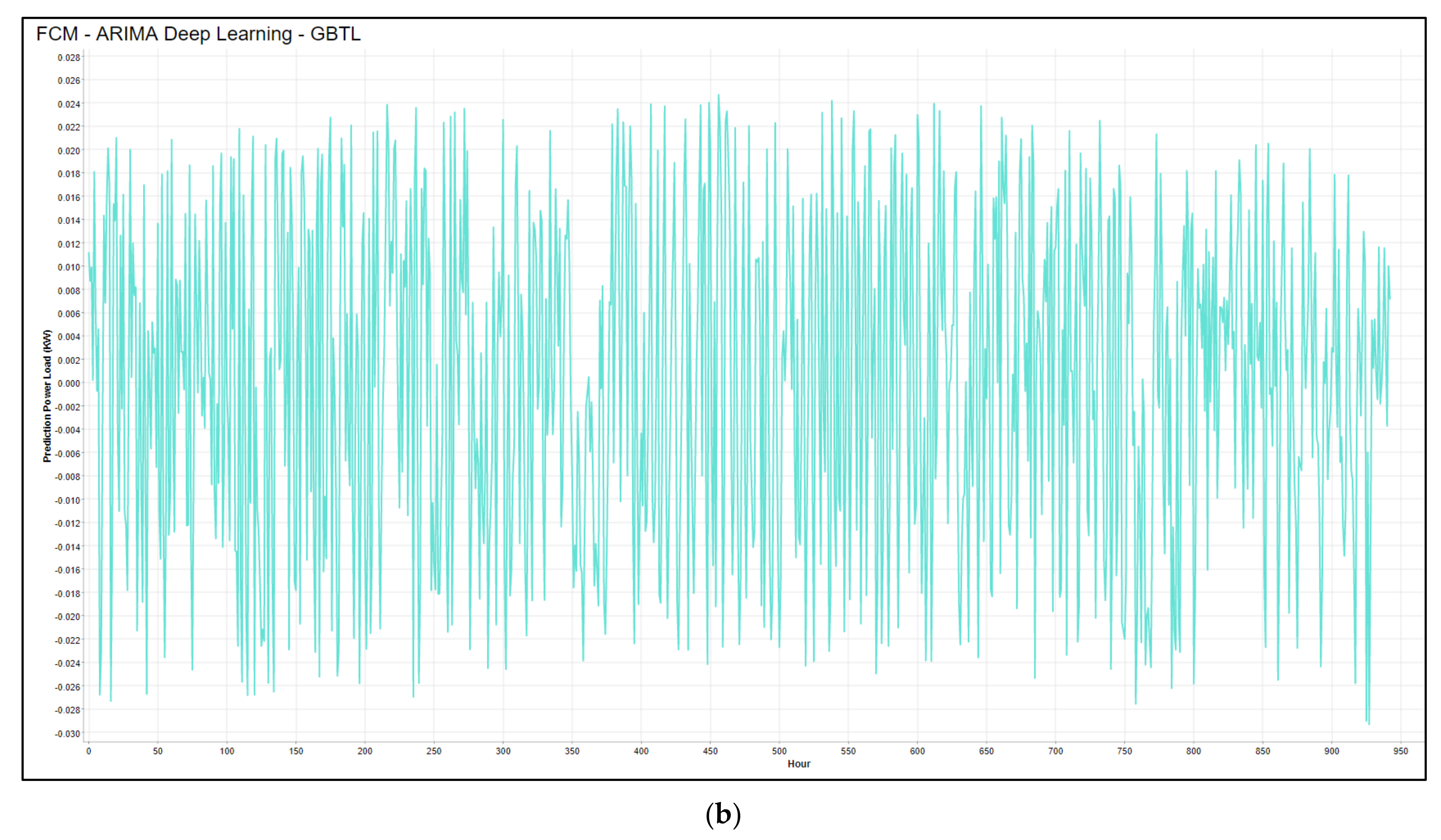
- Fifth Stage (GBTL Model): the ARIMA model can only predict value based on its previous lags (historic data), while no other assumptions are considered, such as weather conditions or any other external factors. Therefore, external variables might improve the forecast accuracy. Consequently, the residuals error resulting from the previous step will pass to the GBTL model to be trained and predicted with external factors such as Maximum, Minimum, and Average Degree. The Gradient-Boosted Trees model has multiple features to predict . The target variable then adds to the predictor sequentially to ensemble data while following the same sequence to correct the preceding predictors [15]. The GBTL can be represented mathematically, as given in Equation (4).
- = the overall forecasting results.
- = the forecasting result from the ARIMA model.
- = the forecasting result from the GBTL model.
6.1.2. Model Evaluation
- n = number of times the summation iteration happens.
- pi = actual value.
- ri = forecast value.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, H.; Wang, K.; Wang, Y.; Gao, M.; Zhang, Y. Energy big data: A survey. IEEE Access 2016, 4, 3844–3861. [Google Scholar] [CrossRef]
- Wu, J.; Guo, S.; Li, J.; Zeng, D. Big data meet green Challenges: Big data toward green applications. IEEE Syst. J. 2016, 10, 888–900. [Google Scholar] [CrossRef]
- He, F.; Zhou, J.; Mo, L.; Feng, K.; Liu, G.; He, Z. Day-ahead short-term load probability density forecasting method with a decomposition-based quantile regression forest. Appl. Energy 2020, 262, 114396. [Google Scholar] [CrossRef]
- Jeong, S.-Y.; Kim, J.-W.; Joo, H.-Y.; Kim, Y.-S.; Moon, J.-H. Development and Application of a Big Data Analysis-Based Procedure to Identify Concerns about Renewable Energy. Energies 2021, 14, 4977. [Google Scholar] [CrossRef]
- Refaat, S.S.; Mohamed, A.; Abu-Rub, H. Big data impact on stability and reliability improvement of smart grid. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1975–1982. [Google Scholar]
- Alahakoon, D.; Yu, X. Smart Electricity Meter Data Intelligence for Future Energy Systems: A Survey. IEEE Trans. Ind. Inform. 2016, 12, 425–436. [Google Scholar] [CrossRef]
- Hasan, M.K.; Ahmed, M.M.; Hashim, A.H.A.; Razzaque, A.; Islam, S.; Pandey, B. A Novel Artificial Intelligence Based Timing Synchronization Scheme for Smart Grid Applications. Wirel. Pers. Commun. 2020, 114, 1067–1084. [Google Scholar] [CrossRef]
- Al-Turjman, F.; Abujubbeh, M. IoT-enabled smart grid via SM: An overview. Future Gener. Comput. Syst. 2019, 96, 579–590. [Google Scholar] [CrossRef]
- Mosavi, A.; Bahmani, A. Energy Consumption Prediction Using Machine Learning: A Review. Preprints 2019. [Google Scholar] [CrossRef]
- Ayob, A.; Salim Reza, S.M.; Hussain, A.; Saad, M.H.M.; Amin, N. Cyber vulnerabilities in smart grid and safety measures for energy meters in advanced metering system and smart meter communications. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8. [Google Scholar] [CrossRef]
- Strasser, T.; Siano, P.; Ding, Y. Methods and Systems for a Smart Energy City. IEEE Trans. Ind. Electron. 2019, 66, 1363–1367. [Google Scholar] [CrossRef]
- Salam, A.; Hibaoui, A. Comparison of Machine Learning Algorithms for the Power Consumption Prediction—Case Study of Tetouan city–. In Proceedings of the 2018 6th International Renewable and Sustainable Energy Conference (IRSEC), Rabat, Morocco, 5–8 December 2018. [Google Scholar]
- Istepanian, L. Iraq’s Draft Electricity Law: What’s Right, What’s Wrong? Brookings. 2019. Available online: https://www.brookings.edu/research/iraqs-draft-electricity-law-whats-right-whats-wrong/ (accessed on 15 September 2020).
- IEA. Iraq’s Energy Sector. International Energy Agency. 2019. Available online: https://www.connaissancedesenergies.org/sites/default/files/pdf-actualites/Iraq_Energy_Outlook.pdf (accessed on 12 November 2020).
- Guerrero, J.I.; García, A.; Personal, E.; Luque, J.; León, C. Heterogeneous data source integration for smart grid ecosystems based on metadata mining. Expert Syst. Appl. 2017, 79, 254–268. [Google Scholar] [CrossRef]
- Kaur, D.; Aujla, G.S.; Kumar, N.; Zomaya, A.Y.; Perera, C.; Ranjan, R. Tensor-Based Big Data Management Scheme for Dimensionality Reduction Problem in Smart Grid Systems: SDN Perspective. IEEE Trans. Knowl. Data Eng. 2018, 30, 1985–1998. [Google Scholar] [CrossRef]
- Nepal, B.; Yamaha, M.; Yokoe, A.; Yamaji, T. Electricity load forecasting using clustering and ARIMA model for energy management in buildings. Jpn. Arch. Rev. 2020, 3, 62–76. [Google Scholar] [CrossRef]
- Sulandari, W.; Subanar; Lee, M.H.; Rodrigues, P.C. Indonesian electricity load forecasting using singular spectrum analysis, fuzzy systems and neural networks. Energy 2020, 190, 116408. [Google Scholar]
- Karthika, S.; Margaret, V.; Balaraman, K. Hybrid short term load forecasting using ARIMA-SVM. In Proceedings of the 2017 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 21–22 April 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Knime Analytics Platform. Available online: https://www.knime.com/ (accessed on 14 September 2021).
- Grover, P. Gradient Boosting from Scratch. Medium. 1 August 2019. Available online: https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d (accessed on 10 November 2020).
- Vom Scheidt, F.; Medinová, H.; Ludwig, N.; Richter, B.; Staudt, P.; Weinhardt, C. Data Analytics in the Electricity Sector—A Quantitative and Qualitative Literature Review. Energy 2020, 100009. [Google Scholar] [CrossRef]
- Saleem, Y.; Crespi, N.; Rehmani, M.; Copeland, R. Internet of Things-Aided Smart Grid: Technologies, Architectures, Applications, Prototypes, and Future Research Directions. IEEE Access 2019, 7, 62962–63003. [Google Scholar]
- Zhan, J.; Huang, J.; Niu, L.; Peng, X.; Deng, D.; Cheng, S. Study of the key technologies of electric power big data and its application prospects in smart grid. In Proceedings of the 2014 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Hong Kong, China, 7–10 December 2014; pp. 1–4. [Google Scholar]
- Zhang, Y.; Huang, T.; Bompard, E. Big data analytics in smart grids: A review. Energy Inform. 2018, 1. [Google Scholar] [CrossRef]
- Fahim, M.; Sillitti, A. Analyzing Load Profiles of Energy Consumption to Infer Household Characteristics Using Smart Meters. Energies 2019, 12, 773. [Google Scholar] [CrossRef]
- Sun, L.; Zhou, K.; Zhang, X.; Yang, S. Outlier Data Treatment Methods toward Smart Grid Applications. IEEE Access 2018, 6, 39849–39859. [Google Scholar] [CrossRef]
- Xia, H.; Zhao, M.; Chen, Y.; Wang, Z.; Yu, Z.; Yang, J. Multi-Source Heterogeneous Core Data Acquisition Method in Edge Computing Nodes. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019. [Google Scholar] [CrossRef]
- Dhupia, B.; Usha Rani, M.; Alameen, A. The Role of Big Data Analytics in Smart Grid Management. In Emerging Research in Data Engineering Systems and Computer Communications; Venkata Krishna, P., Obaidat, M., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 1054. [Google Scholar] [CrossRef]
- Bhattarai, B.P.; Paudyal, S.; Luo, Y.; Mohanpurkar, M.; Cheung, K.; Tonkoski, R.; Hovsapian, R.; Myers, K.S.; Zhang, R.; Zhao, P.; et al. Big data analytics in smart grids: State-of-the-art, challenges, opportunities, and future directions. IET Smart Grid 2019, 2, 141–154. [Google Scholar] [CrossRef]
- Rossi, B.; Chren, S. Smart Grids Data Analysis—A Systematic Mapping Study; Masaryk University: Brno, Czech Republic, 2019; pp. 1–26. [Google Scholar]
- Gnatyuk, V.I.; Kivchun, O.R.; Lutsenko, D.V. Digital platform for management of the regional power grid consumption. IOP Conf. Ser. Earth Environ. Sci. 2021, 689, 012022. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H. A review on machine learning forecasting growth trends and their real-time applications in different energy systems. Sustain. Cities Soc. 2019, 54, 102010. [Google Scholar] [CrossRef]
- Mir, A.A.; Alghassab, M.; Ullah, K.; Khan, Z.A.; Lu, Y.; Imran, M. A Review of Electricity Demand Forecasting in Low- and Middle-Income Countries: The Demand Determinants and Horizons. Sustainability 2020, 12, 5931. [Google Scholar] [CrossRef]
- Babich, L.; Svalov, D.; Smirnov, A.; Babich, M. Industrial Power Consumption Forecasting Methods Comparison. In Proceedings of the 2019 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 25–26 April 2019; pp. 307–309. [Google Scholar]
- Xu, M.; Qin, Z. A novel hybrid ARIMA and regression tree model for the interval-valued time series. J. Stat. Comput. Simul. 2020, 91, 1000–1015. [Google Scholar] [CrossRef]
- Sivarajah, U.; Kamal, M.; Irani, Z.; Weerakkody, V. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef]
- Marlen, A.; Maxim, A.; Ukaegbu, I.A.; Nunna, H.S.V.S.K. Application of Big Data in Smart Grids: Energy Analytics. In Proceedings of the 21st International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Korea, 17–20 February 2019; p. 402. [Google Scholar]
- Samie, F.; Bauer, L.; Henkel, J. From Cloud Down to Things: An Overview of Machine Learning in Internet of Things. IEEE Internet Things J. 2019, 6, 4921–4934. [Google Scholar] [CrossRef]
- Michael, K.; Miller, K. Big Data: New Opportunities and New Challenges [Guest editors’ introduction]. Computer 2013, 46, 22–24. [Google Scholar] [CrossRef]
- Jain, P.; Gyanchandani, M.; Khare, N. Big data privacy: A technological perspective and review. J. Big Data 2016, 3, 25. [Google Scholar] [CrossRef]
- Li, J.; Zhao, Y.; Sun, C.; Bao, X.; Zhao, Q.; Zhou, H. A Survey of Development and Application of Artificial Intelligence in Smart Grid. IOP Conf. Ser. Earth Environ. Sci. 2018, 186, 012066. [Google Scholar] [CrossRef]
- Li-Baboud, Y.; Nguyen, C.; Weiss, M.; Anand, D.; Goldstein, A.; Allnutt, J.; Noseworthy, B.; Subramaniam, R. Timing Challenges in the Smart Grid, Special Publication (NIST SP); National Institute of Standards and Technology: Gaithersburg, MD, USA, 2017. Available online: https://doi.org/10.6028/NIST.SP.1500-08 (accessed on 14 October 2021).
- Joshi, A.V. Essential Concepts in Artificial Intelligence and Machine Learning. In Machine Learning and Artificial Intelligence; Springer: Cham, Switzerland, 2019; pp. 9–20. [Google Scholar]
- Albayati, A.; Abdullah, N.F.; Abu-Samah, A.; Mutlag, A.H.; Nordin, R. A Serverless Advanced Metering Infrastructure Based on Fog-Edge Computing for a Smart Grid: A Comparison Study for Energy Sector in Iraq. Energies 2020, 13, 5460. [Google Scholar] [CrossRef]
- Bi, J.; Yuan, H.; Tie, M.; Song, X. Heuristic virtual machine allocation for multi-tier Ambient Assisted Living applications in a cloud data center. China Commun. 2016, 13, 56–65. [Google Scholar] [CrossRef]
- Häberle, T.; Charissis, L.; Fehling, C.; Nahm, J.; Leymann, F. The Connected Car in the Cloud: A Platform for Prototyping Telematics Services. IEEE Softw. 2015, 32, 11–17. [Google Scholar] [CrossRef]
- Barik, R.K.; Dubey, H.; Samaddar, A.B.; Gupta, D.R.; Ray, P.K. FogGIS: Fog Computing for geospatial big data analytics. In Proceedings of the 2016 IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics Engineering (UPCON), Varanasi, India, 9–11 December 2016; pp. 613–618. [Google Scholar] [CrossRef]
- Birkin, M. Big Data Challenges for Geoinformatics. Geoinfor. Geostat. Overview 2012, 1, 1. [Google Scholar] [CrossRef]
- Tuaimah, F.M.; Abbas, H.M.A. Iraqi Short Term Electrical Load Forecasting Based On Interval Type-2 Fuzzy Logic. Int. J. Electr. Robot. Electron. Commun. Eng. 2014, 8, 1262–1268. [Google Scholar]
- Raak, F.; Susuki, Y.; Hikihara, T. Data-Driven Partitioning of Power Networks Via Koopman Mode Analysis. IEEE Trans. Power Syst. 2016, 31, 2799–2808. [Google Scholar] [CrossRef]
- IBM. IBM Knowledge Center. Ibm.com. 2019. Available online: https://www.ibm.com/support/knowledgecenter/en/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/covr_3-tier.html (accessed on 14 November 2019).
- Kikuchi, S.; Matsumoto, Y. Impact of Live Migration on Multi-tier Application Performance in Clouds. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 261–268. [Google Scholar] [CrossRef]
- Takahashi, N.; Tanaka, H.; Kawamura, R. Analysis of Process Assignment in Multi-tier mobile Cloud Computing and Application to Edge Accelerated Web Browsing. In Proceedings of the 2015 3rd IEEE International Conference on Mobile Cloud Computing, Services, and Engineering, San Francisco, CA, USA, 30 March–3 April 2015; pp. 233–234. [Google Scholar] [CrossRef]
- Alam, K.; El Saddik, A. C2PS: A Digital Twin Architecture Reference Model for the Cloud-Based Cyber-Physical Systems. IEEE Access 2017, 5, 2050–2062. [Google Scholar] [CrossRef]
- Liu, X.; Heo, J.; Sha, L. Modeling 3-tiered Web applications. In Proceedings of the 13th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, Atlanta, GA, USA, 27–29 September 2005; pp. 307–310. [Google Scholar] [CrossRef]
- Li, Y.; Yang, W.; Xu, Y. Multi-Tier Granule Mining for Representations of Multidimensional Association Rules. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 953–958. [Google Scholar] [CrossRef]
- Qin, L.; Huang, T.; Zhang, H.; Gu, J. Development of archives management information system based on NET multi-tier architecture. In Proceedings of the 2009 3rd IEEE International Symposium on Microwave, Antenna, Propagation and EMC Technologies for Wireless Communications, Beijing, China, 27–29 October 2009; pp. 1210–1213. [Google Scholar] [CrossRef]
- Iraqi Ministry of Electricity (MOELC). Available online: https://www.moelc.gov.iq/ (accessed on 15 September 2021).
- Iraqi General Authority for Meteorology and Seismic Monitoring. Available online: http://meteoseism.gov.iq/ (accessed on 10 January 2021).
- Chu, X.; Ilyas, I.F.; Krishnan, S.; Wang, J. Data cleaning: Overview and emerging challenges. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 2201–2206. [Google Scholar]
- Data Science. Understanding Descriptive Statistics. Medium. 2019. Available online: https://towardsdatascience.com/understanding-descriptive-statistics-c9c2b0641291 (accessed on 13 November 2019).
- Liu, X.; Heo, J.; Sha, L.; Zhu, X. Adaptive Control of Multi-Tiered Web Applications Using Queueing Predictor. In Proceedings of the 2006 IEEE/IFIP Network Operations and Management Symposium NOMS 2006, Vancouver, BC, USA, 3–7 April 2006; pp. 106–114. [Google Scholar] [CrossRef]
- Keim, D.; Qu, H.; Ma, K. Big-Data Visualization. IEEE Comput. Graph. Appl. 2013, 33, 20–21. [Google Scholar] [CrossRef][Green Version]
- Donalek, C.; Djorgovski, S.G.; Cioc, A.; Wang, A.; Zhang, J.; Lawler, E.; Yeh, S.; Mahabal, A.; Graham, M.; Drake, A. Immersive and collaborative data visualization using virtual reality platforms. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 609–614. [Google Scholar] [CrossRef]
- Shah, D.; Rajwade, A. Projection Design for Compressive Source Separation Using Mean Errors and Cross-Validation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2035–2039. [Google Scholar] [CrossRef]
- Vandeput, N. Forecast KPI: RMSE, MAE, MAPE & Bias. Medium. 2019. Available online: https://medium.com/analytics-vidhya/forecast-kpi-rmse-mae-mape-bias-cdc5703d242d (accessed on 15 February 2021).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Country | Forecasting Techniques | Dataset | Result and Finding | Limitations | Accuracy |
|---|---|---|---|---|---|---|
| This work | Iraq | A hybrid load forecasting model using fuzzy c-means clustering, ARIMA, and gradient-boosted tree model. (FCM-ARIMA-GBTL) | Power consumption data, weather data | The results showed high accuracy in load forecasting with the proposed method (FCM-ARIMA-GBTL) which gives improved MAPE, MAE, and RMSE achievement in comparison with other evaluated models such as ARIMA and Gradient Boosted Trees alone. | The need for more historical data to improve accuracy. | Presented in results section |
| Ref. [17], 2020 | Japan | A hybrid model comprising a clustering technique and the Auto Regressive Integrated Moving Average (ARIMA) model. (K-means—ARIMA) | Power consumption data | The results show that a combination of clustering and the ARIMA model has proved to increase the performance of the forecasting model more accurately than that using the ARIMA model alone. | Forecasting per hour per day from 6 to 9 AM is used, which may cause uncertainty in the results due to an incomplete cycle. | MAPE = 2.7 |
| Ref. [18], 2020 | Indonesia | A hybrid methodology—Linear Recurrent Formula (SSA-LRF) and Neural Networks (NN) | Power consumption data | The study showed ideal results, as it relies only on energy consumption data without indicating any external factors that may increase or decrease energy consumption. | The performance in implementation of hybrid methodology | Not provided |
| Ref. [3], 2019 | China | A hybrid method with a decomposition-based quantile regression forest | Power consumption data, weather data | The results show that the hybrid method can improve prediction accuracy and providing more prediction information. | Not specified | MAPE = 0.48 |
| Ref. [19], 2018 | India | A hybrid Short Term Load Forecasting using ARIMA-SVM. | Power consumption data, weather data | The proposed ARIMA-SVM gives very good accuracy in STLF, especially if it was fed by external factors such as weather conditions. | The need for more historical data to improve the accuracy. | MAPE = 4.15 |
| Ref. [35], 2019 | Russian Federation | Long short-term memory (LSTM) artificial neural networks (ANN), and support vector machine (SVM) regression | Power consumption data | The results showed superiority for artificial neural networks (ANN), and support vector machine (SVM) regression for time series forecasting | The need to increase the amount of training data to improve prediction accuracy | MAPE range from 0.11 to 0.54 for different periods |
| Ref. [36], 2020 | China | A hybrid ARIMA and regression tree (RT) models (ARIMA—RT). | Interval-valued time-series dataset of the energy sector. | The results show that the ARIMA-RT model has a strong ability to capture the nonlinear part of the time-series dataset. | The period for which the model was applied was not sufficiently appropriate | MAPE = 0.56 |
| Language | English |
|---|---|
| Privacy | Private |
| Source and Ownership | Iraqi Ministry of Electricity (MOELC). |
| Sampling | 5,189,000 subscribers |
| Sampling After Data Cleaning | 1,445,000 Active subscribers |
| Data Collection Period | January 2019 to September 2019 |
| Database Type | CSV and Microsoft SQL Database |
| Parameters | 9 |
| Disc Size | Around 3.5 GB |
| Parameters | Descriptions |
|---|---|
| GUID | Unique identifier—Primary Key |
| Acc. Num. | Account Number |
| Region | Account Province (Fifteen provinces in Iraq)—Lookup Table |
| Met. Num. | Meter Number |
| Acc. Type | Account Type (Household, Commercial, Agricultural, Unclassified, Governmental, Industrial)—Lookup Table |
| Sub. Num. | Subscriber Number |
| Phase | Number of Phase per Subscriber (Single-phase or Tri-phase)—Lookup Table |
| Status | Meter status: Open or Close—Lookup Table |
| Managed by | Managed by (Managed by Local company, Managed by Ministry of Electricity)—Lookup Table |
| Parameters | Description |
|---|---|
| GUID | Unique identifier—Primary Key |
| Account_ GUID | Unique identifier for each account (Many to one linked to Table 3)—Foreign Key |
| Read value | Read value |
| read date | Date of Each Reading |
| Maximum_Temperature | Maximum Temperature |
| Minimum_Temperature | Minimum Temperature |
| Daily_Mean | Daily Mean |
| Average_Rainfall | Average Rainfall |
| Averag_Rainy_Days | Average Rainy Per Days |
| Average_Relative_Humidity | Average Relative Humidity |
| Min | Max | Mean | Std. Deviation | Variance | Skewness | Kurtosis | |
|---|---|---|---|---|---|---|---|
| Read value (Energy consumption) | 36,835 | 64,344 | 51,896.4 | 5479.97 | 30K+ | −0.58 | 0.50 |
| T. max | 12 | 54 | 32.79 | 11.14 | 124.18 | −0.26 | −1.31 |
| Daily mean | 5 | 39 | 23.93 | 10.14 | 102.78 | −0.28 | −1.41 |
| T. min | 2 | 30 | 17.69 | 8.43 | 71.15 | −0.32 | −1.38 |
| Av. rainfall | 0 | 111 | 18.46 | 27.21 | 740.21 | 1.92 | 2.96 |
| Av. Rainy days | 0 | 10 | 2.61 | 2.89 | 8.37 | 0.73 | −0.64 |
| Av. humidity | 20 | 76 | 40.63 | 19.55 | 382.38 | 0.36 | −1.48 |
| Sunshine hours | 192 | 353 | 283.65 | 59.93 | 3592.02 | −0.27 | −1.44 |
| Language | English |
|---|---|
| Privacy | Private |
| Source and Ownership | Iraqi Ministry of Electricity (MOELC). |
| Sampling | One Year for Baghdad Governorate (24 H*365 D) |
| Data Collection Period | 1 January 2019 to 31 December 2019 |
| Database Type | CSV |
| Parameters | (Load value Per Hour, Max, Min, AV Degree Per days) |
| Disc Size | Around 65 KB |
| (p,d,q) | AIC | |
|---|---|---|
| Cluster 0 | (3,0,4) | 5518.749 |
| Cluster 1 | (1,0,3) | 5252.404 |
| Cluster 2 | (3,0,2) | 8001.193 |
| Cluster 3 | (1,0,4) | 6900.293 |
| Cluster 4 | (2,0,3) | 5301.737 |
| Cluster 5 | (4,0,3) | 10,274.279 |
| Cluster 6 | (3,0,1) | 7033.124 |
| Cluster 7 | (4,0,2) | 5924.249 |
| Proposed Model (ARIMA-GBTL) | ARIMA | GBTL | |
|---|---|---|---|
| Cluster 0 | |||
| MAPE | 0.298241254 | 1.595470053 | 2.102847728 |
| MAE | 0.000802411 | 0.010943998 | 0.009823649 |
| RMSE | 0.001040184 | 0.013007015 | 0.012507055 |
| Cluster 1 | |||
| MAPE | 1.268934292 | 4.565898212 | 3.116166309 |
| MAE | 0.001681791 | 0.010046462 | 0.01249306 |
| RMSE | 0.002270159 | 0.012239579 | 0.014918207 |
| Cluster 2 | |||
| MAPE | 0.725948449 | 2.22781236 | 2.675913816 |
| MAE | 0.000863562 | 0.008580184 | 0.009404522 |
| RMSE | 0.001135038 | 0.010676258 | 0.011427171 |
| Cluster 3 | |||
| MAPE | 0.391079094 | 2.21031944 | 1.746144331 |
| MAE | 0.000506608 | 0.009794827 | 0.010266868 |
| RMSE | 0.000657717 | 0.011536968 | 0.012405158 |
| Cluster 4 | |||
| MAPE | 0.319013042 | 2.019749556 | 6.070942807 |
| MAE | 0.00073605 | 0.010264597 | 0.011093827 |
| RMSE | 0.000970941 | 0.01241723 | 0.013213787 |
| Cluster 5 | |||
| MAPE | 0.551668786 | 2.668732358 | 6.894689216 |
| MAE | 0.000929249 | 0.008082002 | 0.008988616 |
| RMSE | 0.001226214 | 0.009605795 | 0.010734888 |
| Cluster 6 | |||
| MAPE | 0.412275984 | 1.925889028 | 2.076377338 |
| MAE | 0.000967922 | 0.009308634 | 0.009529595 |
| RMSE | 0.00125275 | 0.011249835 | 0.011664366 |
| Cluster 7 | |||
| MAPE | 0.112522215 | 1.089237343 | 1.144672198 |
| MAE | 0.00042932 | 0.005786312 | 0.005946305 |
| RMSE | 0.000661391 | 0.008060203 | 0.008308765 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albayati, A.; Abdullah, N.F.; Abu-Samah, A.; Mutlag, A.H.; Nordin, R. Smart Grid Data Management in a Heterogeneous Environment with a Hybrid Load Forecasting Model. Appl. Sci. 2021, 11, 9600. https://doi.org/10.3390/app11209600
Albayati A, Abdullah NF, Abu-Samah A, Mutlag AH, Nordin R. Smart Grid Data Management in a Heterogeneous Environment with a Hybrid Load Forecasting Model. Applied Sciences. 2021; 11(20):9600. https://doi.org/10.3390/app11209600
Chicago/Turabian StyleAlbayati, Ammar, Nor Fadzilah Abdullah, Asma Abu-Samah, Ammar Hussein Mutlag, and Rosdiadee Nordin. 2021. "Smart Grid Data Management in a Heterogeneous Environment with a Hybrid Load Forecasting Model" Applied Sciences 11, no. 20: 9600. https://doi.org/10.3390/app11209600
APA StyleAlbayati, A., Abdullah, N. F., Abu-Samah, A., Mutlag, A. H., & Nordin, R. (2021). Smart Grid Data Management in a Heterogeneous Environment with a Hybrid Load Forecasting Model. Applied Sciences, 11(20), 9600. https://doi.org/10.3390/app11209600